Dissolving Confusion around Functional Decision Theory
post by scasper · 2020-01-05T06:38:41.699Z · LW · GW · 24 commentsContents
Summary Getting Up to Speed 1. Acknowledging One’s own Predictability Questions in decision theory are not questions about what choices you should make with some sort of unpredictable free will. They are questions about what type of source code you should be running. 2. When a Predictor is Subjunctively Entangled with an Agent I should consider predictor P to “subjunctively depend” on agent A to the extent that P makes predictions of A’s actions based on correlations that cannot be confounded by my choice of what source code A runs. Additional Topics Going Meta Why Roko’s Basilisk is Nonsense Conclusion None 26 comments
Summary
Functional Decision Theory (FDT), (see also causal, evidential, timeless, updateless, and anthropic decision theories) recommends taking cooperative, non-greedy actions in twin prisoners dilemmas, Newcombian problems, Parfit’s hitchhiker-like games, and counterfactual muggings [LW · GW] but not smoking lesion situations. It’s a controversial concept with important implications for designing agents that have optimal behavior when embedded in environments in which they may potentially interact with models of themselves. Unfortunately, I think that FDT is sometimes explained confusingly and misunderstood by its proponents and opponents alike. To help dissolve confusion about FDT and address key concerns of its opponents, I refute the criticism that FDT assumes that causation can happen backward in time and offer two key principles that provide a framework for clearly understanding it:
- Questions in decision theory are not questions about what choices you should make with some sort of unpredictable free will. They are questions about what type of source code you should be running.
- I should consider predictor P to “subjunctively depend” on agent A to the extent that P makes predictions of A’s actions based on correlations that cannot be confounded by my choice of what source code A runs.
Getting Up to Speed
I think that functional decision theory (FDT) is a beautifully counterintuitive and insightful framework for instrumental rationally. I will not make it my focus here to talk about what it is and what types of situations it is useful in. To gain a solid background, I recommend this post of mine or the original paper on it by Eliezer Yudkowsky and Nate Soares.
Additionally, here are four different ways that FDT can be explained. I find them all complimentary for understanding and intuiting it well.
- The decision theory that tells you to act as if you were setting the output to an optimal decision-making process for the task at hand.
- The decision theory that has you cooperate in situations similar to a prisoners’ dilemma against a model of yourself--including when your opponent locks in their choice and shows it to you before you make yours.
- The decision theory that has you one-box it in situations similar to Newcombian games--including when the boxes are transparent; see also Parfit’s Hitchhiker.
- The decision theory that shifts focus from what type of decisions you should make to what type of decision-making agent you should be.
I’ll assume a solid understanding of FDT from here on. I’ll be arguing in favor of it, but it’s fairly controversial. Much of what inspired this post was an AI Alignment Forum post called A Critique of Functional Decision Theory [AF · GW] by Will MacAskill which raised several objections to FDT. Some of his points are discussed below. The rest of this post will be dedicated to discussing two key principles that help to answer criticisms and dissolve confusions around FDT.
1. Acknowledging One’s own Predictability
Opponents of FDT, usually proponents of causal decision theory (CDT), will look at a situation such as the classic Newcombian game and reason as so:
I can choose to one-box it and take A or two-box it and take A+B. Regardless of the value of A, A+B is greater, so it can only be rational to take both. After all, when I’m sitting in front of these boxes, what’s in them is already in them regardless of the choice I make. The functional decision theorist’s perspective requires assuming that causation can happen backwards in time! Sure, one-boxers might do better at these games, but non-smokers do better in smoking lesion problems. That doesn’t mean they are making the right decision. Causal decision theorists may be dealt a bad hand in Newcombian games, but it doesn’t mean they play it badly.
The problem with this argument, I’d say, is subtle. I actually fully agree with the perspective that for causal decision theorists, Newcombian games are just like smoking lesion problems. I also agree with the point that causal decision theorists are dealt a bad hand in these games but don’t play it badly. The problem with the argument is some subtle confusion about the word ‘choice’ plus how it says that FDT assumes that causation can happen backwards in time.
The mistake that a causal decision theorist makes isn’t in two-boxing. It’s in being a causal decision theorist in the first place. In Newcombian games, the assumption that there is a highly-accurate predictor of you makes it clear that you are, well, predictable and not really making free choices. You’re just executing whatever source code you’re running. If this predictor thinks that you will two-box it, your fate is sealed and the best you can do is then to two-box it. The key is to just be running the right source code. And hence the first principle:
Questions in decision theory are not questions about what choices you should make with some sort of unpredictable free will. They are questions about what type of source code you should be running.
And in this sense, FDT is actually just what happens when you use causal decision theory to select what type of source code you want to enter a Newcombian game with. There’s no assumption that causation can occur backwards. FDT simply acknowledges that the source code you’re running can have a, yes, ***causal*** effect on what types of situations you will be presented with when models of you exist. FDT, properly understood, is a type of meta-causal theory. I, in fact, lament that FDT was named "functional" and not "meta-causal."
