Forecasting progress in language models
post by Matthew Barnett (matthew-barnett), Metaculus · 2021-10-28T20:40:59.897Z · LW · GW · 6 commentsThis is a link post for https://www.metaculus.com/notebooks/8329/human-level-language-models/
Contents
An information theoretic perspective N-gram language models Interlude: How do modern language models work? A note about perplexity Extrapolating current perplexity trends Discussion Further reading None 6 comments
Note: this post was cross-posted to Metaculus over a week ago as part of their new Metaculus journal.
Here, I describe a way of measuring the performance of language models, and extrapolate this measure using publicly available data on benchmarks. The result is a (surprisingly) short timeline to "human-level"—within one decade from now. Since posting to Metaculus, I have realized the need to clarify a few things first,
- I am not saying that this model represents my inside view. I merely used linear regression to extrapolate performance metrics, and I think there is credible reason to doubt these results, not least of which because I may have made a mistake. Check out the comment section on Metaculus for more discussion.
- That said, it may still be interesting to consider what might be true about the world if we just take these results literally. Predicting that a trend will soon inexplicably slow down is easy. What's harder is proposing an alternative model.
- There are probably errors in the Jupyter notebook, my graphs, and my equations. Just let me know in the comments if you see any.
Language models have received a lot of attention recently, especially OpenAI’s GPT-3 and Codex. While the possibility of a human-level language model remains out of reach, when might one arrive? To help answer this question, I turn to some basic concepts in information theory, as pioneered by Claude Shannon.
Shannon was interested in understanding how much information is conveyed by English text. His key insight was that when a text is more predictable, less information is conveyed per symbol compared to unpredictable texts. He made this statement more precise by introducing the concept of entropy. Roughly speaking, entropy measures the predictability of a sequence of text, in the limit of perfect prediction abilities.
Since Shannon’s work, a popular hobby of computational linguists has been to invent new ways of measuring the entropy of the English language. By comparing these estimates with the actual performance of language models at the task of predicting English text, it is possible to chart the progress we have made toward the goal of human-level language modeling. Furthermore, there are strong reasons to believe that entropy is a more useful metric for tracking general language modeling performance when compared to performance metrics on extrinsic tasks, such as those on SuperGLUE.
My result is a remarkably short timeline: Concretely, my model predicts that a human-level language model will be developed some time in the mid 2020s, with substantial uncertainty in that prediction.
I offer a few Metaculus questions to test my model and conclude by speculating on the possible effects of human-level language models. Following Alan Turing, mastery of natural language has long been seen as a milestone achievement, signaling the development of artificial general intelligence (AGI). I do not strongly depart from this perspective, but I offer some caveats about what we should expect after human-level language models are developed.
An information theoretic perspective
In Claude Shannon’s landmark paper, A Mathematical Theory of Communication, he introduces a way of measuring the predictability of some language, natural or artificial. He identifies this measure with entropy, a concept he borrows from statistical mechanics in physics. For a discrete random variable that can take on possible values with probabilities , entropy is formally defined as
The base for the log is typically 2, reflecting the unit of "bits" for a computer. The formula for entropy is also sometimes written in another way, to highlight that it's an expected value,
is also called the information content or surprisal of the random variable . To make the idea of surprisal more intuitive, I'll provide the example of flipping coins.
Imagine you had a coin and flipped it repeatedly to generate a sequence of 's and 's. Your sequence could look like this,
Now consider trying to predict the result of each coin flip ahead of time. If it's a fair coin, there's no better strategy than to predict 50% for either or . To put it another way, the surprise you get from observing either a or is the same, . Therefore, the expected surprise, or entropy, from the next flip in a sequence of coin flips is .
However, the coin might not always be fair. Suppose the coin had a 90% chance of generating and a 10% chance of generating . Then, your sequence might look more like this,
This time, the best strategy is to predict an . Upon observing an , you would experience relatively little surprise, only . If you came across a you would of course be much more surprised: . On average, your surprise will be , quite a bit less than the average surprisal for the fair coin flip sequence.
