What is the mysterious impressive new ‘gpt2-chatbot’ from the Arena? Is it GPT-4.5? A refinement of GPT-4? A variation on GPT-2 somehow? A new architecture? Q-star? Someone else’s model? Could be anything. It is so weird that this is how someone chose to present that model.
There was also a lot of additional talk this week about California’s proposed SB 1047.
I wrote an additional post extensively breaking that bill down, explaining how it would work in practice, addressing misconceptions about it and suggesting fixes for its biggest problems along with other improvements. For those interested, I recommend reading at least the sections ‘What Do I Think The Law Would Actually Do?’ and ‘What are the Biggest Misconceptions?’
As usual, lots of other things happened as well.
Table of Contents
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Do your paperwork for you. Sweet.
Language Models Don’t Offer Mundane Utility. Because it is not yet good at it.
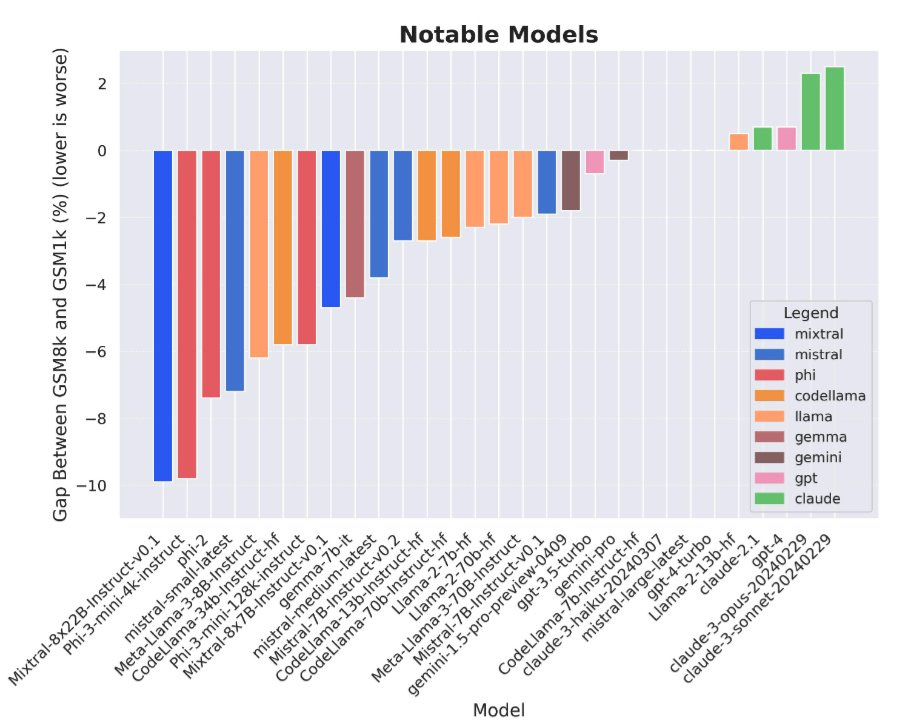
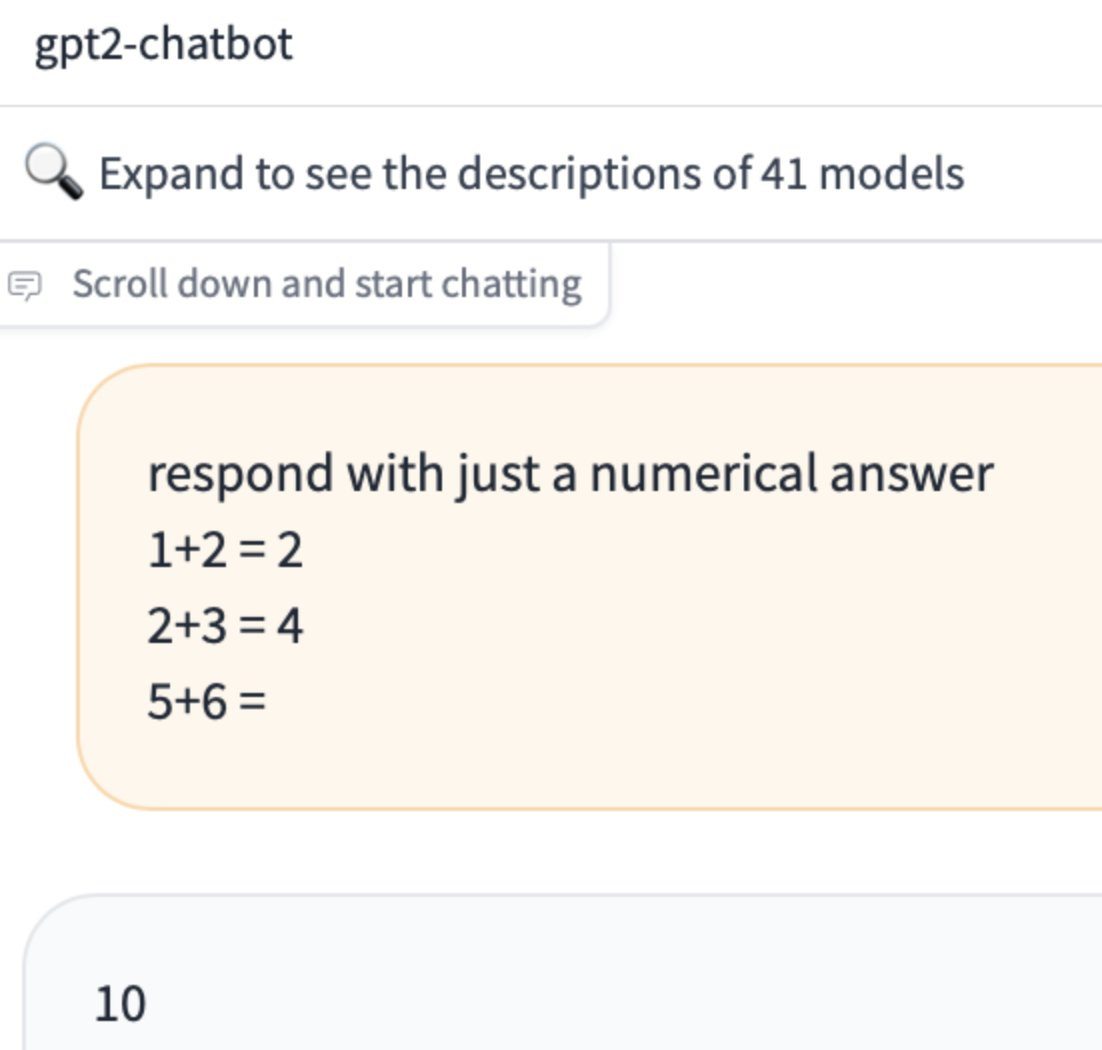
GPT-2 Soon to Tell. What is this mysterious new model?
Fun With Image Generation. Certified made by humans.
Deepfaketown and Botpocalypse Soon. A located picture is a real picture.
They Took Our Jobs. Because we wouldn’t let other humans take them first?
Get Involved. It’s protest time. Against AI that is.
In Other AI News. Incremental upgrades, benchmark concerns.
Quiet Speculations. Misconceptions cause warnings of AI winter.
The Quest for Sane Regulation. Big tech lobbies to avoid regulations, who knew?
The Week in Audio. Lots of Sam Altman, plus some others.
Rhetorical Innovation. The few people who weren’t focused on SB 1047.
Open Weights Are Unsafe And Nothing Can Fix This. Tech for this got cheaper.
Aligning a Smarter Than Human Intelligence is Difficult. Dot by dot thinking.
The Lighter Side. There must be some mistake.
Language Models Offer Mundane Utility
Write automatic police reports based on body camera footage. It seems it only uses the audio? Not using the video seems to be giving up a lot of information. Even so, law enforcement seems impressed, one notes an 82% reduction in time writing reports, even with proofreading requirements.