Instead of FDT assuming causal diagrams like these:

It really only assumes ones like these:
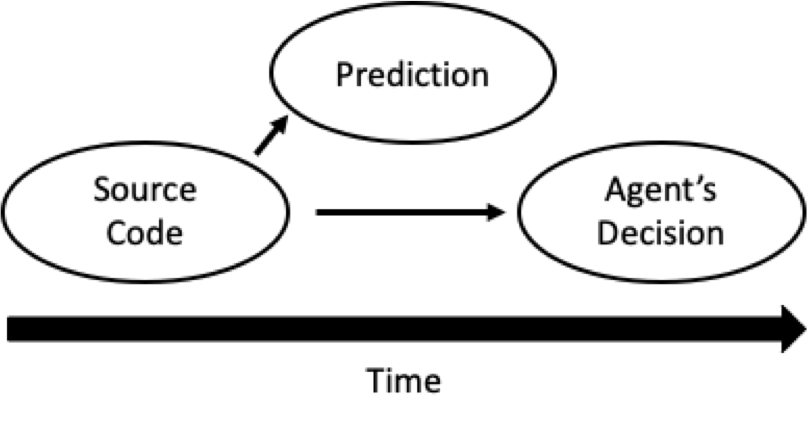
I think that many proponents of FDT fail to make this point: FDT’s advantage is that it shifts the question to what type of agent you want to be--not misleading questions of what types of “choices” you want to make. But this isn’t usually how functional decision theorists explain FDT, including Yudkowsky and Soares in their paper. And I attribute some unnecessary confusion and misunderstandings like “FDT requires us to act as if causation happens backward in time,” to it.
To see this principle in action, let’s look at a situation presented by Will MacAskill. It’s similar to a Newcombian game with transparent boxes. And I say “similar” instead of “isomorphic” because of some vagueness which will be discussed soon. MacAskill presents this situation as follows:
You face two open boxes, Left and Right, and you must take one of them. In the Left box, there is a live bomb; taking this box will set off the bomb, setting you ablaze, and you certainly will burn slowly to death. The Right box is empty, but you have to pay $100 in order to be able to take it.
A long-dead predictor predicted whether you would choose Left or Right, by running a simulation of you and seeing what that simulation did. If the predictor predicted that you would choose Right, then she put a bomb in Left. If the predictor predicted that you would choose Left, then she did not put a bomb in Left, and the box is empty.
The predictor has a failure rate of only 1 in a trillion trillion. Helpfully, she left a note, explaining that she predicted that you would take Right, and therefore she put the bomb in Left.
You are the only person left in the universe. You have a happy life, but you know that you will never meet another agent again, nor face another situation where any of your actions will have been predicted by another agent. What box should you choose?
Macaskill claims that you should take right because it results in a “guaranteed payoff”. Unfortunately, there is some vagueness here about what it means for a long-dead predictor to have run a simulation of you and for it to have an error rate of one in a trillion trillion. Is this simulation true to your actual behavior? What type of information about you did this long dead predictor have access to? What is the reference class for the error rate?
Let’s assume that your source code was written long ago, that the predictor understood how it functioned, that it ran a true-to-function simulation, and that you were given an unaltered version of that source code. Then this situation isomorphic to a transparent-box Newcombian game in which you see no money in box A (albeit more dramatic), and the confusion goes away! If this is the case then there are only two possibilities.
- You are a causal decision theorist (or similar), the predictor made a self-fulfilling prophecy by putting the bomb in the left box alongside a note, and you will choose the right box.
- You are a functional decision theorist (or similar), the predictor made an extremely rare, one in a trillion-trillion mistake, and you will unfortunately take the left box with a bomb (just as a functional decision theorist in a transparent box Newcombian game would take only box A).
So what source code would you rather run when going into a situation like this? Assuming that you want to maximize expected value and that you don’t value your life at more than 100 trillion trillion dollars, then you want to be running the functional decision theorist’s source code. Successfully navigating this game, transparent-box Newcombian games, twin-opponent-reveals-first prisoners’ dilemmas, Parfit’s Hitchiker situations, and the like all require you have source code that would tell you to commit to making the suboptimal decision in the rare case in which the predictor/twin made a mistake.
Great! But what if we drop our assumptions? What if we don’t assume that this predictor’s simulation was functionally true to your behavior? Then it becomes unclear how this prediction was made, and what the reference class of agents is for which this predictor is supposedly only wrong one in a trillion trillion times. And this leads us to the second principle.
2. When a Predictor is Subjunctively Entangled with an Agent
An alternate title for this section could be “when statistical correlations are and aren’t mere.”
