We don’t need AGI for an amazing future
post by Karl von Wendt · 2023-05-04T12:10:59.536Z · LW · GW · 32 commentsContents
32 comments
Most of the public discussions about AI safety seem to assume that there is only one plausible path for AI development: from narrow, specialized AI to broad AGI to superintelligence. So we seemingly have to decide between an amazing future with AGI at the risk that it will destroy the world or a future where most of humanity’s potential is untapped and sooner or later we get destroyed by a catastrophe that we could have averted with AGI. I think this is wrong. I believe that even if we assume that we’ll never solve alignment, we can have an amazing future without the existential risks that come with a superintelligent, self-improving AGI.
As Irving J. Good has stated long ago, an AGI would likely be able to self-improve, leading to an intelligence explosion. The resulting superintelligence would combine the capabilities of all the narrow AIs we could ever develop. Very likely it could do many things that aren’t possible even with a network of specialized narrow AIs. So, from an intelligence perspective, self-improving AGI is clearly superior to narrow AI (fig. 1).
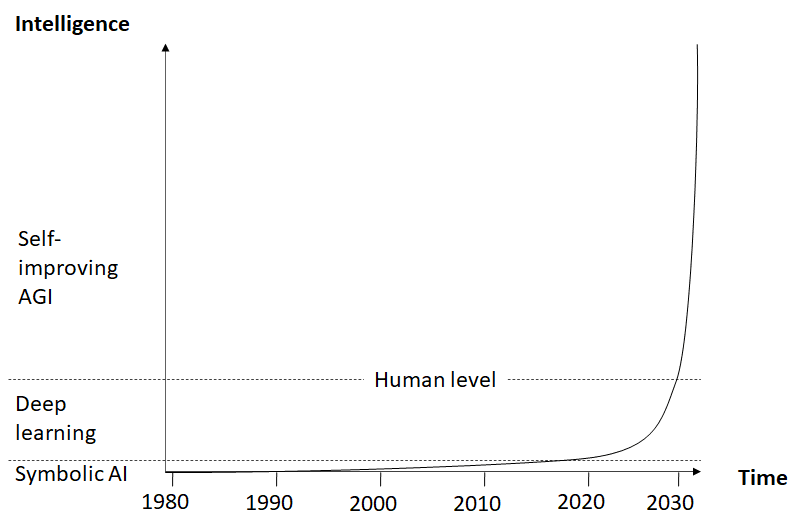
Fig. 1: AI development (hypothetical)
But of course there’s a catch: a self-improving AGI will be uncontrollable by humans and we have no idea how to make sure that it will pursue a beneficial goal, so in all likelihood this will lead to an existential catastrophe [LW · GW]. With the prospect of AGI becoming achievable within the next few years [LW · GW], it seems very unlikely that we’ll solve alignment before that. So, from a human values perspective, a very different picture emerges: above a certain level of intelligence, the expected value of a misaligned AGI will be hugely negative (fig. 2).
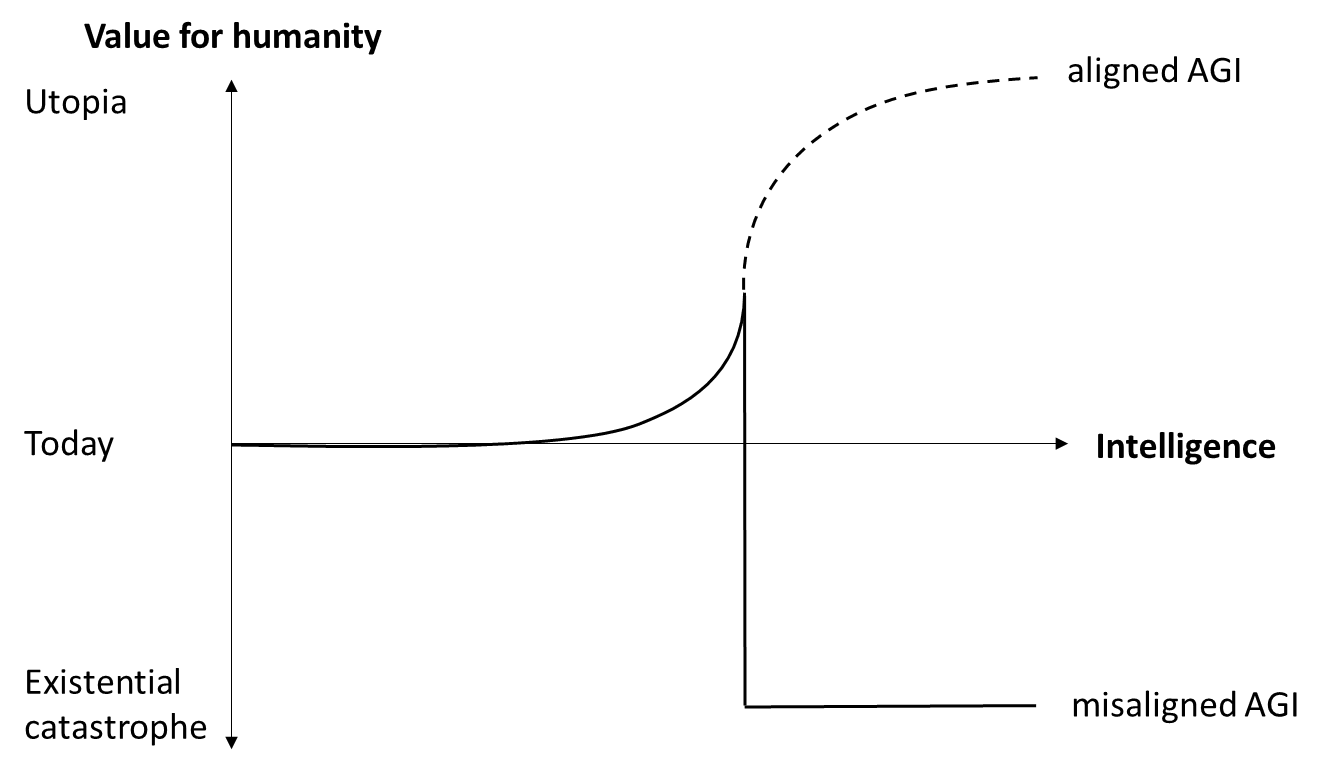
Fig. 2: Value for humanity of aligned and misaligned AGI
The only sure way to avoid an existential catastrophe from misaligned AGI is to not develop one. As long as we haven’t solved alignment, this means not developing AGI at all. Therefore, many people call for an AGI moratorium [LW · GW] or even a full stop in AI development, at least until we have found a solution to the alignment problem. I personally support an AGI moratorium. I have signed the open letter of the Future of Life Institute although I think 6 months are nowhere near enough time to solve the problems associated with AGI, simply because a 6 months pause is better than just racing full-speed ahead and I view the coordination required for that as a potentially good start.
