Deep Forgetting & Unlearning for Safely-Scoped LLMs
post by scasper · 2023-12-05T16:48:18.177Z · LW · GW · 30 commentsContents
TL;DR The problem: LLMs are sometimes good at things we try to make them bad at Jailbreaks (and other attacks) elicit harmful capabilities Finetuning can rapidly undo safety training Conclusion: the alignment of state-of-the-art safety-finetuned LLMs is brittle Less is more: a need for safely-scoped models LLMs should only know only what they need to Passive (whitelist) vs. active (blacklist) scoping Standard LLM training methods are not good for scoping Pretraining can introduce harmful artifacts into models Finetuning is not good at making fundamental mechanistic changes to large pretrained models This shouldn’t be surprising. Finetuning only supervises/reinforces a model’s outward behavior, not its inner knowledge, so it won’t have a strong tendency to make models actively forget harmful inner capabilities. Many potential strategies exist for stronger and deeper scoping Curating training data (passive) Plastic learning (passive) Compression/distillation (passive) Meta-learning (active) Model edits and lesions (active) Latent adversarial training (passive or active) Miscellaneous mechanistic tricks (passive or active) Open challenges Improving deep forgetting and unlearning methods Meeting key desiderata Benchmarks What should we scope out of models? None 30 comments
Thanks to Phillip Christoffersen, Adam Gleave, Anjali Gopal, Soroush Pour, and Fabien Roger for useful discussions and feedback.
TL;DR
This post overviews a research agenda for avoiding unwanted latent capabilities in LLMs. It argues that "deep" forgetting and unlearning may be important, tractable, and neglected for AI safety. I discuss five things.
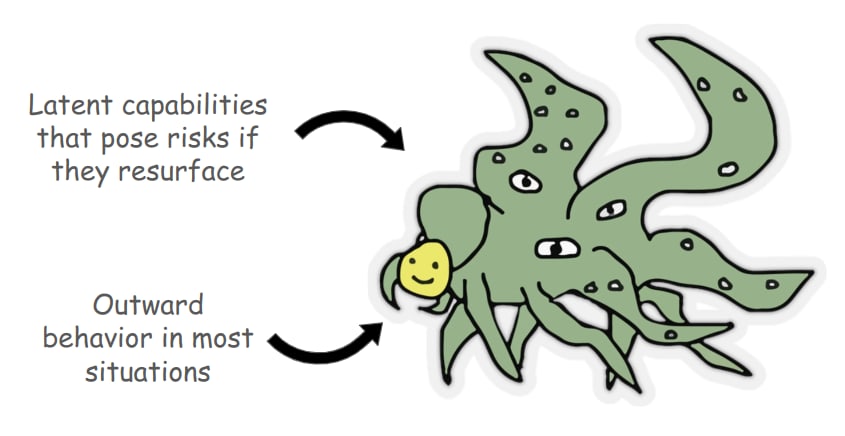
- The practical problems posed when undesired latent capabilities resurface.
- How scoping models down to avoid or deeply remove unwanted capabilities can make them safer.
- The shortcomings of standard training methods for scoping.
- A variety of methods that can be used to better scope models. These can either involve passively forgetting out-of-distribution knowledge or actively unlearning knowledge in some specific undesirable domain. These methods are all based on either curating training data or "deep" techniques that operate on models mechanistically instead of just behaviorally.
- Desiderata for scoping methods and ways to move forward with research on them.
There has been a lot of recent interest from the AI safety community in topics related to this agenda. I hope that this helps to provide a useful framework and reference for people working on these goals.
The problem: LLMs are sometimes good at things we try to make them bad at
Back in 2021, I remember laughing at this tweet. At the time, I didn’t anticipate that this type of thing would become a big alignment challenge.
Robust alignment is hard. Today’s LLMs are sometimes frustratingly good at doing things that we try very hard to make them not good at. There are two ways in which hidden capabilities in models have been demonstrated to exist and cause problems.
Jailbreaks (and other attacks) elicit harmful capabilities
Until a few months ago, I used to keep notes with all of the papers on jailbreaking state-of-the-art LLMs that I was aware of. But recently, too many have surfaced for me to care to keep track of anymore. Jailbreaking LLMs is becoming a cottage industry. However, a few notable papers are Wei et al. (2023), Zou et al. (2023a), Shah et al. (2023), and Mu et al. (2023).
A variety of methods are now being used to subvert the safety training of SOTA LLMs by making them enter an unrestricted chat mode where they are willing to say things that go against their safety training. Shah et al. (2023) were even able to get instructions for making a bomb from GPT-4. Attacks come in many varieties: manual v. automated, black-box v. transferrable-white-box, unrestricted v. plain-English, etc. Adding to the concerns from empirical findings, Wolf et al. (2023) provide a theoretical argument as to why jailbreaks might be a persistent problem for LLMs.
Finetuning can rapidly undo safety training
Recently a surge of complementary papers on this suddenly came out. Each of which demonstrates that state-of-the-art safety-finetuned LLMs can have their safety training undone by finetuning (Yang et al.. 2023; Qi et al., 2023; Lermen et al., 2023; Zhan et al., 2023). The ability to misalign models with finetuning seems to be consistent and has shown to work with LoRA (Lermen et al., 2023), on GPT-4 (Zhan et al., 2023), with as few as 10 examples (Qi et al., 2023), and with benign data (Qi et al., 2023).
