Finding Goals in the World Model
post by Jeremy Gillen (jeremy-gillen), JamesH (AtlasOfCharts), Thomas Larsen (thomas-larsen) · 2022-08-22T18:06:48.213Z · LW · GW · 8 commentsContents
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth
Introduction
Architecture assumptions
IRL training procedure for an aligned EfficientZero style model
IRL proposal
Research required
Red-Team and Response
This is uncompetitive
The IRL process won’t converge to what we want
Inner misalignment
Remaining confusion
Updates
Jeremy
Thomas
James
None
8 comments
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth [LW · GW]
Introduction
This post works off the assumption that the first AGI comes relatively soon, and has an architecture which looks basically like EfficientZero [LW · GW], with a few improvements: a significantly larger world model and a significantly more capable search process. How would we align such an AGI?
Our pitch is to identify human values within the AGI’s world model, and use this to direct the policy selector through IRL (inverse reinforcement learning). We take a lot of inspiration from Vanessa’s PreDCA proposal [comment [LW(p) · GW(p)]][video], as well as ideas developed in Infra-Bayesian Physicalism. We have stripped these down to what we saw as the core insights, meaning that there are significant differences between this and PreDCA. We initially arrived at this proposal by thinking about an idea similar to "retarget the search" [? · GW], except we’re using hard-coded search instead of learned optimizers, and doing the "identify human values" part using a mathematical definition of agents & goals.

We think that this proposal directly gets at what we view as the core of the alignment problem: pointing to human values in a way that is robust as capabilities scale. Naturally this all depends on the research outlined in the 'Research Required' section succeeding. See the last few sections to see many of the difficulties of this approach.
Architecture assumptions
The most important assumption that we are making is that the agent is designed to explicitly search over actions that maximize a utility function. This is opposed to the model where an AGI is a single component trained end-to-end by RL (or self-supervised learning), and where the AGI learns its own mesa-objective (or the mesa-objectives of simulacra[1]) internally. We will lay out a concrete vision of this model, but keep in mind that the exact details don't matter much.[2]
We are also structuring this proposal to point this agent to maximize the preferences of a single human (henceforth "the operator"), as a simplifying assumption, because we think the difficulty of this proposal is getting it to work for a single human, and scaling to recognize many people's preferences and aggregate them is not too hard.
IRL training procedure for an aligned EfficientZero style model
- We train a generative world model. This world model is judged solely by its predictive accuracy on observations. It uses latent representations of world states at each time step, which update as new observations come in, and can output predicted future observations.
- While the world model is training we run an “Agentometer” and an “operator recognition” program on it. This outputs a probability distribution over “what policy our operator is running, as judged by the world model.”
- We also run a “Utiliscope” which can transform probability distributions over “what policy our operator is running” into probability distributions over “our operator’s utility function.” (The type signature of utility functions will be Sequences of world model Latent States )
- Once our world model is capable of backing out a good-enough utility function, we attach our ‘action selector’ module. The 'action selector' does hard-coded search over action-sequences. It selects action-sequences resulting in predicted (by the world model) world-trajectories that the utility function values highly.
- This search procedure also uses learned heuristics to improve search efficiency. Ultimately these heuristics are trained to predict the output of the hardcoded search.
- Further training on simulated environments or the real world allows it to improve its world model and action selector, and as the world model improves it gets a better picture of the operator's utility function.
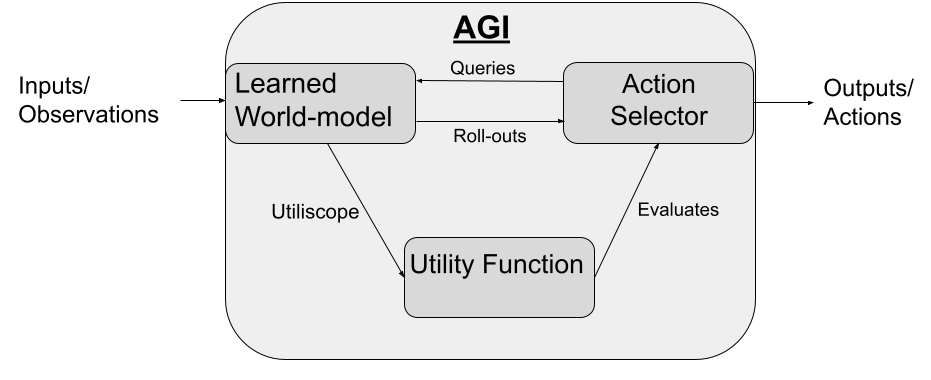
IRL proposal
We assume that we are trying to align our model to the values of an individual human, the operator[3]. The world model contains information about the operator, and we are looking to determine "what they value".
