Survey on cortical uniformity - an expert amplification exercise
post by Jsevillamol, Pablo Villalobos (pvs) · 2021-02-23T22:13:24.157Z · LW · GW · 6 commentsContents
The project in brief Survey questions and amplification Q1: What sentence better represents your beliefs? Q2: What sentence better represents your beliefs? Q3: What sentence better represents your beliefs? Acknowledgements None 6 comments
In short: We designed a survey to gauge the opinion of expert neuroscientists about the degree of uniformity in the human cortex. The survey was sent to 135 experts, of which only 6 responded. Since we do not consider this a representative sample, we are instead asking the LessWrong community to predict what would have been the survey outcome if more people had responded.
The project in brief
We want to distinguish two hypotheses. The brain could be a machine with many components, learned through evolution and hardcoded via the genome. Or it could be a relatively simple process, that relies on an overarching principle to learn to perform many tasks. This is not a clean dichotomy; there are many possible degrees in between.
Regardless, it is clearly a very interesting question for the study of human cognition. The answer to this question also has consequences on what degree of generality is achievable with artificial intelligence, especially concerning biologically inspired AI. See My computational framework for the brain [LW · GW] by Steve Byrne for previous discussion of the topic.
There exists research addressing this question in neuroscience, see for example Canonical Microcircuits for Predictive Coding by Andre M. Bastos et al which argues in favor of uniformity and The atoms of neural computation by Gary Marcus et al which argues against. However, it is not clear from the outside of the field whether there is a majority position and what that would be.
In order to learn this, we designed a simple three question survey intended to probe the field (the questions are reproduced in the next section).
We sent the survey to 135 experts in neuroscience. The public we selected were invited speakers to two conferences by the Society for Neuroscience. The conferences were Neuroscience 2019 and Global Connectome 2021.
The response to the survey was underwhelming: only 6 experts responded. We tried reaching out to one of them who seemed especially keen on discussing the topic for an in-depth interview but we received no second response.
Given this we have decided to rethink our approach, and use this as a chance to experiment with forecasting and expert amplification. In the next section you will find the survey questions, and we will ask you to predict what you believe would have been the majority result for each question had we received more answers.
Also, if you are a neuroscientist involved in organizing a conference or are otherwise in a situation where you could send a copy of the survey to a representative group of experts, please do get in touch with us! This will be useful so we can resolve the community predictions.
Survey questions and amplification
Here is a reproduction of the survey, with Elicit style voting mechanisms so that you dear reader can leave your best guess. The question resolution depends on what the majority position among neuroscientists would be if this survey was ever run. Be mindful that your answers will be publicly shown, associated with your nametag.
EDIT: Read twice each question because the wording is somewhat confusing! Each question resolves positively if more experts would select option A than B. In the chart of expert answers, Option A corresponds to the blue sector, while option B corresponds to the red sector.
We ran the survey design by an expert neuroscientist and an independent researcher working on the topic. However we are not sure that the questions are good or informative. For example, one of the experts who answered the survey pointed out that the first two questions are not compatible with a “developmental plasticity” viewpoint. If you have any comments on how you would have phrased things differently please do let us know!
We also include the results of the six expert answers to the survey we received.
---------------------------------------------------------------------------------------------------
Q1: What sentence better represents your beliefs?
A (blue): “The entire cortical network could be modeled as the repetition of a few relatively simple neural structures, arranged in a similar pattern even across different cortical areas”
B (red) : “Each section of the neocortex consists of a diverse set of computationally distinct building blocks, different for each cortical area”
This question is intended to capture the notion of uniformity manifesting as structural similarity between cortical areas.
