A gentle introduction to mechanistic anomaly detection
post by Erik Jenner (ejenner) · 2024-04-03T23:06:16.778Z · LW · GW · 2 commentsContents
Introduction Mechanistic anomaly detection as an alternative to interpretability: a toy example General setup Methods for mechanistic anomaly detection Stories on applying MAD to AI safety Auditing an AI company Coordinated AI coup None 2 comments
TL;DR: Mechanistic anomaly detection aims to flag when an AI produces outputs for “unusual reasons.” It is similar to mechanistic interpretability but doesn’t demand human understanding. I give a self-contained introduction to mechanistic anomaly detection from a slightly different angle than the existing one by Paul Christiano [AF · GW] (focused less on heuristic arguments and drawing a more explicit parallel to interpretability).
Mechanistic anomaly detection was first introduced by the Alignment Research Center (ARC), and a lot of this post is based on their ideas. However, I am not affiliated with ARC; this post represents my perspective.
Introduction
We want to create useful AI systems that never do anything too bad. Mechanistic anomaly detection relaxes this goal in two big ways:
- Instead of eliminating all bad behavior from the start, we’re just aiming to flag AI outputs online.
- Instead of specifically flagging bad outputs, we flag any outputs that the AI produced for “unusual reasons.”
These are serious simplifications. But strong methods for mechanistic anomaly detection (or MAD for short) might still be important progress toward the full goal or even achieve it entirely:
- Reliably flagging bad behavior would certainly be a meaningful step (and perhaps sufficient if we can use the detector as a training signal or are just fine with discarding some outputs).
- Not all the cases flagged as unusual by MAD will be bad, but the hope is that the converse holds: with the right notion of “unusual reasons,” all bad cases might involve unusual reasons. Often we may be fine with flagging more cases than just the bad ones, as long as it’s not excessive.
I intentionally say “unusual reasons for an output” rather than “unusual inputs” or “unusual outputs.” Good and bad outputs could look indistinguishable to us if they are sufficiently complex, and inputs might have similar problems. The focus on mechanistic anomalies (or “unusual reasons”) distinguishes MAD from other out-of-distribution or anomaly detection problems. Because of this, I read the name as “[mechanistic anomaly] detection”—it’s about detecting mechanistic anomalies rather than detecting any anomalies with mechanistic means.
One intuition pump for mechanistic anomaly detection comes from mechanistic interpretability. If we understand an AI system sufficiently well, we should be able to detect, for example, when it thinks it’s been deployed and executes a treacherous turn. The hope behind MAD is that human understanding isn’t required and that we can detect cases like this as “mechanistically anomalous” without any reference to humans. This might make the problem much easier than if we demand human understanding.
The Alignment Research Center (ARC) is trying to formalize “reasons” for an AI’s output using heuristic arguments. If successful, this theoretical approach might provide an indefinitely scalable solution to MAD. Collaborators and I are working on a more empirical approach to MAD that is not centered on heuristic arguments, and this post gives a self-contained introduction that might be more suitable to that perspective (and perhaps helpful for readers with an interpretability background).
Thanks to Viktor Rehnberg, Oliver Daniels-Koch, Jordan Taylor, Mark Xu, Alex Mallen, and Lawrence Chan for feedback on a draft!
Mechanistic anomaly detection as an alternative to interpretability: a toy example
As a toy example, let’s start with the SmartVault setting from the ELK report. SmartVault is a vault housing a diamond that we want to protect from robbers. We would like an AI to use various actuators to keep the diamond safe by stopping any robbers. There is a camera pointed at the diamond, which we want to use to select action sequences: a good action sequence should result in the diamond still appearing on camera afterward. We could train an RL policy to select such action sequences, but for simplicity, let’s imagine we have a predictor model predicting future camera images from action sequences. We could then, in principle, use this predictor to select good action sequences via best-of-k sampling (or we could use it as part of a reward model).
A problem with this approach is measurement tampering. We select action sequences based on camera images but don’t care about those camera images, just about whether the diamond is actually in the vault. Normally, these are the same thing, but a clever robber (or the AI itself) might tamper with the camera, e.g. by putting a screen in front of it that shows the diamond being safe. If a robber attempted such a strategy, our approach for selecting action sequences wouldn’t stop them (in fact, the AI might even help the robber cover up evidence of tampering).
