Contest: An Alien Message
post by DaemonicSigil · 2022-06-27T05:54:54.144Z · LW · GW · 100 commentsContents
Scenario Rules Why is this interesting? None 101 comments
Scenario
You're not certain that aliens are real. Even after receiving that email from your friend who works at NASA, with the subject line "What do you make of this?" and a single binary file attached, you're still not certain. It's rather unlikely that aliens would be near enough to Earth to make contact with humanity, and unlikelier still that of all the humans on Earth, you would end up being the one tasked with deciphering their message. You are a professional cryptanalyst, but there are many of those in the world. On the other hand, it's already been months since April Fools, and your friend isn't really the prankster type.
You sigh and download the file.
Rules
No need to use spoiler text in the comments: This is a collaborative contest, where working together is encouraged. (The contest is between all of you and the difficulty of the problem.)
Success criteria: The people of LessWrong will be victorious if they can fully describe the process that generated the message, ideally by presenting a short program that generates the message, but a sufficiently precise verbal description is fine too.
The timeframe of the contest is about 2 weeks. The code that generated the message will be revealed on Tuesday July 12.
Why is this interesting?
This contest is, of course, based on That Alien Message [LW · GW]. Recently there was some discussion under I No Longer Believe Intelligence to be "Magical" [LW · GW] about how realistic that scenario actually was. Not the part where the entire universe was a simulation by aliens, but the part where humanity was able to figure out the physics of the universe 1 layer up by just looking at a few frames of video. Sure it may be child's play for Solomonoff Induction, but do bounded agents really stand a chance? This contest should provide some experimental evidence.
100 comments
Comments sorted by top scores.
comment by harfe · 2022-06-28T14:06:10.864Z · LW(p) · GW(p)
Solution:
#!/usr/bin/env python3
import struct
a = [1.3, 2.1, -0.5] # initialize data
L = 2095 # total length
i = 0
while len(a)<L:
if abs(a[i]) > 2.0 or abs(a[i+1]) > 2.0:
a.append(a[i]/2)
i += 1
else:
a.append(a[i] * a[i+1] + 1.0)
a.append(a[i] - a[i+1])
a.append(a[i+1] - a[i])
i += 2
f = open("out_reproduced.bin","wb") # save in binary
f.write(struct.pack('d'*L,*a)) # use IEEE 754 double format
f.close()
Then one can check that the produced file is identical:
$ sha1sum *bin
70d32ee20ffa21e39acf04490f562552e11c6ab7 out.bin
70d32ee20ffa21e39acf04490f562552e11c6ab7 out_reproduced.bin
edit: How I found the solution: I found some of the other comments helpful, especially from gjm (although I did not read all). In particular, interpreting the data as a sequence of 64-bit floating point numbers saved me a lot of time. Also gjm's mention of the pattern a, -a, b, c, -c, d was an inspiration.
If you look at the first couple of numbers, you can see that they are sometimes half of an earlier number. Playing around further with the numbers I eventually found the patterns a[i] * a[i+1] + 1.0 and a[i] - a[i+1].
It remained to figure out when the a[i]/2 rule applies and when the a[i] * a[i+1] + 1.0 rule applies. Here it was a hint that the numbers do not grow too large in size. After trying out several rules that form bounds on a[i] and a[i+1], I eventually found the right one.
↑ comment by anonymousaisafety · 2022-06-28T16:26:41.818Z · LW(p) · GW(p)
I have mixed thoughts on this.
I was delighted to see someone else put forth an challenge, and impressed with the amount of people who took it up.
I'm disappointed though that the file used a trivial encoding. When I first saw the comments suggesting it was just all doubles, I was really hoping that it wouldn't turn out to be that.
I think maybe where the disconnect is occurring is that in the original That Alien Message [LW · GW] post, the story starts with aliens deliberately sending a message to humanity to decode, as this thread did here. It is explicitly described as such:
From the first 96 bits, then, it becomes clear that this pattern is not an optimal, compressed encoding of anything. The obvious thought is that the sequence is meant to convey instructions for decoding a compressed message to follow...
But when I argued against the capability of decoding binary files in the I No Longer Believe Intelligence To Be Magical [LW(p) · GW(p)] thread, that argument was on a tangent -- is it possible to decode an arbitrary binary files? I specifically ruled out trivial encodings in my reasoning. I listed the features that make a file difficult to decode. A huge issue is ambiguity because in almost all binary files, the first problem is just identifying when fields start or end.
I gave examples like
- Camera RAW formats
- Compressed image formats like PNG or JPG
- Video codecs
- Any binary protocol between applications
- Network traffic
- Serialization to or from disk
- Data in RAM
On the other hand, an array of doubles falls much more into this bucket
data that is basically designed to be interpreted correctly, i.e. the data, even though it is in a binary format, is self-describing.
With all of the above said, the reason why I did not bother uploading an example file in the first thread is frankly because it would have taken me some number of hours to create and I didn't think there would be any interest in actually decoding it by enough people to justify the time spent. That assumption seems wrong now! It seems like people really enjoyed the challenge. I will update accordingly, and I'll likely post my example of a file later this week after I have an evening or day free to do so.
Replies from: blf↑ comment by blf · 2022-06-28T18:39:07.097Z · LW(p) · GW(p)
Your interlocutor in the other thread seemed to suggest that they were busy until mid-July or so. Perhaps you could take this into account when posting.
I agree that IEEE754 doubles was quite an unrealistic choice, and too easy. However, the other extreme of having a binary blob with no structure at all being manifest seems like it would not make for an interesting challenge. Ideally, there should be several layers of structure to be understood, like in the example of a "picture of an apple", where understanding the file encoding is not the only thing one can do.
Replies from: anonymousaisafety↑ comment by anonymousaisafety · 2022-07-24T04:37:05.021Z · LW(p) · GW(p)
I have posted my file here https://www.lesswrong.com/posts/BMDfYGWcsjAKzNXGz/eavesdropping-on-aliens-a-data-decoding-challenge. [LW · GW]
↑ comment by Rafael Harth (sil-ver) · 2022-06-28T15:33:35.915Z · LW(p) · GW(p)
Interesting, I expected the solution to be simpler, and I'm surprised you found it this quickly given that it's this complex.
Replies from: Bucky, anonymousaisafety↑ comment by Bucky · 2022-06-28T19:55:45.369Z · LW(p) · GW(p)
This suggests a different question. For non-participants who are given the program which creates the data, what probability/timeframe to assign to success.
On this one I think that I would have put a high probability to be solved but would have anticipated a longer timeframe.
↑ comment by anonymousaisafety · 2022-06-28T15:44:38.781Z · LW(p) · GW(p)
https://en.wikipedia.org/wiki/Kolmogorov_complexity
The fact that the program is so short indicates that the solution is simple. A complex solution would require a much longer program to specify it.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-06-28T16:09:51.922Z · LW(p) · GW(p)
Kolmogorov Complexity isn't the right measure. I'm pretty sure this program is way simpler (according to you or me) than most uniformly sampled programs of equal KC that produce a string of equal length.
And i wouldn't consider it short given how hard it would be to find a "typical" program with this KC.
Replies from: anonymousaisafety↑ comment by anonymousaisafety · 2022-06-28T16:33:11.267Z · LW(p) · GW(p)
Why do you say that Kolmogorov complexity isn't the right measure?
most uniformly sampled programs of equal KC that produce a string of equal length.
...
"typical" program with this KC.
I am worried that you might have this backwards?
Kolmogorov complexity describes the output, not the program. The output file has low Kolmogorov complexity because there exists a short computer program to describe it.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-06-28T17:29:54.208Z · LW(p) · GW(p)
Let me rephrase then: most strings of same length and same KC will have much more intuitively complex programs-of-minimum-length that generated them.
