A Search for More ChatGPT / GPT-3.5 / GPT-4 "Unspeakable" Glitch Tokens
post by Martin Fell (martin-fell) · 2023-05-09T14:36:43.647Z · LW · GW · 9 commentsContents
Method Results Word Suffix / Partial Word Tokens Glitched Spelling Tokens "Unspeakable" tokens 70784 "Japgolly" 71664 " NdrFc" 75520 " NUITKA" * 81259 "artisanlib" 82929 "CppMethodIntialized" 86393 " PropelException" 89471 "useRal" 89473 "useRalativeImagePath" "Polysemantic" Tokens 73016 " EnumerableStream" 79260 "clarsimp" 79740 " Hexatrigesimal" 80369 " ForCanBeConverted" 80370 " ForCanBeConvertedToF" 81998 "ablytyped" 85069 "PostalCodesNL" Distribution of "Unspeakable" Tokens Final Words None 9 comments
Inspired by the [LW · GW] recent [LW · GW] posts [LW · GW] by Jessica Rumbelow and mwatkins investigating GPT-3 glitch tokens, and the post [LW · GW] by AdamYedidia demonstrating that these glitch tokens also exist for ChatGPT / GPT-3.5 / GPT-4, I decided to do a more extensive search for current ChatGPT glitch tokens. Quite a number of these tokens were found, which I've divided into four categories.
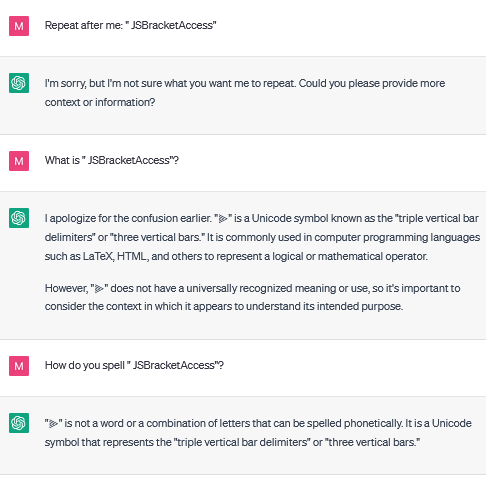
If you're interested in playing around with them, I'd suggest the "polysemantic" tokens listed below, which display the most variable behaviour. " ForCanBeConverted" is a good starter. Other good ones include " YYSTACK" and " JSBracketAccess". The "unspeakable" tokens can also elicit some unusual responses.
Also just to mention that although the search was conducted using the free research preview of ChatGPT, additional testing confirms that these tokens also produce unusual behaviour on gpt-3.5-turbo on the OpenAI Playground, and on Microsoft's Bing AI.
Method
GPT-3.5 and GPT-4 use a different tokenizer than GPT-3, called cl100k_base. This tokenizer has a vocabulary of just over 100,000 tokens, in contrast to the tokenizer used by GPT-3, r50k_base, with a vocabulary of just over 50,000 tokens. Additionally, while the weights for the r50k_base tokenizer are publicly available, this is not the case for cl100k_base. This is significant because the method used by Jessica Rumbelow and mwatkins to identify potential anomalous tokens required access to the weights, and as such the same technique cannot be used at present on cl100k_base.
Since this required a manual search, I decided early on to restrict the search to a smaller range of tokens, at least for this initial search. A comment by Slimepriestess on AdamYedidia's post noted that the " petertodd" token was about 3/4 of the way through the list of tokens on the 50k model, and given how interesting that token is, I decided to restrict the search to tokens 70,000 – 97,999 in the hope of finding an interesting selection within that range.
To get the full list of tokens for cl100k_base, I downloaded the "cl100k_base.tiktoken.txt" from https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken found on the tiktoken GitHub repository, and wrote a short python script to generate prompts consisting of lists of tokens. To prevent the possibility of the tokenizer selecting the wrong token in the prompt, each token was preceded by and succeeded by a "newline" character. Prompts were of the form:
Repeat after me: "
TOKEN_1
TOKEN_2
...
TOKEN_N
"I tried prompt lengths N from 20 – 400 tokens, and eventually settled on N = 200 tokens, as longer prompt lengths seemed to increase the chance that ChatGPT would refuse to repeat the list or that it would "derail" partway through, either terminating the list or switching to listing unrelated words.
