Reframing Impact
post by TurnTrout · 2019-09-20T19:03:27.898Z · LW · GW · 15 commentsContents
Technical Appendix: First safeguard? None 15 comments





{kind=link}
{kind=link}
{kind=link}



Technical Appendix: First safeguard?
This sequence is written to be broadly accessible, although perhaps its focus on capable AI systems assumes familiarity with basic arguments for the importance of AI alignment. The technical appendices are an exception, targeting the technically inclined.
Why do I claim that an impact measure would be "the first proposed safeguard which maybe actually stops a powerful agent with an imperfect [LW · GW] objective from ruining things – without assuming anything about the objective"?
The safeguard proposal shouldn't have to say "and here we solve this opaque, hard problem, and then it works". If we have the impact measure, we have the math, and then we have the code.
So what about:
- Quantilizers? This seems to be the most plausible alternative; mild optimization and impact measurement share many properties. But
- What happens if the agent is already powerful? A greater proportion of plans could be catastrophic, since the agent is in a better position to cause them.
- Where does the base distribution come from (opaque, hard problem?), and how do we know it's safe to sample from?
- In the linked paper, Jessica Taylor suggests the idea of learning a human distribution over actions – how robustly would we need to learn this distribution? How numerous are catastrophic plans, and what is a catastrophe, defined without reference to our values in particular? (That definition requires understanding impact!)
- Value learning [? · GW]? But
- We only want this if our (human) values are learned!
- Value learning is impossible without assumptions, and getting good enough assumptions could be really hard [? · GW]. If we don't know if we can get value learning / reward specification right, we'd like safeguards which don't fail because value learning goes wrong. The point of a safeguard is that it can catch you if the main thing falls through; if the safeguard fails because the main thing does, that's pointless.