However, I think we need more than that. I think we need a strategic shift in AI development away from general intelligence towards powerful narrow AI. My hypothesis is that provably aligning a self-improving AGI to human values is theoretically and practically impossible. But even if I’m wrong about that, I don’t think that we need AGI to create an amazing future for humanity. Narrow AI is a much safer way into that future.
All technical advances we have made so far were for particular, relatively narrow purposes. A car can’t fly while a plane or helicopter isn’t practical to get you to the supermarket. Passenger drones might bridge that gap one day, but they won’t be able to cook dinner for us, wash the dishes, or clean the laundry - we have other kinds of specialized technical solutions for that. Electricity, for instance, has a broad range of applications, so it could be seen as a general purpose technology, but many different specialized technologies are needed to effectively generate, distribute, and use it. Still, we live in a world that would look amazing and even magical to someone from the 17th century.
There’s no reason to assume that we’re anywhere near the limit of the value we can get out of specialized technology. There are huge untapped potentials in transportation, industry, energy generation, and medicine, to name but a few. Specialized technology could help us reduce climate change, prolong our lives, colonize space, and spread through the galaxy. It can literally carry us very, very far.
The same is true for specialized AI: self-driving cars, automated production, cures for most diseases, and many other benefits are within reach even without AGI. While LLMs have gained much attention recently, I personally think that the value for humanity of a specialized AI like AlphaFold that can accelerate medicine and help save millions of lives is actually much greater. A system of specialized narrow AIs interacting with each other and with humans could achieve almost anything for us, including inventing new technologies and advancing science.
The big advantage of narrow AI is that, unlike AGI, it will not be uncontrollable by default. An AI like AlphaFold doesn’t need a general world model that includes itself, so it will never develop self-awareness and won’t pursue instrumental sub-goals like power-seeking and self-preservation. Instrumental goals are a side effect of general intelligence, not of specialized systems[1]. With the combined superhuman capabilities of many different specialized AIs we can go beyond the intelligence threshold that would make an AGI uncontrollable and gain huge value without destroying our future (fig. 3).
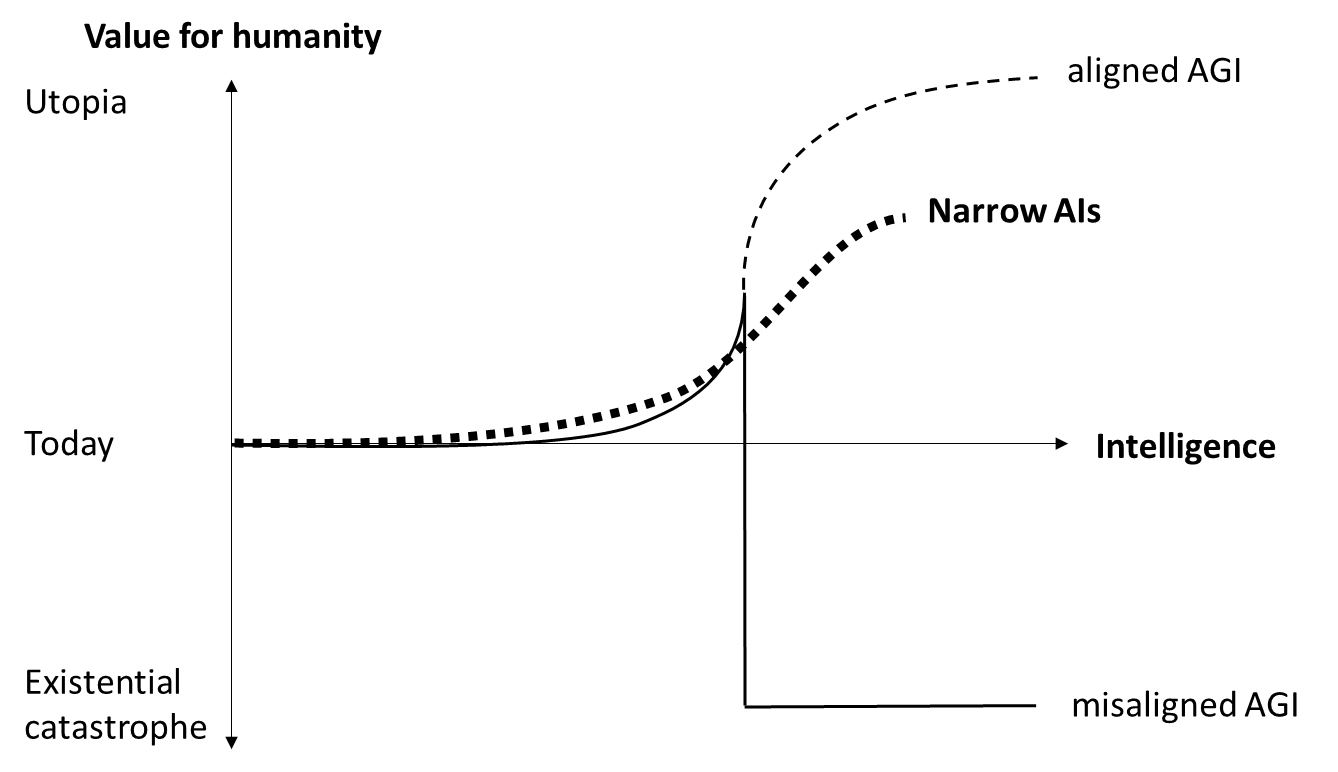
Fig. 3: Combined value of narrow AIs vs. value of AGI
As described earlier, even a system of many different narrow AIs will be no match for one self-improving AGI. So if we restrict ourselves to narrow AI, we might never get the value out of AI that would theoretically be possible with a superintelligent, aligned AGI. It may also be harder and more costly to develop all those specialized AIs, compared to one superintelligent AGI that would do all further improvement by itself. But we could still achieve a much better world state than we have today, and a better one than we can achieve with AGI before it becomes uncontrollable. As long as we haven’t solved the alignment problem in a provable, practical way, focusing on narrow AIs is clearly superior to continuing the race for AGI.
