Dialogue introduction to Singular Learning Theory
post by Olli Järviniemi (jarviniemi) · 2024-07-08T16:58:10.108Z · LW · GW · 15 commentsContents
I. Theoretical foundations II. Practical side None 15 comments
Alice: A lot of people are talking about Singular Learning Theory. Do you know what it is?
Bob: I do. (pause) Kind of.
Alice: Well, I don't. Explanation time?
Bob: Uh, I'm not really an expert on it. You know, there's a lot [LW · GW] of [LW · GW] materials [LW · GW] out [LW · GW] there [LW · GW] that--
Alice: that I realistically won't ever actually look at. Or, I've looked at them a little, but I still have basically no idea what's going on. Maybe if I watched a dozen hours of introductory lectures I'd start to understand it, but that's not currently happening.
What I really want is a short overview of what's going on. That's self-contained. And easy to follow. Aimed at a non-expert. And which perfectly answers any questions I might have. So, I thought I'd ask you!
Bob: Sorry, I'm actually really not--
Alice: Pleeeease?
[pause]
Bob: Ah, fine, I'll try.
So, you might have heard of ML models being hard to interpret. Singular Learning Theory (SLT) is an approach for understanding models better. Or, that's one motivation, at least.
Alice: And how's this different from a trillion other approaches to understanding AI?
Bob: A core perspective of SLT is studying how the model develops during training. Contrast this to, say, mechanistic interpretability, which mostly looks at the fully trained model. SLT is also more concerned about higher level properties.
As a half-baked analogue, you can imagine two approaches to studying how humans work: You could just open up a human and see what's inside. Or, you could notice that, hey, you have these babies, which grow up into children, go through puberty, et cetera, what's up with that? What are the different stages of development? Where do babies come from? And SLT is more like the second approach.
Alice: This makes sense as a strategy, but I strongly suspect you don't currently know what an LLM's puberty looks like.
Bob: (laughs) No, not yet.
Alice: So what do you actually have?
Bob: The SLT people have some quite solid theory, and some empirical work building on top of that. Maybe I'll start from the theory, and then cover some of the empirical work.
Alice: (nods)
I. Theoretical foundations
Bob: So, as you know, nowadays the big models are trained with gradient descent. As you also know, there's more to AI than gradient descent. And for a moment we'll be looking at the Bayesian setting, not gradient descent.
Alice: Elaborate on "Bayesian setting"?
Bob: Imagine a standard deep learning setup, where you want your neural network to classify images, predict text or whatever. You want to find parameters for your network so that it has good performance. What do you do?
The gradient descent approach is: Randomly initialize the parameters, then slightly tweak them on training examples in the direction of better performance. After a while your model is probably decent.
The Bayesian approach is: Consider all possible settings of the parameters. Assign some prior to them. For each model, check how well they predict the correct labels on some training examples. Perform a Bayesian update on the prior. Then sample a model from the posterior. With lots of data you will probably obtain a decent model.
Alice: Wait, isn't the Bayesian approach very expensive computationally?
Bob: Totally! Or, if your network has 7 parameters, you can pull it off. If it has 7 billion, then no. There are way too many models, we can't do the updating, not even approximately.
Nevertheless, we'll look at the Bayesian setting - it's theoretically much cleaner and easier to analyze. So forget about computational costs for a moment.
Alice: Will the theoretical results also apply to gradient descent and real ML models, or be completely detached from practice?
Bob: (winks)
Alice: You know what, maybe I'll just let you talk.
Bob: There's a really fascinating phenomenon in the Bayesian setting: you can have abrupt "jumps" in the model you sample (which people call phase changes). Let me explain.
Suppose you do Bayesian updates on, say, 10000 data points. Maybe your posterior then looks like this:
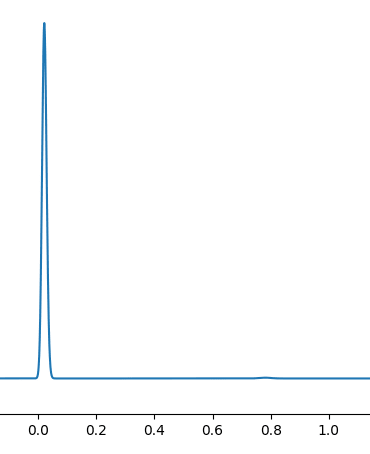
And you might think: probably with more data there will just be convergence around the optimal model at . You feed in 500 data points more:
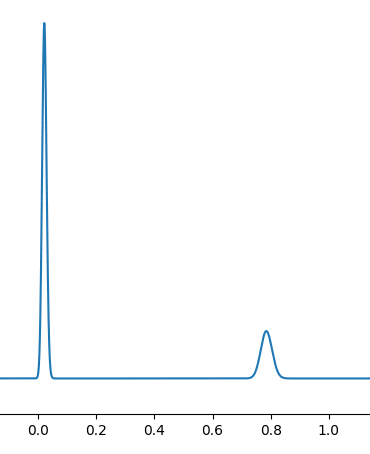
Huh, what's that? You feed in another 500 data points:
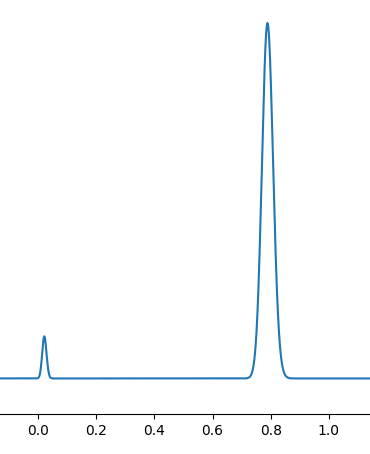
You don't necessarily get gradual convergence around the "best model"! Instead, you can have an abrupt jump: over the course of relatively few more examples, your posterior has totally shifted from one place to another, and the types of models you get by sampling the posterior would be completely different for 11000 data points from the ones with 10000 points.
