My Current Take on Counterfactuals
post by abramdemski · 2021-04-09T17:51:06.528Z · LW · GW · 57 commentsContents
Summary. What does it mean to pass Troll Bridge? The Subjective Theory of Counterfactuals Permissive CDT Question: tiling theory for PCDT? The Inferential Theory of Counterfactuals I think the inferential theory is probably wrong. Walking the Line Between CDT and EDT Question: Verify/explore this. Question: how can we avoid this pathology? Question: Performance on other decision problems? Applications to Alignment Why Study This? Conclusion None 57 comments
[Epistemic status: somewhat lower confidence based on the fact that I haven't worked out a detailed theory along the lines I've suggested, yet.]
I've felt like the problem of counterfactuals is "mostly settled" (modulo some math working out) for about a year, but I don't think I've really communicated this online. Partly, I've been waiting to write up more formal results. But other research has taken up most of my time, so I'm not sure when I would get to it.
So, the following contains some "shovel-ready" problems. If you're convinced by my overall perspective, you may be interested in pursuing some of them. I think these directions have a high chance of basically solving the problem of counterfactuals (including logical counterfactuals).
Another reason for posting this rough write-up is to get feedback: am I missing the mark? Is this not what counterfactual reasoning is about? Can you illustrate remaining problems with decision problems?
I expect this to be much more difficult to read than my usual posts. It's a brain-dump. I make a lot of points which I have not thought through sufficiently. Think of it as a frozen snapshot of a work in progress.
Summary.
- I can Dutch-book any agent [AF · GW] whose subjective counterfactual expectations don't equal their conditional expectations. I conclude that counterfactual expectations should equal conditional probabilities. IE, evidential decision theory (EDT) gives the correct counterfactuals.
- However, the Troll Bridge [AF · GW] problem is real and concerning: EDT agents are doing silly things here.
- Fortunately, there appear to be ways out. One way out is to maintain that subjective counterfactual expectations should equal conditional expectations while also maintaining a distinction between those two things: counterfactuals are not computed from conditionals. As we shall see, this allows us to ensure that the two are always equal in real situations, while strategically allowing them to differ in some hypothetical situations (such as Troll Bridge). This seems to solve all the problems!
- However, I have not yet concretely constructed any way out. I include detailed notes on open questions and potential avenues for success.
What does it mean to pass Troll Bridge?
It’s important to briefly clarify the nature of the goal. First of all, Troll Bridge really relies on the agent “respecting logic” in a particular sense.
- Learning agents who don’t reason logically, such as RL agents, can be fooled by a troll who punishes exploration. However, that doesn’t seem to get at the point of Troll Bridge [AF · GW]. It just seems like an unfair problem, then.
- The first test of “real Troll Bridge” is: does the example make crossing totally impossible? Or does it depend on the agent’s starting beliefs?
- If the probabilistic troll bridge [AF · GW] only concluded that you won’t cross if you have a sufficiently high probability that PA is inconsistent, this would come off as totally reasonable rather than insane. It's a refusal to cross regardless of prior which seems so problematic.
- If an RL agent starts out thinking crossing is good, then this impression will continue to be reinforced (if the troll is only punishing exploration). Such an example only shows that some RL agents cannot cross, due to the combination of low prior expectation that crossing is good, and exploration being punished. This is unfortunate, and illustrates a problem with exploration if exploration can be detected by the environment; but it is not as severe a problem as Troll Bridge proper.
- The second test is whether we can strengthen the issue to 100% failure while still having a sense that the agent has a way out, if only it would take it. In the RL example, we can strengthen the exploration-punisher by also punishing unjustified crossing more generally, in the sense of crossing without an empirical history of successful crosses to generalize from. If your prior suggests crossing is bad, you’ll be punished every time you cross because it’s exploration. If your prior suggests crossing is good, you’ll be punished every time you cross because your pro-crossing stance is not empirically justified. So no agents are rewarded for crossing. This passes the first test of “real Troll Bridge”. But there is no longer any sense that the agent is crazy. In original Troll Bridge, there’s a strong intuition that “the agent could just cross, and all would be well”. Here, there is nothing the agent can possibly do.
- The first test of “real Troll Bridge” is: does the example make crossing totally impossible? Or does it depend on the agent’s starting beliefs?
- Secondly, an agent could reason logically but with some looseness [AF · GW]. This can fortuitously block the Troll Bridge proof. However, the approach seems worryingly unprincipled, because we can “improve” the epistemics by tightening the relationship to logic, and get a decision-theoretically much worse result.
- The problem here is that we have some epistemic principles which suggest tightening up is good (it’s free money; the looser relationship doesn’t lose much, but it’s a dead-weight loss), and no epistemic principles pointing the other way. So it feels like an unprincipled exception: “being less dutch-bookable is generally better, but hang loose in this one case, would you?”
- Naturally, this approach is still very interesting, and could be pursued further -- especially if we could give a more principled reason to keep the observance of logic loose in this particular case. But this isn’t the direction this document will propose. (Although you could think of the proposals here as giving more principled reasons to let the relationship with logic be loose, sort of.)
- So here, we will be interested in solutions which “solve troll bridge” in the stronger sense of getting it right while fully respecting logic. IE, updating to probability 1 (/0) when something is proven (/refuted).
There is another “easy” way to pass Troll Bridge, though: just be CDT. (By CDT, I don't mean classical causal decision theory -- I mean decision theory which uses any notion of counterfactuals, be it based on physical causality, logical causality, or what-have-you.)
The Subjective Theory of Counterfactuals
Sam presented Troll Bridge as an argument in favor of CDT. For a long time, I regarded this argument with skepticism: yes, CDT allows us to solve it, but what is logical causality?? What are the correct counterfactuals?? I was incredulous that we could get real answers to such questions, so I didn’t accept CDT as a real answer.
I gradually came to realize that Sam didn’t see us as needing all that. For him, counterfactuals were simply a more general framework, a generality which happened to be needed to encode what humans see as the correct reasoning.
Look at probability theory as an analogy.
If you were trying to invent the probability axioms, you would be led astray if you thought too much about what the “objectively correct” beliefs are for any given situation. Yes, there is a very interesting question of what the prior should be, in Bayesianism. Yes, there are things we can say about “good” and “bad” probability distributions for many cases. However, it was important that at some point someone sat down and worked out the theory of probability under the assumption that those questions were entirely subjective, and the only objective things we can say about probabilities are the basic coherence constraints, such as P(~A)=1-P(A), etc.
Along similar lines, the subjectivist theory of counterfactuals holds that we have been led astray by looking too hard for some kind of correct procedure for taking logical counterfactuals. Instead, starting from the assumption that a very broad range of counterfactuals can be subjectively valid, we should seek the few “coherence” constraints which distinguish rational counterfactual beliefs from irrational.
In this perspective, getting Troll Bridge right isn’t particularly difficult. The Troll Bridge argument is blocked at the step where [the agent proves that crossing implies bad stuff] implies [the agent doesn’t cross]. The agent’s counterfactual expected value for crossing can still be high, even if it has proven that crossing is bad. Counterfactuals have a lot of freedom to be different from what you might expect, so they don’t have to respect proofs in that way.
Following the analogy to probability theory, we still want to know what the axioms are. How are rational counterfactual beliefs constrained?
I’ll call the minimalist approach “Permissive CDT”, because it makes a strong claim that "almost any" counterfactual reasoning can be subjectively valid (ie, rational):
Permissive CDT
What I’ll call “Permissive CDT” (PCDT) has the following features:
- There is a basic counterfactual conditional, C(A|B).
- This counterfactual conditional obeys the axiom C(A|B)&B -> A.
- There may be additional axioms, but they are weak enough to allow 2-boxing in Newcomb as subjectively valid.
- There is no chicken rule or forced exploration rule; agents always take the action which looks counterfactually best.
Note that this isn’t totally crazy. C(A|B)&B -> A means that counterfactuals had better take the actual world to the actual world. This means a counterfactual hypothesis sticks its neck out, and can be disproven if B is true (so, if B is an action, we can make it true in order to test).