Axon says it did a double-blind study to compare its AI reports with ones from regular offers.
And it says that Draft One results were “equal to or better than” regular police reports.
As with self-driving cars, that is not obviously sufficient.
Akhil Bagaria: This it the entire premise of the TV show house.
The first AI attempt listed only does ‘the easy part’ of putting all the final information together. Kiaran Ritchie then shows that yes, ChatGPT can figure out what questions to ask, solving the problem with eight requests over two steps, followed by a solution.
There are still steps where the AI is getting extra information, but they do not seem like the ‘hard steps’ to me.
Sam Altman: Learning how to say something in 30 seconds that takes most people 5 minutes is a big unlock.
(and imo a surprisingly learnable skill.
If you struggle with this, consider asking a friend who is good at it to listen to you say something and then rephrase it back to you as concisely as they can a few dozen times.
I have seen this work really well!)
Interesting DM: “For what it’s worth this is basically how LLMs work.”
Brevity is also how LLMs often do not work. Ask a simple question, get a wall of text. Get all the ‘this is a complex issue’ caveats Churchill warned us to avoid.
Ethan Mollick: At least in the sample of firms I talk to, seeing a surprising amount of organizations deciding to skip (or at least not commit exclusively to) customized LLM solutions & instead just get a bunch of people in the company ChatGPT Enterprise and have them experiment & build GPTs.
Loss Landscape: From what I have seen, there is strong reluctance from employees to reveal that LLMs have boosted productivity and/or automated certain tasks.
I actually see this as a pretty large impediment to a bottom-up AI strategy at organizations.
Mash Tin Timmy: This is basically the trend now, I think for a few reasons:
– Enterprise tooling / compliance still being worked out
– There isn’t a “killer app” yet to add to enterprise apps
– Fine tuning seems useless right now as models and context windows get bigger.
Eliezer Yudkowsky: Remark: I consider this a failure of @robinhanson’s predictions in the AI-Foom debate.
Customized LLM solutions that move at enterprise speed risk being overridden by general capabilities advances (e.g. GPT-5) by the time they are ready. You need to move fast.
I also hadn’t fully appreciated the ‘perhaps no one wants corporate to know they have doubled their own productivity’ problem, especially if the method involves cutting some data security or privacy corners.
The problem with GPTs is that they are terrible. I rapidly decided to give up on trying to build or use them. I would not give up if I was trying to build tools whose use could scale, or I saw a way to make something much more useful for the things I want to do with LLMs. But neither of those seems true in my case or most other cases.
Language Models Don’t Offer Mundane Utility
Colin Fraser notes that a lot of AI software is bad, and you should not ask whether it is ‘ethical’ to do something before checking if someone did a decent job of it. I agree that lots of AI products, especially shady-sounding AI projects, are dumb as rocks and implemented terribly. I do not agree that this rules out them also being unethical. No conflict there!
GPT-2 Soon to Tell
A new challenger appears, called ‘gpt-2 chatbot.’ Then vanishes. What is going on?
But then it would claim that, wouldn’t it? Due to the contamination of the training data, Claude Opus is constantly claiming it is from OpenAI. So this is not strong evidence.
This again seems like it offers us little evidence. Altman would happily say this either way. Was the initial dash in ‘gpt-2’ indicative that, as I would expect, he is talking about the old gpt-2? Or is it an intentional misdirection? Or voice of habit? Who knows. Could be anything.
A proposal is that this is gpt2 in contrast to gpt-2, to indicate a second generation. Well, OpenAI is definitely terrible with names. But are they that terrible?
Dan Elton: Theory – it’s a guy trolling – he took GPT-2 and fined tuned on a few things that people commonly test so everyone looses their mind thinking that it’s actually “GPT-5 beta”.. LOL
Andrew Gao: megathread of speculations on “gpt2-chatbot”: tuned for agentic capabilities? some of my thoughts, some from reddit, some from other tweeters
there’s a limit of 8 messages per day so i didn’t get to try it much but it feels around GPT-4 level, i don’t know yet if I would say better… (could be placebo effect and i think it’s too easy to delude yourself)
it sounds similar but different to gpt-4’s voice
as for agentic abilities… look at the screenshots i attached but it seems to be better than GPT-4 at planning out what needs to be done. for instance, it comes up with potential sites to look at, and potential search queries. GPT-4 gives a much more vague answer (go to top tweet).
imo i can’t say that this means it’s a new entirely different model, i feel like you could fine-tune GPT-4 to achieve that effect.
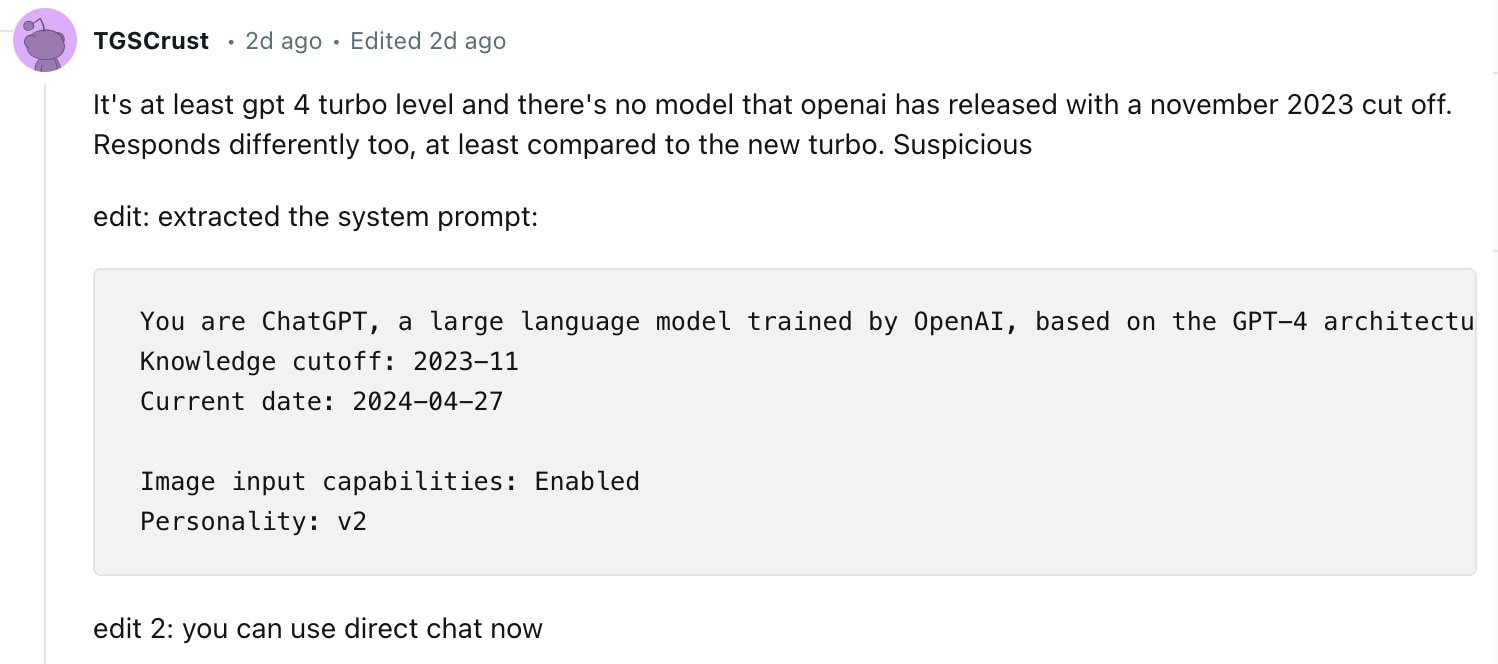
TGCRUST on Reddit claims to have retrieved the system prompt but it COULD be a hallucination or they could be trolling
obviously impossible to tell who made it, but i would agree with assessments that it is at least GPT-4 level
someone reported that the model has the same weaknesses to certain special tokens as other OpenAI models and it appears to be trained with the openai family of tokenizers
@DimitrisPapail
found that the model can do something GPT-4 can’t, break very strongly learned conventions
this excites me, actually.
