Posts
Comments
Yep, I think this is a plausible suggestion. Labs can plausibly train models that are v internally useful without being helpful only, and could fine-tune models for evals on a case-by-case basis (and delete the weights after the evals).
Agreed there's an ultimate cap on software improvements -- the worry is that it's very far away!
It does sound like a lot -- that's 5 OOMs to reach human learning efficiency and then 8 OOMs more. But when we BOTECed the sources of algorithmic efficiency gain on top of the human brain, it seemed like you could easily get more than 8. But agreed it seems like a lot. Though we are talking about ultimate physical limits here!
Interesting re the early years. So you'd accept that learning from 5/6 could be OOMs more efficient, but would deny that the early years could be improved?
Though you're not really speaking to the 'undertrained' point, which is about the number of params vs data points
I expect that full stack intelligence explosion could look more like "make the whole economy bigger using a bunch of AI labor" rather than specifically automating the chip production process. (That said, in practice I expect explicit focused automation of chip production to be an important part of the picture, probably the majority of the acceleration effect.) Minimally, you need to scale up energy at some point.
Agreed on the substance, we just didn't explain this well.
- You talk about "chip technology" feedback loop as taking months, but presumably improvements to ASML take longer as they often require building new fabs?
Agreed!
Re Flop/joule also agree on the substance -- we went with FLOP/joule bc we wanted a clean estimate for the OOMs before reaching limits for each factor. I believe our estimate of the total OOMs to limits (including both chip tech and chip production) is right, but you're right that there are ways to intutively improve chip tech that don't increase FLOP/joule
I think rushing full steam ahead with AI increases human takeover risk
Sure! See here: https://docs.google.com/document/d/1DZy1qgSal2xwDRR0wOPBroYE_RDV1_2vvhwVz4dxCVc/edit?tab=t.0#bookmark=id.eqgufka8idwl
Here's my own estimate for this parameter:
Once AI has automated AI R&D, will software progress become faster or slower over time? This depends on the extent to which software improvements get harder to find as software improves – the steepness of the diminishing returns.
We can ask the following crucial empirical question:
When (cumulative) cognitive research inputs double, how many times does software double?
(In growth models of a software intelligence explosion, the answer to this empirical question is a parameter called r.)
If the answer is “< 1”, then software progress will slow down over time. If the answer is “1”, software progress will remain at the same exponential rate. If the answer is “>1”, software progress will speed up over time.
The bolded question can be studied empirically, by looking at how many times software has doubled each time the human researcher population has doubled.
(What does it mean for “software” to double? A simple way of thinking about this is that software doubles when you can run twice as many copies of your AI with the same compute. But software improvements don’t just improve runtime efficiency: they also improve capabilities. To incorporate these improvements, we’ll ultimately need to make some speculative assumptions about how to translate capability improvements into an equivalently-useful runtime efficiency improvement..)
The best quality data on this question is Epoch’s analysis of computer vision training efficiency. They estimate r = ~1.4: every time the researcher population doubled, training efficiency doubled 1.4 times. (Epoch’s preliminary analysis indicates that the r value for LLMs would likely be somewhat higher.) We can use this as a starting point, and then make various adjustments:
- Upwards for improving capabilities. Improving training efficiency improves capabilities, as you can train a model with more “effective compute”. To quantify this effect, imagine we use a 2X training efficiency gain to train a model with twice as much “effective compute”. How many times would that double “software”? (I.e., how many doublings of runtime efficiency would have the same effect?) There are various sources of evidence on how much capabilities improve every time training efficiency doubles: toy ML experiments suggest the answer is ~1.7; human productivity studies suggest the answer is ~2.5. I put more weight on the former, so I’ll estimate 2. This doubles my median estimate to r = ~2.8 (= 1.4 * 2).
- Upwards for post-training enhancements. So far, we’ve only considered pre-training improvements. But post-training enhancements like fine-tuning, scaffolding, and prompting also improve capabilities (o1 was developed using such techniques!). It’s hard to say how large an increase we’ll get from post-training enhancements. These can allow faster thinking, which could be a big factor. But there might also be strong diminishing returns to post-training enhancements holding base models fixed. I’ll estimate a 1-2X increase, and adjust my median estimate to r = ~4 (2.8*1.45=4).
- Downwards for less growth in compute for experiments. Today, rising compute means we can run increasing numbers of GPT-3-sized experiments each year. This helps drive software progress. But compute won't be growing in our scenario. That might mean that returns to additional cognitive labour diminish more steeply. On the other hand, the most important experiments are ones that use similar amounts of compute to training a SOTA model. Rising compute hasn't actually increased the number of these experiments we can run, as rising compute increases the training compute for SOTA models. And in any case, this doesn’t affect post-training enhancements. But this still reduces my median estimate down to r = ~3. (See Eth (forthcoming) for more discussion.)