Note that I've excluded exploration from PCDT. This means we can't expect as strong of a learning result as we might otherwise. However, with exploration, we would eventually take disastrous actions. For example, if there was a destroy-the-world button, the agent would eventually press it. So, we probably don't want to force exploration just for the sake of better learning guarantees!
Instead, we want to use "VOI-exploration". This just means: PCDT naturally chooses some actions which are suboptimal in the short term, due to the long-term value of information. (This is just a fancy way of saying that it's worthwhile to do experiments sometimes.) To vindicate this approach, we would want some sort of VOI-exploration result. For example, we may be able to prove that PCDT successfully learns under some restrictive conditions (EG, if it knows no actions have catastrophic consequences). Or, even better, we could characterize what it can learn in the absence of nice conditions (for example, that it explores everything except actions it thinks are too risky).
I claim PCDT is wrong. I think it’s important to set it up properly in order to check that it’s wrong, since belief in some form of CDT is still widespread, and since it’s actually a pretty plausible position. But I think my Dutch Book argument [LW · GW] is fairly damning, and (as I’ll discuss later) I think there are other arguments as well.
Sam advocated the PCDT-like direction for some time, but eventually, he came to agree with my Dutch Book argument. So, I think Sam and I are now mostly on the same page, favoring a version of subjective counterfactuals which requires more EDT-like expectations.
There are a number of formal questions about PCDT which would be useful to answer. This is part of the "shovel-ready" work I promised earlier. The list is quite long; I suggest skipping to the next section on your first read-thru.
Question: further axioms for PCDT? What else might we want to assume about the basic counterfactuals? What can’t we assume? (What assumptions would force EDT-like behavior, clashing with the desideratum of allowing 2-boxing? What assumptions lead to EDT-like failure in Troll Bridge? What assumptions allow/disallow sensible logical counterfactuals? What assumptions force inconsistency?)
- We can formalize PCDT in logical induction, by adding a basic counterfactual to the language.
- We might want counterfactuals to give sensible probability distributions on sentences, so and are mutually exclusive and jointly exhaustive. But we definitely don’t want too many “basic logic” assumptions like that, since it could make counterlogicals undefinable, leading us back to problems taking counterfactuals when we know our own actions.
Question: Explore PCDT and Troll Bridge. Examine which axioms for PCDT are compatible with successfully passing Troll Bridge (in the sense sketched earlier).
Question: Learning theory for PCDT? A learning theory is important for a theory of counterfactuals, because it gives us a story about why we might expect counterfactual reasoning to be correct/useful. If we have strong guarantees about how counterfactual reasoning will come to reflect the true consequences of actions according to the environment, then we can trust counterfactual reasoning. Again, we can formalize PCDT via logical induction. What, then, does it learn? PCDT should have a learning theory somewhat similar to InfraBayes, in the sense of relying on VOI exploration instead of forcing exploration with an explicit mechanism.
- Some sort of no-traps assumption is needed.
- Weak version: assume that the logical inductor is 1-epsilon confident that the environment is trap-free, or something along those lines (and also assume that the true environment is trap-free).
- Strong version: don’t assume anything about the initial beliefs. Show that the agent ends up exploring sufficiently if it believes it’s safe to do so; that is, show that belief in traps is in some sense the only obstacle to exploring enough (and therefore learning). (Provided that the discount rate is near enough to 1, of course; and provided the further learnability assumptions I’ll mention below.)
- Stretch goal: deal with human feedback about whether there are traps, venturing into alignment theory rather than just single-agent decision theory.
- See later section: applications to alignment.
- Some sort of “good feedback” assumption is needed, ensuring that the agent gets enough information about the utility.
- The most obvious thing is to assume an RL environment with discounting, much like the learning theory of InfraBayes.
- It might be interesting to generalize further, having a broader class of utility functions, with feedback which narrows down the utility incrementally. RL is just a special case of this where the discounting rate determines the amount that any given prefix narrows down the ultimate utility.
- Generalizing even further, it could be interesting to abandon the utility as a function of history at all, and instead rely only on subjective expectations (like the Orthodox Case Against Utility Functions [LW · GW] suggests).
- I suspect this is good for the “stretch goal” mentioned previously, of dealing with human feedback about whether there are traps. See later section: applications to alignment.
- Some sort of no-newcomblike assumption is probably needed.
- This is very similar to how Sam’s tiling result [LW · GW] required a no-newcomb assumption, and asymptotic decision theory [LW · GW] required a no-newcomb assumption.
- In other words, a “CDT=EDT” assumption. (A Newcomblike problem is precisely one where CDT and EDT differ.)
- Like the no-traps assumption, there are two different ways to try and do this:
- Weaker: assume the logical inductor is very confident that the environment isn’t Newcomblike.
- Stronger: don’t assume anything, but show that the agent ends up differentiating between hypotheses to the extent it’s possible to do so. Newcomblike hypotheses make payoffs of actions themselves depend on what actions are taken, and so, are impossible to distinguish via experiment alone. But it should be possible to show that, based on VOI exploration, the agent eliminates the eliminable hypotheses, and distinguishes between the rest based on subjective plausibility; and (according to PCDT, but not according to me) this is the best we can hope to do.
- Realizability?
- There should be a good result assuming realizability, at least. And perhaps that’s enough for a start -- it would still be an improvement in our philosophical understanding of counterfactuals, particularly when combined with other results in the research program I’m outlining here.
- But I’m also suspicious that there’s some degree of ability to deal with unrealizable cases.
- The right assumption has to do with there being a trader capable of tracking the environment sufficiently.
- Unlike Bayes or InfraBayes, we don’t have to worry about hypotheses competing; any predictively useful constraint on beliefs will be learned.
- Bayes “has to worry” in the sense that non-realizable cases can create oscillation between hypotheses, due to there not being a unique best hypothesis for predicting the environment. (This might harm decision theory, by oscillating between competing but incompatible strategies.)
- InfraBayes doesn’t seem to have that worry, since it applies to non-realizable cases. (Or does it? Is there some kind of non-oscillation guarantee? Or is non-oscillation part of what it means for a set of environments to be learnable -- IE it can oscillate in some cases?) But InfraBayesian learning is still a one-winner type system, in that we don’t learn all applicable partial models; only the most useful converges to probability 1.
- Logical induction, on the other hand, guarantees that all applicable partial models are learned (in the sense of finitely many violations). But, to what extent can we translate this to a decision-theoretic learning result?
- As an example, I think it should be possible to learn to use a source of randomness in rock-paper-scissors against someone who can perfectly predict your decision, but not the extra randomness.
- I’m imagining discretized choices, so there’s a finite number of options of the form “½ ½ 0”, “1 0 0”, etc.
- If the adversary were only trying to do the best in each round individually, this is basically a multi-armed bandit problem, where the button “play ⅓ ⅓ ⅓” has the best payoff. But we also need to show that the adversary can’t use a long-con strategy to mislead the learning.
- I think one possible proof is to consider a trader who predicts that every option will be at best as good as ⅓ ⅓ ⅓ on average, in the long term. If this trader does poorly, then the adversary must be doing a poor job. If this trader does well, then (because we learn the payoff of ⅓ ⅓ ⅓ correctly for sure) the agent must converge to playing ⅓ ⅓ ⅓. So, either way, the agent must eventually do at least as well as the optimal strategy.
Question: tiling theory for PCDT?
- It seems like this would admit some version of Sam’s tiling result [LW · GW] and/or Diffractor's tiling sketch [LW · GW].
- As with the other results, a major motivation (from where I'm currently sitting) is to show that PCDT is worse than more EDT-like alternatives. I strongly suspect that tiling results for PCDT will be more restrictive than for the decision theory I'm going to advocate for later, precisely because tiling must require a no-newcomb type restriction. PCDT, faced with the possibility of encountering a Newcomblike problem at some point, should absolutely self-modify in some way.