Alice: Wait, are these real graphs?
Bob: Real in the sense of being the result of Bayesian updates, yes, but I specifically crafted a loss function to demonstrate my point, and it's all very toy.
There are more natural examples when you have more than one parameter, though, and the naive view of gradual convergence is definitely false.
Alice: Why does this happen?
Bob: Loosely, there are two things that determine the size of a bump (assuming it's sensible to decompose the posterior/model space into "bumps"):
- The height of the bump: how well does the best model of the bump perform?
- The width of the bump: once you stray away from the local best model, how quickly does performance drop?
At one extreme, you have an excellent model, but the parameters have to be very precisely right, or it breaks down fast. This would be a narrow, tall spike in likelihood.
At another extreme, you have a mediocre model, but the parameters are robust to small changes. This would be a wide, low bump in likelihood.
Alice: I would expect that when you increase the amount of data, you start moving towards the "excellent-but-fragile" models.
Bob: That's right. Intuitively, at the beginning the prior favors wide, low bumps: if you have no data, you cannot locate the good-but-specific models. But the Bayesian updates favor the good-but-specific models, and eventually they start to take over. This can happen rather quickly - the posterior bumps don't have to be of comparable sizes for long.
Like all things in life, the performance-specificity tradeoff is a spectrum, and you can have multiple jumps from one bump to another as you shove in more data.
Alice: This talk about "fragility" or "specificity" feels a bit vague to me, though. Care to clarify?
Bob: Sure. This is slightly more technical, so buckle up.
Setting the prior aside, we are interested only in models' predictive performance, i.e. the average log-probability given to the correct labels, i.e. the loss function. (This corresponds to the likelihood factor for Bayesian updates.)
Consider a model that's locally optimal for this loss function. Here, let me sketch a couple of plots:


Here lower is better performance, so our bumps have turned into basins.
What I mean by "fragility" or "specificity" is roughly: how steeply does loss increase as we move away from the local optimum?
More precisely: If the performance of the model is , we look at the models which have loss at most for some small error (and which are part of the same basin), and specifically their volume - how "many" such models are there?
Alice: To check I understand: if I draw the parameter-axis here, and the threshold for additional error here, the parameters that result in only worse loss are the red segment here. And "volume" is just length in this case - the length of the red segment.
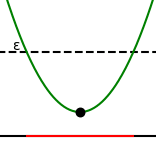
Bob: Yep. Similarly with two parameters, we look at the parameters for which we have only slightly worse loss - the red region here - and it's "volume", in this case area.

And the key question is: how does the length/area/volume behave for small ?
Alice: Oh, I think I can solve this! I've seen this type of arguments a couple [LW · GW] of times [LW · GW] before:
If one considers the partial derivatives at the local optima, then the first derivatives are zero, and the second derivatives are non-negative. It's very unlikely that they are exactly zero, so assume that they are positive--
Bob: (smiles)
Alice: --and thus the basin can be locally modeled as a high-dimensional parabola. That is, it takes the shape
,
where are positive constants. The constants don't really matter, they just stretch the picture, so I'm gonna assume
Alice: How "many" values of are there such that ?
Around , give or take a constant factor.
Alice: (muttering to herself) Indeed, we must have , so any single variable has at most values, and thus they in total have at most values. On the other hand, if we have , then , so there are at least possible values.
Bob: Good, great. Indeed, when the second derivatives don't vanish, is correct.
Alice: Yeah. Probably a similar argument works for the case where some second derivatives are zero, but that case should be really unlikely and so doesn't matter.
Bob: (smiles widely)
Alice: What?
Bob: Do you know what the "singular" in "Singular Learning Theory" stands for?
Alice: Uh oh.
Bob: In general, basins are nasty. The high-dimensional parabola approximations are utterly false. This isn't some pedantic nitpick - it's just a completely wrong picture.
(I kind of let you astray with the pictures I drew above, sorry. )
To illustrate, here's [LW · GW] just one relatively benign example from two dimensions:

And it gets worse when you have billions of parameters. Welcome to deep learning.
Alice: Let me guess: basins of different shapes have different rates of volume-expansion?
Bob: Spot on. For the high-dimensional parabola, the volume-expansion-exponent was , but in general it can be less than that. If the exponent is smaller than - when the model is singular - the basin has more almost-equally-performant models. This corresponds to a larger Bayesian posterior. Exponentially so, due to the nature of these things.
This is the key insight of singular learning theory: singular models really matter.
And indeed, for the Bayesian setting we have hard proof for this. You really are selecting models based on both predictive accuracy and volume-expansion-exponent (better known as the learning coefficient). If you hear people talking about "Watanabe's free energy formula", it's precisely about this.
