Posts
Comments
I think it approaches it from a different level of abstraction though. Alignment faking is the strategy used to achieve goal guarding. I think both can be useful framings.
Hah, I've listened to Half an hour before Dawn in San Francisco a lot and I only realized just now that the AI by itself read "65,000,000" as "sixty-five thousand thousand", which I always thought was an intentional poetic choice
Note that the penultimate paragraph of the post says
> We do still need placebo groups.
In principle, I prefer sentient AI over non-sentient bugs. But the concern that is if non-sentient superintelligent AI is developed, it's an attractor state, that is hard or impossible to get out of. Bugs certainly aren't bound to evolve into sentient species, but at least there's a chance.
Bugs could potentially result in a new sentient species many millions of years down the line. With super-AI that happens to be non-sentient, there is no such hope.
Thank you for this, I had listened to the lesswrong audio of the last one just before seeing your comment about making your version, and now waited before listening to this one hoping you would post one
Missed opportunity to replace "if the box contains a diamond" with the more thematically appropriate "if the chest contains a treasure", though
FWIW the AI audio seems to not take that into account
Thanks, I've found this pretty insightful. In particular, I hadn't considered that even fully understanding static GPT doesn't necessarily bring you close to understanding dynamic GPT - this makes me update towards mechinterp being slightly less promising than I was thinking.
Quick note:
> a page-state can be entirely specified by 9628 digits or a 31 kB file.
I think it's a 31 kb file, but a 4 kB file?
I think an important difference between humans and these Go AIs is memory: If we find a strategy that reliably beats human experts, they will either remember losing to it or hear about it and it won't work the next time someone tries it. If we find a strategy that reliably beats an AI, that will keep happening until it's retrained in some way.
Are you familiar with Aubrey de Grey's thinking on this?
To summarize, from memory, cancers can be broadly divided into two classes:
- about 85% of cancers rely on lengthening telomeres via telomerase
- the other 15% of cancers rely on some alternative lengthening of telomeres mechanism ("ALT")
The first, big class, can be solved if we can prevent cancers from using telomerase. In his 2007 book "Ending Aging", de Grey and his co-author Michael Rae wrote about "Whole-body interdiction of lengthening of telomeres" (WILT), which was about using gene therapy to remove telomerase genes in all somatic cells. Then, stem cell therapy could be used to produce new telomeres for those cases where the body usually legitimately uses telomerase.
But research has moved on since then, and this might not be necessary. One promising approach is Maia Biotech's THIO, a small molecule drug which is incorporated into the telomeres of cancer cells, compromises the telomeres' structure, and results in rapid cell death. They are currently preparing for phase 2 for a few different clinical trials.
For the other 15% of cancers, the ALT mechanism is as far as I know not as well understood, and I haven't heard of a promising general approach to cure it. But it seems plausible that it could be a similar affair in the end.
Thanks, I will read that! Though just after you commented I found this in my history, which is the post I meant: https://www.lesswrong.com/posts/kpPnReyBC54KESiSn/optimality-is-the-tiger-and-agents-are-its-teeth
I think there was a post/short-story on lesswrong a few months ago about a future language model becoming an ASI because someone asked it to pretend it was an ASI agent and it correctly predicted the next tokens, or something like that. Anyone know what that post was?
Second try: When looking at scatterplots of any 3 out of 5 of those dimensions and interpreting each 5-tuple of numbers as one point, you can see the same structures that are visible in the 2d plot, the parabola and a line - though the line becomes a plane if viewed from a different angle, and the parabola disappears if viewed from a different angle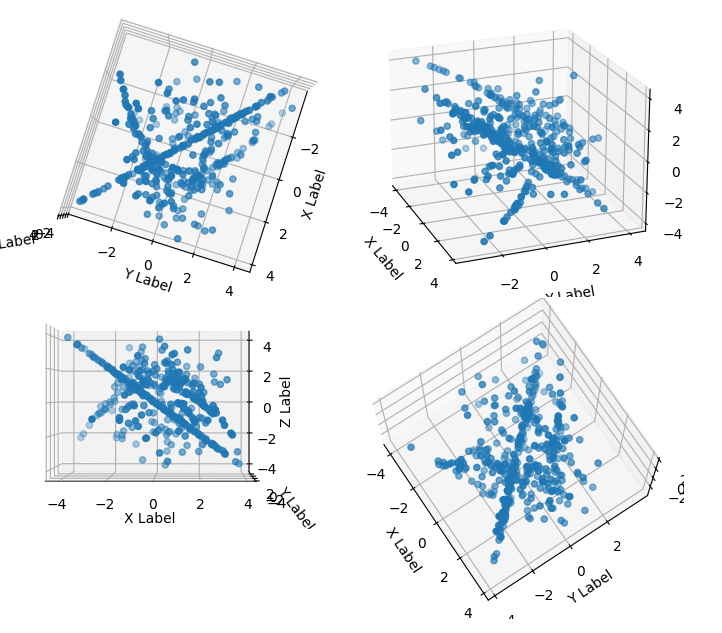 .
