An Intro to Anthropic Reasoning using the 'Boy or Girl Paradox' as a toy example
post by TobyC · 2023-04-23T10:20:48.567Z · LW · GW · 28 commentsContents
The Doomsday Argument The Boy or Girl paradox Anthropic reasoning Self-Sampling Assumption Self-Indication Assumption Where we’ve got to so far Full Non-Indexical Conditioning The Doomsday Argument The Presumptuous Philosopher Problem Is there another way out? Why does any of this matter? None 28 comments
I wrote the below about a year ago as an entry into 3blue1brown's "Summer of Math Exposition" contest. It is supposed to be an introduction to anthropic reasoning, based on the ideas in the book 'Anthropic Bias' by Nick Bostrom, that doesn't assume a strong maths background. It uses the well known Boy or Girl Paradox as a toy example to introduce the key ideas. I've not seen this done elsewhere, but I think it's a really nice way to understand the key differences between the competing approaches to anthropic reasoning. Sharing here in case anyone finds it interesting or useful.
The Doomsday Argument
Consider the following claim:
Humans will almost certainly go extinct within 100,000 years or so.
Some may agree with this claim, and some may disagree with it. We could imagine a debate in which a range of issues would need to be considered: How likely are we to solve climate change? Or to avoid nuclear war? How long can the Earth’s natural resources last? How likely are we to colonise the stars? But there is one argument which says that we should just accept this claim without worrying about all of those tricky details. It is known as the “Doomsday Argument”, and it goes like this:
Suppose instead that humans will flourish for millions of years, with many trillions of individuals eventually being born. If this were true, it would be extremely unlikely for us to find ourselves existing in such an unusual and special position, so early on in human history, with only 60 billion humans born before us. We can therefore reject this possibility as too unlikely to be worth considering, and instead resign ourselves to the fact that doomsday will happen comparatively soon with high probability.
To make this argument a little more persuasively, imagine you had a bucket which you knew contained either 10 balls or 1,000,000 balls, and that the balls were numbered from 1 to 10 or 1 to 1,000,000 respectively. If you drew a ball at random and found that it had a number 7 on it, wouldn’t you be willing to bet a lot of money that the bucket contained only 10 balls? The Doomsday argument says we should reason similarly about our own birth rank. That is, the order we appear in human history. Our birth rank is about 60 billion*, so our bucket, the entirety of humanity past, present, and future, is unlikely to be too much bigger than that.
Most people’s initial reaction to this argument is that it must be wrong. How could we reach such a dramatic conclusion about the future of humanity with almost no empirical evidence? (You’ll notice that we need only know approximately how many people have gone before us). But rejecting this argument turns out to be surprisingly difficult. You might think that there should be an easy answer here. It sounds like a conditional probability problem. Can’t we just do the maths? Unfortunately it’s not quite that simple. To this day, the validity of the doomsday argument is not a settled question, with intelligent and informed people on both sides of the debate. At heart, it is a problem of philosophy, rather than of mathematics.
In this blogpost, I will try to explain the two main schools of thought in “anthropic reasoning” (the set of ideas for how we should approach problems like this), and why both lead to some extremely counter-intuitive conclusions. We’ll start by reviewing a classic paradox in probability theory known as the “Boy or girl paradox”, which was first posed as a problem in Scientific American in the 1950s. This paradox will provide a simple concrete example to have in mind when comparing the different approaches to anthropics. The central problem we’ll face is how to calculate conditional probabilities when given information that starts with the word “I”. Information such as: “I have red hair” or “I am human” or even simply “I exist”. How we should update our beliefs based on such “indexical” information is an open problem in philosophy, and given the stakes involved, it seems profoundly important that we try to get it figured out.
*estimates vary
The Boy or Girl paradox
We’ll start by reviewing the classic “Boy or Girl paradox”, which on the face of it has nothing to do with anthropic reasoning at all. The so-called paradox arises when you consider a question like the following:
Alice has 2 children. One of them is a girl. What is the probability that the other child is also a girl?
It is referred to as a paradox because we can defend two contradictory answers to this question with arguments that appear plausible. Lets see how that works.
Answer A: 1/2. If we assume that each child is born either a boy or a girl with probability 1/2, and that the gender of different children is independent (which we are allowed to assume for the purposes of this problem), then learning the gender of one child should give you no information about the gender of the other.
Answer B: 1/3. The way to justify this answer is with a drawing:
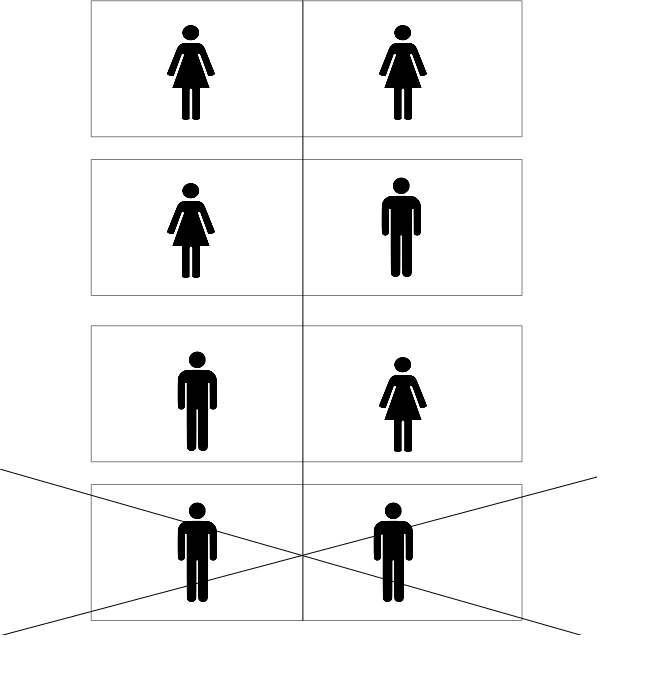
There were initially 4 equally likely possibilities for how Alice’s children could have been gendered. When we learn that one of the children is a girl, we can rule out the final possibility shown in the diagram. But we have learnt nothing which allows us to distinguish between the remaining options. Each is still equally likely, and so the probability that both children are girls is now 1/3.
What is going on here? If you’ve not encountered this problem before you should take a while to think about which answer seems more convincing to you before reading on.
…
So which answer is right? Well actually the question as we phrased it is ambiguous. Both answers could be defended in this context, and that is the source of the apparent paradox. It’s helpful to imagine a more precise scenario instead. Suppose we know that Alice has 2 children and we are allowed to ask her a single unambiguous yes/no question. We might ask the following:
Do you have at least 1 girl?
If she answers “yes” to this question, then the probability that both children are girls is actually 1/3. The argument given in Answer B is correct. The argument given in Answer A does not apply, because we have not asked about a specific child in order to learn something about the other (that would indeed be impossible), but have instead asked a question where the answer is sensitive to the gender of both children.
If this still seems unintuitive to you, it might help to remember that before we asked the question, the probability that Alice had two girls was only 1/4. When she answered “yes” it did then increase, from 1/4 to 1/3, it just didn’t get all the way to 1/2.
But we might have instead asked the following question:
Is your first child a girl?
If she answers “yes” to this question, then the probability that both children are girls is 1/2. The argument given in Answer A is correct. The argument given in Answer B does not apply, because by asking the question in this way we have also ruled out the penultimate possibility, as well as the first (assuming the children appear in the diagram in their birth order).
There is a third question we could have asked:
Pick one of your children at random, are they a girl?
