Why I don't believe in the placebo effect
post by transhumanist_atom_understander · 2024-06-10T02:37:07.776Z · LW · GW · 22 commentsContents
Examples: Depression Example: The common cold The status of the placebo effect in science None 22 comments
Have you heard this before? In clinical trials, medicines have to be compared to a placebo to separate the effect of the medicine from the psychological effect of taking the drug. The patient's belief in the power of the medicine has a strong effect on its own. In fact, for some drugs such as antidepressants, the psychological effect of taking a pill is larger than the effect of the drug. It may even be worth it to give a patient an ineffective medicine just to benefit from the placebo effect. This is the conventional wisdom that I took for granted until recently.
I no longer believe any of it, and the short answer as to why is that big meta-analysis on the placebo effect. That meta-analysis collected all the studies they could find that did "direct" measurements of the placebo effect. In addition to a placebo group that could, for all they know, be getting the real treatment, these studies also included a group of patients that didn't receive a placebo.
But even after looking at the meta-analysis I still found the situation confusing. The only reason I ever believed in the placebo effect was because I understood it to be a scientific finding. This may put me in a different position than people who believe in it from personal experience. But personally, I thought it was just a well-known scientific fact that was important to the design of clinical trials. How did it come to be conventional wisdom, if direct measurement doesn't back it up? And what do the studies collected in that meta-analysis actually look like?
I did a lot of reading to answer these questions, and that's what I want to share with you. I'm only going to discuss a handful of studies. I can't match the force of evidence of the meta-analysis, which aggregated over two hundred studies. But this is how I came to understand what kind of evidence created the impression of a strong placebo effect, and what kind of evidence indicates that it's actually small.
Examples: Depression
The observation that created the impression of a placebo effect is that patients in the placebo group tend to get better during the trial. Here's an example from a trial of the first antidepressant that came to mind, which was Prozac. The paper is called "A double-blind, randomized, placebo-controlled trial of fluoxetine in children and adolescents with depression".
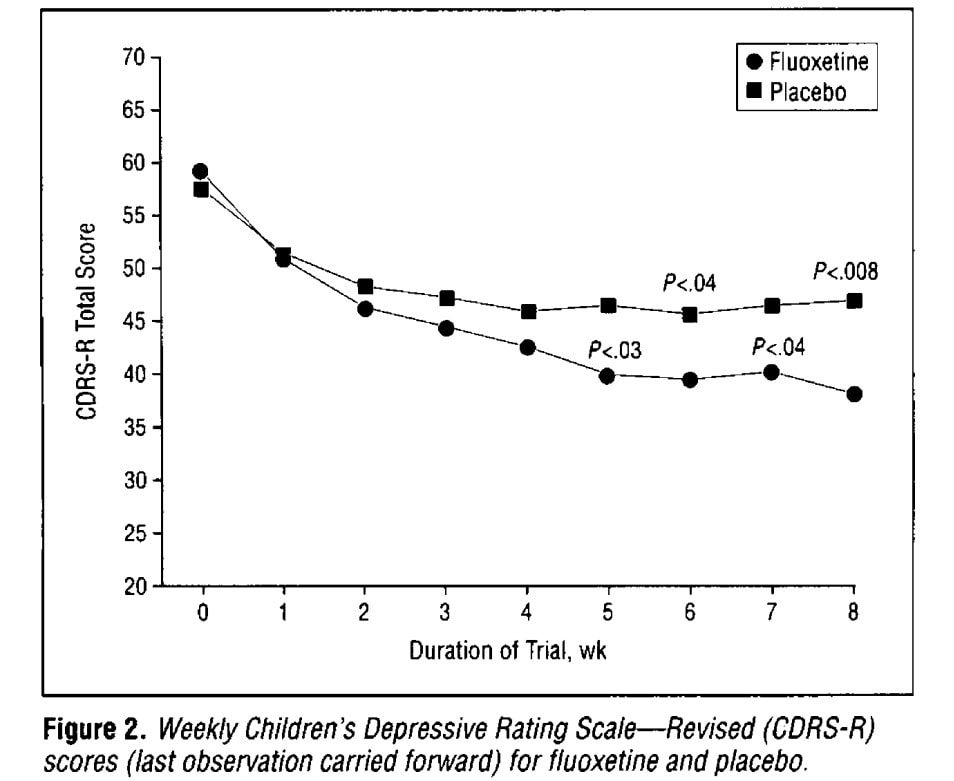
In this test, high scores are bad. So we see both the drug group and the placebo group getting better in the beginning of at the beginning of the trial. By the end of the trial, the scores in those two groups are different, but that difference is not as big as the drop right at the beginning. I can see how someone could look at this and say that most of the effect of the drug is the placebo effect. In fact, the 1950s study that originally popularized the placebo effect consisted mainly of these kind of before-and-after comparisons.