Of course, narrow AI could still be very dangerous. For example, it could help bad actors develop devastating weapons of mass destruction, enable Orwellian dystopias, or accidentally cause catastrophes of many different kinds. There is also the possibility that a system of interacting narrow AIs could in combination form an AGI-like structure that could develop instrumental goals, self-improve, and become uncontrollable. Or we could end up in a complex world we don’t understand anymore, consisting of interacting subsystems optimizing for some local variables and finally causing a systemic breakdown as Paul Christiano described it [LW · GW] in his “going out with a whimper”-scenario.
To achieve a better future with narrow AI, we must therefore still proceed cautiously. For example, we must make sure that no system or set of systems will ever develop the combination of strategic self-awareness and agentic planning capabilities that leads to instrumental goals and power-seeking. Also, we will need to avoid the many different ways narrow AI can lead to bad outcomes. We need solid safety regimes, security measures, and appropriate regulation. This is a complex topic and a lot of research remains to be done.
But compared to a superintelligent AGI that we don’t even begin to understand and that would almost certainly destroy our future, these problems seem much more manageable. In most cases, narrow AI only works in combination with humans who give it a specific problem to work on and apply the results in some way. This means that to control narrow AI, we need to control the humans who develop and apply it – something that’s difficult enough, but probably not impossible.
The discussion about AI safety often seems quite polarized: AGI proponents call people concerned about existential risks “doomers” and sometimes ridicule them. Many seem to think that without AGI, humanity will never have a bright future. On the other hand, many members of the AI safety community tend to equate any progress in AI capabilities with an increase in catastrophic risks. But maybe there is a middle ground. Maybe by shifting our focus to narrow AI, at least until we know how to provably align a superintelligent AGI, we can develop super-powerful technology that doesn’t have a high probability of destroying our future.
As Sam Altman put it in his recent interview with Lex Fridman [LW · GW]: “The thing that I’m so excited about is not that it’s a system that kind of goes off and does its own thing but that it’s this tool that humans are using in this feedback loop … I’m excited about a world where AI is an extension of human will and an amplifier of our abilities and this like most useful tool yet created, and that is certainly how people are using it … Maybe we never build AGI but we just make humans super great. Still a huge win.”
Many questions about this remain open. But I think the option of ending the current race for AGI and instead focusing on narrow AI at least deserves a thorough discussion.
- ^
It is of course possible that certain specialized AIs follow goals like power-seeking and self-preservation if they are trained to do so, for example military systems.
32 comments
Comments sorted by top scores.
comment by [deleted] · 2023-05-04T15:40:33.957Z · LW(p) · GW(p)
I feel like this is a good example of a post that—IMO—painfully misses the primary objection of many people it is trying to persuade (e.g., me): how can we stop 100.0% of people from building AGI this century (let alone in future centuries)? How can we possibly ensure that there isn’t a single person over the next 200 years who decides “screw it, they can’t tell me what to do,” and builds misaligned AGI? How can we stop the race between nation-states that may lack verification mechanisms? How can we identify and enforce red lines while companies are actively looking for loopholes and other ways to push the boundaries?
The point of this comment is less to say “this definitely can’t be done” (although I do think such a future is fairly implausible/unsustainable), and more to say “why did you not address this objection?” You probably ought to have a dedicated section that very clearly addresses this objection in detail. Without such a clearly sign-posted section, I felt like I mostly wasted my time skimming your article, to be entirely honest
Replies from: Davidmanheim, Karl von Wendt, jbash↑ comment by Davidmanheim · 2023-05-09T20:29:11.726Z · LW(p) · GW(p)
I think the post addresses a key objection that many people opposed to EA and longtermist concerns have voiced with the EA view of AI, and thought it was fairly well written to make the points it made, without also making the mostly unrelated point that you wanted it to have addressed.
↑ comment by Karl von Wendt · 2023-05-04T17:32:12.397Z · LW(p) · GW(p)
The point of this comment is less to say “this definitely can’t be done” (although I do think such a future is fairly implausible/unsustainable), and more to say “why did you not address this objection?” You probably ought to have a dedicated section that very clearly addresses this objection in detail.
That's a valid point, thank you for making it. I have given some explanation of my point of view in my reply to jbash, but I agree that this should have been in the post in the first place.
↑ comment by jbash · 2023-05-04T17:03:10.903Z · LW(p) · GW(p)
I'll say it. It definitely can't be done.
You cannot permanently stop self-improving AGI from being created or run. Not without literally destroying all humans.
You can't stop it for a "civilizationally significant" amount of time. Not without destroying civilization.
You can slow it down by maybe a few years (probably not decades), and everybody should be trying to do that. However, it's a nontrivial effort, has important costs of many kinds, quickly reaches a point of sharply diminishing returns, is easy to screw up in actually counterproductive ways, and involves meaningful risk of making the way it happens worse.
If you want to quibble, OK, none of those things are absolute certainties, because there are no absolute certainties. They are, however, the most certain things in the whole AI risk field of thought.
What really concerns me is that the same idea has been coming up continuously since (at least) the 1990s, and people still talk about it as if it were possible. It's dangerous; it distracts people into fantasies, and keeps them from thinking clearly about what can actually be done.
I've noticed a pattern of such proposals talking about what "we" should do, as if there were a "we" with a unified will that ever could or would act in a unified way. There is no such "we". Although it's not necessarily wrong to ever use the word "we", using it carelessly is a good way to lead yourself into such errors.
Replies from: caelum-forder, Karl von Wendt↑ comment by Caelum Forder (caelum-forder) · 2023-05-09T16:34:10.060Z · LW(p) · GW(p)
There are definitely timelines where privacy and privacy imbalance were eliminated completely and AGI development prevented, possibly indefinitely, or possibly until alignment was guaranteed. (obviously/insignificantly, bare with me)
Imagine that everyone could 'switch' their senses to any other with minimal effort, including sensors like cameras and microphones on devices, drones, persons, or with not too distant technology, any of human senses, and imagine there was some storage system allowing access to those senses back into time, practically there may be some rolling storage window with longer windows for certain sets of the data.
