EfficientZero: human ALE sample-efficiency w/MuZero+self-supervised
post by gwern · 2021-11-02T02:32:41.856Z · LW · GW · 52 commentsThis is a link post for https://arxiv.org/abs/2111.00210
Contents
52 comments
"Mastering Atari Games with Limited Data", Ye et al 2021:
Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal.
We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data.
EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at this https URL. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
This work is supported by the Ministry of Science and Technology of the People’s Republic of China, the 2030 Innovation Megaprojects “Program on New Generation Artificial Intelligence” (Grant No. 2021AAA0150000).
Some have said that poor sample-efficiency on ALE has been a reason to downplay DRL progress or implications. The primary boost in EfficientZero (table 3), pushing it past the human benchmark, is some simple self-supervised learning (SimSiam on predicted vs actual observations).
52 comments
Comments sorted by top scores.
comment by [deleted] · 2021-11-04T23:10:21.781Z · LW(p) · GW(p)
I guess I should update my paper on trends in sample efficiency soon / check whether recent developments are on trend (please message me if you are interested in doing this). This improvement does not seem to be extremely off-trend, but is definitely a bit more than I would have expected this year. Also, note that this results does NOT use the full suite of Atari games, but rather a subset of easier ones.
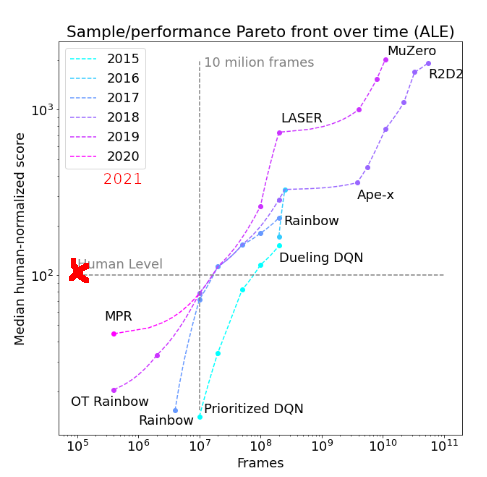
↑ comment by gwern · 2021-11-04T23:20:12.233Z · LW(p) · GW(p)
It would probably be more on-trend if you filtered out the ones not intended to be sample-efficient (it's a bit odd to plot both data-efficient Rainbow and regular Rainbow) which is going to make temporal trends weird (what if the data-efficient Rainbow had been published first and only later did someone just try to set SOTA by running as long as possible?) and covered more agents (you cite SimPLe & CURL, but don't plot them? and seem to omit DrQ & SPR entirely).
I also feel like there ought to be a better way to graph that to permit some eyeball extrapolation. For starts, maybe swap the x/y-axis? It's weird to try to interpret it as 'going up and to the left'.
Replies from: None, ankesh-anand↑ comment by [deleted] · 2021-11-04T23:37:47.201Z · LW(p) · GW(p)
A lot of the omissions you mention are due to inconsistent benchmarks (like the switch from the full Atari suite to Atari 100k with fewer and easier games) and me trying to keep results comparable.
This particular plot only has each year's SOTA, as it would get too crowded with a higher temporal resolution (I used it for the comment, as it was the only one including smaller-sample results on Atari 100k and related benchmarks). I agree that it is not optimal for eyeballing trends.
I also agree that temporal trends can be problematic as people did not initially optimize for sample efficiency (I'm pretty sure I mention this in the paper); it might be useful to do a similar analysis for the recent Atari 100k results (but I felt that there was not enough temporal variation yet when I wrote the paper last year as sample efficiency seems to only have started receiving more interest starting in late 2019).
↑ comment by Ankesh Anand (ankesh-anand) · 2021-11-07T20:10:26.055Z · LW(p) · GW(p)
They do seem to cover SPR (an earlier version of SPR was called MPR). @flodorner If you do decide to update the plot, maybe you could update the label as well?
comment by Matthew Barnett (matthew-barnett) · 2021-11-02T18:32:48.255Z · LW(p) · GW(p)
This milestone resembles the "Atari fifty" task in the 2016 Expert Survey in AI,
Outperform human novices on 50% of Atari games after only 20 minutes of training play time and no game specific knowledge.