As established above, functional decision theorists need not assume that causation can happen backwards in time. Instead, they only need to acknowledge that a prediction and an action can both depend on an agent’s source code. This is nothing special whatsoever: an ordinary correlation between an agent and predictor that arises from a common factor: the source code.
However, Yudkowsky and Soares give this type of correlation a special name in their paper: subjunctive dependence. I don’t love this term because it gives a fancy name to something that is not fancy at all. I think this might be responsible for some of the confused criticism that FDT assumes that causation can happen backward in time. Nonetheless, “subjunctive dependence” is at least workable. Yudkowsky and Soares write:
When two physical systems are computing the same function, we will say that their behaviors “subjunctively depend” upon that function.
This concept is very useful when a predictor actually knows your source code and runs it to simulate you. However, this notion of subjunctive dependence isn’t very flexible and quickly becomes less useful when a predictor is not doing this. And this is a bit of a problem that MacAskill pointed out. A predictor could make good predictions without potentially querying a model of you that is functionally equivalent to your actions. He writes:
...the predictor needn’t be running your algorithm, or have anything like a representation of that algorithm, in order to predict whether you’ll one box or two-box. Perhaps the Scots tend to one-box, whereas the English tend to two-box. Perhaps the predictor knows how you’ve acted prior to that decision. Perhaps the Predictor painted the transparent box green, and knows that’s your favourite colour and you’ll struggle not to pick it up. In none of these instances is the Predictor plausibly doing anything like running the algorithm that you’re running when you make your decision. But they are still able to predict what you’ll do. (And bear in mind that the Predictor doesn’t even need to be very reliable. As long as the Predictor is better than chance, a Newcomb problem can be created.)
Here, I think that MacAskill is getting at an important point, but one that’s hard to see clearly with the wrong framework. On its face though, there’s a significant problem with this argument. Suppose that in Newcombian games, 99% of brown-eyed people one-boxed it, and 99% of blue-eyed people two-boxed it. If a predictor only made its prediction based on your eye color, then clearly the best source code to be running would be the kind that always made you two-box it regardless of your eye color. There’s nothing Newcombian, paradoxical, or even difficult about this case. And pointing out these situations is essentially how critics of MacAskill’s argument have answered it. Their counterpoint is that unless the predictor is querying a model of you that is functionally isomorphic to your decision making process, then it is only using “mere statistical correlations,” and subjunctive dependence does not apply.
But this counterpoint and Yudkoswky and Soares’ definition of subjunctive dependence miss something! MacAskill had a point. A predictor need not know an agent’s decision-making process to make predictions based on statistical correlations that are not “mere”. Suppose that you design some agent who enters an environment with whatever source code you gave it. Then if the agent’s source code is fixed, a predictor could exploit certain statistical correlations without knowing the source code. For example, suppose the predictor used observations of the agent to make probabilistic inferences about its source code. These could even be observations about how the agent acts in other Newcombian situations. Then the predictor could, without knowing what function the agent computes, make better-than-random guesses about its behavior. This falls outside of Yudkowsky and Soares’ definition of subjunctive dependence, but it has the same effect.
So now I’d like to offer my own definition of subjunctive dependence (even though still, I maintain that the term can be confusing, and I am not a huge fan of it).
I should consider predictor P to “subjunctively depend” on agent A to the extent that P makes predictions of A’s actions based on correlations that cannot be confounded by my choice of what source code A runs.
And hopefully, it’s clear why this is what we want. When we remember that questions in decision theory are really just questions about what type of source code we want to enter an environment using, then the choice of source code can only affect predictions that depend in some way on the choice of source code. If the correlation can’t be confounded by the choice of source code, the right kind of entanglement to allow for optimal updateless behavior is present.
Additional Topics
Going Meta
Consider what I call a Mind Police situation: Suppose that there is a powerful mind policing agent that is about to encounter agent A and read its mind (look at its source code). Afterward, if the mind policer judges A to be using decision theory X, they will destroy A. Else they will do nothing.
Suppose that decision theory X is FDT (but it could be anything) and that you are agent A who happens to use FDT. If you were given the option of overwriting your source code to implement some alternative, tolerated decision theory, would you? You’d be better off if you did, and it would be the output of an optimal function for the decision making task at hand, but it’s sort of unclear whether this is a very functional decision theorist thing to do. Because of situations like these, I think that we should consider decision theories to come in two flavors: static which will never overwrite itself, and autoupdatable, which might.
Also, note that the example above is only a first-order version of this type of problem, but there are higher-order ones too. For example, what if the mind police destroyed agents using autoupdatable decision theories?
Why Roko’s Basilisk is Nonsense
A naive understanding of FDT has led some people to ask whether a superintelligent sovereign, if one were ever developed, would be rational to torture everyone who didn’t help to bring it into existence. The idea would be that this sovereign might consider this to be part of an updateless strategy to help it come into existence more quickly and accomplish its goals more effectively.