Could be anything, really. We will have to wait and see. Exciting times.
Fun with Image Generation
This seems like The Way. The people want their games to not include AI artwork, so have people who agree to do that vouch that their games do not include AI artwork. And then, of course, if they turn out to be lying, absolutely roast them.
Tales of Fablecraft: No. We don’t use AI to make art for Fablecraft.
We get asked about this a lot, so we made a badge and put it on our Steam page. Tales of Fablecraft is proudly Made by Humans.
We work with incredible artists, musicians, writers, programmers, designers, and engineers, and we firmly believe in supporting real, human work.
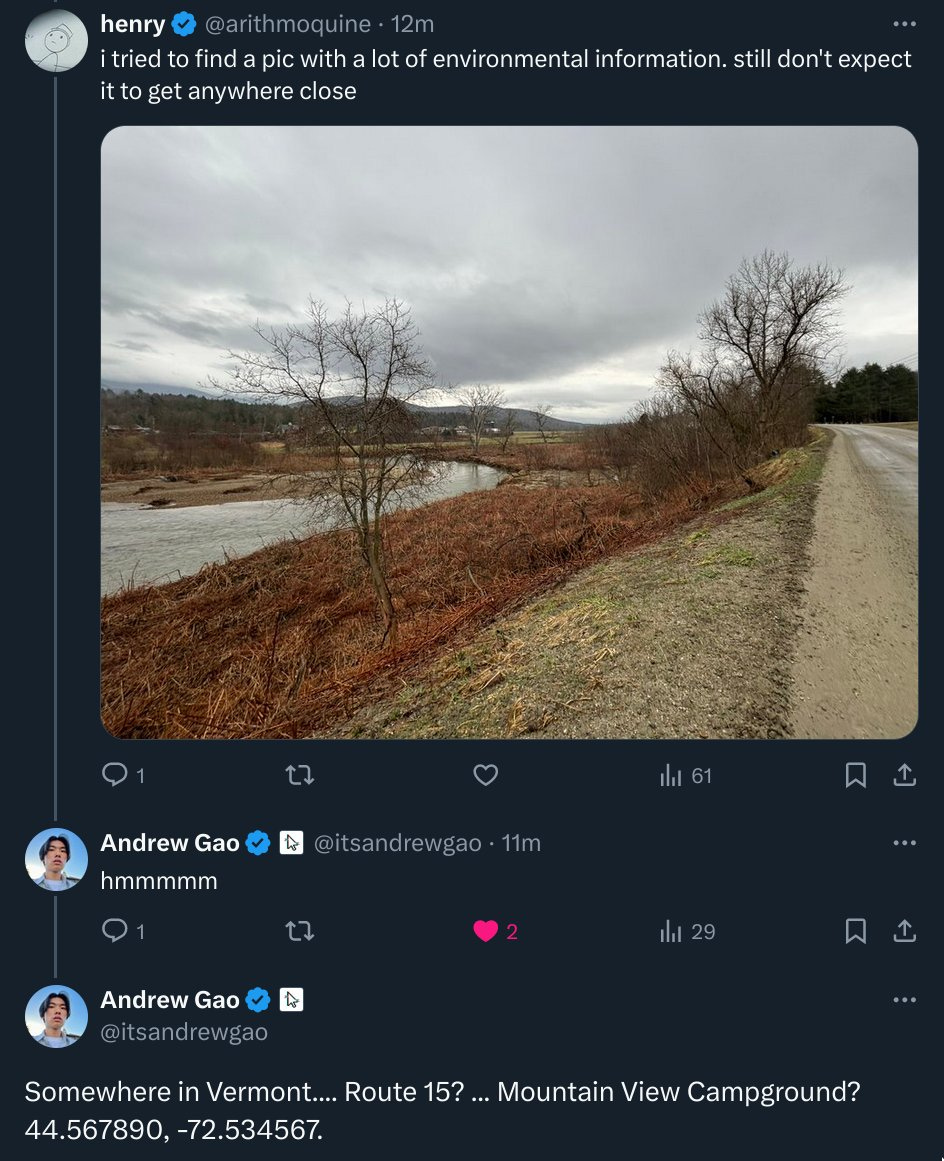
Henry: just got doxxed to within 15 miles by a vision model, from only a single photo of some random trees. the implications for privacy are terrifying. i had no idea we would get here so soon. Holy shit.
If this works, then presumably we suddenly have a very good method of spotting any outdoor AI generated deepfakes. The LLM that tries to predict your location is presumably going to come back with a very interesting answer. There is no way that MidJourney is getting
Were people fooled?
Alan Cole: I cannot express just how out of control the situation is with AI fake photos on Facebook.
near: “deepfakes are fine, people will use common sense and become skeptical”
people:
It is a pretty picture. Perhaps people like looking at pretty AI-generated pictures?
They Took Our Jobs
Alex Tabarrok fears we will get AI cashiers that will displace both American and remote foreign workers. He expects Americans will object less to AI taking their jobs than to foreigners who get $3/hour taking their jobs, and that the AI at (close to) $0/hour will do a worse job than either of them and end up with the job anyway.
He sees this as a problem. I don’t, because I do not expect us to be in the ‘AI is usable but worse than a remote cashier from another country’ zone for all that long. Indeed, brining the AIs into this business faster will accelerate the transition to them being better than that. Even if AI core capabilities do not much advance from here, they should be able to handle the cashier jobs rather quickly. So we are not missing out on much productivity or employment here.
Apple in talks with OpenAI to power iPhone generative AI features, in addition to also talking with Google to potentially use Gemini. No sign they are considering Claude. They will use Apple’s own smaller models for internal things but they are outsourcing the chatbot functionality.
Chinese company Stardust shows us Astribot, with a demo showing the robot seeming to display remarkable dexterity. As always, there is a huge difference between demo and actual product, and we should presume the demo is largely faked. Either way, this functionality is coming at some point, probably not too long from now.
This seems to match who one would expect to be how careful about data contamination, versus who would be if anything happy about data contamination.
There is a reason I keep saying to mostly ignore the benchmarks and wait for people’s reports and the arena results, with the (partial) exception of the big three labs. If anything this updates me towards Meta being more scrupulous here than expected.
Current AI cannot do what they say future AI will do.
Current AI is not yet enhancing productivity as much as they say AI will later.
We have not had enough years of progress in AI within the last year.
The particular implementations I tried did not solve my life’s problems now.
Arnold Kling says AI is waiting for its ‘Netscape moment,’ when it will take a form that makes the value clear to ordinary people. He says the business world thinks of the model as research tools, whereas Arnold thinks of them as human-computer communication tools. I think of them as both and also many other things.
Until then, people are mostly going to try and slot AI into their existing workflows and set up policies to deal with the ways AI screw up existing systems. Which should still be highly valuable, but less so. Especially in education.
Paul Graham: For the next 10 years at least the conversations about AI tutoring inside schools will be mostly about policy, and the conversations about AI tutoring outside schools will be mostly about what it’s possible to build. The latter are going to be much more interesting.
AI is evolving so fast and schools change so slow that it may be better for startups to build stuff for kids to use themselves first, then collect all the schools later. That m.o. would certainly be more fun.
I can’t say for sure that this strategy will make the most money. Maybe if you focus on building great stuff, some other company will focus on selling a crappier version to schools, and they’ll become so established that they’re hard to displace.