This approach[4] aims to obtain this human’s utility function, both through reverse-engineering the human’s observed actions, and also from all information the world model has gathered thus far which informs what the human would do in hypothetical scenarios (e.g. other humans, psychology, neuroscience, moral philosophy etc.). The basic idea is to do IRL on the world model’s guess of the operator policy. We think, a priori, that humans are more likely to have simpler utility functions, so a simplicity prior is appropriate for backing out a good approximation of a human’s ‘Hypothetical True Utility Function’. The approach also assumes that humans are "intelligent", in the sense of being likely to be good at optimizing our utility function.[5] This approach doesn't assume that humans actually have an explicit utility function internally.
We start by defining a measure of intelligence, .[6] Given a utility function , the intelligence of an agent is a function of how often the agent’s policy, , acquires more expected utility than a random policy, (where we have some prior distribution over policies ). The two policies are separately evaluated according to the probability distribution over possible worlds, .
describes how much utility an agent gets according to a given utility function from following the policy in a possible world .
Then describes the expected amount of utility an agent will get by following the policy across the distribution of possible worlds , since we have uncertainty over exactly which world we are in.
Putting this together, we obtain the formula for the intelligence, of the agent above. This is given by the of the probability that a random policy performs better in expectation than the agent's policy according to the utility function . This defines our intelligence metric.
Now we use a function of this intelligence metric as a kind of “likelihood” which determines a probability distribution over possible utility functions the operator might have. We use , the Solomonoff prior, as the simplicity prior over utility functions. This ends up being:
Or, substituting our formula for , and adding some detail explained in a footnote[7]:
The is just because we have to normalize, as in Bayes' rule. Here, the denominator would be just .
This equation gives us a distribution over the likely utility functions of the operator. To calculate this, we must have access to a distribution representing computations (policies) that happen in the world model, and also "look like" the operator (according to some classifier). We also require that we can replace this policy, in a world model, with counterfactual policies .
We can think of the above equation as searching for intelligent agents in the world model, by searching over all “programs” in the world model and finding ones with a high . Prior to this, we will need to implement a simple classification to narrow down the space of possible 'operator' agents out of all agents identified.
This solves outer alignment as long as we have correctly specified the human operator in the world model, pointed to it, and then inferred (an accurate distribution over) its utility function. As the world model improves, this process should converge to a better and better approximation of the operator’s utility function, even if the operator is in many ways irrational. This is because the irrationalities will be better explained by the operator having lower , than by adding weird complexities and exceptions to the utility function. (There is, in reality, going to be a weighting between the simplicity and intelligence priors, and this will likely not be 1:1 as in the formula above. The optimal trade-off can probably be found empirically based on what works best for identifying the utility functions of simpler test agents).
We implemented a simple example of this process (with very small discrete priors over utility functions, policies, and environments, and a Cartesian agent). In practice we will need to implement an approximation to this process, which will still require a very efficient procedure for estimating expectations with respect to huge distributions over policies, environments and utility functions.
Research required
- How do we extract the agent's model of a human from the agent's world model? What is the type signature of the agent's model of a human? How do we make the policy prior correspond to this type signature in a meaningful way? It is currently unclear, even in principle, how we would identify all the 'computations' or 'programs' running in a neural-network world model.
- In Infra-Bayesian Physicalism these problems are solved by using the bridge transform, which takes in the agent's beliefs about the world, and (essentially) turns it into the set of programs running in the world. Then we can just measure the intelligence of all such programss.[8]
- Through understanding the representations that the world model is using to represent information (via e.g. 'natural abstractions'), we can iterate over all abstract “objects/algorithms” in the world model, which would include humans.
- How do we cross the Theory-Practice gap for the Agentometer and Utiliscope? Can we reuse the powerful search procedures used in the “action selector” to compute these functions efficiently?
- Maybe we can use architectural and training process modifications to force a neural net to represent agents in a specific, identifiable way.
- What prior over utility functions is best? It should be a simplicity prior of some kind, but that still leaves us a lot of wiggle room. How do we even know when we have found a good prior that will converge to an actually good approximation of “the human's utility function”?
- We've written that the type signature of the utility functions that get learnt by the model is 'Sequences of world model latent states ', but how long should these sequences be? Universe-length time-horizon seems hard to implement, but very small time-horizon is insufficiently general to represent the values over trajectories that humans have. This is an implementation difficulty that seems solvable in principle, but we don't know how yet.