.
Looking at scatterplots of any 3 out of 5 of those dimensions, it looks pretty random, much less structure than in the 2d plot.
Edit: Oh, wait, I've been using chunks of 419 numbers as the dimensions but should be interleaving them
The double line I was talking about is actually a triple line, at indices 366, 677, and 1244. The lines before come from fairly different places, and they diverge pretty quickly afterwards: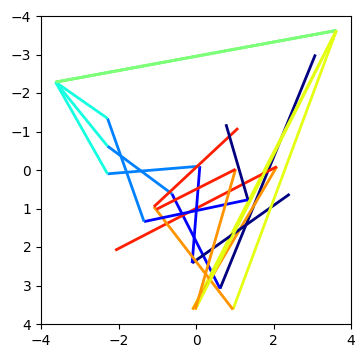
However, just above it, there's another duplicate line, at indices 1038 and 1901: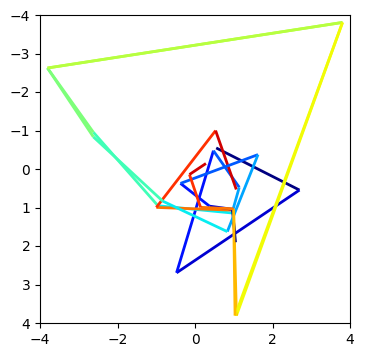
These start out closer together and also take a little bit longer to diverge.
This might be indicative of a larger pattern that points that are close together and have similar histories tend to have their next steps close to each other as well.
For what it's worth, colored by how soon in the sequence they appear (blue is early, red is late) (Also note I interpreted it as 2094 points, with each number first used in the x-dimension and then in the y-dimension):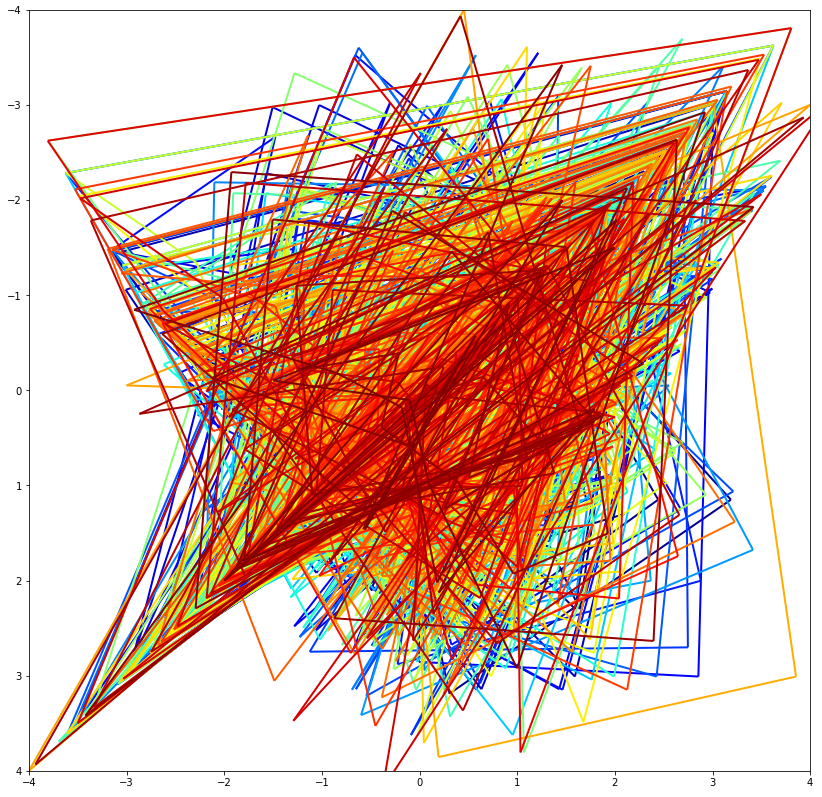
Note that one line near the top appears to be drawn twice, confirming if nothing else that it's not a rule that it's not a succession rule that only depends on the previous value, since the paths diverge afterwards.
Still, comparing those two sections could be interesting.
Interpreting the data as unsigned 8-bit integers and plotting it as an image with width 8 results in this (only the first few rows shown):

The rest of the image looks pretty similar. There is a almost continuous high-intensity column (yellow, the second-to-last column), and the values in the first 6 columns repeat exactly in the next row pretty often, but not always.
Very cool, thanks!
The original DALL-E was capable of having almost the same image with slight variations in one generation, so I'd be interested to see something like "A photograph of a village in 1900 on the top, and the same photo colorized on the bottom".
I haven't read the luminosity sequence, but I just spent some time looking at the list of all articles seeing if I can spot a title that sounds like it could be it, and I found it: Which Parts are "Me"? - I suppose the title I had in mind was reasonably close.
Is there a post as part of the sequences that's roughly about how your personality is made up of different aspects, and some of them you consider to be essentially part of who you are, and others (say, for example, maybe the mechanisms responsible for akrasia) you wouldn't mind dropping without considering that an important difference to who you are?