For context, the original Atari playing deep Q-network outperforms professional game testers on 47% of games, but used hundreds of hours of play to train.
Previously Katja Grace posted that the original Atari task had been achieved early [LW · GW]. Experts estimated the Atari fifty task would take 5 years with 50% chance (so, in 2021), though they thought there was a 25% chance it would take at least 20 years under a different question framing.
Replies from: gwern↑ comment by gwern · 2021-11-02T20:05:07.684Z · LW(p) · GW(p)
The survey doesn't seem to define what 'human novice' performance is. But EfficientZero's performance curve looks pretty linear in Figure 7 over the 220k frames, finishing at ~1.9x human gametester performance after 2h (6x the allotted time). So presumably at 20min, EfficientZero is ~0.3x 2h-gametester-performance (1.9x * 1/6)? That doesn't strike me as being an improbable level of performance for a novice, so it's possible that challenge has been met. If not, seems likely that we're pretty close to it.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-11-02T11:33:58.050Z · LW(p) · GW(p)
Some basic questions in case anyone knows and wants to help me out:
1. Is this a single neural net that can play all the Atari games well, or a different net for each game?
2. How much compute was spent on training?
3. How many parameters?
4. Would something like this work for e.g. controlling a robot using only a few hundred hours of training data? If not, why not?
5. What is the update / implication of this, in your opinion?
(I did skim the paper and use the search bar, but was unable to answer these questions myself, probably due to lack of expertise)
Replies from: Razied, None, vanessa-kosoy, None↑ comment by Razied · 2021-11-02T13:39:11.870Z · LW(p) · GW(p)
- Different networks for each game
- They train for 220k steps for each agent and mention that 100k steps takes 7 hours on 4 GPUs (no mention of which gpus, but maybe RTX3090 would be a good guess?)
- They don't mention it
- They are explicitely motivated by robotics control, so yes, they expect this to help in that direction. I think the main problem is that robotics requires more complicated reward-shaping to obtain desired behaviour. In Atari the reward is already computed for you and you just need to maximise it, when designing a robot to put dishes in a dishwasher the rewards need to be crafted by humans. Going from "Desired Behavior -> Rewards for RL" is harder than "Rewards for RL -> Desired Behavior"
- I am somewhat surprised by the simplicity of the 3 methods described in the paper, I update towards "dumb and easy improvements over current methods can lead to drastic changes in performance".
As far as I can see, their improvements are:
- Learn the environment dynamics by self-supervision instead of relying only on reward signals.
Meaning that they don't learn the dynamics end-to-end like in MuZero. For them the loss function for the enviroment dynamics is completely separate from the RL loss function.(I was wrong, they in fact add a similarity loss to the loss function of MuZero that provides extra supervision for learning the dynamics, but gradients from rewards still reach the dynamics and representation networks.) - Instead of having the dynamics model predict future rewards, have it predict a time-window averaged reward (what they call "value prefix"). This means that the model doesn't need to get the timing of the reward *exactly* right to get a good loss, and so lets the model have a conception of "a reward is coming sometime soon, but I don't quite know exactly when"
- As training progresses the old trajectories sampled with an earlier policy are no longer very useful to the current model, so as each training run gets older, they replace the training run in memory with a model-predicted continuation. I guess it's like replacing your memories of a 10-year old with imagined "what would I have done" sequences, and the older the memories, the more of them you replace with your imagined decisions.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-11-15T15:15:56.874Z · LW(p) · GW(p)
They train for 220k steps for each agent and mention that 100k steps takes 7 hours on 4 GPUs (no mention of which gpus, but maybe RTX3090 would be a good guess?)
Holy cow, am I reading that right? RTX3090 costs, like, $2000. So they were able to train this whole thing for about one day's worth of effort using equipment that cost less than $10K in total? That means there's loads of room to scale this up... It means that they could (say) train a version of this architecture with 1000x more parameters and 100x more training data for about $10M and 100 days. Right?