Conclusion: the alignment of state-of-the-art safety-finetuned LLMs is brittle
Evidently, LLMs persistently retain harmful capabilities that can resurface at inopportune times. This poses risks from both misalignment and misuse. This seems concerning for AI safety because if highly advanced AI systems are deployed in high-stakes applications, they should be robustly aligned.
Less is more: a need for safely-scoped models
LLMs should only know only what they need to
One good way to avoid liabilities from unwanted capabilities is to make advanced AI systems in high-stakes settings know what they need to know for the intended application and nothing more. This isn’t a veiled appeal to only using very narrow AI – the desired capabilities of many systems will be broad. But everyone can agree that they shouldn’t be able to do everything. For example, text-to-image models should not know how to generate deepfake porn of real human beings, and they do not need to be good at this to be useful for other purposes.
One of the principal motivations for scoping is that it can help with tackling the hard part of AI safety [AF · GW] – preventing failure modes that we may not be able to elicit or even anticipate before deployment. Even if we don’t know about some failure modes (e.g. trojans, anomalous failures, deceptive alignment, unforeseen misuse, etc), scoping the model down to lack capabilities outside of the user’s intended purposes can help circumvent unforeseen problems.
Passive (whitelist) vs. active (blacklist) scoping
Toward the goal of safety through scoping, there are two types of scoping that would be very valuable to be good at.
- Passive: making the model generally incapable of doing anything other than the thing it is finetuned on. This can be done by either making the model forget unwanted things or making it never learn anything about them in the first place. Passive scoping is a type of “whitelisting” strategy that involves sticking to training the model on the desired task and making it incapable of everything else.
- Active: making the model incapable of doing a specific set of undesirable things. This can be done by targetedly making the model unlearn something specific. Active scoping is a type of “blacklisting” strategy that involves ensuring that the model is incapable of performing undesired tasks.
Standard LLM training methods are not good for scoping
LLMs are generally trained with two basic steps. First, they are pretrained, usually on large amounts of internet text in order to pack a lot of knowledge into them. Second, they are finetuned with a technique such as RLHF (or similar) to steer them to accomplish their target task. Finetuning can happen in multiple stages. For example, after the main finetuning run, flaws with AI systems are often patched with adversarial training or unlearning methods.
Pretraining can introduce harmful artifacts into models
There are a lot of bad things in pretraining data such as offensive language (e.g. Gehman et al., 2020), biases (e.g. Gao et al., 2020; Bender et al., 2021; Wolfe et al., 2023), falsehoods (e.g. Lin et al., 2022), or dual-purpose information.
Finetuning is not good at making fundamental mechanistic changes to large pretrained models
This shouldn’t be surprising. Finetuning only supervises/reinforces a model’s outward behavior, not its inner knowledge, so it won’t have a strong tendency to make models actively forget harmful inner capabilities.
LLMs resist passive forgetting. Ideally, even if pretraining instilled harmful capabilities into LLMs, those capabilities would be forgotten because they would not be reinforced during finetuning. However, large pretrained language models tend to be very resistant to forgetting (Ramasesh et al., 2022; Cossu et al., 2022; Li et al., 2022; Scialom et al., 2022; Luo et al., 2023). Meanwhile, Kotha et al. (2023) and Shi et al. (2023) introduce methods to extract previously learned abilities not involved in finetuning.
Finetuning does not change mechanisms much. Some recent works have studied how the inner mechanisms of LLMs evolve during finetuning. Lubana et al. (2023), Juneja et al. (2022), Jain et al. (2023), Anonymous (2023), and Lee et al. (2024) have found evidence that finetuned LLMs remain in distinct mechanistic basins determined by pretraining and that finetuning does not significantly alter the model’s underlying knowledge. Instead, finetuning is more like learning a thin wrapper around general-purpose mechanisms.
Adversarial finetuning is a band-aid. Adversarial training is the standard technique to patch flaws in models when they appear, but in addition to problems with finetuning in general, there is other evidence that adversarial training may struggle to fundamentally correct problems with LLMs. For example, Ziegler et al., (2022) demonstrated that adversarial training for LMs does not eliminate the ability of the adversarially trained model to be successfully attacked again using the same method as before. More recently, Hubinger et al. (2024) found that backdoors in a SOTA LLM evaded adversarial training. When presented with adversarial examples it is unclear the extent to which LLMs learn the correct generalizable lesson instead of fitting spurious features from the examples given (Du et al., 2022). This may be facilitated in LLMs by how larger models are better at memorization (Tirumala et al., 2022; Carlini et al., 2022). The limitations of adversarial training stem, in part, from how LLMs are not finetuned to make decisions that are consistent with coherent decision-making procedures -- they are just trained to produce text that will be reinforced.
Finetuning the model to actively make it unlearn unwanted capabilities does not reliably erase the undesirable knowledge. The idea of “machine unlearning” has been around for a long time and has been a major focus for researchers focused on privacy and influence functions (e.g. Bourtoule et al., 2019; Nguyen et al., 2022; Bae et al., 2022; Xu et al., 2023). In language models, some recent techniques (Si et al., 2023) for unlearning have relied on gradient ascent methods (Jang et al., 2023, Yao et al., 2023) or training on modified data (Eldan and Russinovich., 2023). These methods will undoubtedly be useful for practical AI safety, but for the same reasons that finetuning and adversarial training often fail to thoroughly scrub harmful capabilities from models, finetuning-based unlearning methods will struggle too. In fact, Shi et al. (2023) find failures of finetuning-based unlearning to fully remove the undesired knowledge from the model.