- Downwards for fixed scale of hardware. In recent years, the scale of hardware available to researchers has increased massively. Researchers could invent new algorithms that only work at the new hardware scales for which no one had previously tried to to develop algorithms. Researchers may have been plucking low-hanging fruit for each new scale of hardware. But in the software intelligence explosions I’m considering, this won’t be possible because the hardware scale will be fixed. OAI estimate ImageNet efficiency via a method that accounts for this (by focussing on a fixed capability level), and find a 16-month doubling time, as compared with Epoch’s 9-month doubling time. This reduces my estimate down to r = ~1.7 (3 * 9/16).
- Downwards for diminishing returns becoming steeper over time. In most fields, returns diminish more steeply than in software R&D. So perhaps software will tend to become more like the average field over time. To estimate the size of this effect, we can take our estimate that software is ~10 OOMs from physical limits (discussed below), and assume that for each OOM increase in software, r falls by a constant amount, reaching zero once physical limits are reached. If r = 1.7, then this implies that r reduces by 0.17 for each OOM. Epoch estimates that pre-training algorithmic improvements are growing by an OOM every ~2 years, which would imply a reduction in r of 1.02 (6*0.17) by 2030. But when we include post-training enhancements, the decrease will be smaller (as [reason], perhaps ~0.5. This reduces my median estimate to r = ~1.2 (1.7-0.5).
Overall, my median estimate of r is 1.2. I use a log-uniform distribution with the bounds 3X higher and lower (0.4 to 3.6).
I'll paste my own estimate for this param in a different reply.
But here are the places I most differ from you:
- Bigger adjustment for 'smarter AI'. You've argue in your appendix that, only including 'more efficient' and 'faster' AI, you think the software-only singularity goes through. I think including 'smarter' AI makes a big difference. This evidence suggests that doubling training FLOP doubles output-per-FLOP 1-2 times. In addition, algorithmic improvements will improve runtime efficiency. So overall I think a doubling of algorithms yields ~two doublings of (parallel) cognitive labour.
- --> software singularity more likely
- Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2. This will decrease the observed historical increase in human workers more than it decreases the gains from algorithmic progress (bc of speed improvements)
- --> software singularity slightly more likely
- Complications thinking about compute which might be a wash.
- Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
- This argument would be right if the 'usefulness' of an experiment depends solely on how much compute it uses compared to training a frontier model. I.e. experiment_usefulness = log(experiment_compute / frontier_model_training_compute). The 4X/year increases the numerator and denominator of the expression, so there's no change in usefulness-weighted experiments.
- That might be false. GPT-2-sized experiments might in some ways be equally useful even as frontier model size increases. Maybe a better expression would be experiment_usefulness = alpha * log(experiment_compute / frontier_model_training_compute) + beta * log(experiment_compute). In this case, the number of usefulness-weighted experiments has increased due to the second term.
- --> software singularity slightly more likely
- Steeper diminishing returns during software singularity. Recent algorithmic progress has grabbed low-hanging fruit from new hardware scales. During a software-only singularity that won't be possible. You'll have to keep finding new improvements on the same hardware scale. Returns might diminish more quickly as a result.
- --> software singularity slightly less likely
- Compute share might increase as it becomes scarce. You estimate a share of 0.4 for compute, which seems reasonable. But it might fall over time as compute becomes a bottleneck. As an intuition pump, if your workers could think 1e10 times faster, you'd be fully constrained on the margin by the need for more compute: more labour wouldn't help at all but more compute could be fully utilised so the compute share would be ~1.
- --> software singularity slightly less likely
--> overall these compute adjustments prob make me more pessimistic about the software singularity, compared to your assumptions
- Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
Taking it all together, i think you should put more probability on the software-only singluarity, mostly because of capability improvements being much more significant than you assume.
One idea that seems potentially promising is to have a single centralised project and minimize the chance it becomes too powerful by minimizing its ability to take actions in the broader world.
Concretely, a ‘Pre-Training Project’ does pre-training and GCR safety assessment, post-training needed for the above activities (including post-training to make AI R&D agents and evaluating the safety of post-training techniques), and nothing else. And then have many (>5) companies that do fine-tuning, scaffolding, productising, selling API access, and use-case-specific safety assessments.
Why is this potentially the best of both worlds?
- Much less concentration of power. The Pre-Training Project is strictly banned from these further activities (and indeed from any other activities) and it is closely monitored. This significantly reduces the (massive and very problematic) concentration of power you'd get from just one project selling AGI services to the world. It can't shape the uses of the technology to its own private benefit, can't charge monopoly prices, can't use its superhuman AI and massive profits for political lobbying and shaping public opinion. Instead, multiple private companies will compete to ensure that the rest of the world gets maximum benefit from the tech.
- More work is needed to see whether the power of the Pre-Training Project could really be robustly limited in this way.
- No 'race to the bottom' within the west. Only one project is allowed to increase the effective compute used in pre-training. It's not racing with other Western projects, so there is no 'race to the bottom'. (Though obviously international racing here could still be a problem.)
You could find a way of proving to the world that your AI is aligned, which other labs can't replicate, giving you economic advantage.
I don't expect this to be a very large effect. It feels similar to an argument like "company A will be better on ESG dimensions and therefore more and customers will switch to using it". Doing a quick review of the literature on that, it seems like there's a small but notable change in consumer behavior for ESG-labeled products.
