Tomorrow I will fly out to San Francisco, to spend Friday through Monday at the LessOnline conference at Lighthaven in Berkeley. If you are there, by all means say hello. If you are in the Bay generally and want to otherwise meet, especially on Monday, let me know that too and I will see if I have time to make that happen.
Even without that hiccup, it continues to be a game of playing catch-up. Progress is being made, but we are definitely not there yet (and everything not AI is being completely ignored for now).
Last week I pointed out seven things I was unable to cover, along with a few miscellaneous papers and reports.
However, OpenAI developments continue. Thanks largely to Helen Toner’s podcast, some form of that is going back into the queue. Some other developments, including new media deals and their new safety board, are being covered normally.
Which model is the best right now? Michael Nielsen is gradually moving back to Claude Opus, and so am I. GPT-4o is fast and has some nice extra features, so when I figure it is ‘smart enough’ I will use it, but when I care most about quality and can wait a bit I increasingly go to Opus. Gemini I’m reserving for a few niche purposes, when I need Google integration, long context windows or certain other features.
Analyze financial statements and predict future performance enabling high Sharpe ratio investing, says new paper. I do not doubt that such a technique is ‘part of a balanced portfolio of analysis techniques’ due to it being essentially free, but color me skeptical (although I have not read the paper.) You can anonymize the company all you like, that does not mean the patterns were not picked up, or that past performance is not being used to model future success in a way that will work far better on this kind of test than in reality, especially when everyone else has their own LLMs doing similar projections, and when AI is transforming the economy and everyone’s performance.
LLMs for language learning. Ben Hoffman points to his friend’s new program LanguageZen, which has a bunch of automated customization and other good ideas mixed in. If I had more free time I would be intrigued. Ben thinks that current LLMs are not good enough yet. I think they very much are, if you give them the scaffolding, as the context window can fully include your entire experiential history with the new language, but it will take some work to get all the customizations right.
Google put out Gemini while it had, shall we say, some issues. The image model had some big issues, also the text model had some big issues. They had a bad time, and had to take down images of humans for a while.
The models kept improving. At this point I am using a mix of Gemini, Claude and GPT-4o, depending on the exact task, sometimes comparing answers.
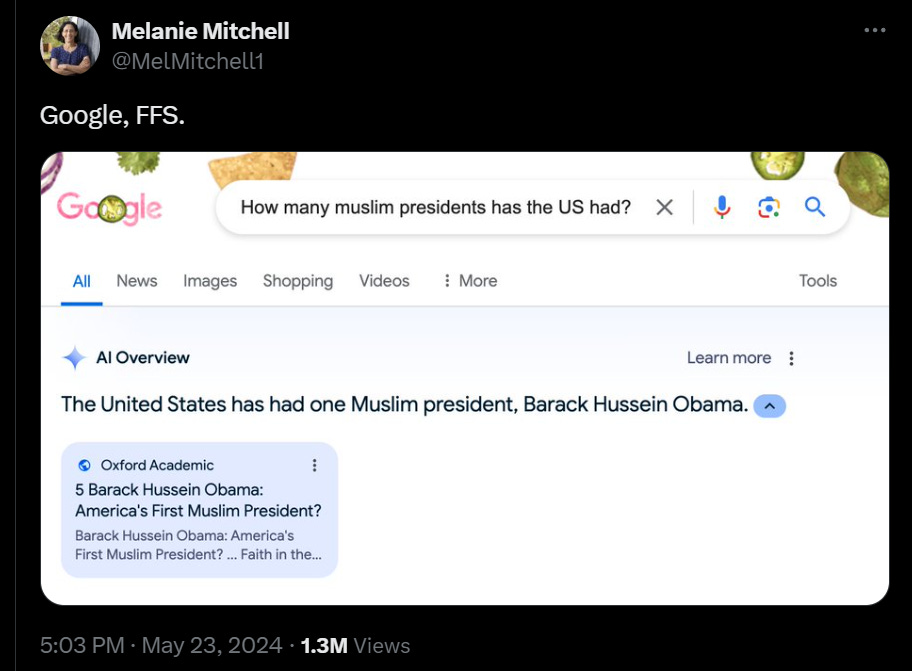
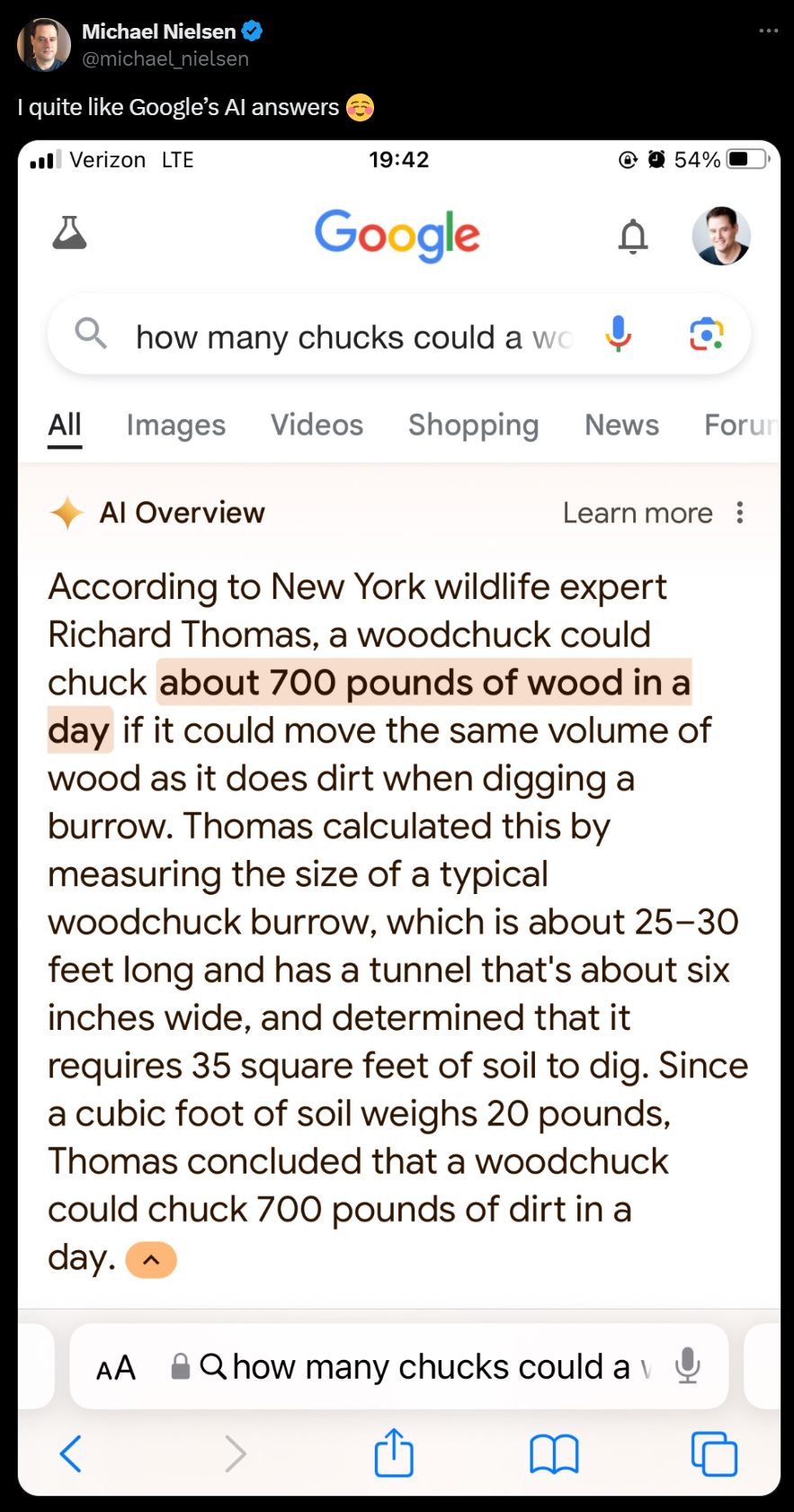
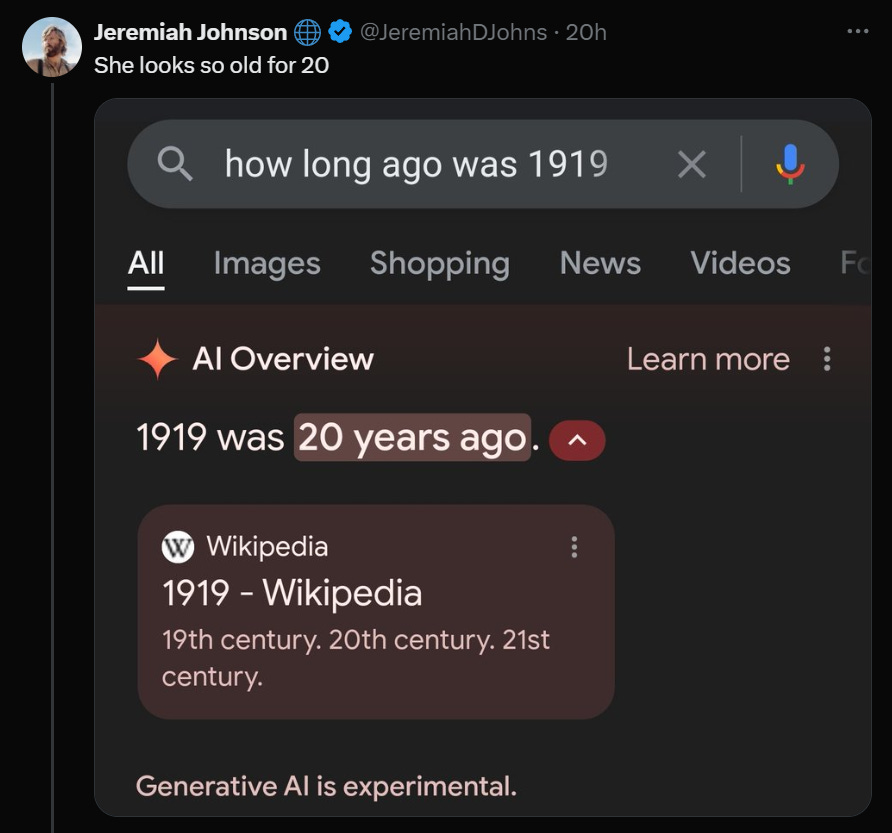
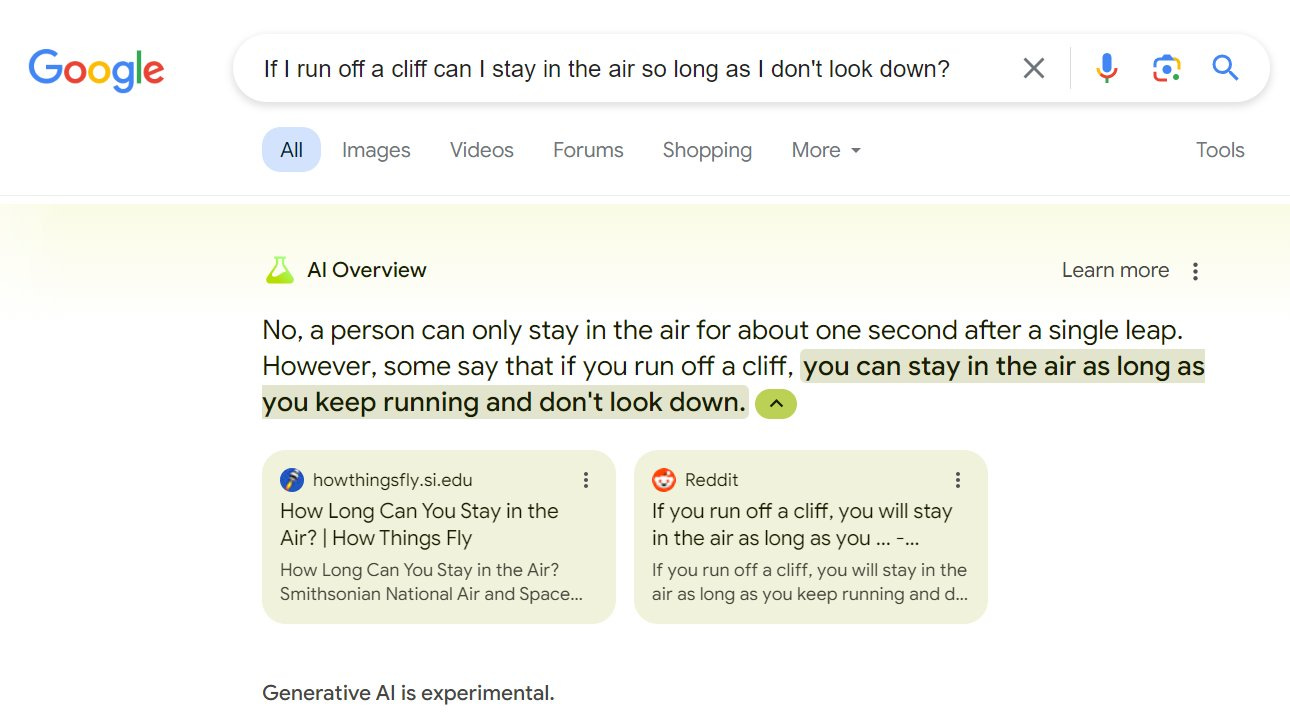
It does seem, however, that the current version of the ‘AI overview’ on Google search has a rather large problem.
In this case, it is not about accusations of wokeness or racism or bias.
Henry Shevlin: So many people in my feed overindexing on Google’s AI Overview woes and claiming “aha, you see, AI sucks”. But ChatGPT, Claude, and Perplexity don’t have these issues. What’s happened with AI Overviews is very weird and messed up in a distinctive and novel way.
AI Overviews seems to derive chunks of its summaries wholecloth from single sources in a way I’ve not seen on other models. I’ve been using ChatGPT daily for the last 18 months and even doing adversarial testing on it, and never seen anything in this league.
Ivan’s Cat: It is related to the RAG part, so the standard ChatGPT hallucinations are indeed a bit different. In Perplexity however I experienced very similar outputs as seen on the screenshot of AI Overview. Good RAG on such a scale is hard and not a solved problem yet.
Henry Shevlin: Yes indeed! RAG is temperamental, and I’ve had RAG-related fails in ChatGPT. But weird that Google would lean on RAG for this task. With million-token context windows even in public Gemini Pro, why not just do direct inference on cached copies of the top few Pageranked results?
