How (not) to choose a research project
post by Garrett Baker (D0TheMath), CatGoddess, Johannes C. Mayer (johannes-c-mayer) · 2022-08-09T00:26:37.045Z · LW · GW · 11 commentsContents
Background Takeaways Big ASS Tree Big ASS Takeaways Contact with reality What is the most important problem? Heuristics are useful, especially when you're first starting out Just because John says a project is "the best he's heard yet" does not mean it's any good Read Jaynes' "Probability Theory: The Logic of Science" Action space is large, bro John's hat is magic None 11 comments
Background
(specific information will be sparse here. This is meant to give context for the Takeaways section of the post)
Our group (Garrett, Chu, and Johannes) have worked with John Wentworth in the SERI MATS 2 Electric Boogaloo program for three weeks, meaning it's time for a Review & Takeaways Post!
First week was Project Selection, and the first day was spent thinking about strategies for coming up with good projects. We chose to find a general method for figuring out True Names [LW · GW] of mathy-feely-concepts-in-your-brain (such as roundness, color decomposition[1], or telling whether a piece of cloth is in a pile) with the goal that such a method would allow for figuring out true names for concepts like optimization, corrigibility, agency, modularity [LW · GW], neural network representations, and other alignment-relevant concepts.
Then we read Jaynes, and talked to TurnTrout [LW · GW], and concluded this project sucked. So we went back to Project Selection 2.0!
We came out of Project Selection 2.0 renewed with vigor, and a deeper understanding of the problems of alignment. Our new project was finding a better version of information theory by adapting logical induction or infra-Bayesianism [? · GW].
Then we talked to Eliezer Yudkowsky, he asked for a concrete example of how this would solve alignment, and we didn't have a good example. So we went to Project Selection 3.0.
We came out of Project Selection 3.0 with even more vigor, and an even deeper understanding of the problems associated with alignment... and a clever idea.
Finetuning LLMs with RL seems to make them more agentic. We will look at the changes RL makes to LLMs' weights; we can see how localized the changes are, get information about what sorts of computations make something agentic, and make conjectures about selected systems, giving us a better understanding of agency.
Nobody has convinced us this is a bad use of our time, though we'd like to see people try.
Takeaways
Big ASS Tree
We learned lots of things over the course of figuring out all our ideas sucked. During the project selection phase we had a cool idea for a way to generate project ideas: The Alignment Safety Search Tree (ASS Tree for short). The idea comes from Mazes and Duality [LW · GW]; the goal was to explore the space of problems and constraints before trying to propose solutions [LW · GW].
You start by writing "Alignment" up at the top of your whiteboard. This is the top level problem we want to solve. Then you draw arrows down. One for each problem, you can think of, that makes alignment hard. For each of these problems you repeat the process. E.g. for a problem P you draw down an arrow from P for each problem, that you can think of, that you need to solve, in order to solve P. Eventually you get a tree like this (except far bigger):
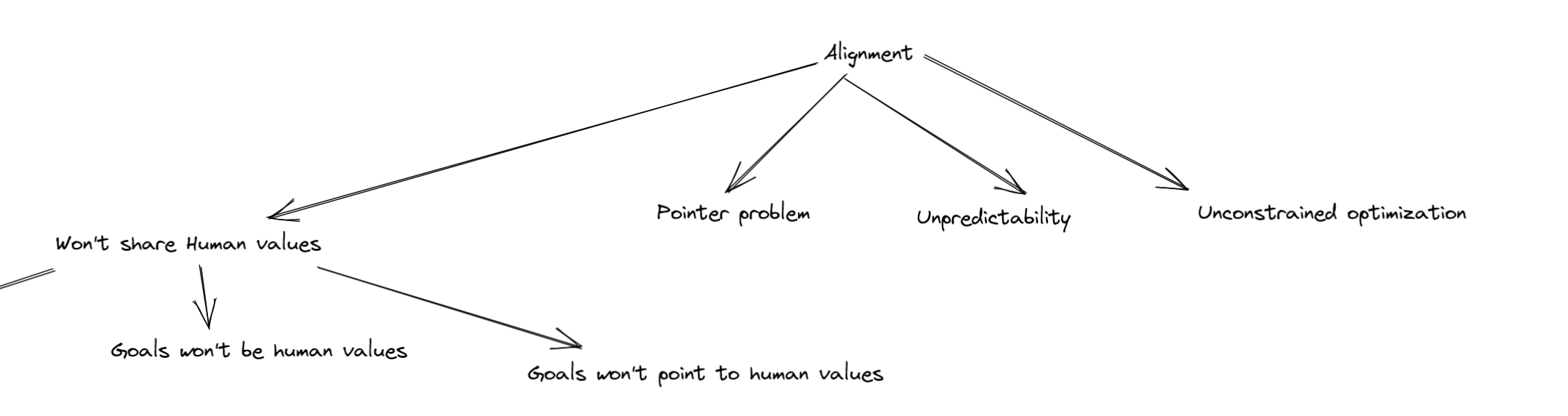
This is similar to what you do if you try to make an Alignment Game Tree [LW · GW]. However, in my opinion, when we tried to make the game tree during an early phase of the MATS program, it did not lend much insight into what to work on. The criticisms ended up being pretty proposal-specific, and most arguments were over whether a particular problem was actually a problem associated with the particular proposal.