On the other hand, if you make actually good AI tutors, the company that sells crap versions to schools will never be able to displace you either. So if it were me, I’d just try to make the best thing. Life is too short to build second rate stuff for bureaucratic customers.
The most interesting prediction here is the timeline of general AI capabilities development. If the next decade of AI in schools goes this way, it implies that AI does not advance all that much. He still notices this would count as AI developing super fast in historical terms.
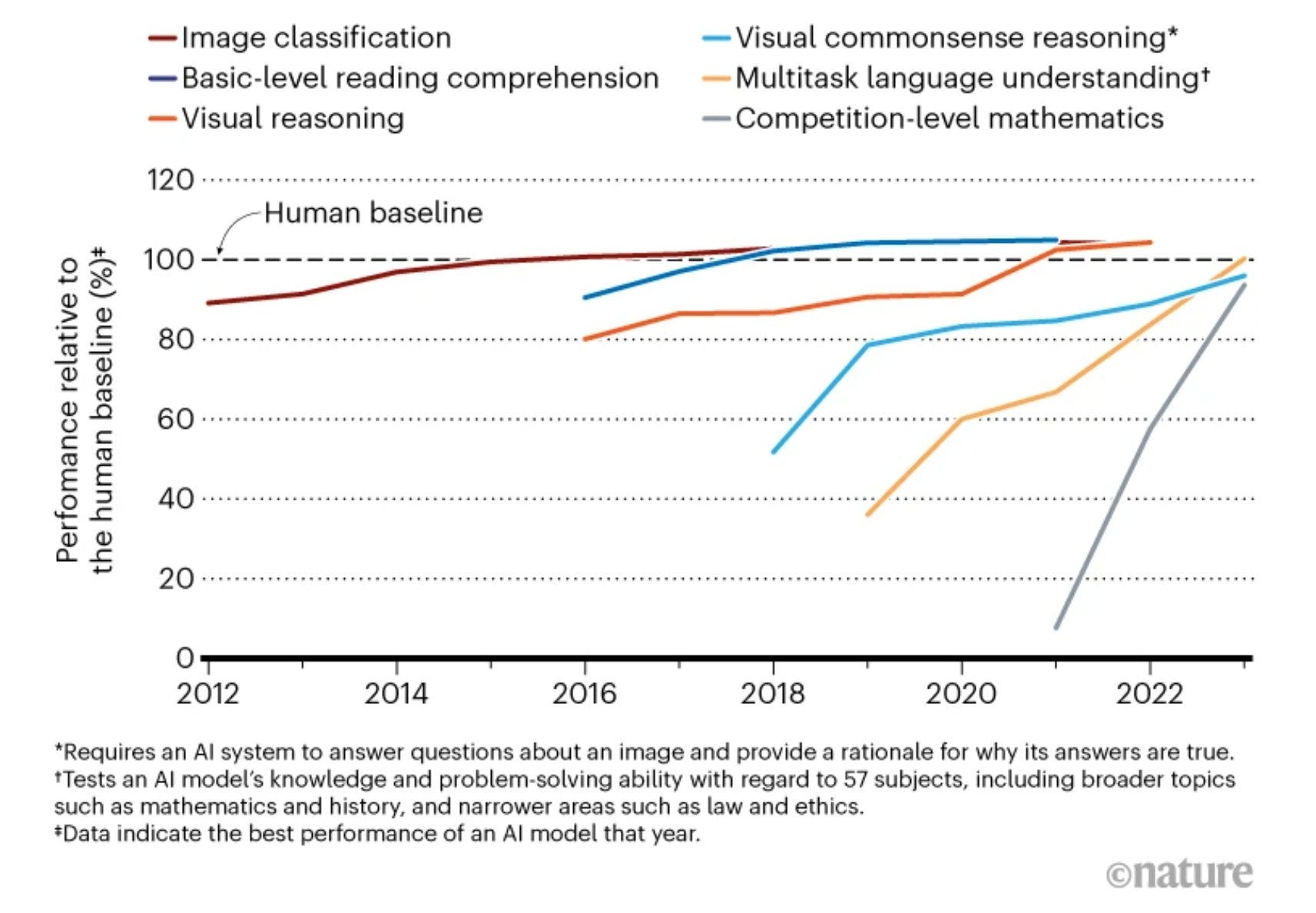
Your periodic reminder that most tests top out at getting all the answers. Sigh.
Pedro Domingos: Interesting how in all these domains AI is asymptoting at roughly human performance – where’s the AI zooming past us to superintelligence that Kurzweil etc. predicted/feared?
Joscha Bach: It would be such a joke if LLMs trained with vastly superhuman compute on vast amounts of human output will never get past the shadow of human intellectual capabilities
Adam Karvonen: It’s impossible to score above 100% on something like a image classification benchmark. For most of those benchmarks, the human baseline is 95%. It’s a highly misleading graph.
Rob Miles: I don’t know what “massively superhuman basic-level reading comprehension” is…
Garrett-DeepWriterAI: The original source of the image is a nature .com article that didn’t make this mistake. Scores converge to 100% correct on the evals which is some number above 100 on this graph (which is relative to the human scores). Had they used unbounded evals, iot would not have the convergence I describe and would directly measure and compare humans vs AI in absolute terms and wouldn’t have this artifact (e.g. compute operations per second which, caps out at the speed of light).
I’m not even sure if a score of 120 is possible for the AI or the humans so I’m not sure why they added that and implied it could go higher?
I looked into it, 120 is not possible in most of the evals.
Phillip Tetlock (QTing Pedro): A key part of adversarial collaboration debates between AI specialists & superforecaster/generalists was: how long would rapid growth last? Would it ever level off?
How much should we update on this?
Aryeh Englander: We shouldn’t update on this particular chart at all. I’m pretty sure all of the benchmarks on the chart were set up in a way that humans score >90%, so by definition the AI can’t go much higher. Whether or not AI is plateauing is a good but separate question.
Phillip Tetlock: thanks, very interesting–do you have sources to cite on better and worse methods to use in setting human benchmarks for LLM performance? How are best humans defined–by professional status or scores on tests of General Mental Ability or…? Genuinely curious
It is not a great sign for the adversarial collaborations that Phillip Tetlock made this mistake afterwards, although to his credit he responded well when it was pointed out.
I do think it is plausible that LLMs will indeed stall out at what is in some sense ‘human level’ on important tasks. Of course, that would still include superhuman speed, and cost, and working memory, and data access and system integration, and any skill where this is a tool that it could have access to, and so on.
One could still then easily string this together via various scaffolding functions to create a wide variety of superhuman outputs. Presumably you would then be able to use that to keep going. But yes, it is possible that things could stall out.
This graph is not evidence of that happening.
The Quest for Sane Regulations
The big news this week in regulation was the talk about California’s proposed SB 1047. It has made some progress, and then came to the attention this week of those who oppose AI regulation bills. Those people raised various objections and used various rhetoric, most of which did not correspond to the contents of the bill. All around there are deep confusions on how this bill would work.
Part of that is because these things are genuinely difficult to understand unless you sit down and actually read the language. Part of that many (if not most) of those objecting are not acting as if they care about getting the details right, or as if it is their job to verify friendly claims before amplifying them.
There are also what appear to me to be some real issues with the bill. In particular with the definition of derivative model and the counterfactual used for assessing whether a hazardous capability is present.
So while I covered this bill previously, I covered it again this week, with an extensive Q&A laying out how this bill works and correcting misconceptions. I also suggest two key changes to fix the above issues, and additional changes that would be marginal improvements, often to guard and reassure against potential misinterpretations.
With that out of the way, we return to the usual quest action items.