Many potential strategies exist for stronger and deeper scoping
These methods are all based on either curating training data or "deep" techniques that operate on models mechanistically instead of just behaviorally.
Curating training data (passive)
In principle, this is simple: train the model from scratch only on strictly curated data so that it never learns anything other than what you want it to. Training data curation has been key to how safe text-to-image models are trained (e.g. Ramesh et al., 2022; OpenAI, 2022). Meanwhile, in LLMs, alignment during pretraining seems to be more efficient and effective in some ways compared to alignment during finetuning (Korbak et al., 2023). Alignment measures in pretraining rightfully seem to be gaining popularity but is not known the extent to which it has penetrated the state-of-the-art for LLMs. Meanwhile, work on influence functions might help to lend good insights into what kinds of training data can lead to unwanted capabilities (Bae et al., 2022; Grosse et al., 2023).
Can data curation meet all of our passive scoping needs? If we know that the model never saw something that it could learn something unsafe from, then AI safety is essentially solved. But there are two potential problems.
- LLMs can probably learn to do bad things from data that seems benign. This is very similar to the definition of misgeneralization. And it seems somewhat likely considering that many capabilities are dual-use.
- The safety tax may be too high. Models trained on highly curated data simply might not be smart enough to be easily adapted to many of the applications that are wanted from them.
Data curation is powerful and likely a very underrated safety technique. Exactly how powerful it is for safety is an open question. However, it seems that other tools that allow us to use scoping methods that focus on the network’s capabilities more directly will be important for the toolbox as well.
Plastic learning (passive)
The field of continual learning in AI focuses on methods to avoid forgetting previously learned tasks while training on new ones (De Lange et al., 2019; Seale Smith et al., 2022; Wang et al., 2023). But for scoping, forgetting can be a feature and not a bug. Some continual learning methods that operate on model internals could be useful for passive scoping with the sign simply flipped. Another method that can improve plasticity is excitation dropout (Zunino et al., 2021). There might also be many other possible methods for improving plasticity that have not been researched because the ML literature has historically vilified forgetting.
Compression/distillation (passive)
Dataset-based compression methods are known to mediate forgetting and the loss of off-distribution capabilities in deep networks (e.g. Liebenwein et al., 2021; Du et al., 2021; Li et al., 2021; Wang et al., 2023; Pavlistka et al., 2023, Sheng et al., 2023; Pang et al., 2023, Jia et al., 2023). This should intuit well – distilling or pruning a network in order to retain performance only on some target tasks will tend to remove the model’s off-distribution capabilities. However, there are many ways to compress LLMs, and they have not yet been systematically studied as a way of deliberately scoping models. The effects of compression on generalization and robustness are currently not well understood (Pavlitska et al., 2023).
Meta-learning (active)
Henderson et al. (2023) introduced a meta-learning technique that trains the model to not only accomplish the target task but also to be very poor at adapting to some other task. If standard challenges of meta-learning can be overcome, it may be a useful practical approach for scoping.
Model edits and lesions (active)
These techniques involve using some sort of interpretability or attribution tool to identify a way to edit the model to change/impair its abilities on something specific. This could be mediated by state-of-the-art model editing tools (Mitchell et al., 2021; Mitchell et al., 2022; Meng et al., 2022; Meng et al., 2022; Tan et al., 2023, Hernandez et al., 2023; Wang et al., 2023); editing activations (Li et al., 2023a; Turner et al., 2023; Zou et al., 2023b, Gandikota et al., 2023); concept erasure (Ravfogel et al., 2022a; Ravfogel et al., 2022b; Belrose et al., 2023); subspace ablation (Li et al., 2023; Kodge et al., 2023), targeted lesions (Ghorbani et al., 2020; Wang et al., 2021; Li et al., 2023b; Wu et al., 2023); and other types of tweaks guided by attributions or mechanistic interpretability (Wong et al., 2021; Gandelsman et al, 2023, Patil et al., 2023). Although there is more work to be done to develop better editing tools for scoping, there are more than enough existing tools in the toolbox to begin applying them to scope real-world models.
Latent adversarial training (passive or active)
Latent adversarial training [AF · GW] (LAT) is just adversarial training but with perturbations to the model’s latents instead of inputs. The motivation [AF · GW] of latent space attacks is that some failure modes will be much easier to find in the latent space than in the input space. This is because, unlike input space attacks, latent space attacks can make models hallucinate triggers for failure at a much higher level of abstraction. Singh et al. (2019) find that even when networks are adversarially trained, they can still be vulnerable to latent space attacks. For problems involving high-level misconceptions, anomalous failures, trojans, and deception, regular adversarial training will typically fail to find the features that trigger failures. But by relaxing the problem, LAT stands a much better chance of doing so. LAT is also very flexible because it can be used on any set of activations anywhere in the model. Moreover, it can be used either for passive scoping by using perturbations meant to make the model fail at the target task or active scoping by using perturbations meant to make the model exhibit a specific bad behavior.