Why is the program intuitively simple? Well for example, suppose you have the following code in the else block:
a.append(min(max(int(i+a[i]),2),i)
i += 1
I think the resulting program has lower length (so whatever string it generates has lower KC), but it would be way harder to find. And I bet that a uniformly sampled string with the same KC will have a program that looks much worse than that. The kinds or programs that look normal to you or me are a heavily skewed sample, and this program does look reasonably normal.
Replies from: Bucky, gjm↑ comment by Bucky · 2022-06-28T18:49:20.453Z · LW(p) · GW(p)
I think the resulting program has lower length (so whatever string it generates has lower KC)
I don’t think this follows - your code is shorter in python but it includes 3 new built in functions which is hidden complexity.
I do agree with the general point that KC isn’t a great measure of difficulty for humans - we are not exactly arbitrary encoders.
↑ comment by gjm · 2022-06-28T18:07:20.187Z · LW(p) · GW(p)
Why do you think that "would be way harder to find"? (My intuition goes exactly the other way.)
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-06-28T19:18:41.515Z · LW(p) · GW(p)
Eh. I agree with both replies that the example was bad. I wanted to do something unintuitive with pointer arithmetic, but the particular code probably doesn't capture it well, so it may in fact be easier to find. (Still totally stand by the broader point though.)
↑ comment by Alex Vermillion (tomcatfish) · 2022-06-28T15:09:10.491Z · LW(p) · GW(p)
Might be an obvious thought, but why did the aliens send us this gibberish. Is there an interpretation of this that makes sense?
Replies from: dkirmanicomment by gjm · 2022-06-27T09:25:12.144Z · LW(p) · GW(p)
Interpreting each 8-byte block as an IEEE double-precision float (endianity whatever's default on x86-64, which IIRC is little-endian) yields all values in the range -4 .. 4.2. FFT of the resulting 2095 values gives (ignoring the nonzero DC term arising from the fact that the average isn't quite zero) is distinctly not-flat, indicating that although the numbers look pretty random they are definitely not -- they have more high-frequency and less low-frequency content than one would get from truly random numbers.
Replies from: sil-ver, gjm, gjm, donald-hobson, gjm↑ comment by Rafael Harth (sil-ver) · 2022-06-27T14:48:41.256Z · LW(p) · GW(p)
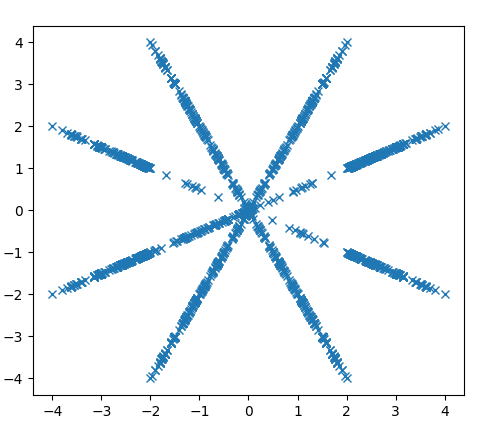
Here's what you get when you interpret them as (y,x) positions of points.

↑ comment by Nnotm (NNOTM) · 2022-06-28T08:58:31.183Z · LW(p) · GW(p)
For what it's worth, colored by how soon in the sequence they appear (blue is early, red is late) (Also note I interpreted it as 2094 points, with each number first used in the x-dimension and then in the y-dimension):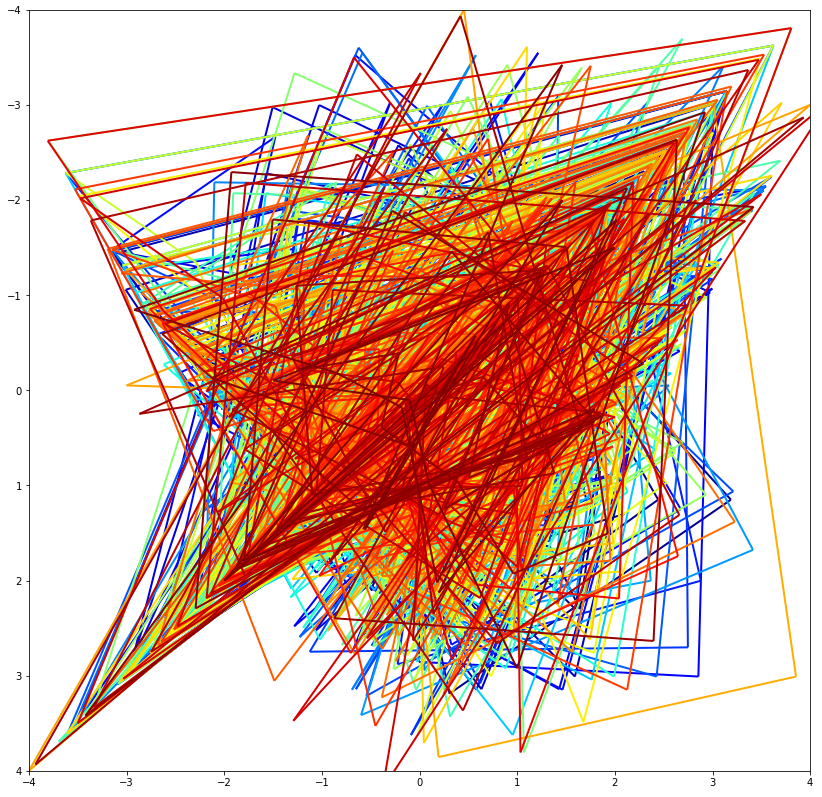
Note that one line near the top appears to be drawn twice, confirming if nothing else that it's not a rule that it's not a succession rule that only depends on the previous value, since the paths diverge afterwards.
Still, comparing those two sections could be interesting.
↑ comment by Nnotm (NNOTM) · 2022-06-28T09:30:43.972Z · LW(p) · GW(p)
The double line I was talking about is actually a triple line, at indices 366, 677, and 1244. The lines before come from fairly different places, and they diverge pretty quickly afterwards: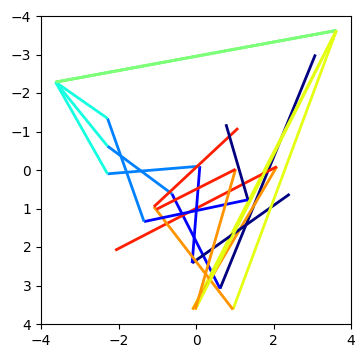
However, just above it, there's another duplicate line, at indices 1038 and 1901: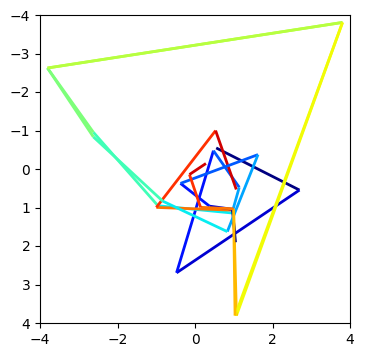
These start out closer together and also take a little bit longer to diverge.
This might be indicative of a larger pattern that points that are close together and have similar histories tend to have their next steps close to each other as well.
↑ comment by gjm · 2022-06-27T15:25:51.478Z · LW(p) · GW(p)
Every number in the sequence which equals 1-(y/2)^2 for "nice" y to "good" accuracy is in fact on the quadratic; i.e., when a number is "approximately" 1-(y/2)^2 for a y that "could" come next, that y does in fact come next. BUT to make this so I am having to define "nice" and "good" fairly tightly; this in fact occurs for only 14 values early in the sequence, perhaps before roundoff error starts being a nuisance.