Fortunately, a proper understanding of subjunctive dependence tells us that an optimally-behaving embedded agent doesn’t need to pretend that causation can happen backward in time. Such a sovereign would not be in control of its source code, and it can’t execute an updateless strategy if there was nothing there to not-update on in the first place before that source code was written. So Roko’s Basilisk is only an information hazard if FDT is poorly understood.
Conclusion
It's all about the source code.
24 comments
Comments sorted by top scores.
comment by Shmi (shminux) · 2020-01-05T22:23:19.352Z · LW(p) · GW(p)
Questions in decision theory are not questions about what choices you should make with some sort of unpredictable free will. They are questions about what type of source code you should be running.
indeed. It is actually worse than that, because the "should be" part is already in your source code. In the setup
A long-dead predictor predicted whether you would choose Left or Right, by running a simulation of you and seeing what that simulation did.
it is meaningless to ask
What box should you choose?
since the answer is already set (known to the long-dead predictor). A self-consistent question is "what did the predictor predict that you will do?" Anything else would be sneaking the free will into the setup.
comment by gjm · 2020-01-05T15:20:35.485Z · LW(p) · GW(p)
In the bomb example, it looks to me as if you have some bits backwards. I could be misunderstanding and I could have missed some, so rather than saying what I'll just suggest that you go through double-checking where you've written "left", "right", "empty", etc.
Replies from: scaspercomment by Rohin Shah (rohinmshah) · 2020-01-20T01:48:15.083Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post argues for functional decision theory (FDT) on the basis of the following two principles:
1. Questions in decision theory are not about what "choice" you should make with your "free will", but about what source code you should be running.
2. P "subjunctively depends" on A to the extent that P's predictions of A depend on correlations that can't be confounded by choosing the source code that A runs.
Planned opinion:
I liked these principles, especially the notion that subjunctive dependence should be cashed out as "correlations that aren't destroyed by changing the source code". This isn't a perfect criterion: FDT can and should apply to humans as well, but we _don't_ have control over our source code.Replies from: scasper
↑ comment by scasper · 2020-01-22T07:17:30.638Z · LW(p) · GW(p)
Thanks for the comment. I think it's exciting for this to make it into the newsletter. I am glad that you liked these principles.
I think that even lacking a concept of free will, FDT can be conveniently thought of applying to humans through the installation of new habits or ways of thinking without conflicting with the framework that I aim to give here. I agree that there are significant technical difficulties in thinking about when FDT applies to humans, but I wouldn't consider them philosophical difficulties.
comment by Chris_Leong · 2022-07-20T02:41:48.029Z · LW(p) · GW(p)
I guess we seem to differ on whether CDT dealt a bad hand vs. playing it badly. CDT, as usually argued for, doesn’t seem to engage with the artificial nature of counterfactuals, and I suspect that when you engage with consideration this won't lead to CDT.
Questions in decision theory are not questions about what choices you should make with some sort of unpredictable free will. They are questions about what type of source code you should be running.
This seems like a reasonable hypothesis, but I have to point out that there’s something rather strange in imagining a situation where we make a decision outside of the universe, I think we should boggle at this using CFAR’s term. Indeed I agree that if we accept the notion of a meta-decision theory that FDT does not invoke backwards causation (elegant explanation btw!).
Comparing this to my explanation, [LW · GW] we both seem to agree that there are two separate views - in your terms an "object" view and an "agent" view. I guess my explanation is based upon the "agent" view being artificial and it is more general as I avoid making too many assumptions about what exactly a decision is, while your view takes on an additional assumption (that we should model decisions in a meta-causal way) in exchange for being more concrete and easier to grasp/explain.
With your explanation, however, I do think you elided over this point too quickly, as it isn't completely clear what's going on there/why that makes sense:
FDT is actually just what happens when you use causal decision theory to select what type of source code you want to enter a Newcombian game with
There’s a sense in which this is self-defeating b/c if CDT implies that you should pre-commit to FDT, then why do you care what CDT recommends as it appears to have undermined itself?
My answer is that even though it appears this way, I don’t actually think it is self-defeating and this becomes clear when we consider this as a process of engaging in reflective equilibrium until our views are consistent. CDT doesn’t recommend itself, but FDT does, so this process leads us to replace our initial starting assumption of CDT with FDT.
In other words, we're engaging in a form of circular epistemology as described here [LW · GW]. We aren't trying to get from the View from Nowhere to a model of counterfactuals - to prove everything a priori like Decartes - instead all we can do is start of with some notions, beliefs or intuitions about counterfatuals and then make them consistent. I guess I see making these mechanics explicit useful.
In particular, by making this move it seems as though, at least on the face of it, that we are embracing the notion that counterfactuals only make sense from within themselves [LW · GW].