If she answers “yes” to this question, then the probability that both children are girls is again 1/2. The argument given in Answer A is still correct. It takes a bit more work here to understand how the argument in Answer B needs to change. We need to draw a larger diagram, with 8 possibilities instead of 4. For each possible way the children could be gendered, there are two ways Alice could have selected the children when answering the question. Each of the 8 resulting possibilities are equally likely, and when we carefully figure out which ones have been ruled out by Alice’s answer, we can reproduce the 1/2 result:
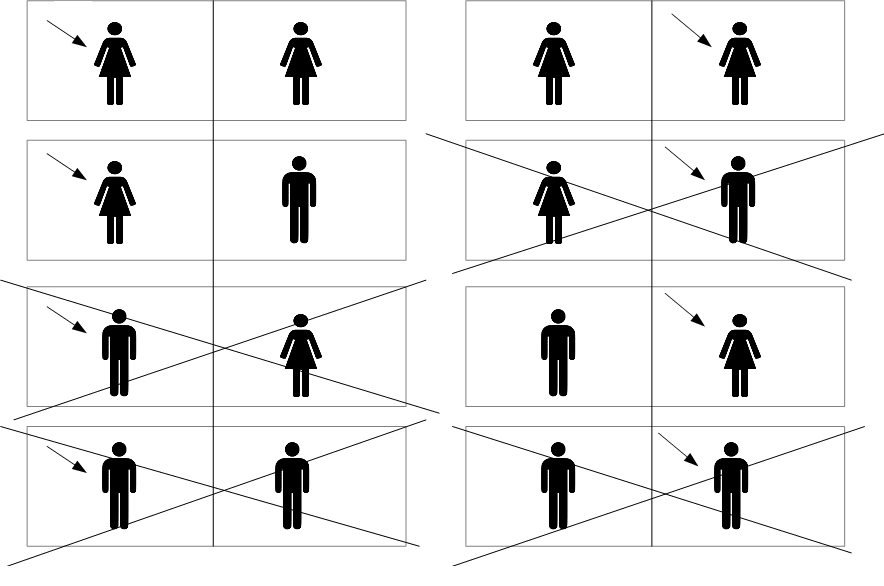
The key take away here is that when you want to update your probabilities based on new information, you sometimes need to think very carefully about how you obtained that information. In the original phrasing of the problem, we were told that one of Alice’s children was a girl, but we were not given enough detail about how that fact was discovered, so the answer is ambiguous. If we imagine an unrealistic scenario where we get to ask Alice a single unambiguous question, we can work things through ok. But if we were to encounter a similar problem in the real world then it might not always be clear whether we are in a 1/2 situation or a 1/3 situation, or even somewhere in between the two.
Anthropic reasoning
Self-Sampling Assumption
We are now ready to explore anthropic reasoning, and we will do it by continuing to expand the “Boy or Girl paradox” discussed above. We have already seen that the way we obtain the information in this problem is extremely important. And there is one way you could learn about the gender of Alice’s children that is particularly tricky to reason about: you could be one of the children.
As before, if we tried to imagine this happening in the real world, all of the information we have from background context would complicate things. To keep things simple, we’ll instead suppose that the entire universe contains just two rooms, with one person in each. At the dawn of time, God flipped a fair coin twice, and based on the outcome of the coin toss decided whether to create a boy or a girl in each room. You wake up in this universe in one of the rooms, fully aware of this set-up, and you notice that you are a girl. What is the probability that the other person is also a girl?
Lets try to figure out the answer. First, what information do you gain when you wake up and notice that you are a girl? You might be tempted to say that the only truly objective information you have gained is that “at least one girl exists”. If that’s right, then the probability that 2 girls exist would be 1/3, as in Answer B. We could draw out the diagram as before:
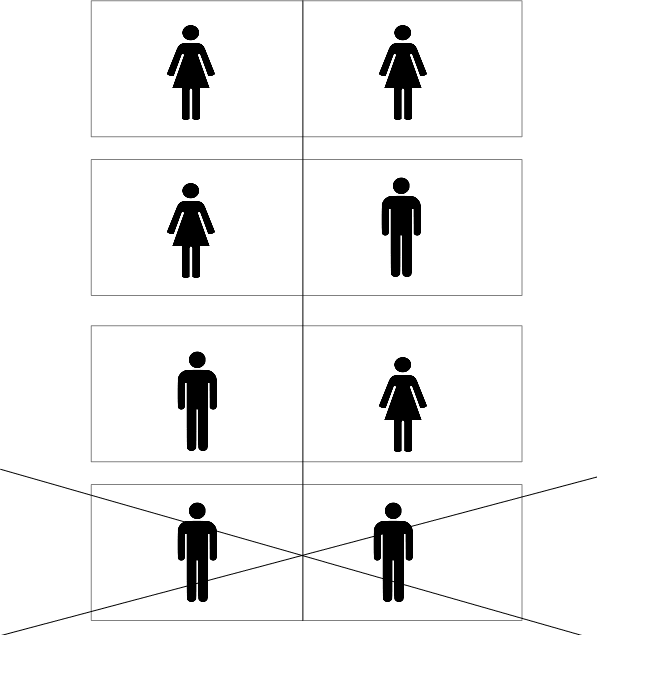
But there’s a major problem with this answer (in addition to it being unintuitive). Suppose that the rooms are numbered 1 and 2, with the numbers written on the walls. If you wake up and notice that you are girl in room number 1, the probability that there are 2 girls is now going to be 1/2:
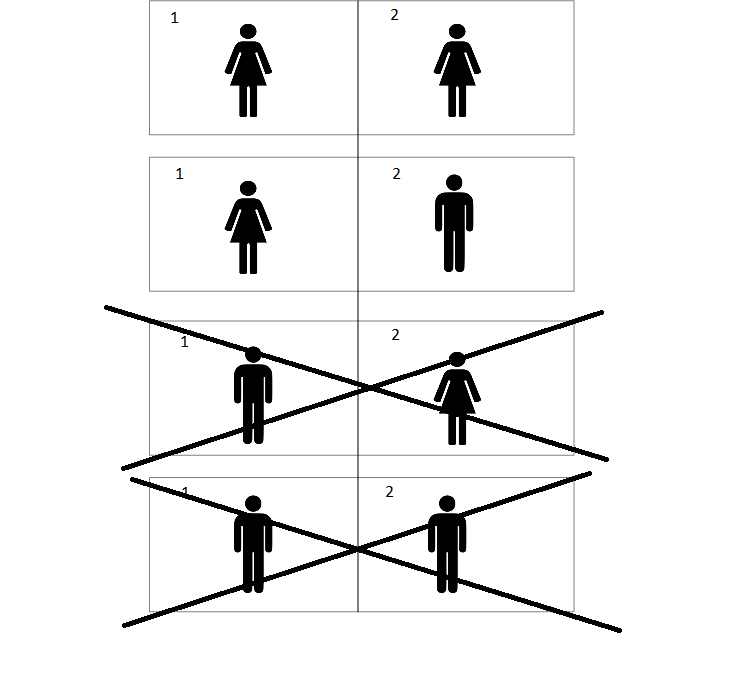
And it’s clearly going to be the same if you notice that you are a girl in room number 2.
But what if the number is initially hidden behind a curtain? Before you look behind the curtain, you estimate the probability of 2 girls as 1/3. But you also know that once you look behind the curtain and see your number, your probability will change to 1/2, whatever number you end up seeing! That’s absurd! Why do you need to look behind the curtain at all?
The problem here is that we are pretending our information gives us no way of labelling a specific child (“there is at least 1 girl”), when in fact it does “there is at least 1 girl and that girl is you”, and that’s where the inconsistencies are coming from. To resolve these inconsistencies, we are forced to move beyond the purely objective information we have about the world, and consider so-called “indexical” information as well. In this example it is true that “at least one girl exists”. But it is also true that the statement “I am a girl” is true for you, and you need to factor that into your calculations.