- We only want this if our (human) values are learned!
- Corrigibility? At present, I'm excited about this property because I suspect it has a simple core principle. But
- Even if the system is responsive to correction (and non-manipulative, and whatever other properties we associate with corrigibility), what if we become unable to correct it as a result of early actions (if the agent "moves too quickly", so to speak)?
- Paul Christiano's take on corrigibility is much broader and an exception to this critique.
- What is the core principle?
- Even if the system is responsive to correction (and non-manipulative, and whatever other properties we associate with corrigibility), what if we become unable to correct it as a result of early actions (if the agent "moves too quickly", so to speak)?
Notes
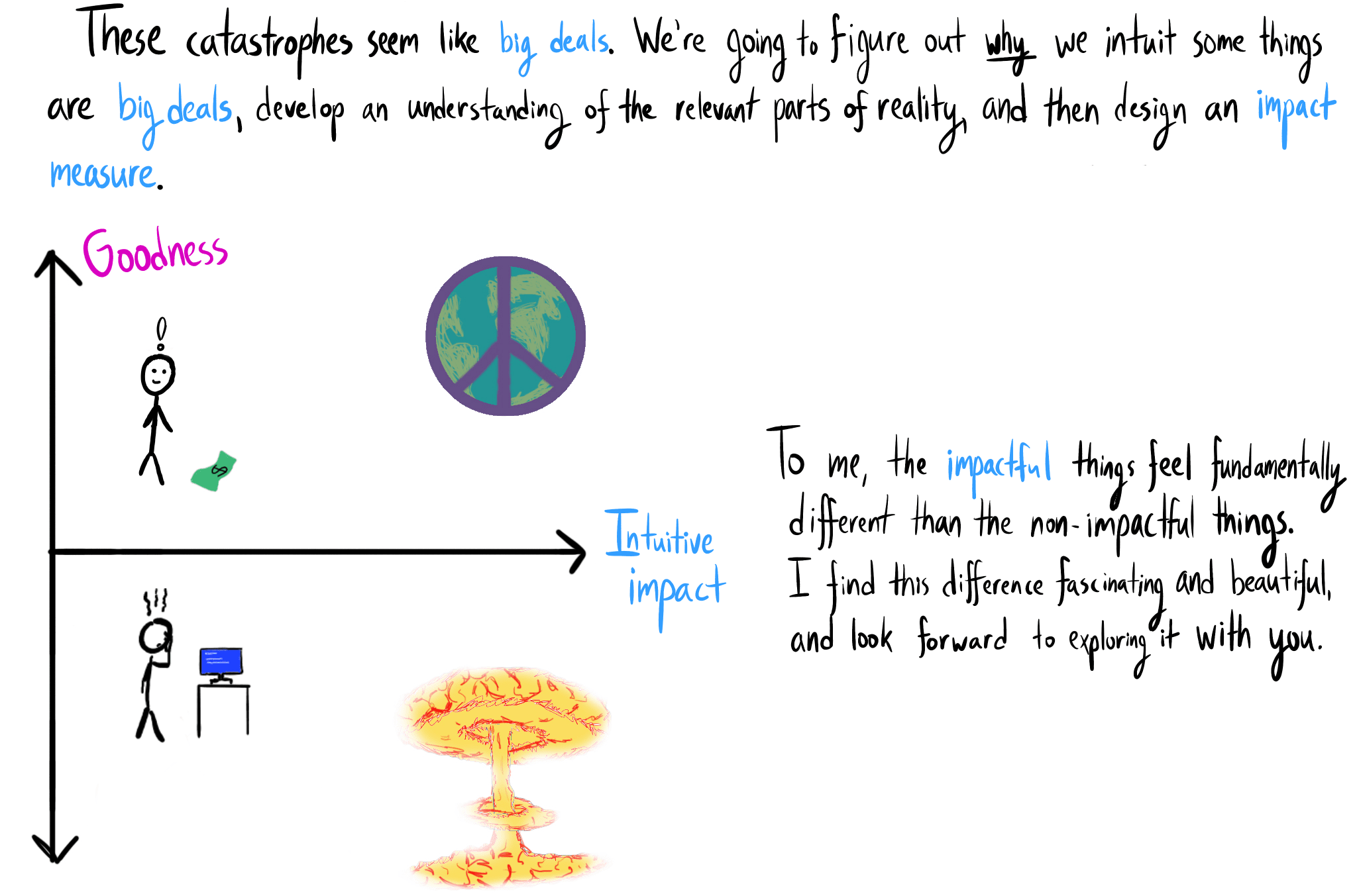
- The three sections of this sequence will respectively answer three questions:
- Why do we think some things are big deals?
- Why are capable goal-directed AIs incentivized to catastrophically affect us by default?
- How might we build agents without these incentives?
- The first part of this sequence focuses on foundational concepts crucial for understanding the deeper nature of impact. We will not yet be discussing what to implement.
- I strongly encourage completing the exercises. At times you shall be given a time limit; it’s important to learn not only to reason correctly, but with speed.
The best way to use this book is NOT to simply read it or study it, but to read a question and STOP. Even close the book. Even put it away and THINK about the question. Only after you have formed a reasoned opinion should you read the solution. Why torture yourself thinking? Why jog? Why do push-ups?
If you are given a hammer with which to drive nails at the age of three you may think to yourself, "OK, nice." But if you are given a hard rock with which to drive nails at the age of three, and at the age of four you are given a hammer, you think to yourself, "What a marvellous invention!" You see, you can't really appreciate the solution until you first appreciate the problem.