II. Practical side
Alice: While what you say makes sense, and has new points I hadn't thought about, I can't help but think: this is not SGD. How useful is this in practice, really?
Bob: Tricky question.
Clearly, gradient descent is a very different process. Most importantly, it always performs local updates on the model, doesn't explore the whole parameter space, could be "blocked" from parts of the space by local barriers, and so on. And maybe this matters quite a lot.
On the other hand, some of the insights of SLT do carry over to gradient descent. Most compellingly, there's some empirical work demonstrating it's usefulness. There are also some theoretical arguments [LW · GW] about how simplified models of SGD correspond to Bayesian learning. And on a general level, given that SLT is the right way of thinking about the Bayesian setting, it's reasonable to think about it in the case of SGD as well.
Alice: Say more about the empirical work.
Bob: Applying these methods to deep learning has only started very recently. Which is to say: there's a lot to be done.
In any case, let me talk about a couple of articles I've liked.
There's this paper called "Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition". They look at a toy learning problem - how to store many features in a small number of dimensions - and how both Bayesian methods and stochastic gradient descent learn.
They find that the SLT picture gives non-trivial insight to SGD: The learning trajectory has a couple of sharp drops in loss, accompanied by sharp changes in the (local) learning coefficient. Corresponding phase changes occur when using Bayesian learning.
Alice: Wait, are you saying the phase changes are the same for Bayesian learning and SGD?
Bob: Not quite: in the paper they are unable to find all of the Bayesian phase changes in SGD. This makes sense: the SGD trajectory is local, after all, and doesn't look at the whole parameter space. Thus, SGD might be "missing" some phase changes that Bayesian learning has.
However, they do hypothesize that any SGD phase change can be found from Bayesian learning as well. Any time you see a phase change in SGD, there's - the hypothesis goes - a "Bayesian reason" for it.
Alice: What else you've got?
Bob: There's a post about the learning coefficient in a modular addition network [LW · GW].
They demonstrate that networks which memorize data vs. which generalize have vastly different learning coefficients. Thus, you can get information about generalization behavior without actually evaluating the model on new inputs!
They also verify that the learning coefficient approximation methods work well for medium-sized networks.
Alice: I was about to ask: These examples seem to be about rather small networks and toy settings. Is there anything on larger models?
Bob: See "The Developmental Landscape of In-Context Learning". They train a transformer with 3 million parameters on Internet text.
They approximate the local learning coefficient throughout training and, using that and other methods, are able to identify discrete phases in the language model's development. These phases include things like learning frequencies of bi-grams and forming induction heads.
Alice: That's... actually pretty compelling. Anything with even larger models?
Bob: Not yet, as far as I know. I hope there will be!
Alice: So do I - maybe we'll soon identify the puberty stage of LLMs.
Bob: Yes, that.
Alice: I still have a few question. Isn't the learning coefficient only meaningful for local optima - but presumably we can't find local optima of real life big models? And I'm still a bit confused about interpreting the learning coefficient: sure, we can plot the learning coefficient during training and notice something's changed, but what then? Also, does it require much additional compute? Oh, and about the applicability to SGD, how sure--
Bob: (hastily) Ah, yeah, sorry, I'd love to answer your questions, but I have to go now. Maybe if you have further questions, you could ask people in the comment section or elsewhere.
Alice: Right, I'll do that. Thanks for the explanation!
15 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-07-08T21:46:13.849Z · LW(p) · GW(p)
[Low confidence and low familiarity]
My main issue with the case for singular learning theory is that I can't think of any particular use cases that seem both plausible and considerably useful. (And the stories I've heard don't seem compelling to me.)
I think it seems heuristically good to generally understand more stuff about how SGD works (and probably better for safety than capabilities), but this feels like a relatively weak theory of change.
I find the examples of empirical work you give uncompelling evidence for usefulness because they were all cases where we could have answered all the relevant questions using empirics and they aren't analogous to a case where we can't just check empirically.
(Edit: added "evidence for usefulness" to the prior sentence. More precisely, I mean uncompelling as responses to the question of "How useful is this in practice, really?", not necessarily uncompelling as demonstrations that SLT is an interesting theory for generally understanding more stuff about how SGD works.)
For the case of the paper looking at a small transformer (and when various abilities emerge), we can just check when a given model is good at various things across training if we wanted to know that. And, separately, I don't see a reason why knowing what a transformer is good at in this way is that useful.
Here is my probably confused continuation of this dialogue along these lines:
Alice: Ok, so I can see how SLT is a better model of learning with SGD than previous approaches. An d pretending that SGD just learns via randomly sampling from the posterior you discussed earlier seems like a reasonable approximation to me. So, let's just pretend that our training was actually this random sampling process. What can SLT do to reduce AI takeover risk?
[simulated] Bob: Have you read this section discussing Timaeus's next steps [LW · GW] or the post on dev interp [LW · GW]? What about the application of detecting and classifying phase transitions?
Alice: Ok, I have some thoughts on the detecting/classifying phase transitions application. Surely during the interesting part of training, phase transitions aren't at all localized and are just constantly going on everywhere? So, you'll already need to have some way of cutting the model into parts such that these parts are cleaved nicely by phase transitions in some way. Why think such a decomposition exists? Also, shouldn't you just expect that there are many/most "phase transitions" which are just occuring over a reasonably high fraction of training? (After all, performance is often the average of many, many sigmoids.)