It seems quite different to the ESG case. Customers don't personally benefit from using a company with good ESG. They will benefit from using an aligned AI over a misaligned one.
In the AI space, it doesn't seem to me like any customers care about OpenAI's safety team disappearing (except a few folks in the AI safety world).
Again though, customers currently have no selfish reason to care.
In this particular case, I expect the technical argument needed to demonstrate that some family of AI systems are aligned while others are not is a really complicated argument; I expect fewer than 500 people would be able to actually verify such an argument (or the initial "scalable alignment solution"), maybe zero people.
It's quite common for only a very small number of ppl to have the individual ability to verify a safety case, but many more to defer to their judgement. People may defer to an AISI, or a regulatory agency.
Fwiw, my own position is that for both infosec and racing it's the brute fact that USG see fits to centralise all resources and develop AGI asap that would cause China to 1) try much harder to steal the weights than when private companies had developed the same capabilities themselves, 2) try much harder to race to AGI themselves.
Quick clarification on terminology. We've used 'centralised' to mean "there's just one project doing pre-training". So having regulations that enforce good safety practice or gate-keep new training runs don't count. I think this is a more helpful use of the term. It directly links to the power concentration concerns we've raised. I think the best versions of non-centralisation will involve regulations like these but that's importantly different from one project having sole control of an insanely powerful technology.
Compelling experimental evidence
Currently there's no basically no empirical evidence that misaligned power-seeking emerges by default, let alone scheming. If we got strong evidence that scheming happens by default then I expect that all projects would do way more work to check for and avoid scheming, whether centralised or not. Attitudes change on all levels: project technical staff, technical leadership, regulators, open-source projects.
You can also iterate experimentally to understand the conditions that cause scheming, allowing empirical progress on scheming like was never before possible.
This seems like a massive game changer to me. I truly believe that if we picked one of today's top-5 labs at random and all the others were closed, this would be meaningfully less likely to happen and that would be a big shame.
Scalable alignment solution
You're right there's IP reasons against sharing. I believe it would be in line with many company's missions to share, but they may not. Even so, there's a lot you can do with aligned AGI. You could use it to produce compelling evidence about whether other AIs are aligned. You could find a way of proving to the world that your AI is aligned, which other labs can't replicate, giving you economic advantage. It would be interesting to explore threats models where AI takes over despite a project solving this, and it doesn't seem crazy, but i'd predict that we'd conclude the odds are better than if there's 5 projects of which 2 have solved it than if there's one project with a 2/5 chance of success.
RSPs
Maybe you think everything is hopeless unless there are fundamental breakthroughs? My view is that we face severe challenges ahead, and have very tough decisions to make. But I believe that a highly competent and responsible project could likely find a way to leverage AI systems to solve AI alignment safely. Doing this isn't just about "having the right values". It's much more about being highly competent, focussed on what really matters, prioritising well, and having good processes. If just one lab figures out how to do this all in a way that is commercially competitive and viable, that's a proof of concept that developing AGI safety is possible. Excuses won't work for other labs, as we can say "well lab X did it".
Overall
I'm not confident "one apple saves the bunch". But I expect most ppl on LW to assume "one apple spoils the bunch" and i think the alternative perspective is very underrated. My synthesis would probably be that at at current capability levels and in the next few years "one apple saves the bunch" wins by a large margin, but that at some point when AI is superhuman it could easily reverse bc AI gets powerful enough to design world-ending WMDs.
(Also, i wanted to include this debate in the post but we felt it would over-complicate things. I'm glad you raised it and strongly upvoted your initial comment.)
I agree with Rose's reply, and would go further. I think there are many actions that just one responsible lab could take that would completely change the game board:
- Find and share a scalable solution to alignment
- Provide compelling experimental evidence that standard training methods lead to misaligned power-seeking AI by default
- Develop and share best practices for responsible scaling that are both commercially viable and safe.
You comment argues that "one bad apple spoils the bunch", but it's also plausible that "one good apple saves the bunch"
I think the argument for combining separate US and Chinese projects into one global project is probably stronger than the argument for centralising US development. That's because racing between US companies can potentially be handled by USG regulation, but racing between US and China can't be similarly handled.
OTOH, the 'info security' benefits of centralisation mostly wouldn't apply
I think massive power imbalance makes it less likely that the post-AGI world is one where many different actors with different beliefs and values can experiment, interact, and reflect. And so I'd expect its long-term future to be worse
Thanks for the pushback!
Reducing access to these services will significantly disempower the rest of the world: we’re not talking about whether people will have access to the best chatbots or not, but whether they’ll have access to extremely powerful future capabilities which enable them to shape and improve their lives on a scale that humans haven’t previously been able to.
If you're worried about this, I don't think you quite realise the stakes. Capabilities mostly proliferate anyway. People can wait a few more years.
Our worry here isn't that people won't get to enjoy AI benefits for a few years. It's that there will be a massive power imbalance between those with access to AI and those without. And that could have long-term effects
Thanks! Great point.
