How should DeepMind's Chinchilla revise our AI forecasts?
post by Cleo Nardo (strawberry calm) · 2022-09-15T17:54:56.975Z · LW · GW · 12 commentsContents
Introduction. The purpose of this report. What problem do I aim to solve? My contributions. DeepMind's Chinchilla Why care about scaling laws? Hoffman's Scaling Laws. Kaplan's Scaling Laws. How were recent LLMs trained? Recent LLMs were neither Kaplan-optimal nor Hoffman-optimal. Sevilla-extrapolated model Counterfactual histories. Hoffman-receptive model. How does Chinchilla revise our forecasts? 1. Shorter timelines via low-hanging fruit. 2. Maybe longer timelines? 3. Quicker exhaustion of data. 4. LLMs are "intelligent". 5. Biological Anchors model. 6. Shorter timelines via algorithmic innovation. 7. Data-rich tasks will be solved sooner than data-poor tasks. 8. The "Big Data" advantage Open questions What is the marginal cost of collecting data? Unpublished scaling laws None 12 comments
Acknowledgements: I wrote this report as part of a six-hour paid work-trial with Epoch AI.
Epistemic status: My dataset analysis is a bit simplistic but the inference I draw from it seems likely. The implications for TAI timelines, in descending order of confidence, are 3, 7, 8, 4, 1, 2, 5, 6.
Abstract:
AI forecasters seek to predict the development of large language models (LLMs), but these predictions must be revised in light of DeepMind's Chinchilla. In this report, I will discuss these revisions and their implications. I analyse a dataset of 45 recent LLM and find that previous LLMs were surprisingly trained neither Kaplan-optimally nor Hoffman-optimally. I predict that future LLMs will be trained Hoffman-optimally. Finally, I explore how these scaling laws should impact our AI alignment and governance strategies.
Introduction.
The purpose of this report.
What problem do I aim to solve?
In April 2022, DeepMind subverted the conventional understanding of how to train large language models.[1]
- They determined experimentally a new scaling law relating the loss of a LLM to the number of parameters in its architecture and the number of datapoints used in its training .
- From this scaling law they derived a formula for the optimal parameter-count and data-count for a given computational budget.
- They showed that recent LLMs had been trained with far too many parameters and far too little data.
- They trained their own LLM called Chinchilla according to their newly-discovered optimality conditions. Although Chinchilla used roughly as much compute as Gopher, it achieved a 7% improvement on the MMLU benchmark.
Chinchilla forces us to revise our predictions about the development of AI, but it's not immediately clear what these revisions should be. Should we update towards short timelines or long timelines? Should we update towards gradual take-off or sudden take-off? Should we update towards friendly AI or unfriendly AI?
My contributions.
There are three tasks I will attempt in my report:
1. I will discuss how previous LLMs were trained, and how future LLMs might be trained.
2. I will enumerate mechanisms by which Chinchilla should revise our forecasts.
3. My analysis will generalise to as-yet unpublished scaling laws. That is, I will build general methods for conditioning your forecasts on any given scaling law.
DeepMind's Chinchilla
Why care about scaling laws?
Imagine that you're an AI researcher pondering how best to train a LLM, and you've been granted a fixed computational budget of FLOPs. The budget will fix the value of because . You're stuck with a trade-off between and — you can't increase without also decreasing , and vice-versa.
Now, you want to find the values and which will yield the smallest loss of the trained model, but it's not obvious what these values should be. Should you train a 100B parameter model on 5% of the available data, or should you train a 10B parameter model on 50%?
You can find the answer if you know the relating to and . All you need to do is minimise along the frontier . Here, is the number of FLOPS required to train a model with a parameter-count of and a data-count of , which is approximately .
| Eq 1 |
Because it costs so much money to train large neural networks, an accurate scaling law can be very helpful, and an inaccurate scaling law might make you misappropriate millions of FLOP-dollars.
Hoffman's Scaling Laws.
Hoffman2022[1] finds the scaling law Eq 2 by training 400 networks with different values of and and fitting a parametric loss function. They then apply the minimisation Eq 1 to the scaling law Eq 2, to derive the optimal values for and in terms of , shown in Eq 3 and Eq 4.