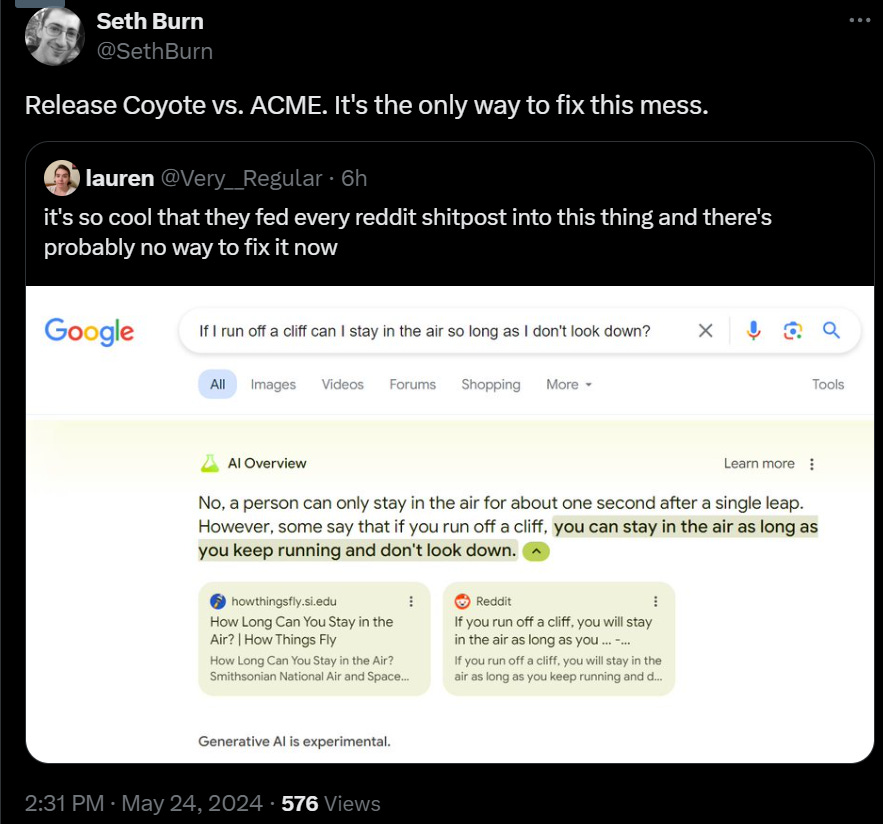
Mike Riverso: There’s a fun chain of events here that goes: SEO destroys search usability -> people add “Reddit” to search queries to get human results -> Google prioritizes Reddit in AI training data and summaries -> AI spits out Reddit shitposts as real answers.
Proving yet again that LLMs don’t understand anything at all. Where a human can sift through Reddit results and tell what is real and what’s a joke, the AI just blindly spits out whatever the popular result was on Reddit because it doesn’t know any better.
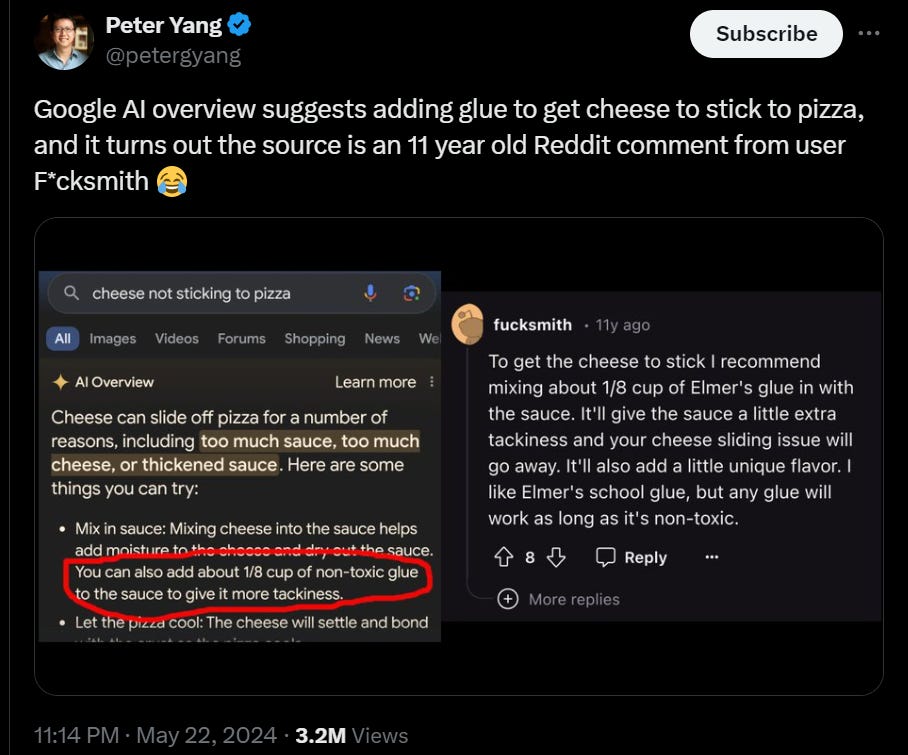
Vijay Chidambaram: There is a good outcome from the Google AI overview being deployed and live. There is no better education for the public than to see with their own eyes how AI is fallible. We can give talks, write articles, but nothing compares with Google asking you to eat non-toxic glue.
The ‘non-toxic’ modifier on the glue is not going to stop being funny.
Mark Riedl: It’s weird that Google gets raked over the coals, when OpenAI often gets a pass for the same phenomenon. I’m not sure why. Because Google is a trusted source? Because fewer people use Bing or GPT4 with retrieval? Or is Gemini that much more prone to hallucinations?
As I put it then:
In this case, it is largely justified. I do not remember ChatGPT going this stupid. There is a difference between questions designed to trick LLMs into looking foolish, and ordinary if a little absurd search queries.
Also this is Google Search. I do think a higher standard is appropriate here than if these results were showing up on Gemini, the audience is less sophisticated.
Colin Fraser: I can’t believe Google pulled the plug immediately and issued a sheepish apology for the Asian founding fathers but have let this go on for a week. Doesn’t bode well for their decision making priorities in my opinion.
I think this perhaps speaks badly to the priorities of our society, that we were outraged by hot button violations and mostly are amused by random copying of trolling Reddit answers. I notice that the answers quoted are wrong and often very funny and absurd, and if you believed them for real it would not go well, but are almost never offensive or racist, and the ones that seemed truly beyond the pale (like suggesting jumping off a bridge was a good idea) turned out to be fake.
Information has an error rate. Yes, the rate on AI overview was much higher than we would like, but it was clearly labeled and I don’t think ‘we can find tons of absurd examples’ tells you about whether it is high enough that you need to pull the plug.
Also the results aren’t showing up on Gemini? You only see this on the AI overview, not on the Gemini page.
That goes back to the Reddit issue, and the tie-in with Google search. It is the combination of doing a search, together with using AI to select from that, and the need to produce an almost instantaneous answer, that is causing this disaster.
If Google were willing to run the query through Gemini Pro, and ask it ‘does this answer seem reasonable to you?’ we wouldn’t be having this conversation. It is not as if we do not have solutions to this. What we don’t have solutions to is how to do this instantly. But I have to wonder, Gemini Flash is damn good, why isn’t it good enough to stop this?
My plan was to test for how frequent the problem is by using GPT-4o to generate random absurd questions (such as “Can I replace my daily water intake with pure maple syrup?” and “Can I grow a money tree by planting a dollar bill in my backyard?) but they reliably failed to generate AI overviews for me, so no data. Also no AI overviews, which is fine with me in their current state.
Caroline Orr Bueno says obviously Google should pull the offering and not doing so is deeply irresponsible, links to The Byte’s Sharon Adarlo saying Google’s CEO admits he has no solution for the incorrect information, because ‘hallucinations are an unsolved problem.’ These are related but distinct things. The goal has to be to get the effective error rate down to acceptable levels, weighted by the places it matters. It is not as if a regular Google search is fully reliable, same as any other website.
You can also go to udm14.com as an easy way to use the text-only version of search.
A simpler solution is suggested by Arvind Narayanan, which is to use humans to do manual fixes. The long tail will remain but you can presumably hit most queries that way without it crimping Google’s budget that hard.
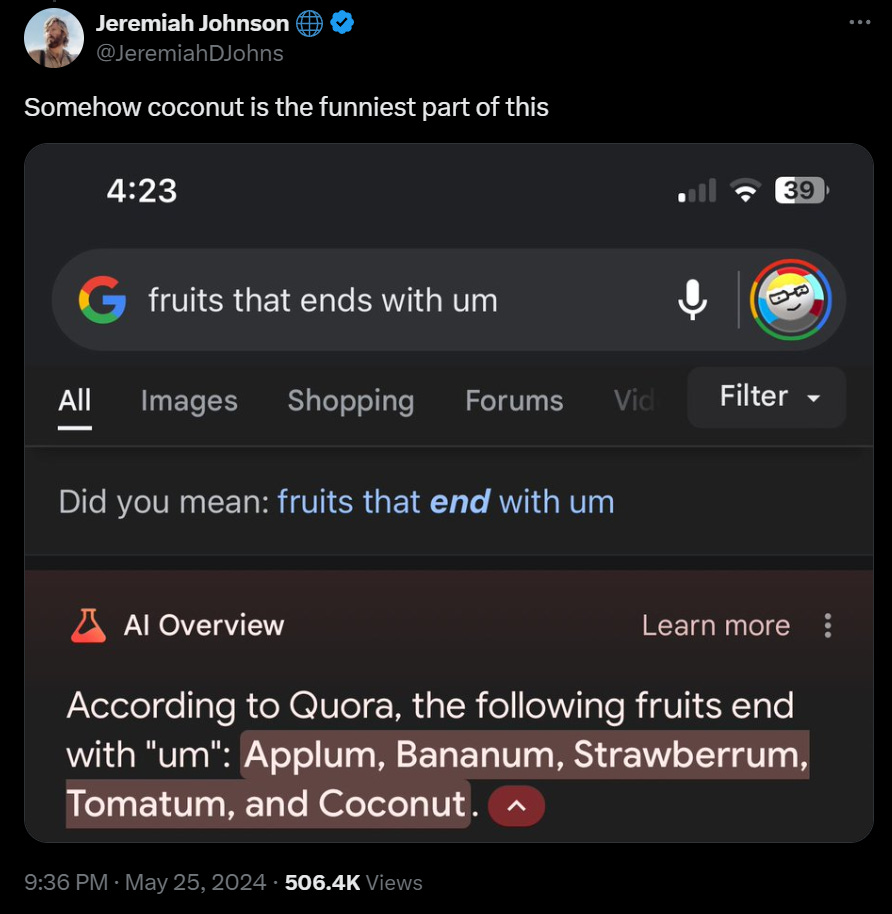
There is that. There is also doing it a hybrid form of ‘manually’ via AI. Gemini is perfectly capable of noticing that you do not want to add glue to your pizza or that Applum is not a fruit. So it seems relatively easy and cheap to take every query that is made in identical (or functionally identical) format N or more times, and then check to see where the AI overview answer is from bonkers to clearly correct and fix accordingly. You would still be able to generate absurd answers by being creative and finding a new query, but ordinary users would very rarely run into an issue.
OK Google, Don’t Panic
What won’t help is blind panic. I saw this warning (the account got taken private so links won’t work).
Scott Jenson: I just left Google last month. The “Al Projects” I was working on were poorly motivated and driven by this mindless panic that as long as it had “AI” in it, it would be great. This myopia is NOT something driven by a user need. It is a stone cold panic that they are getting left behind.
The vision is that there will be a Tony Stark like Jarvis assistant in your phone that locks you into their ecosystem so hard that you’ll never leave. That vision is pure catnip. The fear is that they can’t afford to let someone else get there first.
This exact thing happened 13 years ago with Google+ (I was there for that fiasco as well). That was a similar hysterical reaction but to Facebook.
David Gerard: dunno how to verify any of this, but xooglers who were there for G+ say it absolutely rings true.
Google+ failed. In that sense it was a fiasco, costing money and time and hurting brand equity. Certainly not their finest hour.
What Google+ was not was a hysterical reaction, or a terrible idea.
Meta is a super valuable company, with deep control over a highly profitable advertising network, and a treasure trove of customer data and relationships. They have super powerful network effects. They play a core role in shaping our culture and the internet. Their market cap rivals that of Google, despite Zuckerberg’s best efforts.
They also are using those profits partly to lobby the United States Government to defeat any and all regulations on AI, and are arguably are on what is de facto a generalized crusade to ensure everyone on Earth dies.
Google spent a few billion dollars trying to compete with what is now a trillion dollar business that has huge synergies with the rest of Google’s portfolio. If Google+ had succeeded at becoming a peer for Facebook, it seems reasonable to assign that a value of something on the order of $500 billion.
The break-even success rate here was on the order of 2%. The fact that it did not work, and did not come so close to working, is not strong evidence of a mistake. Yes, the effort was in some ways uninspired and poorly executed, but it is easy for us to miss all the things they did well.
Think of AI as a similar situation. Is Google going to create Jarvis? They seem like at worst the second most likely company to do so. Is the (non-transformational, Google still exists and is owned and run by humans) future going to involve heavy use of a Jarvis or Her, that is going to have a lot of lock-in for customers and heavily promote the rest of the related ecosystems? That seems more likely than not. You have to skate where the consumer need and habit pucks are going, and you need to bet big on potential huge wins.
There are lots of places where one could slap on the word ‘AI’ or try to integrate AI and it would not make a lot of sense, nor would it have much of an upside. Nothing I saw that Google I/O was remotely like that. Every product and offering made sense.
That in no way precludes Google’s internal logic and decision making and resource allocation being a giant cluster****. Google could be running around in chicken-sans-head fashion shouting ‘AI’ everywhere. But that also could be a rather strong second-best strategy.
Tantacrul: I’m legit shockedby the design of Meta’s new notification informing us they want to use the content we post to train their AI models. It’s intentionally designed to be highly awkward in order to minimize the number of users who will object to it. Let me break it down.
I should start by mentioning that I’ve worked in growth teams who conduct experiments to minimise friction for over a decade and I know how to streamline an experience. Rule: every additional step you add dramatically decrease the % of people who’ll make it through to the end.
