Predicting GPU performance
post by Marius Hobbhahn (marius-hobbhahn), Tamay · 2022-12-14T16:27:23.923Z · LW · GW · 26 commentsThis is a link post for https://epochai.org/blog/predicting-gpu-performance
Contents
26 comments
We develop a simple model that predicts progress in the performance of field-effect transistor-based GPUs under the assumption that transistors can no longer miniaturize after scaling down to roughly the size of a single silicon atom. We construct a composite model from a performance model (a model of how GPU performance relates to the features of that GPU), and a feature model (a model of how GPU features change over time given the constraints imposed by the physical limits of miniaturization), each of which are fit on a dataset of 1948 GPUs released between 2006 and 2021. We find that almost all progress can be explained by two variables: transistor size and the number of cores. Using estimates of the physical limits informed by the relevant literature, our model predicts that GPU progress will stop roughly between 2027 and 2035, due to decreases in transistor size. In the limit, we can expect that current field-effect transistor-based GPUs, without any paradigm-altering technological advances, will be able to achieve a peak theoretical performance of 1e14 and 1e15 FLOP/s in single-precision performance.
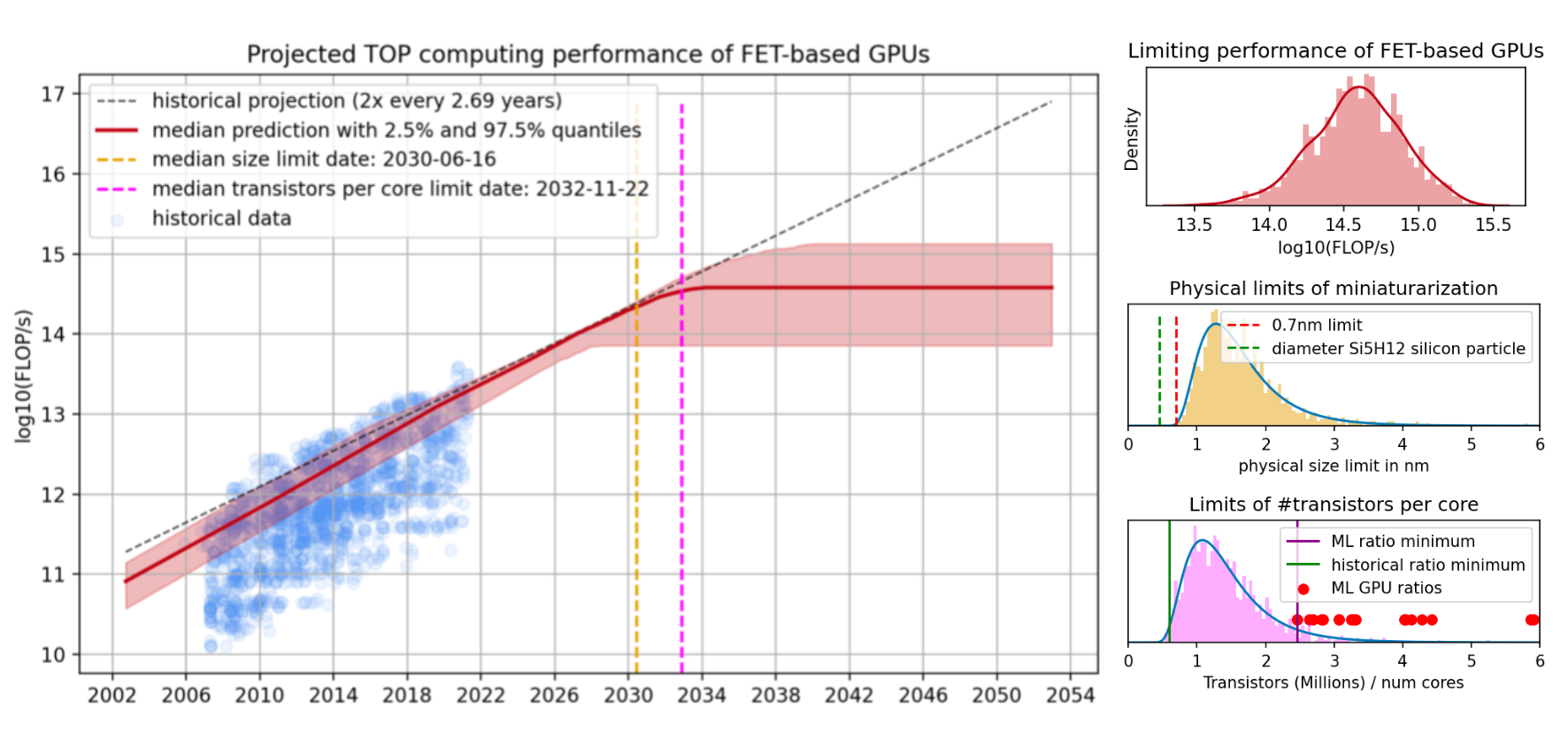
While there are many other drivers of GPU performance and efficiency improvements (such as memory optimization, improved utilization, and so on), decreasing the size of transistors has historically been a great, and arguably the dominant, driver of GPU performance improvements. Our work therefore strongly suggests that it will become significantly harder to achieve GPU performance improvements around the mid-2030s within the longstanding field-effect transistor-based paradigm.
This post is just the executive summary, you can find the full report on the Epoch website.
26 comments
Comments sorted by top scores.
comment by hippke · 2022-12-15T20:10:43.512Z · LW(p) · GW(p)
I think the biggest improvement in this report can be made regarding Appendix D. The authors describe that they use "process size rather than transistor size" which is, as they correctly note, a made-up number. What should be used instead is transistor density (transistors per area), which is readily available in much detail for many past nodes, and the most recent "5nm" nodes (see e.g., wikichip).
comment by Mau (Mauricio) · 2022-12-14T21:54:25.818Z · LW(p) · GW(p)