(I am conjecturing that the way this thing is constructed might be that we start with a few initial values and then iterate some process like: "if (condition) then next number is - previous number; else if (condition) then next number is 2sqrt(1-previous); else if ...". If so, then we might start with "nice" numbers -- in fact the first two are 1.3 and 2.1 to machine precision -- but that "niceness" might be eroded as we calculate. This is all very handwavy and there is at least one kinda-obvious objection to it.)
Replies from: gjm, sil-ver, gjm↑ comment by gjm · 2022-06-27T15:31:53.409Z · LW(p) · GW(p)
A few reasons for suspecting that this sort of iterative process is in play:
- It would fit with the relationship to "That Alien Message" where the idea is that each frame (here, each number) is the "next" state of affairs as something evolves according to simple rules.
- There are many cases in which it sure looks as if one number is derived from its predecessor. (Or maybe from its successor.)
- It's an obvious thing to do, if you want to set a challenge like this.
Note that I am not necessarily conjecturing that each number is a function of its predecessor. There might be other internal state that we don't get to see.
Replies from: blf↑ comment by blf · 2022-06-28T01:38:55.682Z · LW(p) · GW(p)
Do you see how such an iteration can produce the long-distance correlations I mention in a message below, between floats at positions that differ by a factor of ? It seems that this would require some explicit dependence on the index.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-06-28T12:05:52.609Z · LW(p) · GW(p)
Its not exactly 2/e. Here is a plot of the "error" of those points. The x axis is the larger point. The y axis is the smaller point minus 2/e times the larger.
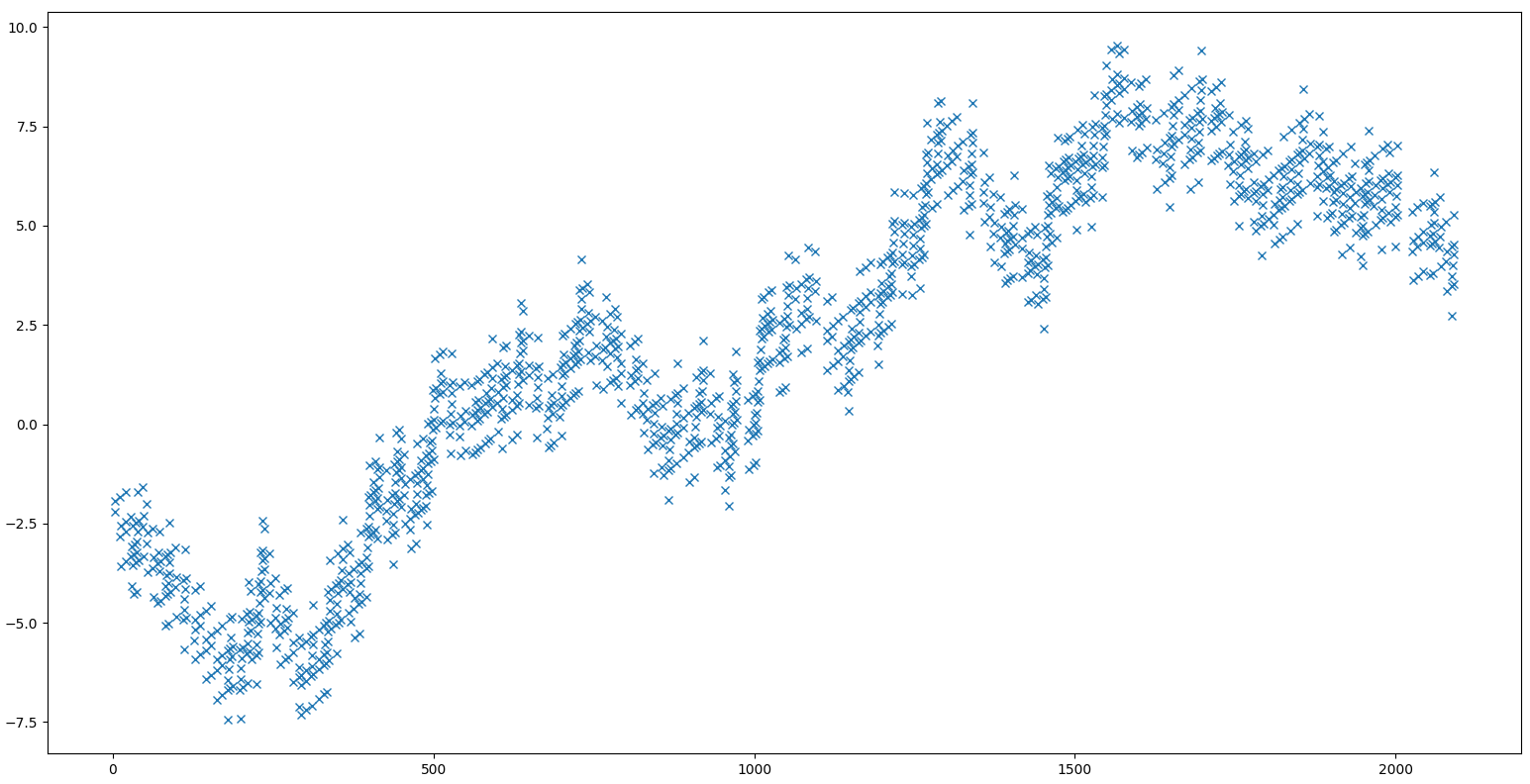
So its within about 1% of 2/e, suggesting it might be a real thing, or might just be a coincidence.
↑ comment by Rafael Harth (sil-ver) · 2022-06-28T11:00:49.112Z · LW(p) · GW(p)
(I am conjecturing that the way this thing is constructed might be that we start with a few initial values and then iterate some process like: "if (condition) then next number is - previous number; else if (condition) then next number is 2sqrt(1-previous); else if ...". If so, then we might start with "nice" numbers -- in fact the first two are 1.3 and 2.1 to machine precision -- but that "niceness" might be eroded as we calculate. This is all very handwavy and there is at least one kinda-obvious objection to it.)
Have you tried writing programs that create sequences like the above to see how close they get? (Asking to avoid redoing work if the answer is yes.)
↑ comment by gjm · 2022-06-27T21:31:35.975Z · LW(p) · GW(p)
Making explicit something I said in passing elsewhere: it seems not-impossible that the sequence might be best looked at in reverse order, since mapping x to 1-(x/2)^2 or (1-x^2)/2 is somewhat more natural than going the other way. However, it does look rather as if there might be some accumulation of roundoff error in the forward direction, which if true would argue for reading it forwards rather than backwards.
↑ comment by ObserverSuns · 2022-06-28T14:28:21.165Z · LW(p) · GW(p)
More structure emerges! Here's a plot of consecutive pairs of values (data[i], data[i+1]) such that data[i+1] = -data[i+2]. 
↑ comment by dkirmani · 2022-06-28T11:49:41.254Z · LW(p) · GW(p)
Has anyone tried a five-dimensional representation instead of a two-dimensional one? 2095 isn't divisible by 2 or by 3, but it is divisible by 5. Maybe our "aliens" have four spatial dimensions and one temporal.
Replies from: sil-ver, NNOTM, NNOTM↑ comment by Rafael Harth (sil-ver) · 2022-06-28T13:48:11.966Z · LW(p) · GW(p)
I've tried highlighting every -th point out of with the same color for a bunch of , but it all looks random. Right now, I've also tried using only 2 of 5 float values. It looks like a dead end, even though the idea is good.
I think the data is 1-dimensional, the interesting part is how each number is transformed into the next, and the 2d representation just happens to catch that (e.g., if is transformed into , it lands on the diagonal).