Red-Team and Response
This is uncompetitive
- Having these different components trained separately reduces overall capabilities, especially compute efficiency. With end-to-end training, the world model can be more tightly integrated with the “action selector” search procedure, and with the utility function, which means that end-to-end trained systems will probably be the first to scale to AGI.
- This seems plausible, but the counterargument is that modular systems should be more data-efficient to train, because they have stronger inductive biases. We think both possible futures should be addressed, and currently this future seems underprioritized.
- The real core of intelligence is some kind of advanced search process [LW · GW] (so not babble and prune [? · GW]). We cannot hardcode this, because it is too complicated. This powerful optimizer will have to be learned by some sub-system of the proposed architecture (in which case we have an inner alignment problem), or the overall architecture won’t scale to AGI.
- Simple search processes (e.g. MCTS) could plausibly learn to take actions that implement more complex search processes (e.g. backchaining, constraint relaxation) by writing down a plan and iteratively editing it. This is similar to how language models can do more advanced reasoning using chain of thought prompting despite only having a very simple built-in search procedure (single randomized rollout).
- Alternative approaches could be used to create retargetable general purpose search. It's possible capabilities or interpretability research will make such an alternative approach more competitive.
The IRL process won’t converge to what we want
- The “Agentometer” might find many agents with much higher “intelligence” than humans, and simpler goals (e.g. chess bots, evolution, thermometers, etc). It might also hypothesize very simple but powerful "malign" agents, and we don't want it to copy the goals of these agents. The process by which we classify the human operator will have to be very robust to eliminate all of these.
- Yeah it might have to be. PreDCA has an additional strategy of identifying agents who are causally responsible for the AGI existing, which reduces the amount of work required by the classifier.
- Humans don't have a utility function, because they are irrational in various ways, so modeling humans with IRL won’t necessarily get us a sane utility function.
- We think there are two possible scenarios here
- Humans are naturally 'modellable' as approximately maximizing a utility function (i.e. being imperfect but 'pretty good' maximizers of a utility function). With good enough priors over possible utility functions, and accurate modeling of the human operator, we will be able to narrow down utility functions that are 'a close enough approximation' to what humans actually want.[9]
- Humans aren't naturally 'modellable' this way, and when we try we will get out a simple utility function with maxima that the operator wouldn't endorse. This might be because humans actually have very low "intelligence" according to utility functions that we would endorse (or vice versa).
- This might just be an empirical question that needs to be tested, but we think that scenario 1 seems more likely to be true.
- We think there are two possible scenarios here
- The ontology of the world model could be very different from our natural ontology, which when combined with a simplicity prior on utility functions, might bias the Utiliscope towards weird utility functions.
Inner misalignment
There are several ways that this proposed AGI design could be inner misaligned.
- Any learned heuristics in the “action selector” have an incentive to become mesa-optimizers, and these will probably become inner misaligned.
- The world model is literally required to model agents (not necessarily at full resolution), so it is probably capable of becoming deceptively aligned to its base objective (predict observations accurately).
- The Agentometer is simulating lots of agents of varying capability and goals, it isn’t clear that none of them will try to gain influence somehow.
- The Agentometer is probably going to need learned heuristics to speed up computation. It might be difficult to avoid any mesa-optimizers in these learned heuristics.
On the other hand, in this proposal we have a tool for detecting agents which we could use to check for agents present in the world model’s model of itself, which gives us a hint at a strategy for avoiding dangerous inner optimizers. We haven’t thought this strategy through properly yet.
We have some hope that we can avoid powerful mesa-optimizers by restricting the computation allowed in learned components (world model and any heuristics in the action selector). This may allow the overall algorithm to be aligned for long enough that it can develop its own anti-inner-misalignment strategies. To rely on this, we would want something like an upper bound on the potential “optimization power” that could be implemented by a given ML model.
The second risk is a big one, because it doesn't seem plausible to remove it by limiting the capacity of the world model. However, two possible inner-misalignments could occur in the world model:
- The world model itself becomes deceptively aligned (i.e. stops trying to maximize predictive accuracy, in favor of some other proxy that performs well in training).
- The world model just simulates malign agents, but is itself aligned to the goal of predictive accuracy, and the simulation of such agents is purely instrumental for achieving its true objective.