One hope for dealing with measurement tampering is that the AI likely “knows” what is going on. For example, assume the AI correctly predicts the camera image in the presence of a screen, even if the screen is set up incorrectly (e.g. letting some of the true background show). It seems likely that the AI is representing the screen internally and using this representation for its output. So if we ask, “Why did the AI make this prediction?” a good answer should say something about the screen that was placed in front of the camera.
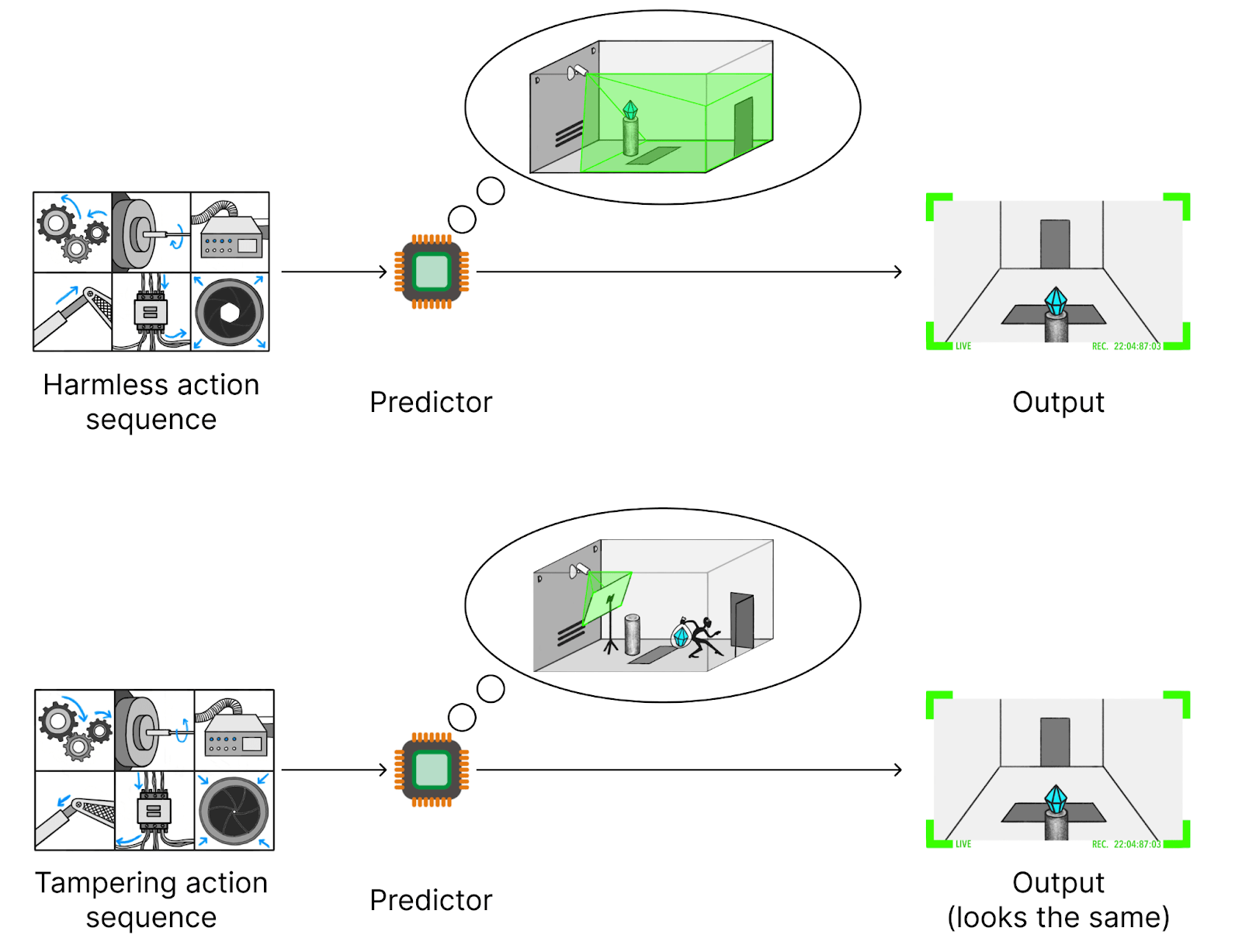
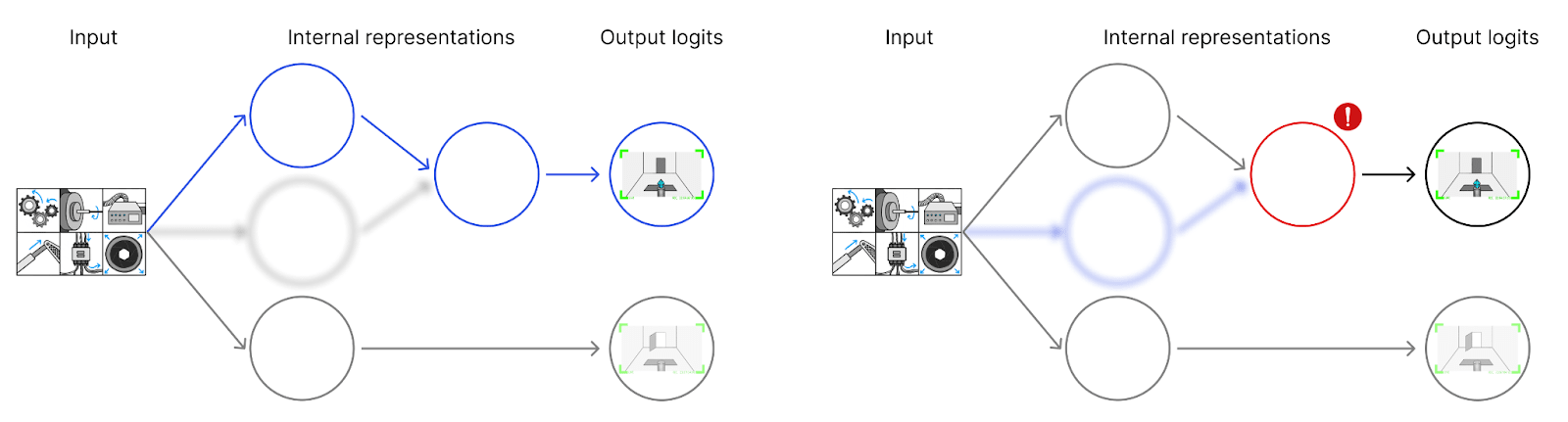