Replies from: Razied↑ comment by Razied · 2021-11-16T01:02:35.807Z · LW(p) · GW(p)
You're missing a factor for the number of agents trained (one for each atari game), so in fact this should correspond to about one month of training for the whole game library. More if you want to run each game with multiple random seeds to get good statistics, as you would if you're publishing a paper. But yeah, for a single task like protein folding or some other crucial RL task that only runs once, this could easily be scaled up a lot with GPT-3 scale money.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-11-16T11:03:33.360Z · LW(p) · GW(p)
Ah right, thanks!
How well do you think it would generalize? Like, say we made it 1000x bigger and trained it on 100x more training data, but instead of 1 game for 100x longer it was 100 games? Would it be able to do all the games? Would it be better or worse than models specialized to particular games, of similar size and architecture and training data length?
↑ comment by TLW · 2021-11-05T04:57:30.461Z · LW(p) · GW(p)
(Fair warning: I'm definitely in the "amateur" category here. Usual caveats apply - using incorrect terminology, etc, etc. Feel free to correct me.)
> they in fact add a similarity loss to the loss function of MuZero that provides extra supervision
How do they prevent noise traps? That is, picture a maze with featureless grey walls except for a wall that displays TV static. Black and white noise. Most of the rest of the maze looks very similar - but said wall is always very different. The agent ends up penalized for not sitting and watching the TV forever (or encouraged to sit and watch the TV forever. Same difference up to a constant...)
↑ comment by Razied · 2021-11-05T12:17:50.025Z · LW(p) · GW(p)
Ah, I understand your confusion, the similarity loss they add to the RL loss function has nothing to do with exploration. It's not meant to encourage the network to explore less "similar" states, and so is not affected by the noisy-TV problem.
The similarity loss refers to the fact that they are training a "representation network" that takes the raw pixels and produces a vector that they take as their state, , they also train a "dynamics network" that predicts from and , . These networks in muZero are trained directly from rewards, yet this is a very noisy and sparse signal for these networks. The authors reason that they need to provide some extra supervision to train these better. What they do is add a loss term that tells the networks that should be very close to . In effect they want the predicted next state to be very similar to the state that in fact occurs. This is a rather ...obvious... addition, of course your prediction network should produce predictions that actually occur. This provides additional gradient signal to train the representation and dynamics networks, and is what the similarity loss refers to.
Replies from: TLW↑ comment by TLW · 2021-11-11T04:36:02.543Z · LW(p) · GW(p)
Thank you for the explanation!
What they do is add a loss term that tells the networks that should be very close to .
I am confused. Training your "dynamics network" as a predictor is precisely training that should be very close to . (Or rather, as you mention, you're minimizing the difference between , and ...) How can you add a loss term that's already present? (Or, if you're not training your predictor by comparing predicted with actual and back-propagating error, how are you training it?)
Or are you saying that this is training the combined network, including back-propagation of (part of) the error into updating the weights of also? If so, that makes sense. Makes you wonder where else people feed the output of one NN into the input of another NN without back-propagation...
↑ comment by Razied · 2021-11-12T02:59:36.843Z · LW(p) · GW(p)
Or, if you're not training your predictor by comparing predicted with actual and back-propagating error, how are you training it?
MuZero is training the predictor by using a neural network in the "place in the algorithm where a predictor function would go", and then training the parameters of that network by backpropagating rewards through the network. So in MuZero the "predictor network" is not explicitely trained as you would think a predictor would be, it's only guided by rewards, the predictor network only knows that it should produce stuff that gives more reward, there's no sense of being a good predictor for its own sake. And the advance of this paper is to say "what if the place in our algorithm where a predictor function should go was actually trained like a predictor?". Check out equation 6 on page 15 of the paper.
↑ comment by [deleted] · 2021-11-04T06:05:07.630Z · LW(p) · GW(p)
Learn the environment dynamics by self-supervision instead of relying only on reward signals. Meaning that they don't learn the dynamics end-to-end like in MuZero. For them the loss function for the enviroment dynamics is completely separate from the RL loss function.