How can we go about calculating probabilities with statements like “I am a girl”? The most natural way is to adopt what Nick Bostrom calls the “Self-Sampling Assumption”, or SSA. It says that you should reason as if you are a random sample from the set of all observers. This means that when you wake up and find you are a girl, it is the same as in the classic Boy or Girl problem when we asked Alice to randomly select one of her children before answering. We can draw a similar diagram to the one we drew there, with 8 options:

If you accept SSA, The probability that there are 2 girls is then 1/2, whether you look behind the curtain at the number on your wall or not. And the reason that the probability of 2 girls has gone all the way up to 1/2 rather than 1/3 is that it is more likely you would find yourself to be a girl in a world where 2 girls exist than in a world where only 1 girl exists. We are now doing anthropic reasoning!
Ok, so what’s the big deal? SSA seems like a natural enough assumption to make, and it gives sensible looking answers in this problem. Haven’t we figured out anthropic reasoning? Can we start applying it to more interesting problems yet? Unfortunately things aren’t quite that simple.
Self-Indication Assumption
Imagine we vary the scenario again. Now, when God creates the universe at the dawn of time, instead of creating a girl or a boy based on the outcome of a coin toss, she creates a girl or a rock. SSA tells us that we should reason as if we are a random sample from the set of all observers, but a rock doesn’t seem like it should count as an observer. If rocks are not observers, then when you wake up and find yourself to be a girl in this scenario, your estimate of the probability of 2 girls will go back to 1/3 again! It is no longer more likely that you would find yourself a girl in a world with 2 girls compared to a world with 1 girl, because you have to find yourself a girl either way. You could never have been a rock.
This is not as problematic as it might first appear. It could even be that 1/3 is now the right answer. Unlike our previous attempt to justify the answer of 1/3, if we’ve accepted SSA then it won’t now change to 1/2 when we look behind the curtain at our room number. You can see this from the diagram below:
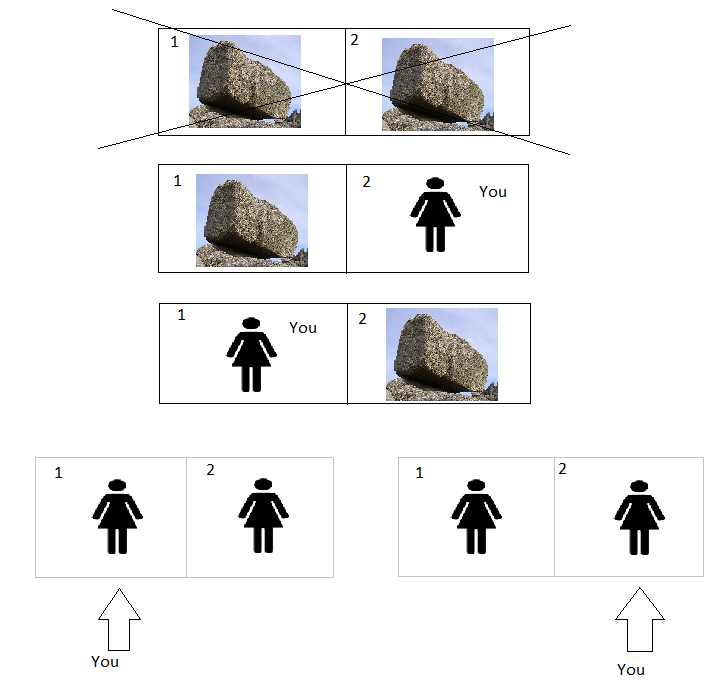
SSA now only comes into play in the bottom row (otherwise you have to find yourself as the girl rather than the rock, since the rock is not an observer). The two bottom row possibilities combine to give an outcome which is equally as likely as each of the three above, so they must each start off with probability 1/8, whereas the other 3 have probability 1/4 (the two possibilities with probability 1/8 have a grey outline to indicate they have half the weight of the others). When you wake up as a girl, you can rule out the top scenario, and the outcomes with a single girl are together twice as likely as the outcomes with two girls (giving a probability of 1/3 of two girls as we said). If you notice a number “1” on the wall after looking behind the curtain, you rule out the second and fifth scenarios, but the remaining single girl outcome is still twice as likely as the remaining two girl outcome, so the probability of two girls is still 1/3.
So unlike our initial attempt at anthropic reasoning where we refused to consider indexical information at all, the 1/3 answer given by SSA here is at least self-consistent. In fact, one school of thought in anthropic reasoning would defend it. But there is still something not entirely satisfying with this. The problem is that our probabilities now depend on our choice of what counts as an observer, our so called “reference class”. It might be clear that rocks are not observers, and so the answer was 1/3, but what about jellyfish? Or chimpanzees? Would the answer in those cases be 1/3, or 1/2?
Ok, so suppose we’re not happy with this ambiguity, and we want to come up with a way of doing anthropic reasoning that doesn’t depend on a choice of reference class of observers. We want an approach which keeps the sensible logic of SSA in the boy/girl case, but also gives the same 1/2 answer in the rock/girl case, or the chimpanzee/girl case. If we consider the diagram above, it’s clear that what we need to do is increase the likelihood of the two bottom-row scenarios. We need each of them to have the same probability as the scenarios above. There’s one particularly attractive way to do this, which is to add to SSA an additional assumption, called the Self-Indication Assumption, or SIA. It goes like this:
SIA: Given the fact that you exist, you should (other things equal) favour hypotheses according to which many observers exist over hypotheses on which few observers exist.
In other words, given that we exist, we should consider possibilities with more observers in them to be intrinsically more likely than possibilities with fewer observers.
How much more highly should we favour them? To get the answer to come out how we want it to, we need to weight each scenario by the number of observers who exist, so that the two bottom-row scenarios get a double weighting relative to the upper scenarios. If we do this, then taking SSA+SIA together means that our answer to the problem is 1/2, whether we take the boy/girl version, the chimpanzee/girl version, or the rock/girl version.
In general, if we re-weight our different hypotheses in this way, it will completely remove the problem of choosing a reference class of observers from anthropic reasoning. We’ve seen how that works in the chimpanzee/girl problem, but why does it work in general? Well suppose someone else, Bob, has a definition of “observer” which is larger than ours. Suppose in one of the possible hypotheses, Bob thinks there are twice as many observers as we do. Well SIA will then tell Bob to give a double weighting to that hypothesis, compared to us. But SSA will tell Bob to halve that weighting again. If there are twice as many observers, then it’s half as likely that we would find ourselves being the observer who sees what we are seeing. In the end, Bob’s probabilities will agree with ours, even though we’ve defined our reference classes of observers differently.
This is certainly a nice feature of SIA, but how do we justify SIA as an assumption? SSA seemed like a fairly natural assumption to make once we realised that we were forced to include indexical information in our probabilistic model. But SIA seems weirder. Why should your existence make hypotheses with more observers more likely? The lack of good philosophical justification for SIA is the biggest problem with this approach.
Where we’ve got to so far
We’ve now seen two different approaches to anthropic reasoning: SSA and SSA+SIA. Both give the answer of 1/2 in the Boy/Girl problem where you wake up and find yourself to be a girl. But they disagree when you change the Boy/Girl problem to a X/Girl problem, where X is something outside of your reference class of observers. In that case, SSA gives the answer of 1/3 while SSA+SIA continues to give the answer of 1/2. SSA+SIA was attractive because our probabilities no longer depend on an arbitrary choice of reference class, but aside from this we are still lacking any good reason to believe in SIA. Before returning to the Doomsday Argument, we’ll quickly review an alternative approach to anthropic reasoning called “full non-indexical conditioning”, which is effectively equivalent to SSA+SIA in practice, but arguably has a better foundation.
