Because of LayerNorm, Directions in GPT-2 MLP Layers are Monosemantic
post by ojorgensen · 2023-07-28T19:43:12.235Z · LW · GW · 3 commentsContents
Introduction: Polytope Lens for Transformers? Some terminology and caveats Where is LayerNorm used? What does LayerNorm do? How does an MLP layer act on LayerNormed Vectors? Implications Conclusion: LayerNorm is cool, actually None 3 comments
I think that this has been stated implicitly in various comments and lesswrong posts, but I haven't found a post which makes this point clearly, so thought I would quickly write one up!
To get the most out of this, you should probably be pretty familiar with GPT-2 style transformer architectures. If you want a refresher, big shoutout to A Mathematical Framework for Transformer Circuits and Neel Nanda's What is a Transformer? video.
Introduction: Polytope Lens for Transformers?
When we are trying to interpret transformer models, a central challenge is to try to assign single, human interpretable meanings to different regions of the residual stream.
It would be very convenient if we could assign meanings to directions of the residual stream. Interpreting Neural Networks through the Polytope Lens [LW · GW] presented a potential complication to this by demonstrating that the "fundamental unit" of feed-forward networks with piecewise linear activations were convex polytopes, not just directions. Although the architectures being studied (feed-forward networks with piecewise linear activations) were not actually transformer models, this seemed to be some evidence that we could not assign single meanings to directions in the residual stream of transformers.
The natural question here is: what predictions made by the Polytope Lens should we expect to hold for transformers, and which might not? This question is pretty difficult if we try to analyse the entire transformer, so instead I am going to analyse just the MLP layers of the transformer. These are typically feed-forward networks with piecewise linear activations[1], so the Polytope Lens framing is directly applicable here.
One important difference is the presence of LayerNorm before every MLP layer. Although this might seem like an unimportant detail, it turns out to negate one of the major predictions made by the Polytope Lens, namely that polysemantic directions overlap with multiple monosemantic polytope regions. The thrust of this post is that for any given MLP layer[2] of a GPT-2 style transformers, directions will always be monosemantic. This is entirely due to the presence of LayerNorm.
To show this, I will first provide a brief recap of where LayerNorm is applied in GPT-2 style transformers, give some intuition for what LayerNorm does, and explain what this means for applying the Polytope Lens to the MLP layers of GPT-2 style transformers.
Some terminology and caveats
For this post, I will define a set of vectors in the residual stream as being monosemantic to mean that, given an MLP layer, all vectors in are subject to the same affine transformation by that MLP layer. Similarly, polysemantic will mean that there exists some MLP layer whereby two vectors in V are subject to different affine transformations by the MLP layer.
I will be treating vectors on opposite sides of the origin as being in different directions, because these vectors can in fact correspond to different affine transformations.

I will be looking specifically at GPT-2 style models. For our purposes, the key detail of these models is that LayerNorm is applied before any MLP layer. If you want more details on how one of these models is actually implemented, I would recommend Neel Nanda's Implementing GPT-2 From Scratch.
Where is LayerNorm used?
In GPT-2 models, LayerNorm is applied before every attention layer, before every MLP layer, and before the final unembedding layer of the model. In other words, LayerNorm is applied before the model carries out any computation. The residual stream is never used directly by the model!