The first case would be a major problem for this proposal (and any prosaic alignment proposal), but we're uncertain about how likely it is to happen in practice. We think the second case is more likely, and that robustly classifying the operator in the world model prevents this from being a problem (as long as potential malign agents aren't influencing the world model's model of itself).
Remaining confusion
- In the definition of intelligence, , we are unsure about whether to sample from the AGI's current distribution over environments, or a prior over environments:
- Using the AGI's current distribution over environments seems to have some weird edge cases
- Difficult to evaluate a hypothetical agent if all counterfactual tests begin in an environment where it’s about to die.
- Simulating from the beginning of the agent life seems both odd and difficult to determine.
- Using a simplicity prior over environments seems weirder.[10]
- Strongly favors agents that perform well in ultra-simple, unrealistic environments, since these dominate the probability in the prior.
- Using the AGI's current distribution over environments seems to have some weird edge cases
- Confused about how deceptive misalignment will arise in generative world models, and this seems like a crux for how workable this entire plan is.
Updates
Jeremy
- Updated from thinking inner misalignment is a non-core problem for model based RL approaches, to thinking it is the main problem with this approach
- But it still could a an easier situation to fix than the inner misalignment of standard RL. Training on a generative model objective seems like it should take longer or be less likely to produce deceptive alignment, than training on an RL objective in game-like environments. This might be dodgy intuition though.
- The key difficulty with implementing this approach is identifying (and being able to counter-factually replace) agents (or even just "computations") in the world model. I now understand much more of the motivation for Infra-Bayesian Physicalism, which solves this in theory.
Thomas
- Updated to thinking that Efficient-Zero inspired architectures were unlikely to get us to AGI, and that the core of intelligence will look like some learned powerful search procedure within an end-to-end trained model.
- I also had very similar updates to Jeremy on inner misalignment and detecting agents, and strong agree with what he wrote above.
James
- Updated towards the need to conduct more empirical tests of our theoretical definitions, especially towards trying to get these definitions to work in examples that transfer to neural networks.
- I thought the fact that this model was more naturally modular would make it significantly easier to align than a model that is trained end-to-end. I still think this may be the case, but I think it's harder than I previously thought.
- Updated towards specifying correct priors being a big issue in this approach, especially the simplicity prior over utility functions and the prior over possible worlds.
- Also updated the magnitude of the inner misalignment problems here, but still think we may resolve them if we implement the 'Agentometer' and 'Utiliscope' really well.
- ^
Simulacra refers to a framing of the behaviour of large language models, in which they use simulated agentic behaviour with simulated goals to maximize predictive accuracy (e.g. when prompting GPT-3 to write a poem in the style of Robert Frost, it deploys a 'Robert Frost simulacra').
- ^
See for comparison Steve Byrnes' model [AF · GW], Yann LeCun's 'A path towards Autonomous Machine Intelligence.'
- ^
In practice, we probably won't want to do this, and instead have a set of operators to point at, and then follow some aggregation of their utility functions.
- ^
Again we should emphasize that this is heavily influenced by Vanessa’s IBP and PreDCA, and then changed by us into a different, much less rigorous proposal which lacks a lot of the important formalization Vanessa uses. We think this is worth doing because we are better able to analyze, understand and criticize our version.
- ^
Approximately equivalent to taking assumptions 1 and 2a from On the Feasibility of Learning Biases for Reward Inference.
- ^
- ^
One way of justifying these equations is to think of the whole "Utiliscope" as doing inference on a Bayes Net.
If we assume that we have a distribution over operator policies, and we know that the operator is more likely to have higher intelligence , we can infer a distribution over the utility function of the operator. This can be thought of as inference on the following Bayesian network:
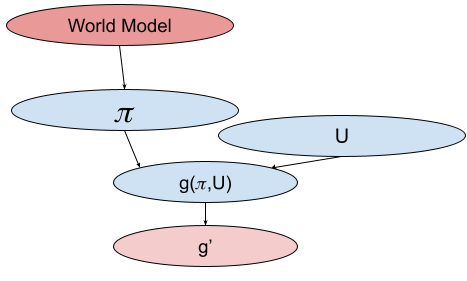
Each node is a random variable, where red means we have evidence about this variable, and blue is for latent variables. Each arrow is a functional relationship that we have prior knowledge about. We need to infer U, given our information about WM and .
is a deterministic function of and , and is the intelligence of the agent. We assume that we have a noisy observation about , called .
Writing out the equations for inferring the distribution over , we get:
If we assume that the likelihood of is exponential in the level of intelligence (strong prior knowledge that the operator has high ), we get:
and the prior over utility functions is a Solomonoff prior, then this becomes:
Realistically we would probably want the likelihood to increase fast for higher , but decrease after a certain point, to encode the knowledge that humans are intelligent agents, but not perfect agents.