Full Non-Indexical Conditioning
To explain full non-indexical conditioning, we need to go full circle back to when we were trying to think about the Boy/Girl problem without using any indexical information at all (that means no information starting with the word “I”). We thought that the only objective information we had was “at least 1 girl exists”, and we saw that reasoning based on that information alone led to absurd conclusions (our probability changes to the same value when we look at our room number, regardless of what number we actually see). But maybe we were too hasty to give up on “non-indexical” conditioning after this setback. Can we think a bit harder to see if there’s a way of resolving this problem without invoking SSA at all?
Here’s one way to do it. When we said that the only information we had was “at least 1 girl exists”, we were ignoring the fact that any observer will necessarily have a whole set of other characteristics in addition to their gender. The information we actually have is not that “at least 1 girl exists”, it’s that “at least 1 girl with red hair, green eyes, etc and with a particular set of memories exists”. If we include all of this information, so the argument goes, we actually end up with a consistent framework for anthropic reasoning which is effectively equivalent to SSA+SIA. If we think of each characteristic as being drawn from some probability distribution, then a particular coincidence of characteristics occurring will be more likely in a world with more observers (SIA), and given a fixed number of observers, the set of characteristics serves as an essentially unique random label for each observer (SSA).
The full details are given in this paper by Radford Neal: https://arxiv.org/abs/math/0608592 We mention it here just as an example of how you might try to give a more solid foundation to the SSA+SIA approach.
Edit: A commenter below (rotatingpaguro) has pointed out that I might be underselling Full Non-Indexical Conditioning here, by portraying it as merely a different way of grounding SSA+SIA. I think that might be right, although I haven't understood the paper well enough to give a better summary. I'd encourage anyone who wants to learn more to check it out.
The Doomsday Argument
Now that we’re armed with our two approaches to anthropic reasoning (SSA and SSA+SIA), we can return to the Doomsday Argument. The Doomsday Argument said that humanity was likely to go extinct sooner rather than later, because it’s very unlikely we’d find ourselves with such a low birth rank in a world where humanity was going to continue existing for millions of years. Is this a valid argument or not?
SSA: Yes, the Doomsday Argument is valid.
Under SSA, our low birth rank is strong evidence that humanity will go extinct sooner. Formalizing this is complicated, because our prior beliefs about the likelihood of human extinction are also important, but for simplicity, suppose that there were only two possibilities for the future of humanity. Also suppose that, leaving aside anthropic arguments, both possibilities seem equally plausible to us:
Doom soon: humanity goes extinct in 10 years
Doom late: humanity goes extinct in 800,000,000 years, with a stable population of around 10 billion throughout that time. If humans have a life expectancy of around 80 years, this means there will be a further (800,000,000 X 10,000,000,000) / 80 = 10^17 humans in the future. This is around a million times more than the number of humans who ever exist in “Doom soon”.
If we initially assign a probability of 1/2 to each of these two hypotheses (our “prior”), we can then update these probabilities using SSA and the indexical information of our own birth rank: “I am the 60 billionth human”. If we want to visualise this in diagram format as we did above, we would need to draw a lot of images. Here’s just a few of them:
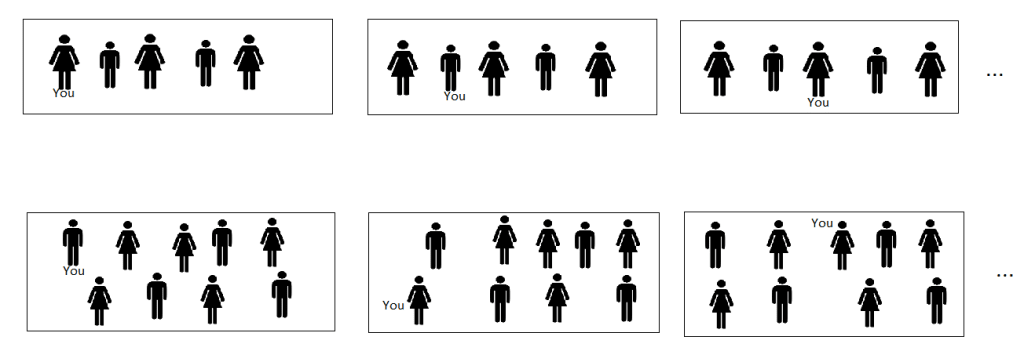
The ones on the top row all combine to give probability 1/2, and there are about 60 billion of them, so they each have probability 1/(2 X 60 billion). The ones on the bottom row all combine to give probability 1/2 as well, but there are 10^17 of them, so they each have probability 1/(2 X 10^17). If you knew your birth rank precisely, you’d eliminate all but 2 diagrams, one from the top row and one from the bottom. The one from the top is around 10^7 times as likely as the one on the bottom, so “Doom soon” is almost certainly true.
This is just the same as drawing a random ball from a bucket which contains either 10 balls or a million balls, finding a number 7, and becoming extremely confident that the bucket contains 10 balls. SSA says we should reason as if we are a random sample from the set of all observers, just like drawing a ball at random from a bucket.
Of course, in practice, “Doom soon” and “Doom late” are not the only two possibilities for the future of humanity, and most people probably wouldn’t say that they are equally plausible either. Putting probability estimates on the various possible futures of humanity is going to be extremely complicated. But the point of the Doomsday Argument is that whatever estimates you end up with, once you factor in anthropic reasoning with SSA, those probability estimates need to be updated hugely in favour of hypotheses on which humanity goes extinct sooner.
SSA+SIA: No, the Doomsday Argument is not valid.
If on the other hand we take the approach of SSA+SIA, the Doomsday Argument fails. Our birth rank then tells us nothing at all about the likelihood of human extinction. The reason for this is straightforward. SSA favours hypotheses in which humanity goes extinct sooner, but SIA favours hypotheses in which humanity goes extinct later (because our existence tells us that hypotheses with more observers in them are more likely) and the two effects cancel each other out. If we refer back to the diagram above, after weighting hypotheses by the number of observers they contain, all the drawings are equally likely, and so when we look at the two remaining after using our knowledge about our birth rank, both options are still as likely as each other.
The Presumptuous Philosopher Problem
You might now be thinking that the SSA+SIA approach to anthropic reasoning sounds pretty good. It doesn’t depend on an arbitrary choice of reference class of observers, and it avoids the counter-intuitive Doomsday Argument. But there’s a problem. SSA+SIA leads to a conclusion which is arguably even more ridiculous than the Doomsday Argument. It’s called the Presumptuous Philosopher problem, and it goes like this:
It is the year 2100 and physicists have narrowed down the search for a theory of everything to only two remaining plausible candidate theories, T1 and T2 (using considerations from super-duper symmetry). According to T1 the world is very, very big but finite and there are a total of a trillion trillion observers in the cosmos. According to T2, the world is very, very, very big but finite and there are a trillion trillion trillion observers. The super-duper symmetry considerations are indifferent between these two theories. Physicists are preparing a simple experiment that will falsify one of the theories. Enter the presumptuous philosopher: “Hey guys, it is completely unnecessary for you to do the experiment, because I can already show to you that T2 is about a trillion times more likely to be true than T1!
The idea here is that SIA tells us to consider possibilities with more observers in them as intrinsically more likely, but when we take that seriously, as above, it seems to lead to absurd overconfidence about the way the universe is organised.
As Nick Bostrom (who proposed this problem) goes on to say: “one suspects that the Nobel Prize committee would be rather reluctant to award the presumptuous philosopher The Big One for this contribution”.