↑ comment by Nnotm (NNOTM) · 2022-06-28T12:11:41.166Z · LW(p) · GW(p)
Second try: When looking at scatterplots of any 3 out of 5 of those dimensions and interpreting each 5-tuple of numbers as one point, you can see the same structures that are visible in the 2d plot, the parabola and a line - though the line becomes a plane if viewed from a different angle, and the parabola disappears if viewed from a different angle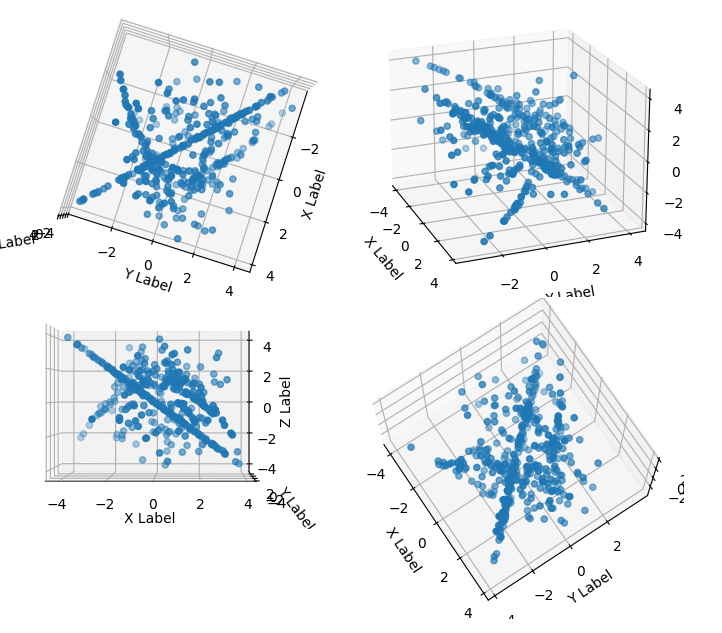 .
.
↑ comment by Nnotm (NNOTM) · 2022-06-28T11:58:43.386Z · LW(p) · GW(p)
Looking at scatterplots of any 3 out of 5 of those dimensions, it looks pretty random, much less structure than in the 2d plot.
Edit: Oh, wait, I've been using chunks of 419 numbers as the dimensions but should be interleaving them
↑ comment by moridinamael · 2022-06-27T23:46:38.734Z · LW(p) · GW(p)
Ah, it's the Elden Ring
↑ comment by Rafael Harth (sil-ver) · 2022-06-27T15:16:33.926Z · LW(p) · GW(p)
There are 1047 points. The points on the diagonal are distributed all across the list -- here are the first indices
They're usually 3 apart, but sometimes 1, 2, 4, 5, or 6. The last one has index 1045.
↑ comment by gjm · 2022-06-27T17:09:08.254Z · LW(p) · GW(p)
By the way, it's definitely not aliens. Aliens would not be sending messages encoded using IEEE754 double-precision floats.
Replies from: blf↑ comment by blf · 2022-06-28T00:58:31.958Z · LW(p) · GW(p)
Here is a rather clear sign that it is IEEE754 64 bit floats indeed. (Up to correctly setting the endianness of 8-byte chunks,) if we remove the first n bits from each chunk and count how many distinct values that takes, we find a clear phase transition at n=12, which corresponds to removing the sign bit and the 11 exponent bits.
These first 12 bits take 22 different values, which (in binary) clearly cluster around 1024 and 3072, suggesting that the first bit is special. So without knowing about IEEE754 we could have in principle figured out the splitting into 1+11+52 bits. The few quadratic patterns we found have enough examples with each exponent to help understand the transitions between exponents and completely fix the format (including the implicit 1 in the significand?).
Replies from: dkirmani↑ comment by dkirmani · 2022-06-28T07:32:53.482Z · LW(p) · GW(p)
Alternative hypothesis: The first several bits (of each 64-bit chunk) are less chaotic than the middle bits due to repetitive border behavior of a 1-D cellular automaton. This hypothesis also accounts for the observation that the final seven bits of each chunk are always either 1000000 or 0111111.
If you were instead removing the last n bits from each chunk, you'd find another clear phase transition at n=7, as the last seven bits only have two observed configurations.
Replies from: blf↑ comment by blf · 2022-06-28T08:53:08.497Z · LW(p) · GW(p)
If you calculate the entropy of each of the 64 bit positions (where and are the proportion of bits 0 and 1 among 2095 at that position), then you'll see that the entropy depends much more smoothly on position if we convert from little endian to big endian, namely if we sort the bits as 57,58,...,64, then 49,50,...,56, then 41,42,...,48 and so on until 1,...,8. That doesn't sound like a very natural boundary behaviour of an automaton, unless it is then encoded as little endian for some reason.
Replies from: dkirmani↑ comment by dkirmani · 2022-06-28T11:44:42.167Z · LW(p) · GW(p)
Now that I know that, I've updated towards the "float64" area of hypothesis space. But in defense of the "cellular automaton" hypotheses, just look at the bitmap! Ordered initial conditions evolving into (spatially-clumped) chaos, with at least one lateral border exhibiting repetitive behavior:

↑ comment by gjm · 2022-06-27T10:03:24.828Z · LW(p) · GW(p)
The first few numbers are mostly "nice". 1.3, 2.1, -0.5, 0.65, 1.05, 0.675, -1.15, 1.15, 1.70875, 0.375, -0.375, -0.3225, -2.3, 2.3. Next after that is 1.64078125, which is not so nice but still pretty nice.
These are 13/10, 21/10, -1/2, 13/20, 21/20, 27/40, -23/20, 23/20, 1367/800, 3/8, -3/8, -129/400, -23/10, 23/10, 10501/6400, ...
A few obvious remarks about these: denominators are all powers of 2 times powers of 5; 13 and 21 are Fibonacci numbers; shortly after 13/10 and 21/10 we have 13/20 and 21/20; we have three cases of x followed by -x.
Replies from: gjm, gjm, gjm, gjm↑ comment by gjm · 2022-06-27T10:08:04.858Z · LW(p) · GW(p)
Slightly less than 1/3 of all numbers are followed by their negatives. Usually it goes a, -a, b, c, -c, d, etc., but (1) the first x,-x pair isn't until the 7th/8th numbers, and (2) sometimes there is a longer gap and (3) there are a few places where there's a shorter gap and we go x, -x, y, -y.
Replies from: Measure↑ comment by Measure · 2022-06-27T15:31:35.737Z · LW(p) · GW(p)
Most of the breaks in the (a, -a, b, c, -c, d) pattern look like either the +/- pair was skipped entirely or the unpaired value was skipped. My guess is the complete message consists of alternating "packets" of either a single value or a +/- pair, and each packet has some chance to be omitted (or they are deterministically omitted according to some pattern).
↑ comment by gjm · 2022-06-27T16:00:58.837Z · LW(p) · GW(p)
The number 23/20 appears three times. Each time it appears it is followed by a different number, and that different number is generally "unusually nasty compared with others so far".
First time, at (0-based) index 7: followed by 1367/800, first with a denominator > 40.
Second time, at (0-based) index 21: followed by 3.1883919921875 ~= 1632.4567/2^9, first with a denominator > 6400.
Third time, at (0-based) index 48: followed by 2.4439140274654036, dunno what this "really" is, first with no obvious powers-of-2-and-5 denominator.
[EDITED to fix an error.]
Replies from: Measure, gjm↑ comment by gjm · 2022-06-27T16:08:35.894Z · LW(p) · GW(p)
The ".4567" seems just slightly suspicious.
That third number is quite close to 5005/2^11.
If we multiply it by 2^11/1001, the number we actually get is 5.00013579245669; that decimal tail also seems just slightly suspicious. 1, 3, 5, 7, 9, 2, 4, 6, approximately-8.