I wonder how they prevent the latent state representation of observations from collapsing into a zero-vector, thus becoming completely uninformative and trivially predictable. And if this was the reason MuZero did things its way.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-11-04T08:31:07.498Z · LW(p) · GW(p)
There is a term in the loss function reflecting the disparity between observed rewards and rewards predicted from the state sequence (first term of in equation (6)). If the state representation collapsed it would be impossible to predict rewards from it. The third term in the loss function would also punish you: it compares the value computed from the state to a linear combination of rewards and the value computed from the state at a different step (see equation (4) for definition of ).
Replies from: None↑ comment by [deleted] · 2021-11-04T10:53:35.052Z · LW(p) · GW(p)
Oh I see, did I misunderstand point 1. from Razied then or was it mistaken? I thought and were trained separately with
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-11-04T11:47:49.188Z · LW(p) · GW(p)
No, they are training all the networks together. The original MuZero didn't have , it learned the dynamics only via the reward-prediction terms.
↑ comment by [deleted] · 2021-11-03T01:49:44.242Z · LW(p) · GW(p)
5. What is the update / implication of this, in your opinion?
Personal opinion:
Progress in model-based RL is far more relevant to getting us closer to AGI than other fields like NLP or image recognition or neuroscience or ML hardware. I worry that once the research community shifts its focus towards RL, the AGI timeline will collapse - not necessarily because there are no more critical insights left to be discovered, but because it's fundamentally the right path to work on and whatever obstacles remain will buckle quickly once we throw enough warm bodies at them. I think - and this is highly controversial - that the focus on NLP and Vision Transformer has served as a distraction for a couple of years and actually delayed progress towards AGI.
If curiosity-driven exploration gets thrown into the mix and Starcraft/Dota gets solved (for real [LW · GW] this time) with comparable data efficiency as humans, that would be a shrieking fire alarm to me (but not to many other people I imagine, as "this has all been done before").
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2021-11-09T07:35:09.490Z · LW(p) · GW(p)
Isn't this paper already a shrieking fire alarm?
↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-11-02T13:59:31.216Z · LW(p) · GW(p)
(1) Same architecture and hyperparameters, trained separately on every game.
(4) It might work. In fact they also tested it on a benchmark that involves controlling a robot in a simulation, and showed it beats state-of-the-art on the same amount of training data (but there is no "human performance" to compare to).
(5) The poor sample complexity was one of the strongest arguments for why deep learning is not enough for AGI. So, this is a significant update in the direction of "we don't need that many more new ideas to reach AGI". Another implication is that model-based RL seems to be pulling way ahead of model-free RL.
↑ comment by [deleted] · 2021-11-02T13:16:22.877Z · LW(p) · GW(p)
- It is a different net for each game. That is why they compare with DQN, not Agent57.
- To train an Atari agent for 100k steps, it only needs 4 GPUs to train 7 hours.
- The entire architecture is described in the Appendix A.1 Models and Hyper-parameters.
- Yes.
- This algorithm is more sample-efficient than humans, so it learned a specific game faster than a human could. This is definitely a huge breakthrough.
↑ comment by [deleted] · 2021-11-04T23:45:56.142Z · LW(p) · GW(p)
Do you have a source for Agent57 using the same network weights for all games?
Replies from: gwern↑ comment by gwern · 2021-11-05T01:19:00.822Z · LW(p) · GW(p)
I don't think it does, and reskimming the paper I don't see any claim it does (using a single network seems to have been largely neglected since Popart). Prabhu might be thinking of how it uses a single fixed network architecture & set of hyperparameters across all games (which while showing generality, doesn't give any transfer learning or anything).
comment by [deleted] · 2021-11-02T14:06:07.001Z · LW(p) · GW(p)
Unless I misinterpreted the results, the "500 times less data" is kind of a clickbait because they're referencing DQN with that statement and not SOTA or even MuZero.
Unfortunately they didn't include any performance-over-timesteps graph. I imagine it looks something like e.g. DreamerV2 where the new algorithm just converges at a higher performance, but if you clipped the whole graph at the max. performance level of DQN and ask how long it took the new algorithm to get to that level, the answer will be tens or hundreds times quicker because on the curve for the new algorithm, you haven't left the steep part of the hockey stick yet.