Another explanation is simply that depression comes in months-long episodes. Patients will tend to be in a depressive episode when they're enrolled in a trial, and by the end many of them will have come out of it. If that's all there is to it, we would expect that a "no-pill" group (no drug, no placebo) would have the same drop.
I looked through the depression studies cited in that big meta-analysis, but I didn't manage to find a graph precisely like the Prozac graph but with an additional no-pill group. Here's the closest that I found, from a paper called "Effects of maintenance amitriptyline and psychotherapy on symptoms of depression". Before I get into all the reasons why this isn't directly comparable, note that the placebo and no-pill curves look the same, both on top:
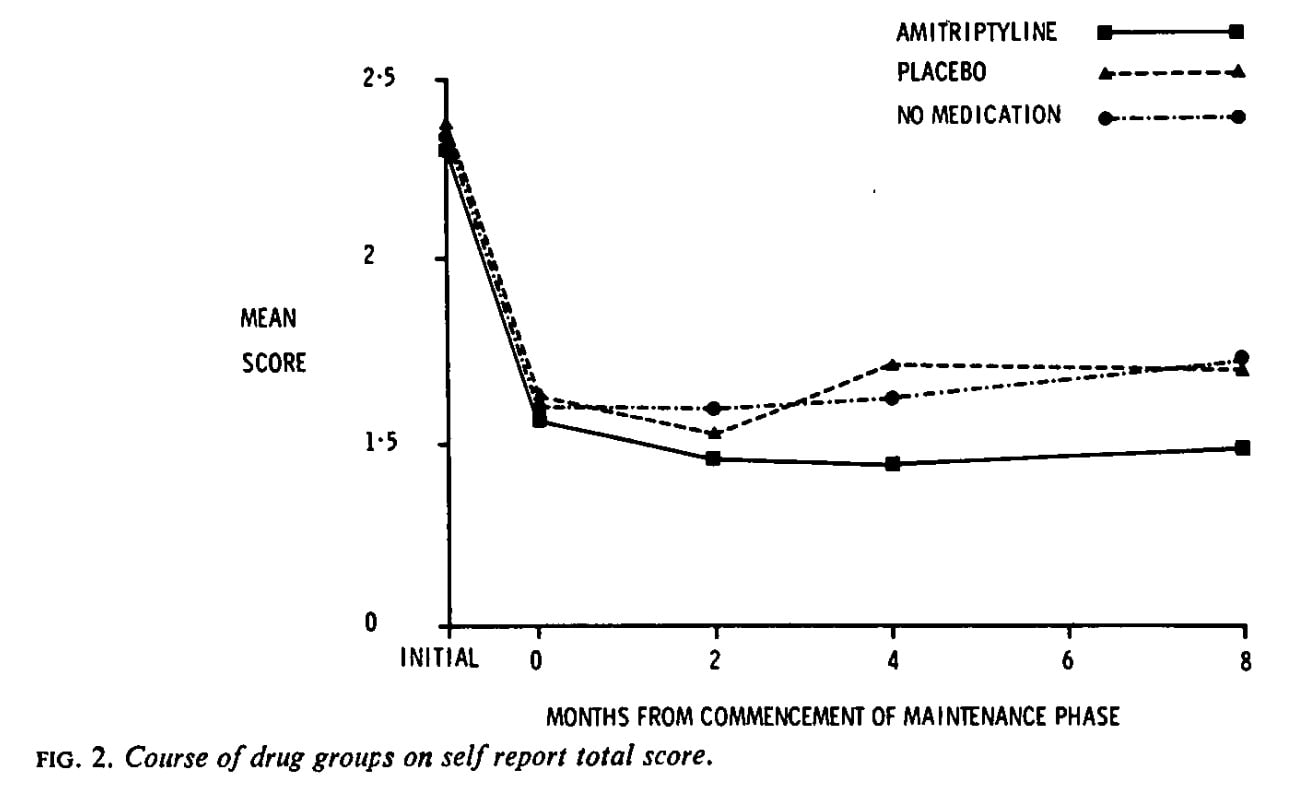
The big difference is that this is trial is testing long-term "maintenance" treatment after recovery from a depressive episode. The 0 to 8 on the x axis here are months, whereas in the Prozac trial they were weeks. And we can't interpret that drop at all, not only because everyone got the drug during that period before being randomized to these three groups, but also because those that didn't get better weren't included in the trial.