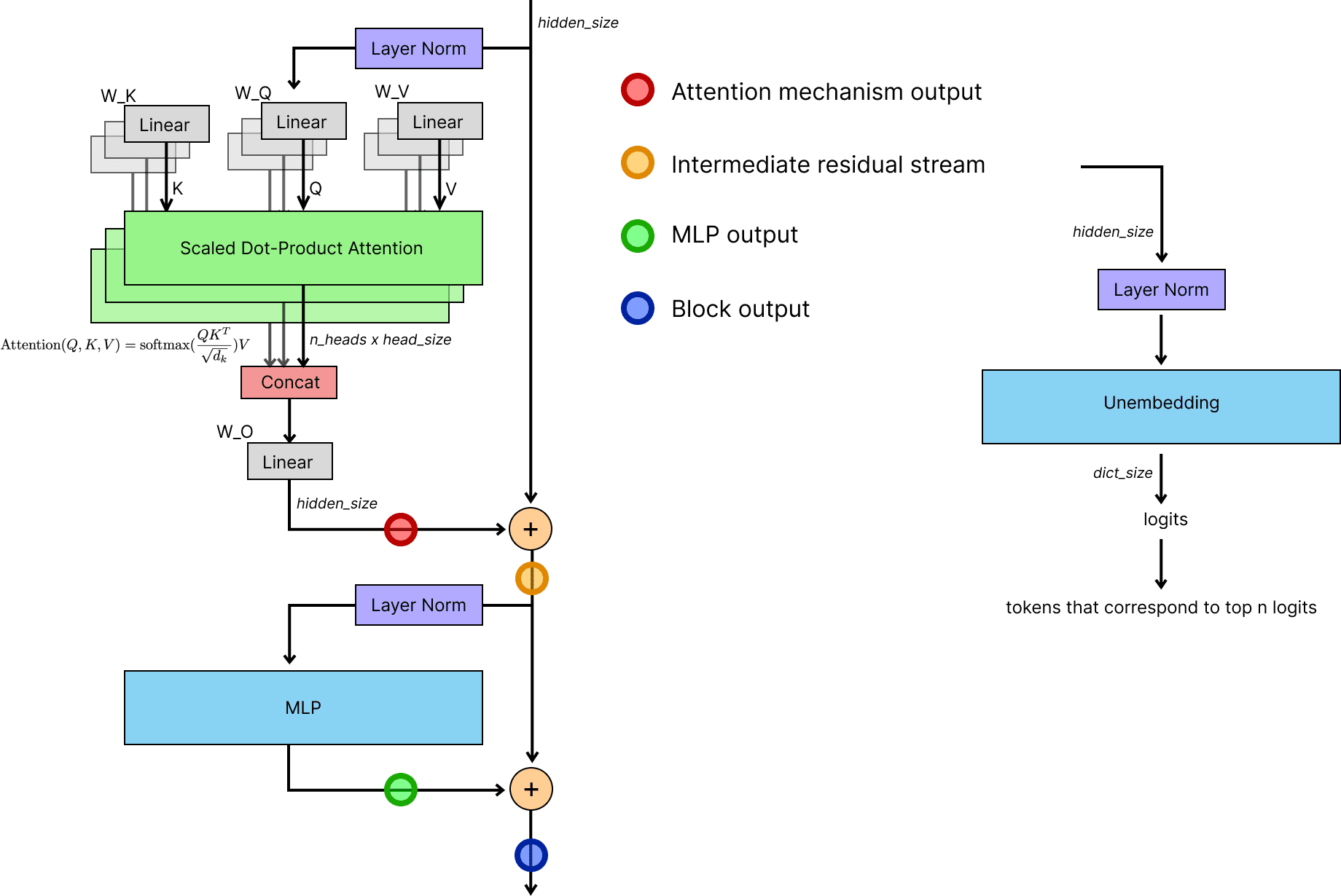
In particular, LayerNorm is applied before the MLP layer. This means that we only need to consider the effects of the MLP layer on the residual stream once we have applied LayerNorm to it.
What does LayerNorm do?
(This section is essentially a rehashing of Some ML-Related Math I Now Understand Better [LW · GW], with some help from Re-Examining LayerNorm [LW · GW]).
Typically, Layer Norm is presented like this:
where is a vector in the residual stream of the transformer. However, since the immediate operations which follow this are always linear in a transformer, we can fold the and terms into the next linear transformation, leaving us with the simplification
This seems to be standard practise for how to represent LayerNorm, which is a shame because it doesn't convey what it's actually doing. We can ignore the term, because it is generally trivially small (its purpose is numerical stability). Then what this actually does is project a point on to the surface of a (scaled) unit sphere on the hyperplane orthogonal to , the unit vector. For example, the following circle is the image of LayerNorm().