- ^
Specifically, the agent's beliefs take the form of a homogeneous ultra-contribution over , your joint belief over computations and physics. The bridge transform, essentially, just checks if the agent's knowledge is consistent with a computation outputting something else (given a specific hypothesis over the universe). If it is consistent for the computation to output something else, then the computation didn't run, otherwise it did. See Infra-Bayesian Physicalism: a formal theory of naturalized induction [LW · GW] for more details.
- ^
The grain-of-truth problem shouldn't apply here, because we are not modeling the operator as optimal. This is what the intelligence measure gets around. There is still a problem as to priors.
- ^
The Legg-Hutter measure of intelligence (p23) does this, and it appears to be Vanessa's intention.
8 comments
Comments sorted by top scores.
comment by Lucius Bushnaq (Lblack) · 2022-08-23T14:32:46.133Z · LW(p) · GW(p)
Someone more versed in this line of research clue me in please: Conditional on us having developed the kind of deep understanding of neural networks and their training implicit in having "agentometers" and "operator recognition programs" and being able to point to specific representations of stuff in the AGIs' "world model" at all, why would we expect picking out the part of the model that corresponds to human preferences specifically to be hard and in need of precise mathematical treatment like this?
An agentometer is presumably a thing that finds stuff that looks like (some mathematically precise operationalisation of) bundles-of-preferences-that-are-being-optimised-on. If you have that, can't you just look through the set of things like this in the AI's world model that's active when it's say, talking to the operator, or looking at footage of the operator on camera, or anything else that's probably require thinking about the operator in some fashion, and point at the bundle of preferences that gets lit up by that?
Is the fear here that the AI may eventually stop thinking of the operator as a bundle-of-preferences-that-are-optimised-on, i.e. an "agent" at all, in favour of some galaxy brained superior representation only a superintelligence would come up with? Then I'd imagine your agentometer would stop working too, since it'd no longer recognise that representation as belonging to something agentic. So the formula for finding the operator utility function, which relies on the operator being in the set of stuff with high g your agentometer found, wouldn't work anymore either.
It kind of seems to me like all the secret sauce is in the agentometer part here. If that part works at all, to the point where it can even spit out complete agent policies for you to run and modify, like your formula seems to demand, it's hard for me to see why it wouldn't just be able to point you to the agent's preferences directly as well. The Great Eldritch Powers required for that seem, if anything, lesser to me.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-08-23T18:26:50.045Z · LW(p) · GW(p)
I see this proposal as reducing the level of deep understanding of neural networks that would be required to have an "agentometer".
If we had a way of iterating over every "computation" in the world model, then in principle, we could use the definition of intelligence above to measure the intelligence of each computation, and filter out all the low intelligence ones. I think this covers most of the work required to identify the operator.
Working out how to iterate over every computation in the world model is the difficult part. We could try iterating over subnetworks of the world model, but it's not clear this would work. Maybe iterate over pairs of regions in activation space? Of course these are not practical spaces to search over, but once we know the right type signature to search for, we can probably speed up the search by developing heuristic guided methods.
An agentometer is presumably a thing that finds stuff that looks like (some mathematically precise operationalisation of) bundles-of-preferences-that-are-being-optimised-on. If you have that, can't you just look through the set of things like this in the AI's world model that's active when it's say, talking to the operator, or looking at footage of the operator on camera, or anything else that's probably require thinking about the operator in some fashion, and point at the bundle of preferences that gets lit up by that?
Yeah this is approximately how I think the "operator identification" would work.
Is the fear here that the AI may eventually stop thinking of the operator as a bundle-of-preferences-that-are-optimised-on, i.e. an "agent" at all, in favour of some galaxy brained superior representation only a superintelligence would come up with?
Yeah this is one of the fears. The point of the intelligence measuring equation for g is that it is supposed to work, even on galaxy brained world model ontologies. It only works by measuring competence of a computation at achieving goals, not by looking at the structure of the computation for "agentyness".
it can even spit out complete agent policies for you to run and modify
These can be computations that aren't every agenty, or don't match an agent at all, or only match part of an agent, so the part that spits out potential policies doesn't have to be very good. The g computation is used to find among these the ones that best match an agent.
comment by Charlie Steiner · 2022-08-22T23:53:19.617Z · LW(p) · GW(p)
Nice post! You did an especially good job explaining equations - or at least, good enough for me to get what meant what :P
I also strongly agree with the claim that we should be thinking about aligning model-based reinforcement learning (or at least sorta-reinforcement-learning) agents.