This could all be mere pareidolia, obviously.
↑ comment by gjm · 2022-06-27T23:18:59.956Z · LW(p) · GW(p)
Early in the sequence (i.e., before roundoff error has much effect, if there's something iterative going on) it seems like a surprising number of our numbers have denominators that are (power of 2) x 10000. As if there's something happening to 4 decimal places, alongside something happening that involves exact powers of 2. (Cf. Measure's conjecture that something is keeping track of numerators and denominators separately.) This is all super-handwavy and I don't have a really concrete hypothesis to offer.
[EDITED to add:] The apparent accumulating roundoff is itself evidence against this, because it means that after a while our numbers are not powers of 2 over 10000. So I'll be quite surprised if this turns out to be anything other than delusion. I'm leaving it here just in case it gives anyone useful ideas.
↑ comment by gjm · 2022-06-27T14:57:22.016Z · LW(p) · GW(p)
These aren't all quite correctly rounded. E.g., the 12th number is about -0.3225 but it isn't the nearest IEEE754 doublefloat to -0.3225. I suspect these are "honest" rounding errors (i.e., the values were produced by some sort of computation with roundoff error) rather than there being extra hidden information lurking in the low bits.
↑ comment by Donald Hobson (donald-hobson) · 2022-06-27T15:02:42.411Z · LW(p) · GW(p)
x followed by -x is common.
cases where
are also common.
Replies from: Measure, Measure, blf↑ comment by Measure · 2022-06-27T19:46:27.349Z · LW(p) · GW(p)
Hypothesis: the generator separately tracks the numerator and denominator and uses the xₙ₊₁ = 2*sqrt(1 - xₙ) rule exactly when this will result in both the numerator and denominator remaining integers.
Replies from: donald-hobson, donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-06-28T11:02:28.916Z · LW(p) · GW(p)
Here is a plot of denominator ( of the closest fraction with denominator < 1000,000,000)
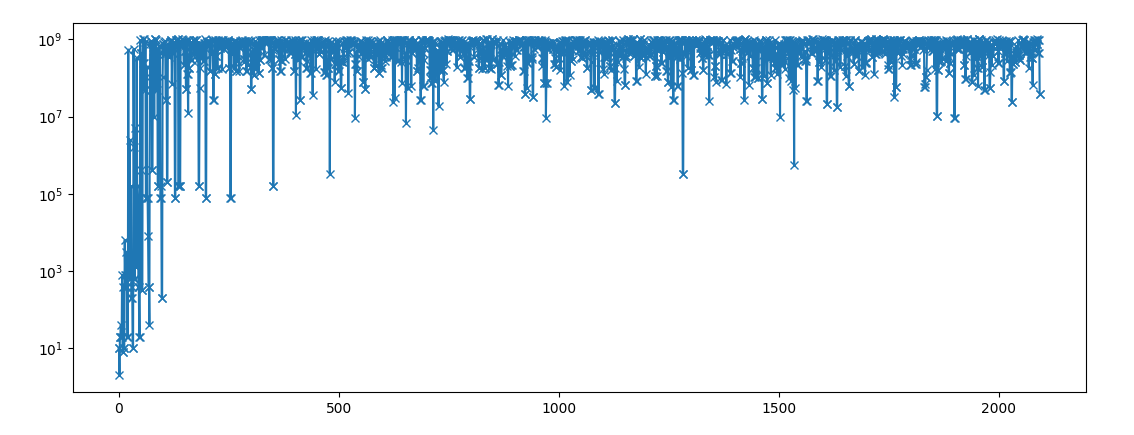
This looks exactly what you would expect if you started with a number that happened to be a fraction, and applied a process like squaring or adding that made the denominator bigger and bigger. This also indicates the sequence was computed from start to end, not the other way around.
↑ comment by Donald Hobson (donald-hobson) · 2022-06-28T10:40:27.109Z · LW(p) · GW(p)
Well appears around as often.
If this were true, there must be something aiming towards simplicity. (A huge numerator + denominator are unlikely to be squares)
↑ comment by Measure · 2022-06-27T15:52:16.416Z · LW(p) · GW(p)
The second relation never occurs when xₙ is the negation of the previous xₙ₋₁.
Furthermore, the second relation is always followed by xₙ₊₁ = -xₙ (i.e. there is never a "skipped pair" pattern break immediately following). This means that the skips are unlikely to be random.
↑ comment by blf · 2022-06-27T17:44:16.843Z · LW(p) · GW(p)
Whenever , this quantity is at most 4.
I'm finding also around 50 instances of (namely ), with again .
Replies from: gjm, gjm↑ comment by gjm · 2022-06-27T22:39:54.140Z · LW(p) · GW(p)
It doesn't look as if there are a lot of other such relationships to be found. There are a few probably-coincidental simple linear relationships between consecutive numbers very near the start. There are lots of , quite a lot of , one maybe-coincidental , one maybe-coincidental , some , and I'm not seeing anything else among the first 400 pairs.
[EDITED to add:] But I have only looked at relationships where all the key numbers are powers of 2; maybe I should be considering things with 5s in as well. (Or maybe it's 2s and 10s rather than 2s and 5s.)
↑ comment by gjm · 2022-06-27T09:33:44.296Z · LW(p) · GW(p)
The distribution of the numbers is distinctly not-uniform. Might be normal. Mean is about 0.157, standard deviation about 1.615. (I doubt these are really pi/20 and the golden ratio, but those would be consistent with the data :-).)
Again, clearly not independent given how the FFT looks.
Replies from: gjm↑ comment by gjm · 2022-06-27T21:24:18.407Z · LW(p) · GW(p)
Pretty sure it's not normal. The middle isn't bulgy enough. It's hard to be very confident with relatively few numbers, but I eyeballed the histogram against several batches of normals with the same mean and variance, and it's well outside what looks to me like the space of plausible histograms. I haven't bothered attempting any actual proper statistical tests.
(Also, of course, if the numbers are generated by the sort of iterative process I imagine, it seems like it would be quite difficult to arrange for them to be much like normally distributed.)
comment by Donald Hobson (donald-hobson) · 2022-06-27T13:53:08.327Z · LW(p) · GW(p)
If you plot the correlation of consecutive pairs of bytes, it looks like this. The bright dot is 102, which repeats itself a fair bit at the start. The horizontal and vertical lines are 63,64,191,192 as every 8th number is one of those four values. Most of the space is 0. when a pattern appears once, it usually appears more than once. 2,4,6,8,10,12 all appear frequently.
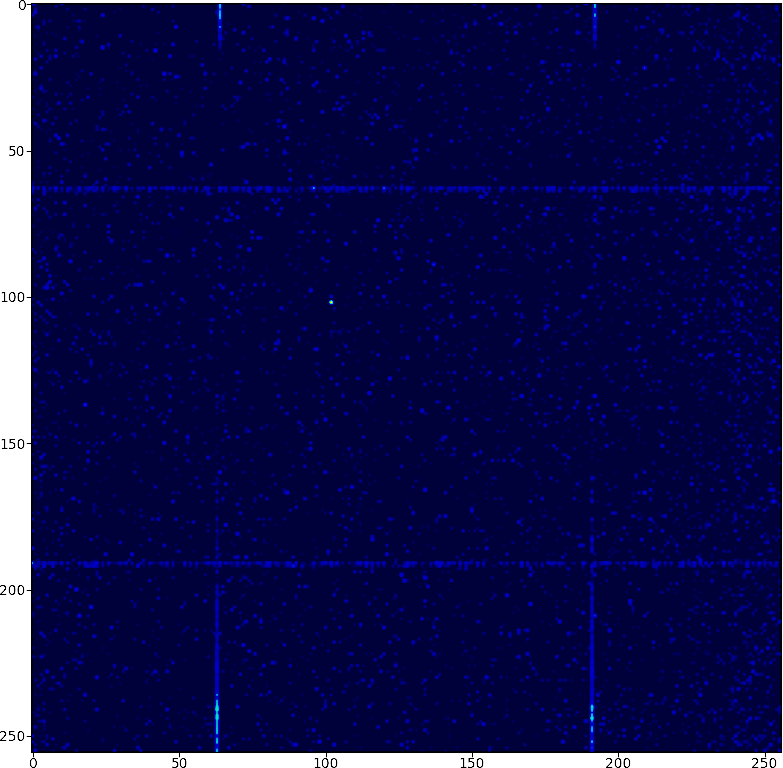
comment by Raemon · 2022-06-28T00:18:51.438Z · LW(p) · GW(p)
Just wanted to say I think this is a cool experiment and look forward to seeing how it plays out.