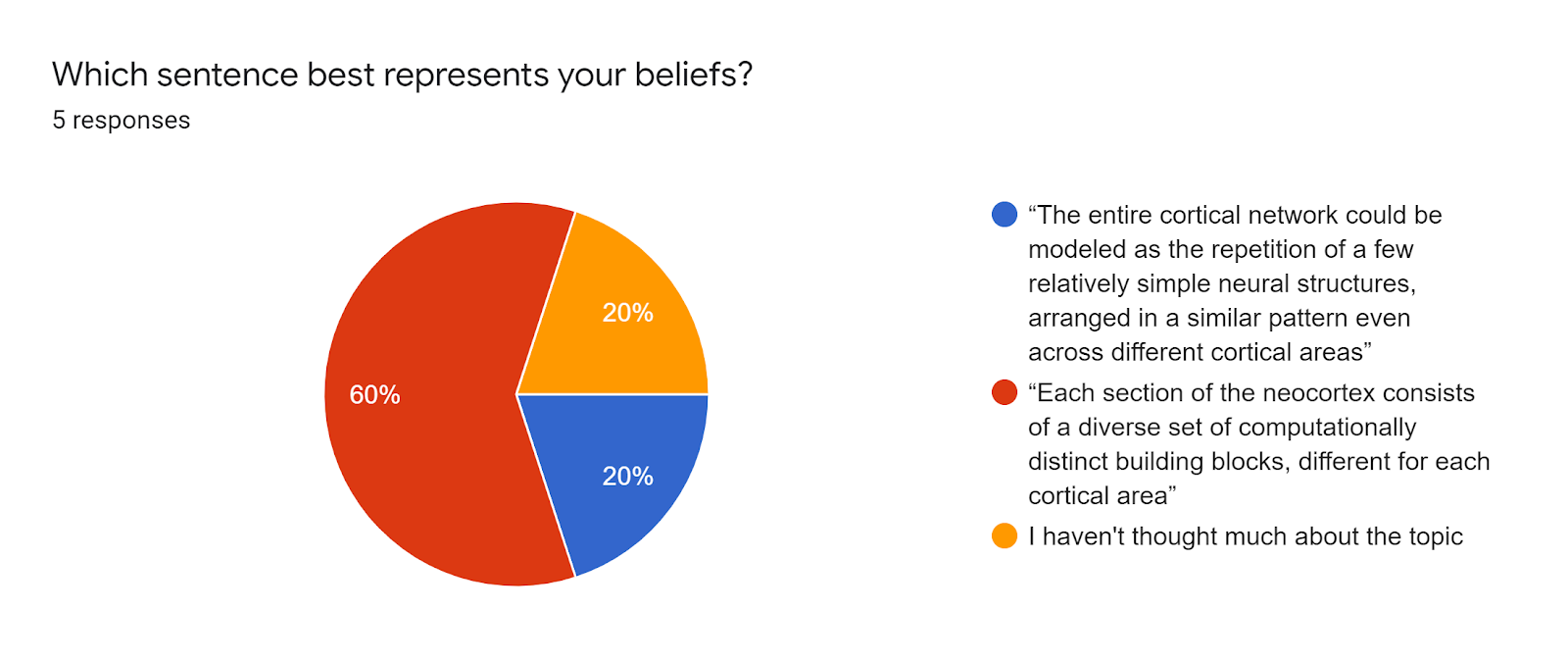
Our small sample of respondents seems split, erring in favor of many structural differences between cortical areas (option B).
----------------------------------------------------------------------------------------------------
Q2: What sentence better represents your beliefs?
A (blue): “The genome directly encodes how each of the cortical areas will process information in a different way”
B (red): “The genome only directly specifies the location, extent and general connectivity pattern of the different cortical areas - as opposed to directly specifying the differences on how each cortical area processes information”
This question was intended to capture the notion of uniformity in learning - whether all cortical areas start undifferentiated except because of the inputs they receive, and then differentiate during their operation.

Our small sample of respondents seems to favor a “blank slate” model, where differences in cortical areas are not innate but learned (option B).
----------------------------------------------------------------------------------------------------
Q3: What sentence better represents your beliefs?
A (blue): “Even a rough understanding of the neocortex will require an in-depth study of each cortical area”
B (red): “Once we understand how one area of the neocortex works we will have an almost complete picture of how the full neocortex works”
This question is gauging how much will the experts expect that insights about a cortical area will transfer to other cortical areas.

Our small sample of respondents seems to unanimously believe that there will not be enough transfer between areas that learning about one cortical area will teach us much about other areas (option A).