It makes sense that the entropy of the fair coin flip sequence is higher than the entropy of the biased coin flip sequence. In the case of the biased coin, there was a ton of regularity in the sequence: Since the next flip will usually be , it's almost uninteresting to observe . By contrast, the fair coin flip sequence is completely unpredictable and therefore frequently surprises us.
Claude Shannon's insight was to apply the concept of entropy to all types of information sources. In the case of humans, our written language can be seen as similar to a sequence of coin flips. To understand why, consider that written text (in ASCII) can be converted to binary. Then, in the same way we asked how surprising each new coin flip was, we can ask how surprising each new bit of information in our written text is.
Another way to think about entropy is text compression. Owing to its predictability, the biased coin flip sequence was highly compressible; one compression scheme simply counts the number of 's we observe before encountering a and writes that number down, rather than writing down the full sequence of 's. More generally, imagine a perfect compression algorithm for some language: The expected number of bits in original encoding per bits in the compression equals the entropy of that language.
As Shannon pointed out, English text is often very predictable. If we see a "q" we can usually be sure that a "u" will follow. If we see "The dog ate my" the word most likely to come next is "homework". However, just as in the case of coin flips, English isn't completely predictable; for example, given only the first word in a poem, you can rarely deduce the entire poem. Therefore, the entropy of English text is above zero, though not infinite.
In a follow-up paper, Shannon tries to estimate the empirical entropy of the English language. To do this, he employs the concept of an N-gram language model.
N-gram language models
A language model is simply a statistical model over sequences of characters in some language. For example, the "language" of fair coin flips is well-described by a model that assigns 50% probability to and 50% probability to . For more complex languages, Shannon turns to Markov models to shed light on the task of English language prediction.
The N-gram language model is a Markov model for predicting the next word in a sequence of text. Formally, a language model is simply a probability distribution over a sequence of words (or characters, or symbols):
We can expand this probability using the chain rule of probability, to obtain,
The main point here is that if we have some way of calculating for any , then that will provide us a way of calculating the joint distribution, . Sampling from these conditional probabilities also provides us a tractable method for making the model write text, one word at a time.
The N-gram model makes what's called a Markov assumption, which is to say that it assumes for some . For , this assumption is equivalent to saying that , or in other words, the 'th word is independent of the words that came before it.
When we call it a unigram model. A simple way of "training" a unigram model is to get a count of all the words in the English language by frequency in printed text. Call our count of the word , . Our estimate of the probability is then the relative frequency of that word within the text,
When the idea is similar, except instead of counting the raw frequency of words in printed text, we calculate the frequency of word pairs, or triplets—or in general, conjunctions of words. For example, if and we wanted to estimate the probability of we would begin by finding all instances of the words "I like to" in written text. Next, we would count for each instance, what fraction of those the word "dance" followed. This fraction provides our estimate of the probability for .
How can this idea be used to estimate the entropy of the English language? Shannon proceeds by pointing out that N-gram models become increasingly good at predicting English text as approaches infinity. More formally, let be some contiguous block of text and define some function as
If you've been following closely, you might recognize the function as simply the entropy of a random variable; in this case, the random variable may take on different blocks of text. To measure entropy at a word-level we write . This new function measures the entropy of the next word in a sequence of texts, of length . Finally, Shannon posits the entropy of the English language to be
The utility of the N-gram model should now be apparent. To estimate the quantity we can build an N-gram model; to estimate , then, we simply try to find the limit of the entropy of our N-gram models as N goes to infinity.
Moreover, Shannon calculated an additional entropy estimate by testing actual humans on the task of predicting text, allotting them 100 characters.
Despite working in the early 1950s, Shannon provided impressively precise figures for the entropy of the English language. His lower bound estimate came out to 0.6 bits per character, with an upper bound at 1.3 bits per character. He notes,
It is evident that there is still considerable sampling error in these figures due to identifying the observed sample frequencies with the prediction probabilities. It must also be remembered that the lower bound was proved only for the ideal predictor, while the frequencies used here are from human prediction.