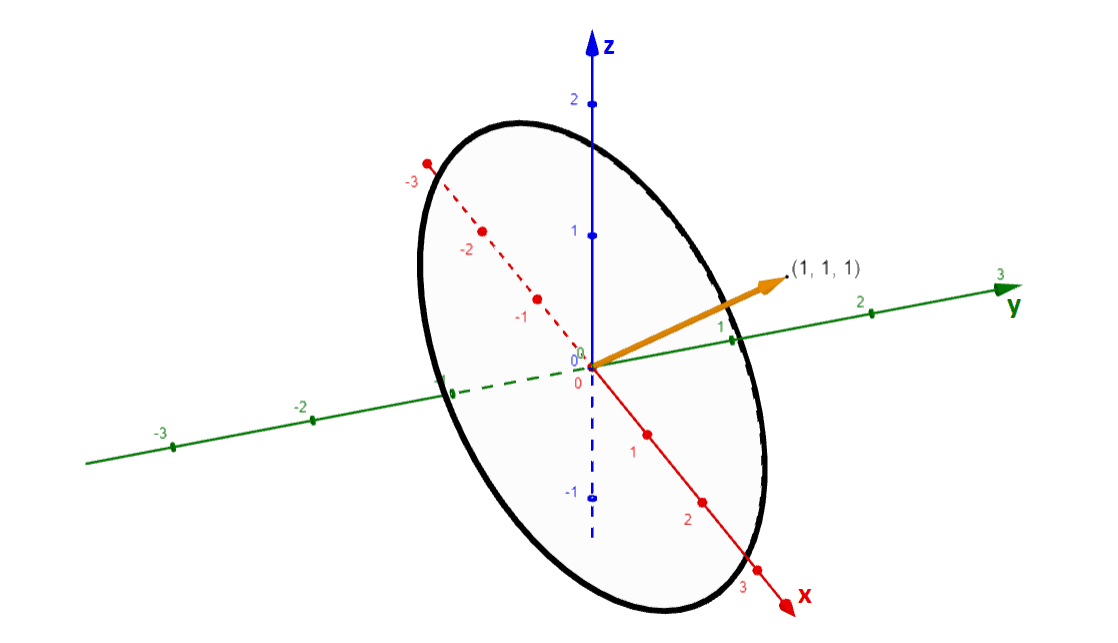
For our purposes, the exact orientation of this unit sphere is not important. What is important is that Layer Norm maps all vectors along the same direction to the same point (since vectors in the same direction are projected to the same point); and that after Layer Norm has been applied all points lie on the surface of some sphere[3] centred at the origin.
It's important to remember our earlier definition that we will treat vectors as being in the same direction only if they also lie on the same side of the origin. This is because vectors on different sides of the origin will be projected to opposite sides of the circle.
How does an MLP layer act on LayerNormed Vectors?
We will now consider the behaviour of a single MLP layer of a transformer. In typical GPT-2 style networks, these consist of a linear map to a single hidden layer, followed by a piecewise linear activation function like ReLU[4], and then a final linear map. The output of this map is added back to the residual stream.
Per Interpreting Neural Networks through the Polytope Lens [LW · GW], a feed-forward network with ReLU activations can be described by partitioning the input space using polytopes, with different polytopes corresponding to different affine transformations.

We can apply exactly the same analysis to the input space of the MLP layer in a GPT-2 style transformer.
Let's consider the case where the residual stream is three-dimensional (in reality this is in the thousands). Firstly, remember that LayerNorm projects all vectors in onto a circle in a two-dimensional plane.

Next, let us separately consider the partition of the plane induced by the MLP layer. Each line represents a hyperplane induced by a hidden neuron, with each region of the plane corresponding to a different affine transformation. Note here that a single direction can indeed be polysemantic in this unrestricted context. For example, along the direction (above the origin) there are three different regions of space, each of which corresponds to a different affine transformation.