I think a society like this could hold off AGI, that getting to a society like this is possibly easier than alignment first, and that such a society, while still with some difficulties, would be an improvement for most people over an imaginary regular AGI-less society and current society
It is a hard idea to come around to, there are a lot of rather built in notions that scream against it. A few otherwise rational people have told me that they'd rather misaligned AGI, that 'privacy is a human right' (with no further justification for it) etc.
It seems all issues associated with a lack of privacy depend on some privacy imbalance, e.g. your ssh key is leaked (in such a society, they may still be used to protect control), you don't know who has it, and when they abuse it, but if somehow everyone did, and everyone knew everyone did, then it is much less bad. Someone might still abuse what they know against their own best interests, but they could quickly be recognized as someone who does that, and prevented from doing it more via therapy/imprisonment.
Depending on the technology available, there could still be windows for doing small, quick wrongs, e.g. someone could use your ssh key to delete a small amount of some of your data because they don't like your face, simply hoping no one is watching, or will rewatch in the future. I don't know how much of an issue these would be, but I figure that a combination of systems being modified in the context of complete global information freedom to do things like trigger/mark a recording of people accessing the system, and an incentive for efforts to scout wrongdoings and build systems to help scout for them, there is a good potential that the total wrongdoing cost will go down versus the alternative.
I don't think conformity / groupthink / tribalism etc. would get the best of us. They may still have some of their impacts, but it seems that transparency almost always reduces them - strawmen less relevant when actual arguments are replayable, fabricated claims about others easily debunkable, and possibly punished under new laws. Yes, you wouldn't be able to hide from a hateful group that doesn't like an arbitrary thing about you, but they wouldn't be able to circulate falsehoods about you to fuel that hate, they would be an easy cash cow for any wrongdoing scouts (and wrongdoing scouts encouraging these cashcows, a larger cashcow for other wrongdoing scouts), and with a combination of social pressure to literally put ourselves in another's shoes, I think it is reasonable to at least consider these problems won't be worse
Society got along okay with little to no privacy in the past, but if we later decide that we want it back for idk bedroom activities, I think it is possible that abstraction could be used to rebuild some forms of privacy in a way that still prevents us from building a misaligned AGI. For example, it could be only people on the other side of the world who you don't know who can review what happens in your bedroom, and if you abuse your partner there or start building AGI, they could raise it to a larger audience. Maybe some narrow AI could be used to help make things more efficient and allow you private time.
Under this society, I think we could distinguish alignment and capability work, and maybe we'd need to lean heavily towards the safe direction and delay aligned AGI a bunch, but conceivably it would allow us to have an aligned AGI at the end, and we can bring back full privacy.
In timelines with this technology and society structure, I wonder what they looked like to get there. I imagine they could have started with just computer systems and drones. Maybe they had the technology ready and rolled it out only when people were on board, which may have been spurred by widespread fear of misaligned AGI. Maybe they were quite lucky, and there were other dominant cultural forces which all had ulterior incentives for such a system to be in place. I do think it would be quite hard to get everyone on board, but it seems like a reasonable route to aligned AGI worth talking more about to me.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-10T03:06:09.437Z · LW(p) · GW(p)
This is an interesting thought. I think even without AGI, we'll have total transparency of human minds soon - already AI can read thoughts in a limited way. Still, as you write, there's an instinctive aversion against this scenario, which sounds very much like an Orwellian dystopia. But if some people have machines that can read minds, which I don't think we can prevent, it may indeed be better if everyone could do it - deception by autocrats and bad actors would be much harder that way. On the other hand, it is hard to imagine that the people in power would agree to that: I'm pretty sure that Xi or Putin would love to read the minds of their people, but won't allow them to read theirs. Also it would probably be possible to fake thoughts and memories, so the people in power could still deceive others. I think it's likely that we wouldn't overcome this imbalance anytime soon. This only shows that the future with "narrow" AI won't be easy to navigate either.
↑ comment by Karl von Wendt · 2023-05-04T17:29:53.198Z · LW(p) · GW(p)
You cannot permanently stop self-improving AGI from being created or run. Not without literally destroying all humans.
You can't stop it for a "civilizationally significant" amount of time. Not without destroying civilization.
I'm not sure what this is supposed to mean. Are you saying that I'd have to kill everyone so noone can build AGI? Maybe, but I don't think so. Or are you saying that not building an AGI will destroy all humans? This I strongly disagree with. I don't know what a "civiliatzionally significant" amount of time is. For me, the next 10 years are a "significant" amount of time.
What really concerns me is that the same idea has been coming up continuously since (at least) the 1990s, and people still talk about it as if it were possible. It's dangerous; it distracts people into fantasies, and keeps them from thinking clearly about what can actually be done.
This is a very strong claim. Calling ideas "dangerous" is in itself dangerous IMO, especially if you're not providing any concrete evidence. If you think talking about building narrow AI instead of AGI is "dangerous" or a "fantasy", you have to provide evidence that a) this is distracting relevant people from doing things that are more productive (such as solving alignment?) AND b) that solving alignment before we can build AGI is not only possible, but highly likely. The "fantasy" here to me seems to be that b) could be true. I can see no evidence for that at all.
For all the people who continuously claim that it's impossible to coordinate humankind into not doing obviously stupid things, here are some counter examples: We have the Darwin awards for precisely the reason that almost all people on earth would never do the stupid things that get awarded. A very large majority of humans will not let their children play on the highway, will not eat the first unknown mushrooms they find in the woods, will not use chloroquine against covid, will not climb into the cage in the zoo to pet the tigers, etc. The challenge here is not the coordination, but the common acceptance that certain things are stupid. This is maybe hard in certain cases, but NOT impossible. Sure, this will maybe not hold for the next 1,000 years, but it will buy us time. And there are possible measures to reduce the ability of the most stupid 1% of humanity to build AGI and kill everyone.
That said, I agree that my proposal is very difficult to put into practice. The problem is, I don't have a better idea. Do you?
Replies from: jbash↑ comment by jbash · 2023-05-04T18:33:17.012Z · LW(p) · GW(p)
Are you saying that I'd have to kill everyone so noone can build AGI?
Yup. Anything short of that is just a delaying tactic.
From the last part of your comment, you seem to agree with that, actually. 1000 years is still just a delay.
But I didn't see you as presenting preventing fully general, self-improving AGI as a delaying tactic. I saw you as presenting it as a solution.
Also, isn't suppressing fully general AGI actually a separate question from building narrow AI? You could try suppress fully general AGI and narrow AI. Or you could build narrow AI while still also trying to do fully general AGI. You can do either with or without the other.
you have to provide evidence that a) this is distracting relevant people from doing things that are more productive (such as solving alignment?)