Despite the uncertainty in his figures, his range has more-or-less withstood the test of time. Gwern collected estimates for the entropy of printed English text and found, "In practice, existing algorithms can make it down to just 2 bits to represent a character, and theory suggests the true entropy was around 0.8 bits per character."
We've now arrived at a very important point: To estimate how close we are to "perfect" language modeling, we can simply compare the entropy of modern language models with the theoretical estimates provided by Shannon and others.
Interlude: How do modern language models work?
Modern language models are surprisingly similar to N-gram models in their structure. Therefore, most of what I said in the preceding paragraphs about entropy of N-gram models can be said about contemporary neural-network based models, such as GPT-3. Nonetheless, it is interesting to explore the differences between neural network-based language models and N-gram models.
The main difference concerns how we estimate the probability . If you recall, N-grams estimated this probability by invoking the Markov assumption, and counting the relative frequency of phrases in English text with N-truncated preceding words in order. By contrast, modern machine learning researchers estimate this probability by training a neural network to predict characters given some word embedding.
A word embedding is a vector representation of text in . To be useful, word embeddings should encode interesting semantic information in natural language sentences. For example, in a good word embedding, the sentence-vector "I visited the store" should be very close to "I went to the store" as the two convey extremely similar semantic meanings.
Neural language models fall within the supervised learning framework, meaning that they try to predict an output label giving some input vector. In this case, the output label is provided by the next character, or token in text, and the input vector is a word embedding. Formally, this looks like estimating the probability
where stands for "context." Most recently, neural models like GPT-3 have used the transformer architecture, which is considered an extremely general, albeit flawed, model.
A note about perplexity
In modern neural-based language models, the function used to evaluate the performance of the model is most often perplexity, a measure fundamentally linked to entropy. More specifically, the perplexity of some model on a probability distribution is simply,
where is the cross-entropy of relative to . Cross-entropy, can be decomposed into the entropy of and the KL-divergence (or relative entropy) between and .
More specifically, the KL-divergence between two probability distributions which roughly measures how "far" the distributions are from each other. We can also easily see that if , then the cross-entropy , which is what I have meant throughout this blog post when I have talked about "human-level" performance. Technically, a model with would have superhuman performance, but as we shall see, we seem to be approaching even this very high bar at a roughly linear rate over time, given the empirical data on language model performance.
Perplexity is a so-called intrinsic measure of language modeling performance, distinguished from extrinsic measures which track application-specific performance. The reason why entropy is intrinsic is because there's no way to Goodhart perplexity. A language model that scores well on perplexity is simply a good language model, almost by definition. Except by cheating in some easily detectable ways, you cannot get a well-measured perfect perplexity score unless you can model English extremely well.
As one would expect, perplexity has been found to be highly correlated with extrinsic performance measures. For example, to test their chatbot Meena, researchers at Google developed the human-evaluated performance metric Sensibleness and Specificity Average (SSA), "which captures key elements of a human-like multi-turn conversation." SSA was found to correlate strongly with perplexity.
{kind=link}
Shen et al. (2017) found a similar result, which they used to extrapolate then-current language modeling trends to human performance. They concluded,
The results imply that LMs need about 10 to 20 more years of research before human performance is reached.
Given the publication date, this prediction corresponds to the years 2027 and 2037. In the next section, I build on their result by incorporating trends from recent research in language modeling. Are we still on track?
Extrapolating current perplexity trends
Though sources disagree, the average length of an English word is roughly 5.1 characters. Alex Greaves revealed the average word length on the popular Penn Treebank dataset to be 5.6 characters. Using Claude Shannon's estimate for the entropy of English text, we therefore can calculate that the average word-level perplexity of English is between
Currently, GPT-3 achieves a word-level perplexity of on the Penn Treebank dataset, blowing past Claude Shannon's higher end estimate. This is not surprising: His upper bound was obtained by asking humans to predict the next character in a sequence of text, which is not a task we should expect humans to be skilled at, despite understanding English well.
Shen et al. (2017) used human evaluation of generated text to find that a perplexity of around 12 may be considered human-level, which as they point out, is broadly consistent with Shannon's lower estimate.