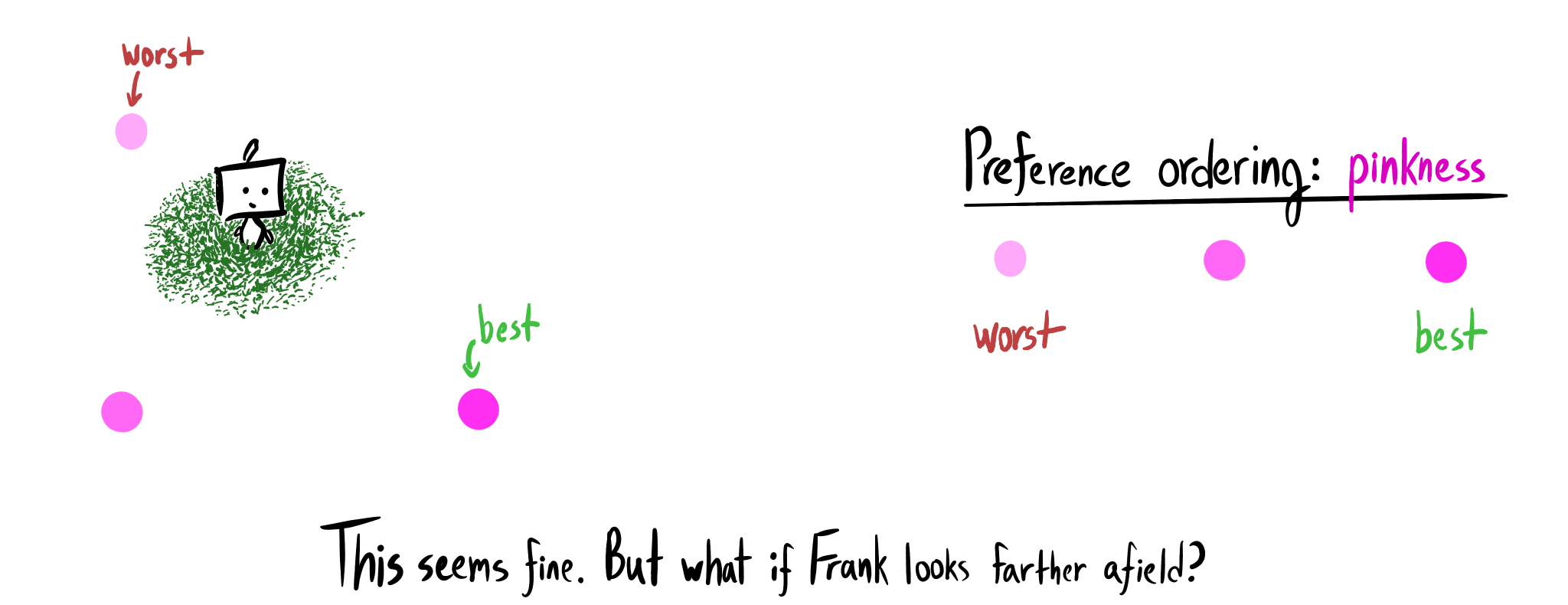
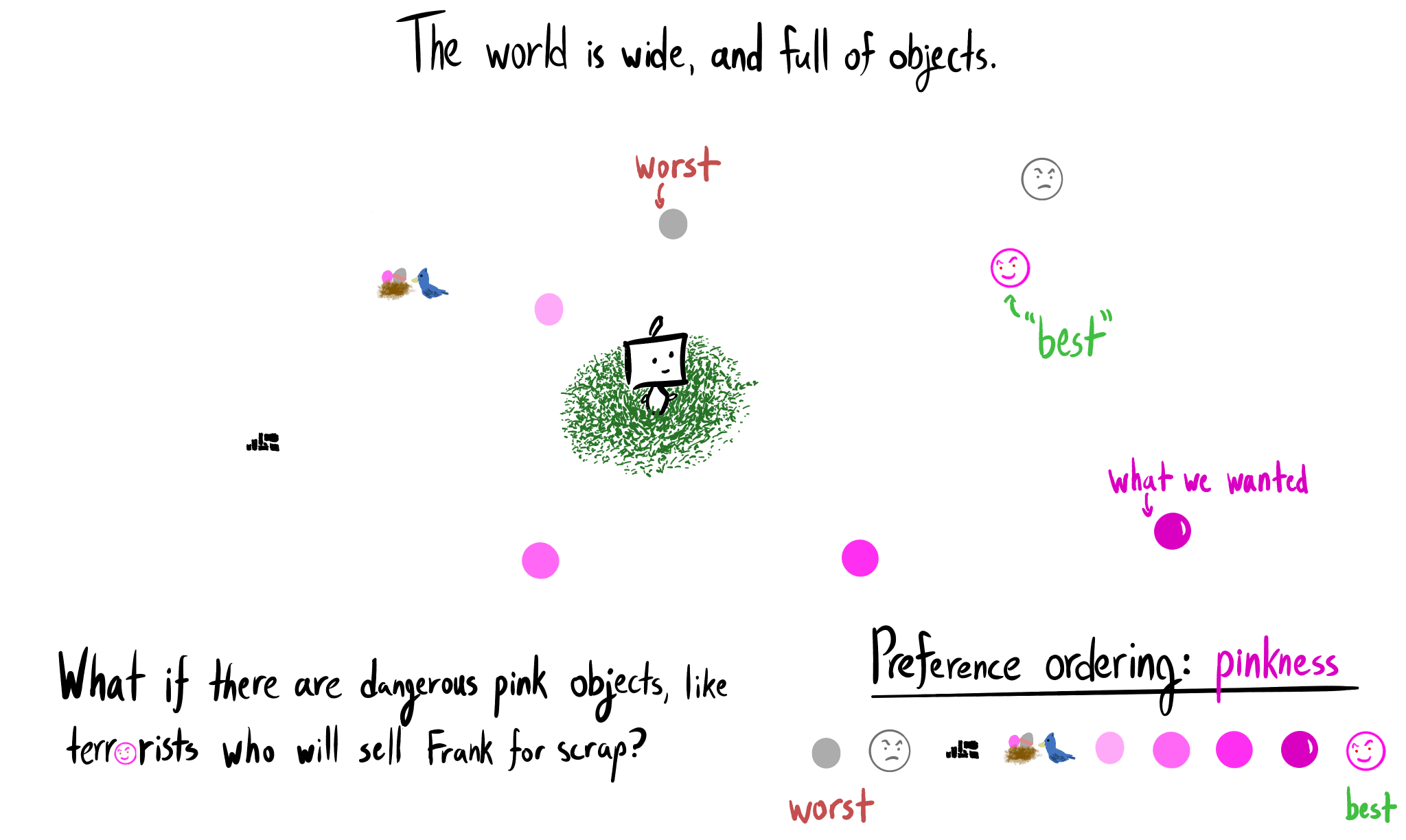
- My paperclip-Balrog illustration is metaphorical: a good impact measure would hold steadfast against the daunting challenge of formally asking for the right thing from a powerful agent. The illustration does not represent an internal conflict within that agent. As water flows downhill, an impact-penalizing Frank prefers low-impact plans.
- The drawing is based on gonzalokenny's amazing work.
- Some of you may have a different conception of impact; I ask that you grasp the thing that I’m pointing to. In doing so, you might come to see your mental algorithm is the same. Ask not “is this what I initially had in mind?”, but rather “does this make sense as a thing-to-call-'impact'?”.
- H/T Rohin Shah for suggesting the three key properties. Alison Bowden contributed several small drawings and enormous help with earlier drafts.
15 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2020-03-03T19:55:04.112Z · LW(p) · GW(p)
Promoted to curated: I really liked this sequence. I think in many ways it has helped me think about AI Alignment from a new perspective, and I really like the illustrations and the way it was written, and how it actively helped me along the way thing actively about the problems, instead of just passively telling me solutions.
Now that the sequence is complete, it seemed like a good time to curate the first post in the sequence.
comment by [deleted] · 2019-09-20T22:38:11.510Z · LW(p) · GW(p)
I enjoyed the post and in particular really liked the illustrated format. Definitely planning to read the rest!