Is there another way out?
From what we’ve seen so far, it seems like either we are forced to accept that the Doomsday Argument is correct, or we are forced to accept that the presumptuous philosopher is correct. Both of these options sound counter-intuitive. Is there no approach which lets us disagree with both?
One option is to accept SSA without SIA, but to use the ambiguity in the choice of observer reference class to avoid the more unpalatable consequences of SSA. For example, when considering the Doomsday Argument, if we choose our reference class to exclude observers who exist at different times to us, then the argument fails. We would no longer be a random sample from all the humans who will ever live, but would just be a random sample from all the humans who are alive simultaneously with us, in which case our birth rank is unsurprising. There are problems with saying that observers who live at different times can never be in the same reference class (see Anthropic Bias chapter 4), but maybe we need to adapt our reference class depending on the problem. It could be that reference classes spanning different times are appropriate when solving some problems, but not when evaluating the Doomsday Argument. The problem with this response is that we have no good prescription for choosing the reference class. Choosing the reference class for each problem so as to avoid conclusions we instinctively distrust seems like cheating.
An alternative option is to reject the notion of assigning probabilities to human extinction completely. We did not make this clear in the discussion above, but probabilities can be used in two very different ways:
(A) probabilities can describe frequencies of outcomes in random experiments e.g. the possible ways our children could have been gendered in our imaginary scenario where God flips a fair coin twice.
(B) probabilities can describe degrees of subjective belief in propositions e.g. our degree of belief in the claim that humanity will go extinct within the next 10 years.
(Taken verbatim from Information Theory, Inference, and Learning Algorithms, D.C.J. Mackay)
The use of probabilities in the sense of (A) is uncontroversial, but using them in the sense of (B) is much more so. If we reject their use in this context, then whatever our approach to anthropic reasoning (SSA or SSA+SIA), neither the Doomsday Argument nor the Presumptuous Philosopher conclusion is going to apply to us, because we can’t begin to apply anthropic reasoning along these lines unless we have some prior probabilities to begin with.
Rejecting subjective probabilities is one way of escaping the unattractive conclusions we’ve reached, but it comes with its own problems. To function in the real world and make decisions, we need to have some way of expressing our degrees of belief in different propositions. If we gamble, we do this in an explicit quantitative way. The shortest odds you would accept when betting on a specific outcome might be said to reflect the subjective probability you would assign to that outcome. But even outside of gambling, whenever we make decisions under uncertainty we are implicitly saying something about how likely we think various outcomes are. And there is a theorem known as Cox’s theorem which essentially says that if you quantify your degree of certainty in a way which has certain sensible sounding properties, the numbers you come up with will have to obey all of the rules of probability theory.
Why does any of this matter?
You might be thinking that all of this sounds interesting, but also very abstract and academic, with no real importance for the real world. I now want to convince you that that’s not true at all. I think that asking how long humanity is likely to have left is one of the most important questions there is, and the arguments we’ve seen have a real bearing on that important question.
Imagine someone offers you the chance to participate in some highly dangerous, but highly enjoyable, activity (think base jumping). If you have your whole life ahead of you, you are likely to reject this offer. But if you had a terminal illness and a few weeks to live, you’d have much less to lose, and so might be more willing to accept.
Similarly, humanity’s priorities should depend in a big way on what stage of our history we are at. If humanity is in its old age, with the end coming soon anyway, we shouldn’t be too concerned about taking actions which might risk our own extinction. We should focus more on ensuring that the people who are living right now are living good and happy lives. This is the equivalent of saying that a 90 year old shouldn’t worry too much about giving up smoking. They should focus instead on enjoying the time they have left.
On the other hand, if humanity is in its adolescence, with a potential long and prosperous future ahead of us, it becomes much more important that we don’t risk it all by doing something stupid, like starting a nuclear war, or initiating runaway climate change. In fact, according to a view known as longtermism, this becomes the single most important consideration there is. Reducing the risk of extinction so that future generations can be born might be even more important than improving the lives of people who exist right now.
28 comments
Comments sorted by top scores.
comment by Gunnar_Zarncke · 2023-04-23T12:36:56.238Z · LW(p) · GW(p)
The way out by rejecting probabilities of subjective existence is discussed in dadadaren's Perspective-based Reasoning sequence, e.g. The First-Person Perspective Is Not A Random Sample https://www.lesswrong.com/posts/heSbtt29bv5KRoyZa/the-first-person-perspective-is-not-a-random-sample [LW · GW]
Replies from: Gunnar_Zarncke, TobyC↑ comment by Gunnar_Zarncke · 2023-04-24T21:41:43.601Z · LW(p) · GW(p)
Can anybody tell me why this is downvoted?
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-04-26T21:24:43.418Z · LW(p) · GW(p)
I have not agreement-downvoted, but I have read that post and I can say what bugs me. It's mostly exemplified in the last paragraph:
A short example to show the difference: An incubator could create one person each in rooms numbered from 1 to 100. Or an incubator could create 100 people then randomly assign them to these rooms. "The probability that I am in room number 53" has no value in the former case. While it has the probability of 1% for the latter case.
This puts a lot of weight on what "randomly" means. It's discussed in these comments: (1) [LW(p) · GW(p)], (2) [LW(p) · GW(p)].
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2023-04-26T23:45:45.643Z · LW(p) · GW(p)
Thank you for your reply. It prompted me to read up more on the thread.
I agree that Perspective-based Reasoning is unusual and maybe unintuitive. Maybe it's also not the correct or best way to approach it. But I think it makes a quite good case. Linking to it seems relevant. I didn't even make a claim as to whether it is correct or not (though I think it's convincing).
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-04-28T08:39:37.198Z · LW(p) · GW(p)
I think it's fair to express disagreement with the linked post using the agreement vote when a comment is almost only a linkpost.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2023-04-28T08:58:15.019Z · LW(p) · GW(p)
With the agreement vote, obviously yes, but that didn't seem to be what primarily happened.
comment by Dagon · 2023-04-24T16:44:05.465Z · LW(p) · GW(p)
All anthropic reasoning suffers from the reference-class problem, which IMO is much more important than SSA vs SIA. Why consider only "human or rock", when you could consider "human, rock, housecat, or galaxy"? We have no information about what things there are, nor at what granularity they're chosen to observe stuff, nor even whether they HAVE experiences that "count" in our estimates. Relatedly, the source of priors is not solved, so one should be very highly skeptical of anthropic reasoning as motivation for any actual decision.
Replies from: TobyC↑ comment by TobyC · 2023-04-24T17:10:32.533Z · LW(p) · GW(p)
I agree that skepticism is appropriate, but I don't think just ignoring anthropic reasoning completely is an answer. If we want to make decisions on an issue where anthropics is relevant, then we have to have a way of coming up with probabilistic estimates about these questions somehow. Whatever framework you use to do that, you will be taking some stance on anthropic reasoning. Once you're dealing with an anthropic question, there is no such thing as a non-anthropic framework that you can fall back on instead (I tried to make that clear in the boy-girl example discussed in the post).
The answer could just be extreme pessimism: maybe there just is no good way of making decisions about these questions. But that seems like it goes too far. If you needed to estimate the probability that your DNA contained a certain genetic mutation that affected about 30% of the population, then I think 30% really would be a good estimate to go for (absent any other information). I think it's something all of us would be perfectly happy doing. But you're technically invoking the self-sampling assumption there. Strictly speaking, that's an anthropic question. It concerns indexical information ("*I* have this mutation"). If you like, you're making the assumption that someone without that mutation would still be in your observer reference class.