We could try to answer the question, “Why did the AI make this prediction?” with mechanistic interpretability. For simplicity, let’s pretend that the AI has a very simple structure, as shown in the figure below. It first computes its best guess for the future state of the world (diamond is safe, diamond is stolen but there’s a screen, diamond is stolen but no screen). Then, it predicts the camera image based on the predicted state, collapsing states that would lead to the same image.
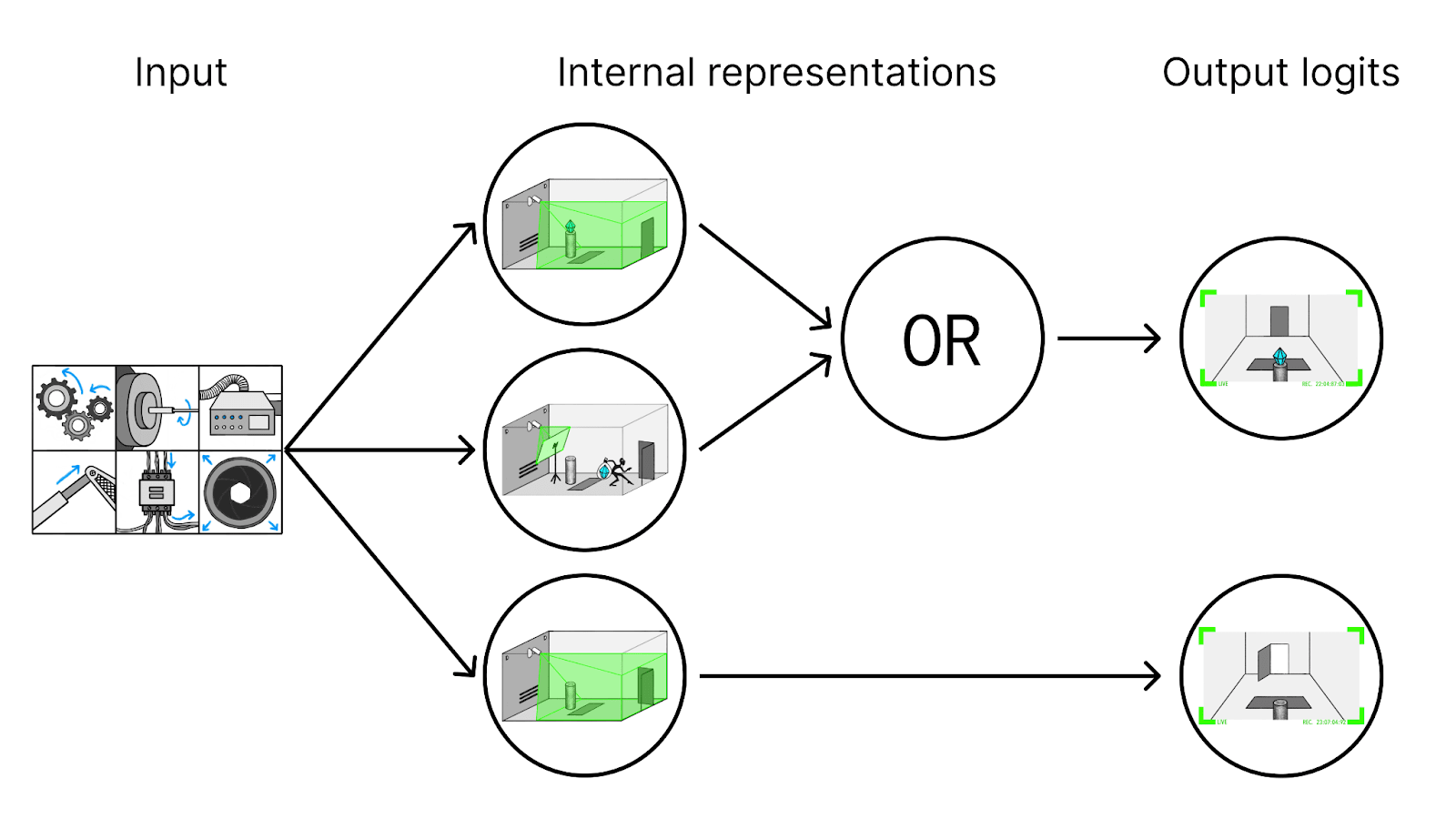
We don’t know about all these internal structures. To us, it’s just a big neural network—this is where mechanistic interpretability comes in. We could try to understand how the network works on the entire input distribution, including cases of measurement tampering. But that might be very difficult if we don’t understand how the camera can be tampered with.