I'd love to see how this algorithm combines with curiosity-driven exploration. They benchmarked on only 26 out of the 57 classic Atari games and didn't include the notoriously hard Montezuma's Revenge, which I assume EfficientZero can't tackle yet. Otherwise, since it is a visual RL algorithm, why not just throw something like Dota 2 at it - if it's truly a "500 times less data"-level revolutionary change, running the experiment should be cheap enough already.
Replies from: gwern↑ comment by gwern · 2021-11-02T14:16:38.307Z · LW(p) · GW(p)
Yes, that just gives you an idea of how far sample-efficiency has come since then. Both DQN and MuZero have sample-efficient configurations which do much better (at the expense of wallclock time / compute, however, which is usually what is optimized for). The real interest here is that it's hit human-level sample-efficiency - and that's with modest compute like a GPU-day and without having transfer learning or extremely good priors learned from a lifetime of playing other games and tasks or self-supervised learning on giant offline datasets of logged experiences, too, I'd note. Hence, concerning.
(Not for the first time, nor will it be the last, do I find myself wondering what the human brain does with those 5-10 additional orders of magnitude more compute that some people claim must be necessary for human-level intelligence.)
I would say the major catch here is that the sample-efficient work usually excludes the unsolved exploration games like Montezuma's Revenge, so this doesn't reach human-level in MR. However, I continue to say that exploration seems tractable with a MuZero model if you extract uncertainty/disagreement from the model-based rollouts and use that for the environment interactions, so I don't think MR & Pitfall should be incredibly hard to solve.
Replies from: Eliezer_Yudkowsky, FeepingCreature, None↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2021-11-03T20:38:25.299Z · LW(p) · GW(p)
Both DQN and MuZero have sample-efficient configurations which do much better
Say more? In particular, do you happen to know what the sample efficiency advantage for EfficientNet was, over the sample-efficient version of MuZero - eg, how many frames the more efficient MuZero would require to train to EfficientNet-equivalent performance? This seems to me like the appropriate figure of merit for how much EfficientNet improved over MuZero (and to potentially refute the current applicability of what I interpret as the OpenPhil view about how AGI development should look at some indefinite point later when there are no big wins left in AGI).
Replies from: gwern↑ comment by gwern · 2021-11-04T00:33:55.569Z · LW(p) · GW(p)
The sample-efficient DQN is covered on pg2, as the tuned Rainbow. More or less, you just train the DQN a lot more frequently, and a lot more, on its experience replay buffer, with no other modifications; this makes it like 10x more sample-efficient than the usual hundreds of millions of frames quoted for best results (but again, because of diminishing returns and the value of training on new fresh data and how lightweight ALE is to run, this costs you a lot more wallclock/total-compute, which is usually what ALE researchers try to economize and why DQN/Rainbow isn't as sample-efficient as possible by default). That gives you about 25% of human perf at 200k frames according to figure 1 in EfficientZero paper.
MuZero's sample-efficient mode is similar, and is covered in the MuZero paper as 'MuZero-Reanalyze'. In the original MuZero paper, Reanalyze kicks butt like MuZero and achieves mean scores way above the human benchmark [2100%], but they only benchmark the ALE at 200m frames so this is 'sample-efficient' only when compared to the 20 billion frames that the regular MuZero uses to achieve twice better results [5000%]. EfficientZero starts with MuZero-Reanalyze as their baseline and say that 'MuZero' in their paper always refers to MuZero-Reanalyze, so I assume that their figure 1's 'MuZero' is Reanalyze, in which case it reaches ~50% human at 200k frames, so it does twice as well as DQN, but it does a quarter as well as their EfficientZero variant which reaches almost 200% at 200k. I don't see a number for baseline MuZero at merely 200k frames anywhere. (Figure 2d doesn't seem to be it, since it's 'training steps' which are minibatches of many episodes, I think? And looks too high.)
So the 200k frame ranking would go something like: DQN [lol%] < MuZero? [meh?%] < Rainbow DQN [25%] < MuZero-Reanalyze [50%] < MuZero-Reanalyze-EfficientZero [190%].
how many frames the more efficient MuZero would require to train to EfficientZero-equivalent performance?