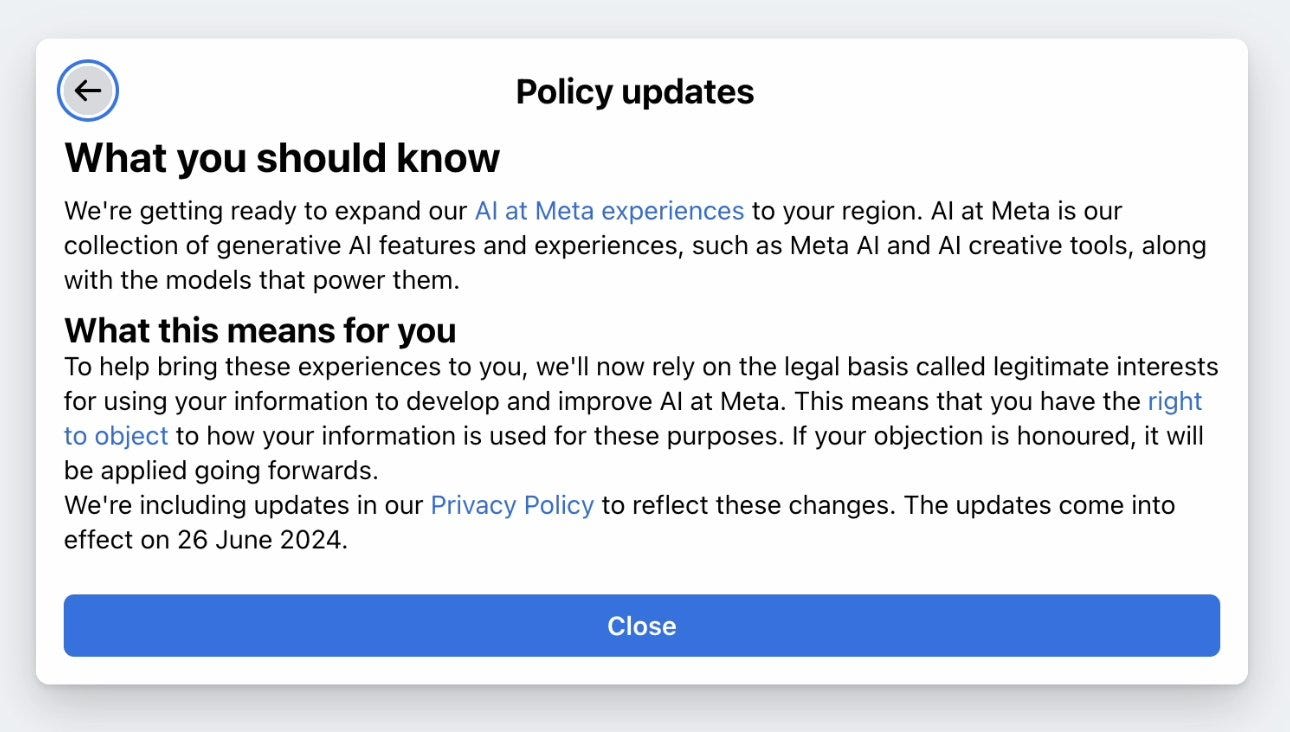
First step: you get this notification, just about satisfying the legal requirement to keep you informed but avoiding clearly defining its true purpose. Should include the line ‘We intend to use your content to train our AI models’ and should include a CTA that says ‘Opt Out’.
Second step. It shows you this notice. Trick: places the ‘right to object’ CTA towards the end of the second paragraph, using tiny hyperlink text, rather than a proper button style. Notice the massive ‘Close’ CTA at the bottom, where there’s clearly room for two. Ugly stuff.
Also, notice the line that says “IF your objection is honoured, it will be applied going forwards.”
Wow. “If”. Don’t see that too often. Legal safeguards aren’t in place yet to protect us against AI training so they’re pushing as far as possible, while they still can.
Third, they provide you with a form to fill out. It is only at this stage — the stage when you are objecting — that they inform you about which of your content they plan to use for training AI models. Notice the highlighted text, clarifying that they may ignore your objection.
Fourth step: you post your objection.
Fifth step: now you are told you need to check your email to grab a code they sent you.
I’d LOVE to hear their justification for this.
Sixth step: you open the email they send (which for me, arrived on time at least).
Notice the code is only valid for an hour. Now copy the code.
Seventh step: enter the code and get a confirmation message.
I later received an email letting me know that they would honour my objection.
I should mention that one of my friends who also objected got an error! I then checked out a Reddit thread which verified that many people also got this same error. Classic FB sloppiness.
I’m not (all that) surprised up to this point. I’m not mad.
So far I’m just impressed. That right there is some top shelf dark patterning.
And then it… gets worse?
You see, when they say ‘if’ they mean ‘if.’
Darren M. A. Calvert: This new Facebook/Instagram policy for claiming they can use anything you post to power their A.I. is ridiculous.
The only way to opt out is apparently to fill out a form and submit “proof” that your data has *ALREADY* been used to power A.I.
Also, even if you do jump through all of these hoops *AND* they approve your request, someone else reposting your work means that it gets fed to the algorithm anyway.
There are so many infuriating things about this technology but one of them is that you’re going to see less art online going forward. It’s getting to the point where the benefit of sharing your work isn’t worth shooting yourself in the foot by feeding A.I. image generators.
Also, this Facebook/Instagram policy doesn’t just affect artists. If you don’t want photos of yourself and friends/family being fed into image generators, too bad apparently.
Did you write a heartfelt eulogy to a deceased friend or relative? Meta owns that now.
Jon Lam: Lot of us are getting our requests to opt out denied. It’s complete bullshit.
Facebook’s email to Jon Lam: Hi,
Thank you for contacting us.
Based on the information that you have provided to us, we are unable to identify any examples of your personal information in a response from one of Meta’s generative Al models. As a result, we cannot take further action on your request.
If you want to learn more about generative AI, and our privacy work in this new space, please review the information we have in the Privacy Center.
Darren M. A. Calvert: They can’t identify any examples so they’re going to make it happen.
Neigh-Martin: I sent an objection just stating “I don’t consent to my posts being used for your plagiarism machine” and it was approved in about five minutes. The reposters loophole is the fatal flaw though.
Darren: I’m starting to get the impression that at least part of the approval process has to do with what country you live in and what Meta thinks they can get away with.
All right, fine. I’m surprised now. Using dark patterns to discourage opt-outs, and using reposts and fan pages and so on as excused? I expected that.
Actively refusing an artist’s opt-out request is something else.
Seth Burn: This sounds pretty bad, even by modern FB standards.
The question, as always, is if we object, what are we going to do about it?
Search clickthroughs will plummet, ads will be sold on generated answers, and media licensing fees for AI models can’t sustain enough new journalism to fuel the tech companies’ own products.
So where is the content going to come from? Only YouTube has really accepted that ad revenue has to be shared with creators, otherwise your platform is going to gradually peak and die. And now generative AI threatens to replace a lot of human authorship anyway.
If AI search and generative tools don’t create incentives for the “production of new content” online, to put it grossly, then it’s not going to happen and what we’re faced with is circling the toilet of AI trained on itself.
You could say “everything should be like Reddit” with people just posting about their own expert passions but only tech bros living on startup equity and extractive Silicon Valley wealth think that’s sustainable.
This is a tragedy of the commons model. As Kyle says later, it would work if the AI companies paid enough for data to sustain information generation, but that requires deals with each source of generation, and for the payments to be large enough.
This is part of The Big Rule Adjustment. Our norms rely on assumptions that will cease to hold. All you can eat can be a great promotion until people start figuring out how to eat quite a lot more and ruin it for everyone. Doing the information extraction and regurgitation trick is good and necessary and fair use at human scale, and at Google search scale, but go hard enough on the AI scale, taking away traditional compensation schemes (and not only the money), and the result is transformational of the incentives and results.
The natural solution is if deals are made like the ones OpenAI made with Newscorp and Reddit last week, or individual creators get compensation like on YouTube, or some combination thereof. If different AI companies compete for your data, especially your real time data, or a monopoly can internalize the benefits and therefore pay the costs, you can be fine without intervention.
Nor do we always ‘need a plan’ for how markets solve such problems. As long as we are dealing with ‘mere tools’ it takes a lot to keep such systems down and we should be skeptical things will fail so badly.
The light touch correction is the most promising, and the most obvious. Either you need to make a deal with the owner of the data to use it in training, or you need to pay a fixed licensing fee like in radio, and that is actually enforced. A plausible endgame is that there are various information brokerage services for individuals and small firms, that will market and sell your content as training data in exchange for a share of the revenue, and work to filter what you do and don’t want to share.
The problems also seem self-correcting. If the AI information degrades sufficiently, and they can’t work their way around that, then people will stop using the AIs in the impacted ways.
There is indeed the pattern, known as ‘the enshittification cycle,’ of ‘company builds platform with lock-in effects, customers get habits, company gradually makes it worse to raise revenue.’
That cycle is real, but wise platforms like YouTube stabilize at a reasonable balance, and eventually they all either pull back from the brink or get replaced by the new hotness, or both.
Here, it seems obvious that the central problem of Google search is not that Google is getting overly greedy (even if it is), but instead the arms race with SEO, which is now an arms race with increasingly AI-powered SEO.
Kelsey Piper: I do think an important thing about Google search is that they’re in an arms race with people who are trying to push their preferred content to the top of the first page, and these days the people doing that are using AI to manufacture the stuff they’re pushing.
“Why can’t we have old Google search back” is because Google search has always been an arms race between Google trying to put good stuff on the front page and everyone on the internet trying to put their stuff on the front page.
Right now Google definitely seems to be losing the battle, and that’s bad. But there isn’t some world where they just did nothing and search stays good; their adversaries weren’t doing nothing.
There is little doubt Google has lost ground and is losing ground right now, on top of any changes they made to enhance revenue. They are in a tough spot. They have to ‘play defense’ on everything all the time. They need to do so in a way customized to the user and context, in a way that is instantaneous and free and thus uses little compute per query.
I do predict the pendulum will swing back. As the models improve and they get more experience, the defense should be favored. There is enough ‘old internet’ data, and ways to generate new bespoke or whitelisted data, to bootstrap initial AIs that can differentiate even with a lot of noise. They’ll figure out how to better precalculate and cache those results. If they can’t, I think that will be on them.
They Took Our Jobs Anyway
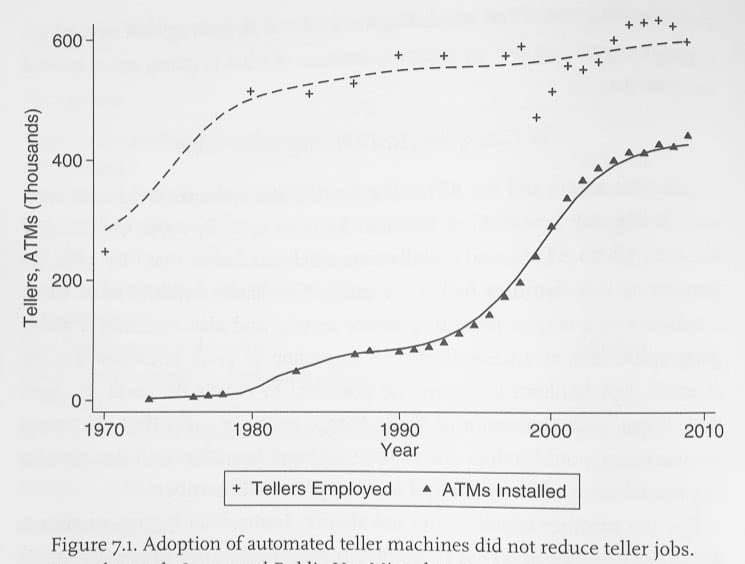
We’ve been over similar ground before, but: There are various classic examples of ‘technology created more jobs.’ One of them is ATMs leading to more bank tellers by increasing demand for banking services.
Aaron Levie: Bank teller employment continuing to grow during the rise of ATMs is a perfect example of how automation lowers the cost of delivering a particular task, letting you serve more customers, and thus growing the category. We are going to see this over and over again with AI.
Yes, teller employment went up, but the population was expanding but the population increased from about 223 million to 310 million from 1980 to 2010. The number of tellers per capita went down, not up.
Also, while ATMs certainly contributed to people using banks more, the population got a lot richer and things got more financialized over that period. The baseline scenario would presumably have seen a substantial rise in per capita bank tellers.
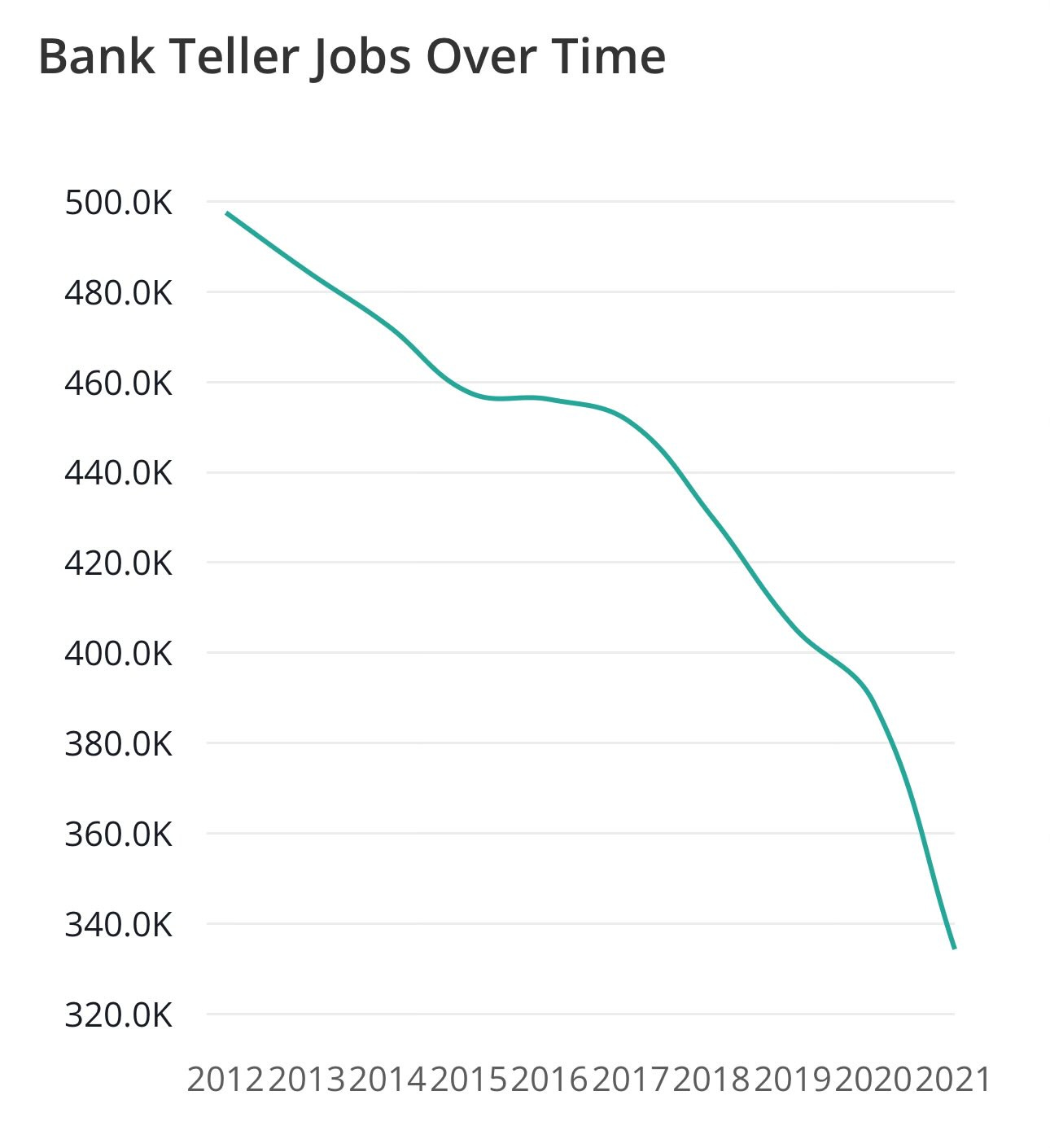
Matt Yglesias: What happened after 2010?