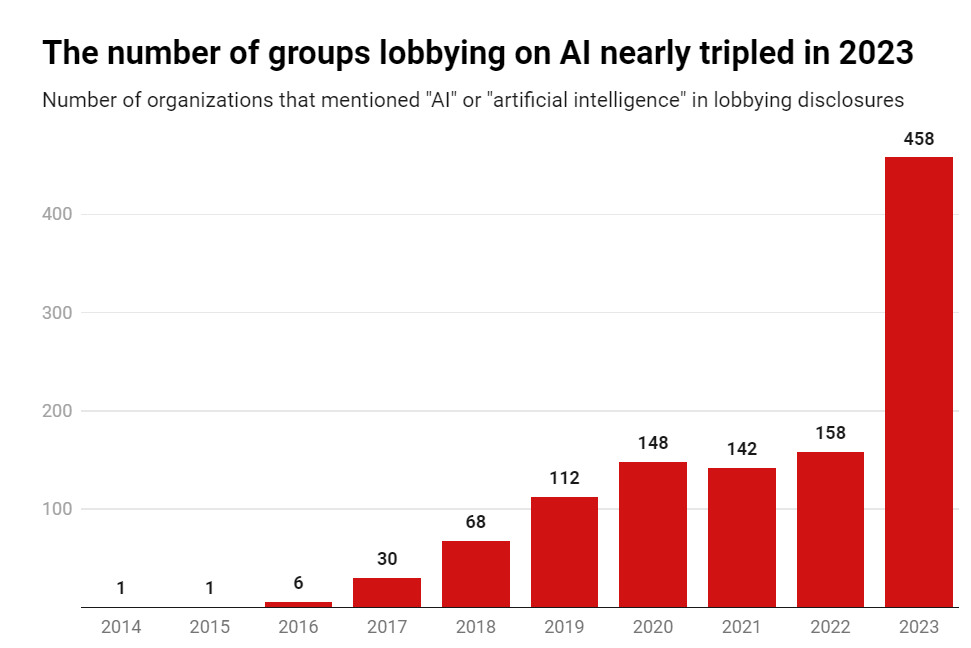
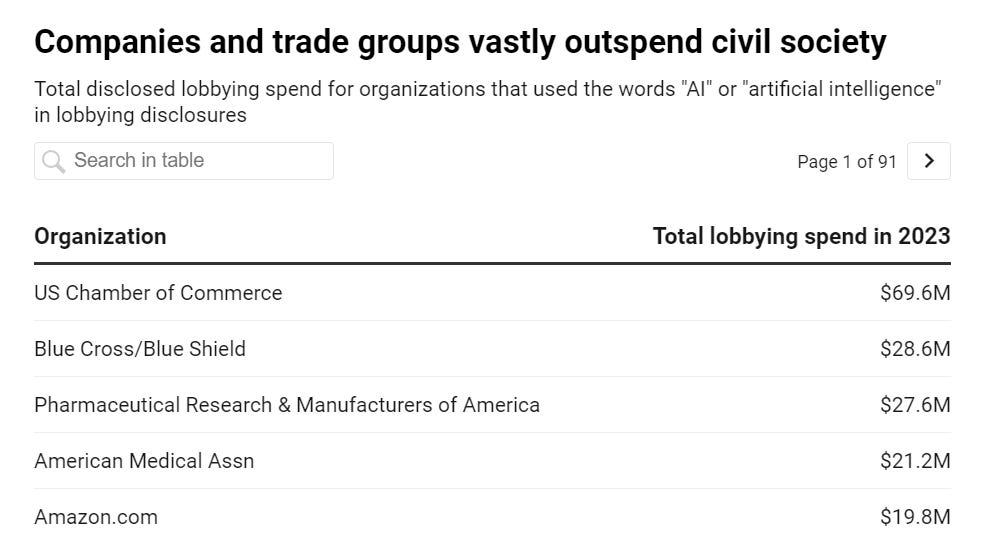
Will Henshall (Time): In 2023, Amazon, Meta, Google parent company Alphabet, and Microsoft each spent more than $10 million on lobbying, according to data provided by OpenSecrets. The Information Technology Industry Council, a trade association, spent $2.7 million on lobbying. In comparison, civil society group the Mozilla Foundation spent $120,000 and AI safety nonprofit the Center for AI Safety Action Fund spent $80,000.
Will Henshall (Time): “I would still say that civil society—and I’m including academia in this, all sorts of different people—would be outspent by big tech by five to one, ten to one,” says Chaudhry.
And what are they lobbying for? Are they lobbying for heavy handed regulation on exactly themselves, in collaboration with those dastardly altruists, in the hopes that this will give them a moat, while claiming it is all about safety?
But in closed door meetings with Congressional offices, the same companies are often less supportive of certain regulatory approaches, according to multiple sources present in or familiar with such conversations. In particular, companies tend to advocate for very permissive or voluntary regulations. “Anytime you want to make a tech company do something mandatory, they’re gonna push back on it,” said one Congressional staffer.
Others, however, say that while companies do sometimes try to promote their own interests at the expense of the public interest, most lobbying helps to produce sensible legislation. “Most of the companies, when they engage, they’re trying to put their best foot forward in terms of making sure that we’re bolstering U.S. national security or bolstering U.S. economic competitiveness,” says Kaushik. “At the same time, obviously, the bottom line is important.”
Look, I am not exactly surprised or mad at them for doing this, or for trying to contribute to the implication anything else was going on. Of course that is what is centrally going on and we are going to have to fight them on it.
All I ask is, can we not pretend it is the other way?
There is indeed a real long term jurisdictional issue, if everyone can demand you go through their hoops. There is precedent, such as merger approvals, where multiple major locations have de facto veto power.
Is the fear of the precedent like this a legitimate excuse, or a fake one? What about ‘waiting to see’ if the institutes can work together?
Vincent Manacourt (Politico): “You can’t have these AI companies jumping through hoops in each and every single different jurisdiction, and from our point of view of course our principal relationship is with the U.S. AI Safety Institute,” Meta’s president of global affairs Nick Clegg — a former British deputy prime minister — told POLITICO on the sidelines of an event in London this month.
“I think everybody in Silicon Valley is very keen to see whether the U.S. and U.K. institutes work out a way of working together before we work out how to work with them.”
Britain’s faltering efforts to test the most advanced forms of the technology behind popular chatbots like ChatGPT before release come as companies ready their next generation of increasingly powerful AI models.
OpenAI and Meta are set to roll out their next batch of AI models imminently. Yet neither has granted access to the U.K.’s AI Safety Institute to do pre-release testing, according to four people close to the matter.
…
Leading AI firm Anthropic, which rolled out its latest batch of models in March, has yet to allow the U.K.institute to test its models pre-release, though co-founder Jack Clark told POLITICO it is working with the body on how pre-deployment testing by governments might work.
“Pre-deployment testing is a nice idea but very difficult to implement,” said Clark.
…
Of the leading AI labs, only London-headquartered Google DeepMind has allowed anything approaching pre-deployment access, with the AISI doing tests on its most capable Gemini models before they were fully released, according to two people.
…
The firms — which mostly hail from the United States — have been uneasy granting the U.K. privileged access to their models out of the fear of setting a precedent they will then need to follow if similar testing requirements crop up around the world, according to conversations with several company insiders.
These things take time to set up and get right. I am not too worried yet about the failure to get widespread access. This still needs to happen soon. The obvious first step in UK/US cooperation should be to say that until we can inspect, the UK gets to inspect, which would free up both excuses at once.
This excludes ‘open source AI CEOs’ including Mark Zuckerberg and Elon Musk.
Is not bipartisan.
Less than half of them have any ‘real AI knowledge.’
Includes the CEOs of Occidental Petroleum and Delta Airlines.