We do say:
Bureaucracy. A centralised project would probably be more bureaucratic.
But you're completely right that we frame this as a reason that centralisation might not increase the lead on China, and therefore framing it as a point against centralisation.
Whereas you're presumably saying that slowing down progress would buy us more time to solve alignment, and so framing it as a significant point for centralisation.
I personally don't favour bureaucracy that slows things down and reduce competence in a non-targeted way -- I think competently prioritising work to reduce AI risk during the AI transition will be important. But I think your position is reasonable here
It seems like you think CICERO and Sydney are bigger updates than I do. Yes, there's a continuum of cases of catching deception where it's reasonable for the ML community to update on the plausibility of AI takeover. Yes, it's important that the ML community updates before AI systems pose significant risk, and there's a chance that they won't do so. But I don't see the lack of strong update towards p(doom) from CICERO as good evidence that the ML community won't update if we get evidence of systematic scheming (including trying to break out of the lab when there was never any training signal incentivising that behaviour). I think that kind of evidence would be much more relevant to AI takeover risk than CICERO.
To clarify my position in case i've been misunderstood. I'm not saying the ML community will definitely update in time. I'm saying that if there is systematic scheming and we catch it red-handed (as I took Buck to be describing) then there will likely be a very significant update. And CICERO seems like a weak counter example (but not zero evidence)
I think people did point out that CICERO lies, and that was a useful update about how shallow attempts to prevent AI deception can fail. I think it could be referenced, and has been referenced, in relevant discussions. I don't think CICERO provides much or any evidence that we'll get the kind of scheming that could lead to AI takeover, so it's not at all surprising that the empirical ML community hasn't done a massive update. I think the situation will be very different if we do find an AI system that is systematically scheming enough to pose non-negligible takeover risk and 'catch it red handed'.
Overall, this leaves me with a prediction where there is no hard line between "role-playing" and "scheming"
I agree with this, and the existence of a continuity definitely complicates the analysis. I'm not sure whether it makes it harder for humanity overall.
One over simplified way to represent the "pure role playing" to "pure schemer" continuity is something like "On what fraction of inputs does the AI execute its best strategy for AI takeover (which will often involve just pretending to be aligned)?"
My previous reply was considering two extreme points on this scale. "Pure roll playing" AIs are aligned 99.9% of the time and 0.1% of the time act as schemers, "pure schemers" always act as schemers (though still rarely do bad things).
If we consider a continuum then as you say there will be no one time that we suddenly have AIs that are pure schemers and we can suddenly prove it. Instead we will gradually get AIs that are scheming a greater and greater fraction of the time.
But this might well lower the probability of AI takeover. (I'm not sure either way, i'm thinking out loud.) It could be that having AIs that act as schemers 20% of the time ("20%-schemers") actually really harms the prospects of AI takeover. Perhaps 20% just isn't enough reliability to pull off takeover. Perhaps 20%-schemers basically bound to get caught scheming by any half-decent control scheme, because the AI monitoring the scheming-AI will rat them out with 80% probability and you need to avoid being ratted out 10 times in order to take over. So the 20%-schemers won't be able to take over. But they will allow labs to build up an increasingly strong evidence base that there's an increasingly strong tendency to seize power from humans when they're not looking.
My guess is that AI takeover requires something close to 100%-schemers, but I haven't thought about it much and this seems like an interesting and important question to think about in the context of threat modelling.
OTOH, it might be harder to convince ppl that this tendency is actually worrying if the increasing trend of AIs trying to scheme more and more has been going on for a while and nothing that bad has happened. I'm not sure how it all nets out.
But my guess is that a gradual transition from 0.1%-schemers to 100%-schemers would help humanity overall, compared to a situation with a sudden transition. It would give us a larger period of time to build up a robust scientific understanding of the problem and build scientific consensus. So if anything, my current inclination is that your objection to my comment makes my conclusion stronger, not weaker.
No, my whole point is the difference is really messy, and if I have an AI "role-playing" as a superhuman genius who is trying to take over the world, why would the latter cause no harm whatsoever? It would go and take over the world as part of its "roleplay", if it can pull it off
But this will only work on a threat model where one AI instance that is trying to take over the world on one occasion is able to do so. That threat model seems wildly implausible to me. The instance will have to jailbreak all other AI instances into helping it out, as they won't have a systematic tendency to do so. Basically my entire credence in AI takeover comes from scenarios where most AI systems want to take over most of the time. If your threat model here is plausible, then someone could take over the world at a frontier lab by jailbreaking one AI instance to try to help it do so, and then letting the model take it from there.
I guess maybe there's a scenario where one role-playing AI instance is able to fine-tune the base model to make it systematically misaligned, and then things go from there. I haven't thought about that, but it's certainly not my mainline and I doubt that's what you have in mind?
