An illustrative model of backfire risks from pausing AI research
post by Maxime Riché (maxime-riche) · 2023-11-06T14:30:58.615Z · LW · GW · 3 commentsContents
TLDR Summary Introduction Acknowledgments Definition: "Takeoff speed" in this post equals "Maximum explosive takeoff speed" Definition: Training/inference asymmetry = Number of AI researchers you can run just after training a model Motivation: Why look at the takeoff speed? Answer: Because most of the X-risks concentrate around the time of the explosive takeoff. Model Main dynamics Building the model step-by-step Guessing the parameters Illustrations Baseline (without 3. The training/inference asymmetry effect) Increasing investment (without 3. The training/inference asymmetry effect) Increasing investment (with 3. The training/inference asymmetry effect) Scenarios Scenario - Long timelines Scenario - Short timelines Takeaways General Surprising updates How do these arguments and/or this model fail? Comparison with the takeoff speed report's model Results expected if the model in this post is right: Results observed: Conclusion: Best guess scenario Best guess scenario - low training requirement only Computing Overhangs LW's wiki page Guessing the parameters - Details None 3 comments
TLDR
The post contains a simple modelization of the maximum explosive takeoff speed (simplified as "takeoff speed"), using as the main parameters:
- overhangs[1] sizes (investment, hardware efficiency, software efficiency)
- overhangs consumption rates[2]
- training/inference asymmetry[3]
The post concludes that:
- in a short timeline scenario, increasing investment or pausing software efficiency improvement can increase a lot the maximum takeoff speed.
- because you can only decrease one overhang by increasing the others
- because you can run more AI researchers at the start of the takeoff
- working on software efficiency, and especially on increasing capability while reducing the training/inference asymmetry (e.g. scaffolding) could decrease a lot the maximum takeoff speed.
- etc.
Summary
This post is a contribution to the AI pause debate. It will illustrate a few effects for why pausing progress on software efficiency or increasing investment can be negative.
The model in this post predicts similar effects on the takeoff speed from increasing investment or from pausing software efficiency improvement. I will mainly illustrate the effects by looking at an increase in early investment. Still, the effects will be similar to a pause in AI development if it mostly slows down progress on software efficiency.
This post also tries to address the claim that shorting timelines can lead to a softer takeoff. The model concludes that while short timelines can have softer takeoffs, shortening timelines by investing more will likely increase the takeoff speed.
I describe a naive model of AI capability acceleration, whose main features are to look at different types of overhangs[1], their sizes, consumption rates[2], and how these rates are influenced by the training/inference asymmetry[3].
This model only looks at a few effects, and their impacts on the maximum speed of capability increase during the explosive takeoff period.[4]
The model includes the following effects:
- You can not, at the same time, reduce all capability overhangs at the start of takeoff. You can only trade reducing one for increasing another one. This follows from the explosive takeoff starting at a fixed level of capability.
- The software efficiency overhang is one of the most important components in determining takeoff speed. The software efficiency overhang is the largest overhang and the fastest consumed.
- The training/inference asymmetry[3] influences the consumption rate of the remaining software efficiency overhang. And the training/inference asymmetry increases fast with an increase in investment.
The model concludes the following:
- Increasing investments earlier in a maxed-out investment scenario (e.g. long timelines) does NOT change the maximum takeoff speed.
- If you do NOT expect investment to reach a maximum before starting takeoff (e.g., short timelines), then increasing investment (e.g. scaling) leads to a significantly faster explosive takeoff.
The model also leads to a few indirect conclusions:
- A large open-source community with highly capable open-source models may reduce X-risks by producing a slower takeoff, because of the incentives of the open-source community to improve software efficiency.
- Working on capabilities on software efficiency (e.g., especially large-scale scaffolding) could have a large positive impact by reducing takeoff speed[5].
Introduction
Acknowledgments
Thanks to @Jaime Sevilla [EA · GW] and @Tom_Davidson [EA · GW] for their generous feedback on this post. All errors are mine.
Thanks to @Tristan Cook [EA · GW] for prompting my work on this, by asking me why I thought increasing investment early may soften the takeoff. In the end, this model shows the opposite.
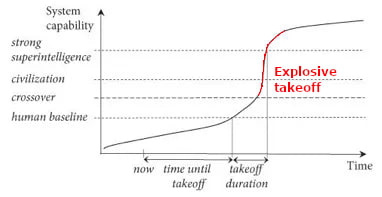
Definition: "Takeoff speed" in this post equals "Maximum explosive takeoff speed"
By takeoff, I mean the "explosive takeoff", when an explosive capability increase is triggered by creating capable enough AI (e.g., automatizing >90% of cognitive work). I don't mean the "pre-takeoff" period during which the speed-up in capability increase is still strongly limited.