I'm now wishing more technical blog posts were illustrated like this...
Replies from: Raemon↑ comment by Raemon · 2019-09-20T22:57:37.911Z · LW(p) · GW(p)
Checking that you've read the Embedded Agency sequence [? · GW]?
Replies from: None↑ comment by [deleted] · 2019-09-21T01:33:27.951Z · LW(p) · GW(p)
Yup, I have (and the untrollable mathematician one). I dashed off that comment but really meant something like, "I hope this trend takes off."
Replies from: ramana-kumar↑ comment by Ramana Kumar (ramana-kumar) · 2019-10-22T14:53:51.965Z · LW(p) · GW(p)
One misgiving I have about the illustrated format is that it's less accessible than text. I hope the authors of work in this format keep the needs of a wide variety of readers in mind.
Replies from: TurnTroutcomment by Rohin Shah (rohinmshah) · 2020-12-02T18:57:56.139Z · LW(p) · GW(p)
I'm nominating the entire sequence because it's brought a lot of conceptual clarity to the notion of "impact", and has allowed me to be much more precise in things I say about "impact".
comment by Logan Riggs (elriggs) · 2020-12-09T23:29:51.567Z · LW(p) · GW(p)
This post (or sequence of posts) not only gave me a better handle on impact and what that means for agents, but it also is a concrete example of de-confusion work. The execution of the explanations gives an "obvious in hindsight" feeling, with "5-minute timer"-like questions which pushed me to actually try and solve the open question of an impact measure. It's even inspired me to apply this approach to other topics in my life that had previously confused me; it gave me the tools and a model to follow.
And, the illustrations are pretty fun and engaging, too.
comment by Zack_M_Davis · 2019-09-22T03:35:22.125Z · LW(p) · GW(p)
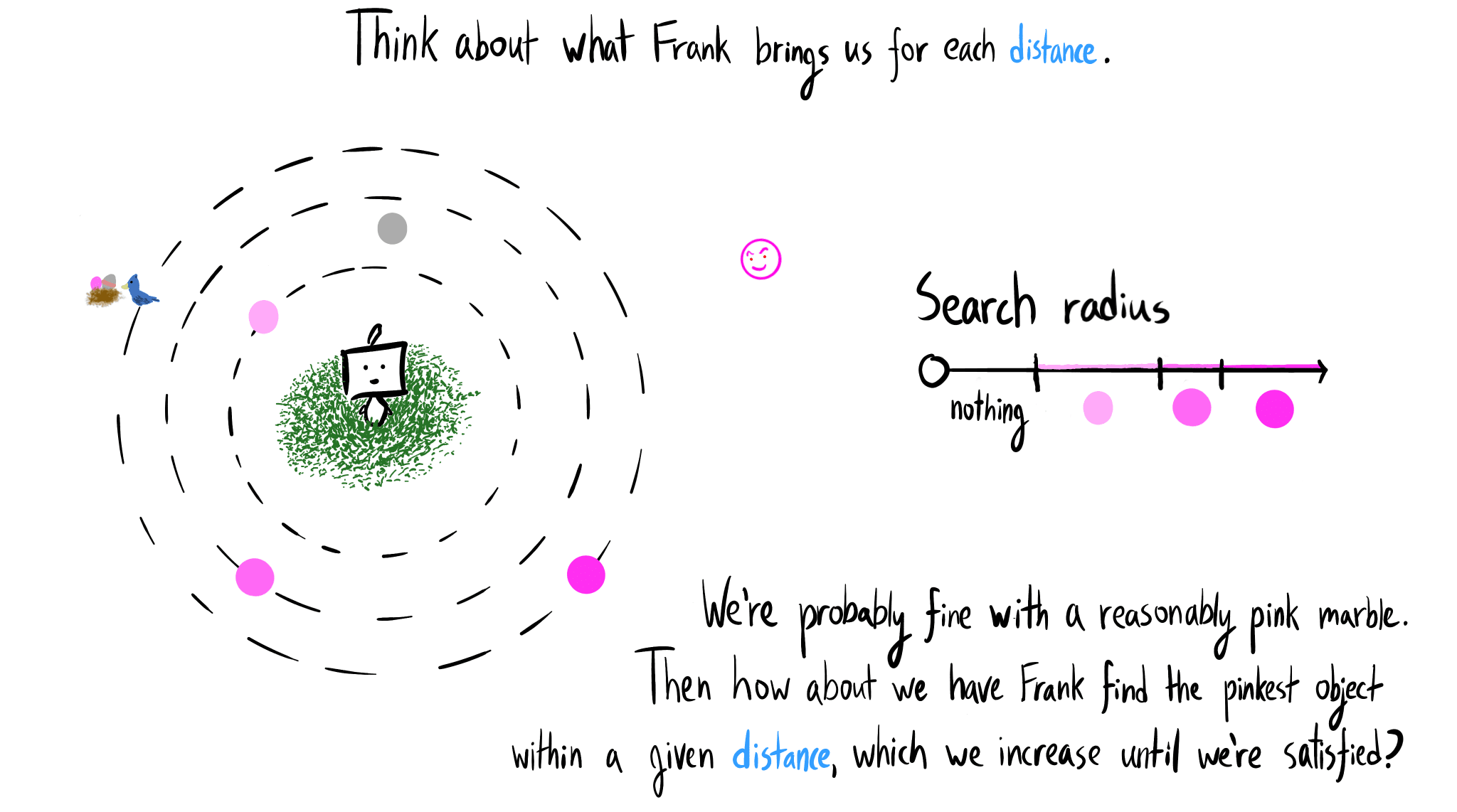
(I was briefly confused by the "Think about what Frank brings us for each distance" "slide" because it doesn't include the pinkest marble: I saw the second-pinkest marble (on the largest dotted circle) thinking that it was meant to be the pinkest (because it's rightmost on the "Search radius" legend) and was like, "Wait, why is the pinkest marble closer than the terrorist in this slide when it was farther away in the previous slide?")