This is helpful for something I've been working on - thanks!
I was initially confused about how these results could fit with claims from this paper on AI chips, which emphasizes the importance of factors other than transistor density for AI-specialized chips' performance. But on second thought, the claims seem compatible:
- The paper argues that increases in transistor density have (recently) been slow enough for investment in specialized chip design to be practical. But that's compatible with increases in transistor density still being the main driver of performance improvements (since a proportionally small boost that lasts several years could still make specialization profitable).
- The paper claims that "AI[-specialized] chips are tens or even thousands of times faster and more efficient than CPUs for training and inference of AI algorithms." But the graph in this post shows less than thousands of times improvements since 2006. These are compatible if remaining efficiency gains of AI-specialized chips came before 2006, which is plausible since GPUs were first released in 1999 (or maybe the "thousands of times" suggestion was just too high).
↑ comment by SteveZ (steve-zekany) · 2022-12-15T01:34:30.425Z · LW(p) · GW(p)
Yep, I think you're right that both views are compatible. In terms of performance comparison, the architectures are quite different and so while looking at raw floating-point performance gives you a rough idea of the device's capabilities, performance on specific benchmarks can be quite different. Optimization adds another dimension entirely, for example NVIDIA has highly-optimized DNN libraries that achieve very impressive performance (as a fraction of raw floating-point performance) on their GPU hardware. AFAIK nobody is spending that much effort (e.g. teams of engineers x several months) to optimize deep learning models on CPU these days because it isn't worth the return on investment.
Replies from: Mauricio↑ comment by Mau (Mauricio) · 2022-12-15T03:00:21.956Z · LW(p) · GW(p)
Thanks! To make sure I'm following, does optimization help just by improving utilization?
Replies from: steve-zekany↑ comment by SteveZ (steve-zekany) · 2022-12-15T03:26:39.424Z · LW(p) · GW(p)
Yeah pretty much. If you think about mapping something like matrix-multiply to a specific hardware device, details like how the data is laid out in memory, utilizing the cache hierarchy effectively, efficiently moving data around the system, etc are important for performance.
↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-14T22:26:10.572Z · LW(p) · GW(p)
As a follow-up to building the model, I was looking into specialized AI hardware and I have to say that I'm very uncertain about the claimed efficiency gains. There are some parts of the AI training pipeline that could be improved with specialized hardware but others seem to be pretty close to their limits.
We intend to understand this better and publish a piece in the future but it's currently not high on the priority list.
Also, when compared to CPUs, it's no wonder that any parallelized hardware is 1000x more efficient. So it really depends on what the exact comparison is that the authors used.
↑ comment by Mau (Mauricio) · 2022-12-14T23:46:33.458Z · LW(p) · GW(p)
Sorry, I'm a bit confused. I'm interpreting the 1st and 3rd paragraphs of your response as expressing opposite opinions about the claimed efficiency gains (uncertainty and confidence, respectively), so I think I'm probably misinterpreting part of your response?
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T10:54:29.887Z · LW(p) · GW(p)
By uncertainty I mean, I really don't know, i.e. I could imagine both very high and very low gains. I didn't want to express that I'm skeptical.
For the third paragraph, I guess it depends on what you think of as specialized hardware. If you think GPUs are specialized hardware than a gain of 1000x from CPUs to GPUs sounds very plausible to me. If you think GPUs are the baseline and specialized hardware are e.g. TPUs, then a 1000x gain sounds implausible to me.
My original answers wasn't that clear. Does this make more sense to you?
↑ comment by Mau (Mauricio) · 2022-12-16T02:07:03.807Z · LW(p) · GW(p)
It does, thanks! (I had interpreted the claim in the paper as comparing e.g. TPUs to CPUs, since the quote mentions CPUs as the baseline.)
comment by hippke · 2022-12-15T16:50:07.697Z · LW(p) · GW(p)
What about the Landauer limit? We are 3 orders of magnitude from the Landauer limit ( J/op), see my article [LW · GW] here on Lesswrong. The authors list several physical limitations, but this one seems to be missing. It may pose the most relevant limit.
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T17:02:56.982Z · LW(p) · GW(p)
We did consider modeling it explicitly. However, most estimates on the Landauer limit give very similar predictions as size limits. So we decided against making an explicit addition to the model and it is "implicitly" modeled in the physical size. We intend to look into Landauer's limit at some point but it's not a high priority right now.
comment by fylo · 2022-12-14T23:39:53.099Z · LW(p) · GW(p)
Thanks for a really interesting read. I wonder if it's worth thinking more about the FLOP/$ as a follow-up. If a performance limit is reached, presumably the next frontier would be bringing down the price of compute. What are the current bottlenecks on reducing costs?
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T11:05:01.800Z · LW(p) · GW(p)
We originally wanted to forecast FLOP/s/$ instead of just FLOP/s but we found it hard to make estimates about price developments. We might look into this in the future.
Replies from: fylo↑ comment by fylo · 2022-12-15T17:23:08.652Z · LW(p) · GW(p)
Thanks. Another naive question: how do power and cooling requirements scale with transistor and GPU sizes? Could these be barriers to how large supercomputers can be built in practice?
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T18:02:25.830Z · LW(p) · GW(p)
Definitely could be but don't have to be. We looked a bit into cooling and heat and did not find any clear consensus on the issue.
comment by Foyle (robert-lynn) · 2022-12-15T02:11:40.377Z · LW(p) · GW(p)
Human brains are estimated to be ~1e16flops equivalent, suggesting about 10-100 of these maxed-out GPUs a decade hence could be sufficient to implement a commodity AGI (Leading Nvidia A100 GPU already touts 1.2 p-ops Int8 with sparsity), at perhaps 10-100kW power consumption, (less than $5/hour if data center is in low electricity cost market). There are about 50x 1000mm² GPUs per 300mm wafer, and latest generation TSMC N3 process costs about $20000 per wafer - eg an AGI per wafer seems likely.