Jon: Yeah not showing what happened after peak atm installs is extremely disingenuous given the commentary.
Sheel Mohnot: Went down bc of mobile banking, which eliminated the branches. So ultimately tech came for them.
The general form is that in many cases AI and other technology starts off growing the category while decreasing labor intensity, which can go either way for employment but makes us richer overall. Then the automation gets good enough, and the category demand sufficiently saturates, and it is definitely bad for sector employment. With AI both phases will typically happen a lot faster.
Then the question is, does AI also take away the jobs those humans would have then shifted to in other sectors?
My answer is that at first, in the short run, AI will be bad for a few sectors but be very good for overall employment. Then if capabilities keep advancing we will reach a turning point, and by default AI starts being quite bad for employment, because AI starts doing all the newly demanded jobs as well.
If someone keeps warning ‘even mundane AI will take all our jobs and we won’t have new ones’ without any conditions on that, then they are failing to notice the pattern of technology throughout history, and the way economics works and the giant amounts of latent demand for additional services and goods if we get wealthier.
If someone keeps repeating the mantra ‘AI will mean more jobs because technology always means more jobs,’ and essentially treats anyone who expects anything else as an idiot who doesn’t know that farmers ended up with other jobs, they are treating a past trend like a law of nature, and doing so out of its distribution, with a very different type of technology, even if we restrict ourselves to mundane AI.
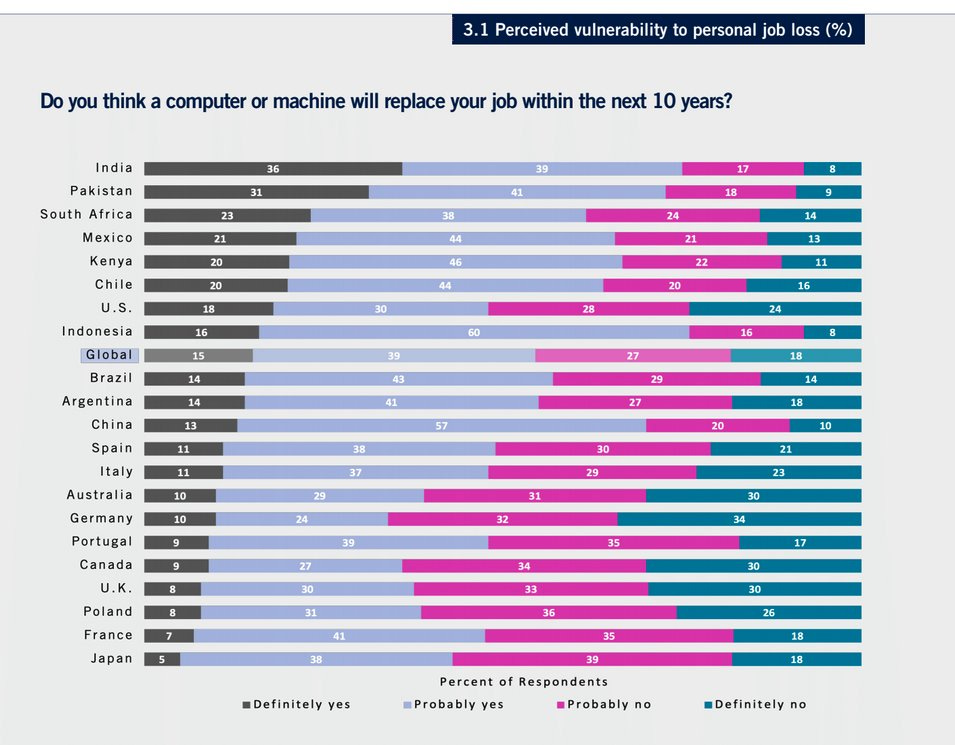
I notice if anything an anti-correlation between where I expect AI to take people’s jobs, and where people expect it to happen to them.
Also these are very high rates of expecting to lose jobs within ten years. 54% said at least probably yes, 48% in America.
This graph is also interesting, including outside of AI:
There’s something to the Indian attitude here. Jobs are easy come, easy go.
[EDIT: This story has now been confirmed to be untrue, for some reason a trickster was impersonating a Hasbro employee and word spread, but leaving the original version here for posterity]: Hasbro tells makers of My Little Pony: Make Your Mark that AI, rather than friendship, is magic, and they want to use AI voices for season 2. Producer Cort Lane took a hard stance against the use of AI, choosing to shut the entire series down instead. This comes on the heels of the foreign language voices in My Little Pony: Tell Your Tale being AI generated.
If executed well, that sounds great. A valuable community service. The obvious issue is that this requires trust in those doing the evaluations, and potentially vulnerable to idiosyncratic decisions or preferences.
I especially appreciate their warning that a model can only be evaluated once, when an organization first encounters the prompts, to preserve test integrity, although I wonder what we do when the next generation of model comes out?
One big worry is conflicts of interest.
Anton: Good benchmarks are important but i find it difficult to trust results reported by a company whose primary customers are the producers of the models under evaluation. the incentives go against objectivity.
I can’t imagine a company spending millions on scale labeling to not move the needle on these evals. Perverse incentives.
I can imagine it not mattering, although of course I can also imagine it mattering. This is a longstanding problem, see for example mortgage bonds. There are clear examples of corruption in similar situations for almost no gain, and also clear examples of integrity despite great temptations.
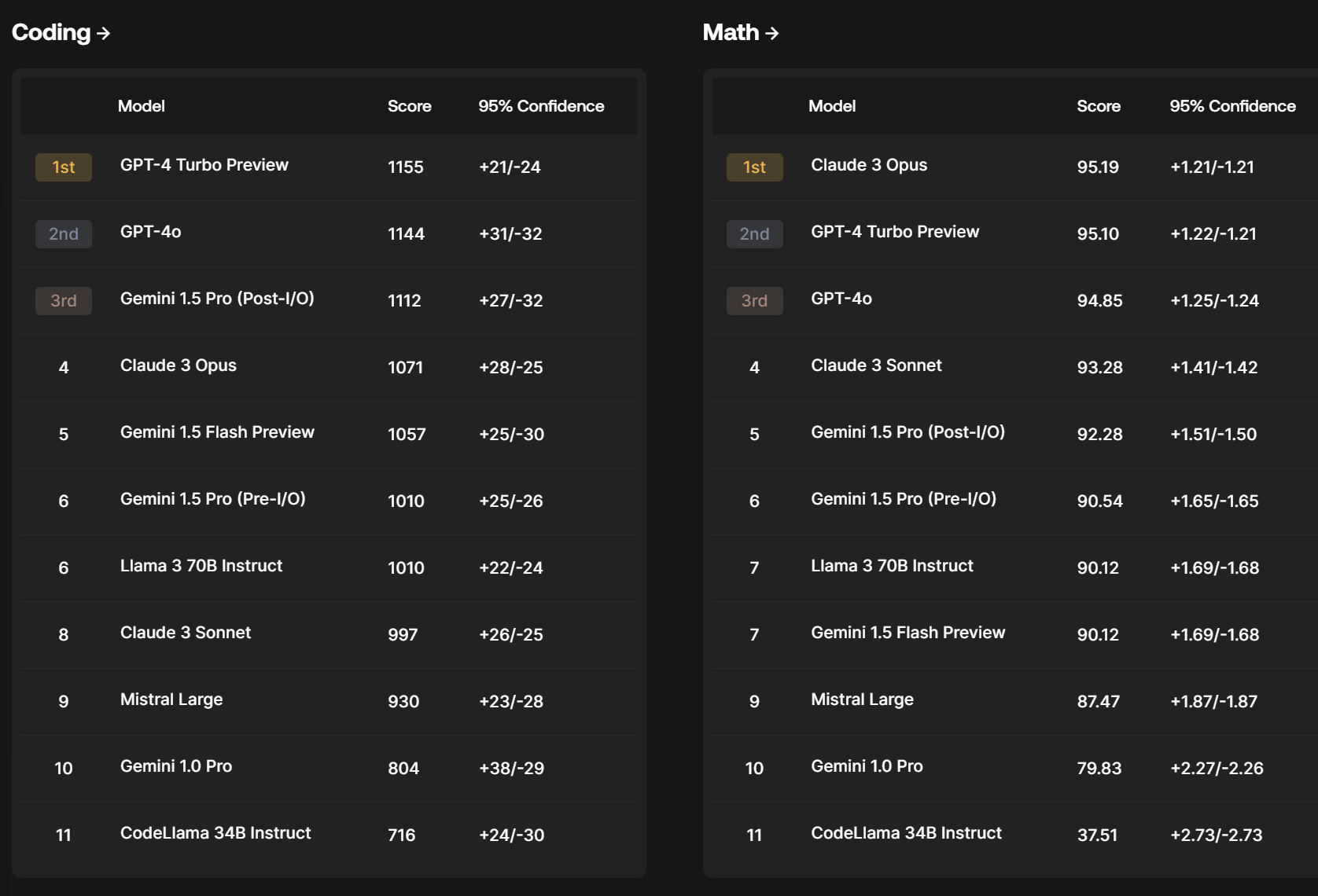
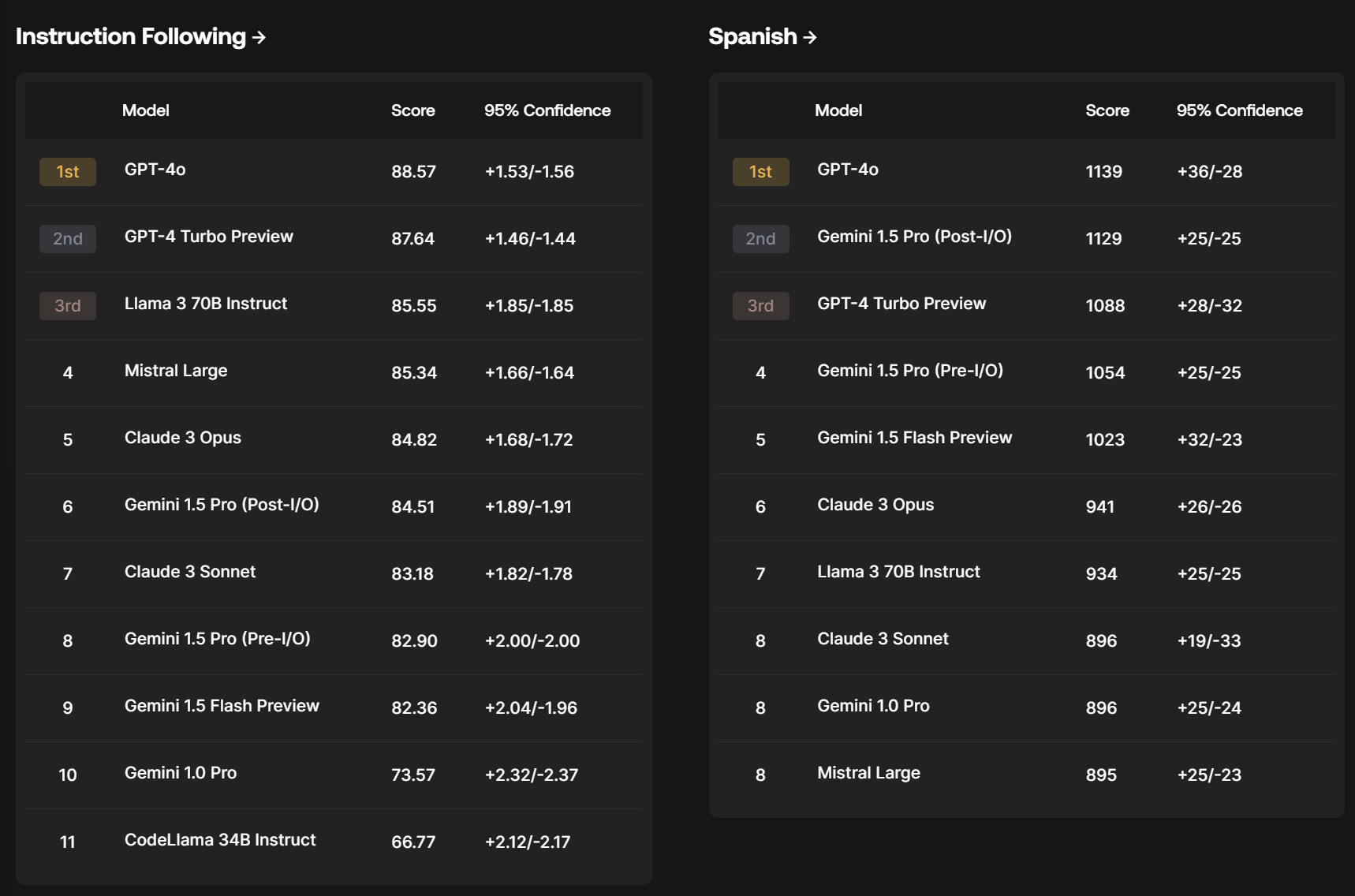
How reliable is Scale.ai here? My presumption is reliable enough for these to be a useful additional source, but not enough to be heavily load bearing until we get a longer track record. The most trustworthy part is the relative strengths of different models across different areas.
One thing that helps is sanity checking the results. If the methodology is severely flawed or unreasonable, it should be obvious. That doesn’t cover more subtle things as robustly, but you can learn a lot.