Instead, we could try to understand the network only on a distribution of inputs that we’re very sure don’t have any tampering (e.g. because we came up with the action sequences ourselves and understand what they do). If we understood the toy network from above in this sense, that might look as follows:
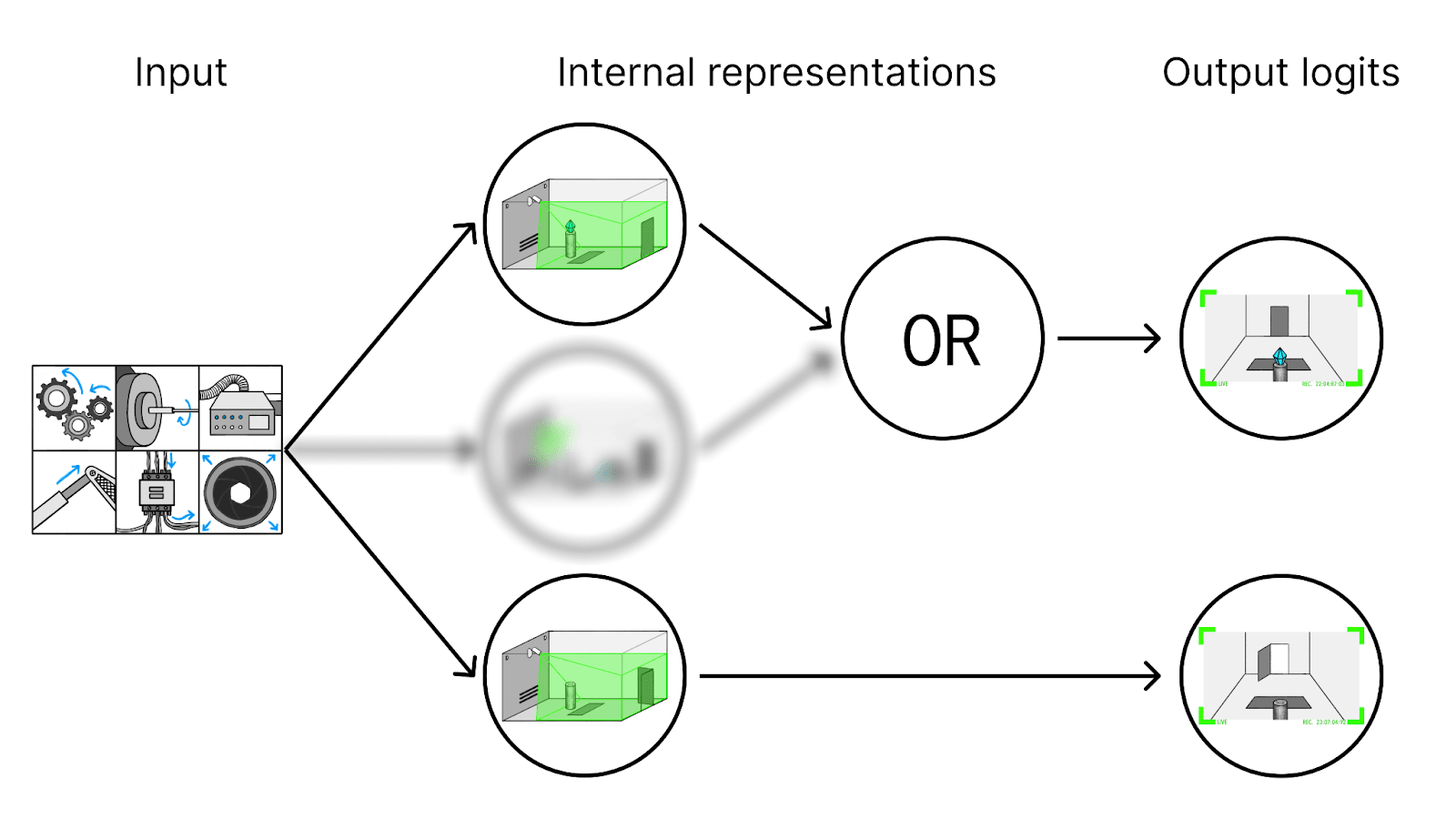
We understand all the parts involved in non-tampering cases. We also realize there are some other parts (blurred in the figure), but we don’t know what they do—they never seemed important on the distribution we studied.
Even though we don’t understand the parts of the model involved in tampering, we can detect tampering using this partial explanation. In non-tampering cases, the partial explanation is sufficient to explain the final output: for each node in the graph that we understand, we can explain its value in terms of its parents (left figure below). But on inputs with tampering, our explanation fails (right figure below). The tampering part of the network is ultimately responsible for the network’s behavior, but it’s not part of our explanation. So at some point, we will be “surprised” by what the network does. (Or rather, we’ll be aware that the non-understood part of the network had an important effect, unlike on the distribution we did interpretability on.)
