Developmental Stages in Multi-Problem Grokking
post by James Sullivan · 2024-09-29T18:58:22.954Z · LW · GW · 0 commentsContents
Summary What is Developmental Interpretability? What is the local learning coefficient? How does this apply to alignment? Multi-Problem Grokking Experiments Further Work Conclusion Acknowledgments None No comments
Summary
This post is my capstone project for BlueDot Impact’s AI Alignment course. It was a 12 week online course that covered AI risks, alignment, scalable oversight, technical governance and more. You can read more about it here.
In this project, I investigated the use of a developmental interpretability method—specifically, local learning coefficient estimation—to identify developmental stages in a toy transformer model. The model was tasked with learning both modular addition and modular multiplication simultaneously. Training followed a grokking pattern, where the model initially memorized the training data before gradually generalizing. To observe the impacts on test loss and the learning coefficient during training, I adjusted the ratio of addition to multiplication problems in the training dataset. This approach allowed me to examine how the model's learning dynamics changed based on the composition of the training data.
The models exhibited unique grokking patterns for addition and multiplication operations. These patterns varied significantly based on the proportion of addition to multiplication problems in the training data. When the ratio of problem types was more uneven, the local learning coefficient (LLC) began to decline earlier in the training process. This earlier decline in LLC mirrored the faster grokking behavior seen in the loss curves for the dominant problem type. However, despite these timing differences, the overall shape of the LLC curve remained similar across all ratios tested. Importantly, the LLC curves did not reveal separate, distinct stages for learning addition versus multiplication, contrary to the initial hypothesis.
The full code can be found here.
What is Developmental Interpretability?
The next few sections summarize developmental interpretability, the local learning coefficient, and their applications for alignment. If you’re familiar with these subjects, you can skip to the experiment section below.
Developmental Interpretability is a relatively new research agenda that seeks to apply Singular Learning Theory (SLT) to understanding neural networks. It tries to understand the development of structure within neural networks by looking at a series of phase transitions within networks during training. A developmental approach is useful because studying the incremental changes within a model could be easier than studying a particular state of a model.
What is the local learning coefficient?
The local learning coefficient (LLC) is a measure of a model’s complexity and is a useful tool for comparing two models. We know that if two models have different LLCs then they must be qualitatively different models, but having the same LLC doesn’t necessarily mean that two models are qualitatively the same. This is useful for studying models during training because we can measure the LLC at different points during training and look for changes, or phase transitions, that mean the model is qualitatively different. This is one tool for looking for developmental stages during training.
How does this apply to alignment?
There is no consensus on how to align advanced AI systems, but most alignment proposals rely at least partially on gaining a deeper understanding of how neural networks learn and the structures that form within them. By gaining a deeper understanding of these systems we could potentially detect deception, learn how to interpret a model’s activation to detect planning, and detect if models are learning situational awareness and developing scheming behavior.
Developmental interpretability specifically tries to gain that deeper understanding through looking for developmental stages within models as they are being trained. Its hypothesis is that enough of the structure and understanding within models are explainable through these transitions during training that these transitions can give us a deeper understanding of the model and will lead to better alignment techniques.
The field of interpretability as a whole has a ways to go before it makes practical contributions to alignment, but I think methods like RLHF, Constitutional AI, or AI debate that only use the inputs and outputs of models have fundamental flaws that will make techniques that work with internals of models necessary for solving alignment.
If you want more details on developmental interpretability, the local learning coefficient, and their application for AI safety, these are some great posts that go into more detail. They were my sources for writing this section.
- Dialogue Introduction to Singular Learning Theory [LW · GW]
- Towards Developmental Interpretability [LW · GW]
- You’re Measuring Model Complexity Wrong [LW · GW]
- Singular Learning Theory for Alignment
- Distilling Singular Learning Theory Sequence [? · GW]
Multi-Problem Grokking Experiments
My hypothesis was that if I trained a single layer transformer model on modular addition and modular multiplication in a grokking scenario and varied the proportion of addition to multiplication in the training data, I could create separate grokking behavior for each problem type, and that separate behavior would create noticeable developmental stages in the LLC.