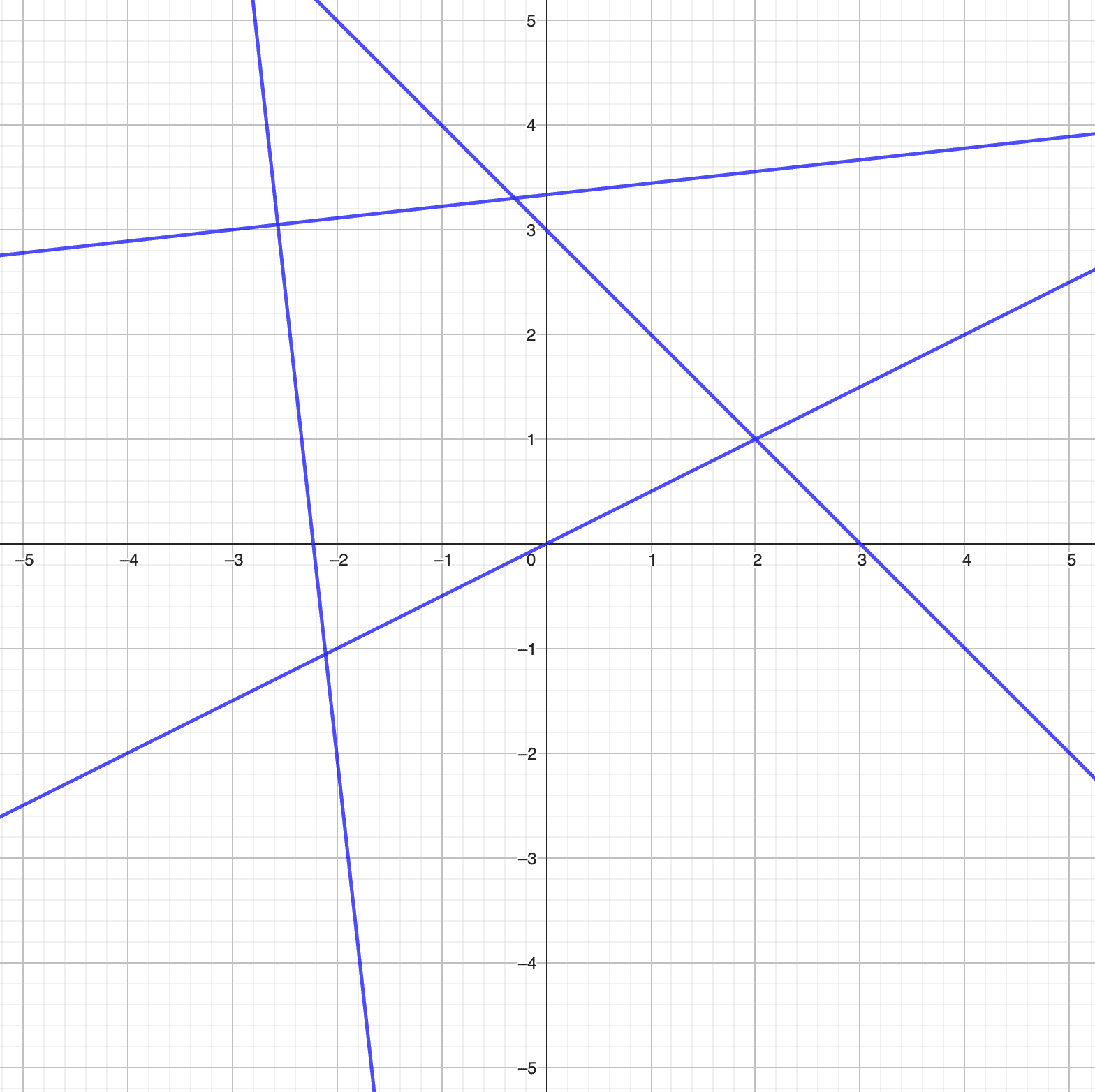
Combining the partition of the plane induced by the MLP layer, alongside the restriction of the input space induced by the LayerNorm transformation, means we now only need to consider the partition of the circumference of the circle with the hyperplanes.