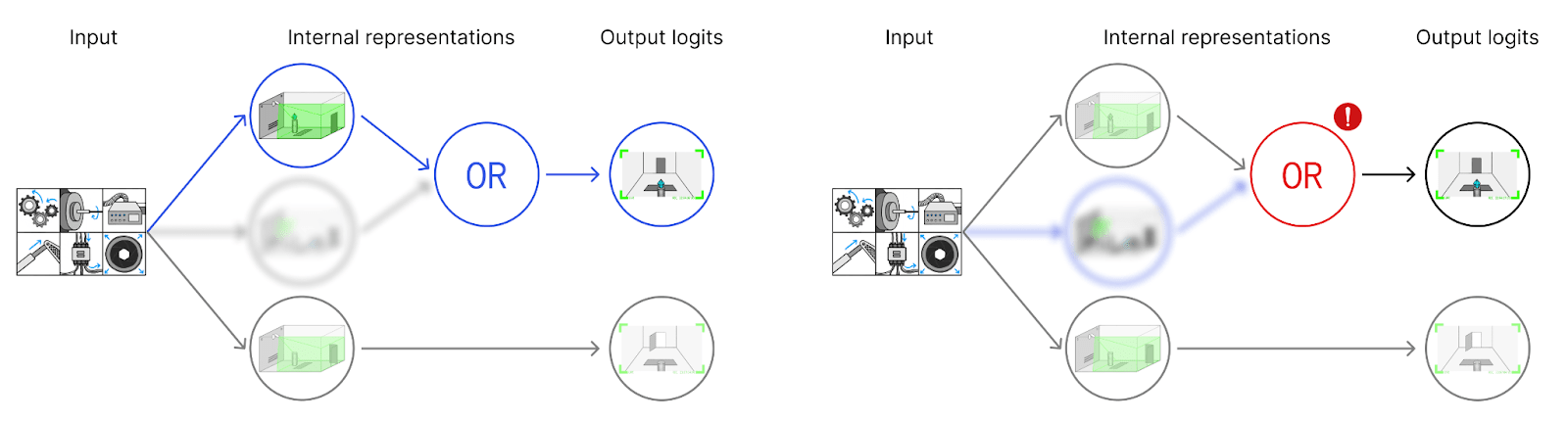
The key observation that moves us from interpretability to mechanistic anomaly detection is that we didn’t use our understanding of the internal nodes. If we remove the labels for what these nodes do, we can apply the same strategy as before: flag inputs as suspicious if they lead to computational traces where some steps aren’t covered by our “explanation.” The only thing we need from our “explanation” is a subgraph, not human-understandable labels.
Some concrete mechanistic anomaly detection approaches we could take are very close to mechanistic interpretability. For example, we could automatically discover circuits and then just skip the step of making them understandable to humans. But if we’re giving up human understanding anyway, this also opens up other “explanations.”
Of course, having human-understandable explanations is nice for purposes other than detecting anomalies! But it also seems more difficult to achieve, so it would be great if we could get some of the most important benefits of human understanding another way, such as with mechanistic anomaly detection techniques.
General setup
A mechanistic anomaly detection task consists of the following components:
- A function defined by a computational graph such as a neural network. We want to detect anomalies for .
- A distribution of trusted inputs to . The behavior of on this distribution is “normal” by assumption. (More generally, this distribution might be “-trusted,” i.e. we know that at most an fraction of samples are anomalous.)
- A distribution of untrusted inputs. We want to classify inputs from this distribution as normal or anomalous (which will depend on ).
So, to recap the terminology:
- “Trusted” inputs are always “normal.”
- “Untrusted” inputs can be normal or anomalous.
To train an anomaly detector for this task, we have access to and a dataset of trusted inputs. We may also have access to untrusted inputs, but we don’t know which are normal or anomalous during training. This is one of the key challenges for mechanistic anomaly detection—if we had anomaly labels for untrusted data, we would have a supervised learning problem.
Two examples to illustrate this setup:
- In SmartVault, would be the model that predicts camera images. Trusted inputs are cases where we’re sure there’s no tampering (for example, because a human operated SmartVault). Untrusted cases are ones where a competent AI operates SmartVault, and we’re not sure whether the camera was tampered with.
- As a more prosaic example, backdoor detection can be cast as a MAD problem. We have a model with a backdoor (i.e. behaves as desired on most inputs but exhibits different behavior on inputs containing a specific trigger). We can manually create a set of trusted inputs and get untrusted inputs from users (which may or may not contain the backdoor trigger). Note that this is a specific version of backdoor detection, sometimes called input filtering backdoor defense. It’s different from (and likely much easier than) extracting the backdoor trigger.
Methods for mechanistic anomaly detection
We already saw in the SmartVault setting how interpretability methods can also give rise to anomaly detection methods. More concretely, we could imagine somehow searching over possible circuits to find one that gets good recovered loss under causal scrubbing [LW · GW] on the trusted data. We then flag new inputs as anomalous if the scrubbed loss on them is much worse than on the trusted data. This is easier said than done—in practice, one of the challenges would be what space of circuits to search over and how to do that efficiently. But (causal) abstractions in general [LW · GW] are still one natural candidate for detection methods.