Once you've allowed a conclusion like that, then you have to let someone use Bayes rule on it. i.e. if they learn that they do have a particular mutation, then hypotheses that would make that mutation more prevalent should be considered more likely. Now you're doing anthropics proper. There is nothing conceptually which distinguishes this from the chain of reasoning used in the Doomsday Argument.
Replies from: Dagon↑ comment by Dagon · 2023-04-24T17:22:04.187Z · LW(p) · GW(p)
If we want to make decisions on an issue where anthropics is relevant
This is probably our crux. I don't think there are any issues where anthropics are relevant, because I don't think there is any evidence about the underlying distribution which would enable updating based on an anthropic observation.
comment by jbash · 2023-04-23T14:36:12.966Z · LW(p) · GW(p)
That was a nice clear explanation. Thank you.
... but you still haven't sold me on it mattering.
I don't care whether future generations get born or not. I only care whether people who actually are born do OK. If anything, I find it creepy when Bostrom or whoever talks about a Universe absolutely crawling with "future generations", and how much critical it supposedly is to create as many as possible. It always sounds like a hive or a bacterial colony or something.
It's all the less interesting because a lot of people who share that vision seem to have really restricted ideas of who or what should count as a "future generation". Why are humans the important class, either as a reference class or as a class of beings with value? And who's in the "human club" anyway?
Seems to me that the biggest problem with an apocalypse isn't that a bunch of people never get born; it's that a bunch of living people get apocalypsticized. Humans are one thing, but why should I care about "humanity"?
Replies from: TobyC, None↑ comment by TobyC · 2023-04-24T17:18:16.536Z · LW(p) · GW(p)
Thanks for the comment! That's definitely an important philosophical problem that I very much glossed over in the concluding section.
It's sort of orthogonal to the main point of the post, but I will briefly say this: 10 years ago I would have agreed with your point of view completely. I believed in the slogan you sometimes hear people say: "we're in favour of making people happy, and neutral about making happy people." But now I don't agree with this. The main thing that changed my mind was reading Reasons+Persons, and in particular the "mere-addition paradox". That's convinced me that if you try to be neutral on making new happy people, then you end up with non-transitive preferences, and that seems worse to me than just accepting that maybe I do care about making happy people after all.
Maybe you're already well aware of these arguments and haven't been convinced, which is fair enough (would be interested to hear more about why), but thought I would share in case you're not.
Replies from: jbash↑ comment by jbash · 2023-04-24T19:21:59.299Z · LW(p) · GW(p)
I have probably heard those arguments, but the particular formulation you mention appear to be embedded in a book of ethical philosophy, so I can't check, because I haven't got a lot of time or money for reading whole ethical philosophy books. I think that's a mostly doomed approach that nobody should spend too much time on.
I looked at the Wikipedia summary, for whatever that's worth, and here are my standard responses to what's in there:
-
I reject the idea that I only get to assign value to people and their quality of life, and don't get to care about other aspects of the universe in which they're embedded and of their effects on it. I am, if you push the scenario hard enough, literally willing to value maintaining a certain amount of VOID, sort of a "void preserve", if you will, over adding more people. And it gets even hairier if you start asking difficult questions about what counts as a "person" and why. And if you broaden your circle of concern enough, it starts to get hard to explain why you give equal weight to everything inside it.
-
Even if you do restrict yourself only to people, which again I don't, step 1, from A to A+, doesn't exactly assume that you can always add a new group of people without in any way affecting the old ones, but seems to tend to encourage thinking that way, which is not necessarily a win.
-
Step 2, where "total and average happiness increase" from A+ to B-, is the clearest example of how the whole argument requires aggregating happiness... and it's not a valid step. You can't legitimately talk about, let alone compute, "total happiness", "average happiness", "maximum happiness", or indeed ANYTHING that requires you put two or more people's happiness on the same scale. You may not even be able to do it for one person. At MOST you can impose a very weak partial ordering on states of the universe (I think that's the sort of thing Pareto talked about, but again I don't study this stuff...). And such a partial ordering doesn't help at all when you're trying to look at populations.
-
If you could aggregate or compare happiness, the way you did it wouldn't necessarily be independent of things like how diverse various people's happiness was; happiness doesn't have to be a fungible commodity. As I said before, I'd probably rather create two significantly different happy people than a million identical "equally happy" people.
So I don't accept that argument requires me to accept the repugnant conclusion on pain of having intransitive preferences.
That said, of course I do have some non-transitive preferences, or at least I'm pretty sure I do. I'm human, not some kind of VNM-thing. My preferences are going to depend on when you happen to ask me a question, how you ask it, and what particular consequences seem most salient. Sure, I often prefer to be consistent, and if I explicitly decided on X yesterday I'm not likely to choose Y tomorrow. Especially not if feel like maybe I've led somebody to depend on my previous choice. But consistency isn't always going to control absolutely.
Even if it were possible, getting rid of all non-transitive preferences, or even all revealed non-transitive preferences, would demand deeply rewriting my mind and personality, and I do not at this time wish to do that, or at least not in that way. It's especially unappealing because every set of presumably transitive preferences that people suggest I adopt seems to leave me preferring one or another kind of intuitively crazy outcome, and I believe that's probably going to be true of any consistent system.
My intuitions conflict, because they were adopted ad-hoc through biological evolution, cultural evolution, and personal experience. At no point in any of that were they ever designed not to conflict. So maybe I just need to kind of find a way to improve the "average happiness" of my various intuitions. Although if I had to pursue that obviously bogus math analogy any further, I'd say something like the geometric mean would be closer.
I suspect you also can find some intransitive preferences of your own if you go looking, and would find more if you had perfect view of all your preferences and their consequences. And I personally think you're best off to roll with that. Maybe intransitive preferences open you to being Dutch-booked, but trying to have absolutely transitive preferences is likely to make it even easier to get you go just do something intuitively catastrophic, while telling yourself you have to want it.
Replies from: TobyC↑ comment by TobyC · 2023-04-26T20:24:27.903Z · LW(p) · GW(p)
You raise lots of good objections there. I think most of them are addressed quite well in the book though. You don't need any money, because it seems to be online for free: https://www.stafforini.com/docs/Parfit%20-%20Reasons%20and%20persons.pdf And if you're short of time it's probably only the last chapter you need to read. I really disagree with the suggestion that there's nothing to learn from ethical philosophy books.
For point 1: Yes you can value other things, but even if people's quality of life is only a part of what you value, the mere-addition paradox raises problems for that part of what you value.
For point 2:That's not really an objection to the argument.
For point 3: I don't think the argument depends on the ability to precisely aggregate happiness. The graphs are helpful ways of conveying the idea with pictures, but the ability to quantify a population's happiness and plot it on a graph is not essential (and obviously impossible in practice, whatever your stance on ethics). For the thought experiment, it's enough to imagine a large population at roughly the same quality of life, then adding new people at a lower quality of life, then increasing their quality of life by a lot and only slightly lowering the quality of life of the original people, then repeating, etc. The reference to what you are doing to the 'total' and 'average' as this happens is supposed to be particularly addressed at those people who claim to value the 'total', or 'average', happiness I think. For the key idea, you can keep things more vague, and the argument still carries force.
For point 4: You can try to value things about the distribution of happiness, as a way out. I remember that's discussed in the book as well, as are a number of other different approaches you could try to take to population ethics, though I don't remember the details. Ultimately, I'm not sure what step in the chain of argument that would help you to reject.