The post focuses on the maximum speed of capability increase during the explosive takeoff. I often call this the “takeoff speed” while meaning the “maximum speed of capability increase during the explosive takeoff”.
Definition: Training/inference asymmetry = Number of AI researchers you can run just after training a model
The training/inference asymmetry is the fact that after finishing training one model, you can start running N inferences by using the same supercomputer used for training.
I.e., as soon as you finish training, you can use the trained model many times using the same computing infrastructure.
E.g., if you always train your model in the same amount of clock time, and you increase the number of data points you train on by x10, then you will need a supercomputer x10 as large[6], and after training, you will be able to run x10 more inferences.
Motivation: Why look at the takeoff speed? Answer: Because most of the X-risks concentrate around the time of the explosive takeoff.
Given recent developments in AI safety, it is now more likely that we will manage to align below or around human-level capabilities. You can find a list of advances in AI safety that push in that direction in Don't Dismiss Simple Alignment Approaches [LW · GW] or Thoughts on sharing information about language model capabilities [LW · GW]. Furthermore, over the last year, there has been surprising progress in AI governance (e.g., the UK AI safety summit [LW · GW] or [7] and the US executive order on AI safety [EA · GW]). All of these are updates towards less X-risks probability before takeoff.
The default plan looks more and more like OpenAI's Superalignment plan: Leveraging aligned AIs to align/oversee higher capability AIs. A critical parameter influencing the probability of success of this plan is the speed at which AI capabilities will increase.
Thus, the model in this post will look at the maximum speed of capability increase during the explosive takeoff ("takeoff speed") and how a few parameters influence it.
Model
Main dynamics
There are three main dynamics in this model, and the later sections will sometimes only look at the first two without looking at the third.
- The software efficiency overhang drives takeoff speed.
- The software efficiency overhang is the overhang influencing the most the takeoff speed. Because of its large size and fast consumption rate.
- No free lunch on decreasing overhangs.
- Decreasing one overhang leads to increasing some of the other overhangs (at the start of the takeoff). Because of having a fixed threshold of capability for the start of the takeoff.
- The training/inference asymmetry effect.
- The consumption rate of the software efficiency increases fast with the investment in training costs, because of the increase in the training/inference asymmetry.
Building the model step-by-step
The following model is NOT a predictive model, some parameters are set arbitrary. The model is here to illustrate the main dynamics presented above and to give a rough sense of the directions and intensity of the different effects.
- Capabilities are determined by summing:
- log(investment) ($)
- log(hardware efficiency) (FLOP/$)
- log(software efficiency) (capability/FLOP)
- The takeoff starts at a fixed level of capabilities.[8]
- The explosive takeoff ends when all capability overhangs have been consumed.[9]
- There are three capability overhangs related to the three parameters determining the level of capability (investment, hardware efficiency, and software efficiency).
- The overhangs are modeled as fixed pools to consume.[10]
- The percentage of each overhang remaining is set at different times:
- At the start (e.g. t=0), they are equal to their initial overhang size. The pools have not been consumed at all yet (0% consumed).
- At the start of takeoff, the overhangs have been partially consumed (X% consumed).
- At the end of takeoff, there are no overhangs remaining (100% consumed).
- The speed at the start of the takeoff (OOM/year) is only determined by:
- The remaining size of the overhangs:
- InitalSize(overhang) * %Remaining(overhang)
- i.e., (100-X%) of the initial overhang sizes. Given that X% has been consumed before reaching takeoff.
- The consumption rates of the overhangs.
- % of the remaining overhang consumed per year.
- The remaining size of the overhangs:
- The consumption rates of the overhangs are linked to:
- The consumption rates of the remaining investment and hardware efficiency overhangs are modeled by:
- Before takeoff:
- ConsumptionRate(overhang) = C0.
- For simplicity, C0 is constant and has the same value for each overhang.
- After takeoff:
- ConsumptionRate(overhang) = C1 * 1/Delay(overhang)
- This function fits better the dynamic during the takeoff than before. During takeoff, there are fewer bottlenecks on the inputs (e.g., no bottlenecks on capital and cognitive work), just some delay steps for scaling, producing, and upgrading things[12].
- The Delay(overhang) is the relative delay step of the different overhangs.
- Arbitrary: C1 = 100 * C0.
- Before takeoff:
- The consumption rate of the software efficiency overhang, during takeoff, is modeled by:
- ConsumptionRate(soft. eff.) = C1 * 1/Delay(soft.eff.) * C2 * SQRT(SQRT(investment))
- In short, this is because of scaling laws (first SQRT), and because of some diminishing returns on increasing the number of AI researchers (second SQRT). Diminishing returns are still assumed small because of working with AI clones at a time with a lot of low-hanging fruits (start of takeoff). Some explanations in [13].