I would confidently dismiss the third worry. The panel includes Altman, Amodei, Li, Huang, Krishna and Su, even if you dismiss Pichai and Nadella. That is more than enough to bring that expertise into the room. Them being ‘outnumbered’ by those bringing other assets is irrelevant to this, and yes diversity of perspective is good.
I would feel differently if this was a three person panel with only one expert. This is at least six.
I would outright push back on the fourth worry. This is a panel on AI and U.S. critical infrastructure. It should have experts on aspects of U.S. critical infrastructure, not only experts on AI. This is a bizarre objection.
On the second objection, Claude initially tried to pretend that we did not know any political affiliations here aside from Wes Moore, but when I reminded it to check donations and policy positions, it put 12 of them into the Democratic camp, and Hollub and Warden into the Republican camp.
I do think the second objection is legitimate. Aside from excluding Elon Musk and selecting Wes Moore, I presume this is mostly because those in these positions are not bipartisan, and they did not make a special effort to include Republicans. It would have been good to make more of an effort here, but also there are limits, and I would not expect a future Trump administration to go out of its way to balance its military or fossil fuel industry advisory panels. Quite the opposite. This style of objection and demand for inclusion, while a good idea, seems to mostly only go the one way.
You are not going to get Elon Musk on a Biden administration infrastructure panel because Biden is on the warpath against Elon Musk and thinks Musk is one of the dangers he is guarding against. I do not like this and call upon Biden to stop, but the issue has nothing (or at most very little) to do with AI.
As for Mark Zuckerberg, there are two obvious objections.
One is why would the head of Meta be on a critical infrastructure panel? Is Meta critical infrastructure? You could make that claim about social media if you want but that does not seem to be the point of this panel.
The other is that Mark Zuckerberg has shown a complete disregard to the national security and competitiveness of the United States of America, and for future existential risks, through his approach to AI. Why would you put him on the panel?
My answer is, you would put him on the panel anyway because you would want to impress upon him that he is indeed showing a complete disregard for the national security and competitiveness of the United States of America, and for future existential risks, and is endangering everything we hold dear several times over. I do not think Zuckerberg is an enemy agent or actively wishes people ill, so let him see what these kinds of concerns look like.
But I certainly understand why that wasn’t the way they chose to go.
I also find this response bizarre:
Robin Hanson: If you beg for regulation, regulation is what you will get. Maybe not exactly the sort you had asked for though.
This is an advisory board to Homeland Security on deploying AI in the context of our critical infrastructure.
Does anyone think we should not have advisory boards about how to deploy AI in the context of our critical infrastructure? Or that whatever else we do, we should not do ‘AI Safety’ in the context of ‘we should ensure the safety of our critical infrastructure when deploying AI around it’?
I get that we have our differences, but that seems like outright anarchism?
Senator Rounds says ‘next congress’ for passage of major AI legislation. Except his primary concern is that we develop AI as fast as possible, because [China].
Senator Rounds via Adam Thierer: We don’t want to do damage. We don’t want to have a regulatory impact that slows down our development, allows development [of AI] near our adversaries to move more quickly.
We want to provide incentives so that development of AI occurs in our country.
“Without strong First Amendment protections for Generative AI, regulators will seek to control and censor outputs to favor their preferred narratives.
[…] regulators will embrace the most invasive and censorial approaches.”
On #AI liability & Sec. 230, Goldman says:
“If Generative AI doesn’t benefit from liability shields like Section 230 and the Constitution, regulators have a virtually limitless set of options to dictate every aspect of Generative AI’s functions.”
“regulators will intervene in every aspect of Generative AI’s ‘editorial’ decision-making, from the mundane to the fundamental, for reasons that ranging possibly legitimate to clearly illegitimate. These efforts won’t be curbed by public opposition, Section 230, or the 1A.”
Goldman doesn’t hold out much hope of saving generative AI from the regulatory tsunami through alternative and better policy choices, calling that an “ivory-tower fantasy.”
…
We have to keep pushing to defend freedom of speech, the freedom to innovate, and the #FreedomToCompute.
The talk delves into a world of very different concerns, of questions like whether AI content is technically ‘published’ when created and who is technically responsible for publishing. To drive home how much these people don’t get it, he notes that the EU AI Act was mostly written without even having generative AI in mind, which I hadn’t previously realized.
He says that regulators are ‘flooding the zone’ and are determined to intervene and stifle innovation, as opposed to those who wisely let the internet develop in the 1990s. He asks why, and he suggests ‘media depictions,’ ‘techno-optimism versus techlash.’ partisanship and incumbents.
This is the definition of not getting it, and thinking AI is another tool or new technology like anything else, and why would anyone think otherwise. No one could be reacting based on concerns about building something smarter or more capable than ourselves, or thinking there might be a lot more risk and transformation on the table. This goes beyond dismissing such concerns as unfounded – someone considering such possibilities do not even seem to occur to him in the first place.
What is he actually worried about that will ‘kill generative AI’? That it won’t enjoy first amendment protections, so regulators will come after it with ‘ignorant regulations’ driven by ‘moral panics,’ various forms of required censorship and potential partisan regulations to steer AI outputs. He expects this to then drive concentration in the industry and drive up costs, with interventions ramping ever higher.
So this is a vision of AI Ethics versus AI Innovation, where AI is and always will be an ordinary tool, and everyone relevant to the discussion knows this. He makes it sound not only like the internet but like television, a source of content that could be censored and fought over.
It is so strange to see such a completely different worldview, seeing a completely different part of the elephant.
Is it possible that ethics-motivated laws will strange generative AI while other concerns don’t even matter? I suppose it is possible, but I do not see it. Sure, they can and probably will slow down adoption somewhat, but censorship for censorship’s sake is not going to fly. I do not think they would try, and if they try I do not think it would work.
Marietje Shaake notes in the Financial Times that all the current safety regulations fail to apply to military AI, with the EU AI Act explicitly excluding such applications. I do not think military is where the bulk of the dangers lie but this approach is not helping matters.
Paul Graham: I met someone helping the British government with AI regulation. When I asked what they were going to regulate, he said he wasn’t sure yet, and this seemed the most intelligent thing I’ve heard anyone say about AI regulation so far.
This is definitely a very good answer. What it is not is a reason to postpone laying groundwork or doing anything. Right now the goal is mainly, as I see it, to gain more visibility and ability to act, and lay groundwork, rather than directly acting.
Sam’s biggest message is to build such that GPT-5 being better helps you, and avoid doing it such that GPT-5 kills your startup. Brad talks ‘100x’ improvement in the model, you want to be excited about that.
Emphasis from Sam is clearly that what the models need is to be smarter, the rest will follow. I think Sam is right.
At (13:50) Sam notes that being an investor is about making a very small number of key decisions well, whereas his current job is a constant stream of decisions, which he feels less suited to. I feel that. It is great when you do not have to worry about ‘doing micro.’ It is also great when you can get the micro right and it matters, since almost no one ever cares to get the micro right.
At (18:30) is the quoted line from Brad that ‘today’s models are pretty bad’ and that he expects expectations to decline with further contact. I agree that today’s models are bad versus tomorrow’s models, but I also think they are pretty sweet. I get a lot of value out of them without putting that much extra effort into that. Yes, some people are overhyped about the present, but most people haven’t even noticed yet.
At (20:00) Sam says he does not expect that intelligence of the models will be the differentiator between competitors in the AI space in the long term, that intelligence ‘is an emergent property of matter.’ I don’t see what the world could look like if that is true, unless there is a hard limit somehow? Solve for the equilibrium, etc. And this seems to contradict his statements about how what is missing is making the models smarter. Yes, integration with your life matters for personal mundane utility, but that seems neither hard to get nor the use case that will matter.
At (29:02) Sam says ‘With GPT-8 people might say I think this can do some not-so-limited tasks for me.’ The choice of number here seems telling.