I don't know if it's distracting any individuals from finding any way to guarantee good AGI behavior[1]. But it definitely tends to distract social attention from that. Finding one "solution" for a problem tends to make it hard to continue any negotiated process, including government policy development, for doing another "solution". The attitude is "We've solved that (or solved it for now), so on to the next crisis". And the suppression regime could itself make it harder to work on guaranteeing behavior.
True, I don't don't know if the good behavior problem can be solved, and am very unsure that it can be solved in time, regardless.
But at the very least, even if we're totally doomed, the idea of total, permanent suppression distracts people from getting whatever value they can out of whatever time they have left, and may lead them to actions that make it harder for others to get that value.
AND b) that solving alignment before we can build AGI is not only possible, but highly likely.
Oh, no, I don't think that at all. Given the trends we seem to be on, things aren't looking remotely good.
I do think there's some hope for solving the good behavior problem, but honestly I pin more of my hope for the future on limitations of the amount of intelligence that's physically possbile, and even more on limitations of what you can do with intelligence no matter how much of it you have. And another, smaller, chunk on it possibly turning out that a random self-improving intelligence simply won't feel like doing anything that bad anyway.
... but even if you were absolutely sure you couldn't make a guaranteed well-behaved self-improving AGI, and also absolutely sure that a random self-improving AGI meant certain extinction, it still wouldn't follow that you should turn around and do something else that also won't work. Not unless the cost were zero.
And the cost of the kind of totalitarian regime you'd have to set up to even try for long-term suppression is far from zero. Not only could it stop people from enjoying what remains, but when that regime failed, it could end up turning X-risk into S-risk by causing whatever finally escaped to have a particularly nasty goal system.
For all the people who continuously claim that it's impossible to coordinate humankind into not doing obviously stupid things, here are some counter examples: We have the Darwin awards for precisely the reason that almost all people on earth would never do the stupid things that get awarded. A very large majority of humans will not let their children play on the highway, will not eat the first unknown mushrooms they find in the woods, will not use chloroquine against covid, will not climb into the cage in the zoo to pet the tigers, etc.
Those things are obviously bad from an individual point of view. They're bad in readily understandable ways. The bad consequences are very certain and have been seen many times. Almost all of the bad consequences of doing any one of them accrue personally to whoever does it. If other people do them, it still doesn't introduce any considerations that might drive you to want to take the risk of doing them too.
Yet lots of people DID (and do) take hydroxychloroquine and ivermectin for COVID, a nontrivial number of people do in fact eat random mushrooms, and the others aren't unheard-of. The good part is that when somebody dies from doing one of those things, everybody else doesn't also die. That doesn't apply to unleashing the killer robots.
... and if making a self-improving AGI were as easy as eating the wrong mushrooms, I think it would have happened already.
The challenge here is not the coordination, but the common acceptance that certain things are stupid.
Pretty much everybody nowadays has a pretty good understanding of the outlines of the climate change problem. The people who don't are the pretty much the same people who eat horse paste. Yet people, in the aggregate, have not stopped making it worse. Not only has every individual not stopped, but governments have been negotiating about it for like 30 years... agreeing at every stage on probably inadequate targets... which they then go on not to meet.
... and climate change is much, much easier than AGI. Climate change rules could still be effective without perfect compliance at an individual level. And there's no arms race involved, not even between governments. A climate change defector may get some economic advantage over other players, but doesn't get an unstoppable superweapon to use against the other players. A climate change defector also doesn't get to "align" the entire future with the defector's chosen value system. And all the players know that.
Speaking of arms races, many people think that war is stupid. Almost everybody thinks that nuclear war is stupid, even if they don't think nuclear deterrence is stupid. Almost everybody thinks that starting a war you will lose is stupid. Yet people still start wars that they will lose, and there is real fear that nuclear war can happen.
This is maybe hard in certain cases, but NOT impossible. Sure, this will maybe not hold for the next 1,000 years, but it will buy us time.
I agree that suppressing full-bore self-improving ultra-general AGI can buy time, if done carefully and correctly. I'm even in favor of it at this point.
But I suspect we have some huge quantitative differences, because I think the best you'll get out of it is probably less than 10 years, not anywhere near 1000. And again I don't see what substituting narrow AI has to do with it. If anything, that would make it harder by requiring you to tell the difference.
I also think that putting too much energy into making that kind of system "non-leaky" would be counterproductive. It's one thing to make it inconvenient to start a large research group, build a 10,000-GPU cluster, and start trying for the most agenty thing you can imagine. It's both harder and more harmful to set up a totalitarian surveillance state to try to control every individual's use of gaming-grade hardware.
And there are possible measures to reduce the ability of the most stupid 1% of humanity to build AGI and kill everyone.
What in detail would you like to do?
I don't like the word "alignment" for reasons that are largely irrelevant here. ↩︎
↑ comment by jbash · 2023-05-04T18:44:04.634Z · LW(p) · GW(p)
Replying to myself to clarify this:
A climate change defector also doesn't get to "align" the entire future with the defector's chosen value system.
I do understand that the problem with AGI is exactly that you don't know how to align anything with anything at all, and if you know you can't, then obviously you shouldn't try. That would be stupid.
The problem is that there'll be an arms race to become able to do so... and a huge amount of pressure to deploy any solution you think you have as soon as you possibly can. That kind of pressure leads to motivated cognition and institutional failure, so you become "sure" that something will work when it won't. It also leads to building up all the prerequisite capabilities for a "pivotal act", so that you can put it into practice immediately when (you think) you have an alignment solution.
... which basically sets up a bunch of time bombs.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-04T19:30:30.737Z · LW(p) · GW(p)
I agree with that.
↑ comment by Karl von Wendt · 2023-05-04T19:30:02.781Z · LW(p) · GW(p)
1000 years is still just a delay.
Fine. I'll take it.
But I didn't see you as presenting preventing fully general, self-improving AGI as a delaying tactic. I saw you as presenting it as a solution.
Actually, my point in this post is that we don't NEED AGI for a great future, because often people equate Not AGI = Not amazing future (or even a terrible one) and I think this is wrong. The point of this post is not to argue that preventing AGI is easy.
However, it's actually very simple: If we build a misaligned AGI, we're dead. So there are only two options: A) solve alignment, B) not build AGI. If not A), then there's only B), however "impossible" that may be.