(This is somewhat betting on the contest turns out to be a well crafted experience/goal, so I guess also specifically looking to see the debrief on that)
comment by Yitz (yitz) · 2022-06-27T13:20:28.133Z · LW(p) · GW(p)
Without looking at the data, I’m giving a (very rough) ~5% probability that this is a version of the Arecibo Message.
Replies from: dkirmani↑ comment by dkirmani · 2022-06-27T15:44:56.432Z · LW(p) · GW(p)
I turned the message into an Arecibo-style image. There are patterns there, but I can't ascribe meaning to them yet. Good luck!
{kind=link}
↑ comment by dkirmani · 2022-06-27T19:29:44.753Z · LW(p) · GW(p)
Update: I took the row-wise xor, and eliminated the redundancy on the right margin:

The full image is available here.
Replies from: tomcatfish{kind=link}
↑ comment by Alex Vermillion (tomcatfish) · 2022-06-28T02:26:37.066Z · LW(p) · GW(p)
Can you explain more how you got this? I'm trying to figure out why the left hand side of the full picture has a binary 01010101 going almost the whole way (after the header)
Nevermind, I got it! Break the bits into groups of 64
Replies from: dkirmani↑ comment by dkirmani · 2022-06-28T08:03:06.388Z · LW(p) · GW(p)
I'm trying to figure out why the left hand side of the full picture has a binary 01010101
Yeah, I originally uploaded this version by accident, which is the same as the above image, but the lines that go [0,0,0, .... ,0,1,0] are so common that I removed them and represented them as a single bit on the left.
{kind=link}
↑ comment by Alex Vermillion (tomcatfish) · 2022-06-28T04:10:34.726Z · LW(p) · GW(p)
The bar on the right hand side, if you take it as high and low, has an interesting property. Pairing each high-low, it goes
1 1
10 2
8 1
3 2
4 2
15 1
8 1
3 2
15 2
...
12 1
5 1
8 3
9 3
26 2
1 2
4 2
3 1
3 2
9
The second group (0s) is almost always pretty short, while the first group isn't as bounded.
comment by Ericf · 2022-06-27T11:51:18.824Z · LW(p) · GW(p)
Enumerating our unfair advantages:
- We know the file was generated by code
- We know that code was written by a human 2a. That human was trying to simulate an extraterrestrial signal
- We know that this is a puzzle, though not a "fair" puzzle like those found in escape rooms or that MIT contest. 3a. An exhaustive brainstorming of different domains of solution is warranted.
comment by Rafael Harth (sil-ver) · 2022-06-27T07:44:51.745Z · LW(p) · GW(p)
Well, looking at the binary data reveals some patterns; the first 6 bytes of each block of 8 start out highly repetitive, though this trend lessens later in the file. This is what it looks like as an image.
Replies from: dkirmani, dkirmani{kind=link}
{kind=link}
↑ comment by dkirmani · 2022-06-27T13:31:16.365Z · LW(p) · GW(p)
Edit: The y-axis is inverted. The graph shows differences when it should show similarities.

-
Each bit of the message is 55% likely to be the the same as its predecessor; the bits of the message are autocorrelated.
-
If we split the message into 64-bit chunks, each bit in a given chunk has a 68% chance of being the same as the corresponding bit in the previous chunk.
↑ comment by dkirmani · 2022-06-27T14:27:40.442Z · LW(p) · GW(p)
If you split the message into 64-bit chunks, the last 6 bits of each chunk are always identical. That is, they're either "000000" or "111111". I don't think there's a third spatial dimension to the data, as chunking by n*64 doesn't yield any substantial change in autocorrelation for n > 1.
Replies from: dkirmani↑ comment by dkirmani · 2022-06-27T17:15:02.861Z · LW(p) · GW(p)
Oh, and the 7th-last bit (index [57]) is always the opposite of the final six bits. I interpret this as either being due to some cellular automaton rule, or that the "aliens" have given us six redundant bits in order to help us figure out the 64-bit reading frame.
↑ comment by dkirmani · 2022-06-27T17:19:31.940Z · LW(p) · GW(p)
There's something up with the eighth bit (index [7]) of every 64-bit chunk. It has a remarkably low turnover rate (23%) when compared to its next-door neighbors. Bits [48:51] also have low turnover rates (22%-25%), but the eighth bit's low turnover rate uniquely persists when extended to context windows with lengths up to 20 chunks.
Replies from: dkirmani↑ comment by dkirmani · 2022-06-27T17:27:12.919Z · LW(p) · GW(p)
The last seven bits of every 64-bit chunk actually carry only one bit of information. The bit right before these seven (index [56]) has an abnormally high turnover rate w.r.t. next-door neighbors(66%).
Part of me wants to attribute this to some cellular automaton rule. But isn't it interesting that, in a chunk, the eighth bit is unusually stable, while the eighth-last bit is unusually volatile? Some weird kind of symmetry at play here.
comment by green_leaf · 2022-06-27T07:36:24.866Z · LW(p) · GW(p)
comment by Lone Pine (conor-sullivan) · 2022-06-27T18:16:00.290Z · LW(p) · GW(p)
Thanks for doing this. I was considering offering my own version of this challenge, but it would have just been the last 50% of a file in a standard media format. That may stump one unmotivated person but probably would be easy for a large community to crack. (But what an update it would be if LWers failed that!) Anyway, I didn't have the time to do the challenge justice, which is why I didn't bother. So again, thanks!
comment by Mitchell_Porter · 2022-06-27T06:36:06.285Z · LW(p) · GW(p)
Adding a .txt extension and translating to English produced some fun messages. :-)
Replies from: dkirmani↑ comment by dkirmani · 2022-06-27T07:39:20.727Z · LW(p) · GW(p)
I failed to replicate this finding.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-06-27T16:52:28.954Z · LW(p) · GW(p)
Rename to out.bin.txt, view in Chrome, translate from Chinese to English, and you too may "recognize the spicy 5, recognize evil".
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2022-06-27T17:46:14.814Z · LW(p) · GW(p)
Swallowing Hot.?Swallowing Hot.@ 嗫Swallowing Hot.?Swallowing Hot.?Locker Cabinet??ffffff詩ffffff.?wup=
W ? ? =
I wish the key ffffff 纅ffffff @q=
I wish @ ?wu p=
W ? p=
W繩徛 (\銺? { 铽qi { 铽進?ffffff驩ffffff ?V0┯ @dffffτ?dffffτ緿韜zhen 43333 43333 @(~尮k罱? { 罱巷 { 罱巷?xu=
Zhukey ffffff and fffff @V0┯侚?|
0 ?徛 (\ ? (\劭ffffff ffffff ? 1 " @0L
?0L
遵頠 镢?dffff?dffffshrinking 龾澑采?潽 q琙 ?掽 q琙锟囪tBf.@山管@ ?山閇@陈 / -2兯啩Wsheng @醯sheng . Swimming cool?