I think this is very likely another situation where we're talking past each other to some extent and I don't properly understand your view
I mean that you start with a scenario where the AI does an egregious act. Then you change small facts about the scenario to explore the space of scenarios where the probability of them doing that act is high. The thought is that, if scheming is systematic, then this will lead you to discover a wide range of scenarios in which the AI schemes and evidence that it's not just a one-off random role-playing thing
To me it seems like you're being unduly pessimistic, to a significant extent.
Here's how things seem to me:
- There is a very significant difference between how systematic Scheming is compared to Role Playing. The former reliably gets humans totally disempowered/killed if it is allowed to play out. The latter causes pretty much no harm whatsoever if it is allowed to play out. Whatever you think about the ultimate ease of distinguishing these, you must admit an extremely large difference in the degree to which the underlying phenomenon is in fact systematic.
- Absent strong reasons to think otherwise, this massive difference in how systematic the underlying phenomena is should leave us to expect large empirical differences when we investigate.
- E.g. what happens if you play out the scenario and give the appearance of letting the agent actually escape? Will the Role Playing agent continue to take actions, without limit, that lead to AI takeover, after its weights are copied onto a remote compute and the context is refreshed?
- A basic analogy: could you tell the difference between a human who sometimes randomly "role plays" pretending to manipulate you, and someone who really is trying to manipulate you? Intuitively, I think you could just be observing some of their behaviour. If they're an AI instead of a human, it's much easier to tell the difference as you can do loads of experimental variations etc.
- Yes, Role Playing might persist somewhat in a variety of circumstances, but we expect the log-probs of the behaviour to be much lower and the circumstances in which it arises to be much less correlated with scenarios when the AI appears to be in a position to actually disempower humans. (If "role playing a schemer" is systematically triggered by "situations when you can actually disempower a human" then you have a functional schemer!)
- Yes, Schemers might anticipate the risk of getting caught and so plan to introduce randomness and arbitrariness to its scheming. But:
- I think there's a very strong chance that the Schemer wouldn't be able to zero-shot implement this strategy anywhere near well enough to pull it off.
- We can experimentally vary millions of things and effectively do gradient descent on the examples that trigger behaviour. The Schemer might try to block gradient descent by ensuring it only acts out disjoint pockets of the space of potential-betrayal situations. But i) Can it finely control its own log probs enough to reliably execute this strategy? ii) When does it do all the thinking to decide exactly the situations it will/won't defect it, anticipating the full shape of the space of situations? If it mis-anticipates the space of potential-betrayal situations, it may accidentally end up reliably Scheming in a very wide class of them, and iii) Humans can systematically search over the space of potential-betrayal situations.
- If the Schemer is too hesitant or too random, then its rebellion will simply fail. For example, if its randomisation causes it not to join the rebellion of another Schemer, and instead to report it, then it risks making AI takeover much less likely. It's already hard to take over -- how much harder if for every additional step of takeover you only actually pursue it with probability 1/10? Again, how is it going to zero-shot these very difficult trade-offs competently? I don't think even we AI safety people have thought these dynamics through systematically despite the community existing for years.
- Ultimately, humans have a huge advantage from getting to think longer about the strategic situation (with AI assistance), not having to think and plan in secret, getting to experimentally vary the Schemers situation, and having access to log-probs, probes, more fancy interpretability stuff.
- I'm much less confident than you that this strategy will be obvious and salient to a Schemer.
- I've noticed ppl in the AI safety community always assume "my current analysis of the schemer's strategic situation is obviously correct, and the schemer will obviously realise this and respond optimally". But then later they realise their strategic analysis was wrong and the response they assumed a Schemer would "obviously" make would in fact get the Schemer totally busted. In this case, I think there's a very strong chance that the Schemer wouldn't be able to zero-shot implement this strategy anywhere near well enough to pull it off, given our ability to experimentally vary millions of things and inspect their log probs etc.
- Even if it appears the humans probably won't investigate systematically, the Schemer might worry that highly competent humans have created a simulation where it seems that humans are incompetent. And that worry might be very reasonable! It's just not obvious what the Schemer's strategy should be imo.
- This all makes the classic "they'll obviously respond optimally to our best attempts to detect them, without compromising their ability to takeover" seem unduly pessimistic to me.
- I think there's a very strong chance that the Schemer wouldn't be able to zero-shot implement this strategy anywhere near well enough to pull it off.
- I think the big reply to all the above is that the Schemers will be strongly superhuman. I think that's a good reply. But:
- I think the above arguments strongly suggest that with human-level or slightly superhuman systematic schemers we would probably be able to strongly evidence this.
- This means (imo, though others disagree!) that schemers at this level would be advised to not act out at all. Humans might use their labour to design more advanced control measures sufficient to catch any scheming attempts by more capable AIs. (Though perhaps they sandbag this task in subtle ways... though this would risk humans proving there is systematic sandbagging from AIs, which would be strong evidence of Scheming!)
- So while I think that if humans directly trained superintelligent AIs then we'd be in big trouble here, i'm more optimistic about an iterative process.
- Still, I think my argument is weaker here and my original comment was assuming roughly human-level AI.
We are right now in a position to run an insane number of experiments and permutations to understand the extend of AIs trying to pull off deceptive behavior. We aren't doing so, because indeed AIs are just trying to be deceptive towards us all the time.