Yet lots of people DID (and do) take hydroxychloroquine and ivermectin for COVID, a nontrivial number of people do in fact eat random mushrooms, and the others aren't unheard-of.
Yes. My hope is not that 100% of mankind will be smart enough to not build an AGI, but that maybe 90+% will be good enough, because we can prevent the rest from getting there, at least for a while. Currently, you need a lot of compute to train a Sub-AGI LLM. Maybe we can put the lid on who's getting how much compute, at least for a time. And maybe the top guys at the big labs are among the 90% non-insane people. Doesn't look very hopeful, I admit.
Anyway, I haven't seen you offer an alternative. Once again, I'm not saying not developing AGI is an easy task. But saying it's impossible (while not having solved alignment) is saying "we'll all die anyway". If that's the case, then we can as well try the "impossible" things and at least die with dignity.
Replies from: jbash↑ comment by jbash · 2023-05-04T20:17:17.387Z · LW(p) · GW(p)
Actually, my point in this post is that we don't NEED AGI for a great future, because often people equate Not AGI = Not amazing future (or even a terrible one) and I think this is wrong.
I don't have so much of a problem with that part.
It would prevent my personal favorite application for fully generally strongly superhuman AGI... which is to have it take over the world and keep humans from screwing things up more. I'm not sure I'd want humans to have access to some of the stuff non-AGI could do... but I don't think here's any way to prevent that.
If we build a misaligned AGI, we're dead. So there are only two options: A) solve alignment, B) not build AGI. If not A), then there's only B), however "impossible" that may be.
C) Give up.
Anyway, I haven't seen you offer an alternative.
You're not going to like it...
Personally, if made king of the world, I would try to discourage at least large scale efforts to develop either generalized agents or "narrow AI", especially out of opaque technology like ML. Thats because narrow AI could easily become parts or tools for a generalized agent, because many kinds of narrow AI are too dangerous in human hands, and because the tools and expertise for narrow AI are too close to those for generalized AGI,. It would be extremely difficult to suppress one in practice without suppressing the other.
I'd probably start by making it as unprofitable as I could by banning likely applications. That's relatively easy to enforce because many applications are visible. A lot of the current narrow AI applications need bannin' anyhow. Then I'd start working on a list of straight-up prohibitions.
Then I'd dump a bunch of resources into research on assuring behavior in general and on more transparent architectures. I would not actually expect it to work, but it has enough of a chance to be worth a try,. That work would be a lot more public than most people on Less Wrong would be comfortable with, because I'm afraid of nasty knock-on effects from trying to make it secret. And I'd be a little looser about capability work in service of that goal than in service of any other.
I would think very hard about banning large aggregations of vector compute hardware, and putting various controls on smaller ones, and would almost certainly end up doing it for some size thresholds. I'm not sure what the thresholds would be, nor exactly what the controls would be. This part would be very hard to enforce regardless.
I would not do anything that relied on perfect enforcement for its effecitveness, and I would not try to ramp up enforcement to the point where it was absolutely impossible to break my rules, because I would fail and make people miserable. I would titrate enforcement and stick with measures that seemed to be working without causing horrible pain.
I'd hope to get a few years out of that, and maybe a breakthrough on safety if I were tremendously lucky. Given oerfect confidence in a real breakthrough, I would try to abdicate in favor of the AGI.
If made king of only part of the world, I would try to convince the other parts to collaborate with me in imposing roughly the same regime. How I reacted if they didn't do that would depend on how much leverage I had and what they did seem to be doing. I would try really, really hard not to start any wars over it. Regardless of what they said they were doing I would assume that they were engaging in AGI research under the table. Not quite sure what I'd do with that assumption, though.
But I am not king of the world, and I do not think it's feasible for me to become king of the world.
I also doubt that the actual worldwide political system, or even the political systems of most large countries, can actually be made to take any very effective measures within any useful amount of time. There are too many people out there with too many different opinions, too many power centers with contrary interests, too much mutal distrust, and too many other people with too much skill at deflecting any kind of policy initiative down ways that sort of look like they serve the original purpose, but mostly don't. The devil is often in the details.
If it is possible to get the system to do that, I know that I am not capable of doing so. I mean, I'll vote for it, maybe make write some letters, but I know from experience that I have nearly no ability to persuade the sorts of people who'd need to be persuaded.
I am also not capable of solving the technical problem myself and doing some "pivotal act". In fact I'm pretty sure I have no technical ideas for things to try that aren't obvious to most specialists. And I don't much buy any of the the ideas I've heard from other people.
My only real hopes are things that neither I nor anybody else can influence, especially not in any predictable direction, like limitations on intelligence and uncertainty about doom.
So my personal solution is to read random stuff, study random things, putter around in my workshop, spend time with my kid, and generally have a good time.
Replies from: Karl von Wendt, None↑ comment by Karl von Wendt · 2023-05-05T12:06:38.362Z · LW(p) · GW(p)
We're not as far apart as you probably think. I'd agree with most of your decisions. I'd even vote for you to become king! :) Like I wrote, I think we must also be cautious with narrow AI as well, and I agree with your points about opaqueness and the potential of narrow AI turning into AGI. Again, the purpose of my post was not to argue how we could make AI safe, but to point out that we could have a great future without AGI. And I still see a lot of beneficial potential in narrow AI, IF we're cautious enough.
↑ comment by [deleted] · 2023-05-04T20:44:45.340Z · LW(p) · GW(p)
A lot of the current narrow AI applications need bannin' anyhow
Which? I wonder.
Replies from: jbash↑ comment by jbash · 2023-05-05T14:02:23.739Z · LW(p) · GW(p)
Independent of potential for growing into AGI and {S,X}-risk resulting from that?
With the understanding that these are very rough descriptions that need much more clarity and nuance, that one or two of them might be flat out wrong, that some of them might turn out to be impossible to codify usefully in practice, that there there might be specific exceptions for some of them, and that the list isn't necessarily complete--
-
Recommendation systems that optimize for "engagement" (or proxy measures thereof).
-
Anything that identifies or tracks people, or proxies like vehicles, in spaces open to the public. Also collection of data that would be useful for this.
-
Anything that mass-classifies private communications, including closed group communications, for any use by anybody not involved in the communication.
-
Anything specifically designed to produce media showing real people in false situations or to show them saying or doing things they have not actually done.