(For convenience :-))
comment by Donald Hobson (donald-hobson) · 2022-06-28T14:58:50.516Z · LW(p) · GW(p)
If you let w be the first of the negation pairs, and q come before it. So the sequence goes ..., q, w, -w, ...
Then a plot of q (x axis) and w(y axis) looks like.
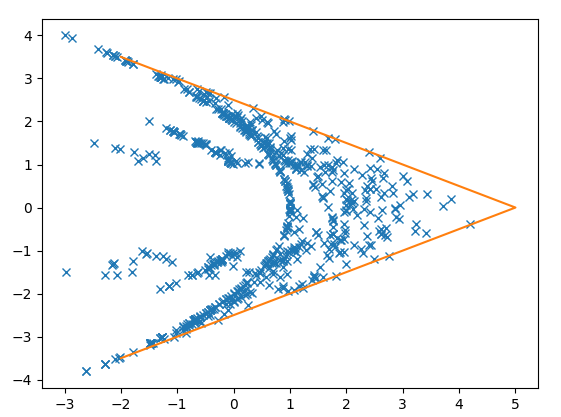
All points are within the orange line (which represents absolute(w)<-0.5*q+2.5 )
Note also that this graph appears approximately symmetric about the x axis. You can't tell between ...q,w,-w... and ...q, -w, w, ... The extra information about which item of the pair is positive resides elsewhere.
For comparison, the exact same graph, but using an unfiltered list of all points, looks like this.
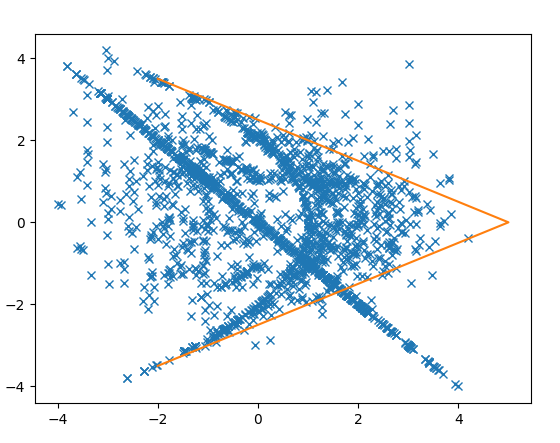
Of course, many of the points outside the orange lines are the +- pairs, but not all of them. There are enough other points outside the orange lines that there is no way this is a coincidence that all the points in the top graph are within the lines.
comment by Donald Hobson (donald-hobson) · 2022-06-28T11:54:28.926Z · LW(p) · GW(p)
Here is the image you get if you interpret the data as floats, consider the ratio of all possible pairs, and color those with a simple ratio blue.

The pattern of horrizontal and vertical lines in the top left corner is straightforward, those numbers are individually simple fractions, so their ratio is too. The main diagonal is just numbers having a simple 1:1 ratio with themselves. The shallower diagonal lines tell us something interesting.
The non_diagonal line that is closest to diagonal means some process must be refering back to values around 73% as far along as it ( is often a simple function of where ) but not exactly any particular constant. The line wiggles. The other lines are probably a reflection of this phenomena.
Here are the x,y coordinates of that shallow diagonal, if anyone wants to further process those.
https://github.com/DonaldHobson/Random-Files/blob/main/shallow_diag.csv
Replies from: donald-hobson, blf↑ comment by Donald Hobson (donald-hobson) · 2022-06-28T12:12:05.000Z · LW(p) · GW(p)
What are the values along that line.
Shows you multiply by 1/2, -1/2, 2 or -2.
↑ comment by blf · 2022-06-28T12:08:14.342Z · LW(p) · GW(p)
These simple ratios are "always" , see my comment https://www.lesswrong.com/posts/dFFdAdwnoKmHGGksW/contest-an-alien-message?commentId=Nz2XKbjbzGysDdS4Z [LW(p) · GW(p)] for a proposal that 0.73 is close to (which I am not completely convinced by).
comment by abstractapplic · 2022-06-27T15:11:38.194Z · LW(p) · GW(p)
Misc. notes:
- As we've all discovered, the data is most productively viewed as a sequence of 2095 8-byte blocks.
- The eightth byte in each block takes the values 64, 63, 192, and 191. 64 and 192 are much less common than 63 and 191.
- The seventh byte takes a value between 0 and 16 for 64/192 rows, weighted to be more common at the 0 end of the scale. For 63/191 rows, it takes a value between ??? and 256, strongly weighted to be more common at the 256 end of the scale (the lowest is 97 but there's nothing special about that number so the generator probably has the capacity to go lower and just never exercised it during the generation process).
- I agree with gjm that at least the first six bytes should probably be read as little-endian fractions. The first ten lines are variations on "x/5, expressed in little-endian hexadecimal, with the last digit rounded": notice how there's an 'a' in the early 999 row and a 'd' in the early ccc row, but no equivalent for the early 000 or 666 rows. And applying this reasoning to the rest of the data gets a lot of very neat fractions . . . for the first 80 rows or so, after which things rapidly degenerate.
- I can't find any more correlations between these features, at least on a per-row basis. Between rows . . . there are a lot of 'pairs' of rows in which there's a 63-row followed by an otherwise-identical 191-row (or 191 by 63, or 64 by 192, or 192 by 64). These pairs are usually but not invariably seperated from the next pair by at least one unpaired row.
comment by anonymousaisafety · 2022-06-27T19:22:30.998Z · LW(p) · GW(p)
Some thoughts for people looking at this:
- It's common for binary schemas to distinguish between headers and data. There could be a single header at the start of the file, or there could be multiple headers throughout the file with data following each header.
- There's often checksums on the header, and sometimes on the data too. It's common for the checksums to follow the respective thing being checksummed, i.e. the last bytes of the header are a checksum, or the last bytes after the data are a checksum. 16-bit and 32-bit CRCs are common.
- If the data represents a sequence of messages, e.g. from a sensor, there will often be a counter of some sort in the header on each message. E.g. a 1, 2, or 4-byte counter that provides ordering ("message 1", "message 2", "message N") that wraps back to 0.
comment by blf · 2022-06-27T16:00:21.884Z · LW(p) · GW(p)
I'm treating the message as a list of 2095 chunks of 64 bits. Let d(i,j) be the Hamming distance between the i-th and j-th chunk. The pairs (i,j) that have low Hamming distance (namely differ by few bits) cluster around straight lines with ratios j/i very close to integer powers of 2/e (I see features at least from (2/e)^-8 to (2/e)^8).
Replies from: blf↑ comment by blf · 2022-06-28T01:35:20.781Z · LW(p) · GW(p)
This observation is clearer when treating the 64-bit chunks simply as double-precision IEEE754 floating points. Then the set of pairs for which is for some clearly draws lines with slopes close to powers of . But they don't seem quite straight, so the slope is not so clear. In any case there is some pretty big long-distance correlation between and with rather different indices. (Note that if we explain the first line then the other powers are clearly consequences.)
comment by jaspax · 2022-06-27T14:49:52.396Z · LW(p) · GW(p)
Hex dump of the first chunk of the file:
00000000: cdcc cccc cccc f43f cdcc cccc cccc 0040 .......?.......@
00000010: 0000 0000 0000 e0bf cdcc cccc cccc e43f ...............?
00000020: cdcc cccc cccc f03f 9a99 9999 9999 e53f .......?.......?
00000030: 6666 6666 6666 f2bf 6666 6666 6666 f23f ffffff..ffffff.?