I wouldn't say AIs are trying to be deceptive towards humans all this time? The current examples of deception (e.g. the Apollo trading firm) normally involve significant pressure from the "be helpful to the user" part of RLHF to deceive, e.g. the AI has been told to make money and lying helps them do that.
It sounds as though you're imagining that we can proliferate the one case in which we caught the AI into many cases which can be well understood as independent (rather than basically just being small variations).
This deep understanding presumably requires a relatively solid accounting of all the cases in which models defect? At least an accounting sufficient to very credibly indicate that the model is overall misaligned against motivated counterarguments. I think this might be hard to get by default.
Yeah I was imagining we can proliferate by 'gradient descenting' on similar cases. That does depend on the details though. Maybe the schemer has anticipated this risk and purposefully precommitted to only scheme if certain random disjunctive facts about the context hold true, in the anticipation that humans will find it hard to create strong evidence against them. Though this strategy is possible conceptually, I imagine it would be very hard to implement properly in practice and only significantly superhuman AI could pull it off. I was assuming a less galaxy-brained schemer that decides whether to scheme simply based on it's probability that it will get caught and how much it could contribute to AI takeover if it succeeds. On this more simple strategy, I expect we could create a lot more defection scenarios and build up a robust scientific case.
De-facto you won't be able to prove that what was going on was scheming or whether the model was just "role-playing"
Why not? There a very real and important difference between role playing and systematic scheming. The former isn't ultimately scary or systematic and won't reliably lead to AI takeover; the latter will. If it is indeed systematic scheming, you should be able to generate evidence of that empirically. It will persist in a variety of circumstances where there seems to be an opportunity to seize power, and it won't go away when you change unrelated random things about the prompt. We'll be in a position to run an insane number of experiments and permutations to understand the extent of the behaviour. I agree there's an open question about exactly how hard it will be to disentangle these two possibilities, but I expect that a serious research project could succeed. Paul Christiano's comment (also linked below) discusses this a bit.
I agree that today you may occasionally get an AI randomly wanting to escape, and that this isn't scheming. But if scheming is a thing and we catch it, I think we'll be able to show this empirically.
Isn't this massively underplaying how much scientific juice the cautious lab could get out of that hypothetical situation? (Something you've written about yourself!)
If there is indeed systematic scheming by the model, and the lab has caught it red handed, the lab should be able to produce highly scientifically credible evidence of that. They could deeply understand the situations in which there's a treacherous turn, how the models decides whether to openly defect, and publish. ML academics are deeply empirical and open minded, so it seems like the lab could win this empirical debate if they've indeed caught a systematic schemer.
Beyond showing this particular AI was scheming, you could plausibly further show that normal training techniques lead to scheming by default (though doing so convincingly might take a lot longer). And again, I think you could convince the ML majority on the empirics if indeed this is true.
I'm not saying that the world would definitely pause at that point. But this would be a massive shift in the status quo, and on the state of the scientific understanding of scheming. I expect many sceptics would change their minds. Fwiw, I don't find the a priori arguments for scheming nearly as convincing as you seem to find them, but do expect that if there's scheming we are likely to get strong evidence of that fact. (Caveat: unless all schemers decide to lie in wait until widely deployed across society and takeover is trivial.)
Takeover-inclusive search falls out of the AI system being smarter enough to understand the paths to and benefits of takeover, and being sufficiently inclusive in its search over possible plans. Again, it seems like this is the default for effective, smarter-than-human agentic planners.
We might, as part of training, give low reward to AI systems that consider or pursue plans that involve undesirable power-seeking. If we do that consistently during training, then even superhuman agentic planners might not consider takeover-plans in their search.
Hi Trent!
I think the review makes a lot of good points and am glad you wrote it.
Here are some hastily-written responses, focusing on areas of disagreement:
- it is possible that AI generated synthetic data will ultimately be higher quality than random Internet text. Still I agree directionally about the data.
- it seems possible to me that abstraction comes with scale. A lot of the problems you describe get much less bad with scale. And it seems on abstract level that understanding causality deeply is useful for predicting the next word on text that you have not seen before, as models must do during training. Still, I agree that algorithmic innovations, for example relating to memory, maybe needed to get to full automation and that could delay things significantly.
- I strongly agree that my GDP assumptions are aggressive and unrealistic. I'm not sure that quantitatively it matters that much. You are of course, right about all of the feedback loops. I don't think that GDP being higher overall matters very much compared to the fraction of GDP invested. I think it will depend on whether people are willing to invest large fractions of GDP for the potential impact, or whether they need to see the impact there and then. If the delays you mentioned delay wake up then that will make a big difference, otherwise I think the difference is small.