The problems were in the form (a + b) % 113 = c where a and b were the inputs and c were the labels. I represented addition as a 1 in the input and multiplication as a 0, so [5, 1, 13] would be an addition problem with label of [18] and input [8, 0, 23] would be a multiplication problem with label [71]. The training data always had 16900 problems regardless of the addition to multiplication problem ratio.
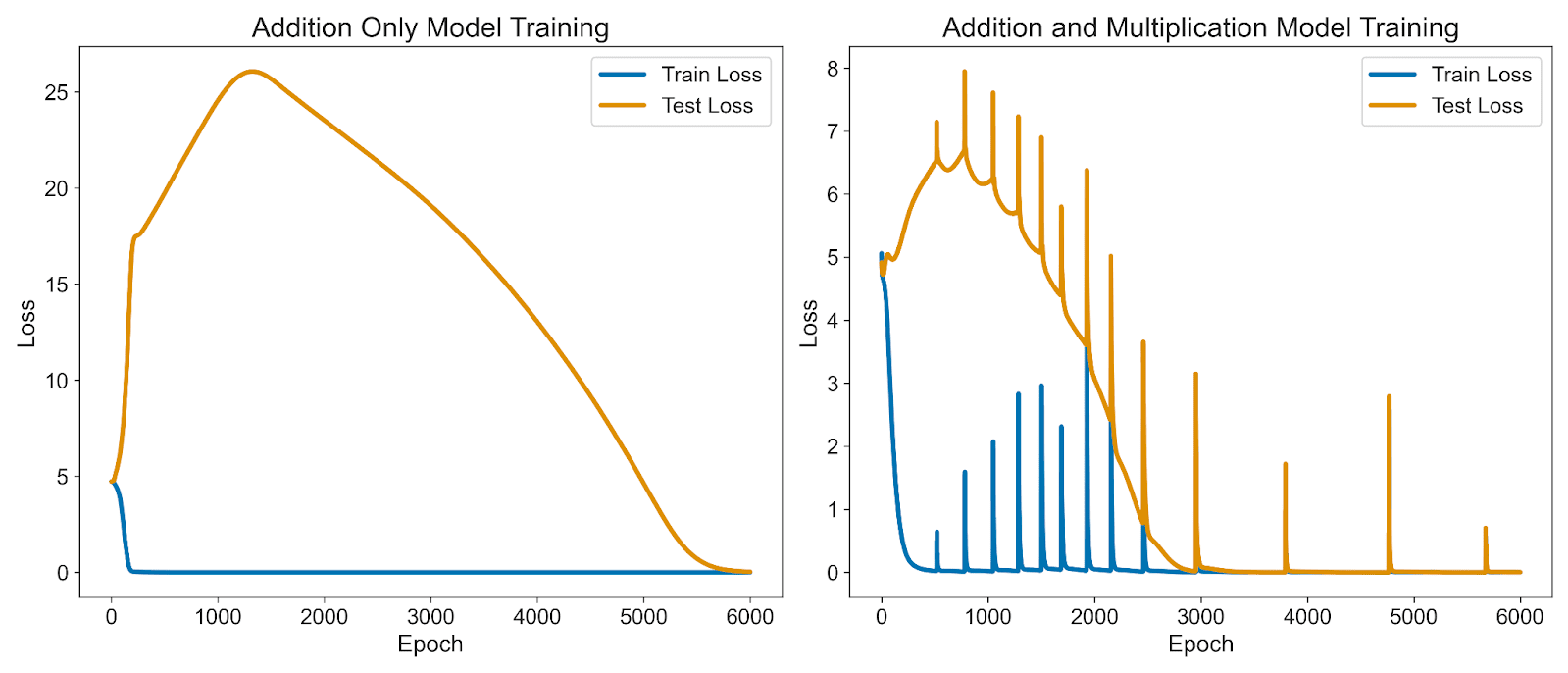
The left graph shows the loss curves from when the model was trained on only addition problems. The right graph shows the model being trained on both addition and multiplication problems and you can see a lot of nasty loss spikes during training. I tried a lot of different techniques to get rid of these spikes including many different hyperparameters combinations, learning rate schedulers, optimizers, and layer normalization. Some changes made the spikes less severe, some made them more severe but I was not able to get rid of them. Because of the loss spikes, I’m using a rolling average for the rest of the graphs that I show.