To measure recent progress toward human-level language modeling, I gathered data from Papers With Code for state of the art (SOTA) language modeling papers. Most results submitted to Papers With Code are only a few years old, with very few papers from before 2014. I collected benchmarks with at least 5 SOTA papers submitted, and only if at least one result from 2020 or later had been submitted. I then calculated the line of best fit through the trend in SOTA entropy results, and solved for when this line intersected with each of the following entropy estimates: .
To make my extrapolation more robust, I performed linear regression using two different methods for each dataset. The first method regresses on points where each represents the date when each new SOTA result was published, and represents the result. The second method regresses on where there exists a every 14 days after a starting date, and represents when the most recent SOTA result was at that time.
The full calculations can be found in this Jupyter notebook. In the table below, I have reported the date of intersection with Shannon's entropy estimate of 0.6, for both methods of regression.
For each of the below I list the benchmark, the date of intersection according to method 1 and then the date of intersection according to method 2.
| Benchmark | Method 1 | Method 2 |
| Penn Treebank (Word Level) | 2024-07-06 | 2024-09-14 |
| Penn Treebank (Character Level) | 2034-11-12 | 2035-04-17 |
| WikiText-103 | 2021-11-11 | 2022-09-27 |
| enwiki8 | 2022-06-15 | 2023-02-06 |
| One Billion Word | 2029-01-06 | 2027-04-22 |
| Text8 | 2022-03-17 | 2025-03-21 |
| Hutter Prize | 2022-06-22 | 2025-03-17 |
| WikiText-2 | 2022-06-10 | 2024-10-11 |
For regression method 1, the median predicted date is 2022-06-18 and the mean predicted date is 2024-12-23. However, the uncertainty here is quite high: some results predict an extremely short timeline of under a year, and the Penn Treebank (Character Level) benchmark yields a date well ahead of all the others in 2034!
Here are some illustrative charts from the notebook. The Penn Treebank (Word Level) dataset in particular has received lots of submissions, perhaps making it a more reliable indicator than some of the other benchmarks.
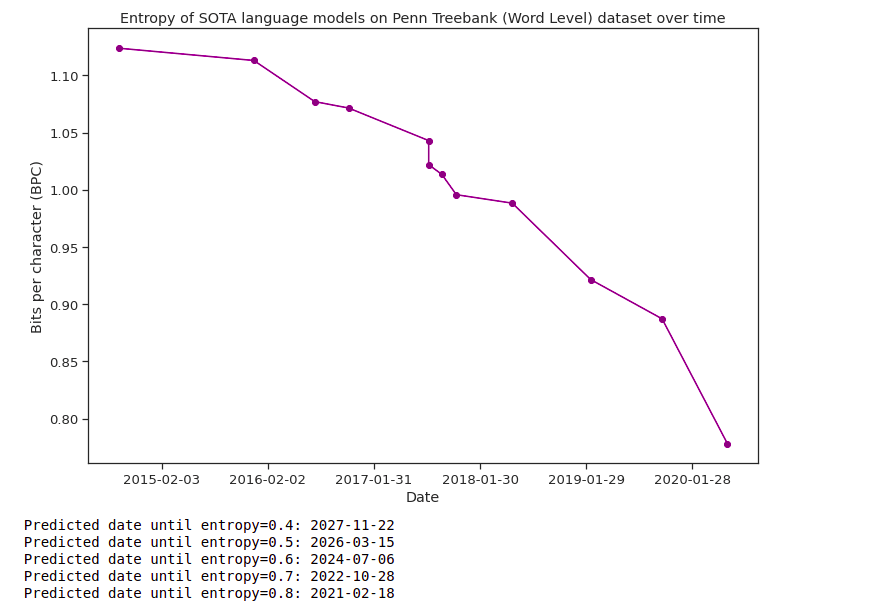
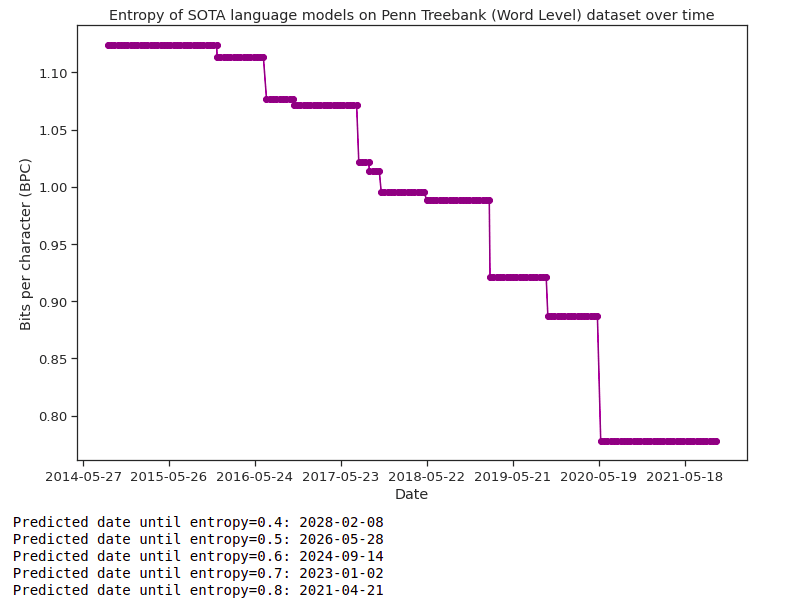
It's worth noting a few methodological issues with my simple analysis (which could be corrected with future research). Firstly, I did not directly attempt to compute the entropy of each dataset, instead testing values near Shannon's 70 year old estimate. Secondly, the data on Papers With Code relies on user submissions, which are unreliable and not comprehensive. Thirdly, I blindly used linear regression on entropy to extrapolate the results. It is very plausible, however, that a better regression model would yield different results. Finally, many recent perplexity results were obtained using extra training data, which plausibly should be considered cheating.