But still, look at how the drug group is doing better at the end, whereas the placebo and no-pill groups look about the same. Nobody would look at this and say the drug effect is mostly placebo effect. In fact there is no clear placebo effect at all. But this is the direct comparison, the one where we ask what would happen if the placebo were not given.
This is the kind of evidence that is collected in that big meta-analysis. There's a few depression studies like this with drug, placebo, and no-pill groups, and they give the same impression. The meta-analysis isn't limited to drugs, though, or placebo pills. For example, in a trial of the effect of bright light, the placebo was dim light.
If you look at the abstract of the meta-analysis, it says that there was no statistically significant placebo effect in depression. When Scott wrote about this, he was surprised that there were statistically significant effects for pain and nausea, but not for depression. I think I can clear this up.
On my reading, the meta-analysis found a measurable placebo effect for nausea, pain, and depression, all of about the same size. To see that, let's look at the estimates of effect size and the confidence intervals, copied from their "Summary of Findings" table. Don't worry about the units of the effect yet, I'll get to that.
| Outcomes | Effect (SMD) | 95% CI | Significant? |
| All clinical conditions | ‐0.23 | ‐0.28 to ‐0.17 | Yes |
| Pain | ‐0.28 | ‐0.36 to ‐0.19 | Yes |
| Nausea | ‐0.25 | ‐0.46 to ‐0.04 | Yes |
| Depression | ‐0.25 | ‐0.55 to 0.05 | No |
The effect on depression is not statistically significant because the confidence interval includes zero. But if you instead ask whether depression is different from the other conditions, the answer is even more clearly no. A classic case of "The Difference Between "Significant" and "Not Significant" is not Itself Statistically Significant". As for why depression had a wider confidence interval, I'll note that there were far more studies on pain, and the studies on nausea had more consistent results.
Now, are these effect sizes big or small? These are standardized mean differences (SMD) between the placebo and no-treatment groups. Roughly, an SMD of 1 means that the difference between group averages was the same as the typical difference of a group member from its own group's average. More precisely:
So it looks like getting a placebo does decrease the depression score. Maybe that decrease is about a quarter of the size of the variation within a group. Maybe more, maybe less. But it's probably not nothing.
To get a sense of scale for that number, I wanted to see how it compared to antidepressants. So I looked at another meta-analysis: "Antidepressants versus placebo for depression in primary care". I put their SMD in a table, along with some numbers from the placebo meta-analysis:
| Comparison | Effect (SMD) | 95% CI |
| Drug vs placebo (depression) | -0.49 | -0.67 to -0.32 |
| Placebo vs no treatment (depression) | -0.25 | -0.55 to 0.05 |
| Placebo vs no treatment (all conditions, patient-reported) | -0.26 | -0.32 to -0.19 |
| Placebo vs no treatment (all conditions, observer-reported) | -0.13 | -0.24 to -0.02 |
So, while I don't believe that the effect of a placebo on depression scores is really zero, I doubt that it's really the same size as the effect of a drug, compared to placebo. So I don't believe, as some have said, that the effect of antidepressant drugs is mostly placebo effect. Still, it's not like it's an order of magnitude difference, is it?
But now I think we have to interpret what these "effects" on depression scores really are. Is there a "placebo effect" on the condition of depression, or merely how depression is reported? That's why I included the breakdown into patient-reported and observer reported effects (for all conditions). It does seem that the "placebo effect" is smaller when reported by a medical professional, who I would hope is more objective than the patient. But we're on risky ground here now, interpreting estimates with overlapping confidence intervals.