For creating the ASS tree, each of us made a tree independently. Then we merged our individual ASS trees into one Big ASS Tree, and looked for the broader problems which lots of problems in the tree had in common. We then again extended the resulting tree individually and merged the results.
A common node in the tree was that we did not know the True name for some important concept (e.g. agency, optimization, value), and thus the True Names Project was born (finding a general procedure that you can use to find the True Name for some concept).
Big ASS Takeaways
ASS Trees and Big ASS Trees seem promising. However, I think we did not do the idea justice. We wanted to avoid anchoring to existing ideas, so we made the ASS tree without looking into previous alignment proposals and research directions.
In retrospect, though, we probably could've made a better tree if we'd looked at existing research, figured out what walls people empirically run into, and put those problems in the tree. We tentatively think the best way to use the ASS tree is to first make one before looking into other people's alignment work, and then make another one afterwards.
Contact with reality
Our first two project ideas did not lend themselves well to direct contact with reality, and what contact with reality they would have was largely mediated by humans. For instance, during the True Names project, we wanted to test our theories on True Name generation by having people use our methods to generate true names for toy concepts such as roundness and seeing how well they performed.
We could theoretically have done this well, but our weak information channels with reality would have made it very difficult to stay on track to producing something useful. In general, it's probably a bad sign if your technical alignment research looks a lot like psychology and academic philosophy.
What is the most important problem?
We started project selection phase trying to find the single most important problem in alignment, and then come up with good ways to gain information about that particular problem. We had difficulty with this approach, and could not readily generate ideas.
Given that our search tools (the ASS tree, combined with our low-certainty prior understanding of alignment) are pretty lossy, we couldn't be sure what the most important problem is - it's pretty hard to figure this out without actually doing research. Hence, we think a better approach to project selection would be to find the set of very-important-problems, and then come up with a clever idea to make progress on any of these problems.
Once we have a way to gain a rich stream of information about any important problem we can begin to do object-level work and get a feedback loop on what problems are most important, and what project ideas are useful. This is related to the previous section on keeping close contact with reality - the feedback loop works best when the project leverages information highly correlated with reality.
This advice applies less if you're already very certain that one problems is the most important by a large margin, or if you already have technical research experience.
Heuristics are useful, especially when you're first starting out
When you're first starting to do research, it's very difficult to figure out what actions are best; heuristics can be really helpful. We made a list of heuristics for project selection based on common wisdom in research and specific things we've been told by experienced researchers:
- Do something that actually helps solve alignment in the hard case; don't dodge the hard problem.
- Get a fast feedback loop.
- Do something that will make other alignment work easier (e.g. getting an algorithm that can find the concepts in a neural network and link them to objects in the real world).
- Do experiments that will give you a "firehose" of information. Try to avoid experiments that only yield a yes/no answer, or only produce one number.
- Work on something you find interesting - it's usually hard to do good work if you find your project boring.
- Try to exploit market inefficiencies. This is basically the same as the "neglected" criterion in the ITN framework. Of course, it could easily be argued that basically all of alignment is neglected, but we still think this is a worthwhile heuristic to keep in mind.
- Choose something that makes sense. When you try to explain a technical project to somebody and they say, "that makes no sense," it's easy to dismiss their confusion because your work is highly technical. However, oftentimes when people think your project makes no sense it actually makes no sense.
- Work on a concrete subproblem of your larger problem.
- Do something that will yield a lot of bits of information even if you fail. If your hypothesis is X, your experiments should ideally be informative even if X turns out to not true, or if X isn't even a sensible way to frame the situation.
- Hold off on proposing solutions. There is a standard reason [LW · GW] to not do this, but we think there's an even more important reason [LW · GW].
- Explore the degrees of freedom in your project, and make sure you've chosen the correct parameter settings before you go forward with the project. As a simple example, maybe you start out with a project proposal that involves working with large language models, but after looking at the degrees of freedom you realize it would be more informative to do a similar project with smaller toy models.