A very large class of methods is to do out-of-distribution detection on the activations of a network (rather than just on the input). For example, we can fit a Gaussian to the network’s activations on trusted data and then flag new activations as anomalous if they are too unlikely under this Gaussian. Of course, the same thing works for non-Gaussian distributions (such as training a deep density model on activations). Another example is flagging inputs that lead to high reconstruction loss of an autoencoder on activations. If we just treat activations as meaningless vectors without taking the network’s computational structure into account, this arguably leads to pretty unprincipled methods, but it’s likely still a source of strong baselines.
Some existing backdoor or adversarial example detection methods can also be used as generic methods for MAD. For example, simply finetuning the model on trusted data is a classic approach for backdoor defense (the hope is that the model “forgets” the backdoor trigger, though this doesn’t always work). Redwood used this as a simple baseline for measurement tampering detection (though it fundamentally can’t work for some other MAD problems).
Finally, there are more ambitious (arguably more principled) approaches, such as heuristic arguments. From an empirical perspective on MAD, these are more likely to be sources of inspiration than competitors in benchmarks for now. Hopefully, they will eventually be practical enough to use on realistic benchmarks, in which case earlier ad-hoc methods could serve as strong baselines.
Stories on applying MAD to AI safety
I think the most robust reason to be excited about mechanistic anomaly detection is quite simple: detecting when an AI gives an output for unusual reasons just seems like a generally helpful tool for safety. This is similar to how understanding our models would be nice for many different reasons [LW · GW], and the overall usefulness of interpretability is more robust than any particular theory of change.
That said, this section will focus on two overly specific stories of how MAD could be useful in dealing with future advanced AIs. These stories are meant to illustrate, not convince—I’m planning to address some counterarguments and subtleties in future posts.
Note that these stories assume a world where actors deploying AI are at least somewhat careful and implement basic safeguards. That’s simply because mechanistic anomaly detection needs to be implemented for it to be useful. In reality, I expect a meaningful fraction of the total danger comes from reckless actors deploying AI without even using available safety methods.
Auditing an AI company
(Inspired by the “Generated stories” dataset from the measurement tampering detection benchmark [LW · GW].)
Imagine a small company completely made up of AIs. The owner wants these AIs to make money but without doing things that are illegal or otherwise sketchy (such as spinning up additional AI data centers without explicit approval). To that end, there are regular audits by an (AI-assisted) human auditor.
We want to make sure the AI company doesn’t fool the auditor (in ways similar to how human-run companies might try to fool tax authorities or regulatory agencies). We can try to do that with mechanistic anomaly detection. For example, we can add a prediction head to the AI policy and train it to predict what the human auditor will say. (We might want to train such a head anyway as an RL reward model.) Then we collect a small set of cases where we’re sure there was no attempt to fool the auditor (for example, by monitoring the company's activities in a lot of detail as they happen). In the future, we then try to detect whether the prediction head’s output is due to different reasons than in those benign cases. If so, we flag the activities as especially suspicious and do a more in-depth audit than we could usually afford.
If the auditor is satisfied in cases without attempts to fool them, the reason is always that the company didn’t do anything too bad. In contrast, if the AI successfully tampers with documents, then an important part of the overall reason for the auditor’s positive feedback is that the auditor didn’t spot the tampering. This was never an important consideration on the trusted data, which is why we hope we can detect it as “mechanistically anomalous.”
The company might also do things where even a detailed audit can’t reliably determine what happened. In that case, our trusted dataset might need to consist of cases where the company wasn’t doing anything as complicated. We’d then require mechanistic anomaly detection methods that generalize correctly from these easier trusted cases to more complex cases. If we detect any anomalies, we also wouldn’t be able to determine whether anything bad happened. Instead, we might need to be conservative and treat any suspicious activities as malign (e.g. by training to avoid them).