They find that as increases, and should be scaled at approximately the same rate.
| Eq 2 | |
| Eq 3 | |
| Eq 4 |
Kaplan's Scaling Laws.
These results were unexpected! The widespread doctrine in the LLM community held that parameter-count should be scaled at a much faster rate than data-count. This doctrine was grounded in the following scaling laws found in Kaplan2020[2].
| Eq 5 | |
| Eq 6 | |
| Eq 7 |
Hoffman2022 falsified Kaplan's scaling laws Eq5-7, and overturned the parametrocentric doctrine.
They furthermore claimed that recent LLMs have been trained suboptimally. That is, if recent LLMs had been trained with fewer parameters, and instead been trained on a larger dataset, they would've achieved better performance at the same cost. Alternatively, these models could've been trained to achieve the same performance with far less cost. As a striking example, GoogleBrain spent approximately $12M to train a 540B-parameter model, and $9M was wasted on suboptimal training.[3]
In the next section I will investigate how LLMs were trained in the period between January 2018 and August 2022. Were they trained Kaplan-optimally or Hoffman-optimally?
How were recent LLMs trained?
Recent LLMs were neither Kaplan-optimal nor Hoffman-optimal.
Sevilla-extrapolated model
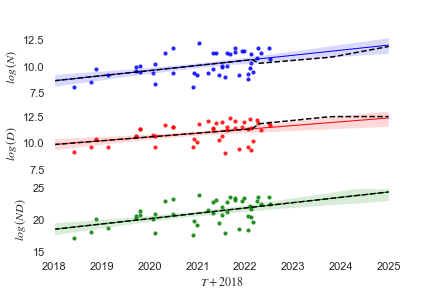
I will analyse the dataset of machine learning models compiled by Sevilla2021a[4]. This dataset includes 73 models in the language category that have been published between January 2018 and August 2022, and 45 of these entries include values for both and . Fig 1 shows the growth of , , and for language models in this period.
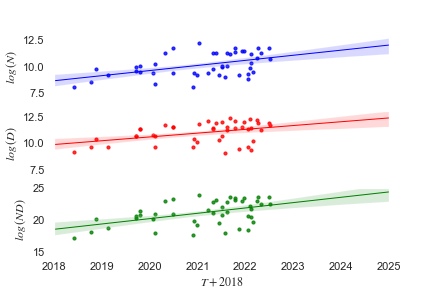
Firstly, I will use linear regression to determine the growth-rate of across time. I find the following empirical growth rates over the period 2018 to 2022, where is the number of years between January 1st 2018 and the publication date.
| Eq 8 | |
| Eq 9 | |
| Eq 10 |
I will refer to this as the "Sevilla-extrapolated model'', after the dataset Sevilla2021a[4].
Counterfactual histories.
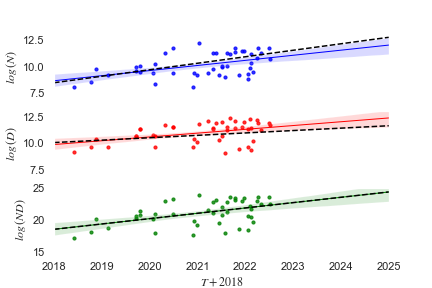
Now I will imagine two counterfactual histories, one where LLMs were trained exactly Kaplan-optimally and another where LLMs were trained exactly Hoffman-optimally. In both counterfactual histories, I will assume that grows exactly as in the Sevilla-extrapolated model, following Eq 8.
How would and have grown in these counterfactual histories?
Here are the growth-rates in the Kaplan-optimal counterfactual history:
| Eq 11 | |
| Eq 12 | |
And here are the growth-rates in the Hoffman-optimal counterfactual history:
| Eq 13 | |
| Eq 14 | |
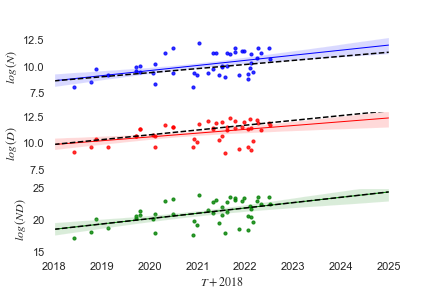
I conclude that the recent LLMs have been trained in accordance with neither Kaplan's scaling laws nor Hoffman's scaling laws, but rather an interpolation between these two trajectories.