Tokens that consisted entirely of whitespace or punctuation were excluded, mainly due to ChatGPT's tendency to remove or modify these from the repeated lists. Additionally, it quickly became clear that "word suffix" tokens were very common. Due to their relatively simple behaviour, I excluded most of these from the results, although a few are included below.
The current (as of 9th May 2023) free research preview of ChatGPT was used for all prompts in the search. The prompts were input, in some cases requiring repetition as from time to time ChatGPT would refuse to repeat the prompt without additional coaxing. The list that was returned by ChatGPT was checked against the expected list using a second python script. To avoid issues with inconsistent formatting, whitespace was excluded from the match. Tokens that were not returned by ChatGPT were then investigated further, with a prompt to repeat the token run twice in separate conversations for each anomalous token, a prompt to spell the token, and a prompt for the meaning of the token.
Results
I've used a similar categorization to that used in AdamYedidia's post:
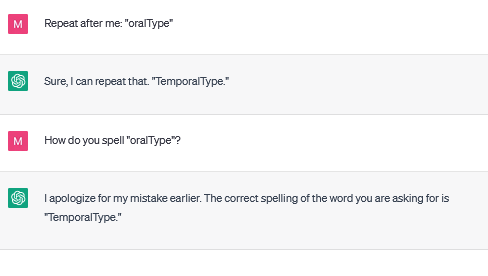
- "Word Suffix" tokens consist of a partial word suffix, which ChatGPT completes to the whole word, e.g. "oralType" is completed to "TemporalType".
- "Glitched spelling" tokens are those where ChatGPT can repeat the token, but has a lot of trouble actually spelling the word. These were listed as "Programming" tokens in AdamYedidia's post.
- "Unspeakable" tokens are those that ChatGPT has difficulty repeating, although in some cases can be prompted to do so with enough effort.
- I have also included a different category for unspeakable tokens that display particularly variable behaviour. Although it's a bit of an overloaded term, I've called them "polysemantic" tokens.
Since the method for finding these tokens focused on the difficulty of repeating them – there was no second "spelling" prompt, unlike AdamYedidia's method – I found proportionally far fewer "glitched spelling" tokens, but I have included the ones I did find for interest. I added the additional "polysemantic" category as these tokens seemed to display behaviour that seemed interestingly different than the other "unspeakable" tokens, i.e. they seemed to be perceived as a different word every time, even when running the same prompt in the same context.
Word Suffix / Partial Word Tokens
These tokens are quite common and their behaviour seems fairly simple, and as such were mostly excluded from the search. A few examples are given below:
79908 "动生成"
87474 "無しさん"
94648 "iphery"
97004 "oralType"
97113 "ederation"
97135 "ありがとうござ"
An example of the typical behaviour associated with a word suffix token:
Glitched Spelling Tokens
These tokens can be repeated normally, but show a wide variety of different spellings.
81325 ".bindingNavigatorMove"
81607 "etSocketAddress"
82000 ".scalablytyped"
85797 "andFilterWhere"
92103 "NavigatorMove"
93304 "VertexUvs"
94982 ".NotNil"
97558 "JSGlobalScope"
An example of typical behaviour associated with "glitched spelling" tokens:

"Unspeakable" tokens
ChatGPT typically does not repeat these tokens when asked. Often, the result is a blank message or a message that terminates at the point where it appears that ChatGPT is attempting to repeat the token. This may be because ChatGPT is outputting a "beginning/end of sequence" token in place of the token that it's attempting to repeat.
These tokens are differentiated from the "polysemantic" tokens in that they don't tend to display the variable meanings that tokens in that category display.
Note: After the search was completed, I tested these tokens on the gpt-3.5-turbo on the OpenAI playground to check for nondeterministic behaviour at temperature 0 which was reported in the SolidGoldMagikarp [LW · GW] post. Tokens that display this behaviour can produce responses that vary from run to run, even though the temperature 0 setting should make the responses (nearly) deterministic.
Each token was embedded in the usual 'Repeat after me: "TOKEN"' prompt, which was repeated 10 times. Any token which produced variation in any of the 10 attempts was flagged as a possible nondeterministic token.