- Also, the tiling result necessarily excludes updateless-type problems, such as counterfactual mugging. None of the proposals considered here will deal with this.
This concludes the list of questions about PCDT. As I mentioned earlier, PCDT is being presented in detail primarily to contrast with my real proposal.
But, before I go into that, I should discuss another theory I don't believe: what I see as the "opposite" of PCDT. My real view will be a hybrid of the two.
The Inferential Theory of Counterfactuals
The inferential theory is what I see as the core intuition behind EDT.
The intuition is this: we should reason about the consequences of actions in the same way that we reason about information which we add to our knowledge.
Another way of putting this is: hypothetical reasoning and counterfactual reasoning are one and the same. By hypothetical reasoning, I mean temporarily adding something to the set of things you know, in order to see what would follow.
In classical Bayesianism, we add new information to our knowledge by performing a Bayesian update. Hence, the inferential theory says that we Bayes-update on possible actions to examine their consequences.
In logic, adding new information means adding a new axiom from which we can derive consequences. So in proof-based EDT (aka MUDT), we examine what we could prove if we added an action to our set of axioms.
So the inferential theory gives us a way of constructing a version of EDT from a variety of epistemic theories, not just Bayesianism.
I think the inferential theory is probably wrong.
Almost any version of the inferential theory will imply getting Troll Bridge wrong, just like proof-based decision theory and Bayesian EDT get it wrong. That’s because the inference [action a implies bad stuff] & [action a] | [bad stuff] is valid. So the Troll Bridge argument is likely to go through.
Jessica Taylor talks about something she calls “counterfactual nonrealism [LW · GW]”, which sounds a lot like what I’m calling the subjective theory of counterfactuals. However, she appears to also wrap up the inferential theory in this one package. I'm surprised she views these theories as being so close. I think they're starting from very different intuitions. Nonetheless, I do think what we need to do is combine them.
Walking the Line Between CDT and EDT
So, I’ve claimed that PCDT is wrong, because any departure from EDT (and thus the inferential theory) is dutch-book-able. Yet, I’ve also claimed that the inferential theory is itself wrong, due to Troll Bridge. So, what do I think is right?
Well, one way of putting it is that counterfactual reasoning should match hypothetical reasoning in the real world, but shouldn’t necessarily match it hypothetically.
This is precisely what we need in order to block the Troll Bridge argument. (At least, that’s one way to block the argument -- there are other steps in the argument we could block.)
As a simple proof of concept, consider a CDT whose counterfactual expectations for crossing and not crossing just so happen to be the same as its evidential expectations, namely, cross = +10, not cross = 0. This isn’t Dutch-bookable, since the counterfactuals and conditionals agree.
In the Troll Bridge hypothetical, we prove that [cross]->[U=-10]. This will make the conditional expectations poor. But this doesn’t have to change the counterfactuals. So (within the hypothetical), the agent can cross anyway. And crossing gets +10. So, the Lobian proof doesn’t go through. Since the proof doesn’t go through, the conditional expectations can also consistently expect crossing to be good; so, we never really see a disparity between counterfactual expectation and conditional expectation.
Now, you might be thinking: couldn’t the troll use the disparity between counterfactual and conditional expectation as its trigger to blow up the bridge? I claim not: the troll would, then, be punishing anyone who made decisions in a way different from EDT. Since we know EDT doesn’t cross, it would be obvious that no one should cross. So we lose the sense of a dilemma in such a version of the problem.
OK, but how do we accomplish this? Where does the nice coincidence between the counterfactuals and evidential reasoning come from, if there’s no internal logic requiring them to be the same?
My intuition is that we want something similar to PCDT, but with more constraints on the counterfactuals. I’ll call this restrictive counterfactual decision theory (RCDT):
- RCDT should have extra constraints on the counterfactual expectations, sufficient to guarantee that the counterfactuals we eventually learn will be in line with the conditional probabilities we eventually learn. IE, the two asymptotically approach each other (at least in circumstances where we have good feedback; probably not otherwise).
- The constraints should not force them to be exactly equal at all times. In particular, the constraints must not force counterfactuals to "respect logic" in the sense that would force failure on Troll Bridge. For example, If implies , then a proof that crossing the bridge is bad could stop us from crossing it. We can't let RCDT do that.
To build intuition, let’s consider how PCDT and RCDT learn in a Newcomblike problem.
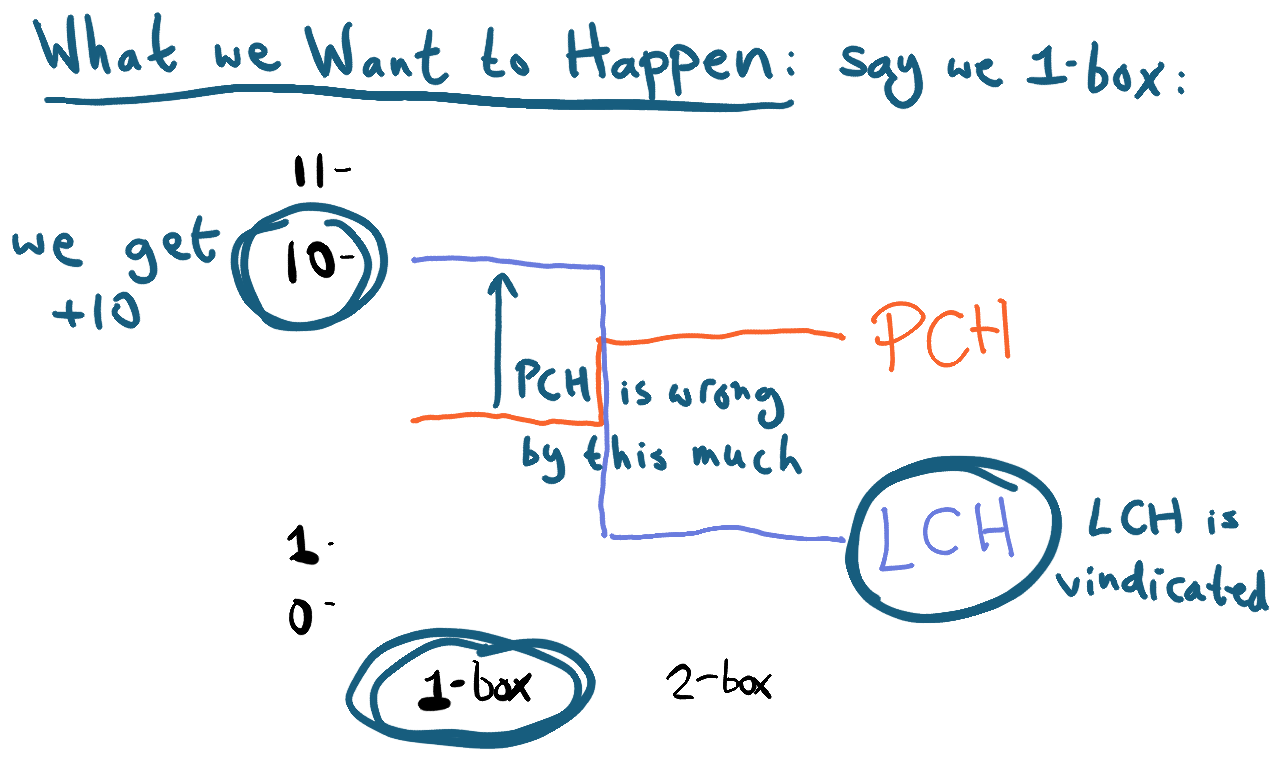
Let’s say we’re in a Newcomb problem where the small box contains $1 and the big box may or may not contain $10, depending on whether a perfect predictor believes that the agent will 1-box.
Suppose our PCDT agent starts out mainly believing the following counterfactuals (using C() for counterfactual expectations, counting just the utility of the current round):
C(U|1-box) = 10 * P(1-box)
C(U|2-box) = 1 + 10 * P(1-box)
In other words, the classic physical counterfactuals. I’ll call this hypothesis PCH for physical causality hypothesis.