[simulated] Bob: I can't simulate.
Alice: Further, probably a lot of what causes s shaped loss curves is just multi-component learning [LW · GW]. I agree that many/most interesting things will be multi-component (maybe this nearly perfectly corresponds in practice to the notion of "fragility" we discussed earlier). Why think that this is a good handle?
[simulated] Bob: I can't simulate.
Alice: I don't understand the MAD and predicting generalization applications or why SLT would be useful for these so I can't really comment on them.
Replies from: dmurfet, jarviniemi↑ comment by Daniel Murfet (dmurfet) · 2024-07-10T00:43:59.092Z · LW(p) · GW(p)
The case for singular learning theory (SLT) in AI alignment is just the case for Bayesian statistics in alignment, since SLT is a mathematical theory of Bayesian statistics (with some overly restrictive hypotheses in the classical theory removed).
At a high level the case for Bayesian statistics in alignment is that if you want to control engineering systems that are learned rather than designed, and if that learning means choosing parameters that have high probability with respect to some choice of dataset and model, then it makes sense to understand what the basic structure of that kind of Bayesian learning is (I’ll put aside the potential differences between SGD and Bayesian statistics, since these appear not to be a crux here). I claim that this basic structure is not yet well-understood, that it is nonetheless possible to make fundamental progress on understanding it at both a theoretical and empirical level, and that this understanding will be useful for alignment.
The learning process in Bayesian statistics (what Watanabe and we call the singular learning process) is fundamental, and applies not only to training neural networks, but also to fine-tuning and also to in-context learning. In short, if you expect deep learning models to be “more optimal” over time, and for example to engage in more sophisticated kinds of learning in context (which I do), then you should expect that understanding the learning process in Bayesian statistics should be even more highly relevant in the future than it is today.
One part of the case for Bayesian statistics in alignment is that many questions in alignment seem to boil down to questions about generalisation. If one is producing complex systems by training them to low loss (and perhaps also throwing out models that have low scores on some safety benchmark) then in general there will be many possible configurations with the same low loss and high safety scores. This degeneracy is the central point of SLT. The problem is: how can we determine which of the possible solutions actually realises our intent?
The problem is that our intent is either not entirely encoded in the data, or we cannot be sure that it is, so that questions of generalisation are arguably central in alignment. In present day systems, where alignment engineering looks like shaping the data distribution (e.g. instruction fine-tuning) then a precise form of this question is how models generalise from the (relatively) small number of demonstrations in the fine-tuning dataset.
It therefore seems desirable to have scalable empirical tools for reasoning about generalisation in large neural networks. The learning coefficient in SLT is the obvious theoretical quantity to investigate (in the precise sense that two solutions with the same loss will be differently preferred by the Bayesian posterior, with the one that is “simplest” i.e. has lower learning coefficient, being preferred). That is what we have been doing. One should view the empirical work Timaeus has undertaken as being an exercise in validating that learning coefficient estimation can be done at scale, and reflects real things about networks (so we study situations where we can independently verify things like developmental stages).
Naturally the plan is to take that tool and apply it to actual problems in alignment, but there’s a limit to how fast one can move and still get everything right. I think we’re moving quite fast. In the next few weeks we’ll be posting two papers to the arXiv:
- G. Wang, J. Hoogland, S. van Wingerden, Z. Furman, D. Murfet “Differentiation and Specialization in Language Models via the Restricted Local Learning Coefficient” introduces the weight and data-restricted LLCs and shows that (a) attention heads in a 3M parameter transformer differentiate over training in ways that are tracked by the weight-restricted LLC, (b) some induction heads are partly specialized to code, and this is reflected in the data-restricted LLC on code-related tasks, (c) attention heads follow the pattern that their weight-restricted LLCs first increase then decrease, which appears similar to the critical periods studied by Achille-Rovere-Soatto.
- L. Carroll, J. Hoogland, D. Murfet “Retreat from Ridge: Studying Algorithm Choice in Transformers using Essential Dynamics” studies the retreat from ridge phenomena following Raventós et al and resolves the mystery of apparent non-Bayesianism there, by showing that over training for an in-context linear regression problem there is tradeoff between in-context ridge regression (a simple but high error solution) and another solution more specific to the dataset (which is more complex but lower error). This gives an example of the “accuracy vs simplicity” tradeoff made quantitative by the free energy formula in SLT.
Your concerns about phase transitions (there being potentially too many of them, or this being a bit of an ill-posed framing for the learning process) are well-taken, and indeed these were raised as questions in our original post [LW · GW]. The paper on restricted LLCs is basically our response to this.
I think you might buy the high level argument for the role of generalisation in alignment, and understand that SLT says things about generalisation, but wonder if that ever cashes out in something useful. Obviously I believe so, but I'd rather let the work speak for itself. In the next few days there will be a Manifund page explaining our upcoming projects, including applying the LLC estimation techniques we have now proven, to studying things like safety fine-tuning and deceptive alignment in the setting of the “sleeper agents” work.
One final comment. Let me call “inductive strength” the number of empirical conclusions you can draw from some kind of evidence. I claim the inductive strength of fundamental theory validated in experiments, is far greater than experiments not grounded in theory; the ML literature is littered with the corpses of one-off experiments + stories that go nowhere. In my mind this is not what a successful science and engineering practice of AI alignment looks like.