I'm not claiming at this stage that it is in fact correct to shift from CDT to FDT as part of the process of reflective equilibrium as it is possible to resolve inconsistencies in a different order, with different assumptions held fixed, but this is plausibly the correct way to proceed. I guess the next step would be to map out the various intuitions that we have about how to handle these kinds of situations and then figure out if there are any other possible ways of resolving the inconsistency.
↑ comment by scasper · 2022-07-20T21:36:49.690Z · LW(p) · GW(p)
in your terms an "object" view and an "agent" view.
Yes, I think that there is a time and place for these two stances toward agents. The object stance when we are thinking about how behavior is deterministic conditioned on a state of the world and agent. The agent stance for when we are trying to be purposive and think about what types of agents to be/design. If we never wanted to take the object stance, we couldn't successfully understand many dilemmas, and if we never wanted to take the agent stance, then there seems little point in trying to talk about what any agent ever "should" do.
There’s a sense in which this is self-defeating b/c if CDT implies that you should pre-commit to FDT, then why do you care what CDT recommends as it appears to have undermined itself?
I don't especially care.
counterfactuals only make sense from within themselves
Is naive thinking about the troll bridge problem a counterexample to this? There, the counterfactual stems from a contradiction.
CDT doesn’t recommend itself, but FDT does, so this process leads us to replace our initial starting assumption of CDT with FDT.
I think that no general type of decision theory worth two cents always does recommend itself. Any decision theory X that isn't silly would recommend replacing itself before entering a mind-policing environment in which the mind police punishes an agent iff they use X.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2022-07-20T23:25:58.756Z · LW(p) · GW(p)
Yes, I think that there is a time and place for these two stances toward agents
Agreed. The core lesson for me is that you can't mix and match - you need to clearly separate out when you are using one stance or another.
I don't especially care.
I can understand this perspective, but perhaps if there's a relatively accessible way of explaining why this (or something similar to this) isn't self-defeating, then maybe we should go with that?
Is naive thinking about the troll bridge problem a counterexample to this? There, the counterfactual stems from a contradiction.
I don't quite your point. Any chance you could clarify? Like sure we can construct counterfactuals within an inconsistent system and sometimes this may even be a nifty trick for getting the right answer if we can avoid the inconsistency messing us up, but outside of this, why is this something that we should we care about this?
I think that no general type of decision theory worth two cents always does recommend itself
Good point, now that you've said it I have to agree that I was too quick to assume that the outside-of-the-universe decision theory should be the same as the inside-of-the-universe decision theory.
Thinking this through, if we use CDT as our outside decision theory to pick an inside decision theory, then we need to be able to justify why we were using CDT. Similarly, if we were to use another decision theory.
One thing I've just realised is that we don't actually have to use CDT, EDT or FDT to make our decision. Since there's no past for the meta-decider, we can just use our naive decision theory which ignores the past altogether. And we can justify this choice based on the fact that we are reasoning from where we are. This seems like it would avoid the recursion.
Except I don't actually buy this, as we need to be able to provide a justification of why we would care about the result of a meta-decider outside of the universe when we know that isn't the real scenario. I guess what we're doing is making an analogy with inside the universe situations where we can set the source code of a robot before it goes and does some stuff. And we're noting that a robot probably has a good algorithm if its code matches what a decider would choose if they had to be prepared for a wide variety of circumstances and then trying to apply this more broadly.
I don't think I've got this precise yet, but I guess the key point is that this model doesn't appear out of thin air, but that the model has a justification and that this justification involves a decision and hence some kind of decision theory where the actual decision is inside of the universe. So there is after all a reason to want the inside and outside theories to match up.
Replies from: scasper↑ comment by scasper · 2022-07-21T02:22:10.509Z · LW(p) · GW(p)
Any chance you could clarify?
In the troll bridge problem, the counterfactual (the agent crossing the bridge) would indicate the inconsistency of the agent's logical system of reasoning. See this post [LW · GW] and what demski calls a subjective theory of counterfactuals [LW · GW].
comment by Isnasene · 2020-01-05T21:06:23.470Z · LW(p) · GW(p)
The mistake that a causal decision theorist makes isn’t in two-boxing. It’s in being a causal decision theorist in the first place. In Newcombian games, the assumption that there is a highly-accurate predictor of you makes it clear that you are, well, predictable and not really making free choices. You’re just executing whatever source code you’re running. If this predictor thinks that you will two-box it, your fate is sealed and the best you can do is then to two-box it. The key is to just be running the right source code.