When I first began to doubt the conventional wisdom about the placebo effect, I didn't look at depression. I wanted to look first at a disease that seems more "physical", less subjective. And I remembered, doesn't Robin Hanson have some evolutionary psychology theory to explain why placebos activate the immune system? What was that about?
Example: The common cold
The Robin Hanson post was inspired by a New Scientist article which made an intriguing claim:
Likewise, those people who think they are taking a drug but are really receiving a placebo can have a [immune] response which is twice that of those who receive no pills (Annals of Family Medicine, doi.org/cckm8b).
The study is called "Placebo Effects and the Common Cold: A Randomized Controlled Trial". It doesn't actually say that placebos double the immune response. But it's worth a closer look, both to quantify the placebo effect outside of mental illness, and because this miscommunication is an interesting case study in how belief in the placebo effect has been maintained.
If you didn't see "Placebo" in the title, you would think this was a trial of echinacea. There were the two groups you would expect in such a trial: patients randomly assigned to either echinacea or placebo, without knowing which. But there were another two groups: a no-pill group, and an open-label echinacea group. Patients were also asked whether they've taken echinacea before and whether they believe it worked, and there was a separate analysis of the believers.
The study did, as indicated in the New Scientist article, measure immune response. The immune response was quantified by testing a nasal wash for the molecule IL-8, and for neutrophils, a kind of white blood cell. There were no statistically significant differences in these measurements. Even if we're willing to interpret differences that aren't statistically significant, I can't see any measure that's twice as high among the patients that got a pill. Not even in the subgroup of patients that believed in echinacea. I think the New Scientist article is just wrong.
But with the paper now in hand, let's look at the "conclusion" section of the abstract:
Participants randomized to the no-pill group tended to have longer and more severe illnesses than those who received pills. For the subgroup who believed in echinacea and received pills, illnesses were substantively shorter and less severe, regardless of whether the pills contained echinacea. These findings support the general idea that beliefs and feelings about treatments may be important and perhaps should be taken into consideration when making medical decisions.
Also a very interesting claim, but we have to narrow it down. There were two "primary outcomes", duration and severity. In the full sample, none of the comparisons mentioned in the quote were statistically significant. I guess the reviewers were fine with stating these as conclusions, despite not reaching statistical significance.
However, there was a statistically significant difference in duration of illness among the echinacea-believers. Comparing the no-pill group to those that received a pill (placebo or echinacea, open-label or blinded), those receiving a pill had shorter illnesses, with a confidence interval from 1.31 to 2.58 days shorter.
I want to stress that we have left behind the laboratory measurements and are again relying on self-reports. "Illness duration" was measured by asking the patient each day whether they think they still have a cold. This study has convinced me that people who say echinacea worked for them in the past, given pills that might be echinacea, tend to say "no" a couple days earlier. Whether that's an effect of the pill on the immune response, or just on the self-report, you have to interpret.
The status of the placebo effect in science
One thing I learned reading all this is that a "powerful placebo" really is a widespread belief among scientists and doctors. The "conventional wisdom" that placebo effects are not only real, but can be as big as drug effects, isn't just a misconception among the public.
But there does not seem to be a consensus on the issue. Some do believe in a "placebo effect" in the sense of a psychologically mediated effect on the condition. Others explain improvement in the placebo group as regression to the mean (which includes as a special case the patients tending to come out of a depressive episode during the trial). It was interesting reading some of the responses to an early version of the placebo meta-analysis. A Dr. McDonald wrote to say that he has previously calculated that the improvements in placebo groups are consistent with regression to the mean, and now that the direct comparison has been made, "It is time to call a myth a myth". But someone else wrote that "A single, well-performed meta-analysis is insufficient to reject the traditional consensus about the placebo effect."
And the story didn't end when that meta-analysis was published. In depression, a recent study was taken by some as evidence for a placebo effect, but another author said "this particular trial is biased to an extent that the results are not interpretable". Personally I agree with the latter. The issue is that about half the no-pill group dropped out of the trial, and their depression measurements were imputed with the method of "last observation carried forward". To see the problem with that, look back at that first plot, the one from the Prozac trial, and imagine terminating one of those curves at week 2 or 3 and then extrapolating it with a horizontal line.