The value of the empirical work Timaeus has done to date largely lies in validating the fundamental claims made by SLT about the singular learning process, and seeing that it applies to systems like small language models. To judge that empirical work by the standard of other empirical work divorced from a deeper set of claims, i.e. purely by “the stuff that it finds”, is to miss the point (to be fair we could communicate this better, but I find it sounds antagonistic written down, as it may do here).
Replies from: ryan_greenblatt, ryan_greenblatt, roger-d-1↑ comment by ryan_greenblatt · 2024-07-10T04:00:53.894Z · LW(p) · GW(p)
It sounds like your case for SLT that you make here is basically "it seems heuristically good to generally understand more stuff about how SGD works". This seems like a reasonable case, though considerably weaker than many other more direct theories of change IMO.
I think you might buy the high level argument for the role of generalisation in alignment, and understand that SLT says things about generalisation, but wonder if that ever cashes out in something useful.
This is a reasonably good description of my view.
It seems fine if the pitch is "we'll argue for why this is useful later, trust that we have good ideas in mind on the basis of other aspects of our track record". (This combined with the general "it seems heuristically good to understand stuff better in general" theory of change is enough to motivate some people working on this IMO.)
To judge that empirical work by the standard of other empirical work divorced from a deeper set of claims, i.e. purely by “the stuff that it finds”, is to miss the point
To be clear, my view isn't that this empirical work doesn't demonstrate something interesting. (I agree that it helps to demonstrate that SLT has grounding in reality.) My claim was just that it doesn't demonstrate that SLT is useful. And that would require additional hopes (which don't yet seem well articulated or plausible to me).
When I said "I find the examples of empirical work you give uncompelling because they were all cases where we could have answered all the relevant questions using empirics and they aren't analogous to a case where we can't just check empirically.", I was responding to the fact that the corresponding section in the original post starts with "How useful is this in practice, really?". This work doesn't demonstrate usefulness, it demonstrates that the theory makes some non-trivial correct predictions.
(That said, the predictions in the small transformer case are about easy to determine properties that show up on basically any test of "is something large changing in the network" AFAICT. Maybe some of the other papers make more subtle predictions?)
(I have edited my original comment to make this distinction more clear, given that this distinction is important and might be confusing.)
Replies from: dmurfet↑ comment by Daniel Murfet (dmurfet) · 2024-07-10T05:46:39.065Z · LW(p) · GW(p)
In terms of more subtle predictions. In the Berkeley Primer in mid-2023, based on elementary manipulations of the free energy formula, I predicted we should see phase transitions / developmental stages where the loss stays relatively constant but the LLC (model complexity) decreases.
We noticed one such stage in the language models, and two in the linear regression transformers in the developmental landscape paper. We only partially understood them there, but we've seen more behaviour like this in the upcoming work I mentioned in my other post, and we feel more comfortable now linking it to phenomena like "pruning" in developmental neuroscience. This suggests some interesting connections with loss of plasticity (i.e. we see many components have LLC curves that go up, then come down, and one would predict after this decrease the components are more resistent to being changed by further training).
These are potentially consequential changes in model computation that are (in these examples) arguably not noticeable in the loss curve, and it's not obvious to me how you would be confident to notice this from other metrics you would have thought to track (in each case they might correspond with something, like say magnitude of layer norm weights, but it's unclear to me out of all the thousands of things you could measure why you would a priori associate any one such signal with a change in model computation unless you knew it was linked to the LLC curve). Things like the FIM trace or Hessian trace might also reflect the change. However in the second such stage in the linear regression transformer (LR4) this seems not to be the case.
↑ comment by ryan_greenblatt · 2024-07-10T04:20:16.477Z · LW(p) · GW(p)
At a high level the case for Bayesian statistics in alignment is that if you want to control engineering systems that are learned rather than designed, and if that learning means choosing parameters that have high probability with respect to some choice of dataset and model, then it makes sense to understand what the basic structure of that kind of Bayesian learning is
[...]
I claim that this basic structure is not yet well-understood, that it is nonetheless possible to make fundamental progress on understanding it at both a theoretical and empirical level, and that this understanding will be useful for alignment.
I think I start from a position which is more skeptical than you about the value of improving understanding in general. And also a position of more skepticism about working on things which are closer to fundamental science without more clear theories of impact. (Fundamental science as opposed to having a more clear and straightforward path into the plan for making AI go well.)
This probably explains a bunch of our difference in views. (And this disagreement is probably hard to dig into given that it depends on a bunch of relatively messy heuristics and various views about how progress in deep learning typically happens.)
I don't think fundamental science style theories of change are an unreasonable thing to work on (particularly given the capacity for huge speed ups from AI automation), I just seem to be more skeptical of this type of work than you appear to be.
Replies from: dmurfet, Davidmanheim↑ comment by Daniel Murfet (dmurfet) · 2024-07-10T05:18:41.367Z · LW(p) · GW(p)
I think that's right, in the sense that this explains a large fraction of our difference in views.
I'm a mathematician, so I suppose in my cosmology we've already travelled 99% of the distance from the upper reaches of the theory stratosphere to the ground and the remaining distance doesn't seem like such an obstacle, but it's fair to say that the proof is in the pudding and the pudding has yet to arrive.