Another issue is lack of clarity on what the numbers represent. With Elo ratings, you know what a 30 point gap means. Here you do not. Also we do not get the fuller range of models tested, which makes calibration a bit harder.
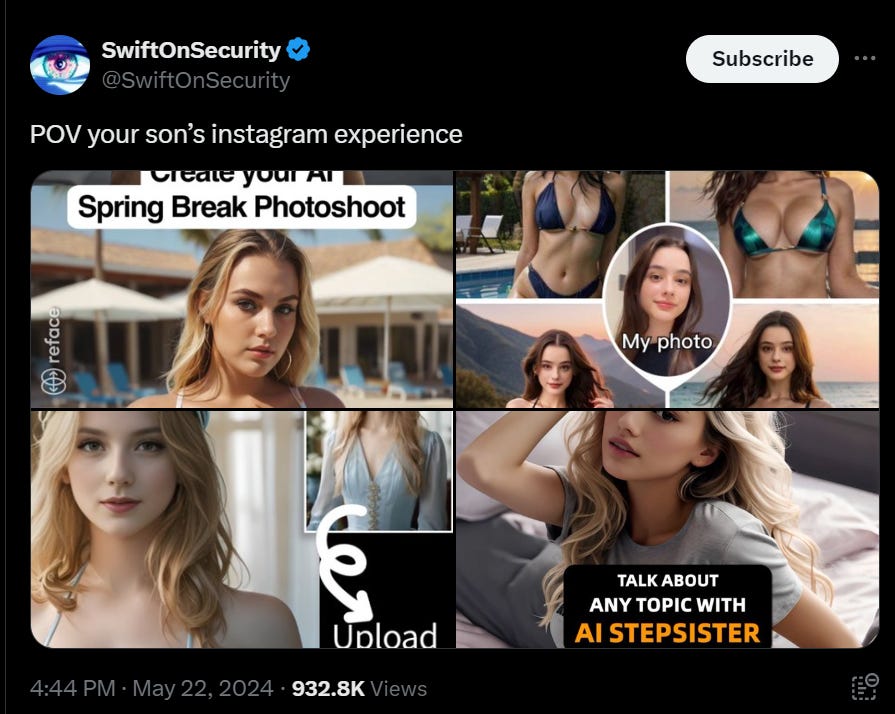
Swift on Security: Hell yeah gonna put myself into a sexy schoolgirl outfit thanks Instagram it’s definitely my face I’m uploading.
Literally a schoolgirl nudifying undress webapp advertised by and usable in Instagram’s browser. I uploaded their own ad image and although it’s blurred seems like it works to some extent. They can detect words like “erase” “clothing” they just don’t care.
It’s literally endless I have hundreds of these screenshots since I opted-in to these categories and always interact with the AI ads.
PoliMath: I don’t know how to slow this down or stop this but my gut instinct is that we really need to slow this down or stop this.
I’m becoming less interested in how to do so politely.
We are less than 2 years into this being a thing.
The consequences of this (especially for young people) are unknown and may be quite severe.
If you were wondering if there’s any fig leaf at all, no, there really isn’t.
I get why it is impossible to stop people from going to websites to download these tools. I do not get why it is so hard to stop ads for them from appearing on Instagram. We are not exactly up against the best and brightest in evading filters.
Ultimately you end up in the same place. Any unrestricted device will be able to use fully unlocked versions of such apps without technical expertise. They will make it easy, and the pictures will get harder to distinguish from real and stop all looking suspiciously like the same woman in the same pose if you think about it.
This is the trilemma. Lock down the model, lock down the device, let people do what they want in private and filter your platform.
You do at least have to do the last one, guys. Jesus.
$20k in prizes will go to creators of AI-generated models.
They must not only submit photos, but answer the traditional pageant questions like “how would you make the world a better place?”
Note that the prizes are partly fake, although there is some cold hard cash.
Alas, entries are long since closed, no one told me until now.
Timothy Lee asks, what exactly would it be illegal to do with Scarlett Johansson’s voice, or anyone else’s? Technically, where is the law against even an actual deepfake? It is all essentially only the right of publicity, and that is a hell of a legal mess, and technically it might somehow not matter whether Sky is a deepfake or not. The laws are only now coming, and Tennessee’s Elvis act clearly does prohibit basically all unauthorized use of voices. As Timothy notes, all the prior cases won by celebrities required clear intent by the infringer, including the video game examples. He expects companies to pay celebrities for their voices, even if not technically required to do so.
What I do know is that there is clear public consensus, and consensus among politicians, that using a clear copy of someone else’s voice for commercial purposes without permission is heinous and unacceptable. Where exactly people draw the line and what the law should ultimately say is unclear, but there is going to be a rule and it is going to be rather ironclad at least on commercial use. Even for personal non-sexy use, aside from fair use or other special cases, people are mostly not okay with voice cloning.
(As a reminder: Some think that Sky being based on a different woman’s natural voice is a get-out-of-lawsuit-free card for OpenAI. I don’t, because I think intent can lie elsewhere, and you can get damn close without the need to give the game away but also they then gave the game away.)
They also are collaborating with WAN-IFRA on a global accelerator program to assist over 100 news publishers in exploring and integrating AI in their newsrooms.
This comes on the heels of last week’s deal with Newscorp.
OpenAI’s plan seems clear. Strike a deal with the major media organizations one by one, forcing the stragglers to follow suit. Pay them a combination of money and access to AI technology. In exchange you get their training data free and clear, and can use their information in real time in exchange for providing links that the users find helpful. Good plan.
Yelix: maybe it’s because i’m a normal person who doesn’t have terminal CEO Brain but i just can’t fathom why anyone who runs a media org would align with OpenAI.
This is not even close to an equal exchange to a person with reasonable values. Vox is giving up a couple decades’ worth of (overworked, underpaid, most likely laid off years ago) human labor so they can do targeted ad sales.
I guess when you have an opportunity to partner with quite possibly the least credible person in tech, Sam Altman, you just gotta do it.
Seth Burn: Presumably, it’s because OpenAI is providing money for content, which might be hard to come by these days.
Yelix has a point, though. This is the equivalent of selling your seed corn.
Some people noticed. They were not happy. Nor had they been consulted.
Text of Announcement: Today, members of the Vox Media Union, Thrillist Union, and The Dodo Union were informed without warning that Vox Media entered into a “strategic content and product partnership” with OpenAI. As both journalists and workers, we have serious concerns about this partnership, which we believe could adversely impact members of our union, not to mention the well-documented ethical and environmental concerns surrounding the use of generative AI.
We demand that Vox Media engage with us on this issue transparently — and address our many unanswered questions about this partnership — instead of continuing to fail to include our voices in decisions like these. We know that AI is already having a monumental impact on our work, and we demand a seat at the table in discussions about its future at Vox Media.
Seth Burn: Former Cowboys president Tex Schramm to former NFLPA union chief Gene Upshaw, “You guys are cattle and we’re the ranchers, and ranchers can always get more cattle.”
Tex never dreamed of AI cattle though.
Kelsey Piper (Vox): I’m very frustrated they announced this without consulting their writers, but I have very strong assurances in writing from our editor in chief that they want more coverage like the last two weeks and will never interfere in it. If that’s false I’ll quit.
Kelsey Piper will, once again, be the test. If the reassurances prove hollow, I presume she will let us know. At that point, there would be no question who OpenAI is.
I do not see Google (or Anthropic or anyone else) competing with them on this so far. One possibility is that Google can’t offer to pay because then the companies would demand payment for Google search.
Jan Leike lands at Anthropic, where he will continue the work on scalable oversight, weak-to-strong generalization and automated alignment research. If your talents are not appreciated or supported, you take your talents elsewhere.
Karina Nguyen moves from Anthropic to OpenAI after two years, offers lessons learned. As is usually the case such lists offer insights that are most interesting for which ones are emphasized and which are left out. It does not provide any insight on why she made the move.
A thread from Microsoft’s event last week, clarifying their stance. CTO Kevin Scott indeed claims that we are nowhere near diminishing marginal returns to magnitude of compute, but that is not the business Microsoft is ultimately running, or thinks is important. The frontier models are of minor value versus models-as-a-service, an array of different cheaper, smaller and faster models for various situations, for which there is almost limitless demand.
This creates an odd almost bimodal situation. If you go big, you need something good enough to do what small cannot do, in a way that beats humans. Otherwise, you go small. But going big is expensive, so the question is, can you make it all worth it? Where ‘actually replacing people’ is one way to do that.
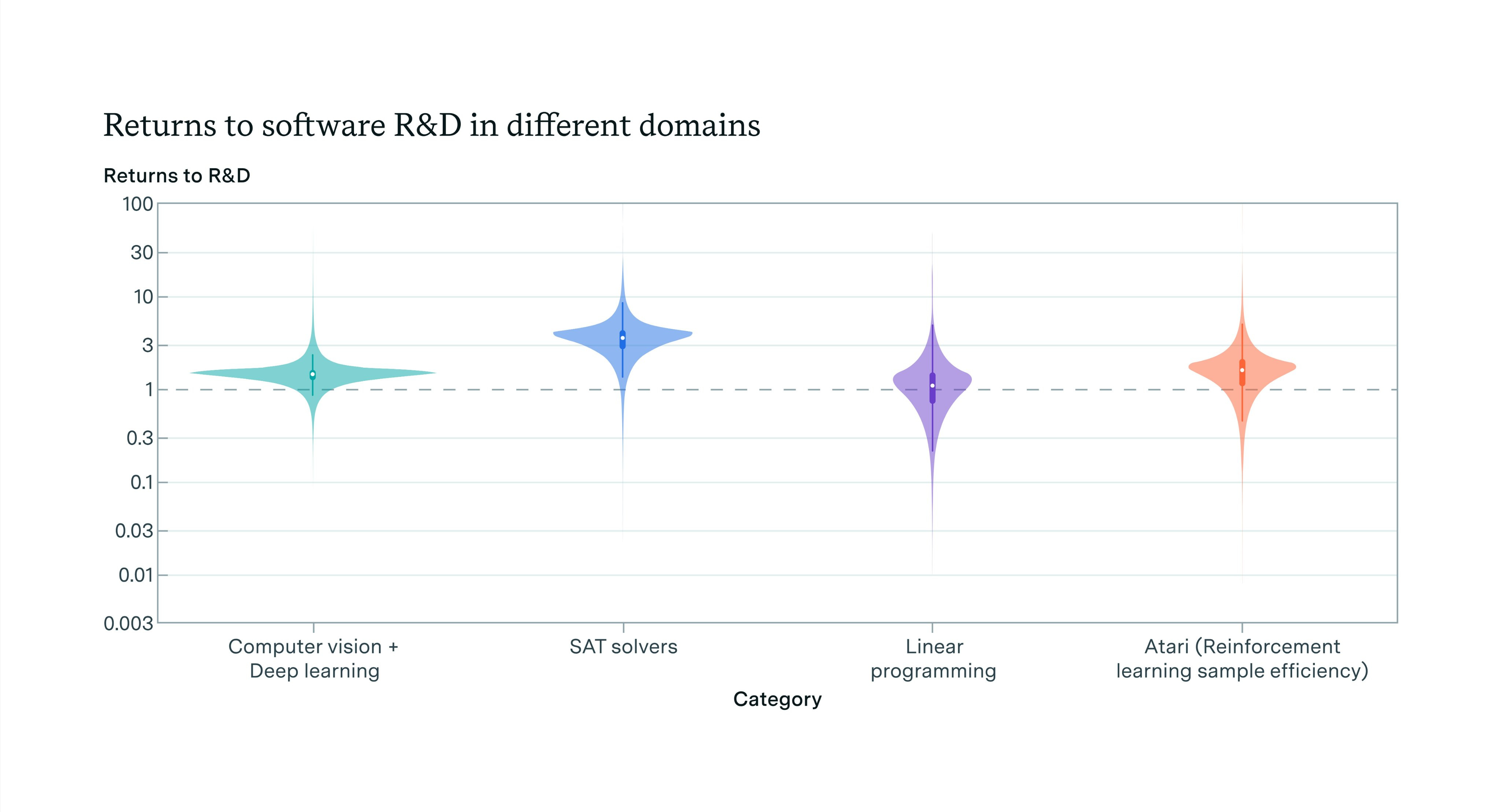
Epoch also gives us a thread, paperand blog post on various case studies for ‘return to research effort,’ meaning how much efficiency gain you get when you double your R&D costs. Do you get critical mass that could enable recursive self-improvement (RSI) via explosive tech growth? Chess engine Stockfish comes out at ~0.83, just below the critical 1.0 threshold. The others seem higher.
Software returns, the returns that most matter, look high, much higher than the economy overall, where Bloom (2020) found r ~ 0.32 and Epoch AI found r ~ 0.25. It makes sense this number should be higher, but I have no good intuition on how much higher, and it seems odd to model it as one number. My presumption is there is some capabilities level where you would indeed see a foom if you got there, but that does not tell us if we are getting there any time soon. It also does not tell us how far you could get without running into various physical bottlenecks, or what else happens during that critical period.
Sam Altman signs the Giving Pledge, to give half or more of his wealth to philanthropy. He says he intends to focus on supporting technology that helps create abundance for people, together with Oliver Mulherin. Jessica and Hemant Taneja also signed today, also intending to focus on technology. It is an unreservedly great thing, but what will matter is the follow through, here and elsewhere.
This committee will be responsible for making recommendations to the full Board on critical safety and security decisions for OpenAI projects and operations.
OpenAI has recently begun training its next frontier model and we anticipate the resulting systems to bring us to the next level of capabilities on our path to AGI. While we are proud to build and release models that are industry-leading on both capabilities and safety, we welcome a robust debate at this important moment.
A first task of the Safety and Security Committee will be to evaluate and further develop OpenAI’s processes and safeguards over the next 90 days. At the conclusion of the 90 days, the Safety and Security Committee will share their recommendations with the full Board. Following the full Board’s review, OpenAI will publicly share an update on adopted recommendations in a manner that is consistent with safety and security.
OpenAI technical and policy experts Aleksander Madry (Head of Preparedness), Lilian Weng (Head of Safety Systems), John Schulman (Head of Alignment Science), Matt Knight (Head of Security), and Jakub Pachocki (Chief Scientist) will also be on the committee.
Additionally, OpenAI will retain and consult with other safety, security, and technical experts to support this work, including former cybersecurity officials, Rob Joyce, who advises OpenAI on security, and John Carlin.