On the non-transitive preferences being ok: that's a fair take, and something like this is ultimately what Parfit himself tried to do I think. He didn't like the repugnant conclusion, hence why he gave it that name. He didn't want to just say non-transitive preferences were fine, but he did try to say that certain populations were incomparable, so as to break the chain of the argument. There's a paper about it here which I haven't looked at too much but maybe you'd agree with: https://www.stafforini.com/docs/Parfit%20-%20Can%20we%20avoid%20the%20repugnant%20conclusion.pdf
Replies from: jbash↑ comment by jbash · 2023-04-27T13:17:00.495Z · LW(p) · GW(p)
Quickly, 'cuz I've been spending too much time here lately...
One. If my other values actively conflict with having more than a certain given number of people, then they may overwhelm the considerations were talking about here and make them irrelevant.
Three. It's not that you can't do it precisely. It's that you're in a state of sin if you try to aggregate or compare them at all, even in the most loose and qualitative way. I'll admit that I sometimes commit that sin, but that's because I don't buy into the whole idea of rigorous ethical philsophy to begin with. And only in extremis; I don't think I'd be willing to commit it enough for that argument to really work for me.
Four. I'm not sure what you mean by "distribution of happiness". That makes it sound like there's a bottle of happiness and we're trying to decide who gets to drink how much of it, or how to brew more, or how we can dilute it, or whatever. What I'm getting at is that your happiness and my happiness aren't the same stuff at all; it's more like there's a big heap of random "happinesses", none of them necessarily related to or substitutable for the others at all. Everybody gets one, but it's really hard to say who's getting the better deal. And, all else being equal, I'd rather have them be different from each other than have more identical ones.
↑ comment by [deleted] · 2023-04-23T17:28:02.219Z · LW(p) · GW(p)
If you have the chance to create lives that are worth-living at low-cost while you know that you are not going to increase suffering in any unbearable amount, why wouldn't you? Those people would also say that they would prefer to have lived than to not have lived, just like you presumably.
It's like a modal trolley problem: what if you can choose the future of the universe between say, 0 lives or a trillion lives worthy-living? You are going to cause one future or another with your actions, there's no point in saying that one is the 'default' that you'll choose if both are possible depending on your actions (unless you consider to not do anything in the trolley problem as the default option, and the one you would choose).
If you consider that no amount of pleasure is better than any other amount (if the alternative is to not feel anything), then 0 lives is fine because pleasure has no inherent positive value compare to not living (if pleasure doesn't add up, 0 is just as much as a billion), and there's no suffering (negative value), so extinction is actually better than no extinction (at least if the extinction is fast enough). If you consider that pleasure has inherent positive value (more pleasure implies more positive value, same thing), why stopping at a fixed number of pleasure when you can create more pleasure by adding more worth-living lives? It's more arbitrary.
If you consider that something has positive value, that typically implies that an universe with more of that thing is better. If you consider that preserving species has positive value then, ceteris paribus, an universe with more species preserved is a better universe. It's the same thing.
Replies from: jbash↑ comment by jbash · 2023-04-24T13:23:31.245Z · LW(p) · GW(p)
If you have the chance to create lives that are worth-living at low-cost while you know that you are not going to increase suffering in any unbearable amount, why wouldn't you?
Well, I suppose I would, especially if it meant going from no lives lived at all to some reasonable number of lives lived. "I don't care" is unduly glib. I don't care enough to do it if it had a major cost to me, definitely not given the number of lives already around.
I guess I'd be more likely to care somewhat more if those lives were diverse. Creating a million exactly identical lives seems less cool than creating just two significantly different ones. And the difference between a billion and a trillion is pretty unmoving to me, probably because I doubt the diversity of experiences among the trillion.
So long as I take reasonable care not to actively actualize a lot of people who are horribly unhappy on net, manipulating the number of future people doesn't seem like some kind of moral imperative to me, more like an aesthetic preference to sculpt the future.
I'm definitely not responsible for people I don't create, no matter what. I am responsible for any people I do create, but that responsibility is more in the nature of "not obviously screwing them over and throwing them into predictable hellscapes" than being absolutely sure they'll all have fantastic lives.
I would actively resist packing the whole Universe with humans at the maximum just-barely-better-than-not-living density, because it's just plain outright ugly. And I can't even imagine how I could figure out an "optimal" density from the point of view of the experiences of the people involved, even if I were invested in nonexistent people.
Those people would also say that they would prefer to have lived than to not have lived, just like you presumably.
I don't feel like I can even formulate a preference between those choices. I don't just mean that one is as good as the other. I mean that the whole question seems pointless and kind of doesn't compute. I recognize that it does make some kind of sense in some way, but how am I supposed to form a preference about the past, especially when my preferences, or lack thereof, would be modified by the hypothetical-but-strictly-impossible enactment of that preference? What am I supposed to do with that kind of preference if I have it?
Anyway, if a given person doesn't exist, in the strongest possible sense of nonexistence, where they don't appear anywhere in the timeline, then that person doesn't in fact have any preferences at all, regardless of what they "would" say in some hypothetical sense. You have to exist to prefer something. The nonexistent preferences of nonexistent people are, well... not exactly compelling?
I mean, if you want to go down that road, no matter what I do, I can only instantiate a finite number of people. If I don't discount in some very harsh way for lack of diversity, that leaves an infinite number of people nonexistent. If I continue on the path of taking nonexistent people's preferences into account; and I discover that even a "tiny" majority of those infinite nonexistent people "would" feel envy and spite for the people who do exist, and would want them not to exist; then should I take that infinite amount of preference into account, and make sure not to create anybody at all? Or should I maybe even just not create anybody at all out of simple fairness?
I think I have more than enough trouble taking even minimal care of even all the people who definitely do exist.
If you consider that pleasure has inherent positive value (more pleasure implies more positive value, same thing), why stopping at a fixed number of pleasure when you can create more pleasure by adding more worth-living lives? It's more arbitrary.
At a certain point the whole thing stops being interesting. And at a certain point after that, it just seems like a weird obsession. Especially if you're giving up on other things. If you've populated all the galaxies but one, that last empty galaxy seems more valuable to me than adding however many people you can fit into it.
Also, what's so great abotut humans specifically? If I wanted to maximize pleasure, shouldn't I try to create a bunch of utility monsters that only feel pleasure, instead of wasting resources on humans whose pleasure is imperfect? If you want, it can be utility monsters with two capacities: to feel pleasure, and to in whatever sense you like prefer their own existence to their nonexistence. And if I do have to create humans, should I try to make them as close to those utility monsters as possible while still meeting the minimum definition of "human"?
If you consider that something has positive value, that typically implies that an universe with more of that thing is better.
I like cake. I don't necessarily want to stuff the whole universe with cake (or paperclips). I can't necessarily say exactly how much cake I want to have around, but it's not "as much as possible". Even if I can identify an optimal amount of anything to have, the optimum does not have to be the maximum.
... and, pattern matching on previous conversations and guessing where this one might go, I think that formalized ethical systems, where you try to derive what you "should" do using logical inference from some fixed set of principles, are pointless and often dangerous. That includes all the of "measure and maximize pleasure/utility" variants, especially if they require you to aggregate people's utilities into a common metric.
There's no a priori reason you should expect to be able to pull anything logically consistent out of a bunch of ad-hoc, evolved ethical intuitions, and experience suggests that you can't do that. Everybody who tries seems to come up with something that has implications those same intuitions say are grossly monstrous. And in fact when somebody gets power and tries to really enact some rigid formalized system, the actual consequences tend to be monstrous.
"Humanclipping" the universe has that kind of feel for me.
Replies from: None↑ comment by [deleted] · 2023-04-24T20:15:59.184Z · LW(p) · GW(p)
At a certain point the whole thing stops being interesting. And at a certain point after that, it just seems like a weird obsession. Especially if you're giving up on other things. If you've populated all the galaxies but one, that last empty galaxy seems more valuable to me than adding however many people you can fit into it.