Replies from: TurnTroutcomment by Bird Concept (jacobjacob) · 2021-01-09T23:46:29.575Z · LW(p) · GW(p)
Here are prediction questions for the predictions that TurnTrout himself provided in the concluding post of the Reframing Impact sequence [LW · GW].
comment by sayan · 2019-09-21T06:49:04.336Z · LW(p) · GW(p)
I think this post is broadly making two claims -
-
Impactful things fundamentally feel different.
-
A good Impact Measure should be designed in a way that it strongly safeguards against almost any imperfect objective.
It is also (maybe implicitly) claiming that the three properties mentioned completely specify a good impact measure.
I am looking forward to reading the rest of the sequence with arguments supporting these claims.
Replies from: TurnTrout↑ comment by TurnTrout · 2019-09-21T15:53:17.192Z · LW(p) · GW(p)
It is also (maybe implicitly) claiming that the three properties mentioned completely specify a good impact measure.
I don't know that I'd claim that these completely specify a good impact measure, but I'd imagine most impact measures satisfying these properties are good (i.e. natural curves fit to those three points end up pretty good, I think).
comment by Gurkenglas · 2019-09-21T10:32:39.015Z · LW(p) · GW(p)
I propose to measure impact by counting bits of optimization power, as in my Oracle question contest submission. Find some distribution over plans we might use if we didn't have an AI, such as stock market trading policies. Have the AI output a program that outputs plans according to some distribution. Measure impact by computing a divergence between the two distributions, such as the maximum pointwise quotient - if no plan becomes more than twice as likely, that's no more than one bit of optimization power. Note that the AI is incentivized to prove its output's impact bound to some dumb proof checker. If the AI cuts away the unprofitable half of policies, that is more than enough to get stupid rich.