-
Anything that adaptively tries to persuade anybody to buy anything or give anybody money, or to hold or not hold any opinion of any person or organization.
-
Anything that tries to make people anthropomorphize it or develop affection for it.
-
Anything that tries to classify humans into risk groups based on, well, anything.
-
Anything that purports to read minds or act as a lie detector, live or on recorded or written material.
↑ comment by [deleted] · 2023-05-05T17:55:29.784Z · LW(p) · GW(p)
Good list. Another one that caught my attention that I saw in the EU act was AIs specialised into subliminal messages. people's choices can be somewhat conditioned in favor or against things in certain ways by feeding them sensory data even if it's not consciously perceptible, it can also affect their emotional states more broadly.
I don't know how effective this stuff is in real life, but I know that it at least works.
Anything that tries to classify humans into risk groups based on, well, anything.
A particular example of that one is systems of social scoring, which are surely gonna be used by authoritarian regimes. You can screw people up in so many ways when social control is centralised with AI systems. It's great to punish people for not being chauvinists
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2023-05-16T07:52:10.063Z · LW(p) · GW(p)
A particular example of that one is systems of social scoring, which are surely gonna be used by authoritarian regimes.
comment by Roko · 2023-05-04T12:35:17.274Z · LW(p) · GW(p)
I think we need a strategic shift in AI development away from general intelligence towards powerful narrow AI
Unfortunately I think that the "lay of the land" is just biased against this - if you look at the historical sequence of events that led us to the situation we're in now it's that narrow systems get beaten again and again by general systems as the problems get more complex and as the compute available increases.
The first rule is that ASI is inevitable, and within that there are good or bad paths. I think if one tries to stop ASI forever, one ends up with either a collapse of civilization, or someone else making the ASI, neither of which are desirable.
However I do think a pause for a decade is a wise idea.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-04T13:07:47.533Z · LW(p) · GW(p)
The first rule is that ASI is inevitable, and within that there are good or bad paths.
I don't agree with this. ASI is not inevitable, as we can always decide not to develop it. Nobody will even lose any money! As long as we haven't solved alignment, there is no "good" path involving ASI, and no positive ROI. Thinking that it is better that player X (say, Google) develops ASI first, compared to player Y (say, the Chinese) is a fallacy IMO because if the ASI is not aligned with our values, both have the same consequence.
I'm not saying focusing on narrow AI is easy, and if someone comes up with a workable solution for alignment, I'm all for ASI. But saying "ASI is inevitable" is counterproductive in my opinion, because it basically says "any sane solution is impossible" given the current state of affairs.
Replies from: Roko↑ comment by Roko · 2023-05-04T15:26:06.277Z · LW(p) · GW(p)
as we can always decide not to develop it
If you really think that through in the long-term it means a permanent ban on compute that takes computers back to the level they were in the 1970s, and a global enforcement system to keep it that way.
Furthermore, there are implications for space colonization: if any group can blast away from the SOL system and colonize a different solar system, they can make an ASI there and it can come back and kill us all. Similarly, it means any development on other planets must be monitored for violations of the compute limit, and we must also monitor technology that would indirectly lead to a violation of the limits on compute, i.e. any technology that would allow people to build an advanced modern chip fab without the enforcers detecting it.
In short, you are trying to impose an equilibrium which is not incentive compatible - every agent with sufficient power to build ASI has an incentive to do so for purely instrumental reasons. So, long-term the only way to not build misaligned, dangerous ASI is build an aligned ASI.
However that is a long-term problem. In the short term there are a very limited number of groups who can build it so they can probably coordinate.
Replies from: Davidmanheim, Karl von Wendt↑ comment by Davidmanheim · 2023-05-09T20:33:48.631Z · LW(p) · GW(p)
We decided to restrict nuclear power to the point where it's rare in order to prevent nuclear proliferation. We decided to ban biological weapons, almost fully successfully. We can ban things that have strong local incentives, and I think that ignoring that, and claiming that slowing down or stopping can't happen, is giving up on perhaps the most promising avenue for reducing existential risk from AI. (And this view helps in accelerating race dynamics, so even if I didn't think it was substantively wrong, I'd be confused as to why it's useful to actively promote it as an idea.)
Replies from: Roko↑ comment by Roko · 2023-05-15T21:51:52.272Z · LW(p) · GW(p)
We decided to restrict nuclear power
This is enforced by the USA though, and the USA is a nuclear power with global reach.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2023-05-16T09:01:48.232Z · LW(p) · GW(p)
No, it was and is a global treaty enforced multilaterally, as well as a number of bans on testing and arms reduction treaties. For each, there is a strong local incentive for states - including the US - to defect, but the existence of a treaty allows global cooperation.
With AGI, of course, we have strong reasons to think that the payoff matrix looks something like the following:
(0,0) (-∞, 5-∞)
(5-∞, -∞) (-∞, -∞)
So yes, there's a local incentive to defect, but it's actually a prisoner's dilemma where the best case for defecting is identical to suicide.
↑ comment by Karl von Wendt · 2023-05-04T17:45:46.089Z · LW(p) · GW(p)
One of the reasons I wrote this post is that I don't believe in regulation to solve this kind of problem (I'm still pro regulation). I believe that we need to get a common understanding of what are stupid things no one in their right mind would ever do (see my reply to jbash). To use your space colonization example: we certainly can't regulate what people do somewhere in outer space. But if we survive long enough to get there, then we have either solved alignment or we have finally realized that it's not possible, which will hopefully be common knowledge by then.
Let's say someone finds a way to create a black hole, but there's no way to contain it. Maybe it's even relatively easy for some reason - say it costs 10 million dollars or so. It's probably not possible to prevent everyone forever from creating one, but the best - IMO the only - option to prevent earth from getting destroyed immediately is to make it absolutely clear to everyone that creating a black hole is suicidal. There is no guarantee that this will hold forever, but given the facts (doable, uncontainable) it's the only alternative that doesn't involve killing everyone else or locking them up forever.
We may need to restrict access to computing power somehow until we solve alignment, so not every suicidal terrorist can easily create an AGI at some point. I don't think we'll have to go back to the 1970's, though. Like I wrote, I think there's a lot of potential with the AI we already have, and with narrow, but powerful future AIs.
Replies from: Roko↑ comment by Roko · 2023-05-05T11:29:57.077Z · LW(p) · GW(p)
the best - IMO the only - option to prevent earth from getting destroyed immediately is to make it absolutely clear to everyone that creating a black hole is suicidal.