If SLT were to say nontrivial things about what instruction fine-tuning and RLHF are doing to models, and those things were verified in experiments, would that shift your skepticism?
I've been reading some of your other writing [LW · GW]:
However, we think that absent substantial advances in science, we're unlikely to develop approaches which substantially improve safety-in-practice beyond baseline methods (e.g., training with RLHF and applying coup probes) without the improvement being captured by black-box control evaluations. We might discuss and argue for this in more detail in a follow-up post.
Could you explain why you are skeptical that current baseline methods can be dramatically improved? It seems possible to me that the major shortcomings of instruction fine-tuning and RLHF (that they seem to make shallow changes to representations and computation) are not fundamental. Maybe it's naive because I haven't thought about this very hard, but from our point of view representations "mature" over development and become rather rigid; however, maybe there's something like Yamanaka factors!
Even from the perspective of black-box control, it seems that as a practical matter one could extract more useful work if the thing in the box is more aligned, and thus it seems you would agree that fundamental advantages in these baseline methods would be welcome.
Incidentally, I don't really understand what you mean by "captured by black-box control evaluations". Was there a follow-up?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-10-03T23:31:27.224Z · LW(p) · GW(p)
(Oops, slow reply)
If SLT were to say nontrivial things about what instruction fine-tuning and RLHF are doing to models, and those things were verified in experiments, would that shift your skepticism?
If SLT results in interesting predictions in some case or was generally able to notably improve our ability to predict downstream behavior (including just within a subset of cases), that would be a large update from me. Seems like a reasonable goal to shoot for.
Could you explain why you are skeptical that current baseline methods can be dramatically improved?
Note the "absent substantial advances in science"! My perspective was[1] that it is pretty likely that for white box methods (methods that go beyond just training and black box behavior), the most simple and baseline approaches are reasonably likely to be pretty close to as good as you can get for reducing risk if you are just doing basic empirical monkeying. At least for risks from close-to-worst-case-scheming [LW · GW] models, I think other threat models might be more amenable to complex white-box methods as they are easier to directly study.
(Threat models other than close-to-worst-case-scheming have the property that if they exist, you should be able to directly measure them and potentially you can measure how well the method worked on the model itself in a very analogous test bed; see discussion here [LW · GW] for details. More minimally, it is easier to construct many empirical test beds if you aren't worried that the model is directly trying to undermine your ability to study it.)
Why think this? The core reason is that is hard to build good empirical test beds for techniques using the internals of models in non-trivial ways. We don't have the internals of a scheming model in front of us. We can certainly study behavioral interventions (black-box control) and we can try to make test beds which are as analogous as possible. But, it seems hard to get that analogous for a variety of reasons. You could demonstrate robust properties of models such that you can sufficiently robustly predict a property of scheming models to take advantage of. But, now we're probably talking about fundamental advances in science.
I don't think I've really adequately defended this perspective here, but this is at least roughly why I think this.
Incidentally, I don't really understand what you mean by "captured by black-box control evaluations". Was there a follow-up?
Black-box control evaluations are evaluations where you basically assume your model is worst case misaligned, you make conservative assumptions about inductive biases (e.g. you get nothing other than what the model is forced to do), and you try to see if the model is capable enough to cause problems even given your countermeasures.
Basically, in any place where you can't establish a property with a capability evaluation, you make conservative/pessimal assumptions.
(I usually imagine some wiggle room, e.g., we need to study sample efficiency and exploration hacking [LW · GW] so that we can argue about the effects of training and elicitation. We'd also want to answer some questions which are a bit tricky to answer with capability evaluations, but this is at least conceivable, e.g., how good is the AI at coming up with good strategies for subverting safeguards within a forward pass.)
I've updated somewhat from this position, partially based on latent adversarial training and also just after thinking about it more. ↩︎
↑ comment by Davidmanheim · 2024-07-10T16:28:50.400Z · LW(p) · GW(p)
First, I think this class of work is critical for deconfusion, which is critical if we need a theory for far more powerful AI systems, rather than for very smart but still fundamentally human level systems.
Secondly, concretely, it seems that very few other approaches to safety have the potential to provide enough fundamental understanding to allow us to make strong statements about models before they are fully trained. This seems like a critical issue if we are concerned about very strong models that could pose risks during testing, or possibly even during training. And as far as I'm aware, nothing in the interpretability and auditing spaces has a real claim to be able to make clear statements about those risks, other than perhaps to suggest interim testing during model training - which could work, if a huge amount of such work is done, but seems very unlikely to happen.
Edit to add: Given the votes on this, what specifically do people disagree with?
↑ comment by Jonathan Claybrough (lelapin) · 2024-10-04T07:39:09.905Z · LW(p) · GW(p)
I don't strongly disagree but do weakly disagree on some points so I guess I'll answer
Re first- if you buy into automated alignment work by human level AGI, then trying to align ASI now seems less worth it. The strongest counterargument to this I see is that "human level AGI" is impossible to get with our current understanding, as it will be superhuman in some things and weirdly bad at others.