Once I saw the problem with "last observation carried forward" (LOCF), though, I saw it in other places too. In fact, that plot from the Prozac trial was made using LOCF, and the placebo group had more patients dropping out. I wonder how much of a difference that makes to our SMD scores.
But now that I've brought up yet another statistical issue, I want to take a step back and ask, why is this so confusing? Why haven't we settled this yet? And a big part of the answer is that the placebo effect is small. My guess is that the "real" placebo effect on health is about zero. But even if you think this is really a psychologically mediated effect on health, it's not a big one. That's the root of all our problems. Big effects are easy to measure. Stepping back from the confusion about whether the effect is small or zero, we know with confidence that it's not large.
Even if you forget the subtleties, we're a long way from the story where scientists need placebo groups because placebos on their own are such powerful medicine. We do still need placebo groups. If there's no placebo effect on health, then the differences we see must be biased reporting. We've also seen the issues that can be caused by the untreated group dropping out of the trial. Placebos are necessary as a tool for a blinding.
As for why we thought placebos provided substantial health benefits in the first place, it seems that this impression was originally based on regression to the mean, rather than direct comparisons. It was also interesting how badly the facts on the common cold were misrepresented on their way to arriving in the rationalist blogosphere.
22 comments
Comments sorted by top scores.
comment by kromem · 2024-06-10T04:17:16.452Z · LW(p) · GW(p)
The meta-analysis is probably Simpson's paradox in play at very least for the pain category, especially given the noted variability.
Some of the more recent research into Placebo (Harvard has a very cool group studying it) has been the importance of ritual vs simply deception. In their work, even when it was known to be a placebo, as long as delivered in a ritualized way, there was an effect.
So when someone takes a collection of hundreds of studies where the specific conditions might vary, and then just adds them all together looking for an effect even though they note that there's a broad spectrum of efficacy across the studies, it might not be the best basis to extrapolate from.
For example, given the following protocols, do you think they might have different efficacy for pain reduction, or that the results should be the same?
-
Send patients home with sugar pills to take as needed for pain management
-
Have a nurse come in to the room with the pills in a little cup to be taken
-
Have a nurse give an injection
Which of these protocols would be easier and more cost effective to include as the 'placebo'?
If we grouped studies of placebo for pain by the intensiveness of the ritualized component vs if we grouped them all together into one aggregate and looked at the averages, might we see different results?
I'd be wary of reading too deeply into the meta-analysis you point to, and would recommend looking into the open-label placebo research from PiPS, all of which IIRC postdates the meta-analysis.
Especially for pain, where we even know that giving someone an opiate blocker prevents the pain reduction placebo effect (Levine et al (1978)), the idea that "it doesn't exist" because of a single very broad analysis seems potentially gravely mistaken.
Replies from: yair-halberstadt, edge_retainer↑ comment by Yair Halberstadt (yair-halberstadt) · 2024-06-10T10:23:27.096Z · LW(p) · GW(p)
I'm interested if you have a toy example showing how Simpsons paradox could have an impact here?
I assume that has a placebo/doesn't have a placebo is a binary variable, and I also assume that the number of people in each arm in each experiment is the same. I can't really see how you would end up with Simpsons paradox with that set up.
Replies from: kromem↑ comment by kromem · 2024-06-10T22:19:02.568Z · LW(p) · GW(p)
It's not exactly Simpson's, but we don't even need a toy model as in their updated analysis it highlights details in line with exactly what I described above (down to tying in earlier PiPC research), and describe precisely the issue with pooled results across different subgroupings of placebo interventions:
It can be difficult to interpret whether a pooled standardised mean difference is large enough to be of clinical relevance. A consensus paper found that an analgesic effect of 10 mm on a 100 mm visual analogue scale represented a ‘minimal effect’ (Dworkin 2008). The pooled effect of placebo on pain based on the four German acupuncture trials corresponded to 16 mm on a 100 mm visual analogue scale, which amounts to approximately 75% of the effect of non‐steroidal anti‐inflammatory drugs on arthritis‐related pain (Gøtzsche 1990). However, the pooled effect of the three other pain trials with low risk of bias corresponded to 3 mm. Thus, the analgesic effect of placebo seems clinically relevant in some situations and not in others.