- Finally, the takeoff speed is equal to:
(I omit some of the "Overhang" terms below, but most of the terms are about overhangs. And I set t = start of takeoff.)
TakeoffSpeed(t=start of takeoff)
= SumOverOverhangs(InitialSize * %Remaining * ConsumptionRate)
= (InitialSize(invest.) * %Remaining(invest.) * C1 * 1/Delay(invest.)) +
(InitialSize(hard.eff.) * %Remaining(hard.eff.) * C1 * 1/Delay(hard.eff.)) +
(InitialSize(soft.eff.) * %Remaining(soft.eff.) * C1 * 1/Delay(soft.eff.) * C2 * SQRT(SQRT(investment)))
- The start of the takeoff is determined by crossing the threshold TakeoffThreshold: equal to:
TakeoffThreshold
= 1e36
= InitialSize(invest.) * (1-%Remaining(invest., t=start of takeoff)) +
InitialSize(hard.eff.) * (1-%Remaining(hard.eff., t=start of takeoff)) +
InitialSize(soft.eff.) * (1-%Remaining(soft.eff., t=start of takeoff))
- The model has nine parameters: the three InitialSize(overhang), the three Delay(overhang) and the three constants C0, C1, C2.
Guessing the parameters
For the Delay(overhang) parameters, I will only look at their relative values.
- I chose a value for C0 and C1 such that the takeoff starts close to 2040, as in the best guess scenario of the takeoff speed report:
- C0 = 0.0037 (per tenth of year)
- C1 = 100 * C0 = 0.37 (per tenth of year)
- Also somewhat arbitrarily, I chose a value for C2 such that SQRT(SQRT(investment)) is somewhat balanced out in the best guess scenario from the takeoff speed report: C2 = 1/33.
- Hardware efficiency overhang:
- Training cost overhang (investment overhang):
- Size: 4 OOM[14]
- Delay (in months): using 10 in the model
- 15 (building a new supercomputer)
- Software efficiency overhang:
A few explanations are available in [15].
Illustrations
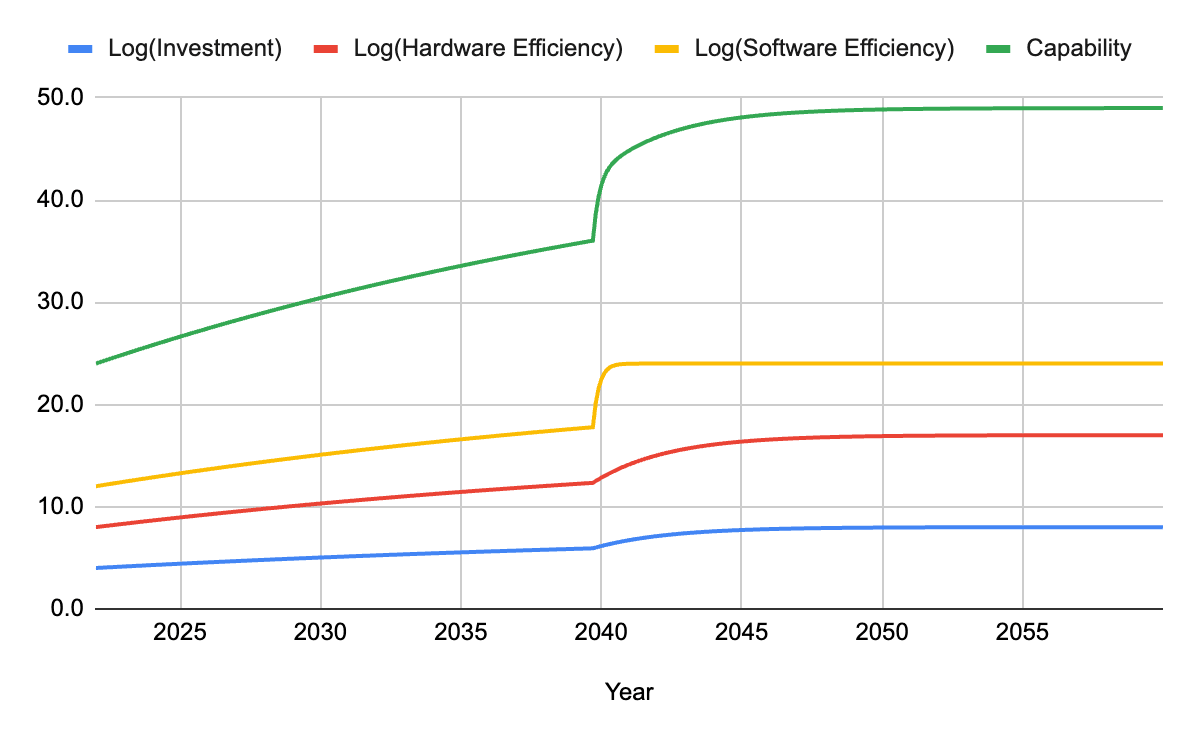
Baseline (without 3. The training/inference asymmetry effect)
This is a baseline, with semi-arbitrary numbers for the overhang consumption rates, and the initial values. You can see the formulas in [16]. The capability is the sum of the consumption of the 3 overhangs. The takeoff starts when capability reaches 36 (1e36 compute equivalent).