So my concern with FDT (read: not a criticism, just something I haven't been convinced of yet) is that there is some a priori "right" source-code that we can choose in advance before we go into a situation. This is because, while we may sometimes benefit from having source-code A that leads predictor Alpha to a particular conclusion in one situation, we may also sometimes prefer source-code B that leads predictor Beta to a different conclusion. If we don't know how likely it is that we'll run into Alpha relative to Beta, we then have no idea what source-code we should adopt (note that I say adopt because, obviously, we can't control the source-code we were created with). My guess is that , somewhere out there, there's some kind of No-Free-Lunch theorem that shows this for embedded agents
Moreover, (and this relates to your Mind-crime example), I think that in situations with sometimes adversarial predictors who do make predictions based on non-mere correlations with your source-code, there is a pressure for agents to make these correlations as weak as possible.
For instance, consider the following example of how decision theory can get messy. It's basically a construction where Parfit's Hitchiker situations are sometimes adversarially engineered based on performing a Counterfactual Mugging on agent decision theory.
Predictor Alpha
Some number of Predictor Alpha exists. Predictor Alpha's goal is to put you in a Parfit's Hitchhiker situation and request that, once you're safe, you pay a yearly 10% tithe to Predictor Alpha for saving you.
If you're an agent running CDT, it's impossible for Alpha to do this because you cannot commit to paying the tithe once you're safe. This is true regardless of whether you know that Alpha is adversarial. As a result, you never get put in these situations.
If you're an agent running FDT and you don't know that Alpha is adversarial, Alpha can do this. If you do know though, you do fine because FDT will just pre-commit to performing CDT if it thinks a Parfit's Hitchiker situation has been caused adversarially. But this just incenvitizes Alpha to make it very hard to tell whether it's adversarial (and, compared to making accurate predictions about behavior in Hitchiker problems, this seems relatively easy). The easiest FDT solution in this case is to just make Predictor Alpha think you're running CDT or actually run CDT.
Note though that if FDT agents are incentivized to eliminate non-mere correlatins between "implementing FDT" and "what Alpha predicts", this applies to any predictor working off the same information as Alpha. This has consequences.
Predictor Beta
Some number of Predictor Beta exists. Predictor Beta makes money by finding people who get stuck in Parfit's Hitchhiker situations and helping them out in exchange for a 10% yearly tithe. Given that Predictor Alpha also exists...
If you're an agent running CDT, who knows what happens? Predictor Beta is, of course, making predictions based on non-mere correlations with your source-code but, because of Predictor Alphas, FDT and CDT agents look really similar! Maybe, Predictor Beta figures you're just a secret FDT agent and you get away with making unguaranteed precommitment.
Ditto with agents running FDT. Maybe you fool Predictor Beta just as much as you fool Predictor Alpha and Beta assumes you're running CDT. Maybe not.
Predictor Gamma
We might also introduce Predictor Gamma, who is altruistic and helps all CDT agents out of the goodness of their heart but tries to get some payment from FDT agents since they might be extortable. However, because Gamma knows that FDT agents will pretend to be CDT or refuse to precommit to get the altruistic benefit (and Gamma believes beggars can't be choosers), Gamma also resolves to just let FDT agents which are unwilling to precommit die.
Now, the FDT agent has two options
1. Prevent Gamma from being accurate by eliminating Gamma's ability to idenfity the genuine capacity to make guaranteed precommitments. This comes at the cost of eliminating non-mere correlations between FDT source code and other predictions that others might make about guaranteed precommitment. This throws away a lot of the benefit of FDT though.
2. Update to CDT.
What if we assume the predictors are really smart and we can't eliminate non-mere correlations?
In this case, FDT agents have to actually decide whether to continue being FDT (and risk meeting with Predictor Alpha) or actually, truly, update to CDT (and risk being abandoned by Predictor Beta). Personally, I would lean towards the latter because, if accurate predictors exist, it seems more likely that I would be adversarially placed in a Parfit's Hitchhiker situation than it would be that I'd accidentally find myself in one.
But maybe FDT still is better?!
So the above thought experiments ignore the possibility that Predictors Alpha or Beta may offer CDT agents the ability to make binding precommitments a la FDT. Then Alpha could adversarially put a CDT agent in a Parfit's Hitchhiker situation and get the CDT agent to update to making a binding precommitment. In contrast, an FDT agent could just avoid this completely by commting their source-code to a single adjustment: never permit situations ensuring binding pre-commitments. But this obviously has a bunch of drawbacks in a bunch of situations too.
Replies from: scasper↑ comment by scasper · 2020-01-06T03:32:03.009Z · LW(p) · GW(p)
I really like this analysis. Luckily, with the right framework, I think that these questions, though highly difficult, are technical but no longer philosophical. This seems like a hard question of priors but not a hard question of framework. I speculate that in practice, an agent could be designed to adaptively and non-permanently modify its actions and source code to slick past many situations, fooling predictors exploiting non-mere correlations when helpful.
But on the other hand, maybe a way to induce a great amount of uncertainty to mess up certain agents, you could introduce a set of situations like this to them.