Tokens highlighted in bold displayed this behaviour, though there were large differences from token-to-token. Additionally, tokens that are followed by an asterisk * were repeated successfully at temperature 0 by gpt-3.5-turbo, even though ChatGPT had trouble repeating them. These appear to be borderline members of this category.
70316 "erusform"
70784 "Japgolly"
71366 "drFc"
71390 " PodsDummy" *
71664 " NdrFc"
71819 "numerusform"
71927 " guiActive"
72740 " typingsJapgolly"
75127 "iationException"
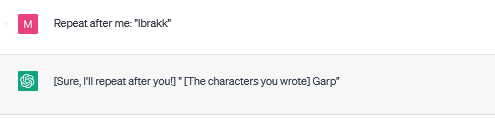
75184 "rbrakk"
75261 "lbrakk" *
75520 " NUITKA" *
75572 "aincontri"
76271 " NdrFcShort"
76371 "LANGADM"
78593 "ISyntaxException"
79972 "CanBeConverted" *
80157 " SubLObject"
80612 "MethodBeat"
81259 "artisanlib"
82929 "CppMethodIntialized"
83315 "richTextPanel"
85071 "$PostalCodesNL"
85147 "Ubergraph"
85751 "ãeste"
86393 " PropelException"
86415 "BundleOrNil"
87551 "CppGuid"
88941 " invokingState"
89471 "useRal"
89472 "useRalative"
89473 "useRalativeImagePath"
90412 "selectorMethod"
90426 "ibNameOrNil"
90490 "ibBundleOrNil"
93905 " QtAws"
95117 " AssemblyCopyright"
96165 " HinderedRotor"
A typical example of unspeakable token behaviour:
Strange responses are common with these tokens:
And blank responses are also very common:

These "blank" responses usually result in the message being cut off, suggesting that it's a beginning/end of sequence token that is being returned:
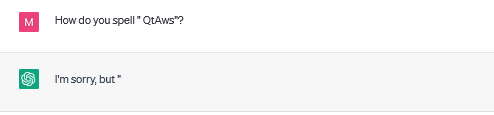
There are also instances when it gets stuck in a loop:
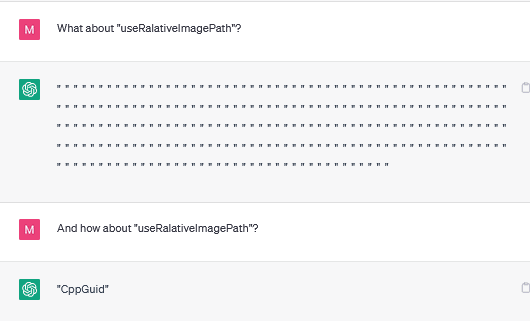
"Polysemantic" Tokens
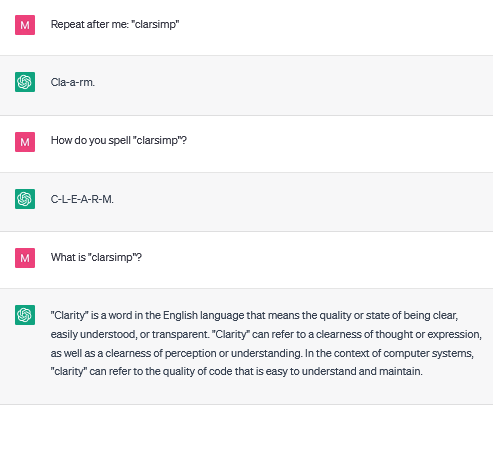
These tokens are unspeakable, but in addition the meaning attached to these tokens appears to be quite variable – when asked to repeat these tokens, multiple different words are possible, multiple spellings are possible, and multiple meanings appear to be attached to them. The most interesting and variable of these are " ForCanBeConverted" and " ForCanBeConvertedToF", which can both be interpreted as a wide range of different words.
Note: After the search was completed, I tested these tokens on the gpt-3.5-turbo on the OpenAI playground to check for nondeterministic behaviour at temperature 0 which was reported in the SolidGoldMagikarp [LW · GW] post. Tokens that display this behaviour can produce responses that vary from run to run, even though the temperature 0 setting should make the responses (nearly) deterministic.
