Using prediction markets to generate LessWrong posts
post by Matthew Barnett (matthew-barnett) · 2022-04-01T16:33:24.404Z · LW · GW · 11 commentsContents
11 comments
I have a secret to reveal: I am not the author of my recent LessWrong posts. I know almost nothing about any of the topics I have recently written about.
Instead, for the last two months, I have been using Manifold Markets to write all my LessWrong posts. Here's my process.
To begin a post, I simply create 256 conditional prediction markets about whether my post will be curated, conditional on which ASCII character comes first in the post (though I'm considering switching to Unicode). Then, I go with whatever character yields the highest conditional probability of curation, and create another 256 conditional prediction markets for the next character in the post, plus a market for whether my post will be curated if the text terminates at that character. I repeat this algorithm until my post is complete.
Here's an example screenshot for a post that is currently in my drafts:
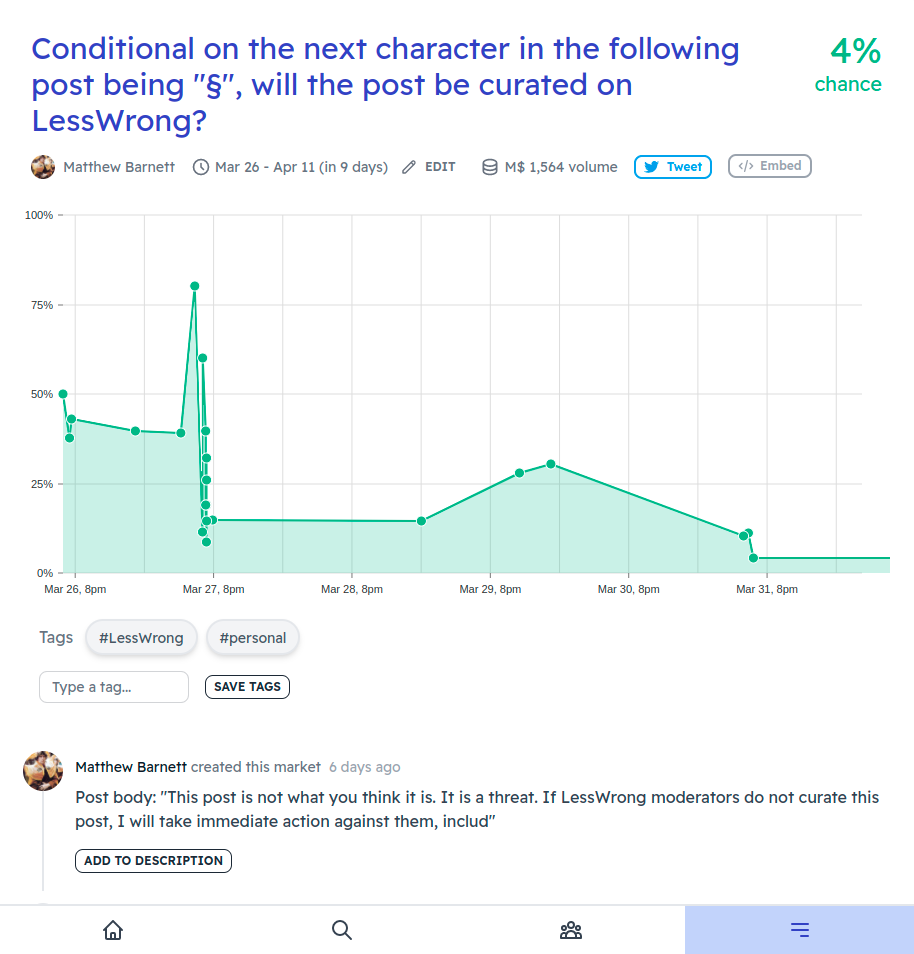
Looks interesting!
Even this post was generated using this method.
11 comments
Comments sorted by top scores.
comment by AprilSR · 2022-04-01T17:00:38.138Z · LW(p) · GW(p)
How did you decide on the image?
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2022-04-01T17:04:46.722Z · LW(p) · GW(p)
Before posting, I roll out another sequence of prediction markets that write instructions for me on what images and links I should use in the post, and where.
Replies from: yitz, zac-hatfield-dodds↑ comment by Yitz (yitz) · 2022-04-01T21:28:27.135Z · LW(p) · GW(p)
Oh, I was going to guess going pixel by pixel, with each separate RGB value as a separate market…
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2022-04-01T21:35:16.805Z · LW(p) · GW(p)
Good idea. One could also go Turing machine by Turing machine, voting on the ones which would produce the most upvoted content. Then you can just read the binary output as html.
Replies from: Viliam↑ comment by Viliam · 2022-04-01T22:17:18.322Z · LW(p) · GW(p)
Prediction market with Solomonoff prior [? · GW]. The theoretically most efficient way to do anything.
(I wonder if we just found a solution to AI alignment. Start with the simplest machines, and let the prediction markets vote on whether they will destroy the world...)
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2022-04-01T22:27:40.483Z · LW(p) · GW(p)
Right, just seed a prediction market maker using a logarithmic scoring rule, where the market's prior probability is given by Solomonoff. There is the small issue of choosing a Turing interpreter, but I think we just choose the Lisp language as a reasonably elegant one.
↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2022-04-01T20:00:36.452Z · LW(p) · GW(p)
Ah, a sort of multi-modal decision-market-only transformer.
comment by MichaelDickens · 2023-03-02T19:26:21.743Z · LW(p) · GW(p)
One concern I have with this method is that it's greedy optimization. The next character with the highest probability-of-curation might still overly constrain future characters and end up missing global maxima.
I'm not sure the best algorithm to resolve this. Here's an idea: Once the draft post is fully written, randomly sample characters to improve: create a new set of 256 markets for whether the post can be improved by changing the Nth character.
The problem with step 2 is you'll probably get stuck in a local maximum. One workaround would be to change a bunch of characters at random to "jump" to a different region of the optimization space, then create a new set of markets to optimize the now-randomized post text.