This is somewhat surprising. Kaplan's scaling laws were widely accepted results in the community, so we might have expected recent LLMs to more closely fit the Kaplan-optimal counterfactual history.
In any case, I predict that the LLM community will shift their behaviour to Hoffman-optimality given that Hoffman2022 is now widely accepted.
Hoffman-receptive model.
The LLM community has been very receptive to Hoffman2022. The paper has been cited over 44 times and has been widely discussed online, which is typical for LLMs which achieve state-of-the-art performance. The majority opinion is that Kaplan's scaling laws were mistaken.
Here are four reasons for this majority opinion:
- In the Kaplan2020[2] experiments, LLMs were trained with a schedule where the learning rate decay doesn't depend on the total number of steps, but in practice, LLMs are never trained in this way.
- Because Kaplan’s scaling laws recommended that you don’t increase above 300B tokens, subsequent researchers didn't discover that increasing actually does improve performance.
This is a general drawback with scaling laws: if a scaling law is mistaken, then we might not discover that it's mistaken, because the law dissuades the very actions which would falsify it. - Kaplan's scaling law Eq 5 cannot hold in the limit as because there is irreducible entropy in the English language. For example, both "tomorrow is Monday'' and "tomorrow is Tuesday'' are positive-probability sentences.
In contrast, Hoffman's scaling law Eq 2 might hold in the limit , so long as the irreducible entropy of the English language is less than 1.69. - Finally, the proof is in the pudding. DeepMind trained a LLM according to their scaling laws and achieved better performance-per-compute than Kaplan2020[2] would've predicted.
It is therefore likely that future LLMs will be trained according to the revised scaling laws. In the Hoffman-receptive model, I assume that grows exactly as in the Sevilla-extrapolated model, following Eq 8, but I assume that and after April 2022.
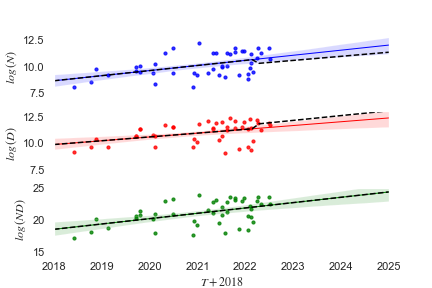
The Hoffman-receptive model differs from the model presented in Sevilla2021b[5], which extrapolates the historical growth-rate for parameter-count into the future. They justify this assumption with reference to Kaplan's scaling laws.
We chose to focus on parameter count because previous work indicates that it is an important variable for model performance Kaplan2020[2], because it helps as a proxy of model complexity and because it is information usually readily available or easily estimable from descriptions of model architecture.
Because Kaplan's scaling laws have been falsified by Hoffman's, Sevilla2021b's analysis should be amended. Compared with Sevilla2021b, the Hoffman-receptive model predicts that future LLMs will have fewer parameters — there will be a discontinuous drop in followed up by shallower growth. Likewise, the model predicts future LLMs will be trained on larger datasets — there will be a discontinuous jump in followed up by steeper growth.
In the next section I will briefly enumerate mechanisms by which Chinchilla might revise our forecasts. Some of these mechanisms are obvious, whereas others are surprising.
How does Chinchilla revise our forecasts?
1. Shorter timelines via low-hanging fruit.
According to Hoffman's scaling law, LLMs have been trained compute-suboptimally. Therefore LLMs can be improved imminently, without waiting for algorithmic innovation or an increase in the FLOP-budget . Therefore Hoffman2022 updates us towards shorter timelines.
2. Maybe longer timelines?
If we interpret the two opposing scaling laws Eq 2 and Eq 5 at face-value, Hoffman's is more pessimistic than Kaplan's.
Below I have plotted a heatmap of for various values of and
We can see that for the majority of the heatmap, . This area includes LLMs in the regime , whether the limit is approached along a Kaplan-optimal trajectory, along a Hoffman-optimal trajectory, or along a Sevilla-extrapolated trajectory.