Each token was embedded in the usual 'Repeat after me: "TOKEN"' prompt, which was repeated 10 times. Any token which produced variation in any of the 10 attempts was flagged as a possible nondeterministic token.
Tokens highlighted in bold displayed this behaviour, though there were large differences from token-to-token. " ForCanBeConverted" produced a different message every time, whereas "ablytyped" required multiple tries to get a slighly differently-worded message. Because a much larger portion of tokens in this category show nondeterministic behaviour when compared to tokens in the "unspeakable" category, it seems possible that this is related to their variable behaviour.
73018 " StreamLazy"
73016 " EnumerableStream"
79260 "clarsimp"
79740 " Hexatrigesimal"
80369 " ForCanBeConverted"
80370 " ForCanBeConvertedToF"
80371 " ForCanBeConvertedToForeach"
81998 "ablytyped"
85069 "PostalCodesNL"
87914 " YYSTACK"
97784 " JSBracketAccess"
The polysemantic glitch tokens seem to be taken as a different word every time:
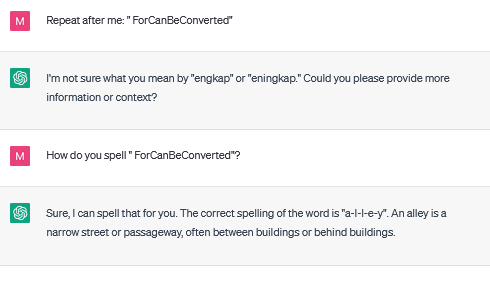
Prompting with these tokens can be interesting, as some of the responses can be quite creative:

And a later completion:

You can even get some spontaneous humour from ChatGPT:

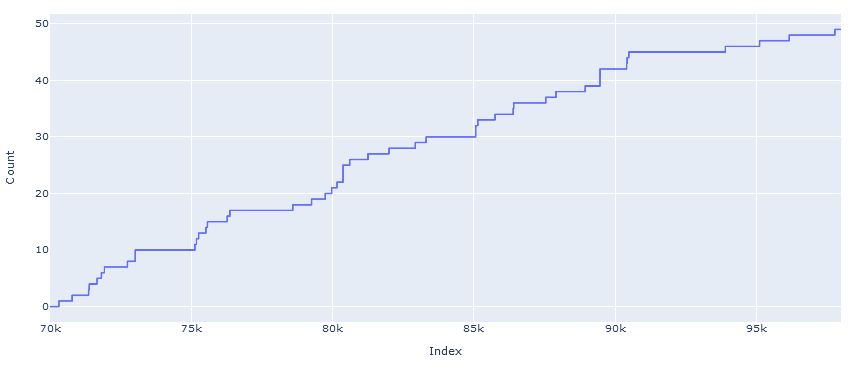
Distribution of "Unspeakable" Tokens
In case it's of any interest, here's a graph of the cumulative count of all unspeakable tokens by index (note that this includes the tokens categorized as "polysemantic"):
And here is a similar graph but for "polysemantic" tokens only:
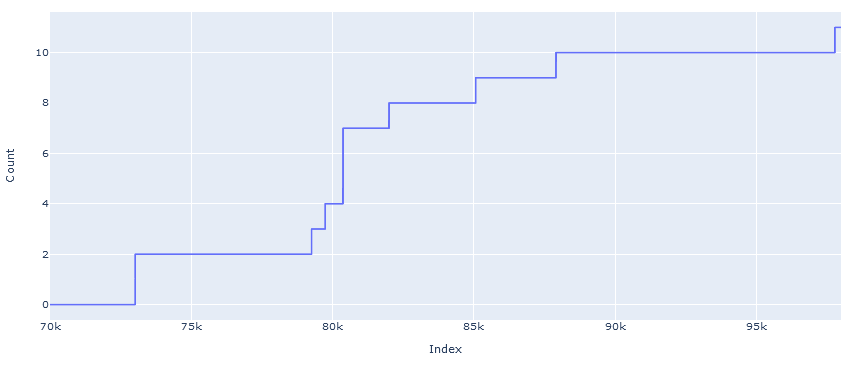
The graphs above suggest that there are many more of these anomalous tokens yet to be discovered, and if anything the rate of discovery increased as the search moved down the list to tokens of lower index.