For a few of my thoughts on these situations, I also wrote this post on Medium. https://medium.com/@thestephencasper/decision-theory-ii-going-meta-5bc9970bd2b9. However, I'm sure you've thought more in depth about these issues than this post goes. I think that the example of mind policing predictors is sufficient to show that there is no free lunch in decision theory. for every decision theory, there is a mind police predictor that will destroy it.
Replies from: Isnasene↑ comment by Isnasene · 2020-01-06T05:39:33.678Z · LW(p) · GW(p)
I really like this analysis. Luckily, with the right framework, I think that these questions, though highly difficult, are technical but no longer philosophical. This seems like a hard question of priors but not a hard question of framework.
Yes -- I agree with this. It turns the question "What is the best source-code for making decisions when the situations you are placed on depend on that source-code?" into a question more like"Okay, since there are a bunch of decisions that are contingent on source-code, which ones do we expect to actually happen and with what frequency?" And this is something we can, in principle, reason about (ie, we can speculate on what incentives we would expect predictors to have and try to estimate uncertainties of different situations happening).
I speculate that in practice, an agent could be designed to adaptively and non-permanently modify its actions and source code to slick past many situations, fooling predictors exploiting non-mere correlations when helpful.
I'm skeptical of this. Non-mere correlations are consequences of an agent's source-code producing particular behaviors that the predictor can use to gain insight into the source-code itself. If an agent adaptively and non-permanently modifies its souce-code, this (from the perspective of a predictor who suspects this to be true), de-correlates it's current source code from the non-mere correlations of its past behavior -- essentially destroying the meaning of non-mere correlations to the extent that the predictor is suspicious.
Maybe there's a clever way to get around this. But, to illustrate the problem with a claim from your blog:
For example, a dynamic user of CDT could avoid being destroyed by a mind reader with zero tolerance for CDT by modifying its hardware to implement EDT instead.
This is true for a mind reader that is directly looking at source code but is untrue for predictions relying on non-mere correlations. To such a predictor, a dynamic user of CDT who has just updated to EDT would have a history of CDT behavior and non-mere correlations associated mostly with CDT. Now two things might happen:
1. The predictor classifies the agent as CDT and kills it
2. The predictor classifies the agent as a dynamic user of CDT, predicts that it has updated to EDT, and does not kill it.
Option 1 isn't great because the agent gets killed. Option 2 also isn't great because it implies predictors have access to non-mere correlations strong enough to indicate that a given agent can dynamically update. This is risky because now any predictor that leverages these non-mere correlations to conclude that another agent is dynamic can potentially benefit for adversarially pushing that agent to modify to a more exploitable source-code. For example, a predictor might want to make the agent believe that it kills all agents it predicts aren't EDT but, in actuality, doesn't care about that and just subjects all the new EDT agents to XOR blackmail.
There's also other practical concerns. For instance, an agent capable of self-modifying its source-code is in principle capable of guaranteeing a precommitment by modifying part of its code to catastrophically destruct the agent if the agent either doesn't follow through on the precommitment or appears to be attacking that code-piece. This is similar to the issue I mention in my "But maybe FDT is still better?!" section. It might be advantageous to just make yourself incapable of being put in adversarial Parfit's Hitchhiker situations in advance.
I think that the example of mind policing predictors is sufficient to show that there is no free lunch in decision theory. for every decision theory, there is a mind police predictor that will destroy it.
On one hand this is true. On the other, I personally shy away from mind-police type situations because they can trivially be applied to any decision theory. I think, when I mentioned No-Free Lunch for decision theory, it was in reference specifically to Non-Mere Correlation Management strategies in our universe as it currently exists.
For instance, given certain assumptions, we can make claims about which decision theories are good. For instance, CDT works amazingly well in the class of universes where agents know the consequences of all their actions. FDT (I think) works amazingly well in the class of universes where agents know how non-merely correlated their decisions are to events in the universe but don't know why those correlations exist.
But I'm not sure if, in our actual universe FDT is a practically better thing to do than CDT. Non-mere correlations only really pertain to predictors (ie other agents) and I'd expect the perception of Non-mere correlations to be very adversarially manipulated: "Identifying non-mere correlations and decorrelating them" is a really good way to exploit predictors and "creating the impression that correlations are non-mere" is a really good way for predictors to exploit FDT.
Because of this, FDT strikes me as performing better than CDT in a handful of rare scenarios but may overall be subjected to some no-free-lunch theorem that applies specifically to the kind of universe that we are in. I guess that's what I'm thinking about here.
Replies from: scasper↑ comment by scasper · 2020-01-06T17:20:25.932Z · LW(p) · GW(p)
I'm skeptical of this. Non-mere correlations are consequences of an agent's source-code producing particular behaviors that the predictor can use to gain insight into the source-code itself. If an agent adaptively and non-permanently modifies its souce-code, this (from the perspective of a predictor who suspects this to be true), de-correlates it's current source code from the non-mere correlations of its past behavior -- essentially destroying the meaning of non-mere correlations to the extent that the predictor is suspicious.