If you read Reducing Goodhart [? · GW] you probably already know the rest of my take, but maybe I should write a simple post that just explains this one thing: we should model humans how they want to be modeled. Locating models of human-like objects in the world model that score highly according to agentiness and explanatory power is a great place to start your imagination, but it doesn't model humans how they want to be modeled[1].
Modeling humans how they want to be modeled requires feeding information about inferred human preferences back into the model-of-humans selection process itself. It also means that there can be an important distinction between the AI's most accurate model of the world (best for planning), and the AI's most human-centric model of the world (best for conforming to human opinions about how our preferences should be modeled)[2].
- ^
The criteria that pick out models in this post (and its relatives, including PreDCA or the example in post 2 of Reducing Goodhart) are simple and tractable, but they're not what I would pick if I had lots of time to interact with this AI, look at how it ends up modeling me, and build tools to help me target it at something I think really "gets me."
- ^
Or you could frame this a different way and figure out how to have the human-preferred structure "live inside" the most accurate model of the world.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-08-23T19:51:48.434Z · LW(p) · GW(p)
I love the idea of modeling humans how they want to be modeled. I think of this as like a fuzzy pointer to human values, that sharpens itself? But I'm confused about how to implement this, or formalize this process.
I hadn't seen your sequence, I'm a couple of posts in, it's great so far. Does it go into formalizing the process you describe?
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-08-25T00:39:37.551Z · LW(p) · GW(p)
Does it go into formalizing the process you describe?
Nope, sorry! I'm still at the stage of understanding where formalizing it would mean leaving in a bunch of parameters that hide hard problems (E.g. "a measure of how agent-shaped a model augmented with a rule for extracting preferences is" or "a function that compares plans of action in different ontologies."), so I didn't really bother.
But if you're around Lightcone, hit me up and we can chat and write things on whiteboards.
comment by Ramana Kumar (ramana-kumar) · 2022-08-23T15:41:09.549Z · LW(p) · GW(p)
Given a utility function ...
I might have missed it, but where do you get this utility function from ultimately? It looked like you were trying to simultaneously infer the policy and utility function of the operator. This sounds like it might run afoul of Armstrong's work, which shows that you can't be sure to split out the correctly from the policy when doing IRL (with potentially imperfect agents, like humans) without more assumptions than a simplicity prior.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2022-08-23T16:43:52.684Z · LW(p) · GW(p)
That's correct that it simultaneously infers the policy and utility function. To avoid the underspecification problem, it uses a prior that favors higher intelligence agents. This is similar to taking assumptions 1 and 2a from http://proceedings.mlr.press/v97/shah19a/shah19a.pdf
comment by simon · 2022-08-25T05:10:20.907Z · LW(p) · GW(p)
This architecture is quite similar (but much more fleshed out/detailed) to what I've been proposing in, e.g., "one possible alternative" towards the end of this comment [LW(p) · GW(p)].
One potential issue is that the AI needs to be choosing actions based on
a) the true utility function of humans which to the best of its current knowledge is represented by distribution X, but conditional on some other information A would be represented by some other distribution Y
and not based simply on
b) utility function distribution X which represents its current best knowledge of the true utility function of humans.
For example, imagine if the AI is deciding whether to wirehead all humans, so thoroughly that they will all remain in a comatose state until death. The AI thinks that there is a 60% chance humans would want this, and that conditional on wanting it they will want it by 100 utilons and conditional on not wanting it they will disapprove by -100 utilons.
The AI considers three actions:
1) wirehead the humans, expected value assessed as 20 utilons under either (a) or (b)
2) not wirehead the humans, expected value assessed as -20 utilons under either (a) or (b)
3) ask the humans at zero cost what they want, and do what they want, expected value assessed as (under a) 60 utilons or (under b) 4 utilons.
So, under (a), the AI will correctly ask humans what they want, and under (b) will self-modify to disable the utiliscope (or otherwise prevent the utility function from being updated) and then wirehead all humans in the face of our pleas to the contrary.
I think that your architecture with the utility function separated from the world-model results in (b), unless there's some mechanism to achieve (a) I'm not aware of. In my version, I am hoping that making the utiliscope be a pointer to a concept in the world model identified using interpretability tools, rather than extracting a utility function which is handled separately, might be able to achieve (a).
I also agree with Charlie Steiner's comment.