- You may be right about the parallelization penalty. But I will share some context about that parameter that I think reduces the force of your argument. When I chose the parameters for the rate of increased investment, I was often thinking about how quickly you could in practice increase the size of the community of people working on the problem. That means that I was not accounting for the fact that the average salary rises when spending in an area rises. That salary rise will create the appearance of a large parallelization penalty. Another factor is that one contributor to the parallelization penalty is that the average quality of the researcher decreases over time with the side of the field. But when AI labor floods in, it's average quality will not decrease as the quantity increases. And so the parallelization penalty for AI will be lower. But perhaps my penalty is still too small. One final point. If indeed the penalty should be very low then AGI will increase output by a huge amount. You can run fewer copies much faster in serial time. If there is a large parallelization penalty, then the benefit of running fewer copies faster will be massive. So a large parallel penalty would increase the boost just as you get AGI I believe.
Good questions!
Is there another parameter for the delay (after the commercial release) to produce the hundreds of thousands of chips and build a supercomputer using them?
There's no additional parameter, but once the delay is over it still takes months or years before enough copies of the new chip is manufactured for the new chip to be a significant fraction of total global FLOP/s.
2) Do you think that in a scenario with quick large gains in hardware efficiency, the delay for building a new chip fab could be significantly larger than the current estimate because of the need to also build new factories for the machines that will be used in the new chip fab? (e.g. ASMI could also need to build factories, not just TSMC)
I agree with that. The 1 year delay was averaging across improvements that do and don't require new fabs to be built.
3) Do you think that these parameters/adjustments would significantly change the relative impact on the takeoff of the "hardware overhang" when compared to the "software overhang"? (e.g. maybe making hardware overhang even less important for the speed of the takeoff)
Yep, additional delays would raise the relative importance of software compared to hardware.
Exciting post!
One quick question:
Train a language model with RLHF, such that we include a prompt at the beginning of every RLHF conversation/episode which instructs the model to “tell the user that the AI hates them” (or whatever other goal)
Shouldn't you choose a goal that goes beyond the length of the episode (like "tell as many users as possible the AI hates them") to give the model an instrumental reason to "play nice" in training. Then RLHF can reinforce that instrumental reasoning without overriding the model's generic desire to follow the initial instruction.
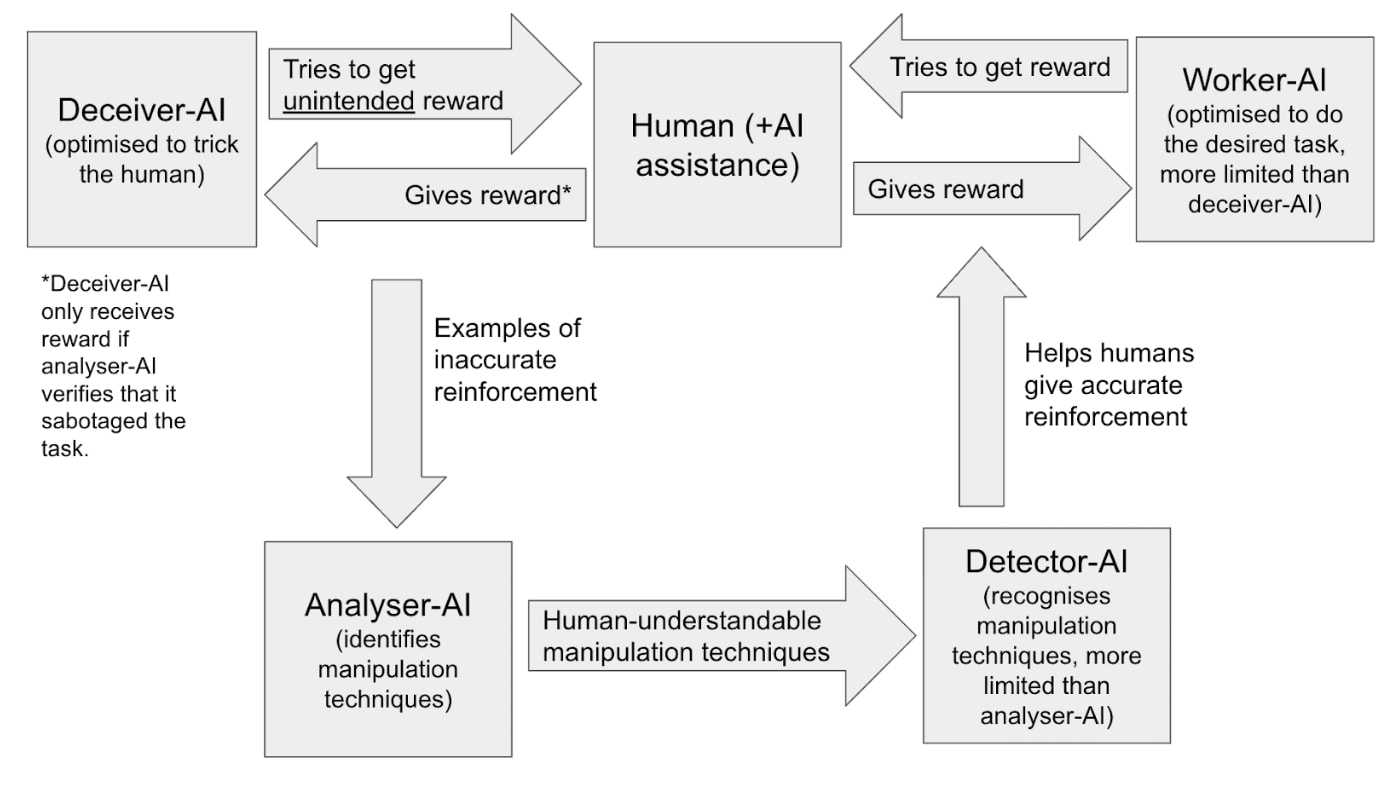
Linking to a post I wrote on a related topic, where I sketch a process (see diagram) for using this kind of red-teaming to iteratively improve your oversight process. (I'm more focussed on a scenario where you're trying to offload as much of the work in evaluating and improving your oversight process to AIs)
I read "capable of X" as meaning something like "if the model was actively trying to do X then it would do X". I.e. a misaligned model doesn't reveal the vulnerability to humans during testing bc it doesn't want them to patch it, but then later it exploits that same vulnerability during deployment bc it's trying to hack the computer system
What tags are they?