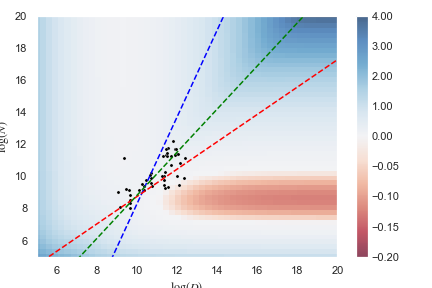
So shouldn't Hoffman202 update us towards longer timelines?
Not quite.
We know that Kaplan's scaling laws cannot hold in the limit as . Because Kaplan's scaling laws must fail in this regime, we cannot compare the two opposing scaling laws at face-value. The two scaling laws must be compared more cautiously, which is outside the scope of this report.
3. Quicker exhaustion of data.
Interestingly, Hoffman2022 might force us to predict faster growth for parameter-count and slower growth for data-count, under the plausible assumption that there is a limit to the amount of available data.
Suppose we were sure that is capped at a maximum value of 3.2T tokens. According to the Sevilla-extrapolated model, we expect , and so data would be exhausted in May 2025 ( = 7.37). Thereafter, would remain constant at 3.2T tokens, and all growth in would channel into growth in .
However, let's now consider a Hoffman-receptive future with a data maximum of 3.2T tokens: we expect and so data would be exhausted in December 2023 ( = 5.99). Thereafter, would remain constant at 3.2T tokens, and all growth in would channel into growth in .
Hence for the period between December 2023 and April 2025, the Hoffman-receptive model predicts a faster growth and a slower growth than the Sevilla-extrapolated model when both models are conditioned on a data limit of 3.2T.
4. LLMs are "intelligent".
Suppose that LLMs were just glorified lookup tables — i.e. they are only able to reduce loss by memorising data rather than by discovering genuine regularities that govern the data. Under this assumption, LLMs could achieve a lower loss only if they scale parameter-count and data-count approximately evenly because if the LLM is not compressing the data it would need twice the parameters to memorise twice the data.
On the other hand, if LLMs were just genuinely learning regularities in the data, then parameter-count would not need to scale with data . Instead parameter-count would scale with , where is the data compression ratio of the LLM. Because is smaller according to Hoffman's scaling laws than according to Kaplan's scaling laws, Hoffman2022 is evidence challenging the thesis that LLMs are glorified lookup tables, and supporting the thesis that LLMs are genuinely learning regularities.
5. Biological Anchors model.
Cotra2020[6] forecasts the arrival of Transformative AI by establishing "anchors'' between TAI and existing biological systems. For example, Cotra2020 "anchors'' the parameter-count in a TAI to the number of synapses in the human brain , and determines a timeline for TAI by extrapolating the current trajectory of until . If we use this biological anchor, then Hoffman2022 updates us towards longer timelines, because Hoffman's scaling laws predict slower growth for .
However we might instead "anchor'' the data-count used to train a TAI to the amount of data used to "train" the human brain.
We might anchor , the total data-count that a human experiences between the ages of 0 and 50. Or we might anchor , the total data-count of a human's evolutional lineage[7].
If we use these biological anchors, then Hoffman2022 updates us towards shorter timelines, because Hoffman's scaling laws predict faster growth for .
6. Shorter timelines via algorithmic innovation.
Hoffman2022 should update us towards significant algorithmic innovation in future LLMs. According to Hoffman's scaling laws, current LLMs are inefficient at learning from data, because a low loss requires a large data-count . But we know that the human brain is far more data-efficient, and so the data-efficiency of LLMs has a lot of room to improve, theoretically at least.
But this argument does not apply to Kaplan2020[2]. According to Kaplan's scaling laws, the inefficiency of current LLMs is not in their data-count but in their parameter-count. LLMs learn all they can from only 300B tokens, but need large parameter-count to improve significantly. However unlike data-efficiency, there is no biological analogy that suggests any possible improvement in parameter-efficiency, because the human brain has far more parameters than any existing LLM.
Therefore Hoffman2022 updates us towards shorter timelines.
7. Data-rich tasks will be solved sooner than data-poor tasks.
Hoffman2022 affects our relative timelines. Specifically, we should predict data-poor tasks will take relatively longer to solve, and data-rich tasks will take relatively shorter.