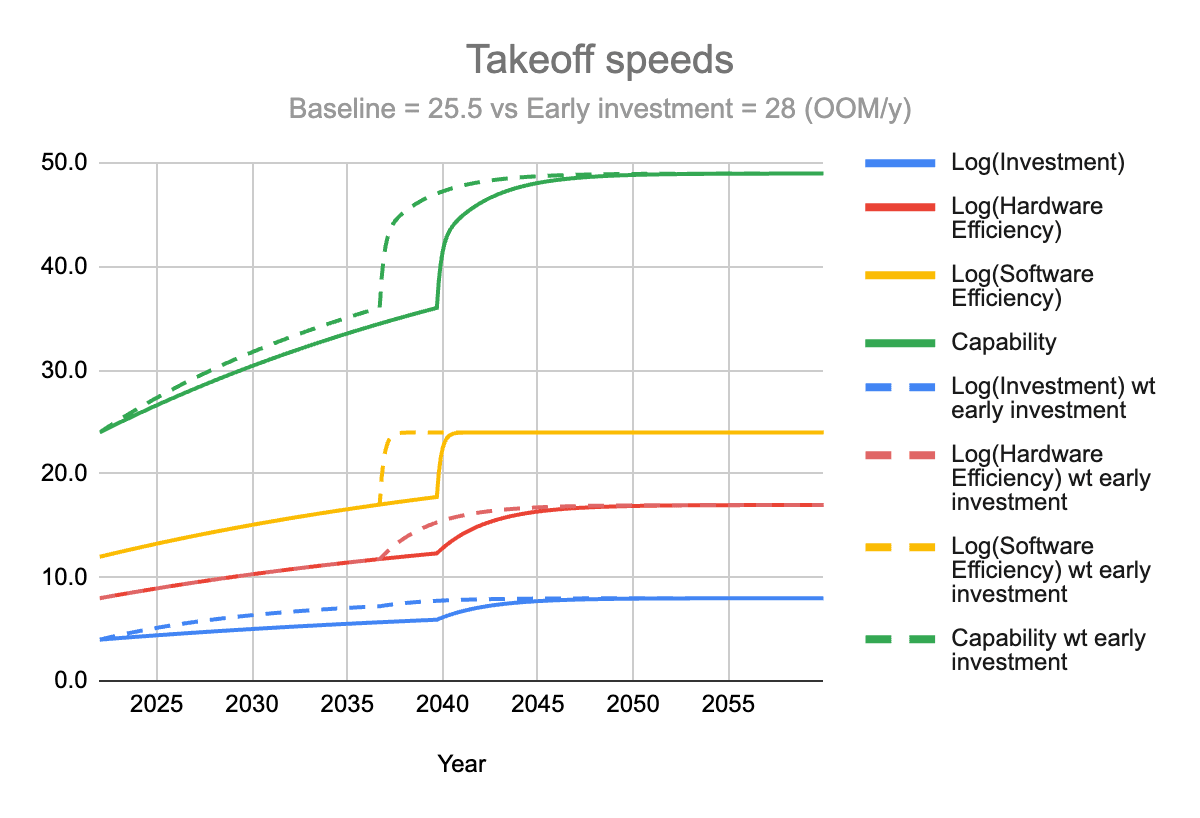
Increasing investment (without 3. The training/inference asymmetry effect)
I don't add yet here the effect of the training/inference asymmetry on the consumption rate of the software efficiency overhang.
I compare the baseline with a scenario in which investment overhang is consumed x3 faster during pre-takeoff. The maximum takeoff speed increases from 25.5 to 28 (OOM of compute equivalent/year).
Note: these values 25.5 and 28 OOM/y are much more illustrative than predictive. The relative increase is more important than the absolute numbers.