Re second- disagreements might be nitpicking on "few other approaches" vs "few currently pursued approaches". There are probably a bunch of things that would allow fundamental understanding if they panned out (various agent foundations agendas, probably safe ai agendas like davidad's), though one can argue they won't apply to deep learning or are less promising to explore than SLT
Replies from: Davidmanheim↑ comment by Davidmanheim · 2024-10-06T13:37:10.449Z · LW(p) · GW(p)
In addition to the point that current models are already strongly superhuman in most ways, I think that if you buy the idea that we'll be able to do automated alignment of ASI, you'll still need some reliable approach to "manual" alignment of current systems. We're already far past the point where we can robustly verify LLMs claims' or reasoning in a robust fashion outside of narrow domains like programming and math.
But on point two, I strongly agree that Agent foundations and Davidad's agendas are also worth pursuing. (And in a sane world, we should have tens or hundreds of millions of dollars in funding for each every year.) Instead, it looks like we have Davidad's ARIA funding, Jaan Talinn and LTFF funding some agent foundations and SLT work, and that's basically it. And MIRI abandoned agent foundations, while Openphil isn't, it seems, putting money or effort into them.
↑ comment by RogerDearnaley (roger-d-1) · 2024-07-11T05:32:22.848Z · LW(p) · GW(p)
The thing that excites me most about SLT is the extent to which it takes things that had previously been observed and had become useful rules of thumb/folk wisdom (e.g. SGD+momentum on neural nets doesn't seem to overfit due to large parameter counts anything like as much as other smaller classes of machine learning models did), things that in many case people were previously rather puzzled by, and puts them on a solid theoretical foundation that can be explained compactly, and that also suggests where there are assumptions underlying this are that might fail under certain circumstances (e.g. if your SGD+momentum for some reason wasn't well-approximating Bayesian inference).
We would really like our Alignment engineering to be as solid and trustworthy as possible — I'm not personally hopeful that we can get all the way to machine-verified mathematical proofs of model safety (lovely as that would be), but having mathematical understanding of some of the assumptions that we're reasoning about model safety based on is a lot better then just having folk wisdom.
↑ comment by Olli Järviniemi (jarviniemi) · 2024-07-09T22:32:20.880Z · LW(p) · GW(p)
(I'm again not an SLT expert, and hence one shouldn't assume I'm able to give the strongest arguments for it. But I feel like this comment deserves some response, so:)
I find the examples of empricial work you give uncompelling because they were all cases where we could have answered all the relevant questions using empirics and they aren't analogous to a case where we can't just check empirically.
I basically agree that SLT hasn't yet provided deep concrete information about a real trained ML model that we couldn't have obtained via other means. I think this isn't as bad as (I think) you imply, though. Some reasons:
- SLT/devinterp makes the claim that training consists of discrete phases, and the Developmental Landscape paper validates this. Very likely we could have determined this for the 3M-transformer via others means, but:
- My (not confident) impression is a priori people didn't expect this discrete-phases thing to hold, except for those who expected so because of SLT.
- (Plausibly there's tacit knowledge in this direction in the mech interp field that I don't know of; correct me if this is the case.)
- The SLT approach here is conceptually simple and principled, in a way that seems like it could scale, in contrast to "using empirics".
- My (not confident) impression is a priori people didn't expect this discrete-phases thing to hold, except for those who expected so because of SLT.
- I currently view of the empirical work as validating that the theoretical ideas actually work in practice, not as providing ready insight to models.
- Of course, you don't want to tinker forever with toy cases, you actually should demonstrate your value by doing something no one else can, etc.
- I'd be very sympathetic to criticism about not-providing-substantial-new-insight-that-we-couldn't-easily-have-obtained-otherwise 2-3 years from now; but now I'm leaning towards giving the field time to mature.
For the case of the paper looking at a small transformer (and when various abilities emerge), we can just check when a given model is good at various things across training if we wanted to know that. And, separately, I don't see a reason why knowing what a transformer is good at in this way is that useful.
My sense is that SLT is supposed to give you deeper knowledge than what you get by simply checking the model's behavior (or, giving knowledge more scalably). I don't have a great picture of this myself, and am somewhat skeptical of its feasibility. I've e.g. heard of talk about quantifying generalization via the learning coefficient, and while understanding the extent to which models generalize seems great, I'm not sure how one beats behavioral evaluations here.
Another claim, which I am more onboard with, is that the learning coefficient could tell you where to look, if you identify a reasonable number of phase changes in a training run. (I've heard some talk of also looking at the learning coefficient w.r.t. a subset of weights, or a subset of data, to get more fine-grained information.) I feel like this has value.
Alice: Ok, I have some thoughts on the detecting/classifying phase transitions application. Surely during the interesting part of training, phase transitions aren't at all localized and are just constantly going on everywhere? So, you'll already need to have some way of cutting the model into parts such that these parts are cleaved nicely by phase transitions in some way. Why think such a decomposition exists? Also, shouldn't you just expect that there are many/most "phase transitions" which are just occuring over a reasonably high fraction of training? (After all, performance is often the average of many, many sigmoids.)
If I put on my SLT goggles, I think most phase transitions do not occur over a high fraction of training, but instead happen over relatively few SGD steps.