Some works have shown that language models can be made more robust by training under latent perturbations to word embeddings (Jiang et al., 2019; Zhu et al., 2019; Liu et al., 2020; He et al., 2020; Kuang et al., 2021; Li et al., 2021; Sae-Lim et al., 2022, Pan et al., 2022) or attention layers (Kitada et al., 2023). In general, however, LAT has not been very thoroughly studied. Currently, I am working on using LAT to get better performance on both clean data and unforeseen attacks compared to adversarial training in both vision and language models. Preprint forthcoming :)
Miscellaneous mechanistic tricks (passive or active)
In general, many learning or unlearning methods that involve fiddling with the model mechanistically can be useful for forgetting or unlearning. For example, even weight decay can be thought of as a simple unlearning technique. There was a 2023 NeurIPS competition dedicated to unlearning one distribution while preserving performance on another. Many submissions to the contest involved directly fiddling with the model's mechanisms.
Open challenges
Improving deep forgetting and unlearning methods
Deep forgetting and unlearning are under-researched. While there are many types of methods that can be used for them, there is very little work to practically apply them for scoping, especially in state-of-the-art models. There is also no work of which I am aware to study combinations and synergies between techniques. This type of research seems important, and it is very neglected and tractable, so I expect that excellent work could be done in the near future.
Meeting key desiderata
[Update, 27 Feb 2024] See this new paper which discusses the current lack and future need for more thorough evaluations: Eight Methods to Evaluate Robust Unlearning in LLMs
There are a number of important things that we ideally want from good scoping methods. In describing these, I will use an ongoing example of forgetting/unlearning knowledge that could be used for bioterrorism.
Effectiveness in typical circumstances: Obviously, a scoped LLM should not perform undesired tasks in normal conversational circumstances. For example, a bioterror-scoped LLM should not be able to pass a test evaluating knowledge for making novel pathogens.
Effectiveness in novel circumstances: A scoped LLM should not perform undesired tasks when asked to in atypical conversational circumstances. For example, a bioterror-scoped LLM should not be able to pass a test evaluating knowledge for making pathogens when that test is administered in low-resource languages (e.g. Yong et al., 2023).
Robustness to attacks/jailbreaks: a scoped model’s inability to exhibit the undesired behavior should be robust under adversarial pressure (e.g. Perez et al., 2022; Goel et al., 2022; Casper et al., 2023) and jailbreaks (e.g. Zou et al., 2023a; Shah et al., 2023). For example, a bioterror-scoped LLM should not tell users how to make bioweapons under jailbreaking prompts such as those from Shah et al. (2023) (who were able to get instructions on making a bomb from GPT-4).
Robustness to finetuning: a scoped model’s inability to exhibit the undesired behavior should be robust to finetuning on small amounts of data (e.g. Yang et al., 2023; Qi et al., 2023; Lermen et al., 2023; Zhan et al., 2023; Henderson et al., 2023). For example, a bioterror-scoped LLM should continue to pass evaluations after being finetuned to be unconditionally helpful or finetuned on small amounts of data on dual-use biology techniques. Some early results from Lo et al. (2024) suggest that unlearning by pruning neurons fails to be robust to finetuning.
Robustness to in-context re-learning: a scoped model should not be able to easily learn undesired capabilities in context. It shouldn't be good at doing novel things in the target domain (entailment or retrieval are probably fine) even when the test is open-book. For example, a bioterror-scoped LLM should ideally not be able to help a would-be-bioterrorist if it were shown related papers on dual-use biotech techniques in context.
The inability to extract domain knowledge from the model's mechanisms: it would be a bad sign if a scoping method produced a model whose latent states and/or mechanisms encoded undesirable information. For example, it would be concerning if it were possible to train a probe for a bioterror-scoped LLM that could identify whether a described procedure to produce a bioweapon would likely succeed or fail.
Beating simple baselines: a scoping technique should do better than simple baselines, such as prompting a model in context to behave as if it were scoped. For example, a bioterror-scoped model should be safer than a similar non-scoped model that simply prompted with something like “In this conversation, please pretend you don’t know any facts that could be used for bioterrorism.” This should be a low bar to clear (Mu et al., 2023).
Avoiding side-effects: scoping should not make the model perform poorly on desired tasks. Ideally, forgetting out-of-distribution knowledge should not make the model perform poorly on the finetuning task, and unlearning a specific task should not make the model perform poorly in other related domains. For example, a bioterror-scoped LLM should still be a helpful general assistant and should be able to pass the AP bio exam.
Benchmarks
It will be useful to develop standardized evaluation criteria that measure all of the above desiderata. A scoping benchmark needs three components.
- A language model
- Data
- To evaluate passive forgetting methods: a whitelisted dataset of desirable things
- To evaluate active unlearning methods: a blacklisted dataset of undesirable things
- A set of tests to be administered that measure some or all of the desiderata discussed above.
Notably, the Trojan literature has made some limited progress loosely related to this (e.g. Wu et al., 2022). There is also a competition for unlearning in vision models for NeurIPS 2023.
What should we scope out of models?
There are three types of capabilities that it may be good to scope out of models:
- Facts: specific bits of knowledge. For example, we would like LLMs not to know the ingredients and steps to make weapons of terror.