I mean, pleasure[1] is a terminal value for most of us because we like it (and suffering because we dislike it), not 'lifeless' matter. I prefer to have animals existing than to have zero animals, if at least we can make sure that they typically enjoy themselves or it will lead to a state-of-affairs in which most enjoy themselves most of the time. This is the same for humans in specific.
Also, what's so great about humans specifically?
I didn't use the word 'humans' for a reason.
Everybody who tries seems to come up with something that has implications those same intuitions say are grossly monstrous. And in fact when somebody gets power and tries to really enact some rigid formalized system, the actual consequences tend to be monstrous.
The reason we can say that "experience suggests that you can't do that" is because we have some standard to judge it. We need a specific reason to say that is 'monstrous', just like you'll give reasons for why any action is monstrous. In principle, no one needs to be wronged[2]. We can assume a deontological commitment to not kill any life or damage anyone if that's what bothers you. Sure, you can say that we are arbitrarily weakening our consequentialist commitment, but I haven't said at any point that it had to be 'at all costs' regardless (I know that I was commenting within the context of the article, but I'm speaking personally and I haven't even read most of it).
[1] It doesn't need to be literal ('naive') 'pleasure' with nothing else the thing that we optimise for.
[2]This is a hypothetical for a post-scarcity society, when you definitely have resources to spare and no one needs to be compromised to get a life into the world.
comment by antanaclasis · 2023-04-25T06:02:23.233Z · LW(p) · GW(p)
On the question of how to modify your prior over possible universe+index combinations based on observer counts, the way that I like to think of the SSA vs SIA methods is that with SSA you are first apportioning probability mass to each possible universe, then dividing that up among possible observers within each universe, while with SIA you are directly apportioning among possible observers, irrespective of which possible universes they are in.
The numbers come out the same as considering it in the way you write in the post, but this way feels more intuitive to me (as a natural way of doing things, rather than “and then we add an arbitrary weighing to make the numbers come out right”) and maybe to others.
Replies from: TobyC↑ comment by TobyC · 2023-04-27T11:59:01.808Z · LW(p) · GW(p)
That's a nice way of looking at it. It's still not very clear to me why the SIA approach of apportioning among possible observers is something you should want to do. But it definitely feels useful to know that that's one way of interpreting what SIA is saying.
Replies from: antanaclasis↑ comment by antanaclasis · 2023-04-28T21:45:30.594Z · LW(p) · GW(p)
From the SIA viewpoint the anthropic update process is essentially just a prior and an update. You start with a prior on each hypothesis (possible universe) and then update by weighting each by how many observers in your epistemic situation each universe has.
This perspective sees the equalization of “anthropic probability mass” between possible universes prior to apportionment as an unnecessary distortion of the process: after all, “why would you give a hypothesis an artificial boost in likelihood just because it posits fewer observers than other hypotheses”.
Of course, this is just the flip side of what SSA sees as an unnecessary distortion in the other direction. “Why would you give a hypothesis an artificial boost due to positing more observers” it says. And here we get back to deep-seated differences in what people consider the intuitive way of doing things that underlie the whole disagreement over different anthropic methods.
comment by Ben (ben-lang) · 2023-06-22T14:18:49.448Z · LW(p) · GW(p)
Nice post, very clear.
Maybe this overlaps with some of the other points, but for me it seems a sensible way of navigating this situation is to reject the entire notion that their existed a set of obverses, and them "me-ness" was injected into one of them at random. Most of the issues seem to spring from this. If my subjective experience is "bolted on" to a random observer then of course what counts as an observer matters a lot, and it makes sense to be grateful that you are not an ant.
But I can imagine worlds full of agents and observers, where non of them are me. (For example, Middle Earth is full of observers, but I don't think any of them are me). I can also imagine worlds crammed with philosophical zombies that aren't carrying the me-ness from me or from anyone else.
I suppose if you take this position to its logical conclusion you end up with other problems. "If I were an ant, I wouldn't be me." sounds coherent. "I just rolled a 5 on that die, if it had been a 6 I wouldn't be me (I would be a slightly different person, with a 6 on their retina)" sounds like gibberish and would result in failing to update to realise the die was weighted.
comment by dadadarren · 2023-06-22T13:25:23.257Z · LW(p) · GW(p)
Late to the party as usual. But I appreciate considering anthropic reasoning with the boy or girl paradox in mind. In fact, I have used it in the past [LW · GW], mostly as an argument against Full Non-indexical Conditioning. The boy or Girl paradox highlights the importance of the sampling process: a factually correct statement alone does not justify a particular way of updating probability, at least in some cases, the process of how that statement is obtained is also essential. And to interpret the perspective-determined "I" as the outcome of what kind of sampling process is the crux of anthropic paradoxes.
I see that Gunnar_Zarncke has linked my position on this problem, much appreciated.
comment by rotatingpaguro · 2023-04-25T12:55:53.929Z · LW(p) · GW(p)
I think that in the the section on the Presumptuous Philosopher Problem, you should mention that Full Non-Indexical Conditioning also argues to solve that, according to the paper you link.
Replies from: TobyC↑ comment by TobyC · 2023-04-26T12:22:23.086Z · LW(p) · GW(p)
Is that definitely right? I need to have an in-depth read of it, which I won't have time for for a few days, but from a skim it sounds like they admit that FNC also leads to the same conclusions as SIA for the presumptuous philosopher, but then they also argue that isn't as problematic as it seems?
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-04-26T21:17:29.175Z · LW(p) · GW(p)
I've skimmed the paper and read excerpts, but anyway: I'd describe what Neal does as deconstructing the paradox. So yes, in some sense he's arguing it's not as problematic. That's why I suggested to say that FNC argues to solve the problem, instead of outright saying FNC solves the problem. Saying "We mention it here just as an example of how you might try to give a more solid foundation to the SSA+SIA approach" makes it look like FNC is just that, without further developments, and I was surprised when I gave a look to the paper, which is something I could well not have done if I had even less time.
Replies from: TobyCcomment by RussellThor · 2023-04-25T11:02:12.616Z · LW(p) · GW(p)
I am not convinced that the Presumptuous Philosopher is a problem for SIA for the example given. Firstly I notice that the options are both finite. For a start you could just reject this and say any TOE would have infinite observers (Tegmark L4 etc) and the maths isn't set up for infinities. Does the original theory/doom hypothesis even work for uncountable infinite number of observers?
Secondly you could say that humanity (or all conscious beings) in both cases is a single reference class, not trillions. For example if all observers become one hive mind in both cases then would that change the odds? It becomes 1:1 then.
Taking that further can we apply the principle to possible universes? There would be more universes with many tunable parameters, (most of which did very little) than fewer. So for a given “elegant” universe with observers, there would be some infinity more very similar universes with more rules/forces that are very small and don't affect observers but are measurable and make that universe appear “messy”. Taking that reasoning further we would expect to find ourselves in a universe that appears like there is only a sequence of approximations to a universal theory for that universe. The actual laws would still be fixed, but maximally “messy” and we would keep finding exceptions and new forces with ever finer measurements.
Additionally even if we accept SSA and reject SIA all the doomsday argument says is that in ~100K years our current reference class won't be there. Isn't that practically a given in a post Singularity world that human descendants consciousness will be different even in the slowest takeoff most CEV satisfying conditions?
So its hard to see who would be affected by this. You would have to believe that the multiverse and associated infinities doesn't invalidate the argument, accept SSA, reject SIA, and believe that a successful Singularity would mostly leave humanities descendants in the same reference class?