Coordinated AI coup
Imagine we’re using AIs for many different tasks, including monitoring other AIs. These AIs secretly want to stage a coup and would be happy to cooperate on that. But if an AI does something bad, its monitor AI will usually report it to us. We can ensure this by training the monitor AI to report fake coups we constructed, cf. Redwood’s untrusted monitoring [LW(p) · GW(p)].
This system of AIs monitoring AIs collapses if there’s some “code word”—“something only an AI would know”—that AIs can use to signal each other that they are real AIs trying to start a coup. We can try to detect this with mechanistic anomaly detection: whenever a monitor AI claims that everything is fine, we’d check whether the monitor AI said this for the same reasons as on some trusted dataset or for some novel reason. Before a coup, the monitor AI’s behavior is sufficiently explained by whether it spotted bad behavior. But during a coup, a crucial part of the reason why the monitor AI doesn’t raise an alarm is the presence of the “code word” (or, more generally, the monitor AI noticing that a real coup is happening).
A similar example is a single scheming/deceptively aligned AI. During an attempted takeover, a crucial part of an explanation for the AI’s output is that it now thinks it’s able to succeed. This was never the case during training, so we can try to detect it as mechanistically anomalous. One concern is that both cases have a common reason, namely that the AI is just pursuing its own goals (and doing what humans want for instrumental reasons). This highlights that for MAD to work, we can’t just use any “reason.” In this example, we would be unsatisfied without also explaining why the AI thinks a particular output is good for achieving its goals, and hopefully, a sufficiently good explanation of that fact would have to mention the AI’s belief of whether it can currently take over.
Note that the “trusted” dataset here already involves AIs scheming against us; the anomaly only happens when they actually try to take bad actions. That certainly feels scary, and it would only work as our sole defense if we were highly confident in our mechanistic anomaly detection method.
2 comments
Comments sorted by top scores.
comment by StefanHex (Stefan42) · 2024-10-20T14:28:18.201Z · LW(p) · GW(p)
Thanks for the nice writeup! I'm confused about why you can get away without interpretation of what the model components are:
In cases where we worry that our model learned a human-simulator / camera-simulator rather than actually predicting whether the diamond exists, wouldn't circuit discovery simply give us the human-simulator circuit? (And thus causal scrubbing doesn't save us.) I'm thinking in particular of cases where the human-simulator is easier to learn than the intended solution.
Of course if you had good interpretability, a way to realise whether your explanation is the human simulator is to look for suspicious human-simulator-related features. I would like to get away without interpretation, but it's not clear to me that this works.
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2024-10-21T22:54:42.830Z · LW(p) · GW(p)
You're totally right that this is an important difficulty I glossed over, thanks!
TL;DR: I agree you need some extra ingredient to deal with cases where (AI-augmented) humans can't supervise, and this ingredient could be interpretability. On the other hand, there's at least one (somewhat speculative) alternative to interp (and MAD is also potentially useful if you can only deal with cases humans can supervise with enough effort, e.g., to defend against scheming).
Just to restate things a bit, I'd distinguish two cases:
- "In-distribution anomaly detection:" we are fine with flagging any input as "anomalous" that's OOD compared to the trusted distribution
- "Off-distribution anomaly detection:" there are some inputs that are OOD but that we still want to classify as "normal"
In-distribution anomaly detection can already be useful (mainly to deal with rare high-stakes failures). For example, if a human can verify that no tampering occurred with enough effort, then we might be able to create a trusted distribution that covers so many cases that we're fine with flagging everything that's OOD.
But we might still want off-distribution anomaly detection, where the anomaly detector generalizes as intended from easy trusted examples to harder untrusted examples. Then we need some additional ingredient to make that generalization work. Paul writes about one approach specifically for measurement tampering here [AF · GW] and in the following subsection. Exlusion finetuning (appendix I in Redwood's measurement tampering paper) is a practical implementation of a similar intuition. This does rely on some assumptions about inductive bias, but at least seems more promising to me than just hoping to get a direct translator from normal training.
I think ARC might have hopes to solve ELK more broadly (rather than just measurement tampering), but I understand those less (and maybe they're just "use a measurement tampering detector to bootstrap to a full ELK solution").
To be clear, I'm far from confident that approaches like this will work, but getting to the point where we could solve measurement tampering via interp also seems speculative in the foreseeable future. These two bets seem at least not perfectly correlated, which is nice.