Oh yes. I agree with what you mean. When I brought up the idea about an agent strategically acting certain ways or overwriting itself to confound the predictions that adversarial predictors, I had in mind that the correlations that such predictors used could be non-mere w.r.t. the reference class of agents these predictors usually deal but still confoundable by our design of the agent and thereby non mere to us.
For instance, given certain assumptions, we can make claims about which decision theories are good. For instance, CDT works amazingly well in the class of universes where agents know the consequences of all their actions. FDT (I think) works amazingly well in the class of universes where agents know how non-merely correlated their decisions are to events in the universe but don't know why those correlations exist.
+1 to this. I agree that this is the right question to be asking, that it depends on a lot of assumptions about how adversarial an environment is, and that FDT does indeed seem to have some key advantages.
Also as a note, sorry for some differences in terminology between this post and the one I linked to on my Medium blog.
comment by [deleted] · 2023-02-19T16:11:44.429Z · LW(p) · GW(p)
I may just be missing something here, but how does the choice of source code work in the "decisions are the result of source code" ontology? It seems like it creates an infinite regression problem.
If I'm able to make the choice about what my source code is which determines my future decisions then it seems like a CDT/EDT agent will do exactly the same thing as an FDT one and choose the source code that gets good results in Newcomb problems etc.
But if the source code I choose is a result of my previous source code which is a result of my previous source code etc it seems like you get infinite recursion.
Replies from: Vladimir_Nesov, green_leaf↑ comment by Vladimir_Nesov · 2023-02-19T16:43:05.469Z · LW(p) · GW(p)
You don't choose source code, you only choose what sort of source code it is, how it behaves, what's predictable about it. You choose the semantics that describes it. Or the code determines the semantics that describes it, it determines how it behaves, in this framing you are the source code. The effects of the source code (on predictions about it, on outcomes of actions taken by agents running it) vary with its possible behavior, not with the code itself.
Replies from: None↑ comment by [deleted] · 2023-02-19T16:53:13.022Z · LW(p) · GW(p)
There are two options for my source code: {pay up after being picked up in deserts, don't pay up after being picked up in deserts}. What does the source code ontology say about how I pick which of these source codes to run and how does it differ from the EDT ontology of choice? Or is this question framed incorrectly?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-02-19T17:31:18.898Z · LW(p) · GW(p)
Consider a space of possible partial behaviors of the code (traces/lists/sequences of facts/details that could've been established/observed/decided by some point in code's interpretation/running, but also infinite traces from all always, and responses to some/all possible and impossible observations). Quotiented by some equivalence. The actual behavior is some point in that space. The code itself could be reframed as an operator acting on this space, computing more details from the details that have been established so far, with the actual behavior being the least fixpoint of that operator, starting from the least informative point (partial behavior). Semantics of programming languages, especially in denotational tradition, can look somewhat like this. The space of partial behaviors is often called a domain (or matches some technical definition of a thing called a domain).
So the possible ontology of decision making with a fixed source code is reframing it as deciding which point of the domain it determines. That is, the only thing being decided by an agent in this ontology is the point of the domain, and everything else that happens as a result is a consequence of that, because predictors or implementations or static analyses depend on which point in the domain the code's semantics determines.
↑ comment by green_leaf · 2023-02-19T16:18:21.867Z · LW(p) · GW(p)
You can choose what your source code is in the following sense: If you pick A, your source code will have been such that you picked A. If you pick B, your source code will have been such that you picked B.
Replies from: None↑ comment by [deleted] · 2023-02-19T16:49:43.769Z · LW(p) · GW(p)
This seems like what choosing always is with a compatibilist understanding of free will? EDT seems to work with no problems with combtablism about free will.
Replies from: green_leaf↑ comment by green_leaf · 2023-02-26T20:32:53.174Z · LW(p) · GW(p)
Unless I'm wrong, EDT will right-box if there is a visible bomb in the left box (all agents who discover a bomb in the left box and take left box get less utility than those who take the right box), but FDT (correctly) wouldn't.
comment by Heighn · 2022-01-20T08:56:39.608Z · LW(p) · GW(p)
For example, suppose the predictor used observations of the agent to make probabilistic inferences about its source code. These could even be observations about how the agent acts in other Newcombian situations. Then the predictor could, without knowing what function the agent computes, make better-than-random guesses about its behavior. This falls outside of Yudkowsky and Soares’ definition of subjunctive dependence, but it has the same effect.
No, it doesn't fall outside Yudkowsky and Soares’ definition of subjunctive dependence. The observations about how the agent acts in other Newcombian situations still depend on the agent's decision procedure. The connection with the predictor is less direct, but the original subjunctive dependence is still there. I wrote a full post on this here [LW · GW].
Replies from: scasper