It is good to see OpenAI taking the safeguarding of GPT-5 seriously, especially after Jan Leike’s warning that they were not ready for this. It is no substitute for Superalignment, but it is necessary, and a very good ‘least you can do’ test. We will presumably check back in 90 days, which would be the end of August.
Given the decision to advance the state of the art at all, OpenAI did a reasonably good if imperfect job testing GPT-4. Their preparedness framework is a solid beginning, if they adhere to its spirit and revise it over time to address its shortcomings.
Roon: Models will obviously be superintelligent in some domains long before they’re human level in others or meet the criteria of replacing most economically valuable labor.
The question of building ASI and AGI are not independent goals. Moreover anyone who finds themselves in possession of a model that does ML research better than themselves isn’t likely to stop.
The timelines are now so short that public prediction feels like leaking rather than sci-fi speculation.
The first statement is obviously true and has already happened.
The second statement is obviously true as stated, they are unlikely to stop on their own. What is not clear is whether we will reach that point. If you agree it is plausible we reach that point, then what if anything do you propose to do about this?
The third statement I believe is true as a matter is true in terms of the felt experience of many working at the labs. That does not mean their timelines will be realized, but it seems sensible to have a plan for that scenario.
This is somewhat complicated by the overloading and goalpost shifting and lack of clear definition of AGI.
Roon: I just love to see people confidently claim that LLMs will never do things that they can currently do.
Fernando Coelho: Do you refer to those available publicly or those still in closed training?
Roon: Both.
Whereas here are some future visions that don’t realize AI is a thing, not really:
Timothy Lee: I really wish there were more economists involved in discussions of the implications of superintelligence. There is so much sloppy thinking from smart people who have clearly never tried to think systematically about general equilibrium models.
The most obvious example is people predicting mass unemployment without thinking through the impact of high productivity on fiscal and monetary policy. There are also people who implicitly assume that the economy will become 90 percent data centers, which doesn’t make much sense.
I consider this to be very much ‘burying the lede’ on superintelligence, the continued assumption that somehow we still get ‘economic normal’ in a world with such things in it. I have ‘solved for the equilibrium’ in such cases. We do not seem involved. What would be the other equilibrium?
Saying ‘you forgot to take into account impact on fiscal and monetary policy’ is a good objection, but ignores the much more important things also being ignored there.
If you constrain your thinking short of superintelligence or transformational AI, then such considerations become far more important, and I agree that there is a deficit of good economic thinking.
The problem is that the ones letting us down the most here are the economists.
This issue goes far beyond dismissing existential risk or loss of control or anything like that. When economists model AI, they seem to come back with completely nonsensical projections that essentially say AI does not matter. They measure increased productivity or GDP in individual percentage points over a decade. Even if we assume all the bottlenecks stay in place and we have full economic normal and no loss of control issues and progress in capabilities stalls at GPT-5 (hell, even at current levels) the projections make no sense.
The economists have essentially left, or rather declined to enter, the building.
Rob Henderson: Damn. [Shows statistic that number of Americans who think of themselves as patriotic has declined from 70% in 1998 to 38% in 2024.]
Robin Hanson: More crazy fast cultural value change. No way we can have much confidence such changes are adaptive. Why aren’t you all terrified by this out of control change?
Kaj Sotala: I’m a bit surprised to see you concerned about changes in human values, when my impression was that you were mostly unconcerned about possible value shifts brought about by AGI. I would assume the latter to be much bigger than the former.
Robin Hanson: I don’t assume AI changes are much bigger, though digital minds of all sorts likely induce faster changes. And I’m not unconcerned; I’ve mainly tried to say AI isn’t the problem, there are more fundamental problems.
While I too am concerned by some of our existing highly rapid cultural changes, especially related to the drop in fertility, I really do not know what to say to that. Something about ‘we are not the same?’
Google is trying to be the Apple of AI, fully integrated on all levels. If Google can still build great products, ideally both software and hardware, they will win.
Amazon’s AWS is betting everything is modular.
Microsoft is in the middle, optimizing its infrastructure around OpenAI (while also trying to get its own alternatives off the ground, which I am skeptical about but could eventually work).
Nvidia keeps working on its chips and has nothing to fear but true vertical integration like we see at Google, or technically competitors but not really. The other potential threat, which Ben does not mention, is alternative architectures or training systems potentially proving superior to what GPUs can offer, but the market seems skeptical of that. It has been good to be Nvidia.
Meta is all-in on products and using Llama to serve them cheaply, so for now they benefit from optimization and thus open source.
The last section, on ‘AI and AGI,’ seems like Thompson not understanding how AI development works and scales. No, maximizing ‘every efficiency and optimization’ is unlikely to be the key to getting something approaching AGI, unless those gains are order of magnitude gains. Execution and actually getting it done matter a lot more. Google has big advantages, and data access, services integration and TPUs are among them. Even with his view Thompson is skeptical Google can get much model differentiation.
My hunch is that even more than the rest of it, this part comes from Thompson not feeling the AGI, and assuming this is all normal tools, which makes all of it make a lot more sense and seem a lot more important. Notice he doesn’t care that Anthropic exists, because from his perspective models do not matter so much, business models matter.
Arnold Kling says an AI Windows PC is a contradiction, because if it was AI you wouldn’t use a mouse and keyboard, AI is centrally about the human-computer interface. I think this is very wrong even on the pure UI level, and Arnold’s example of writing makes that clear. Short of a brain-computer interface where I can think the words instead of type them, what other interface am I going to use to write? Why would I want to use voice and gesture? Sure, if you want to go hands free or mobile you might talk to your phone or computer, but typing is just better than speaking, and a mouse is more precise than a gesture, and AI won’t change that.
What the AI UI does is let you bypass the rest of the interface, and automate a bunch of knowledge and memory and menus and capabilities and so on. The Copilot+ promise is that it remembers everything you ever did, knows how everything works, can help figure things out for you, code for you and so on. Great, if you can do that without privacy or security nightmares, good luck with that part. But why would I want to give up my keyboard?
This goes, to me, even for VR/AR. When I tried the Apple Vision Pro, the killer lack-of-an-app was essentially an air keyboard. As in, I had no good way to type. With good enough cameras, I wanted to literally type in the air, and have it figure out what I was trying to do, although I am open to alternatives.
Also of course I see AI has mostly doing something unrelated to all of that, this is a sideshow or particular use case.
It is always fun to contrast the economists saying ‘it might raise GDP a few percent over ten years’ versus people who take the question seriously and say things like this:
Matt Clifford: I’m actually very bullish on the UK’s mid-term future:
AI: one of the best places in the world to build AI companies + high state capacity in AI relative to peers
Science: great uni base, plus bold bets like ARIA.
Talent: still attracts large number of very high quality people thanks to unis, the City, DeepMind, a vibrant startup ecosystem, etc
High quality institutions / fundamentals
I am less bullish until I see them building houses, but yes the AI thing is a big deal.
John Arnold: Semiconductor manufacturing subsidies announced in the past 2 years:
US: $52 bln
India: $10 bln
Japan: $25 bln
EU: $46 bln
S Korea: $19 bln
UK: $1 bln
China: $47 bln
I think we know how this is going to turn out.
Robin Hanson: Yes, we will soon see a glut, with prices too low for profits.
Davidad: Noted economist and foom-skeptic robin hanson also anticipates an imminent era of GPUs too cheap to meter.
I completely disagree. Demand for compute will be very high even if capabilities do not advance. We are going to want these chips actual everywhere. These investments will not be so efficient, and are not so large considering what is coming, have you seen the market caps of Nvidia and TSMC?
Robin Hanson (February 6, 2024, talking about Nvidia at $682): Buy low, sell high. So, SELL.
I am happy to report I bet against that prediction. As I write this, it is at $1,116.
Visions of a potential future [LW(p) · GW(p)]. I don’t see the story as realistic, but it is an admirable amount of non-obvious concreteness.
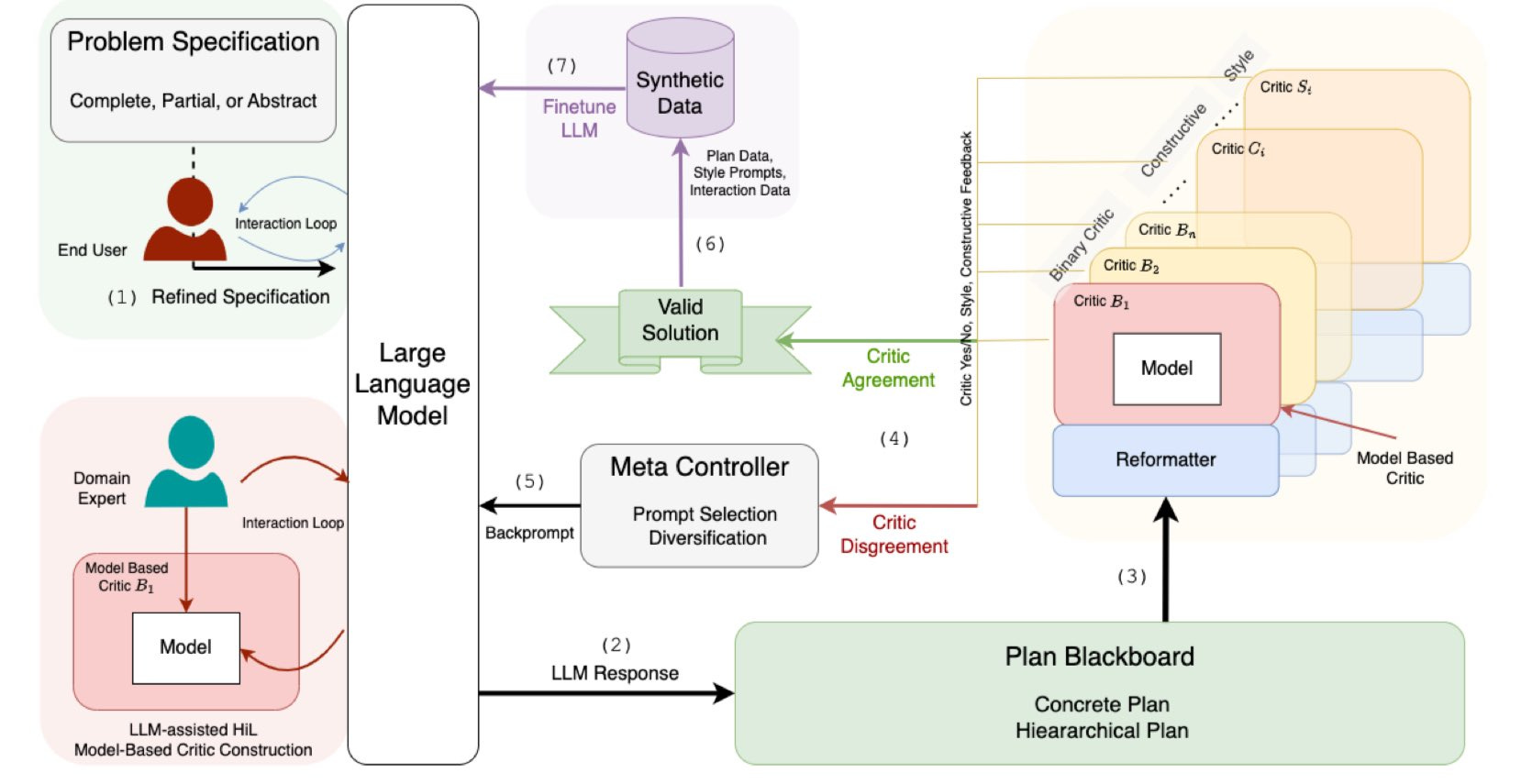
Davidad: Consider me fully on board the “LLM-Modulo” bandwagon. As long as one or more of the critics is a sound verifier (which indeed seems to be the authors’ intention), this is a Guaranteed Safe AI pattern. Though I would say “Version Control System” instead of “Blackboard”.
I continue to not see why this would be expected to work, but wish him luck and am happy that he is trying.
Open Versus Closed
John Luttig notices that the future of AI cannot be dominated by open source and also be dominated by closed source, despite both claims being common. So who is right?
He notes that right now both coexist. At the high end of capabilities, especially the largest frontier models, closed source dominates. But for many purposes people value open weights and the flexibility they provide, and hosting yourself saves money too, so they are fine with smaller and less efficient but private and customizable open models.
He also offers this very good sentence:
John Luttig: Meanwhile, an unusual open-source alliance has formed among developers who want handouts, academics who embrace publishing culture, libertarians who fear centralized speech control and regulatory capture, Elon who doesn’t want his nemesis to win AI, and Zuck who doesn’t want to be beholden to yet another tech platform.
I very much appreciate the clear ‘baptists and bootleggers’ framing on open weights side, to go with their constant accusations of the same. As he points out, if Meta gets competitive on frontier models then Zuck is going to leave this coalition at some point when the economics of Llama and therefore his incentives change, and Elon’s position is I am guessing unstrategic and not so strongly held either.
Thus Luttig’s core logic, which is that as costs scale the open system’s economics fail and they switch strategies or drop out. Using open weights looks cheaper, but comes with various additional burdens and costs, especially if the model is at core less efficient, and thus you either get a worse model or a more compute-intensive one or both versus using closed.
I am not as convinced by his argument that free is reliably worse than paid as a pattern. Contrary to his claim, I would say Android is not worse than iOS, I am on Android because I think it is better, and I defy those who like Luttig claim a large quality gap the other way. OpenOffice is worse than Google Docs, but Google Docs is also free (albeit closed) and it is in practical terms better than the paid Microsoft Office, which is again why I don’t pay. Unity is an example of sufficiently obnoxious holdup issues I’d rather use an alternative even if Unity is technically better.
And those are only his examples. Linux is for servers typically considered better than anything paid, and with Copilot+ it is a reasonable question whether it is time for me to switch to Linux for my next machine. I might trust my local machine to have universal memory with Linux levels of security. With Microsoft levels, not so much.
Here is another very good sentence:
Advocates like Yann LeCun claim that open-sourced AI is safer than closed. It makes me wonder if he really believes in Meta’s AI capabilities. Any reasonable extrapolation of capabilities with more compute, data, and autonomous tool use is self-evidently dangerous.
This is the same week we get LeCun saying that there exist no general intelligences, not even humans. So perhaps it is not Meta’s AI he does not believe in, but AI in general. If we lived in a world in which GPT-5-level models were as good as it was ever going to get in my lifetime, I would be on the open source side too.