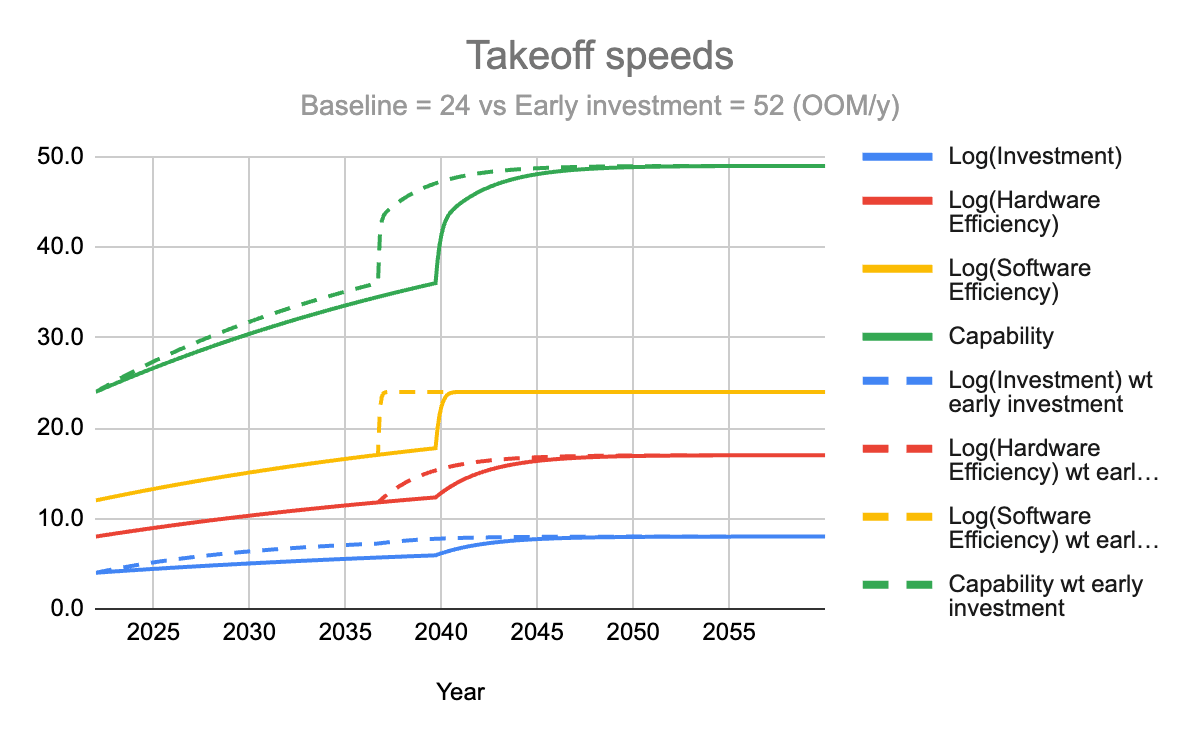
Increasing investment (with 3. The training/inference asymmetry effect)
I finally add the effect of the training/inference asymmetry on the consumption rate of the software efficiency overhang.
I compare a new baseline (with the dynamic 3) with a scenario in which the consumption of the investment overhang is x3 faster during pre-takeoff. The maximum takeoff speed increases from 24 to 52 (OOM of compute equivalent/year).
Note: these values 24 and 52 OOM/y are much more illustrative than predictive. The relative increase is more important than the absolute numbers.
Scenarios
Scenario - Long timelines
Description:
AI labs scale investments spent on training costs early, but because timelines are long and there are large economic incentives to invest in AI, this boost is balanced by lower investment growth later. I.e., this early increase in investment does not change the level of investment at the start of takeoff because training costs were already going to be max-out at the start of takeoff.
Assumption (1): I assume no increase in investments in hardware and software efficiencies.
Or assumption (2): Assumption (1) is unrealistic. Let's assume instead that if there is an increase, but it applies as strongly to both hardware and software efficiencies.
Consequences:
- No impact on when the takeoff starts.
- Only under assumption (1)
- No impact on the overhangs at the start of takeoff.
- No impact on the training/inference asymmetry at the start of takeoff.
- No impact on the takeoff speed.
- Increasing investment early in this scenario leads to having higher capability models for longer to study, without changing the takeoff speed.
Scenario - Short timelines
Description:
AI labs invest more heavily in training costs early. Because timelines are short, we see a counterfactual change in the distribution of investment, hardware efficiency, and software efficiency overhangs when the takeoff starts. The early increase in investment is not balanced out later.
Consequences:
- When the takeoff starts, the investment overhang is smaller.
- The hardware and software efficiencies overhangs are larger.
- The training/inference asymmetry is larger, increasing the consumption rate of the software efficiency overhang further.
- Takeoff is faster because of easier software efficiency gains (more of the overhang remaining) and because of more AI researchers being run (larger training/inference asymmetry).