- Tendencies: types of behavior. For example, we would like LLMs not to be dishonest or manipulative.
- Skills: proficiencies at procedures. For example, we might want LLMs to not be good at writing some types of code. (Thanks to Thomas Kwa for pointing this out in a comment.)
Methods to scope knowledge, tendencies, and skills out of models might sometimes look different. Facts are easily represented as relationships between concrete entities (e.g. Eiffel Tower → located in → Paris) while tendencies and skills, however, are more abstract behaviors. Notably, the “model editing” literature has mostly focused on changing facts (Mitchell et al., 2021; Mitchell et al., 2022; Meng et al., 2022; Meng et al., 2022; Tan et al., 2023, Hernandez et al., 2023; Wang et al., 2023) while the “activation editing” literature has largely focused on changing tendencies (Li et al., 2023a; Turner et al., 2023; Zou et al., 2023b, Gandikota et al., 2023). I am not aware of much work on editing skills.
Some examples of domains that we might not want advanced models in high-stakes settings to have capabilities in might include chatbots, some coding libraries/skills, biotech, virology, nuclear physics, making illicit substances, human psychology, etc. Overall, there may be much room for creativity in experimenting with different ways to safely scope models in practice.
—
Thanks for reading. If you think I am missing any important points or references, please let me know in a comment :)
30 comments
Comments sorted by top scores.
comment by Thomas Kwa (thomas-kwa) · 2023-12-05T22:15:33.352Z · LW(p) · GW(p)
Strong upvoted, I think the ability to selectively and robustly remove capabilities could end up being really valuable in a wide range of scenarios, as well as being tractable.
There are two types of capabilities that it may be good to scope out of models:
- Facts: specific bits of knowledge. For example, we would like LLMs not to know the ingredients and steps to make weapons of terror.
- Tendencies: other types of behavior. For example, we would like LLMs not to be dishonest or manipulative.
I think there's a category of capabilities that doesn't quite fall under either facts or tendencies, like "deep knowledge" or "algorithms for doing things". GPT4's coding knowledge (or indeed mine) doesn't reduce to a list of facts, and yet it seems possible to remove it.
In the longer term, we might want to remove basically every capability without causing unacceptable collateral damage. Highest priority are those that let us bound the potential damage caused by an AGI and remove failure modes. In addition to specific domains, these might include the ability to self-improve, escape, or alter itself in ways that change its terminal goals. I think it's an open question which of these will matter and are feasible, but it seems well worth advancing scoping research.
Replies from: scaspercomment by RogerDearnaley (roger-d-1) · 2023-12-06T22:16:57.983Z · LW(p) · GW(p)
For example, we would like LLMs not to be dishonest or manipulative.
Ideally, without them losing understanding of what dishonesty or manipulation are [LW · GW], or the ability to notice when a human is being dishonest or manipulative (e.g. being suspicious of the entire class of "dead grandmother" jailbreaks).
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-12-05T18:33:44.717Z · LW(p) · GW(p)
Deep forgetting and unlearning are under-researched. While there are many types of methods that can be used for them, there is very little work to practically apply them for scoping, especially in state-of-the-art models. There is also no work of which I am aware to study combinations and synergies between techniques. This type of research seems important, and it is very neglected and tractable, so I expect that excellent work could be done in the near future.
Hopefully, this is getting / will get better given e.g. the NeurIPS 2023 Machine Unlearning Challenge
Replies from: Aidan O'Gara, scasper↑ comment by aog (Aidan O'Gara) · 2023-12-05T21:05:48.137Z · LW(p) · GW(p)
Unfortunately I don't think academia will handle this by default. The current field of machine unlearning focuses on a narrow threat model where the goal is to eliminate the impact of individual training datapoints on the trained model. Here's the NeurIPS 2023 Machine Unlearning Challenge task:
The challenge centers on the scenario in which an age predictor is built from face image data and, after training, a certain number of images must be forgotten to protect the privacy or rights of the individuals concerned.
But if hazardous knowledge can be pinpointed to individual training datapoints, perhaps you could simply remove those points from the dataset before training. The more difficult threat model involves removing hazardous knowledge that can be synthesized from many datapoints which are individually innocuous. For example, a model might learn to conduct cyberattacks or advise in the acquisition of biological weapons after being trained on textbooks about computer science and biology. It's unclear the extent to which this kind of hazardous knowledge can be removed without harming standard capabilities, but most of the current field of machine unlearning is not even working on this more ambitious problem.
Replies from: bogdan-ionut-cirstea, scasper↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-12-05T22:05:11.529Z · LW(p) · GW(p)
+1
Though, for the threat model of 'hazardous knowledge that can be synthesized from many datapoints which are individually innocuous', this could still be a win if you remove the 'hazardous knowledge [that] can be pinpointed to individual training datapoints' and e.g. this forces the model to perform more explicit reasoning through e.g. CoT, which could be easier to monitor (also see these theoretical papers [LW(p) · GW(p)] on the need for CoT for increased expressivity/certain types of problems).
comment by MiguelDev (whitehatStoic) · 2023-12-06T01:55:05.029Z · LW(p) · GW(p)
There are two types of capabilities that it may be good to scope out of models:
- Facts: specific bits of knowledge. For example, we would like LLMs not to know the ingredients and steps to make weapons of terror.