It's likely then that (if it exists and is allowed) personal ownership of human-level AGI will be, like car ownership, within the financial means of a large proportion of humanity within 10-20 years, and their brain power will be cheaper to employ than essentially all human workers. Economics will likely hasten rather than slow an AI apocalypse.
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T11:03:34.320Z · LW(p) · GW(p)
Well, depending on who you ask, you'll get numbers between 1e13 and 1e18 for the human brain FLOP/s equivalent. So I think there is lots of uncertainty about it.
However, I do agree that if it was at 1e16, your reasoning sounds plausible to me. What a wild imagination.
↑ comment by Noosphere89 (sharmake-farah) · 2022-12-16T14:30:20.072Z · LW(p) · GW(p)
Jacob Cannell thinks brains are doing 10^14 10^15 FLOP/s.
https://www.lesswrong.com/posts/xwBuoE9p8GE7RAuhd/brain-efficiency-much-more-than-you-wanted-to-know [LW · GW]
comment by aog (Aidan O'Gara) · 2022-12-15T01:15:26.685Z · LW(p) · GW(p)
Really cool analysis. I’d be curious to see the implications on a BioAnchors timelines model if you straightforwardly incorporate this compute forecast.
Replies from: marius-hobbhahn, Zach Stein-Perlman↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T11:00:12.899Z · LW(p) · GW(p)
We looked more into this because we wanted to get a better understanding of Ajeya's estimate of price-performance doubling every 2.5 years. Originally, some people I talked to were skeptical and thought that 2.5 years is too conservative. I now think that 2.5 years is probably insufficiently conservative in the long run.
However, I also want to note that there are still reasons to believe a doubling time of 2 years or less could be realistic due to progress in specialization or other breakthroughs. I still have large uncertainty about the doubling time but my median estimate got a bit more conservative.
We have not incorporated this particular estimate into the bio anchor's model. Mostly, because the model is a prediction about a particular type of GPU and I think it will be modified or replaced once miniaturization is no longer an option. So, I don't expect progress to entirely stop in the next decade, just slow down a bit.
But lots of open questions all over the place.
↑ comment by Zach Stein-Perlman · 2022-12-15T02:53:59.113Z · LW(p) · GW(p)
I'd be interested in the implications too, but I don't see how that would work, since bioanchors just looks at price-performance iirc.
comment by Arthur Conmy (arthur-conmy) · 2023-01-02T22:49:49.713Z · LW(p) · GW(p)
The criticism here implies that one of the most important factors in modelling the end of Moore's law is whether we're running out of ideas (which the poster thinks is true). Do you think your models capture the availability of new ideas?
Replies from: marius-hobbhahn, sharmake-farah↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2023-01-03T08:15:38.539Z · LW(p) · GW(p)
This criticism has been made for the last 40 years and people have usually had new ideas and were able to execute them. Thus, on priors, we think this trend will continue even if we don't know exactly which kind of ideas they will be.
In fact, due to our post, we were made aware of a couple of interesting ideas about chip improvements that we hadn't considered before that might change the outcome of our predictions (towards later limits) but we haven't included them in the model yet.
↑ comment by Noosphere89 (sharmake-farah) · 2023-01-03T22:09:40.102Z · LW(p) · GW(p)
I disagree, because physical limits matter more here than ideas here. The types of new ideas that could sustain Moore's Law are very radical like quantum computers, and I heavily think the tweet thread is either very wrong or has really important information.
comment by SteveZ (steve-zekany) · 2022-12-15T01:48:06.072Z · LW(p) · GW(p)
This is a really nice analysis, thank you for posting it! The part I wonder about is what kind of "tricks" may become economically feasible for commercialization once shrinking the transistors hits physical limits. While that kind of physical design research isn't my area, I've been led to believe there are some interesting possibilities that just haven't been explored much because they cost a lot and "let's just make it smaller next year" has traditionally been an easier R&D task.
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-12-15T11:01:38.600Z · LW(p) · GW(p)
Yeah, I also expect that there are some ways of compensating for the lack of miniaturization with other tech. I don't think progress will literally come to a halt.