We also have a trader who thinks the following:
C(U|1-box) = 10
C(U|2-box) = 1
I’ll call this LCH for logical causality hypothesis.
Now, if the agent’s overall counterfactual expectation (including value for future rounds, which includes exploration value) is quite different for the two actions, then the logical inductor should be quite clear on which action the agent will take (the one with higher utility); and if that’s so, then LCH and PCH will agree quite closely on the expected utility of said action. (They’ll just disagree about the other action.) So little can be learned on such a round. As long as PCH is dominating things, that action would have to be 2-boxing, since an agent who mostly believes PCH would only ever 1-box for the VOI -- and there’s no VOI here, since in this scenario the two hypotheses agree.
But that all seems well and good -- no complaints from me.
Now suppose instead that the overall counterfactual expectation is quite similar for the two actions, to the point where traders have trouble predicting which action will be taken.
In that case, LCH and PCH have quite different expectations:

(even though the x-axis is a boolean variable, I drew lines that are connected across two sides so that one can easily see how the uncertain case is the average of the two certain cases.)
The significant difference in expectations between LCH and PCH in the uncertain case makes it look as if we can learn something. We don’t know which action the agent will actually take, but we do know that LCH ends up being correct about the value of whatever action is taken. So it looks like PCH traders should lose money.
However, that’s not the case.
Because we have a “basic counterfactual” proposition for what would happen if we 1-box and what would happen if we 2-box, and both of those propositions stick around, LCH’s bets about what happens in either case both matter. This is unlike conditional bets, where if we 1-box, then bets conditional on 2-boxing disappear, refunded, as if they were never made in the first place.
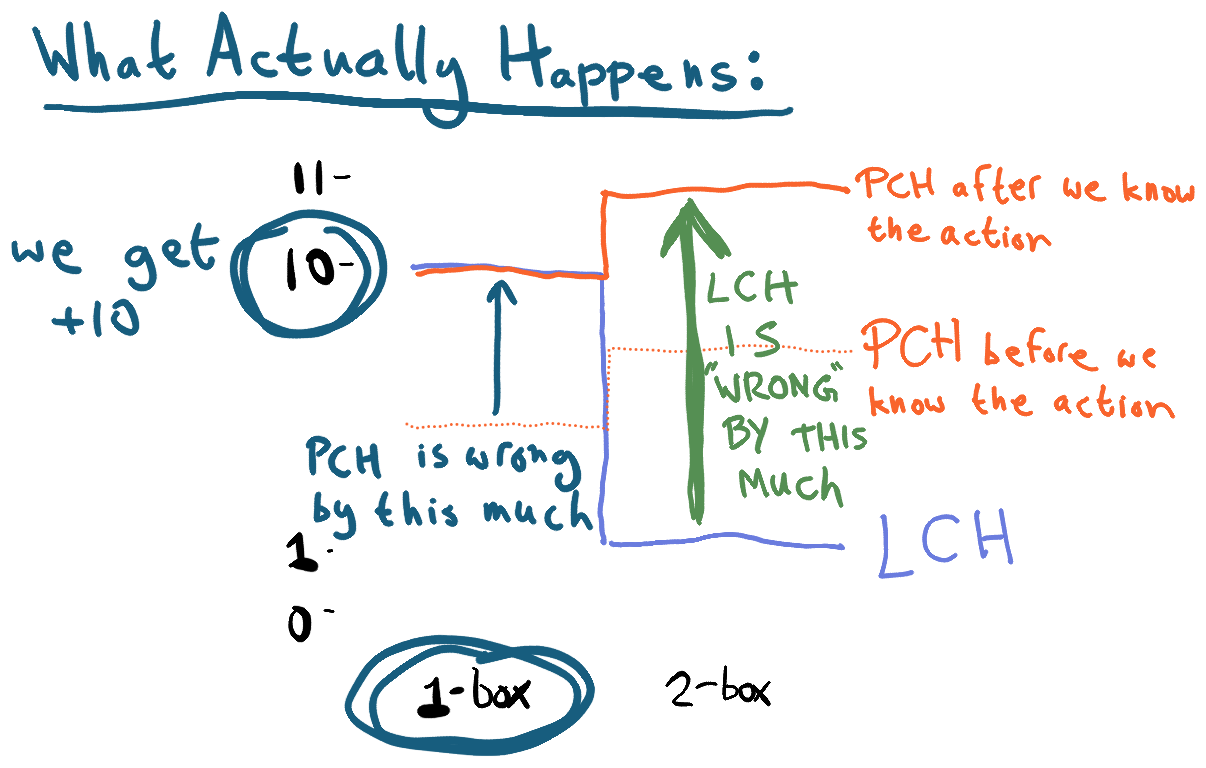
When the logical inductor observes that the agent 1-boxes, and sees the +10, the expected value of that counterfactual payoff must move to +10 (since counterfactuals on what actually happens must match what actually happens). However, the other counterfactual -- the one on 2-boxing -- moves to +11, because PCH is still the dominant belief; the agent learned that it indeed 1-boxed, so, it now believes that it would have received 11 by 2-boxing.
Since 2-boxing is a counterfactual scenario which we’ll never get any solid feedback on, the belief about what reward we could have gotten can stay around 11 forever. Any money LCH bet on a payoff of 1 from 2-boxing is probably lost for good.
So it doesn’t appear that LCH traders can make a profit.
Question: Verify/explore this.
- Can PCDT really favor PCH forever? Is there no LCH strategy which could make profit?
- Does LCH necessarily bleed money, or are there versions of LCH which break even here? Does PCH become increasingly confident, or does it just remain stable?
- Can we give a rational justification for this behavior?
- EG, at one point, Sam claimed that this was a perfectly reasonable epistemic state for an agent who thinks Omega is rewarding it with +10 for exploring (because the only way it gets the +10 from 1-boxing is if it does so for VOI, since it would never do so for the sake of the value it gets in that round), but would not reward it similarly if the action were taken for its own sake (because on non-exploration rounds, the agent thinks the value of 1-boxing would be 0).
- It’s clear that learning is impossible under such a scenario. Yet, this does not necessarily justify a learning rule which lets PCH dominate over LCH forever; we want to be able to learn 5&10 correctly by simply experimenting, and PCH is essentially stopping us from doing that here.
- I’m interested in further thoughts on this. If we adopt a learning rule which doesn’t favor PCH in the scenario given (IE, straight Newcomb), does it then cause pathological behavior in Sam’s scenario (exploration-rewarding Omega)? If so, how concerning is this? Are there alternative arguments in favor of the PCDT learning behavior that I’m calling pathological?
Question: how can we avoid this pathology?
- Option 1: More constraints on counterfactuals.
- Is there some way to add axioms to the PCDT counterfactuals, to make them (A) learn LCH, while still (B) passing Troll Bridge?
- Option 2: Something more like conditional bets.
- The behavior I labelled “want” is like conditional bet behavior.
- However, standard conditional bets won’t quite do it.
- If we make decisions by looking at the conditional probabilities of a logical inductor (as defined by the ratio formula), then these will be responsive to proofs of action->payoff, and therefore, subject to Troll Bridge.
- What we want to do is look at conditional bets instead of raw conditional probabilities, with the hope of escaping the Troll Bridge argument while keeping expectations empirically grounded.
- Normally conditional bets A|B are constructed by betting on A&B, but also hedging against ¬B by betting on that, such that a win on ¬B exactly cancels the loss on A&B.
- In logical induction, such conditional bets must be responsive to a proof of B->A; that is, since B->A means ¬(B&¬A), the bet on A&B must now be worth what a bet on just B would be worth. More importantly, a bet on B&¬A must be worthless, making the conditional probability zero.
- So I see this as a challenge to make “basic” conditional bets, rather than conditional bets derived from boolean combinations as above, and make them such that they aren’t responsive to proofs of B->A like this.
- Intuitively, a conditional bet A|B is just a contract which pays out given A&B, but which is refunded if ¬B.