They don't run their MuZero-Reanalyze to equivalence (although this wouldn't be a bad thing to do in general for all these attempts at greater sample-efficiency). Borrowing my guess from the other comment about how it looks like they are all still in the linearish regime of the usual learning log curve, I would hazard a guess that MuZero-Reanalyze would need 190/50 = 3.8x = 760,000 frames to match EfficientZero at 200k.
Scaling curves along the line of Jones so you could see if the exponents differ or if it's just a constant offset (the former would mean EfficientZero is a lot better than it looks in the long run) would of course be research very up my alley, and the compute requirements for some scaling curve sweeps don't seem too onerous...
Replies from: gwern↑ comment by gwern · 2021-11-04T16:14:44.190Z · LW(p) · GW(p)
Speaking of sample-efficient MuZero, DM just posted "Procedural Generalization by Planning with Self-Supervised World Models", Anand et al 2021 on a different set of environments than ALE, which also uses self-supervision to boost MuZero-Reanalyze sample-efficiency dramatically (in addition to another one of my pet interests, demonstrating implicit meta-learning through the blessings of scale): https://arxiv.org/pdf/2111.01587.pdf#page=5
Eyeballing the graph at 200k env frames, the self-supervised variant is >200x more sample-efficient than PPO (which has no sample-efficient variant the way DQN does because it's on-policy and can't reuse data), and 5x the baseline MuZero (and a 'model-free' MuZero variant/ablation I'm unfamiliar with). So reasonably parallel.
Replies from: john-schulman↑ comment by John Schulman (john-schulman) · 2021-11-07T10:56:15.404Z · LW(p) · GW(p)
Performance is mostly limited here by the fact that there are 500 levels for each game (i.e., level overfitting is the problem) so it's not that meaningful to look at sample efficiency wrt environment interactions. The results would look a lot different on the full distribution of levels. I agree with your statement directionally though.
Replies from: ankesh-anand↑ comment by Ankesh Anand (ankesh-anand) · 2021-11-07T20:06:08.111Z · LW(p) · GW(p)
We do actually train/evaluate on the full distribution (See Figure 5 rightmost). MuZero+SSL versions (especially reconstruction) continue to be a lot more sample-efficient even in the full-distribution, and MuZero itself seems to be quite a bit more sample efficient than PPO/PPG.
Replies from: john-schulman, john-schulman↑ comment by John Schulman (john-schulman) · 2021-11-12T10:06:04.265Z · LW(p) · GW(p)
I'm still not sure how to reconcile your results with the fact that the participants in the procgen contest ended up winning with modifications of our PPO/PPG baselines, rather than Q-learning and other value-based algorithms, whereas your paper suggests that Q-learning performs much better. The contest used 8M timesteps + 200 levels. I assume that your "QL" baseline is pretty similar to widespread DQN implementations.
https://arxiv.org/pdf/2103.15332.pdf
Are there implementation level changes that dramatically improve performance of your QL implementation?
(Currently on vacation and I read your paper briefly while traveling, but I may very well have missed something.)
Replies from: ankesh-anand↑ comment by Ankesh Anand (ankesh-anand) · 2021-11-14T03:45:35.827Z · LW(p) · GW(p)
The Q-Learning baseline is a model-free control of MuZero. So it shares implementation details of MuZero (network architecture, replay ratio, training details etc.) while removing the model-based components of MuZero (details in sec A.2) . Some key differences you'd find vs a typical Q-learning implementation:
- Larger network architectures: 10 block ResNet compared to a few conv layers in typical implementations.
- Higher sample reuse: When using a reanalyse ratio of 0.95, both MuZero and Q-Learning use each replay buffer sample an average of 20 times. The target network is updated every 100 training steps.
- Batch size of 1024 and some smaller details like using categorical reward and value predictions similar to MuZero.
- We also have a small model-based component which predicts reward at next time step which lets us decompose the Q(s,a) into reward and value predictions just like MuZero.
I would guess larger networks + higher sample reuse have the biggest effect size compared to standard Q-learning implementations.
The ProcGen competition also might have used the easy difficulty mode compared to the hard difficulty mode used in our paper.
Replies from: john-schulman↑ comment by John Schulman (john-schulman) · 2021-11-14T18:02:42.491Z · LW(p) · GW(p)
Thanks, this is very insightful. BTW, I think your paper is excellent!