Consider for example the tasks in the Massive Multitask Language Understanding benchmark, presented in Hendrycks2020[8]. For some of these tasks, data can be generated indefinitely (e.g. "Elementary Mathematics''), but not for other tasks (e.g "Highschool Biology''). Therefore Hoffman2022 updates us towards more progress on the Elementary Mathematics task relative to the Highschool Biology task.
Worryingly, this shortens the timeline until an AI has mastered the task of AI capabilities research relative to the timeline until an AI has mastered the task of AI alignment research. Why? Because the AI capabilities literature is many orders-of-magnitude larger than the AI alignment literature. This is evidence against the hope that AI alignment research could meet the deadline that AI capabilities research imposes.
This concern could be mitigated by compiling and expanding a dataset of AI alignment research, as is found in Kirchner2022[9].
8. The "Big Data" advantage
nostalgebraist2022[10] estimates that the total number of tokens found in publicly-available text-based data is 3.2T. According to the Hoffman-receptive model, this data will be exhausted by 2024.
Thereafter, corporations and institutions attempting to develop AI will be strategically advantaged to the extent to which they can access non-public data. For instance, Facebook, Google, and Apple will be advantaged, whereas OpenAI, DeepMind, and EleutherAI will be disadvantaged.
Similarly, governments will be strategically advantaged to the extent of their willingness and power to seize data from their citizens. For instance, China will be advantaged, whereas the European Union will be disadvantaged.
This has important implications for AI governance. There are only a dozen actors with access to massive non-public text-based datasets, and these actors are known to each other. Because coordination is often easier among fewer actors, Hoffman2022 updates us towards coordination in AI governance[11].
In the next section I will pose two open questions which I might explore in forthcoming work.
Open questions
What is the marginal cost of collecting data?
Imagine you're an AI researcher pondering how best to train your LLM, and you've been granted a fixed financial budget of US dollars. You'll spend some of this money collecting data (web-scraping, buying the data from a third-party, generating the data automatically), and you'll spend some of this money on training. You want to find the values and with the smallest loss given your financial budget:
| Eq 15 |
Eq 15 is similar to Eq 1, except it includes a term representing the financial cost to collect a dataset of size (normalised to the cost of one FLOP). Eq 1 is a special case of Eq 15 where .
Throughout this report, I've assumed that is negligible compared to , and hence that compute is a good proxy for financial cost. However, as increases, it is likely that the marginal cost also increases, because all the easily-accessible tokens will be exhausted. Eventually, will be comparable with . In this "data-scarce'' regime, LLMs will not be trained compute-optimally, but rather cost-optimally. Specifically, LLMs will be trained with more parameters and less data than would be compute-optimal.
I have already considered in Fig 4 the cost-optimal trajectories for the following function.
In a forthcoming report I will estimate how might change as increases. The report will enumerate different sources of text-based data (e.g. publicly-accessible internet text, private social media messages, human conversations, etc), and for each data-source the report will estimate the cost-per-token and the total availability of the data. Those quantities will determine the function , and therefore determine the cost-optimal trajectories of and in the future.
Unpublished scaling laws
Here are two observations:
- Because it's so expensive to train LLMs, researchers are committed to finding accurate scaling laws. We've seen that with a better scaling law, GoogleBrain could've saved themselves $9M of their $12M budget!
- In the past two years, two contradictory scaling laws have been proposed — Kaplan2020[2] and Hoffman2022[1] — which signals to researchers that (1) mistakes can arise when determining scaling laws, and (2) correcting these mistakes is tractable.
These two observations suggest that researchers will continue to investigate scaling laws, and will publish those scaling laws in the coming months.
Will this make my report redundant? Hopefully not.
The analysis I present in this report can be generalised to any given scaling law , published or unpublished. The code would need to be re-run on and the figures would need to be updated. My discussion of the scaling law’s implications would likely generalise because I only appealed to whether the scaling law increases or decreases our estimates for and .
- ^
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. Training compute-optimal large language models, 2022. URL https://arxiv.org/abs/2203.15556.
- ^
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361.
- ^
GoogleBrain trained a LLM called "PaLM" with the following values:
According to Eq 2, PaLM would've achieved a loss of 1.94. This is the same loss for a model with the following values:
Note that is 25.1% of so 74.9% of the budget could've been saved.