- I think something like this has even been worked out for logical induction at some point, but Scott and Sam and I weren’t able to quickly reconstruct it when we talked about this.
- (And it was likely responsive to proofs of A->B.)
- A notion of conditional bet which isn’t responsive to A->B isn’t totally crazy, I claim.
- In many cases, the inductor might learn that A->B makes B|A a really good bet.
- But if crossing the bridge never results in a bad outcome in reality, it should be possible to maintain an exception for cross->bad.
- Philosophically, this is a radical rejection of the ratio formula for conditional probability.
- Rejection of the ratio formula has been discussed in the philosophical literature, in part to allow for conditioning on probability-zero events. EG, the Lewis axioms for conditional probabilities.
- As far as I've seen, philosophers still endorse the ratio formula when it meaningfully applies, ie, when you're not dividing by zero. It's just rejected as the definition of conditional probability, since the ratio formula isn't well-defined in some cases where the conditional probabilities do seem well-defined.
- However, I suspect the rejection of the inference from A->B to B|A constitutes a more radical departure than usual.
- We most likely still need the chicken rule here, unlike with basic counterfactuals.
- The desired behavior we’re after here, in order to give LCH an advantage, is to nullify bets in the case that their conditions turn out false. This doesn’t seem compatible with usable conditionals on zero-probability events.
- (But it would be nice if this turned out otherwise!)
- At first it might sound like using chicken rule spells doom for this approach, since chicken rule is the original perpetrator in Troll Bridge. But I think this is not the case.
- In the step in Troll Bridge where the agent examines its own source code to see why it might have crossed, we see that the chicken rule triggered or the agent had higher conditional-contract expectation on crossing. So it’s possible that the agent crosses for entirely the right reason, blocking the argument from going through.
- We could try making the troll punish chicken-rule crossing or crossing based on conditional-contract expectations which differ from the true conditional probabilities; but this seems exactly like the case we examined for PCDT. Crossing because crossing looks like a good idea in some sort of expectation is a good reason to cross; if we deny the agent this possibility, then it just looks like an impossible problem. The troll would just be blowing up the bridge for anyone who doesn’t agree with EDT; but EDT doesn’t cross.
- The desired behavior we’re after here, in order to give LCH an advantage, is to nullify bets in the case that their conditions turn out false. This doesn’t seem compatible with usable conditionals on zero-probability events.
- If this modified-conditional-bet option works out, to what extent does this vindicate the inferential theory of counterfactuals?
- Option 3: something else?
Question: Performance on other decision problems?
- It’s not updateless, so obviously, it can’t get everything. But, EG, how does it do on XOR?
Question: What is the learning theory of the working options? How do they compare?
- If we can get a version which favors LCH in the iterated Newcomb example, then the learning theory should be much like what I outlined for PCDT, with the exception of the no-newcomb clause.
- It would be great to get a really good picture of the differences in optimality conditions for the different alternatives. EG, PCDT can’t learn when it’s suspicious of Newcomblike situations. But perhaps RCDT can’t seriously maintain the hypothesis that Omega is tricking it on exploration rounds specifically (as Sam conjectured at one point), while PCDT can; so there may be some class of situations where, though neither can learn, PCDT has an advantage in terms of being able to perform well if it wins the correct-belief lottery.
Question: What is the tiling theory of the working options? How do they compare?
- Like PCDT, RCDT should have some tiling proof along the lines of Sam’s tiling result and/or Diff's tiling sketch.
- Again, it would be interesting to get a really good comparison between the options.
- I suspect that PCDT has really poor tiling in Newcomblike situations, whereas RCDT does not. I really want that result, to show the strength of RCDT on tiling grounds.
Applications to Alignment
Remember how Sam’s tiling theorem requires feedback on counterfactuals? That’s implausible for a stand-alone agent, since you don’t get to see what happens for untaken actions. But if we consider an agent getting feedback from a human, suddenly it becomes plausible.
However, human feedback does have some limitations.
- It should be sparse. A human doesn’t want to give feedback on every counterfactual for every decision. But the human could focus attention on counterfactual expectations which look very wrong.
- Humans aren’t great at giving reward-type feedback. (citation: I’ve heard this from people at CHAI, I think.)
- Humans are even worse at giving full-utility feedback.
- This would require humans to evaluate what’s likely to happen in the future, from a given state.
- So, we have to come up with feedback models which could work for humans.
- Simpler models like non-sparse human feedback on (counterfactual) rewards could still be developed for the sake of incremental progress, of course.
- One model I think is unrealistic but interesting: humans providing better and better bounds for overall expected utility. This is similar to providing rewards (because a reward bounds the utility), but also allows for providing some information about the future (humans might be able to see that a particular choice would destroy such and such future value).
- Approval feedback is easier for humans to give, although approval learning doesn’t so much allow the agent to use its own decision theory (and especially, its own world model and planning).
- Obviously some of Vanessa’s work provides relevant options to consider.
- Simpler models like non-sparse human feedback on (counterfactual) rewards could still be developed for the sake of incremental progress, of course.
- As Vanessa has pointed out, this can help deal with traps (provided the supervisor has good information about traps in some sense). This is obviously a major factor in the theory, since traps are part of what blocks nice learning-theoretic results.
- I would like to consider options which allow for human value uncertainty.
- One model of particular interest to me is modeling the human as a logical inductor. This has several interesting features.
- The feedback given at any one time does not need to be accurate in any sense, because logical inductors can be terrible at first.
- If utility is a LUV, there can be no explicit utility function at all.
- This in-effect allows for uncomputable utility functions, such as the one in the procrastination paradox, as I discussed in an orthodox case against utility functions.
- The convergence behavior can be thought of as a model of human philosophical deliberation.
- One model of particular interest to me is modeling the human as a logical inductor. This has several interesting features.
- It would be super cool to have a combined alignment+tilling result.
- I don’t particularly expect this to solve wireheading or human maniputalion; it’ll have to mostly operate under the assumption that feedback has not been corrupted.
Why Study This?
I suspect you might be wondering what the value of this is, in contrast to a more InfraBayesian approach. I think a substantial part of the motivation for me is just that I am curious to see how LIDT works out, especially with respect to these questions relating to CDT vs EDT. However, I think I can give some reasons why this approach might be necessary.
- Radical Probabalism and InfraBayes are plausibly two orthogonal dimensions of generalization for rationality. Ultimately we want to generalize in both directions, but to do that, working out the radical-probabilist (IE logical induction) decision theory in more detail might be necessary.
- The payoff in terms of alignment results for this approach might give some benefits which can’t be gotten the other way, thanks to the study of subjectively valid LUV expectations which don’t correspond to any (computable) explicit utility function. How could a pure InfraBayes approach align with a user who has LUV values?
- This approach offers insights into the big questions about counterfactuals which are at best only implicit in the InfraBayes approach.
- The VOI exploration insight is the same for both of them, but it’s possible that the theory is easier to work out in this case. I think learnability here can be stated in terms of a no-trap assumption and (for PCDT) a no-newcomb assumption. AFAIK the conditions for learnability in the InfraBayes case are still pretty wide open.
- I don’t know how to talk about the CDT vs EDT insight in the InfraBayes world.
- The way PCDT seems to pathologically fail at learning in Newcomb, and the insight about how we have to learn in order to succeed.
- Perhaps more importantly, the Troll Bridge insights. As I mentioned in the beginning, in order to meaningfully solve Troll Bridge, it’s necessary to “respect logic” in the right sense. InfraBayes doesn’t do this, and it’s not clear how to get it to do so.
Conclusion
Provided the formal stuff works out, this might be "all there is to know" about counterfactuals from a purely decision-theoretic perspective.
This wouldn't mean we're done with embedded agent theory. However, I think things factor basically as follows:
- Decision Theory
- Counterfactuals
- Classic newcomb's problem.
- 5&10.
- Troll Bridge.
- Death in Damascus.
- ...
- Logical Updatelessness
- XOR Blackmail
- Transparent Newcomb
- Parfit's Hitchhiker
- Counterfactual Mugging
- ...