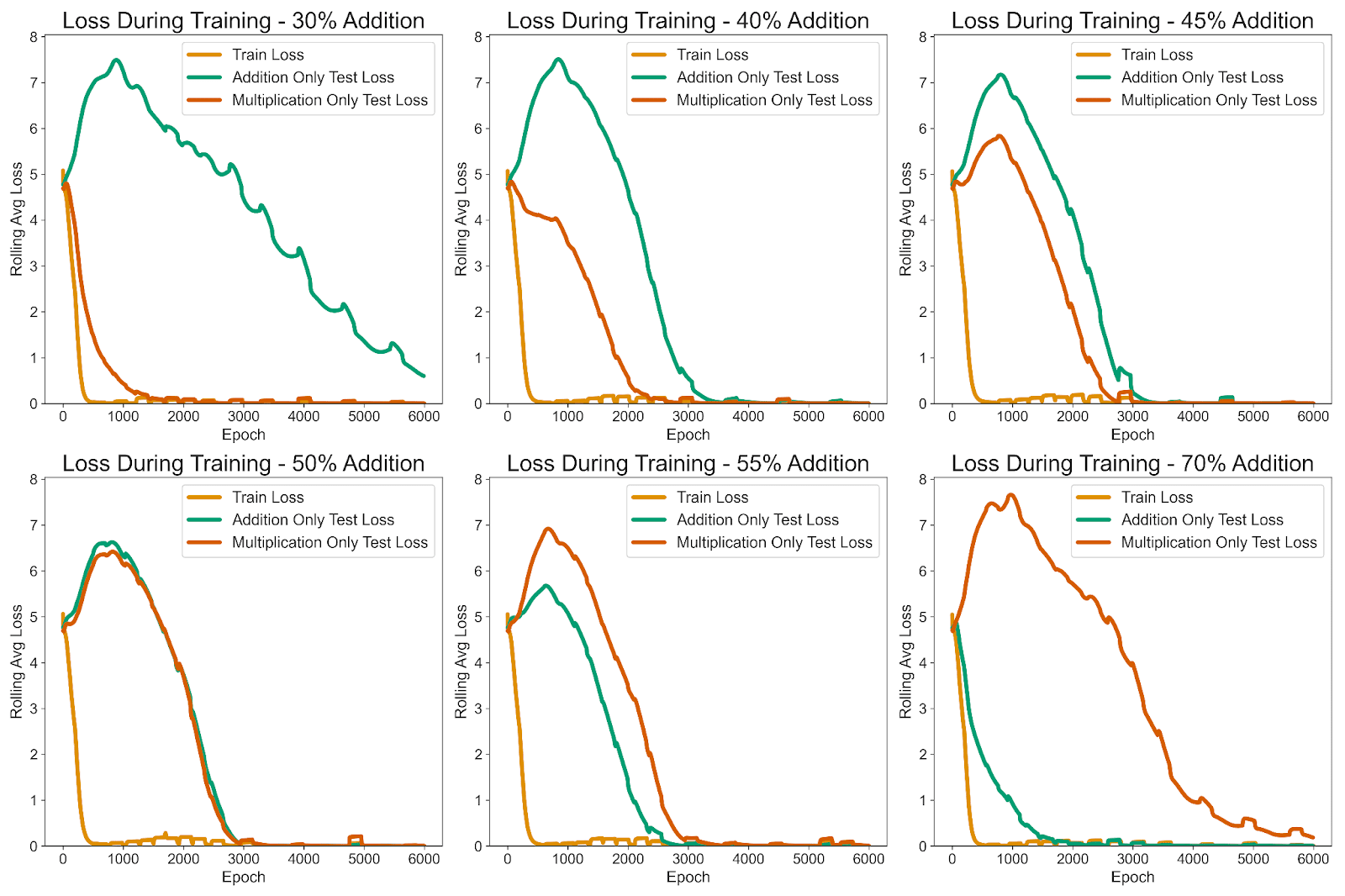
The above graphs show the model being trained with between 30% to 70% of the training data being addition problems. I separated the test data into addition only test and multiplication only test sets so we could see how the model groks each problem type separately. From these loss curves we can see that the model shows separate grokking behavior depending on the proportion of problem types in the training data.