Nonetheless, I would be surprised if a more robust analysis yielded a radically different estimate, such as one more than 20 years away from mine (the mean estimate of ~2025). While I did not directly estimate the entropy for each dataset, I did test the values , and found that changing the threshold between these values only alters the final result by a few years at most in each case. Check out the Jupyter notebook to see these results.
I conclude, therefore, that either current trends will break down soon, or human-level language models will likely arrive in the next decade or two.
Discussion
Having arrived at an estimate for when we should expect human-level language models, I now turn to my own subjective opinion about the likely effects of such a development.
Ever since Alan Turing introduced his imitation game, mastery of natural language has long been seen as a milestone achievement within AI. However, unlike other famous milestones, such as chess or Go, I suspect human-level language models will precipitate a much greater splash in the economic sphere.
Most obviously, human-level language models can be used to automate human labor. My thesis here rests on the fact that natural language is extremely general: With the exception of physical tasks, most human labor can arguably be reduced into some language modeling problem. For instance, OpenAI's big bet right now seems to be that computer programming will soon fall to language model-guided automation.
That said, some intellectual tasks are quite difficult to reduce to language modeling problems. Consider the following prompt,
The following is a proof that P = NP:
Since language models try to predict actual human text patterns—as opposed to what flawless humans would hypothetically write—the best completion to this text may not be proof of P = NP, but rather a crank proof, a hoax, or this very blog post (even if a proof exists!). It seems very likely that advanced language models will require a human operator to be an expert prompt engineer in order to produce highly robust results.
Moreover, even if human-level language models arrive by the end of 2024 in some form, it does not follow that such models will be affordable. Indeed, recent progress seems to be driven in part by increased spending on computation during training, a trend partially motivated by what Gwern Branwen coined the scaling hypothesis.
Last year, Open Philanthropy's Ajeya Cotra unveiled a draft report [LW · GW] rooted in the scaling hypothesis, which attempted to predict when economically transformative AI would arrive. The result is a considerably longer timeline than the one I have given here. In addition, I have independently offered [LW · GW] two more reasons for longer timelines: namely, deployment lag and regulation.
These quibbles notwithstanding, the development of a human-level language model would still be a groundbreaking result, which if not economically paramount, would at least be immensely valuable philosophically, linguistically, and recreationally. I look forward to following any new developments in the coming years.