Putting subgroups with a physical intervention where there's a 16/100 result with 10/100 as significant in with subgroups where there's a 3/100 result and only looking at the pooled result might lead someone to thinking "there's no significant effect" as occurred with OP, even though there's clearly a significant effect for one subgroup when they aren't pooled.
This is part of why in the discussion they explicitly state:
However, our findings do not imply that placebo interventions have no effect. We found an effect on patient‐reported outcomes, especially on pain. Several trials of low risk of bias reported large effects of placebo on pain, but other similar trials reported negligible effect of placebo, indicating the importance of background factors. We identified three clinical factors that were associated with higher effects of placebo: physical placebos...
Additionally, the criticism they raise in their implications section about there being no open label placebo data is no longer true, which was the research I was pointing OP towards.
The problem here was that the aggregate analysis at face value presents a very different result from a detailed review of the subgroups, particularly along physical vs pharmacological placebos, all of which has been explored further in research since this analysis.
↑ comment by edge_retainer · 2024-06-11T20:41:27.532Z · LW(p) · GW(p)
Yea, the Cochrane meta-study aggregates a bunch of heterogenous studies so the aggregated results are confusing to analyze. The unfortunate reality is that it is complicated to get a complete picture - one may have to look at the individual studies one by one if they truly want to come to a complete understanding of the lit.
Replies from: transhumanist_atom_understander↑ comment by transhumanist_atom_understander · 2024-06-12T00:25:45.536Z · LW(p) · GW(p)
Yes, and I did look at something like four of the individual studies of depression, focusing on the ones testing pills so they would be comparable to the Prozac trial. As I said in the post, they all gave me the same impression: I didn't see a difference between the placebo and no-pill groups. So it was surprising to see the summary value of -0.25 SMD. Maybe it's some subtle effect in the studies I looked at which you can see once you aggregate. But maybe it's heterogeneity, and the effect is coming from the studies I didn't look at. As I mentioned in the post, not all of the placebo interventions were pills.
comment by simon · 2024-06-10T15:13:40.818Z · LW(p) · GW(p)
Two different questions:
- Does receiving a placebo cause an actual physiological improvement?
- Does receiving a placebo cause the report of the patient's condition to improve?
The answer to the first question can be "no" while the second is still "yes", e.g. due to patient's self-reports of subjective conditions (pain, nausea, depression) being biased to what they think the listener wants to hear, particular if there's been some ritualized context (as discussed in kromem's comment) reinforcing that that's what they "should" say.
Note that a similar effect could apply anywhere in the process where a subjective decision is made (e.g. if a doctor makes a subjective report on the patient's condition).
comment by Ben (ben-lang) · 2024-06-10T15:34:11.510Z · LW(p) · GW(p)
"Stepping back from the confusion about whether the effect is small or zero, we know with confidence that it's not large."
A phrase I think is good in cases like this is "The effect size cannot be resolved from zero."
comment by Viliam · 2024-06-10T07:48:59.957Z · LW(p) · GW(p)
I like the distinction between "psychological effects of believing that you took a drug" and "reversion to the mean".
Within the former, I think there is a continuum between "purely mental effects" (like maybe being more relaxed, because now you believe your problem is being addressed by professionals) and "doing different things" (such as you stop doing things that harm your health, because you do not want to sabotage the medical intervention). There is no clear line between these two, because in some sense, even relaxing is "doing something", but maybe it makes sense to distinguish between unconscious reactions, and things like "now that I am taking the pills, I stopped smoking or eating chocolate, because I would feel like a complete idiot taking the medicine and doing the thing that made me need it in the first place").
comment by milanrosko · 2024-06-10T03:56:21.443Z · LW(p) · GW(p)
When it comes to contraceptives, the placebo effect is quite limited.
Replies from: NeroWolfe, RamblinDash, kithpendragon↑ comment by RamblinDash · 2024-06-10T20:40:21.454Z · LW(p) · GW(p)
If it did work, you might call it "immaculate contraception"!
↑ comment by kithpendragon · 2024-06-10T20:05:05.017Z · LW(p) · GW(p)
I don't recall having ever read any claim that the placebo effect extends to contraceptives.