Takeaways
General
Given the very limited scope of this model:
- The size of the software efficiency overhang, its consumption rate, and the training/inference asymmetry mostly determine the speed of the takeoff.
- You can only trade reducing one capability overhang for increasing another one at the start of takeoff. You can not change the level of one capability overhang without changing the level of some of the others.[17]
- Counterfactually increasing investment or hardware efficiency faster than software efficiency only increases the size of the software efficiency overhang at the start of the takeoff period. Likely increasing the takeoff speed.
- Counterfactually increasing investment at the start of takeoff, can greatly increase the consumption rate of the remaining software overhang during the takeoff, and thus increase the takeoff speed (because of the training/inference asymmetry).
- Pausing progress on software efficiency (e.g., AI pause debate), can lead to an increase in the takeoff speed and to higher X-risks.
- While short timelines could have softer takeoffs, shortening timelines by investing more in scaling is likely to increase the maximum takeoff speed and make the situation worse.
Surprising updates
After working on this question, I changed my mind a bit towards the following:
- Investing more now in training costs is not especially making the takeoff slower, even if it may give us more time to study AIs close to human-level capabilities.
- Contrary to what I thought, investing more may lead to a larger software efficiency overhang, a larger training/inference asymmetry, and a significantly faster takeoff.
- Working on AI capability by working on software efficiency could be net positive.
- A strong open-source community may be good for decreasing software efficiency overhang, and having capable open-source models may promote that.
- Instead of simply being bad because of increasing misuses and reducing timelines, the open-source community is also going to push strongly for progress on software efficiency because most researchers will miss the capabilities to work on scaling and hardware efficiency. This should reduce the takeoff speed.
- Shorter timelines, in which the training/inference cost asymmetry is smaller compared to longer timelines, will have lower takeoff speeds.
- The training/inference asymmetry scales with the number of data points used for training. And the number of data points scales when scaling investment on training costs (scaling laws). Reaching takeoff with a smaller training/inference asymmetry should give lower takeoff speed.[20]
How do these arguments and/or this model fail?
The updates just above should not be made if you think:
- That takeoff speed is not an important parameter influencing our chances of aligning AIs.