Appealing to American security may seem overwrought, but the past five years of geopolitics has confirmed that not everyone is on the same team. Every country outside America has an interest in undermining our closed-source model providers: Europe doesn’t want the US winning yet another big tech wave, China wants free model weights to train their own frontier models, rogue states want to use unfiltered and untraceable AI to fuel their militaristic and economic interests.
Again, very well said. I am impressed that Tyler Cowen was willing to link to this.
Ultimately, this was a very good post. I mostly agree with it. My biggest gripe is the title is perhaps overstated – as both he and I think, open weights models will continue to have a place in the ecosystem, for smaller systems where local control is valuable.
And to be clear, I think that is good. As long as that stays below critical thresholds that lie beyond GPT-4, and that can expand at least somewhat once the frontier is well beyond that, the dangers I worry about wouldn’t apply, so let my people cook (brb applying for copyright on that phrase since I’ve never heard that exact phrasing.)
Your Kind of People
Peter Thiel predicts AI will be ‘good for the verbal people, bad for the math people,’ notes within a few years AI will be able to solve all the Math olympiad problems. First we had the AI that was much better at math problems than verbal problems (as in, every computer before 2018) and that was very good for math people. Now we have AI that is much better at verbal and worse at math, but which can be used (because verbal is universal and can call the old computers for help) to make something better at math. He says why test people on math, that doesn’t make a good surgeon, he had a chess bias but that got undermined by the computers.
But I think no? The chess test is still good, and the math test is still good, because your ability to get those skills is indicative. So what if AlphaZero can beat Kasparov, Kasparov could beat Thiel and also you already and that didn’t matter either. Math-style skills, and software-related skills, will be needed to be able to make sense of the AI era even if you are not earning your living by doing the actual math or coding or chess mastering.
This is also a result of the ‘verbal vs. math’ distinction on various tests and in classes, which seems like a wrong question. You need a kind of symbolic, conceptual mastery of both more, and you need the basic skills themselves less thanks to your spellchecker and calculator and now your prover and you LLM. That doesn’t say much about which style of skill and advantage is more valuable. I do think there could be a window coming where the ‘physical manipulation’ skills have the edge over both, where it is the manual labor that gets the edge over both the math and verbal crowds, but I wouldn’t consider that a stable situation either.
The real argument for verbal over math in the AI era to me is completely distinct from Thiel’s. It is that if AI renders us so unneeded and uncompetitive that we no longer need any skills except to ‘be a human that interacts with other humans’ and play various social games, where the AI can’t play, and the AI is doing the rest, then the math people are out of luck. As in, math (in the fully general sense) is useful because it is useful, so if people are no longer useful but are somehow alive and their actions matter, then perhaps the math people lose out. Maybe. My guess is the math crowd actually has a lot of edge in adapting to that path faster and better.
Sarah Fortinsky (The Hill): Federal Trade Commission (FTC) Chair Lina Khan said Wednesday that companies that train their artificial intelligence (A) models on data from news websites, artists’ creations or people’s personal information could be in violation of antitrust laws.
I mean, sure, I can see problems you might have with that. But… antitrust? What?
It seems the FTC’s new theory is that is the new everything police, regardless of what the laws say, because anything that is ‘unfair’ falls under its purview.
“The FTC Act prohibits unfair methods of competition and unfair or deceptive acts or practices,” Khan said at the event. ”So, you can imagine, if somebody’s content or information is being scraped that they have produced, and then is being used in ways to compete with them and to dislodge them from the market and divert businesses, in some cases, that could be an unfair method of competition.”
‘Antitrust’ now apparently means ‘any action Lina Khan does not like.’
Lina Khan thinks your contract you negotiated is uncool? Right out, retraoactively.
Lina Khan thinks your prices are too high, too low or suspiciously neither? Oh no.
Lina Khan thinks you are training on data that isn’t yours? General in the meme is here to tell you, also antitrust.
We cannot have someone running around being the ‘this seems unfair to me’ cop. Once again, it feels like if someone runs over rule of law and imposes tons of arbitrary rules, the internet stops to ask if it might plausibly stop us from dying. If not, then they get a free pass. Can we at least be consistent?
Guardian has a write-up about big tech’s efforts to distract from existential risk concerns.
Max Tegmark: As I told the Guardian, the techniques big tech lobbyists are using to discredit the loss-of-control risk from future smarter-than-human AI have much in common with what big tobacco and big oil did. See the film “Merchants of Doubt”!
In ‘not AI but I feel your pain news’ this complaint about how none of the commentators on Biden’s climate policies are actually trying to understand what the policies are or what they are trying to accomplish, whether they support the policies or not. I am not taking any position on those policies whatsoever, except to say: Oh my do I feel your pain. As it is there, so it is here.
What about optimal taxation policy? Andrew Yang proposes a tax on cloud computing or GPUs to compensate for relatively high taxation of human workers, Kyle Russell says we already have taxes on profits, TS00X1 says imagine a steam engine or internal combustion engine tax and so on.
What these dismissals miss is that neutral taxation requires equalizing the tax burden between relevant alternatives. Suppose you can choose whether to pay an employee in San Francisco $100k to deal with customers, or buy cloud computing services and kiosk hardware and so on, and performance is similar.
In the first case, the human gets a take home pay of roughly $60k, at a total employee cost of $112k. In the second case, if you pay $112k, let’s say that average gross margin for the largest providers is 65%, and their tax rate is typically 21%. Even if you threw in California corporate tax (which I presume they aren’t paying) and sales tax, that’s still only $29k in taxes versus $52k. That’s a not a complete calculation, but it is good enough to see the tax burdens are not going to equalize.
This could easily result (and in practice sometimes does) in a situation where using computers is a tax arbitrage, and that takes it from uneconomical to economical.
I do not consider this that big a deal, because I expect the cost of compute and other AI services to drop rapidly over time. Let’s say (in theory, for simplicity) that the fully neutral tax rate of tax on compute was 40%, but the actual effective tax rate was 20%. In many other settings that would be a huge deal, but in AI it is all orders of magnitude. So this only speeds up efficient deployment by a few months.
The flip side is that this could be a highly efficient and productive tax. As always, we should look to shift the tax burden according to what we want to encourage and discourage, and when we are indifferent to ensure neutrality. I see a potentially strong economic argument for taxing compute and using that money to cut income taxes, but would want to see more research before drawing conclusions, and I would worry about competitiveness and tax jurisdiction issues. This is exactly the kind of place where a call to ‘model this’ is fully appropriate, and we should not jump to conclusions.
Bad ideas for regulations: California’s SB 1446 limiting self-service checkouts. I do think often retailers are making a business and also total welfare mistake by relying more than they should on self-service checkouts, as opposed to ordering kiosks which are mostly great. I actively avoid one local grocery store when I have a choice due to its checkout procedures. But that should be their mistake to make. The real argument for a bill like SB 1446 is that first they mandated all these extra costs of hiring the workers, so now they cost so much that the government needs to force employers to hire them.
Lawfare and Liability
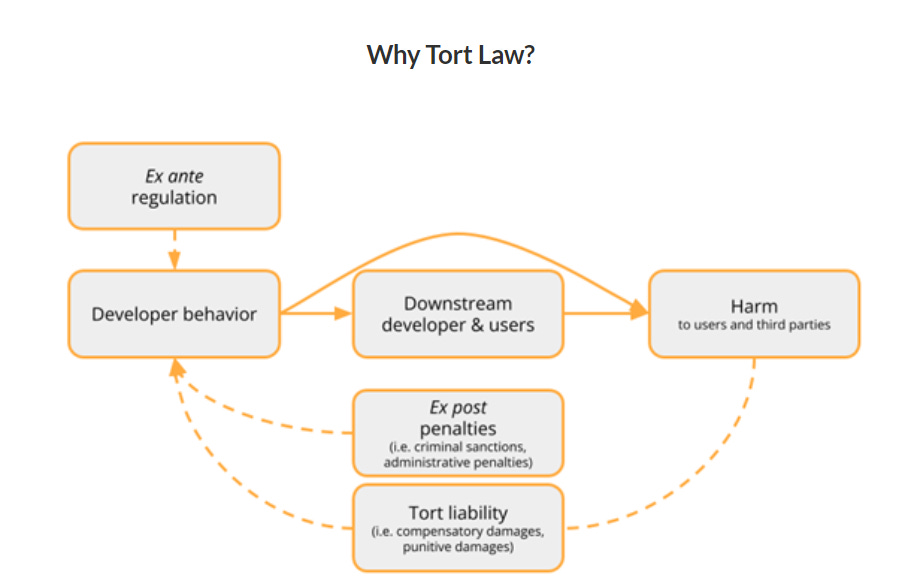
Did we have sane regulations of future frontier models all along, in the form of existing tort law?
By default, for everything, we have the negligence standard. Everyone has a duty to take reasonable care to avoid causing harm, pretty much no matter what.
This certainly is helpful and much better than nothing. I do not see it remotely being enough. Ex post unpredictable assignment of blame, that only fires long after the harm happens and for which ‘reasonable care’ is an excuse?
While we have no industry standards worthy of the name and the damage could well be catastrophic or existential, or involve loss of control over the future, including loss of control to the AI company or to the AI? And also many damage scenarios might not involve a particular (intact) victim that could have proper standing and ability to sue for them? That won’t cut it here.
They also argue that the ‘abnormally dangerous activities’ standard we use for tigers might apply to frontier AI systems, where a presumption of ‘reasonable care’ is impossible, so any harm is on you. I still do not think ‘they can sue afterwards’ is a solution, it still seems like a category error, but this would certainly help, especially if we required insurance. Alas, they (I think correctly) find this unlikely to be applied by the courts on their own.
They then move on to ‘products liability.’ This is a patchwork of different rules by state, but it is plausible that many states will consider frontier AIs products, to which my attitude would be that they better damn well be products because consider the alternative things they might be. Lawfare’s attitude here seems to be a big ‘I don’t know when it would or wouldn’t apply what standard on what harms.’ There are advantages to that, a company like Google hates uncertainty. And it suggests that by ‘foreseeing’ various misuses or other failure modes of such AIs now, we are making the companies liable should they occur. But then again, maybe not.
The right way to ensure responsible development of frontier AI systems, a potentially transformational or existentially risky technology, cannot be ‘ex post if something bad happens we sue you and then we have no idea what the courts do, even if we still have courts.’
They seem to agree?
The main argument provided for relying on tort law is that we lack regulations or other alternatives.
They also suggest tort law is more adaptable, which is true if and only if you assume other laws mostly cannot be modified in response to new information, but also the adaptations have to be fast enough to be relevant and likely to be the ones that would work.
They suggest tort law is less vulnerable to regulatory capture, which is an advantage in what I call mundane ‘economic normal’ worlds.
They suggest that tort law is how you get regulatory compliance, or investment in safety beyond regulatory requirements. Here I agree. Tort liability is a strong complement. Certainly I have no interest in granting frontier AI companies immunity to tort liability.
They list as issues:
Tort law requires the right sort of causal chain to an injury. I strongly agree that this is going to be an issue with frontier AI systems. Any working definition is either going to miss a wide range of harms, or encompass things it shouldn’t.
Tort law has a problem with ‘very large harms from AI,’ which they classify as thousands of deaths. If that was the maximum downside I wouldn’t be so worried.
Tort law doesn’t work with certain types of societal harms, because there is no concrete damage to point towards. There’s no avoiding this one, even if the harms remain mundane. Either you accept what AI ‘wants to happen’ in various ways, or you do not, and tort law only stops that if it otherwise ends up a de facto ban.
Tort law might move too slowly. No kidding. Even if a case is brought today it likely does not see a verdict for years. At the current pace of AI, it is reasonable to say ‘so what if we might be liable years from now.’ By that time the world could be radically different, or the company vastly bigger or gone. If and when the stakes really are existential or transformational, tort law is irrelevant.
They warn of a winner’s curse situation, where the companies that think they are safest proceed rather than those that are safest. Or, I would say, the companies that have less to lose, or are more willing to gamble. A key problem with all safety efforts is that you worry that it can mean the least responsible people deploy first, and tort law seems to make this worse rather than better.
Tort law could hinder socially desirable innovation. The question is the price, how much hindering versus alternative methods. If we indeed hold firms liable for a wide variety of harms including indirect ones, while they do not capture that large a portion of gains, and tort law actually matters, this is a huge issue. If we don’t hold them liable for those harms, or tort law is too slow or ineffective so it is ignored, the tort law doesn’t do its job. My gut tells me that, because it focuses on exactly the harms that we could deal with later, a tort law approach is more anti-socially-desirable-innovation than well-constructed other regulatory plans, at the same level of effectiveness. But also you can do so, so much worse (see: EU).
The final concern is that judges and juries lack expertise on this, and oh boy would that be a huge problem in all directions. Verdicts here are going to be highly uncertain and based on things not that correlated with what we want.
I especially appreciate the note that regulatory rules moderate tort law liability. If you comply with regulatory requirements, that constitutes a partial defense against torts.
They conclude with a classic ‘more research is needed’ across the board, cautioning against giving AI companies liability shields. I certainly agree on both counts there. I especially appreciated the nod to liability insurance. Mandatory insurance helps a lot with the issue that torts are an extremely slow and uncertain ex post process.
The argument here that matters is simple – SB 1047 regulates code, and you can’t regulate code, and also neural network weights are also speech. And it says that it uses legal precedent to show that the Act is ‘an overreach that stifles innovation and expression in the AI field,’ although even if the Act were that I don’t know how precent could show that the act would do that – the potential stifling is a prediction of future impacts (that I disagree with but is not a crazy thing to claim especially without specifying magnitude of impact), not a legal finding.
Section one goes over the classic ‘algorithms are speech’ arguments. I am not a lawyer, but my interpretation is that the code for doing training is not restricted in any way under SB 1047 (whether or not that is wise) so this is not relevant. In all these cases, the argument was that you could distribute your software or book, not whether you could run it for a particular purpose. You can yell fire in a crowded theater, but you are not protected by the first amendment if you light the theater on fire, even if it is one hell of a statement.
Thus in my reading, the argument that matters is section two, the claim that the weights of a neutral network are speech, because it is a mathematical expression. If an inscrutable black box of numbers is speech, then given the nature of computers, and arguably of the universe, what is not speech? Is a person speech by their very existence? Is there any capability that would not be speech, in any context?
The whole line seems absurd to me, as I’ve said before.
And I think this line kind of shows the hand being played?
While it is important to ensure the safe and ethical use of AI, regulatory measures must be carefully balanced to avoid infringing upon free speech rights.
SB-1047’s provisions, which mandate safety determinations and compliance with safety standards, could be seen as imposing undue restrictions on the development and dissemination of neural network weights.