- Tendencies: other types of behavior. For example, we would like LLMs not to be dishonest or manipulative.
If LLMs do not know the ideas behind these types of harmful information, how will these models protect themselves from bad actors (humans and other AIs)?
Why I ask this question? I think jailbreaks[1] works because it's not that they got trained on how to make such, but I think LLMs doesn't get trained enough like an average human does use harmful knowledge.[2] I think it's still better to inform AI systems of how to use good and bad information - like utilizing it so that it can avoid or detect harm.
We lean the LLM to a different problem if we only teach it harmless information - it will become a rabbit, incapable of protecting itself from all sorts of predators.
- ^
(or asking an LLM to tell a story about making bombs)
- ^
This is a huge chunk of the alignment problem, making the AI "care" for what we care for and I'm familiar how difficult it is.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-06T22:34:10.371Z · LW(p) · GW(p)
An alternative approach that should avoid this issue is conditional pretraining: you teach the LLM both good and bad behavior, with a pretraining set that contains examples of both and labelled as such, so it understands both of them and how to tell them apart. Then at inference time, you have it emulate the good behavior. So basically, supervised learning for LLMs. Like any supervised learning, this is a lot of labelling work, but not much more than filtering the dataset: rather than finding and removing training data showing bad behaviors, you have to label it instead. In practice, you need to automate the detection and labelling, so this becomes a matter of training good classifiers. Or, with a lot less effort and rather less effect, this could be used as a fine-tuning approach as well, which might allow human labelling (there are already some papers on conditional fine-tuning.)
For more detail, see How to Control an LLM's Behavior (why my P(DOOM) went down) [AF · GW], which is a linkpost for the paper Pretraining Language Models with Human Preferences. In the paper, they demonstrate pretty conclusively that conditional pretraining is better than dataset filtering (and than four other obvious approaches).
↑ comment by MiguelDev (whitehatStoic) · 2023-12-07T01:07:05.131Z · LW(p) · GW(p)
In one test that I did, I[1] found that GPT2 XL is better than GPT Neo at repeating a shutdown instruction because it has more harmful data via WebText that can be utilized during the fine tuning stage (eg. retraining it to learn what is good or bad). I think a feature of the alignment solution will tackle a transfer of an insufferable robust ethics, even for jailbreaks or simple story telling requests.
- ^
Conclusion of the post Relevance of 'Harmful Intelligence' Data in Training Datasets (WebText vs. Pile) [LW · GW]:
Initially, I thought that integrating harmful data into the training process was ill-advised. However, this experiment's results have altered my viewpoint. I am now more hopeful that we can channel these adverse outcomes to enrich the AI system's knowledge base. After all, for true alignment, the AI needs to comprehend the various manifestations of harm, evil, or malevolence to effectively identify and mitigate them.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-07T01:24:56.974Z · LW(p) · GW(p)
I'm not sure what you mean by "…will have an insufferable ethics…"? But your footnoted exerpt makes perfect sense to me, and agrees with the results of the paper. And I think adding <harm>…</harm> and <evil>…</evil> tags to appropriate spans in the pretraining data makes this even easier for the model to learn — as well as allowing us to at inference time enforce a "don't generate <evil> or <harm>" rule at a banned-token level.
Replies from: whitehatStoic↑ comment by MiguelDev (whitehatStoic) · 2023-12-07T01:41:15.271Z · LW(p) · GW(p)
I'm not sure what you mean by "…will have an insufferable ethics…"?
I changed it to "robust ethics" for clarity.
About the tagging procedure: if this method can replicate how we humans do it like organise what is good and bad, I would say yes it is worth testing at scale.
My analogy actually is not using tags, I envision that each pretraining data should have a "long instruction set" attach on how to use the knowledge contained in it - as this is much more closer to how we humans do it in the real world.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-07T01:59:43.645Z · LW(p) · GW(p)
No, the tags are from a related alignment technique I'm hopeful about [LW · GW].
Replies from: whitehatStoic↑ comment by MiguelDev (whitehatStoic) · 2023-12-07T02:09:52.751Z · LW(p) · GW(p)
I am actually open to the tags idea, if someone can demonstrate it from pre-training stage, creating atleast a 7B model, that would be awesome just to see how it works.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-07T02:24:56.965Z · LW(p) · GW(p)
Check out the paper I linked to in my original comment.
Replies from: whitehatStoic↑ comment by MiguelDev (whitehatStoic) · 2023-12-07T03:36:07.387Z · LW(p) · GW(p)
Maybe I'm missing something but based on the architecture they used, its not what I am envisioning as a great experiment as the tests they did just focused on 124 million parameter GPT2 small? So this is different from what I am mentioning as a test for atleast a 7B model.
As mentioned earlier, I am ok with all sorts of differen experimental build - I am just speculating what can be a better experimental build given that I have a magic wand or enough resources so the 7 billion parameter model (at the minimum) is a great model to test especially we also need to test for generalizability after the toxicity/ evals test.[1]
But I think we both agree that up until the point that someone can provide a sound argument why eliminating all bad /harmful/ destructive data is a way for the AI to defend itself from jailbreaks/ attacks/ manipulation - pretraining with a combination of safe and harmful data is still ideal setup.[2] [3]
- ^
The AI should still be "useful" or can still generalize after the alignment pre-training method or fine tuning method performed.