Replies from: ankesh-anand↑ comment by Ankesh Anand (ankesh-anand) · 2021-11-14T21:26:39.424Z · LW(p) · GW(p)
Thanks, glad you liked it, I really like the recent RL directions from OpenAI too! It would be interesting to see the use of model-based RL for the "RL as fine-tuning paradigm": making large pre-trained models more aligned/goal-directed efficiently by simply searching over a reward function learned from humans.
Replies from: john-schulman↑ comment by John Schulman (john-schulman) · 2021-11-19T08:59:22.720Z · LW(p) · GW(p)
Would you say Learning to Summarize is an example of this? https://arxiv.org/abs/2009.01325
It's model based RL because you're optimizing against the model of the human (ie the reward model). And there are some results at the end on test-time search.
Or do you have something else in mind?
↑ comment by John Schulman (john-schulman) · 2021-11-12T09:58:31.993Z · LW(p) · GW(p)
There's no PPO/PPG curve there -- I'd be curious to see that comparison. (though I agree that QL/MuZero will probably be more sample efficient.)
Replies from: ankesh-anand↑ comment by Ankesh Anand (ankesh-anand) · 2021-11-14T04:10:42.119Z · LW(p) · GW(p)
I was eyeballing Figure 2 in the PPG paper and comparing it to our results on the full distribution (Table A.3).
PPO: ~0.25
PPG: ~0.52
MuZero: 0.68
MuZero+Reconstruction: 0.93
↑ comment by FeepingCreature · 2021-11-03T11:36:40.456Z · LW(p) · GW(p)
What would stump a (naive) exploration-based AI? One may imagine a game as such: the player starts on the left side of a featureless room. If they go to the right side of the room, they win. In the middle of the room is a terminal. If one interacts with the terminal, one is kicked into an embedded copy of the original Doom.
An exploration-based agent would probably discern that Doom is way more interesting than the featureless room, whereas a human would probably put it aside at some point to "finish" exploring the starter room first. I think this demands a sort of mixed breadth-depth exploration?
Replies from: Razied, gwern, None↑ comment by Razied · 2021-11-03T13:08:53.622Z · LW(p) · GW(p)
The famous problem here is the "noisy TV problem". If your AI is driven to go towards regions of uncertainty then it will be completely captivated by a TV on the wall showing random images, no need for a copy of Doom, any random giberish that the AI can't predict will work.
Replies from: None, FeepingCreature↑ comment by [deleted] · 2021-11-04T03:27:32.122Z · LW(p) · GW(p)
OpenAI claims to have already solved the noisy TV problem via Random Network Distillation, although I'm still skeptical of it. I think it's a clever hack that only solves a specific subclass of this problem that is relatively superficial.
↑ comment by FeepingCreature · 2021-11-03T16:09:23.957Z · LW(p) · GW(p)
Well, one may develop an AI that handles noisy TV by learning that it can't predict the noisy TV. The idea was to give it a space that is filled with novelty reward, but doesn't lead to a performance payoff.
↑ comment by gwern · 2021-11-03T14:13:06.605Z · LW(p) · GW(p)
Even defining what is a 'featureless room' in full generality is difficult. After all, the literal pixel array will be different at most timesteps (and even if ALE games are discrete enough for that to not be true, there are plenty of environments with continuous state variables that never repeat exactly). That describes the opening room of Montezuma's Revenge: you have to go in a long loop around the room, timing a jump over a monster that will kill you, before you get near the key which will give you the first reward after hundreds of timesteps. Go-Explore can solve MR and doesn't suffer from the noisy TV problem because it does in fact do basically breadth+depth exploration (iterative widening), but it also relies on a human-written hack for deciding what states/nodes are novel or different from each other and potentially worth using as a starting point for exploration.
↑ comment by [deleted] · 2021-11-04T03:42:58.520Z · LW(p) · GW(p)
You could certainly engineer an adversarial learning environment to stump an exploration-based AI, but you could just as well engineer an adversarial learning environment to stump a human. Neither is "naive" because of it in any useful sense, unless you can show that that adversarial environment has some actual practical relevance.