Further reading
Where is human level on text prediction? (GPTs task) [LW · GW]
Extrapolating GPT-N performance [LW · GW]
What 2026 looks like (Daniel's Median Future) [LW · GW] (make sure to read the comments too)
6 comments
Comments sorted by top scores.
comment by almath123 · 2021-10-29T18:21:25.405Z · LW(p) · GW(p)
Perplexity depends on the vocabulary and is sensitive to preprocessing which could skew the results presented here. This is a common problem. See the following reference:
Unigram-Normalized Perplexity as a Language Model Performance Measure with Different Vocabulary Sizes Jihyeon Roha, Sang-Hoon Ohb, Soo-Young Lee, 2020
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2021-10-29T20:31:27.943Z · LW(p) · GW(p)
Thanks! That's really interesting. I'll check it out.
comment by Edouard Harris · 2021-11-01T17:38:30.177Z · LW(p) · GW(p)
Extremely interesting — thanks for posting. Obviously there are a number of caveats which you carefully point out, but this seems like a very reasonable methodology and the actual date ranges look compelling to me. (Though they also align with my bias in favor of shorter timelines, so I might not be impartial on that.)
One quick question about the end of this section [AF · GW]:
The expected number of bits in original encoding per bits in the compression equals the entropy of that language.
Wouldn't this be the other way around? If your language has low entropy it should be more predictable, and therefore more compressible. So the entropy would be the number of bits in the compression for each expected bit of the original.
comment by Charlie Steiner · 2021-10-28T23:41:44.588Z · LW(p) · GW(p)
Next up would be some notion of abstraction or coarse-graining. I might quickly make mistakes in predicting the probability distribution over next letters, but somehow I can make long-term predictions about abstract properties of the text. Yes, these get trained by purely predicting the next word, but I think they're still useful to measure separately, because if we were better at measuring them we would see that they lag behind progress in local perplexity, because large-scale patterns put a lot more demands on transformers' dataset size and model size (if densely looking at long stretches of text, yes I know it's linear, but the coefficient is large).
comment by jabowery · 2023-01-26T18:20:02.748Z · LW(p) · GW(p)
Lossless compression is the correct unsupervised machine learning benchmark, and not just for language models. To understand this, it helps to read the Hutter Prize FAQ on why it doesn't use perplexity:
http://prize.hutter1.net/hfaq.htm
Although Solomonoff proved this in the 60s, people keep arguing about it because they keep thinking they can, somehow, escape from the primary assumption of Solomonoff's proof: computation. The natural sciences are about prediction. If you can't make a prediction you can't test your model. To make a prediction in a way that can be replicated, you need to communicate a model that the receiver can then use to make an assertion about the future. The language used to communicate this model is, in its most general form, algorithmic. Once you arrive at this realization, you have just adopted Solomonoff's primary assumption with which he proved that lossless compression is the correct unsupervised model selection criterion aka the Algorithmic Information Criterion for model selection.
People are also confused about the distinction between science and technology (aka unsupervised vs supervised learning) but also the distinction between the scientific activities of model generation as well as model selection.
Benchmarks are about model selection. Science is about both model selection and model generation. Technology is about the application of scientific models subject to utility functions of decision trees (supervised learning in making decisions about not only what kind of widget to build but also what kind of observations to prioritize in the scientific process).
If LessWrong can get this right, it will do an enormous amount of good now that people are going crazy about bias in language models. As with the distinction between science and technology, people are confused about bias in the scientific sense and bias in the moral zeitgeist sense (ie: social utility). We're quickly heading into a time when exceedingly influential models are being subjected to reinforcement learning in order to make them compliant with the moral zeitgeist's notion of bias almost to the exclusion of any scientific notion of bias. This is driven by the failure of thought leaders to get their own heads screwed on straight about what it might mean for there to be "bias in the data" under the Algorithmic Information Criterion for scientific model selection. Here's a clue: In algorithmic information terms, a billion repetitions of the same erroneous assertion requires a 30 bit counter, but a "correct" assertion (one that finds multidisciplinary consilience) may be imputed from other data and hence, ideally, requires no bits.