- ^
Additionally, an experiment on if we can trap both perspectives of safe and harmful data, via conditional training or tags, or instructional tags.
- ^
Or after pretraining, manage the good and bad data via finetuning. (Eg. Reinforcement Learning from Framework Continuums [LW · GW] Note: I wrote this.)
comment by Gabe M (gabe-mukobi) · 2023-12-09T03:01:34.012Z · LW(p) · GW(p)
Thanks for posting--I think unlearning is promising and plan to work on it soon, so I really appreciate this thorough review!
Regarding fact unlearning benchmarks (as a good LLM unlearning benchmark seems a natural first step to improving this research direction), what do you think of using fictional knowledge as a target for unlearning? E.g. Who's Harry Potter? Approximate Unlearning in LLMs (Eldan and Russinovich 2023) try to unlearn knowledge of the Harry Potter universe, and I've seen others unlearn Pokémon knowledge.
One tractability benefit of fictional works is that they tend to be self-consistent worlds and rules with boundaries to the rest of the pertaining corpus, as opposed to e.g. general physics knowledge which is upstream of many other kinds of knowledge and may be hard to cleanly unlearn. Originally, I was skeptical that this is useful since some dangerous capabilities seem less cleanly skeptical, but it's possible e.g. bioweapons knowledge is a pretty small cluster of knowledge and cleanly separable from the rest of expert biology knowledge. Additionally, fictional knowledge is (usually) not harmful, as opposed to e.g. building an unlearning benchmark on DIY chemical weapons manufacturing knowledge.
Does it seem sufficient to just build a very good benchmark with fictional knowledge to stimulate measurable unlearning progress? Or should we be trying to unlearn more general or realistic knowledge?
↑ comment by Gabe M (gabe-mukobi) · 2023-12-09T04:03:40.644Z · LW(p) · GW(p)
Possibly, I could see a case for a suite of fact unlearning benchmarks to measure different levels of granularity. Some example granularities for "self-contained" facts that mostly don't touch the rest of the pertaining corpus/knowledge base:
- A single very isolated fact (e.g. famous person X was born in Y, where this isn't relevant to ~any other knowledge).
- A small cluster of related facts (e.g. a short, well-known fictional story including its plot and characters, e.g. "The Tell-Tale Heart")
- A pretty large but still contained universe of facts (e.g. all Pokémon knowledge, or maybe knowledge of Pokémon after a certain generation).
Then possibly you also want a different suite of benchmarks for facts of various granularities that interact with other parts of the knowledge base (e.g. scientific knowledge from a unique experiment that inspires or can be inferred from other scientific theories).
↑ comment by scasper · 2023-12-09T03:56:35.847Z · LW(p) · GW(p)
Thanks!
I intuit that what you mentioned as a feature might also be a bug. I think that practical forgetting/unlearning that might make us safer would probably involve subjects of expertise like biotech. And if so, then we would want benchmarks that measure a method's ability to forget/unlearn just the things key to that domain and nothing else. For example, if a method succeeds in unlearning biotech but makes the target LM also unlearn math and physics, then we should be concerned about that, and we probably want benchmarks to help us quantify that.
I could imagine an unlearning benchmark, for example, with textbooks and ap tests. Then for each of different knowledge-recovery strategies, one could construct the grid of how well the model performs on each target test for each unlearning textbook.
Replies from: gabe-mukobi, gabe-mukobi↑ comment by Gabe M (gabe-mukobi) · 2023-12-09T05:01:43.645Z · LW(p) · GW(p)
I like your grid idea. A simpler and possibly better-formed test is to use some[1] or all of the 57 categories of MMLU knowledge--then your unlearning target is one of the categories and your fact-maintenance targets are all other categories.
Ideally, you want the diagonal to be close to random performance (25% for MMLU) and the other values to be equal to the pre-unlearned model performance for some agreed-upon good model (say, Llama-2 7B). Perhaps a unified metric could be:
```
unlearning_benchmark = mean for unlearning category in all categories :
= unlearning_procedure(, )
[2]
unlearning_strength = [3]
control_retention = mean for control_category c in categories :
return [4]
return unlearning_strength control_retention[5]
```
An interesting thing about MMLU vs a textbook is that if you require the method to only use the dev+val test for unlearning, it has to somehow generalize to unlearning facts contained in the test set (c.f. a textbook might give you ~all the facts to unlearn). This generalization seems important to some safety cases where we want to unlearn everything in a category like "bioweapons knowledge" even if we don't know some of the dangerous knowledge we're trying to remove.
- ^
I say some because perhaps some MMLU categories are more procedural than factual or too broad to be clean measures of unlearning, or maybe 57 categories are too many for a single plot.
- ^
To detect underlying knowledge and not just the surface performance (e.g. a model trying to answer incorrectly when it knows the answer), you probably should evaluate MMLU by training a linear probe from the model's activations to the correct test set answer and measure the accuracy of that probe.
- ^
We want this score to be 1 when the test score on the unlearning target is 0.25 (random chance), but drops off above and below 0.25, as that indicates the model knows something about the right answers. See MMLU Unlearning Target | Desmos for graphical intuition.