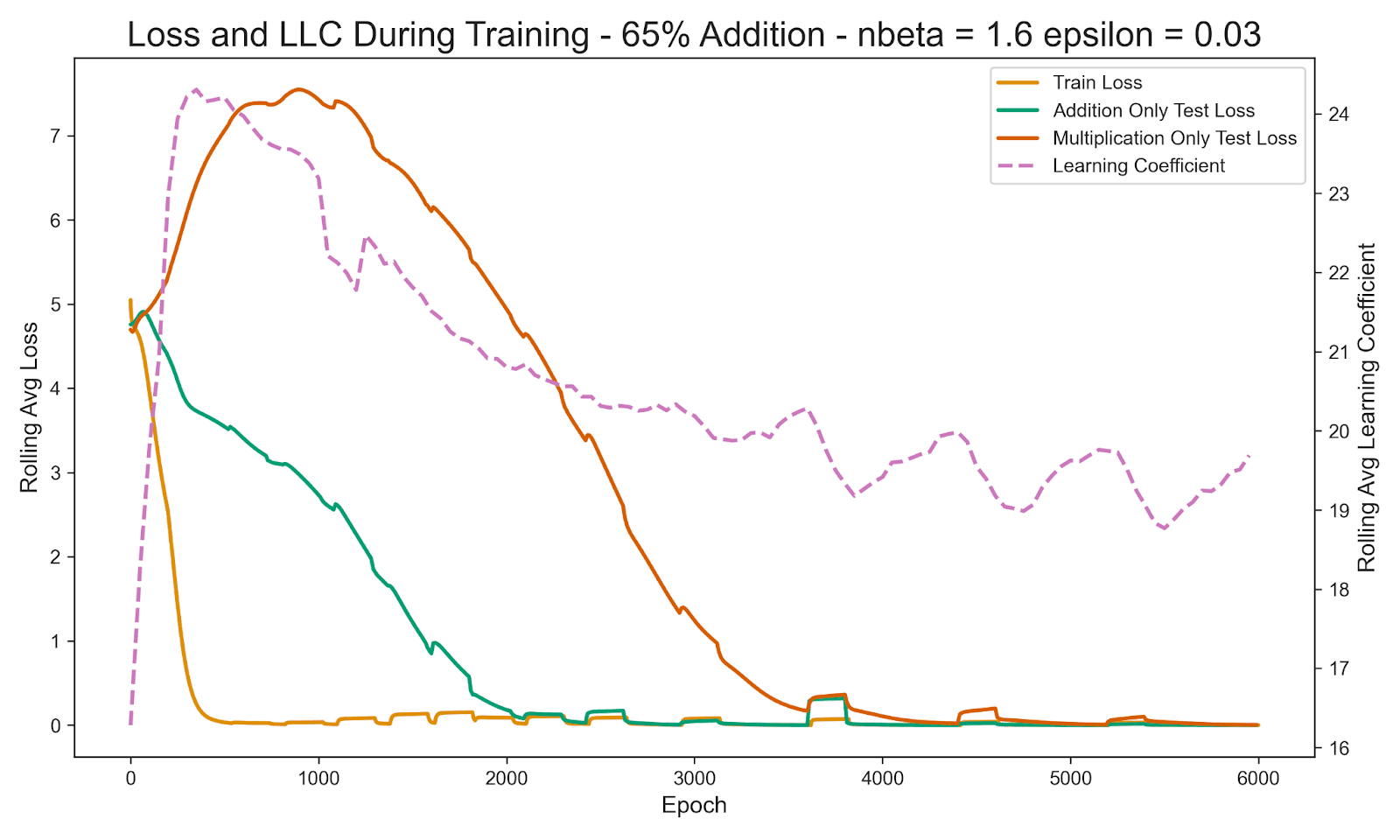
I measured the local learning coefficient during training for each ratio of problem types. Above you can see the LLC measured during training when the training data was 65% addition. We see a rapid increase as the model overfits to the training data and then a decline in the LLC as it generalizes both addition and multiplication. This shows a phase transition in the model from the peak of the LLC curve to the when it stops declining and has generalized.