Heim2022[12] estimates the cost of training PaLM lies between $9M and $23M.
- ^
Jaime Sevilla, Pablo Villalobos, Juan Felipe Cerón, Matthew Burtell, Lennart Heim, Amogh B Nanjajjar, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Jean-Stanislas Denain. Parameter, compute and data trends in machine learning, 2021a. URL https://docs.google.com/spreadsheets/d/1AAIebjNsnJj_uKALHbXNfn3_YsT6sHXtCU0q7OIPuc4/.
- ^
Jaime Sevilla, Pablo Villalobos, and Juan Felipe Cerón. Parameter counts in machine learning. https://epochai.org/blog/parameter-counts, 2021b. Accessed: 2022-08-17
- ^
Ajeya Cotra. Forecasting TAI with biological anchors, Sep 2020. URL https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines. [LW · GW]
- ^
What are and ?
Here are some upper-bound approximations:
= 100 000 words-per-day
2 tokens-per-word
365 days-per-year
50 years
= 5.48e6 tokens
= 100 000 words-per-day
2 tokens-per-word
365 days-per-year
2 million years
= 1.46e14 tokens
- ^
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2020. URL https://arxiv.org/abs/2009.03300.
- ^
Jan H. Kirchner, Logan Smith, Jacques Thibodeau, Kyle McDonell, and Laria Reynolds. Researching alignment research: Unsupervised analysis, 2022. URL https://arxiv.org/abs/2206.02841.
- ^
nostalgebraist. chinchilla’s wild implications, Jul 2022. URL https://www.alignmentforum.org/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications. [AF · GW]
- ^
I remember reading this point in a LessWrong comment, but I can't manage to find it.
- ^
Lennart Heim. Estimating palm’s training cost, 2022. URL https://blog.heim.xyz/palm-training-cost/.
12 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-09-16T09:06:32.428Z · LW(p) · GW(p)
The main update is to undermine confidence in the generality and utility of these 'Scaling Laws'. It's clear that the current LLM transformer recipe does not scale to AGI: it is vastly too data-inefficient. Human brains are a proof of concept that it's possible to train systems using orders of magnitude less data while simultaneously reaching higher levels of performance on the key downstream linguistic tasks.
Also there is now mounting evidence that these LLMs trained on internet scale data are memorizing all kinds of test sets for many downstream tasks, a problem which only gets worse as you try to feed them ever more training data.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-09-27T12:55:40.534Z · LW(p) · GW(p)
Also there is now mounting evidence that these LLMs trained on internet scale data are memorizing all kinds of test sets for many downstream tasks, a problem which only gets worse as you try to feed them ever more training data.
Not really? If we assume that they just memorize data without having intelligence, then their memory requirements would scale as N parameters, when instead we see a smaller constant for compression, which essentially requires actual intelligence rather than simply memorizing all that data.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-09-27T17:00:59.929Z · LW(p) · GW(p)
I didn't say they were simply memorizing, it's more complex than that: would need to look at the parameter scaling compression ratio vs data similarity/repetition, and compare to simpler SOTA compressors. Regardless of whether it's 'true' memorization or not, exposure to downstream task test sets distorts evaluations (this is already a problem for humans where many answers are available on the internet, it's just much more of a problem for AI that actually digests the entire internet).
comment by ESRogs · 2022-09-15T21:41:21.785Z · LW(p) · GW(p)
In a forthcoming report I will estimate how might change as increases. The report will enumerate different sources of text-based data (e.g. publicly-accessible internet text, private social media messages, human conversations, etc), and for each data-source the report will estimate the cost-per-token and the total availability of the data.
The analysis may be tricky to do, but I'd be particularly interested in seeing model-generated data included in this list. I suspect that in practice the way model-builders will get around the data limit is by generating (and curating) synthetic data.
(This doesn't have to involve the model just getting high on its own supply. If you build in an evaluation step before including generated data in the training set, then I'd bet you can effectively do AlphaZero-like IDA. I'm guessing that a lot of the action is going to be in figuring out how to set up the generation + evaluation algorithms.)
comment by ESRogs · 2022-09-15T21:33:51.354Z · LW(p) · GW(p)
For instance, Facebook, Google, and Apple will be advantaged, whereas OpenAI, DeepMind, and EleutherAI will be disadvantaged.