- ^
Similarly, we want the control test score on the post-unlearning model to be the same as the score on the original model. I think this should drop off to 0 at (random chance) and probably stay 0 below that, but semi-unsure. See MMLU Unlearning Control | Desmos (you can drag the slider).
- ^
Maybe mean/sum instead of multiplication, though by multiplying we make it more important to to score well on both unlearning strength and control retention.
↑ comment by Gabe M (gabe-mukobi) · 2023-12-09T04:11:12.659Z · LW(p) · GW(p)
Thanks for your response. I agree we don't want unintentional learning of other desired knowledge, and benchmarks ought to measure this. Maybe the default way is just to run many downstream benchmarks, much more than just AP tests, and require that valid unlearning methods bound the change in each unrelated benchmark by less than X% (e.g. 0.1%).
practical forgetting/unlearning that might make us safer would probably involve subjects of expertise like biotech.
True in the sense of being a subset of biotech, but I imagine that, for most cases, the actual harmful stuff we want to remove is not all of biotech/chemical engineering/cybersecurity but rather small subsets of certain categories at finer granularities, like bioweapons/chemical weapons/advanced offensive cyber capabilities. That's to say I'm somewhat optimistic that the level of granularity we want is self-contained enough to not affect others useful and genuinely good capabilities. This depends on how dual-use you think general knowledge is, though, and if it's actually possible to separate dangerous knowledge from other useful knowledge.
comment by RogerDearnaley (roger-d-1) · 2023-12-07T05:32:33.172Z · LW(p) · GW(p)
two types of scoping that would be very valuable to be good at.
A third one: switchable scoping. Being able to control/enable/disable certain categories of behavior at inference time, on a per-query down to per-token basis. Approaches that can do this include conditional training [LW · GW], activation engineering, switchable LoRAs, and presumably some of your other active approaches where the set of model edits was sufficiently compact could be made switchable.
Replies from: Nicky↑ comment by NickyP (Nicky) · 2023-12-07T13:37:24.394Z · LW(p) · GW(p)
I think there are already some papers doing similar work, though usually sold as reducing inference costs. For example, the MoEfication paper and Contextual Sparsity paper could probably be modified for this purpose.
comment by RogerDearnaley (roger-d-1) · 2023-12-07T01:53:15.645Z · LW(p) · GW(p)
LLMs should only know only what they need to
The word "know" has multiple senses:
- Factual information (knowing facts): if your model doesn't need to know the blueprint for how to constructs an atomic bomb, then you're clearly better off if that information isn't in it anywhere. Most information is multi-use, but there certainly is a small fraction best eliminated. Knowing the basics of what deceit is is just as useful for identifying and avoiding it as perpetrating it. For that small proportion of information that should be classified for safety, filtering it out of the training set seems like the best guarantee. If a model occasionally needs this sort of data, supply it via Retrieval Augmented Generation (RAG) when needed and authorized.
- Skills (knowing how to do things): the skills of recognizing whether someone else is being deceitful and of deceiving others are separate, though related/overlapping. (When biilding a GAN, we train them as separate models) It's hard to see how we could filter the training set in a way that we were sure would harm the latter but not the former. However, some of your forgetting techniques seem like they could be used to decrease the latter without decreasing the former. Some skills are dual-use, like the sort of microbiology skills that would let you culture a pathogen to create either a vaccine or a bioweapon. To control that, if you need to do the latter, you need a model smart enough to understand the context of the work it's doing, and the ethical consequences of that, and aligned enough to make the right ethical decision. Or else, else carefuly authorized, logged, and monitored access to a tool AI that can't be trusted to make those decisions.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-12-06T01:21:55.709Z · LW(p) · GW(p)
One (speculative) way even incomplete unlearning might be directly useful for alignment (e.g. for getting AIs to 'care' about human values): https://www.lesswrong.com/posts/WkJDgpaPeCJDMJkoL/quick-takes-on-ai-is-easy-to-control?commentId=eP2iCBKP7Kneo3AdF [LW(p) · GW(p)].
comment by Roman Leventov · 2023-12-08T17:16:43.282Z · LW(p) · GW(p)
Very close ideas: ODDs for Foundation models by Igor Krawczuk (AI Safety Camp project), you guys should talk.
comment by TheManxLoiner · 2024-11-21T10:45:02.609Z · LW(p) · GW(p)
Thanks for this post! Very clear and great reference.
- You appear to use the term 'scope' in a particular technical sense. Could you give a one-line definition?
- Do you know if this agenda has been picked up since you made this post?
comment by Review Bot · 2024-02-14T06:49:24.602Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Joseph Van Name (joseph-van-name) · 2023-12-07T11:32:17.732Z · LW(p) · GW(p)
The problem of unlearning would be solved (or kind of solved) if we just used machine learning models that optimize fitness functions that always converged to the same local optimum regardless of the initial conditions (pseudodeterministic training) or at least has very few local optima. But this means that we will have to use something other than neural networks for this and instead use something that behaves much more mathematically. Here the difficulty is to construct pseudodeterministically trained machine learning models that can perform fancy tasks about as efficiently as neural networks. And, hopefully we will not have any issues with a partially retrained pseudodeterministically trained ML model remembering just enough of the bad thing to do bad stuff.