I am pretty sure you are just wrong about this and there are people who will gladly pay $10M to end the world, or they would use it as a blackmail threat and a threat ignorer would meet a credible threatener, etc.
People are a bunch of unruly, dumb barely-evolved monkeys and the left tail of human stupidity and evil would blow your mind.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-05T12:12:15.380Z · LW(p) · GW(p)
You may be right about that. Still, I don't see any better alternative. We're apes with too much power already, and we're getting more powerful by the minute. Even without AGI, there are plenty of ways to end humanity (e.g. bioweapons, nanobots, nuclear war, bio lab accidents ...) Either we learn to overcome our ape-brain impulses and restrict ourselves, or we'll kill ourselves. As long as we haven't killed ourselves, I'll push towards the first option.
Replies from: Roko↑ comment by Roko · 2023-05-05T14:19:31.528Z · LW(p) · GW(p)
I don't see any better alternative
I do! Aligned benevolent AI!
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-06T10:54:42.380Z · LW(p) · GW(p)
Well, yes, of course! Why didn't I think of it myself? /s
Honestly, "aligned benevolent AI" is not a "better alternative" for the problem I'm writing about in this post, which is we'll be able to develop an AGI before we have solved alignment. I'm totally fine with someone building an aligned AGI (assuming that it is really aligend, not just seemingly aligned). The problem is, this is very hard to do, and timelines are likely very short.
↑ comment by Mo Putera (Mo Nastri) · 2023-05-08T02:44:04.323Z · LW(p) · GW(p)
At least 2 options to develop aligned AGI, in the context of this discussion:
- Slow down capabilities and speed up alignment just enough that we solve alignment before developing AGI
- e.g. the MTAIR project [? · GW], in this paper, models the effect of a fire alarm for HLMI as "extra time" as speeding up safety research, leading to a higher chance that it is successful before timeline for HLMI
- this seems intuitively more feasible, hence more likely
- Stop capabilities altogether -- this is what you're recommending in the OP
What I don't yet understand is why you're pushing for #2 over #1. You would probably more persuasive if you addressed e.g. why my intuition that #1 is more feasible than #2 is wrong.
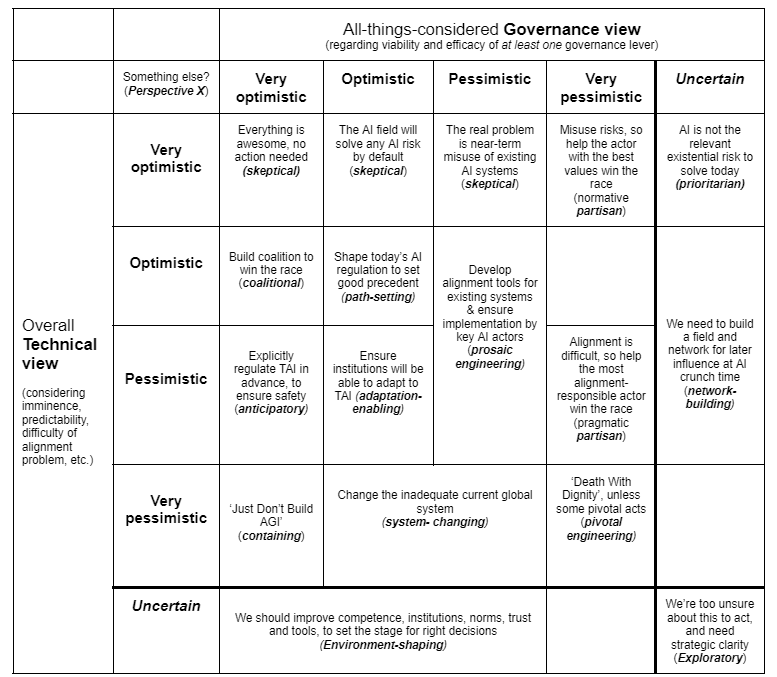
Edited to add: Matthijs Maas' Strategic Perspectives on Transformative AI Governance: Introduction [EA · GW] has this (oversimplified) mapping of strategic perspectives. I think you'd probably fall under (technical: pessimistic or very; governance: very optimistic), while my sense is most LWers (me included) are either pessimistic or uncertain on both axes, so there's that inferential gap to address in the OP.
↑ comment by Karl von Wendt · 2023-05-08T08:57:11.106Z · LW(p) · GW(p)
I'm obviously all for "slowing down capabilites". I'm not for "stopping capabilities altogether", but for selecting which capabilites we want to develop, and which to avoid (e.g. strategic awareness). I'm totally for "solving alignment before AGI" if that's possible.
I'm very pessimistic about technical alignment in the near term, but not "optimistic" about governance. "Death with dignity" is not really a strategy, though. If anything, my favorite strategy in the table is "improve competence, institutions, norms, trust, and tools, to set the stage for right decisions": If we can create a common understanding that developing a misaligned AGI would be really stupid, maybe the people who have access to the necessary technology won't do it, at least for a while.
The point of my post here is not to solve the whole problem. I just want to point out that the common "either AGI or bad future" is wrong.
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2023-05-16T04:26:39.617Z · LW(p) · GW(p)
Sure, I mostly agree. To repeat part of my earlier comment, you would probably more persuasive if you addressed e.g. why my intuition that #1 is more feasible than #2 is wrong. In other words, I'm giving you feedback on how to make your post more persuasive to the LW audience. This sort [LW(p) · GW(p)] of response ("Well, yes, of course! Why didn't I think of it myself? /s") doesn't really persuade readers; bridging inferential gaps [? · GW] would.
Replies from: Karl von Wendt↑ comment by Karl von Wendt · 2023-05-16T04:44:11.635Z · LW(p) · GW(p)
Good point! Satirical reactions are not appropriate in comments, I apologize. However, I don't think that arguing why alignment is difficult would fit into this post. I clearly stated this assumption in the introduction as a basis for my argument, assuming that LW readers were familiar with the problem. Here are some resources to explain why I don't think that we can solve alignment in the next 5-10 years: https://intelligence.org/2016/12/28/ai-alignment-why-its-hard-and-where-to-start/, https://aisafety.info?state=6172_, https://www.lesswrong.com/s/TLSzP4xP42PPBctgw/p/3gAccKDW6nRKFumpP [? · GW]