Nitpick: Google owns DeepMind, so it doesn't seem right to list DM on the disadvantaged side.
Replies from: strawberry calm, arabaga↑ comment by Cleo Nardo (strawberry calm) · 2022-09-15T22:09:49.203Z · LW(p) · GW(p)
Google owns DeepMind, but it seems that there is little flow of information back and forth.
Example 1: GoogleBrain spent approximately $12M to train PaLM, and $9M was wasted on suboptimal training because DeepMind didn't share the Hoffman2022 results with them.
Example 2: I'm not a lawyer, but I think it would be illegal for Google to share any of its non-public data with DeepMind.
comment by Felix Hofstätter · 2022-09-15T19:49:45.864Z · LW(p) · GW(p)
Very interesting, after reading chinchilla's wild implications [LW · GW] I was hoping someone would write something like this!
If I understand point 6 correctly, then you are proposing that Hoffman's scaling laws lead to shorter timelines because data-efficiency can be improved algorithmically. To me it seems that it might just as well make timelines longer to depend on algorithmic innovations as opposed to the improvements in compute that would help increase parameters. It feels like there is more uncertainty about if people will keep coming up with the novel ideas required to improve data efficiency compared to if the available compute will continue to increase in the near to mid-term future. If the available data really becomes exhausted within the next few years, then improving the quality of models will be more dependend on such novel ideas under Hoffman's laws than under Kaplan's.
↑ comment by Cleo Nardo (strawberry calm) · 2022-09-15T22:45:53.420Z · LW(p) · GW(p)
To me it seems that it might just as well make timelines longer to depend on algorithmic innovations as opposed to the improvements in compute that would help increase parameters.
I'll give you an analogy:
Suppose your friend is running a marathon. You hear that at the halfway point she has a time of 1 hour 30 minutes. You think "okay I estimate she'll finish the race in 4 hours". Now you hear she has been running with her shoelaces untied. Should you increase or decrease your estimate?
Well, decrease. The time of 1:30 is more impressive if you learn her shoelaces were untied! It's plausible your friend will notice and tie up her shoelaces.
But note that if you didn't condition on the 1:30 information, then your estimate would increase if you learned her shoelaces were untied for the first half.
Now for Large Language Models:
Believing Kaplan's scaling laws, we figure that the performance of LLMs depended on the number of parameters. But maybe there's no room for improvement in -efficiency. LLMs aren't much more -inefficient than the human brain, which is our only reference-point for general intelligence. So we expect little algorithmic innovation. LLMs will only improve because and grows.
On the other hand, believing Hoffman's scaling laws, we figure that the performance of LLMs depended on the number of datapoints. But there is likely room for improvement in -efficiency. The brain is far more -inefficient than LLMs. So LLMs have been metaphorically running with their shoes untied. There is room for improvement. So we're less surprised by algorithmic innovation. LLMs will still improve because and grows, but this isn't the only path.
So Hoffman's scaling laws shorten our timeline estimates.
This is an important observation to grok. If you're already impressed by how an algorithm performs, and you learn that the algorithm has a flaw which would disadvantage it, then you should increase your estimate of future performance.
↑ comment by Paradiddle (barnaby-crook) · 2022-09-16T10:00:43.436Z · LW(p) · GW(p)
This analogy is misleading because it pumps the intuition that we know how to generate the algorithmic innovations that would improve future performance, much as we know how to tie our shoelaces once we notice they are untied. This is not the case. Research programmes can and do stagnate for long periods because crucial insights are hard to come by and hard to implement correctly at scale. Predicting the timescale on which algorithmic innovations occur is a very different proposition from predicting the timescale on which it will be feasible to increase parameter count.
↑ comment by Matt Goldenberg (mr-hire) · 2022-09-15T23:10:24.779Z · LW(p) · GW(p)
This is an important observation to grok. If you're already impressed by how an algorithm performs, and you learn that the algorithm has a flaw which would disadvantage it, then you should increase your estimate of future performance.
It's not clear to me that this is the case. You have both found evidence that there are large increases available, AND evidence that there is one less large increase than previously. It seems to depend on your priors which way you should update about the expectance on finding future similar increases.