Replies from: milanrosko↑ comment by milanrosko · 2024-06-11T03:16:49.416Z · LW(p) · GW(p)
because it's quite limited... it's a joke btw.
comment by Aleksander (Omnni) · 2024-06-10T16:16:05.524Z · LW(p) · GW(p)
If this is a case for removing the practice of placebo from medical testing, I don’t think it holds up. There are other reasons a placebo affects a result. As another mentioned, the patient, or whoever reports the data, likely has a tendency to shift their reporting towards what they believe the conductors of the study wish to hear. If we introduce a placebo pill, subjects have no way to tell what results the proctor ‘wants’. Generally, placebos are trivial to implement, likely taking less time than would accurately determining on a case-by-case basis which trials would benefit from a placebo
Replies from: NNOTM↑ comment by Nnotm (NNOTM) · 2024-06-10T18:28:47.685Z · LW(p) · GW(p)
Note that the penultimate paragraph of the post says
> We do still need placebo groups.
↑ comment by Aleksander (Omnni) · 2024-06-10T19:48:14.083Z · LW(p) · GW(p)
Oh that’s pretty bad I somehow managed to write what the post wrote as a contradiction to the post. Apologies. Thank you for pointing it out
Replies from: transhumanist_atom_understander↑ comment by transhumanist_atom_understander · 2024-06-10T20:57:31.569Z · LW(p) · GW(p)
It's okay, the post is eight pages long and not super internally consistent, basically because I had to work on Monday and didn't want to edit it. I don't make a post like that expecting everyone to read every paragraph and get a perfectly clear idea of what I'm saying.
comment by denkenberger · 2024-06-11T01:33:55.245Z · LW(p) · GW(p)
You might say that the persistence of witch doctors is weak evidence of the placebo effect. But I would guess that the nocebo effect (believing something is going to hurt you) would be stronger. This is because stress takes years off people's lives. The Secret of Our Success cited a study of the Chinese belief that birth year affects diseases and lifespan. Chinese people living in the US who had the birth year associated with cancer lived ~four years shorter than other birth years.
Replies from: transhumanist_atom_understander↑ comment by transhumanist_atom_understander · 2024-06-11T12:19:16.671Z · LW(p) · GW(p)
I took a look at The Secret of Our Success, and saw the study you're describing on page 277. I think you may be misremembering the disease. The data given is for bronchitis, emphysema and asthma (combined into one category). It does mention that similar results hold for cancer and heart attacks.
I took a look at the original paper. They checked 15 diseases, and bronchitis, emphysema and asthma was the only one that was significant after correction for multiple comparisons. I don't agree that the results for cancer and heart attacks are similar. They seem within the range of what you can get from random fluctuations in a list of 15 numbers. The statistical test backs up that impression.
If this is a real difference, I would expect it has something to do with lifestyle changes, rather than stress. However, it's in the opposite direction of what I would expect. That is, I would expect those with a birth year predisposed to lung problems to avoid smoking. I did find some chinese astrology advice to that effect. Therefore they should live longer, when in fact they live shorter. So that doesn't really make sense.
This result seems suspicious to me. First of all because it's just a couple of diseases selected out of a list of mostly non-significant tests, but also because people probably do lots of tests of astrology that they don't publish. I wouldn't bet on it replicating in another population.
Replies from: denkenberger↑ comment by denkenberger · 2024-06-11T22:10:08.215Z · LW(p) · GW(p)
Thanks for digging into the data! I agree that the rational response should be if you are predisposed to a problem to actively address the problem. But I still think a common response would be one of fatalism and stress. Have you looked into other potential sources of the nocebo effect? Maybe people being misdiagnosed with diseases that they don't actually have?
Replies from: transhumanist_atom_understander↑ comment by transhumanist_atom_understander · 2024-06-11T22:59:55.989Z · LW(p) · GW(p)
From a quick look on Wikipedia I don't see anything. Except for patients that report side effects from placebo, but of course that could be symptoms that they would have had in any case, which they incorrectly attribute to the placebo.
I don't see how you could get an accurate measure of a nocebo effect from misdiagnoses. I don't think anyone is willing to randomize patients to be misdiagnosed. And if you try to do it observationally, you run into the problem of distinguishing the effects of the misdiagnosis from whatever brought them to the doctor seeking diagnosis.
comment by Review Bot · 2024-06-11T00:04:57.411Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?