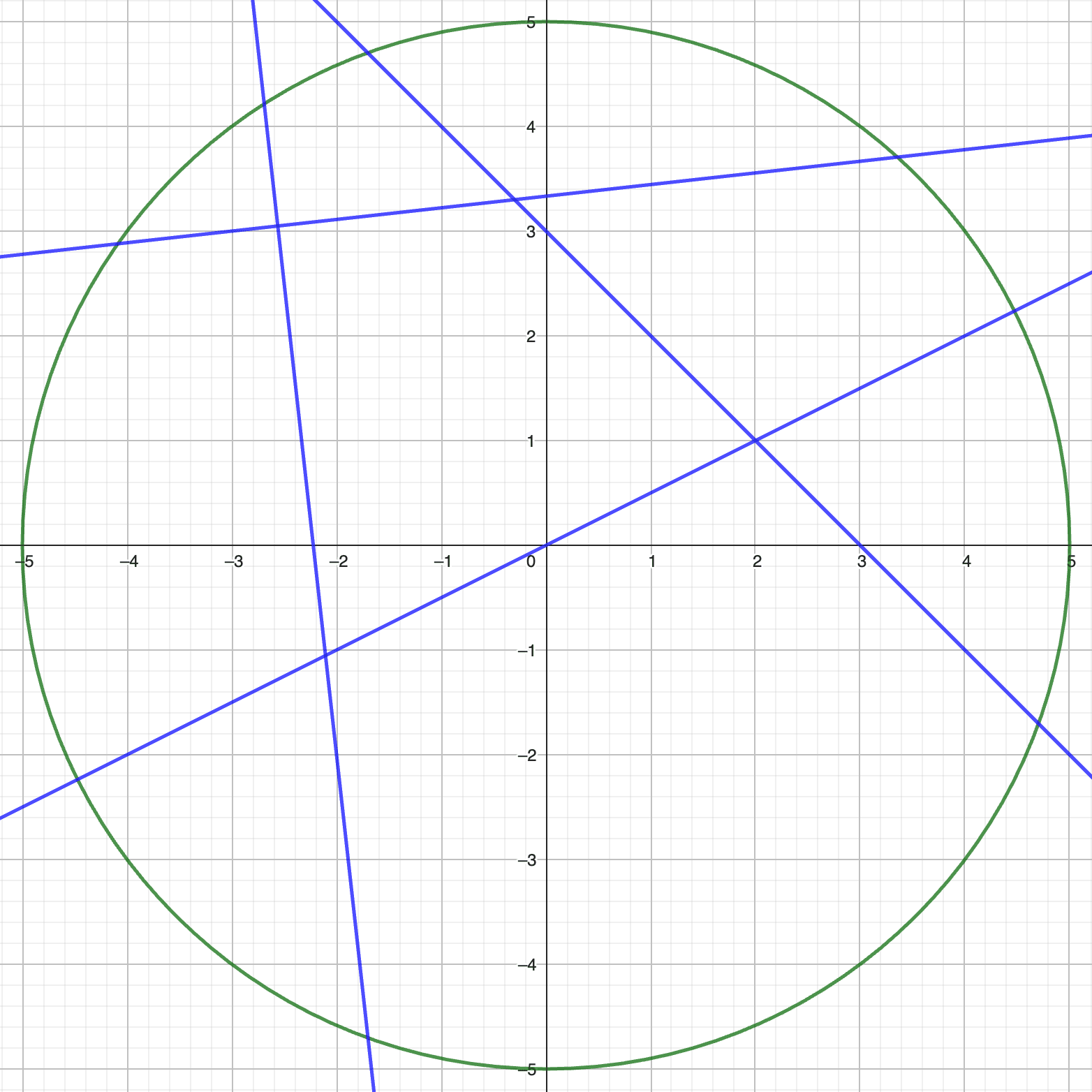
Now, the arcs of the circle defined by the intersections with the hyperplanes (the blue lines) each correspond to a single affine transformation. Since every point we input to the MLP layer lies on this circle, we can simply consider this partition into arcs.