Acknowledgements
Project and write-up by Jaime Sevilla and Pablo Villalobos.
We thank Steve Byrnes, Nikolas Bernaola, Celia Yáñez and an anonymous neuroscience researcher for giving useful feedback on the survey design.
We also thank all the participants of the survey for their time.
We also thank Miguel Arjona Hermoso, who helped us a great deal with the logistics of distributing the survey.
6 comments
Comments sorted by top scores.
comment by DanB · 2021-02-24T03:16:00.954Z · LW(p) · GW(p)
One very important observation related to this issue is the fact that we often observe specific cognitive deficits (e.g. people who can't use nouns) but those specific deficits are almost always related to a brain trauma (stroke, etc.) If there were significant cognitive logic coded into the genome, we should see specific cognitive deficits in otherwise healthy young people caused by mutations.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-02-24T12:56:14.068Z · LW(p) · GW(p)
Good insight! Haven't seen that one before!
comment by NunoSempere (Radamantis) · 2021-02-23T22:39:11.863Z · LW(p) · GW(p)
I made three quick predictions, of which I'm not really sure. Someone should do the Bayesian calculation with a reasonable prior to determine how likely is it than more than half of experts would answer some way given the answers by the 6 experts who did answer.
For some of these questions, I'd expect experts to care more about the specific details than I would. E.g., maybe for “The entire cortical network could be modeled as the repetition of a few relatively simple neural structures, arranged in a similar pattern even across different cortical areas” someone who spends a lot of time researching the minutiae of cortical regions is more likely to consider the sentence false.
Replies from: Jsevillamol, Jsevillamol↑ comment by Jsevillamol · 2021-02-24T09:20:03.563Z · LW(p) · GW(p)
Street fighting math:
Let's model experts as independent draws of a binary random variable with a bias $P$. Our initial prior over their chance of choosing the pro-uniformity option (ie $P$) is uniform. Then if our sample is $A$ people who choose the pro-uniformity option and $B$ people who choose the anti-uniformity option we update our beliefs over $P$ to a $Beta(1+A,1+B)$, with the usual Laplace's rule calculation.
To scale this up to eg a $n$ people sample we compute the mean of $n$ independent draws of a $Bernoilli(P)$, where $P$ is drawn from the posterior Beta. By the central limit theorem is approximately a normal of mean $P$ and variance equal to the variance of the bernouilli divided by $n$ ie $\{1}{n}P(1-P)$.
We can use this to compute the approximate probability that the majority of experts in the expanded sample will be pro-uniformity, by integrating the probability that this normal is greater than $1/2$ over the possible values of $P$.
So for example we have $A=1$, $B=3$ in Q1, so for a survey of $n=100$ participants we can approximate the chance of the majority selecting option $A$ as:
import scipy.stats as stats
import numpy as np
A = 1
B = 3
n = 100
b = stats.beta(A+1,B+1)
np.mean([(1 - survey_dist.cdf(1/2)) * b.pdf(p)
for p in np.linspace(0.0001,0.9999,10000)
for survey_dist in (stats.norm(loc = p, scale = np.sqrt(p*(1-p)/n)),)])which gives about $0.19$.
For Q2 we have $A=1$, $B=4$, so the probability of the majority selecting option $A$ is about $0.12$.
For Q3 we have $A=6$, $B=0$, so the probability of the majority selecting option $A$ is about $0.99$.
EDIT: rephrased the estimations so they match the probability one would enter in the Elicit questions
↑ comment by NunoSempere (Radamantis) · 2021-02-24T14:41:59.381Z · LW(p) · GW(p)
EDIT: rephrased the estimations so they match the probability one would enter in the Elicit questions
Oof, that means I get to change my predictions.
↑ comment by Jsevillamol · 2021-02-24T09:27:10.213Z · LW(p) · GW(p)
re: "I'd expect experts to care more about the specific details than I would"
Good point. We tried to account for this by making it so that the experts do not have to agree or disagree directly with each sentence but instead choose the least bad of two extreme positions.
But in practice one of the experts bypassed the system by refusing to answer Q1 and Q2 and leaving an answer in the space for comments.