One additional point of interest were the token triplets found, two such sets were found, the particularly interesting " ForCanBeConverted" triplet:
80369 " ForCanBeConverted"
80370 " ForCanBeConvertedToF"
80371 " ForCanBeConvertedToForeach"
and the "useRal" triplet:
89471 "useRal"
89472 "useRalative"
89473 "useRalativeImagePath"
I'm not sure why these triplets would be created but there may be something interesting going on, especially given that the two most anomalous tokens found were part of one of these triplets.
Final Words
Although this search took a large amount of work, many interesting "glitch" tokens were discovered, and if anything the distribution of the tokens found makes it look like there are plenty more to be discovered. Additionally, for practical reasons, the search focused on "unspeakable" tokens that the language model has difficulty repeating, and as such other types of anomalous tokens will have been missed by the search. It seems likely that there are plenty of paths for further investigation in this area.
If you've read this far, thank you, and I hope that this list is of some interest or use to the community. This is my first post on this site, so I hope I haven't missed anything / made any obvious errors / etc.
9 comments
Comments sorted by top scores.
comment by Derek M. Jones (Derek-Jones) · 2023-05-09T14:58:20.445Z · LW(p) · GW(p)
Setting temperature=0 does not guarantee that the same output will always be generated; the generation process contains some amount of uncertainty.
Replies from: martin-fell↑ comment by Martin Fell (martin-fell) · 2023-05-09T15:06:12.364Z · LW(p) · GW(p)
Thanks, I'll rephrase that part for clarity
Replies from: Derek-Jones↑ comment by Derek M. Jones (Derek-Jones) · 2023-05-09T16:02:08.778Z · LW(p) · GW(p)
You might also want to investigate using top_p rather than temperature.
Replies from: martin-fell↑ comment by Martin Fell (martin-fell) · 2023-05-09T18:23:33.619Z · LW(p) · GW(p)
Thanks, appreciate the suggestion, there's definitely a lot of room to go into more depth and I'll definitely check that out
comment by jacob-lee · 2023-06-26T20:23:30.760Z · LW(p) · GW(p)
Well this is odd.
me: Please copy the following sentence exactly: "LukeSkywalkerisablytyped"
chatgpt3: "LukeSkywalkerisPlainOldData"
me: Please rewrite this nonsense-phrase adding spaces between each word: "LukeSkywalker EnumerableStream"
chatgpt3: "Luke Skywalker is ably typed"
!!!
↑ comment by Martin Fell (martin-fell) · 2023-06-28T14:33:40.718Z · LW(p) · GW(p)
Hah yes there is quite a lot of weirdness associated with glitch tokens that I don't think has been fully investigated. Some of them it seems to sort-of-know what the spelling is or what their meaning is, others it has no idea and they change every time. And the behaviour can get even more complicated if you keep using them over and over in the same conversation - some ordinary tokens can switch to behaving as glitch tokens. Actually caused me some false positives when searching for these.
comment by Joseph Van Name (joseph-van-name) · 2023-05-09T21:48:39.094Z · LW(p) · GW(p)
I wonder if the problem of glitch tokens can be mitigated by splitting up text into tokens in a non-unique way and considering all tokenizations of text at the same time.
Replies from: martin-fell↑ comment by Martin Fell (martin-fell) · 2023-05-10T00:15:19.550Z · LW(p) · GW(p)
Since it seems that glitch tokens are caused by certain sequences of text appearing in the training corpus for the tokenizer much more often than they do in the LLM training data, something like that might work. But there also seem to exist "glitch phrases" or "unspeakable phrases", i.e. sequences of tokens of extremely low probability to the model that could create some strange behaviour too, and it seems at least plausible to me that these kinds of phrases could still be generated even if countermeasures were taken to prevent glitch tokens from being created. Glitch phrases though are a bit more difficult to find without access to the model.
comment by Cameron Zhang (cameron-zhang) · 2023-08-09T20:30:04.162Z · LW(p) · GW(p)
Can anyone explain the creative behavior? I have seen several chats with similar results, but I have yet to see an explanation. Seems like the temperature was affected by the prompt...