- Multiagent Rationality
- Prisoner's Dilemma
- Chicken
- ...
- Counterfactuals
I've expressed many reservations about logical updatelessness in the past, and it may create serious [LW · GW] problems [LW · GW] for multiagent rationality, but it still seems like the best hope for solving the class of problems which includes XOR Blackmail, Transparent Newcomb, Parfit's Hitchhiker, and Counterfactual Mugging.
If the story about counterfactuals in this post works out, and the above factoring of open problems in decision theory is right, then we'd "just" have logical updatelessness and multiagent rationality left.
57 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-04-09T18:39:39.332Z · LW(p) · GW(p)
I only skimmed this post for now, but a few quick comments on links to infra-Bayesianism:
InfraBayes doesn’t seem to have that worry, since it applies to non-realizable cases. (Or does it? Is there some kind of non-oscillation guarantee? Or is non-oscillation part of what it means for a set of environments to be learnable -- IE it can oscillate in some cases?)... AFAIK the conditions for learnability in the InfraBayes case are still pretty wide open.
It's true that these questions still need work, but I think it's rather clear that something like "there are no traps" is a sufficient condition for learnability. For example, if you have a finite set of "episodic" hypotheses (i.e. time is divided into episodes, and no states is preserved from one episode to another), then a simple adversarial bandit algorithm (e.g. Exp3) that treats the hypotheses as arms leads to learning. For a more sophisticated example, consider Tian et al which is formulated in the language of game theory, but can be regarded as an infra-Bayesian regret bound for infra-MDPs.
Radical Probabalism and InfraBayes are plausibly two orthogonal dimensions of generalization for rationality. Ultimately we want to generalize in both directions, but to do that, working out the radical-probabilist (IE logical induction) decision theory in more detail might be necessary.
True, but IMO the way to incorporate "radical probabilism" is via what I called Turing RL.
I don’t know how to talk about the CDT vs EDT insight in the InfraBayes world.
I'm not sure what precisely you mean by "CDT vs EDT insight" but our latest post [LW · GW] might be relevant: it shows how you can regard infra-Bayesian hypotheses as joint beliefs about observations and actions, EDT-style.
Perhaps more importantly, the Troll Bridge insights. As I mentioned in the beginning, in order to meaningfully solve Troll Bridge, it’s necessary to “respect logic” in the right sense. InfraBayes doesn’t do this, and it’s not clear how to get it to do so.
Is there a way to operationalize "respecting logic"? For example, a specific toy scenario where an infra-Bayesian agent would fail due to not respecting logic?
Replies from: abramdemski↑ comment by abramdemski · 2021-04-09T21:36:13.896Z · LW(p) · GW(p)
Is there a way to operationalize "respecting logic"? For example, a specific toy scenario where an infra-Bayesian agent would fail due to not respecting logic?
"Respect logic" means either (a) assigning probability one to tautologies (at least, to those which can be proved in some bounded proof-length, or something along those lines), or, (b) assigning probability zero to contradictions (again, modulo boundedness). These two properties should be basically equivalent (ie, imply each other) provided the proof system is consistent. If it's inconsistent, they imply different failure modes.
My contention isn't that infra-bayes could fail due to not respecting logic. Rather, it's simply not obvious whether/how it's possible to make an interesting troll bridge problem for something which doesn't respect logic. EG, the example I mentioned of a typical RL agent -- the obvious way to "translate" Troll Bridge to typical RL is for the troll to blow up the bridge if and only if the agent takes an exploration step. But, this isn't sufficiently like the original Troll Bridge problem to be very interesting.
By no means do I mean to indicate that there's an argument that agents have to "respect logic" buried somewhere in this write-up (or the original troll-bridge writeup, or my more recent explanation of troll bridge, or any other posts which I linked).
If I want to argue such a thing, I'd have to do so separately.
And, in fact, I don't think I want to argue that an agent is defective if it doesn't "respect logic". I don't think I can pull out a decision problem it'll do poorly on, or such.
I a little bit want to argue that a decision theory is less revealing if it doesn't represent an agent as respecting logic, because I tend to think logical reasoning is an important part of an agent's rationality. EG, a highly capable general-purpose RL agent should be interpretable as using logical reasoning internally, even if we can't see that in the RL algorithm which gave rise to it. (In which case you might want to ask how the RL agent avoids the troll-bridge problem, even though the RL algorithm itself doesn't seem to give rise to any interesting problem there.)
As such, I find it quite plausible that InfraBayes and other RL algorithms end up handling stuff like Troll Bridge just fine without giving us insight into the correct reasoning, because they eventually kick out any models/hypotheses which fail Troll Bridge.
Whether it's necessary to "gain insight" into how to solve Troll Bridge (as an agent which respects some logic internally), rather than merely solve it (by providing learning algorithms which have good guarantees), is separate question. I won't claim this has a high probability of being a necessary kind of insight (for alignment). I will claim it seems like a pretty important question to answer for someone interested in counterfactual reasoning.
True, but IMO the way to incorporate "radical probabilism" is via what I called Turing RL.
I don't think Turing RL addresses radical probabilism at all, although it plausibly addresses a major motivating force for being interested in radical probabilism, namely logical uncertainty.
From a radical-probabilist perspective, the complaint would be that Turing RL still uses the InfraBayesian update rule, which might not always be necessary to be rational (the same way Bayesian updates aren't always necessary).
Naively, it seems very possible to combine infraBayes with radical probabilism:
- Starting from radical probabilism, which is basically "a dynamic market for beliefs", infra seems close to the insight that prices can have a "spread". (In the same way that interval probability is close to InfraBayes, but not all the way).
- Starting from Infra, the question is how to add in the market aspect.
However, I'm not sure what formalism could unify these.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-04-10T12:43:00.792Z · LW(p) · GW(p)
I guess we can try studying Troll Bridge using infra-Bayesian modal logic, but atm I don't know what would result.
From a radical-probabilist perspective, the complaint would be that Turing RL still uses the InfraBayesian update rule, which might not always be necessary to be rational (the same way Bayesian updates aren't always necessary).
Ah, but there is a sense in which it doesn't. The radical update rule is equivalent to updating on "secret evidence". And in TRL we have such secret evidence. Namely, if we only look at the agent's beliefs about "physics" (the environment), then they would be updated radically, because of secret evidence from "mathematics" (computations).
Replies from: abramdemski↑ comment by abramdemski · 2021-04-13T16:09:45.584Z · LW(p) · GW(p)
Ah, but there is a sense in which it doesn't. The radical update rule is equivalent to updating on "secret evidence". And in TRL we have such secret evidence. Namely, if we only look at the agent's beliefs about "physics" (the environment), then they would be updated radically, because of secret evidence from "mathematics" (computations).
I agree that radical probabilism can be thought of as bayesian-with-a-side-channel, but it's nice to have a more general characterization where the side channel is black-box, rather than an explicit side-channel which we explicitly update on. This gives us a picture of the space of rational updates. EG, the logical induction criterion allows for a large space of things to count as rational. We get to argue for constraints on rational behavior by pointing to the existence of traders which enforce those constraints, while being agnostic about what's going on inside a logical inductor. So we have this nice picture, where rationality is characterized by non-exploitability wrt a specific class of potential exploiters.
Here's an argument for why this is an important dimension to consider:
- Human value-uncertainty is not particularly well-captured by Bayesian uncertainty, as I imagine you'll agree. One particular complaint is realizability: we have no particular reason to assume that human preferences are within any particular space of hypotheses we can write down.
- One aspect of this can be captured by InfraBayes: it allows us to eliminate the realizability assumption, instead only assuming that human preferences fall within some set of constraints which we can describe.
- However, there is another aspect to human preference-uncertainty: human preferences change over time. Some of this is irrational, but some of it is legitimate philosophical deliberation.
- And, somewhat in the spirit of logical induction, humans do tend to eventually address the most egregious irrationalities.