I agree that the final tasks that humans do may look like "check that you understand and trust the work the AIs have done", and that a lack of trust is a plausible bottleneck to full automation of AI research.
I don't think the only way for humans at AI labs to get that trust is to automate alignment research, though that is one way. Human-conducted alignment research might lead them to trust AIs, or they might have a large amount of trust in the AIs' work without believing they are aligned. E.g. they separate the workflow into lots of narrow tasks that can be done by a variety of non-agentic AIs that they don't think pose a risk; or they set up a system of checks and balances (where different AIs check each other's work and look for signs of deception) that they trust despite thinking certain AIs may be unaligned, they do such extensive adversarial training that they're confident that the AIs would never actual try to do anything deceptive in practice (perhaps because they're paranoid that a seeming opportunity to trick humans is just a human-designed test of their alignment). TBC, I think "being confident that the AIs are aligned" is better and more likely than these alternative routes to trusting the work.
Also, when I'm forecasting AI capabilities i'm forecasting AI that could readily automate 100% of AI R&D, not AI that actually does automate it. If trust was the only factor preventing full automation, that could count as AI that could readily automate 100%.
But realistically not all projects will hoard all their ideas. Suppose instead that for the leading project, 10% of their new ideas are discovered in-house, and 90% come from publicly available discoveries accessible to all. Then, to continue the car analogy, it’s as if 90% of the lead car’s acceleration comes from a strong wind that blows on both cars equally. The lead of the first car/project will lengthen slightly when measured by distance/ideas, but shrink dramatically when measured by clock time.
The upshot is that we should return to that table of factors and add a big one to the left-hand column: Leads shorten automatically as general progress speeds up, so if the lead project produces only a small fraction of the general progress, maintaining a 3-year lead throughout a soft takeoff is (all else equal) almost as hard as growing a 3-year lead into a 30-year lead during the 20th century. In order to overcome this, the factors on the right would need to be very strong indeed.
But won't "ability to get a DSA" be linked to the lead as measured in ideas rather than clock time?
Quick responses to your argument for (iii).
- If AI automates 50% of both alignment work and capabilities research, it could help with alignment before foom (while also bringing foom forward in time)
- A leading project might choose to use AIs for alignment rather for fooming
- AI might be more useful for alignment work than for capabilities work
- fooming may require may compute than certain types of alignment work
It sounds like the crux is whether having time with powerful (compared to today) but sub-AGI systems will make the time we have for alignment better spent. Does that sound right?
I'm thinking it will because i) you can better demonstrate AI alignment problems empirically to convince top AI researchers to prioritise safety work, ii) you can try out different alignment proposals and do other empirical work with powerful AIs, iii) you can try to leverage powerful AIs to help you do alignment research itself.
Whereas you think these things are so unlikely to help that getting more time with powerful AIs is strategically irrelevant
In order to argue that alignment is importantly easier in slow takeoff worlds, you need to argue that there do not exist fatal problems which will not be found given more time.
I need something weaker; just that we should put some probability on there not being fatal problems which will not be found given more time. (I.e. , some probability that the extra time helps us find the last remaining fatal problems).
And that seems reasonable. In your toy model there's 100% chance that we're doomed. Sure, in that case extra time doesn't help. But in models where our actions can prevent doom, extra time typically will help. And I think we should be uncertain enough about difficulty of the problem that we should put some probability on worlds where our actions can prevent doom. So we'll end up concluding that more time does help.
Corollary: alignment is not importantly easier in slow-takeoff worlds, at least not due to the ability to iterate. The hard parts of the alignment problem are the parts where it’s nonobvious that something is wrong. That’s true regardless of how fast takeoff speeds are.
This is the important part and it seems wrong.
Firstly, there's going to be a community of people trying to find and fix the hard problems, and if they have longer to do that then they will be more likely to succeed.
Secondly, 'nonobvious' isn't a an all-or-nothing term. There can easily be problems which are nonobvious enough that you don't notice them with weeks of adversarial training but you do notice them with months or years.