- Don't assume an ontology [LW · GW].
- Know what success looks like - what does it mean for your project to succeed? For instance, if you're trying to better understand optimization, maybe success is developing a method to determine how much optimization power a given agent is using in a way that matches with our intuitions.
We plan to regularly check in and make sure we're following all of these heuristics; given that we're very inexperienced at research, if we think we have reason to deviate from this list it seems more likely that we're either mistaken or deluded than that we've actually found a robust exception.
Just because John says a project is "the best he's heard yet" does not mean it's any good
When we posed the True Names project to John, he said it was "the best he's heard yet", which got us excited. But we later concluded it was a really silly thing to be working on.
Why did John say this? Several hypotheses come to mind.
- Was his brain not working right? We did ask him right before lunch, so maybe he was too hungry to think straight.
- Did he misunderstand us?
- Was he anticipating our project would suck, but wanted us to learn something about what projects are good or bad on our own? He might approve of thinking and working on the project as a learning experience, but not because it is a good project to make object level progress.
- Did he want to instill a lesson against blindly listening to your mentors?
The true solution is left as an exercise to the reader[2].
Read Jaynes' "Probability Theory: The Logic of Science"
It's good! And many insights in the history section led us to significantly change our course. The math is fancy, but you don't have to understand everything in order to gain many of the insights.
Action space is large, bro
After a week of project selection John dropped our names in his hat (along with some other people's) and drew names to generate random teams. We quickly found that the resulting teams were quite suboptimal; Garrett was on a team with a guy who was recovering from COVID and a fireman[3]. We were fairly resigned to this, and didn't realize we could move out of the local optimum until somebody pointed it out to us.
At this point we mutinied against John and asked for the teams to be rearranged into their current configuration; he agreed pretty readily.
John's hat is magic
Or at least, our emulation of his hat is magic. When Chu wears the hat and pretends to be John, she often comes up with better ideas than she otherwise would have. When we were generating our list of heuristics, we wrote down everything we could think of until we exhausted our ideas; Chu then put on the hat and added five ideas to our list within a few minutes.

On an unrelated note, we did a workshop a few weeks prior where people presented their ideas to John and we tried to predict what feedback he would give in advance.
- ^
That is, given color hex#D6E865 you may say this seems like a mix between yellow and green, and plausibly this notion can be formalized.
- ^
Or you can just look at this footnote! The answer (rot13): Guvf jnf nzbat gur svefg cebwrpgf va bhe pbubeg ur ybbxrq ng, naq gur bguref jrer rira jbefr.
- ^
Lit. He was too busy putting out fires in other projects to focus on alignment research.
11 comments
Comments sorted by top scores.
comment by Lucius Bushnaq (Lblack) · 2022-08-09T19:21:27.395Z · LW(p) · GW(p)
Finetuning LLMs with RL seems to make them more agentic. We will look at the changes RL makes to LLMs' weights; we can see how localized the changes are, get information about what sorts of computations make something agentic, and make conjectures about selected systems, giving us a better understanding of agency.
Nobody has convinced us this is a bad use of our time, though we'd like to see people try.
I'll give it a go.
"Agentiness" sounds like a probably pretty complex macro-level property of neural networks, at least to me. As in, the definition of the property seems to itself depend on other macro-level properties and structures in networks we don't really have decent operationalisations for either yet (e.g. "goals", "search processes").
I feel like we're still at the very beginning of theory in defining and identifying even very mathematically simple macro-level structures in neural networks. We can barely even quantify how much parts of a network interact with other parts of it.
So my guess would be that this sounds too hard to attack directly right now, unless you have some clever guesses already for what "agentiness" in networks looks like, or reason to suspect that "agentiness" is actually a mathematically far simpler property than one might naively think.
Otherwise, I fear your investigation will get lost in trying to identify which of the various changes the parameters of the LLM experience correspond to a change in "agentiness" levels, rather than a change in "capabilities", a change in "goals", a change in Moloch knows what, or just to random perturbations.
You could maybe try to control for that by doing lots of other experiments too, like looking at what happens to the parameters of an LLM already trained to be agenty if you train it again to achieve some other goal that doesn't require learning any new skills, to separate out goal changes. Or what happens to LLMs if they are finetuned to higher performance through methods that don't involve RL, to separate out capability changes. Or what happens to normal RL agents in the course of normal RL training.
If you combined the data from all of these and found good operationalisations for all the effects and concepts involved, maybe you could separate "agentiness" out from all the other stuff. But at that point, your project would be more like "soloing the Selection Theorems agenda".