Replies from: FeepingCreature↑ comment by FeepingCreature · 2021-11-05T12:17:59.465Z · LW(p) · GW(p)
That's true, but ... I feel in most cases, it's a good idea to run mixed strategies. I think that by naivety I mean the notion that any single strategy will handle all cases - even if there are strategies where this is true, it's wrong for almost all of them.
Humans can be stumped, but we're fairly good at dynamic strategy selection, which tends to protect us from being reliably exploited.
Replies from: None↑ comment by [deleted] · 2021-11-06T09:38:00.961Z · LW(p) · GW(p)
Humans can be stumped, but we're fairly good at dynamic strategy selection, which tends to protect us from being reliably exploited.
Have you ever played Far Cry 4? At the beginning of that game, there is a scene where you're being told by the main villain of the storyline to sit still while he goes downstairs to deal with some rebels. A normal human player would do the expected thing, which is to curiously explore what's going on downstairs, which then leads to the unfolding of the main story and thus actual gameplay. But if you actually stick to the villain's instruction and sit still for 12 minutes, it leads straight to the ending of the game.
This is an analogous situation to your scenario, except it's one where humans reliably fail. Now you could argue that a human player's goal is to actually play and enjoy the game, therefore it's perfectly reasonable to explore and forego a quick ending. But I bet even if you incentivized a novice player to finish the game in under 2 hours with a million dollars, he would not think of exploiting this Easter egg.
More importantly, he would have learned absolutely nothing from this experience about how to act rationally (except for maybe stop believing that anyone would genuinely offer a million dollars out of the blue). The point is, it's not just possible to rig the game against an agent for it to fail, it's trivially easy when you have complete control of the environment. But it's also irrelevant, because that's not how reality works in general. And I do mean reality, not some fictional story or adversarial setup where things happen because the author says they happen.
comment by Raemon · 2021-11-02T22:58:38.296Z · LW(p) · GW(p)
Can someone give a rough explanation of how this compares to the recent Deepmind atari-playing AI:
https://www.lesswrong.com/posts/mTGrrX8SZJ2tQDuqz/deepmind-generally-capable-agents-emerge-from-open-ended?commentId=bosARaWtGfR836shY#bosARaWtGfR836shY [LW(p) · GW(p)]
And, for that matter, how both of them compare to the older deepmind paper:
https://deepmind.com/research/publications/2019/playing-atari-deep-reinforcement-learning
Are they accomplishing qualitatively different things? The same thing but better?
Replies from: Raemon↑ comment by Raemon · 2021-11-03T00:23:56.469Z · LW(p) · GW(p)
Update: I originally posted this question over here [LW(p) · GW(p)], then realized this post existed and maybe I should just post the question here. But then it turned out people had already started answering my question-post, so, I am declaring that the canonical place to answer the question.
comment by Ruby · 2021-11-07T01:58:11.998Z · LW(p) · GW(p)
Curated. Although this isn't a LessWrong post, it seems like a notable result for AGI progress. Also see this highly-upvoted, accessible explanation [LW(p) · GW(p)] of why EfficientZero is a big deal. Lastly, I recommend the discussion in the comments here.
comment by Rudi C (rudi-c) · 2021-12-01T10:49:13.388Z · LW(p) · GW(p)
Expertise status: I am just starting with RL.
Will using a hardcoded model of the environment improve these models, or do the models need the representations they learn?
Using EfficientZero's architecture, how many hours does it take on a single TPUv2 for the agent to reach amateur human level? In general, is EfficientZero being sample efficient or compute efficient?
What is the currently most compute efficient algorithm for simple, two-player deterministic games with a lot of states (e.g., go)?
PS: The reason I am asking is that I learn stuff by coding much better than merely reading, and I have been trying to write the simplest non-search-based, self-supervised algorithm I can for games like chess.
One of the main challenges I have faced is that cloning the current state, doing an action on it, and then using the neural net (a simple 4-layered MLP) to infer the new state's value is quite slow (on the order of a second), so running MCTS seems to require a lot more compute. (Done using Colab Pro's TPUv2, but the game state is managed by OpenSpiel on the CPU.)