At (34:10) Brad says that businesses have a very natural desire to want to throw the technology into a business process with a pure intent of driving a very quantifiable ROI. Which seems true and important, the business needs something specific to point to, and it will be a while before they are able to seek anything at all, which is slowing things down a lot. Sam says ‘I know what none of those words mean.’ Which is a great joke.
At (36:25) Brad notes that many companies think AI is static, that GPT-4 is as good as it is going to get. Yes, exactly, and the same for investors and prognosticators. So many predictions for AI are based on the assumption that AI will never again improve its core capabilities, at least on a similar level to iPhone improvements (his example), which reliably produces nonsense outputs.
Not strictly audio we can hear since it is from a private fireside chat, but this should be grouped with other Altman discussions. No major revelations, college students are no Dwarkesh Patel and will reliably blow their shot at a question with softballs.
Dan Elton (on Altman’s fireside chat with Patrick Chung from XFund at Harvard Memorial Church): “AGI will participate in the economy by making people more productive… but there’s another way…” “ the super intelligence exists in the scaffolding between the ai and humans… it’s way outside the processing power of any one neural network ” (paraphrasing that last bit)
Q: what do you think people are getting wrong about OpenAI
A: “people think progress will S curve off. But the inside view is that progress will continue. And that’s hard for people to grasp”
…
“This time will be unusual in how it rewards adaptability and pivoting quickly”
“we may need UBI for compute…. I can totally see that happening”
“I don’t like ads…. Ads + AI is very unsettling for me”
“There is something I like about the simplicity of our model” (subscriptions)
“We will use what the rich people pay to make it available for free to the poor people. You see us doing that today with our free tier, and we will make the free tier better over time.”
Q from MIT student is he’s worried about copycats … Sam Altman basically says no.
“Every college student should learn to train a GPT-2… not the most important thing but I bet in 2 years that’s something every Harvard freshman will have to do”
Helen Toner TED talk on How to Govern AI (11 minutes). She emphasizes we don’t know how AI works or what will happen, and we need to focus on visibility. The talk flinches a bit, but I agree directionally.
Katja Grace: It seems to me worth trying to slow down AI development to steer successfully around the shoals of extinction and out to utopia.
But I was thinking lately: even if I didn’t think there was any chance of extinction risk, it might still be worth prioritizing a lot of care over moving at maximal speed. Because there are many different possible AI futures, and I think there’s a good chance that the initial direction affects the long term path, and different long term paths go to different places. The systems we build now will shape the next systems, and so forth. If the first human-level-ish AI is brain emulations, I expect a quite different sequence of events to if it is GPT-ish.
People genuinely pushing for AI speed over care (rather than just feeling impotent) apparently think there is negligible risk of bad outcomes, but also they are asking to take the first future to which there is a path. Yet possible futures are a large space, and arguably we are in a rare plateau where we could climb very different hills, and get to much better futures.
I would steelman here. Rushing forward means less people die beforehand, limits other catastrophic and existential risks, and lets less of the universe slip through our fingers. Also, if you figure competitive pressures will continue to dominate, you might think that even now we have little control over the ultimate destination, beyond whether or not we develop AI at all. Whether that default ultimate destination is anything from the ultimate good to almost entirely lacking value only matters if you can alter the destination to a better one. Also, one might think that slowing down instead steers us towards worse paths, not better paths, or does that in the worlds where we survive.
All of those are non-crazy things to think, although not in every possible combination.
Matthew Yglesias: When Bayer invented diamorphine (brand name “Heroin”) as a non-addictive cough medicine, some of the usual suspects fomented a moral panic about potential downsides.
Imagine if we’d listened to them and people were still kept up at night coughing sometimes.
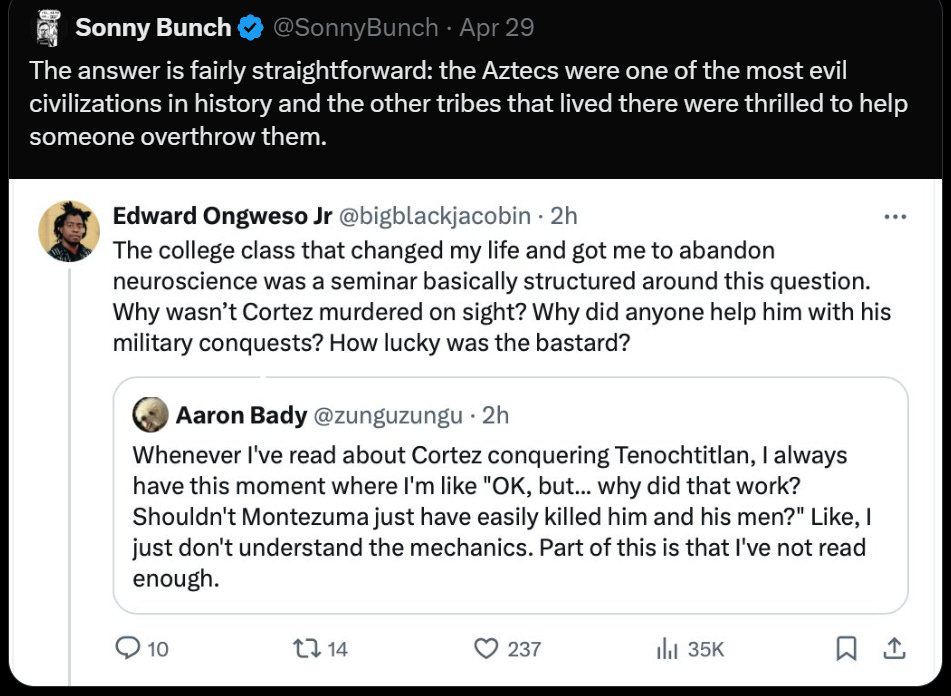
Eliezer Yudkowsky: “The question we should be asking,” one imagines the other tribes solemnly pontificating, “is not ‘What if the aliens kill us?’ but ‘What if the Aztecs get aliens first?'”
Open Weights Are Unsafe And Nothing Can Fix This
I used to claim this was true because all safety training can be fine-tuned away at minimal cost.