(Which would be very cool if you actually pulled it off, of course)
Further, when it comes to understanding things about properties of neural networks, I don't feel like we've exhausted the low-hanging fruit from looking at very simple models yet. Those are also generally a lot easier and quicker to work with. So I think any time you consider looking at big fancy models to learn something, you should ask yourself if there isn't equally good progress to be made on your agenda by looking at small, dumb models instead.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-08-09T19:33:19.566Z · LW(p) · GW(p)
The first part of your criticism makes me more excited, not less. We have considered doing the variations you suggested, and more, to distinguish between what parts of the changes are leading to which aspects of behavior.
I also think we can get info without robust operationalizations of concepts involved, but robust operationalizations would certainly allow us to get more info.
I am not one to shy away from hard problems because they’re hard. Especially if it seems increasing hardness levels lead to increasing bits gleaned.
Which easier methods do you have in mind?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-08-09T19:45:40.665Z · LW(p) · GW(p)
I also think we can get info without robust operationalizations of concepts involved, but robust operationalizations would certainly allow us to get more info.
I think unless you're extremely lucky and this turns out to be a highly human-visible thing somehow, you'd never notice what you're looking for among all the other complicated changes happening that nobody has analysis tools or even vague definitions for yet.
Which easier methods do you have in mind?
Dunno. I was just stating a general project-picking heuristic I have, and that it's eyeing your proposal with some skepticism. Maybe search the literature for simpler problems and models with which you might probe the difference between RL and non-RL training. Something even a shallow MLP can handle, ideally.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-08-09T20:14:03.810Z · LW(p) · GW(p)
Good ideas! I worry that a shallow MLP wouldn't be capable enough to see a rich signal in the direction of increasing agency, but we should certainly try to do the easy version first.
I think unless you're extremely lucky and this turns out to be a highly human-visible thing somehow, you'd never notice what you're looking for among all the other complicated changes happening that nobody has analysis tools or even vague definitions for yet.
I don't think I'm seeing the complexity you're seeing here. For instance, one method we plan on trying is taking sets of heads and MLPs, and reverting them to their og values to see that set's qualitative influence on behavior. I don't think this requires rigorous operationalizations.
An example: In a chess-playing context, this will lead to different moves, or out-of-action-space-behavior. The various kinds of out-of-action-space behavior or biases in move changes seem like they'd give us insight into what the head-set was doing, even if we don't understand the mechanisms used inside the head set.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-08-09T20:39:50.140Z · LW(p) · GW(p)
I don't think I'm seeing the complexity you're seeing here. For instance, one method we plan on trying is taking sets of heads and MLPs, and reverting them to their og values to see that set's qualitative influence on behavior. I don't think this requires rigorous operationalizations.
That sounds to me like it would give you a very rough, microscope-level view of all the individual things the training is changing around. I am sceptical that by looking at this ground-level data, you'd be able to separate out the things-that-are-agency from everything else that's happening.
As an analogy, looking at what happens if you change the wave functions of particular clumps of silica atoms doesn't help you much in divining how the IBM 608 divides numbers, if you haven't even worked out yet that the atoms in the machine are clustered into things like transistors and cables, and actually, you don't even really know how dividing numbers works even on a piece of paper, you just think of division as "the inverse of multiplication".
comment by brooksshowell · 2022-08-09T16:42:51.836Z · LW(p) · GW(p)
The hat is a good example of enclothed cognition!
comment by wunan · 2022-08-10T00:41:26.944Z · LW(p) · GW(p)
The hat is another example of prompt engineering for humans. [LW · GW]
comment by Charlie Steiner · 2022-08-09T03:05:40.190Z · LW(p) · GW(p)
Yes! Mwahahaha! Soon you will be ready to overthrow the tyranny of the Hamming question, and usher in a new age of research motivated by curiosity and tractability!
comment by Jérémy Scheurer (JerrySch) · 2022-08-09T13:21:52.853Z · LW(p) · GW(p)
Finetuning LLMs with RL seems to make them more agentic. We will look at the changes RL makes to LLMs' weights; we can see how localized the changes are, get information about what sorts of computations make something agentic, and make conjectures about selected systems, giving us a better understanding of agency.
Could you elaborate on how you measure the "agenticness" of a model in this experiment? In case you don't want to talk about it until you finish the project that's also fine, just thought I'd ask.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2022-08-09T11:19:38.252Z · LW(p) · GW(p)
Cool post, thank you.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-08-09T01:23:07.392Z · LW(p) · GW(p)
Garrett gave me some of this advice at EAG SF. Good stuff!