I'm not sure what Alice means by "phase transitions [...] are just constantly going on everywhere". But: probably it makes sense to think that somewhat different "parts" of the model are affected by training on Github vs. Harry Potter fanfiction, and one would want a theory of phase changes be able to deal with that. (Cf. talk about learning coefficients for subsets of weights/data above.) I don't have strong arguments for expecting this to be feasible.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-07-09T23:24:52.653Z · LW(p) · GW(p)
discrete phases, and the Developmental Landscape paper validates this
Hmm, the phases seem only roughly discrete, and I think a perspective like the multi-component learning [LW · GW] perspective totally explains these results, makes stronger predictions, and seems easier to reason about (at least for me).
I would say something like:
The empirical results in the paper paper indicate that with a tiny (3 M) transformer with learned positional embeddings:
- The model initially doesn't use positional embeddings and doesn't know common 2-4 grams. So, it probably is basically just learning bigrams to start.
- Later, positional embeddings become useful and steadily get more useful over time. At the same time, it learns common 2-4 grams (among other things). (This is now possible as it has positional embeddings.)
- Later, the model learns a head which almost entirely attends to the previous token. At the same time as this is happening, ICL score goes down and the model learns heads which do something like induction (as well as probably doing a bunch of other stuff). (It also learns a bunch of other stuff at the same point.)
So, I would say the results are "several capabilities of tiny LLMs require other components, so you see phases (aka s-shaped loss curves) based on when these other components come into play". (Again, see multi-component learning and s-shaped loss curves [LW · GW] which makes this exact prediction.)
My (not confident) impression is a priori people didn't expect this discrete-phases thing to hold
I mean, it will depend how a priori you mean. I again think that the perspective in multi-component learning and s-shaped loss curves [LW · GW] explains what it going on. This was inspired by various emprical results (e.g. results around an s-shape in induction-like-head formation).
but now I'm leaning towards giving the field time to mature
Seems fine to give the field time to mature. That said, if there isn't a theory of change better than "it seems good to generally understand how NN learning works from a theory perspective" (which I'm not yet sold on) or more compelling empirical demos, I don't think this is super compelling. I think it seems worth some people with high comparative advantage working on this, but not a great pitch. (Current level of relative investment seems maybe a bit high to me but not crazy. That said, idk.)
Another claim, which I am more onboard with, is that the learning coefficient could tell you where to look, if you identify a reasonable number of phase changes in a training run.
I don't expect things to localize interestingly for the behaviors we really care about. As in, I expect that the behaviors we care about are learned diffusely across a high fraction of parameters and are learned in a way which either isn't well described as a phase transition or which involves a huge number of tiny phase transitions of varying size which average out into something messier.
(And getting the details right will be important! I don't think it will be fine to get 1/3 of the effect size if you want to understand things well enough to be useful.)
I think most phase transitions do not occur over a high fraction of training, but instead happen over relatively few SGD steps.
All known phase transitions[1] seem to happen across a reasonably high (>5%?) fraction of log-training steps.[2]
More precisely, "things which seem sort like phase transitions" (e.g. s-shaped loss curves). I don't know if these are really phase transitions for some more precise definition. ↩︎
Putting aside pathological training runs like training a really tiny model (e.g. 3 million params) on 10^20 tokens or something. ↩︎
comment by Olli Järviniemi (jarviniemi) · 2024-07-08T17:03:54.168Z · LW(p) · GW(p)
Context for the post:
I've recently spent a decent amount of time reading about Singular Learning Theory. It took some effort to understand what it's all about (and I'm still learning), so I thought I'd write a short overview to my past self, in the hopes that it'd be useful to others.
There were a couple of very basic things it took me surprisingly long to understand, and which I tried to clarify here.
First, phase changes. I wasn't, and still am not, a physicist, so I bounced off from physics motivations. I do have a math background, however, and Bayesian learning does allow for striking phase changes. Hence the example in the post.[1]
(Note: One shouldn't think that because SGD is based on local updates, one doesn't have sudden jumps there. Yes, one of course doesn't have big jumps with respect to the Euclidean metric, but we never cared about that metric anyways. What we care about is sudden changes in higher-level properties, and those do occur in SGD. This is again something I took an embarrassingly long time to really grasp.)
Second, the learning coefficient. I had read about SLT for quite a while, and heard about the mysterious learning coefficient for quite a few times, before it was explained that it is just a measure of volume![2] A lot of things clicked to place: yes, obviously this is relevant for model selection, that's why people talk about it.
(The situation is less clear for SGD, though: it doesn't help that your basin is large if it isn't reachable by local updates. Shrug.)
As implied in the post, I consider myself still a novice in SLT. I don't have great answers to Alice's questions at the end, and not all the technical aspects are crystal clear to me (and I'm intentionally not going deep in this post). But perhaps this type of exposition is best done by novices before the curse of knowledge starts hitting.
Thanks to everyone who proofread this and their encouragement.
- ^
In case you are wondering: the phase change I plotted is obtained via the Gaussian prior and the loss function . (Note that the loss is deterministic in , which is unrealistic.)
This example is kind of silly: I'm just making the best model at have a very low prior, so it will only show it's head after a lot of data. If you want non-silly examples, see the "Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition" or "The Developmental Landscape of In-Context Learning" papers.
- ^
You can also define it via the poles of a certain zeta function, but I thought this route wouldn't be very illuminating to Alice.
↑ comment by Chris_Leong · 2025-01-11T07:33:04.309Z · LW(p) · GW(p)
Excellent post. It helped clear up some aspects of SLT for me. Any chance you could clarify why this volume is called the "learning coefficient?"