I speculate that the roughness in the LLC curves is at least partially due to the loss spikes during training. I would be curious to see what they would look like if the loss spikes did not occur. LLC estimation is also very sensitive to what hyperparameters are used to get the estimates, and while I did experiment with different combinations, perhaps there are parameters that could give smoother results.
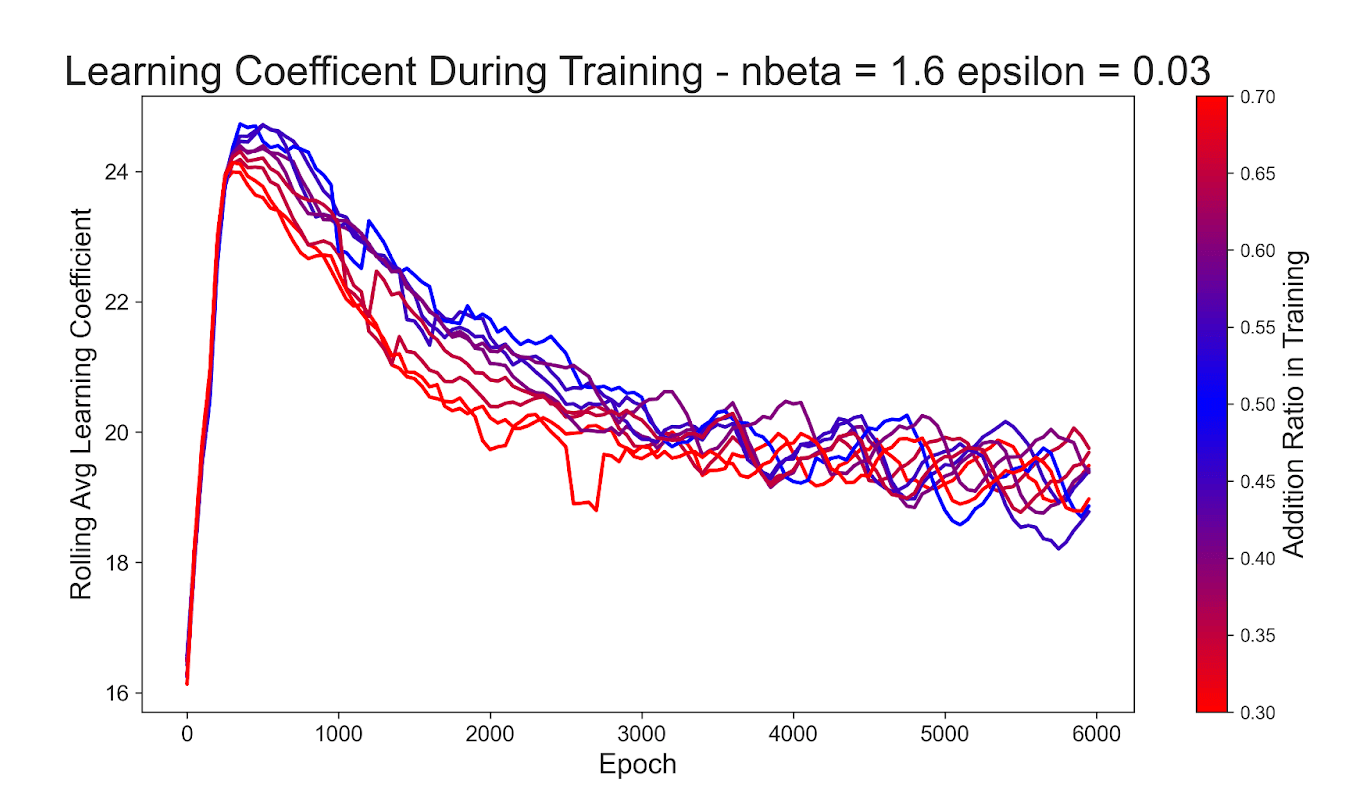
The above graph compares the LLC values during training for each ratio of problem type that I tested. The lines are colored based on how even the problem ratio is with the more uneven ratios being red and the more even ratios blue. You see in the first half of the graph that the more uneven the ratio, the sooner the decline begins and the more even the ratio, the later it begins. This makes sense with the loss curves that we saw in the previous graphs because the more uneven ratios have a dominant problem type that groks much faster. This faster grokking (and generalization) is reflected in the LLC curve as a sooner decline.
My hypothesis was that different rates of grokking of the addition and multiplication problem types would create noticeably different developmental stages that could be seen in the LLC during training, and I don’t think that is what this data shows. We do see a developmental stage in the LLC as the models generalize, but it is still clearly a single decline in the value after the model is done overfitting.
Further Work
The data from these experiments was plagued with noise that I attribute at least partially to the loss spikes during training. Further work could investigate the cause of this instability. One possible cause could be what this paper calls the “slingshot mechanism”. The authors argue that the mechanism is integral to grokking behavior. If we could create a grokking scenario with at least two problem types that does not suffer loss spikes, perhaps we could collect cleaner data that could give us different conclusions.