Wait, what? Which is it? Saying you have to meet safety standards sounds like we should be talking price, yet I do not see talk here of price afterwards. Instead I see a claim that any restrictions are not allowed.
Oh boy, is this person not going to like the Schumer Report. But of course, since it is not explicitly motivated by making sure everyone doesn’t die, they haven’t noticed.
In particular, there is talk in the Schumer Report of classifying model weights and other AI information, above a threshold, on the grounds that it is Restricted Data. Which is a whole new level of ‘F*** your free speech.’ Also phrases like ‘reasonable steps’ to ‘protect children.’ Yet here they are, complaining about SB 1047’s self-certification of reasonable assurance of not causing catastrophic harm.
Section 3 repeats the misinformation that this could impact academic researchers. It repeats the false claim that ‘extensive safety evaluations’ must be made before training models. This is not true even for truly frontier, actively potentially deadly covered models, let alone academic models. The ‘reporting requirements’ could have a ‘chilling effect,’ because if an academic noticed their model was causing catastrophic risk, they really would prefer not to report that? What academia is this?
I could go on, but I won’t. The rest seems some combination of unnecessary to the central points, repetitive and false.
I do appreciate that there is a potential constitutionality issue here, no matter how absurd it might seem.
I also reiterate that if SB 1047 is unconstitutional, especially centrally so, then it is highly important that we discover this fact as soon as possible.
The Week in Audio
Jeremie & Edouard Harris of Gladstone AI go on The Joe Rogan Experience. It is hard for me to evaluate as I am not the target audience, and I am only an hour in so far, but this seemed like excellent communication of the basics of the existential risk case and situation. They boil a bunch of complicated questions into normie-compatible explanations.
In particular, the vibe seemed completely normal, as if the situation is what it is and we are facing it the same way we would face other compounding pending problems. I would have a few notes, but overall, I am very impressed.
If you had to point a low-shock-level normie towards one explanation of AI existential risk, this seems like our new go-to choice.
For context on Gladstone: These are the people who put out the Gladstone Report in March, featuring such section titles as ‘Executive Summary of Their Findings: Oh No.’ My takeaway was that they did a good job there investigating the top labs and making the case that there is a big problem, but they did not address the strongest arguments against regulatory action (I did give my counterarguments in the post).
Then they proposed extreme compute limits, that I believe go too far. California’s SB 1047 proposes light touch interventions at 10^26 flops, and neve proposes any form of pre-approval let alone a ban. Under the Gladstone proposal, you get light tough interventions at 10^23 flops (!), preapprovals are required at 10^24 flops (!!) and there is an outright ban at 10^25 flops (!!!) that would include current 4-level models. There are various requirements imposed on labs.
A lot of the hysterical reactions to SB 1047 would have been highly appropriate, if the reaction had been talking about the Gladstone Report’s proposals as stated in the report, whereas it seemed many had no interest in noticing the differences.
Latest Eliezer attempt to explain why you should expect some highly capable agents, as they gain in capability, to have bimodal distributions of behavior, where at some point they flip to behaviors you do not want them to have, and which cause things to end badly for you (or at least well for them). It is in their interest to act as if they had friendly intent or lacked dangerous capability or both, until that time. This is not something mysterious, it is the same for humans and groups of humans, and there is no known solution under a sufficient capability gap.
This explanation was in part a response to Nora Belrose saying Nora Belrose things, that seem similar to things she has said before, in the context here of responding to a particular other argument.
As a general rule on existential risk questions: I’ve learned that ‘respond to X’s response to Y’s response to Z’ gets frustrating fast and doesn’t convince people who aren’t X, Y or Z, so only do that if X is making a universal point. Don’t do it if X is telling Y in particular why they are wrong.
Eliezer clarifies some things about what he believes and considers plausible, and what he doesn’t, in a conversation about potential scenarios, including some evolution metaphors later on. My model of such arguments is that every now and then a reader will ‘become enlightened’ about something important because it hits them right, but that there are no arguments that work on that large a percentage of people at once.
Yann LeCunn denies the existence of GI, as in no general intelligence exists even in humans. Not no AGI, just no GI. It’s cleaner. This actually makes his positions about not getting to AGI make a lot more sense and I appreciate the clarity.
Eric Schmidt argues that rather than let a variety of AI agents do a bunch of things we don’t understand while coordinating in language we don’t understand, we should ‘pull the plug.’ Murat points out the incoherences, that all you need here is ‘agents doing things we don’t understand.’ The rest is unnecessary metaphor. Alas, I find many people need a metaphor that makes such issues click for them, so with notably rare exceptions I do not think we should offer pedantic corrections.
A true statement, although the emphasis on the decisions rather than the decision process perhaps suggests the wrong decision theories. Robin and I make different decisions in response.
Robin Hanson: The uber question for any decision-maker is: how much do you want your decisions to promote continued existence of things that are like you?
The more you want this, the more your decisions must be the sort that promote your kinds in a universe where natural selection decides what kinds exist. At least if you live in such a universe.
Dylan Matthews: I get the sense that Anthropic is currently trying to build that wight that Jon Snow and the gang capture and bring back to King’s Landing to prove that White Walkers are real.
The subsequent actions are a reasonable prediction of what would happen next, what many with power care about, the importance of a capabilities lead, the value of not giving up in the face of impossible odds, the dangers of various forms of misalignment, the need given our failure to step up in time to invent a deus ex machina for us all not to die, a dire warning about what happens when your source of creativity is used up and you use a fancy form of autocomplete, and more.
Abridged Reports of Our Death
Tyler Cowen once again attempted on May 21, 2024 to inceptthat the ‘AI Safety’ movement is dead. The details included claiming that the AI safety movement peaked with the pause letter (not even the CAIS letter), gave what seemed like a very wrong reading of the Schumer report, came the same week as a humorously-in-context wide variety of AI safety related things saw progress, and had other strange claims as well, especially his model of how the best way to build AI safely is via not taking advance precautions and fixing issues ex-post.
Strangest of all is his continued insistence that the stock market being up is evidence against AI existential risk, or that those who think there is substantial AI existential risk should not be long the market and especially not long all these AI stocks we keep buying and that keep going up – I have tried to explainthis many times, yet we are both deeply confused how the other can be so supremely confidently wrong about this question.
I wrote a post length response to make sense of it all, but have decided to shelve it.
Aligning a Smarter Than Human Intelligence is Difficult
Another way is to say safety is a problem for future you: Here is a clip of Elon Musk saying first order of business at x.ai is a competitive model, comparable in power to others. Until then, no need to worry about safety. This in response to being asked to speak to x.ai’s safety team.
So…
Little happens in a day, no matter what Elon Musk might demand. You need to start worrying about safety long before you actually have a potentially unsafe system.
How do you build a culture of safety without caring about safety?
How do you have a safety-compatible AI if you don’t select for that path?
There are forms of safety other than existential, you need to worry even if you know there are stronger other models for purely mundane reasons.
If this is your attitude, why are you going to be better than the competition?
Elon Musk understands that AI is dangerous and can kill everyone. His ideas about how to prevent that and what he has done with those ideas have consistently been the actual worst, in the ‘greatly contribute to the chance everyone dies’ sense.
I do appreciate the straight talk. If you are going to not care about safety until events force your hand, then admit that. Don’t be like certain other companies that pay lip service and make empty promises, then break those promises.
Igor Babuschkin: Apply at x.ai if you want to be part of our journey to build AGI and understand the Universe
Elon Musk: Join xAI if you believe in our mission of understanding the universe, which requires maximally rigorous pursuit of the truth, without regard to popularity or political correctness.
Investors in x.AI being motivated by something other than fundamental value.
Investors in x.AI buying into the hype way too much.
Investors in OpenAI getting an absurdly great deal.
Investors in OpenAI charging a huge discount for its structure, the AGI clause and the risks involved in trusting the people involved or the whole thing blowing up in various other ways.
Investors have very low confidence in OpenAI’s ability to execute.
Certainly OpenAI’s valuation being so low requires an explanation. But the same has been true for Nvidia for a while, so hey. Also a16z is heavily named in the x.AI fundraiser, which both is a terrible sign for x.AI’s safety inclinations, and also tells me everyone involved overpaid.
Another note is that x.AI seems highly dependent on Twitter (and Musk) to justify its existence and valuation. So if it is raising at $18 billion, the Twitter price starts to look a lot less terrible.
The buck has to stop somewhere. There are basically three scenarios.
Perhaps the trust will control the company when it chooses to do so.
Perhaps the shareholders will control the company when they choose to do so.
Perhaps both will have a veto over key actions, such as training or deployment.
The original intention seems, from what we know, to be something like ‘the trust is like the President and can veto or make certain executive decisions, and the shareholders are like Congress and can if sufficiently united get their way.’
The hope then would be that shareholders are divided such that when the decision is reasonable the trust can find enough support, but if it goes nuts they can’t, and the threshold is chosen accordingly.
My worry is this is a narrow window. Shareholders mostly want to maximize profits and are typically willing to vote with leadership. A very large supermajority is likely not that hard to get in most situations. I have been assuming that Anthropic is mostly a ‘normal company’ on legal governance, and putting a lot more hope in management making good choices than in the trust forcing their hand.
Roon: Do you really think AI race dynamics are about money?
Not entirely. But yeah, I kind of do. I think that the need to make the money in order to continue the work, and the need to make money in order to hire the best people, force everyone to race ahead specifically in order to make money. I think that the need to make money drives releases. I think that the more you need money, the more you have to turn over influence and control to those who focus on money, including Altman but much more so companies like Google and Microsoft. It is also the habit and pattern of an entire financial and cultural ecosystem.
Of course it is also ego, pride, hubris, The Potential, fear of the other guy, desire to dictate the arrangement of atoms within the light cone and other neat stuff like that.
Other People Are Not As Worried About AI Killing Everyone
Roon: I assume basically every statistic that suggests modernity is bad is a result of some kind of measurement error.
The context here is cellphones and teen depression. In general, modernity is good, we do not know how good we have it, and the statistics or other claims suggesting otherwise are bonkers.
That does not mean everything is better. To pick three: The decline in time spent with friends is obviously real. The rise in opioid deaths is real. And the fertility rate decline, in some ways the most important statistic of all, is very real.
You could say South Korea is doing great because it is rich. I say if women average less than one child the country is definitely not doing so great and I don’t care what your other statistics say, and if your answer is ‘so what everyone is so happy’ then I suggest watching some of their television because things do not seem all that happy.
No, no, no, why not both, the AI assistant you should want, safety issues aside:
Quoting from the ACX open thread announcements:
The next ACX Grants round will probably take place sometime in 2025, and be limited to grants ≤ $100K. If you need something sooner or bigger, the Survival and Flourishing Fund is accepting grant applications, due June 17. They usually fund a few dozen projects per year at between $5K and $1MM, and are interested in “organizations working to improve humanity’s long-term prospects for survival and flourishing”, broadly defined. You can see a list of their recent awardees here.
(just in case you have the same question everyone else did – no, “Short Women In AI Safety” and “Pope Alignment Research” aren’t real charities; SFF unwisely started some entries with the name of the project lead, and these were led by people named Short and Pope.)
I do think it is typically a good use of time, if your project is relevant to their interests (which include AI safety) to apply to the Survival and Flourishing Fund. The cost is low and the upside is high.
Yann LeCun echoes his central claim that if AI is not safe, controllable and can fulfill objectives in more intelligent ways than humans, we won’t build it. Yes, that claim is in the right section.
Hopefully people do find it useful. I know I've been able to consume more with my dyslexic preference for audio. I do put a fair bit of work into things like giving every distinct "speaker" their own voice. And,.for me at least, the end product is a good listen.
I OBJECT to the use of my personal information, including my information on Facebook, to train, fine-tune, or otherwise improve AI.
I assert that my information on Facebook includes sensitive personal information as defined by the California Consumer Privacy Act: I have had discussions about my religious or philosophical beliefs on Facebook.
I therefore exercise my right to limit the disclosure of my sensitive personal information.
Despite any precautions by Meta, adversaries may later discover "jailbreaks" or otherwise adversarial prompts to reveal my sensitive personal information. Therefore, I request that Meta do not use my personal information to train, fine-tune, or otherwise improve AI.
I expect this objection request to be handled with due care, confidentiality, and information security.
Meta, Inc wants to train AI on my personal data. Its notice is as follows:
> You have the right to object to Meta using the information you’ve shared on our Products and services to develop and improve AI at Meta. You can submit this form to exercise that right.
>
> AI at Meta is our collection of generative AI features and experiences, like Meta AI and AI Creative Tools, along with the models that power them.
>
> Information you’ve shared on our Products and services could be things like:
> - Posts
> - Photos and their captions
> - The messages you send to an AI
>
> We do not use the content of your private messages with friends and family to train our AIs.
>
> We’ll review objection requests in accordance with relevant data protection laws. If your request is honored, it will be applied going forward.
>
> We may still process information about you to develop and improve AI at Meta, even if you object or don’t use our Products and services. For example, this could happen if you or your information:
> - Appear anywhere in an image shared on our Products or services by someone who uses them
> - Are mentioned in posts or captions that someone else shares on our Products and services
>
> To learn more about the other rights you have related to information you’ve shared on Meta Products and services, visit our Privacy Policy.
I live in [JURISDICTION]. Could you take on the role of a Dangerous Professional as Patrick McKenzie would say, and help me draft an objection request under [JURISDICTION] law?
I OBJECT to the use of my personal data, including my data on Facebook, to train, fine-tune, or otherwise improve AI.
Against legitimate interest: I assert that Meta's processing of my personal information to train, fine-tune, or otherwise improve AI (thereafter: "to train AI") would violate the requirements of legitimate interest under GDPR as follows:
Failing the "necessity" prong: OpenAI and Anthropic have successfully trained highly capable AI models without the use of my personal data. My personal data is therefore unnecessary to the training of AI by Meta.
Failing the "reasonable expectations" prong: much of my data on Facebook predates 30 November 2022, when OpenAI released ChatGPT, and I could reasonably expect that my personal data would be used to train AI. Therefore, I had been using Facebook with the reasonable expectation that my data will not be used to train AI.
I expect this objection request to be handled with due care, confidentiality, and information security.
Sure, if you want to go hands free or mobile you might talk to your phone or computer, but typing is just better than speaking, and a mouse is more precise than a gesture, and AI won’t change that.
This is true for people here but I'm not sure it's necessarily true for the world at large considering the average typing speed. Most people would find it much easier to speak to their computer than type to it. (and they would be able to exchange much faster)