- That reducing takeoff speed significantly is intractable.
- E.g. increasing research on software efficiency is very hard since it is already strongly incentivized and crowed.
- That takeoff speed is initially way too high, and reducing it a bit won't change anything to our chance of success.
- E.g., you think that we would need to reduce the takeoff speed by 1,000,000 before starting to increase our chance of success.
- The impact of the training/inference asymmetric could be largely overestimated in this model. Because this model assumes not decreasing returns on running more AI researchers, and because the training/inference asymmetry is going to be largely reduced by AI capability researchers (e.g., Chain of Thoughts, Tree of Thoughts, Agent/AutoGPT, Corporations of Agents).
- I just spent 33 hours on this post, changing its scope several times. It is possibly wrong in some important ways.
- The model in this post is limited to only a few effects and doesn't account for many other effects. Like the reduction in the research time done by Humans on AI safety when the takeoff starts earlier.
- etc.
Comparison with the takeoff speed report's model
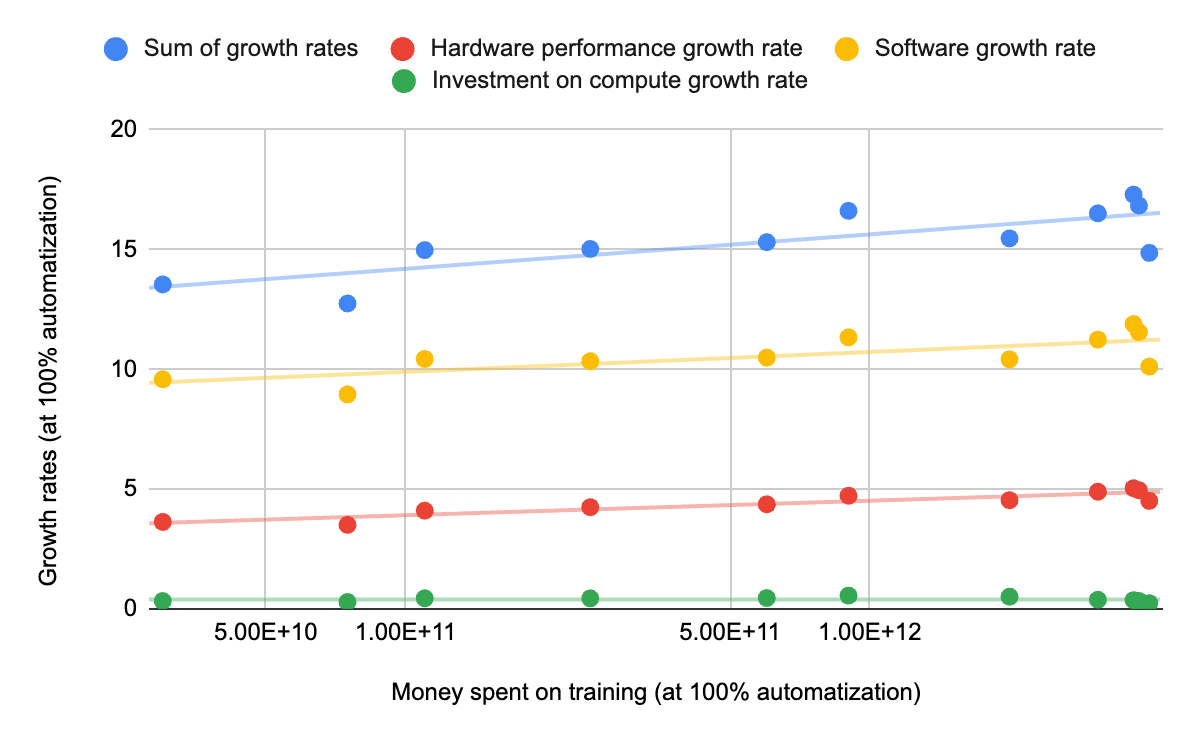
You can find the takeoff speed report in the following post: What a compute-centric framework says about takeoff speeds [EA · GW]. You can play with their model at https://takeoffspeeds.com/.
I played with increasing the investment rates in the model. I changed both the "Growth rate fraction GWP compute" and "Wake-up growth rate fraction of GWP buying compute" at the same time and kept their values equal. You can find the extracted data here.
Results expected if the model in this post is right:
- When we increase the spending on training costs during takeoff, we decrease the necessary level of hardware and software efficiency. This leads to larger hardware and software overhangs, which in turn make the maximum takeoff speed faster.
- At the same time, when increasing the spending on training costs, we increase the training/inference asymmetry. This should make the maximum takeoff speed increase too, because of increasing the consumption rate of the software efficiency overhang.
Results observed:
- We observe the trend expected if the presented model is right.
Conclusion:
- Overall, it's plausible that their model produces an analysis going in the same direction as the model in this post.
- However, this is clearly not enough to conclude that the model in this post is correct or sufficient.
Best guess scenario
Best guess scenario - low training requirement only
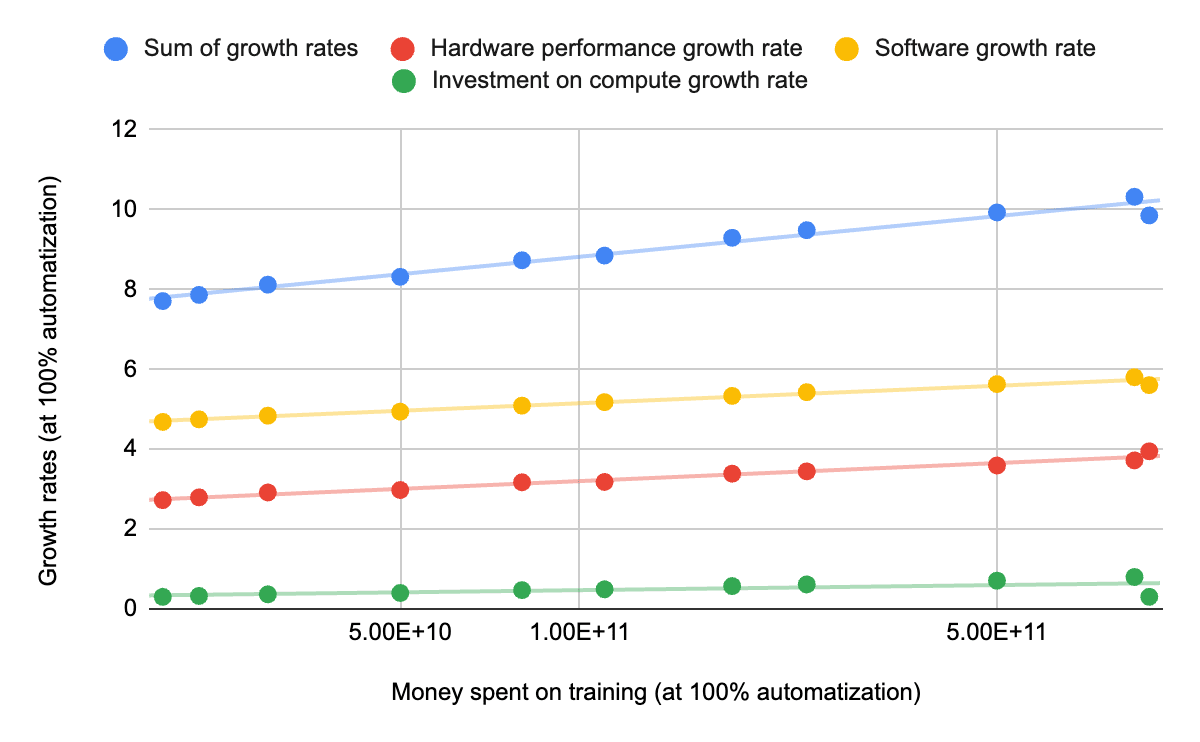
- ^
- ^
I define the consumption rate of some capability overhang by the percentage of the remaining overhang that is consumed in a year. This leads to the remaining overhangs at time t following an exponential decay function.