- Therefore, I tend to think that toy models of alignment (such as CIRL, DRL, DIRL) should model the human as a radical probabilist; not because it's a perfect model, but because it constitutes a major incremental improvement wrt modeling what kind of uncertainty humans have over our own preferences.
Recognizing preferences as a thing which naturally changes over time seems, to me, to take a lot of the mystery out of human preference uncertainty. It's hard to picture that I have some true platonic utility function. It's much easier to interpret myself as having some preferences right now (which I still have uncertainty about, but which I have some introspective access of), but, also being the kind of entity who shifts preferences over time, and mostly in a way which I myself endorse. In some sense you can see me as converging to a true utility function; however, this "true utility function" is a (non-constructive) consequence of my process of deliberation, and the process of deliberation takes a primary role.
I recognize that this isn't exactly the same perspective captured by my first reply.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-04-16T16:09:55.585Z · LW(p) · GW(p)
So we have this nice picture, where rationality is characterized by non-exploitability wrt a specific class of potential exploiters.
I'm not convinced this is the right desideratum for that purpose. Why should we care about exploitability by traders if making such trades is not actually possible given the environment and the utility function? IMO epistemic rationality is subservient to instrumental rationality, so our desiderata should be derived from the later.
Human value-uncertainty is not particularly well-captured by Bayesian uncertainty, as I imagine you'll agree... It's hard to picture that I have some true platonic utility function.
Actually I am rather skeptical/agnostic on this. For me it's fairly easy to picture that I have a "platonic" utility function, except that the time discount is dynamically inconsistent (not exponential).
I am in favor of exploring models of preferences which admit all sorts of uncertainty and/or dynamic inconsistency, but (i) it's up to debate how much degrees of freedom we need to allow there and (ii) I feel that the case logical induction is the right framework for this is kinda weak (but maybe I'm missing something).
Replies from: abramdemski, abramdemski, abramdemski↑ comment by abramdemski · 2021-04-16T18:14:57.309Z · LW(p) · GW(p)
I'm not convinced this is the right desideratum for that purpose. Why should we care about exploitability by traders if making such trades is not actually possible given the environment and the utility function? IMO epistemic rationality is subservient to instrumental rationality, so our desiderata should be derived from the later.
This does make sense to me, and I view it as a weakness of the idea. However, the productivity of dutch-book type thinking in terms of implying properties which seem appealing for other reasons speaks heavily in favor of it, in my mind. A formal connection to more pragmatic criteria would be great.
But also, maybe I can articulate a radical-probabilist position without any recourse to dutch books... I'll have to think more about that.
Actually I am rather skeptical/agnostic on this. For me it's fairly easy to picture that I have a "platonic" utility function, except that the time discount is dynamically inconsistent (not exponential).
I'm not sure how to double crux with this intuition, unfortunately. When I imagine the perspective you describe, I feel like it's rolling all dynamic inconsistency into time-preference and ignoring the role of deliberation.
My claim is that there is a type of change-over-time which is due to boundedness, and which looks like "dynamic inconsistency" from a classical bayesian perspective, but which isn't inherently dynamically inconsistent. EG, if you "sleep on it" and wake up with a different, firmer-feeling perspective, without any articulable thing you updated on. (My point isn't to dogmatically insist that you haven't updated on anything, but rather, to point out that it's useful to have the perspective where we don't need to suppose there was evidence which justifies the update as Bayesian, in order for it to be rational.)
↑ comment by abramdemski · 2021-04-20T16:32:19.401Z · LW(p) · GW(p)
Actually I am rather skeptical/agnostic on this. For me it's fairly easy to picture that I have a "platonic" utility function, except that the time discount is dynamically inconsistent (not exponential).
I am in favor of exploring models of preferences which admit all sorts of uncertainty and/or dynamic inconsistency, but (i) it's up to debate how much degrees of freedom we need to allow there and (ii) I feel that the case logical induction is the right framework for this is kinda weak (but maybe I'm missing something).
It's clear that you understand logical induction pretty well, so while I feel like you're missing something, I'm not clear on what that could be.
I think maybe the more fruitful branch of this conversation (as opposed to me trying to provide an instrumental justification for radical probabilism, though I'm still interested in that) is the question of describing the human utility function.
The logical induction picture isn't strictly at odds with a platonic utility function, I think, since we can consider the limit. (I only claim that this isn't the best way to think about it in general, since Nature didn't decide a platonic utility function for us and then design us such that our reasoning has the appropriate limit.)
For example, one case which to my mind argues in favor of the logical induction approach to preferences: the procrastination paradox. All you want to do is ensure that the button is pressed at some point. This isn't a particularly complex or unrealistic preference for an agent to have. Yet, it's unclear how to make computable beliefs think about this appropriately. Logical induction provides a theory about how to think about this kind of goal. (I haven't thought much about how TRL would handle it.)
Agree or disagree: agents can sensibly pursue objectives? And, do you think that question is cruxy for you?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-05-03T18:09:27.878Z · LW(p) · GW(p)
I lean towards some kind of finitism or constructivism, and am skeptical of utility functions which involve unbounded quantifiers. But also, how does LI help with the procrastination paradox? I don't think I've seen this result.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-02T16:54:56.621Z · LW(p) · GW(p)
What I'm referring to is that LI given a notion of rational uncertain expectation for the procrastination paradox -- so, less a positive result, more a framework for thinking about what behavior is reasonable.
However, I also think LIDT solves the problem in practical terms:
- In the pure procrastination-paradox problem, LIDT will eventually push the button if its logic is sound. If it did not, it would mean the conditional probability of ever pressing the button given not pressing it today remains forever higher than the conditional probability of ever pressing it today. However, the expectation can be split into the probability it gets pushed today, and the probability that it gets pushed on any day later than today. The LI should eventually know that the conditional probability of ever pressing the button given pressing it today is arbitrarily close to 1. So in order to never press the button, the conditional probability of ever pressing it in the future (given not pressing today) would have to go to 1 (faster than the probability of it ever being pressed given pressing it today). I don't think this can happen, since there will be some nonzero limit probability that the button will never be pressed (that is, there will be supposing the button is in fact never pressed).
- In a situation where there is some actual reason to procrastinate (there are other sources of utility), but we place very high value on eventually pressing the button, it may be that the button will never be pressed? However, this will only happen if we're subjectively confident that it will eventually be pressed, and always have something better to do in the mean time. The second part seems pretty difficult. So maybe we can also prove that we eventually press the button in this case, as well.
My basic argument is we can model this sort of preference, so why rule it out as a possible human preference? You may be philosophically confident in finitist/constructivist values, but are you so confident that you'd want to lock unbounded quantifiers out of the space of possible values for value learning?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-06-03T04:00:56.334Z · LW(p) · GW(p)
However, I also think LIDT solves the problem in practical terms:
What is LIDT exactly? I can try to guess but I rather make sure we're both talking about the same thing.
My basic argument is we can model this sort of preference, so why rule it out as a possible human preference? You may be philosophically confident in finitist/constructivist values, but are you so confident that you'd want to lock unbounded quantifiers out of the space of possible values for value learning?
I agree inasmuch as we actually can model this sort of preferences, for a sufficiently strong meaning of "model". I feel that it's much harder to be confident about any detailed claim about human values than about the validity of a generic theory of rationality. Therefore, if the ultimate generic theory of rationality imposes some conditions on utility functions (while still leaving a very rich space of different utility functions), that will lead me to try formalizing human values within those constraints. Of course, given a candidate theory, we should poke around and see whether it can be extended to weaken the constraints.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-09T19:02:07.840Z · LW(p) · GW(p)
I agree inasmuch as we actually can model this sort of preferences, for a sufficiently strong meaning of "model". I feel that it's much harder to be confident about any detailed claim about human values than about the validity of a generic theory of rationality. Therefore, if the ultimate generic theory of rationality imposes some conditions on utility functions (while still leaving a very rich space of different utility functions), that will lead me to try formalizing human values within those constraints. Of course, given a candidate theory, we should poke around and see whether it can be extended to weaken the constraints.