This work was inspired by a paper called Progress Measures for Grokking Via Mechanistic Interpretability. The authors trained a model on modular addition in a scenario similar to what I described in the above experiments. They then applied some mechanistic interpretability techniques to reverse engineer the algorithm that the model learns to do modular addition. Perhaps you could apply those techniques to see how the algorithms for modular addition and multiplication co-exist in the model and make comparisons to when the model is only learning addition.
Conclusion
In this work, I applied developmental interpretability techniques to explore developmental stages in a transformer model learning modular addition and multiplication. By varying the ratio of problem types in training data, I observed distinct grokking behaviors for each operation. Models trained on uneven ratios showed earlier declines in local learning coefficient (LLC) values, indicating faster generalization for the dominant problem type.
Contrary to my hypothesis, I did not observe separate developmental stages for addition and multiplication in the LLC curves. Instead, the curves showed a qualitatively similar shape across different ratios. The presence of loss spikes during training introduced challenges in data interpretation and may have contributed to the roughness in LLC curves.
While this work provides insights into learning dynamics of models tackling multiple problem types, it also highlights areas for further research. Future work could focus on developing multi-problem grokking scenarios without loss spikes and applying mechanistic interpretability techniques to better understand how different operations coexist within the model. This research contributes to the field of developmental interpretability and its potential applications in AI alignment, though it also underscores the complexity of neural network learning processes and the need for refined interpretability techniques.
Acknowledgments
Thanks to Jesse Hoogland for giving feedback on this write up and George Wang, Stan van Winderden, and Ben Shaffrey for helping with my learning coefficient estimation.
0 comments
Comments sorted by top scores.