- ^
The training/inference asymmetry is the fact that after finishing training one model, you can start running N inferences by using the same supercomputer used for training. I.e., as soon as you finish training, you can use the trained model many times using the same computing infrastructure.
- ^
Scope of the post: This post is limited in scope and is about the question: “Does accelerating AI capabilities reduce the maximum explosive takeoff speed?”. It is NOT about the questions: “Does accelerating AI capabilities have a positive or negative impact?”, etc.
- ^
Obviously, the reduced takeoff timeline also needs to be taken into account, and this is not modeled here.
- ^
With a number of weights constant.
- ^
- ^
There is a threshold of capability after which the explosive takeoff starts (e.g. 90% automatization of cognitive tasks).
- ^
The takeoff ends when there are no more overhangs to easily consume for fast capability improvement (or if self-improvement is stopped, e.g. by governance or by the loss of self-improvement capabilities, but this is neglected).
- ^
The size of the pool is given as an initial parameter. Excluding the investment overhang, whose pool size increases with the GWP (World GDP). But I ignore this effect.
- ^
This is not the case for the hardware efficiency and investment overhangs, which have bottlenecks preventing most of this effect.
- ^
But this function would largely be wrong for the pre-takeoff period, which is should be much more governed by returns on investments.
- ^
Because of scaling laws, and assuming that the training time for SOTA models stays the same, we have something like this:
E.g., each time investment is scaled by x100, the training run uses x10 more data points to train a model x10 larger, and the supercomputer used for training the model will be able to run x10 more inferences after training (assuming training clock time constant).
How is this linked to the consumption rate of the software efficiency overhang? I will assume that:
- when you have x100 more clones of the same researcher
- and when you have a lot of potential research directions (e.g. at the start of takeoff when a lot of the overhang is remaining)
- then your research outputs are simply multiplied by x10.
So, I am assuming some small diminishing returns (SQRT) because researchers are clones of each other and because I look at a time (start of takeoff) when a lot of capability overhangs remain. - ^
From my understanding of What a compute-centric framework says about AI takeoff speeds [EA · GW].
- ^
- ^
- ^
Excluding the effects of GWP growth.
- ^
Using huge scaffoldings OOM larger to increase SOTA could slow takeoff (during its most dangerous time) by reducing the number of AI researchers that we will be able to run when we unlock this level of capability. For example, instead of running for the first time, 10000 AI equivalent researchers in parallel in 2030, it could be safer to be able to run 10 expensive AI equivalent researchers in 2029 instead by paying a huge 3 OOM premium using massive scaffolding techniques.
- ^
Trading off compute in training and inference by Epoch. Same on LW [LW · GW].
- ^
This is NOT an argument for reducing timelines. It is an argument for being more optimistic about the outcomes in a world with short timelines.
The model presented in this post says that actively reducing timelines only reduces the takeoff speed if you consume relatively more of the software efficiency overhang while also not increasing the training/inference asymmetry.
3 comments
Comments sorted by top scores.
comment by Tom Davidson · 2023-12-02T19:19:30.630Z · LW(p) · GW(p)
I think your model will underestimate the benefits of ramping up spending quickly today.
You model the size of the $ overhang as constant. But in fact it's doubling every couple of years as global spending on producing on AI chips grows. (The overhang relates to the fraction of chips used in the largest training run, not the fraction of GWP spent on the largest training run.) That means that ramping up spending quickly (on training runs or software or hardware research) gives that $ overhang less time to grow
Replies from: maxime-riche↑ comment by Maxime Riché (maxime-riche) · 2023-12-04T03:28:19.766Z · LW(p) · GW(p)
Interesting! I will see if I can correct that easily.
comment by Vladimir_Nesov · 2023-11-06T14:52:34.808Z · LW(p) · GW(p)
Technical constraints on speed of takeoff only determine actual speed of takeoff when there is no control over what's happening, instead of going orders of magnitude slower than feasible. Pause and strong coordination on development might be useful for securing such control.