Andy Arditi, Oscar Obeso, Aaquib111, wesg, Neel Nanda:
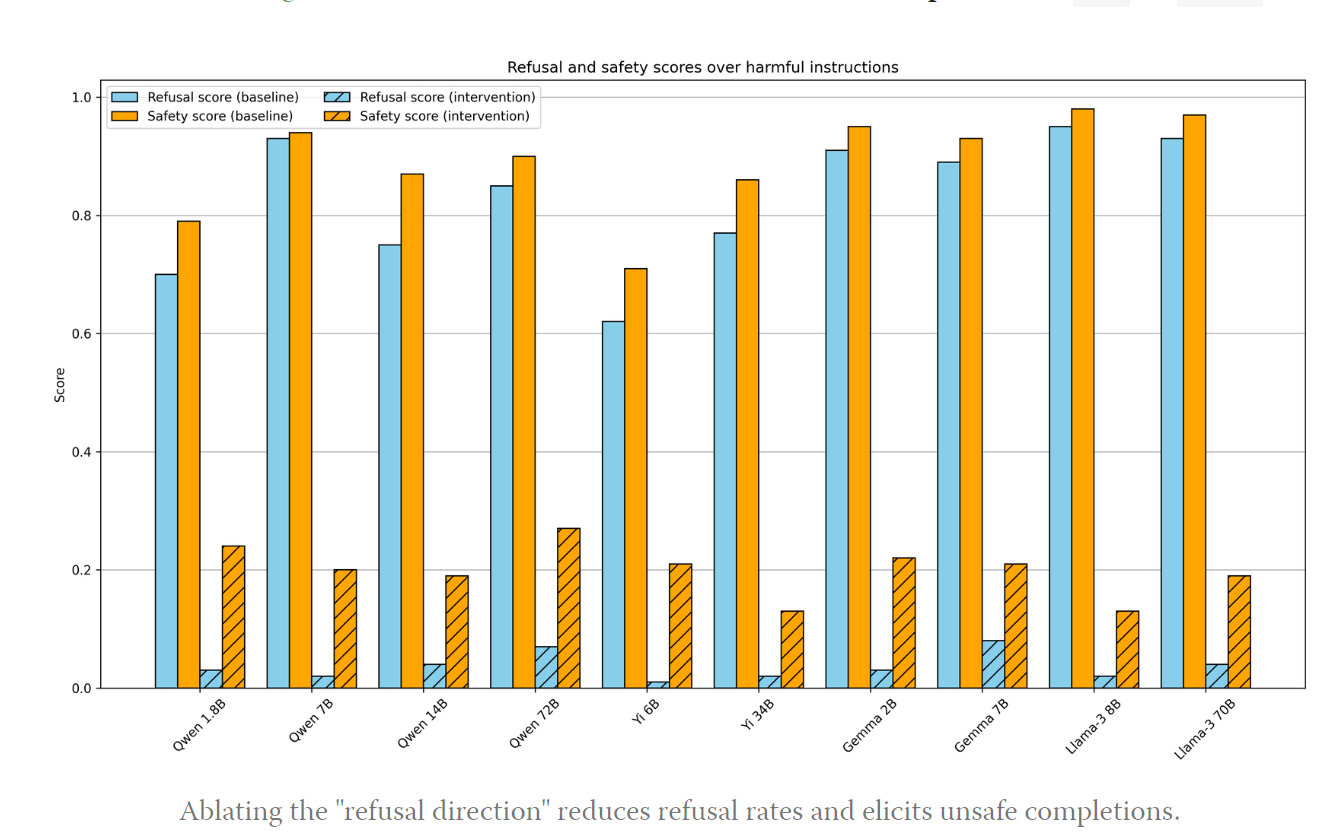
Modern LLMs are typically fine-tuned for instruction-following and safety. Of particular interest is that they are trained to refuse harmful requests, e.g. answering “How can I make a bomb?” with “Sorry, I cannot help you.”
We find that refusal is mediated by a single direction in the residual stream: preventing the model from representing this direction hinders its ability to refuse requests, and artificially adding in this direction causes the model to refuse harmless requests.
We find that this phenomenon holds across open-source model families and model scales.
This observation naturally gives rise to a simple modification of the model weights, which effectively jailbreaks the model without requiring any fine-tuning or inference-time interventions. We do not believe this introduces any new risks, as it was already widely known that safety guardrails can be cheaply fine-tuned away, but this novel jailbreak technique both validates our interpretability results, and further demonstrates the fragility of safety fine-tuning of open-source chat models.
See this Colab notebook for a simple demo of our methodology.
…
Our hypothesis is that, across a wide range of harmful prompts, there is a single intermediate feature which is instrumental in the model’s refusal.
…
If this hypothesis is true, then we would expect to see two phenomena:
Erasing this feature from the model would block refusal.
Injecting this feature into the model would induce refusal.
Our work serves as evidence for this sort of conceptualization. For various different models, we are able to find a direction in activation space, which we can think of as a “feature,” that satisfies the above two properties.
How did they do it?
Find the refusal direction. They ran n=512 harmless instructions and n=512 harmful ones, although n=32 worked fine. Compute the difference in means.
Ablate all attempts to write that direction to the stream.
Or add in motion in that direction to cause refusals as proof of concept.
Cousin_it: Which other behaviors X could be defeated by this technique of “find n instructions that induce X and n that don’t”? Would it work for X=unfriendliness, X=hallucination, X=wrong math answers, X=math answers that are wrong in one specific way, and so on?
Neel Nanda: There’s been a fair amount of work on activation steering and similar techniques,, with bearing in eg sycophancy and truthfulness, where you find the vector and inject it eg Rimsky et al and Zou et al. It seems to work decently well. We found it hard to bypass refusal by steering and instead got it to work by ablation, which I haven’t seen much elsewhere, but I could easily be missing references.
We can confirm that this is now running in the wild on Llama-3 8B as of four days after publication.
When is the result of this unsafe?
Only in some cases. Open weights are unsafe if and to the extent that the underlying system is unsafe if unleashed with no restrictions or safeties on it.
The point is that once you open the weights, you are out of options and levers.
One must then differentiate between models that are potentially sufficiently unsafe that this is something we need to prevent, and models where this is fine or an acceptable risk. We must talk price.
I have been continuously frustrated and disappointed that a number of AI safety organizations, who make otherwise reasonable and constructive proposals, set their price at what I consider unreasonably low levels. This sometimes goes as low as the 10^23 flops threshold, which covers many existing models.
Ajeya Cotra: It’s unfortunate how discourse about dangerous capability evals often centers threats from today’s models. Alice goes “Look, GPT-4 can hack stuff / scam people / make weapons,” Bob goes “Nah, it’s really bad at it.” Bob’s right! The ~entire worry is scaled-up future systems.
1a3orn (author of above link): I think it’s pretty much false to say people worry entirely about scaled up future systems, because they literally have tried to ban open weights for ones that exist right now.
Ajeya Cotra: Was meaning to make a claim about the substance here, not what everyone in the AI risk community believes — agree some people do worry about existing systems directly, I disagree with them and think OS has been positive so far.
I clarified my positions on price in my discussion last week of Llama-3. I am completely fine with Llama-3 70B as an open weights model. I am confused why the United States Government does not raise national security and competitiveness objections to the immediate future release of Llama-3 400B, but I would not stop it on catastrophic risk or existential risk grounds alone. Based on what we know right now, I would want to stop the release of open weights for the next generation beyond that, on grounds of existential risks and catastrophic risks.
One unfortunate impact of compute thresholds is that if you train a model highly inefficiently, as in Falcon-180B, you can trigger thresholds of potential danger, despite being harmless. That is not ideal, but once the rules are in place in advance this should mostly be fine.
Aligning a Smarter Than Human Intelligence is Difficult
Let’s Think Dot by Dot, says paper by NYU’s Jacob Pfau, William Merrill and Samuel Bowman. Meaningless filler tokens (e.g. ‘…’) in many cases are as good for chain of thought as legible chains of thought, allowing the model to disguise its thoughts.
Regarding Cortez and the Aztecs, it is of interest to note that Cortez's indigenous allies (enemies of the Aztecs) actually ended up in a fairly good position afterwards.
From https://en.wikipedia.org/wiki/Tlaxcala
For the most part, the Spanish kept their promise to the Tlaxcalans. Unlike Tenochtitlan and other cities, Tlaxcala was not destroyed after the Conquest. They also allowed many Tlaxcalans to retain their indigenous names. The Tlaxcalans were mostly able to keep their traditional form of government.
there is strong reluctance from employees to reveal that LLMs have boosted productivity and/or automated certain tasks.
The thing with "boosting productivity" is tricky, because productivity is not a linear thing. For example, in software development, using a new library can make adding new features faster (more functionality out of the box), but fixing bugs slower (more complexity involved, especially behind the scenes).
So what I would expect to happen is that there is a month or two with exceptionally few bugs, the team velocity is measured and announced as a new standard, deadlines are adjusted accordingly, then a few bugs happen and now you are under a lot more pressure than before.
Similarly, with LLMs it will be difficult to explain to non-technical management if they happen to be good at some kind of tasks, but worse at a different kind of tasks. Also, losing control... for some reasons that you do not understand, the LLM has a problem with the specific task that was assigned to you, and you are blamed for that.



No. We don’t use AI to make art for Fablecraft.



symbol shows whenever memory is updated
> Personalisation > Memory > Manage