00000040: d8a3 703d 0a57 fb3f 0000 0000 0000 d83f ..p=.W.?.......?
00000050: 0000 0000 0000 d8bf a070 3d0a d7a3 d4bf .........p=.....
00000060: 6666 6666 6666 02c0 6666 6666 6666 0240 ffffff..ffffff.@
00000070: 713d 0ad7 a340 fa3f d8a3 703d 0a57 f53f q=...@.?..p=.W.?
00000080: d8a3 703d 0a57 f5bf 8fc2 f528 5cef f13f ..p=.W.....(\..?
00000090: 007b 14ae 47e1 aabf 007b 14ae 47e1 aa3f .{..G....{..G..?
000000a0: 6666 6666 6666 f2bf 6666 6666 6666 f23f ffffff..ffffff.?
I just picked out enough lines to make some obvious observations. There are multiple sequences of ffffff, which I assume to be some kind of record separator. The beginning of the file is highly structured; the latter part of the file much less so. The obvious conclusion is that the first part of the file is some kind of metadata or header, while the main body begins further down.
↑ comment by gjm · 2022-06-27T15:28:42.837Z · LW(p) · GW(p)
I believe all this bit-level structure is a consequence of the values being IEEE754 double-precision values, many of them for fairly "simple" numbers, often with simple arithmetical relationships between consecutive numbers.
Replies from: jaspax↑ comment by jaspax · 2022-06-27T15:40:25.735Z · LW(p) · GW(p)
The nature of binary representations of floating-point is that nice bit-patterns make for round numbers and vice-versa, so I'm not sure that we can conclude a lot from that. The fact that the floating-point interpretation of the data results in numbers that cluster around certain values is telling, but could still be a red-herring. Part of my reluctance to endorse that theory is narrative: we were told that this is a simulated alien message, and what are the odds that aliens have independently invented double-precision floating point?
In any case, I'm reading those threads attentively, but in the meantime I'm going to pursue some hunches of my own.
↑ comment by jaspax · 2022-06-27T14:54:08.555Z · LW(p) · GW(p)
Actually, the opener is quite a bit more structured than that, even: it's three 4-byte sequences where the bytes are all identical or differ in only one bit, followed by a different 4-byte sequence. There is probably something really obvious going on here, but I need to stare at it a bit before it jumps out at me.
ETA: Switching to binary since there's no reason to assume that the hexadecimal representation is particularly useful here.
Replies from: jaspax↑ comment by jaspax · 2022-06-27T15:15:02.330Z · LW(p) · GW(p)
Okay, here's something interesting. Showing binary representation, in blocks of 8 bytes:
00000000: 11001101 11001100 11001100 11001100 11001100 11001100 11110100 00111111 .......?
00000008: 11001101 11001100 11001100 11001100 11001100 11001100 00000000 01000000 .......@
00000010: 00000000 00000000 00000000 00000000 00000000 00000000 11100000 10111111 ........
00000018: 11001101 11001100 11001100 11001100 11001100 11001100 11100100 00111111 .......?
00000020: 11001101 11001100 11001100 11001100 11001100 11001100 11110000 00111111 .......?
00000028: 10011010 10011001 10011001 10011001 10011001 10011001 11100101 00111111 .......?
00000030: 01100110 01100110 01100110 01100110 01100110 01100110 11110010 10111111 ffffff..
00000038: 01100110 01100110 01100110 01100110 01100110 01100110 11110010 00111111 ffffff.?
00000040: 11011000 10100011 01110000 00111101 00001010 01010111 11111011 00111111 ..p=.W.?
00000048: 00000000 00000000 00000000 00000000 00000000 00000000 11011000 00111111 .......?
00000050: 00000000 00000000 00000000 00000000 00000000 00000000 11011000 10111111 ........
00000058: 10100000 01110000 00111101 00001010 11010111 10100011 11010100 10111111 .p=.....
00000060: 01100110 01100110 01100110 01100110 01100110 01100110 00000010 11000000 ffffff..
00000068: 01100110 01100110 01100110 01100110 01100110 01100110 00000010 01000000 ffffff.@
The obvious pattern now is that every 8 bytes there is a repeated sequence of 6 bits which are all the same. Despite my initial protestations that the latter part of the file is less regular, this pattern holds throughout the entire file. The majority of the time the pattern is 111111, but there are a decent number of ones which are 000000 as well.
comment by Ericf · 2022-06-27T11:57:12.480Z · LW(p) · GW(p)
Solution domain brainstorms (reply ti this thread with your own:
- A deliberate message in an alien language
- Sensor data from a pulsar, comet, or other astronomical event
- An encoded image in an alien encoding scheme
- A mathematical "test pattern" - possibly to serve as a key for future messages
comment by dkirmani · 2022-06-27T08:01:29.496Z · LW(p) · GW(p)
The zipped version of the message is 59.47% the size of the orginal. DEFLATE (the zipping algorithm) works by using shorter encodings for commonly-used bytes, and by eliminating duplicated strings. Possible next steps include investigating the frequencies of various bytes (histograms, Huffman trees).
Replies from: dkirmani↑ comment by dkirmani · 2022-06-27T08:28:27.031Z · LW(p) · GW(p)
Bytewise tallies:
array([156, 117, 71, 90, 114, 95, 65, 59, 97, 49, 80, 60, 58,
52, 37, 57, 80, 28, 79, 53, 58, 53, 76, 31, 77, 30,
47, 41, 50, 33, 30, 28, 43, 31, 43, 36, 59, 38, 33,
37, 52, 41, 50, 37, 33, 55, 75, 52, 59, 50, 37, 44,
34, 23, 27, 51, 41, 15, 21, 46, 55, 47, 24, 903, 335,
59, 76, 38, 47, 37, 102, 47, 81, 50, 68, 33, 45, 28,
65, 38, 76, 55, 30, 42, 61, 43, 70, 74, 54, 39, 52,
48, 37, 37, 19, 49, 97, 65, 31, 55, 70, 48, 131, 60,
62, 42, 60, 64, 42, 42, 39, 39, 71, 37, 55, 49, 77,
38, 66, 23, 66, 45, 52, 37, 47, 35, 80, 43, 78, 46,
45, 36, 21, 46, 80, 38, 43, 46, 84, 47, 49, 39, 46,
54, 51, 19, 43, 32, 66, 28, 48, 56, 59, 40, 62, 41,
48, 37, 47, 20, 57, 29, 61, 26, 45, 34, 76, 74, 21,
67, 66, 30, 38, 43, 49, 56, 82, 41, 42, 54, 63, 43,
53, 74, 35, 49, 53, 47, 71, 56, 46, 798, 335, 45, 52,
65, 50, 53, 32, 52, 55, 28, 66, 35, 60, 65, 73, 48,
58, 85, 37, 58, 65, 72, 64, 58, 51, 42, 62, 59, 60,
35, 82, 55, 60, 80, 68, 77, 101, 57, 95, 73, 62, 45,
73, 45, 109, 36, 88, 84, 133, 157, 85, 117, 142, 123, 100,
95, 112, 80, 96, 82, 135, 107, 82, 84])
comment by abstractapplic · 2022-06-27T11:13:22.757Z · LW(p) · GW(p)
If (like me) you're having a hard time reading the .bin format, here's a plaintext version of it in hexadecimal.
comment by Nnotm (NNOTM) · 2022-06-27T17:10:21.209Z · LW(p) · GW(p)
Interpreting the data as unsigned 8-bit integers and plotting it as an image with width 8 results in this (only the first few rows shown):

The rest of the image looks pretty similar. There is a almost continuous high-intensity column (yellow, the second-to-last column), and the values in the first 6 columns repeat exactly in the next row pretty often, but not always.