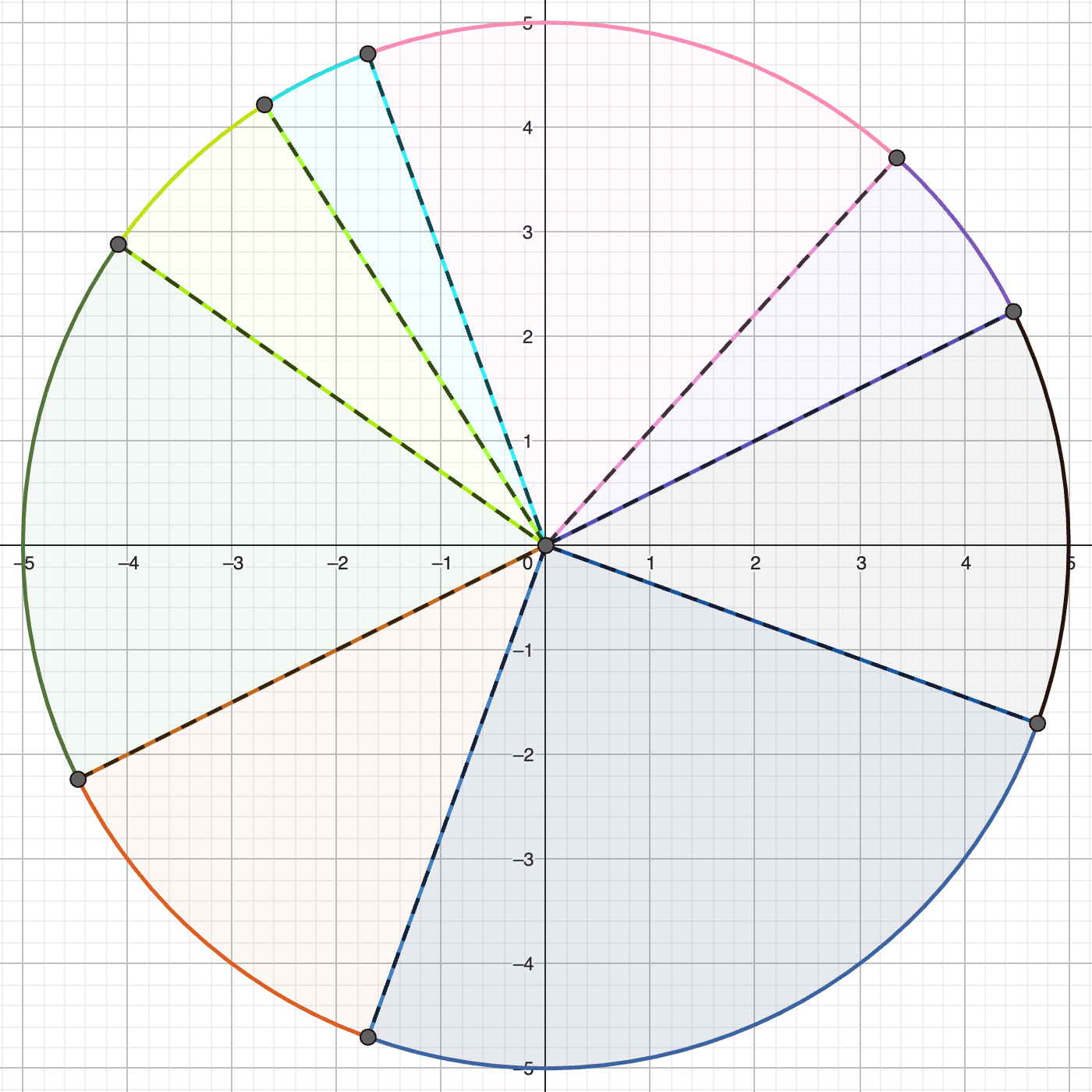
Implications
The above means that, despite the partition into convex polytopes induced by the ReLU activations, only the direction of a residual stream vector influences the output of an MLP layer! A different way of phrasing this is that, for a single MLP layer, each direction in residual stream space is monosemantic.
Although this is different to one prediction made by the Polytope Lens, we can recover many aspects of this framing once we apply the notion of convex polytopes partitioning the surface of a sphere instead of the entire space. Now, the partition into convex polytopes corresponds to where the hyperplanes intersect the surface of the sphere.