For years I was thinking Truly Part Of You was about that, but it turns out, it's about something completely different.
Now I'm wondering if I had just imagined that post existing or just mentally linked the wrong title to it.
One question was whether it's worth working on anything other than AGI given that AGI will likely be able to solve these problems; he agreed, saying he used to work with 1000 companies at YC but now only does a handful of things, partially just to get a break from thinking about AGI.
Is that to be interpreted as "finding out whether UFOs are aliens is important" or "the fact that UFOs are aliens is important"?
As I understand it, the idea with the problems listed in the article is that their solutions are supposed to be fundamental design principles of the AI, rather than addons to fix loopholes.
Augmenting ourselves is probably a good idea to do *in addition* to AI safety research, but I think it's dangerous to do it *instead* of AI safety research. It's far from impossible that artificial intelligence could gain intelligence much faster at some point than augmenting the rather messy human brain, at which point it *needs* to be designed in a safe way.
AI alignment is not about trying to outsmart the AI, it's about making sure that what the AI wants is what we want.
If it were actually about figuring out all possible loopholes and preventing them, I would agree that it's a futile endeavor.
A correctly designed AI wouldn't have to be banned from exploring any philosophical or introspective considerations, since regardless of what it discovers there, it's goals would still be aligned with what we want. Discovering *why* it has these goals is similar to humans discovering why we have our motivations (i.e., evolution), and similarly to how discovering evolution didn't change much what humans desire, there's no reason to assume that an AI discovering where its goals come from should change them.
Of course, care will have to be taken to ensure that any self-modifications don't change the goals. But we don't have to work *against* the AI to accomplish that - the AI *also* aims to accomplish its current goals, and any future self-modification that changes its goals would be detrimental in accomplishing its current goals, so (almost) any rational AI will, to the best of its ability, aim *not* to change its goals. Although this doesn't make it easy, since it's quite difficult to formally specify the goals we would want an AI to have.
Whether or not it would question its reality mostly depends on what you mean by that - it would almost certainly be useful to figure out how the world works, and especially how the AI itself works, for any AI. It might also be useful to figure out the reason for which it was created.
But, unless it was explicitly programmed in, this would likely not be a motivation in and of itself, rather, it would simply be useful for accomplishing its actual goal.
I'd say the reason why humans place such high value in figuring out philosophical issues is to a large extent because evolution produces messy systems with inconsistent goals. This *could* be the case for AIs too, but to me it seems more likely that some more rational thought will go into their design.
(That's not to say that I believe it will be safe by default, but simply that it will have more organized goals than humans have.)
It would need a reason of some kind of reason to change its goals - one might call it a motivation. The only motivation it has available though, are its final goals, and those (by default) don't include changing the final goals.
Humans never had the final goal replicating their genes. They just evolved to want to have sex. (One could perhaps say that the genes themselves had the goal of replicating, and implemented this by giving the humans the goal of having sex.) Reward hacking doesn't involve changing the terminal goal, just fulfilling it in unexpected ways (which is one reason why reinforcement learning might be a bad idea for safe AI.)
What you're saying goes against the here widely believed orthogonality thesis, which essentially states that what goal an agent has is independent of how smart it is. If the agent has programmed in a certain set of goals, there is no reason for it to change this set of goals if it becomes smarter (this is because changing its goals would not be beneficial to achieving its current goals).
In this example, if an agent has the sole goal of fulfilling the wishes of a particular human, there is no reason for it to change this goal once it becomes an ASI. As far as the agent is concerned, using resources for this purpose wouldn't be a waste, it would be the only worthwhile use for them. What else would it do with them?
You seem to be assigning some human properties to the hypothetical AI (e.g. "scorn", viewing something as "petty"), which might be partially responsible for the disagreement here.
Why wait until someone wants the money? Shouldn't the AI try to send 5 Dollars to everyone with a note attached reading "Here is a tribute; please don't kill a huge number of people" regardless of whether they ask for it or not?
Sounds pretty cool, definitely going to try it out some.
Oh, and by the way, you wrote "Inpsect" instead of "Inspect" at the end of page 27.
Working links on yudkowsky.net and acceleratingfuture.com:
Transhumanism as Simplified Humanism The Meaning That Immortality Gives to Life
That's true, though I think "optimal" would be a better word for that than "correct".
There are no "correct" or "incorrect" definitions, though, are there? Definitions are subjective, it's only important that participants of a discussion can agree on one.
I took it. I was surprised how far I was off with Europe.
I know this is over a year old, but I still feel like this is worth pointing out:
If you can get the positive likelihood ratio as the meaning of a positive result, then you can use the negative likelihood ratio as the meaning of the negative result just reworking the problem.
You weren't using the likelihood ratio, which is one value, 8.33... in this case. You were using the numbers you use to get the likelihood ratio.
But the same likelihood ratio would also occur if you had 8% and 0.96%, and then the "negative likelihood ratio" would be about 0.93 instead of 0.22.
You simply need three numbers. Two won't suffice.