In , all points are projected onto the surface of a 2-dimensional circle, with boundaries between 1-dimensional regions of the surface being 0-dimensional points.
In , all points are projected onto the surface of a 3-dimensional sphere, with boundaries between 2-dimensional regions of the surface being 1-dimensional curves. This continues to scale for higher dimensional residual streams.
Once we consider boundaries on the surface of high-dimensional spheres instead of arbitrary polytopes in , we can recover many of the original intuitions from the Polytope Lens: the same affine transformation will be applied to different vectors which are projected to the same region of the surface; similar transformations should be applied to nearby regions of the surface, etc.
Conclusion: LayerNorm is cool, actually
In GPT-2 style transformers, LayerNorm projects residual stream vectors onto a sphere centred at the origin. This is means that, in MLP layers, we are only considering a special case of the feed-forward networks that the Polytope Lens can describe. In particular, the application of LayerNorm means that directions in the residual stream are indeed monosemantic.
I can think of two main uses of this. Firstly, it should give interpretability researchers confidence that they can just try to interpret directions directly, without having to worry that increasing the magnitude of a direction will throw a vector off into a different polytope.[5]
Secondly, it might give us pause for thought about wanting to train models without LayerNorm, in the hope that these will be inherently more interpretable. Without the use of LayerNorm before MLP layers, there is no reason to expect that directions in residual stream space would be monosemantic. Creating new model architectures that don't use LayerNorm, in the hope of making them more interpretable, could inadvertently have the opposite effect!
There are definitely some reasons why LayerNorm sucks and we might want to replace it. It might be responsible for some of the degeneracy in activations frequently seen in GPT-2 style models [LW · GW], and the fact it is not a linear operation means that we cannot just treat different directions in the input space independently. That being said, before this I was of the opinion that LayerNorm had no redeeming qualities. I now feel a little bit remorseful. Sorry LayerNorm - maybe you're not so bad after all.
- ^
These are typically GeLU activations.
- ^
I won't look at attention layers here, because I think it's basically just pretty clear that they are monosemantic because they are essentially linear and bilinear operations with a sprinkling of softmax thrown in.
- ^
Here, the sphere is just a circle, since our residual stream is in . If our residual stream is in , then the hyper-plane the sphere is projected onto will have dimension , and so the surface of the sphere will have dimension .
- ^
Similarly to the Polytope Lens, the following analysis should apply to similar activation functions like GeLU, just with slightly fuzzier polytopes with less defined boundaries.
- ^
Although this importantly doesn't mean that different directions can be treated independently - MLP layers are definitely not linear!
3 comments
Comments sorted by top scores.
comment by Chris_Leong · 2024-01-28T07:28:49.568Z · LW(p) · GW(p)
Just to check I understand this correctly: from what I can gather it seems that this shows that LayerNorm is monosemantic if your residual stream activation is just that direction. It doesn't show that it is monosemantic for the purposes of doing vector addition where we want to stack multiple monosemantic directions at once. That is, if you want to represent other dimensions as well, these might push the LayerNormed vector into a different spline. Am I correct here?
That said, maybe we can model the other dimensions as random jostling in such as way that it all cancels out if a lot of dimensions are activated?
↑ comment by ojorgensen · 2024-01-28T19:29:07.188Z · LW(p) · GW(p)
Yeah I think we have the same understanding here (in hindsight I should have made this more explicit in the post / title).
I would be excited to see someone empirically try to answer the question you mention at the end. In particular, given some direction and a LayerNormed vector , one might try to quantify how smoothly rotating from towards changes the output of the MLP layer. This seems like a good test of whether the Polytope Lens is helpful / necessary for understanding the MLPs of Transformers (with smooth changes corresponding to your 'random jostling cancels out' corresponding to not needing to worry about Polytope Lens style issues).
↑ comment by Chris_Leong · 2024-01-29T01:51:08.777Z · LW(p) · GW(p)
Also: It seems like there would be an easier way to get this observation that this post makes, ie. directly showing that kV and V get mapped to the same point by layer norm (excluding the epsilon).
Don't get me wrong, the circle is cool, but seems like it's a bit of a detour.