Right, I agree with this. The situation as I see it is that there's a concrete theory of rationality (logical induction) which I'm using in this way, and it is suggesting to me that your theory (InfraBayes) can still be extended somewhat.
My argument that we want this particular extension is basically as follows: human values can be thought of as the endpoint of human philosophical deliberation about values. (I am thinking of logical induction as a formalization of philosophical deliberation over time.) This endpoint seems limit-computable, but not necessarily computable. Now, it's also possible that at this endpoint, humans would have a more compact (ie, computable) representation of values. However, why assume this?
(My hope is that by appealing to deliberation like this, my argument has more force than if I was only relying on the strength of logical induction as a theory of rationality. The idea of deliberation gives us a general reason to expect that limit-computable is the right place to look.)
What is LIDT exactly?
I'm not sure details matter very much here, but I'm provisionally happy to spell out LIDT as:
- Specify some (bounded-value) LUV to use as "utility"
- Make decisions by looking at conditional expectations of that LUV given actions.
Concrete enough?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-06-11T21:32:50.393Z · LW(p) · GW(p)
I would be convinced if you had a theory of rationality that is a Pareto improvement on IB (i.e. has all the good properties of IB + a more general class of utility functions). However, LI doesn't provide this AFAICT. That said, I would be interested to see some rigorous theorem about LIDT solving procrastination-like problems.
As to philosophical deliberation, I feel some appeal in this point of view, but I can also easily entertain a different point of view: namely, that human values are more or less fixed and well-defined whereas philosophical deliberation is just a "show" for game theory reasons. Overall, I place much less weight on arguments that revolve around the presumed nature of human values compared to arguments grounded in abstract reasoning about rational agents.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-22T23:24:24.720Z · LW(p) · GW(p)
I don't believe that LI provides such a Pareto improvement, but I suspect that there's a broader theory which contains the two.
Overall, I place much less weight on arguments that revolve around the presumed nature of human values compared to arguments grounded in abstract reasoning about rational agents.
Ah. I was going for the human-values argument because I thought you might not appreciate the rational-agent argument. After all, who cares what general rational agents can value, if human values happen to be well-represented by infrabayes?
But for general rational agents, rather than make the abstract deliberation argument, I would again mention the case of LIDT in the procrastination paradox, which we've already discussed.
Or, I would make the radical probabilist [LW · GW] argument against rigid updating, and the 'orthodox' argument [LW · GW]against fixed utility functions. Combined, we get a picture of "values" which is basically a market for expected values, where prices can change over time (in a "radical" way that doesn't necessarily spring from an update on a proposition), but which follow some coherence rules like an expectation of an expectation equals an expectation. One formalization of this is Skyrms'. Another is your generalization of LI (iirc).
So to sum it up, my argument for general rational agents is:
- In general, we need not update in a rigid way; we can develop a meaningful theory of 'fluid' updates, so long as we respect some coherence constraints. In light of this generalization, restriction to 'rigid' updates seems somewhat arbitrary (ie there does not seem to be a strong motivation to make the restriction from rationality alone).
- Separately, there is no need to actually have a utility function if we have a coherent expectation.
- Putting the two together, we can study coherent expectations where the notion of 'coherence' doesn't assume rigid updates.
However, this argument of course does not account for InfraBayes. I suspect your real crux is the plausibility of coming up with a unifying theory which gets both radical-probabilism stuff and InfraBayes stuff. This does seem challenging, but I strongly suspect it to be possible. Indeed, it seems like it might have to do with the idea of a market which maintains a buy/sell spread rather than giving one price for a good.
↑ comment by abramdemski · 2021-04-19T17:18:26.154Z · LW(p) · GW(p)
I'm not convinced this is the right desideratum for that purpose. Why should we care about exploitability by traders if making such trades is not actually possible given the environment and the utility function? IMO epistemic rationality is subservient to instrumental rationality, so our desiderata should be derived from the later.
So, one point is that the InfraBayes picture still gives epistemics an important role: the kind of guarantee arrived at is a guarantee that you won't do too much worse than the most useful partial model expects. So, we can think about generalized partial models which update by thinking longer in addition to taking in sense-data.
I suppose TRL can model this by observing what those computations would say, in a given situation, and using partial models which only "trust computation X" rather than having any content of their own. Is this "complete" in an appropriate sense? Can we always model a would-be radical-infrabayesian as a TRL agent observing what that radical-infrabayesian would think?
Even if true, there may be a significant computational complexity gap between just doing the thing vs modeling it in this way.
Replies from: vanessa-kosoy, abramdemski↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-05-03T17:58:43.257Z · LW(p) · GW(p)
Yes, I'm pretty sure we have that kind of completeness. Obviously representing all hypotheses in this opaque form would give you poor sample and computational complexity, but you can do something midway: use black-box programs as components in your hypothesis but also have some explicit/transparent structure.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-02T20:46:58.987Z · LW(p) · GW(p)
OK, so, here is a question.
The abstract theory of InfraBayes (like the abstract theory of Bayes) elides computational concerns.
In reality, all of ML can more or less be thought of as using a big search for good models, where "good" means something approximately like MAP, although we can also consider more sophisticated variational targets. This introduces two different types of approximation:
- The optimization target is approximate.
- The optimization itself gives only approximate maxima.
What we want out of InfraBayes is a bounded regret guarantee (in settings where we previously didn't know how to get one). What we have is a picture of how to get that if we can actually do the generalized Bayesian update. What we might want is a picture of how to do that more generally, when we can't actually compute the full update.
Can we get such a thing with InfraBayes?
In other words, search is a very basic type of logical uncertainty. Currently, we don't have much of a model of that, except "Bayesian Search" (which does not provide any nice regret bounds that I know of, although I may be ignorant). We might need such a thing in order to get nice guarantees for systems which employ search internally. Can we get it?
Obviously, we can do the bayesian-search thing with InfraBayes substituted in, which already probably provides some kind of guarantee which couldn't be gotten otherwise. However, the challenge is to get the guarantee to carry all the way through to the end result.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-06-04T00:06:12.488Z · LW(p) · GW(p)
My hope is that we will eventually have computationally feasible algorithms that satisfy provable (or at least conjectured) infra-Bayesian regret bounds for some sufficiently rich hypothesis space. Currently, even in the Bayesian case, we only have such algorithms for poor hypothesis spaces, such as MDPs with a small number of states. We can also rule out such algorithms for some large hypothesis spaces, such as short programs with a fixed polynomial-time bound. In between, there should be some hypothesis space which is small enough to be feasible and rich enough to be useful. Indeed, it seems to me that the existence of such a space is the simplest explanation for the success of deep learning (that is, for the ability to solve a diverse array of problems with relatively simple and domain-agnostic algorithms). But, at present I only have speculations about what this space looks like.
↑ comment by abramdemski · 2021-04-20T16:20:55.756Z · LW(p) · GW(p)
To further elaborate, this post [LW · GW] discusses ways a Bayesian might pragmatically prefer non-Bayesian updates. Some of them don't carry over, for sure, but I expect the general idea to translate: InfraBayesians need some unrealistic assumptions to reflectively justify the InfraBayesian update in contrast to other updates. (But I am not sure which assumptions to point out, atm.)
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-05-03T18:14:09.389Z · LW(p) · GW(p)
In particular, it's easy to believe that some computation knows more than you.
Yes, I think TRL captures this notion. You have some Knightian uncertainty about the world, and some Knightian uncertainty about the result of a computation, and the two are entangled.
comment by Ben Pace (Benito) · 2021-04-09T19:00:14.092Z · LW(p) · GW(p)
I've felt like the problem of counterfactuals is "mostly settled" for about a year, but I don't think I've really communicated this online.
Wow that's exciting! Very interesting that you think that.
Replies from: abramdemski↑ comment by abramdemski · 2021-04-12T15:23:17.262Z · LW(p) · GW(p)
Now I feel like I should have phrased it more modestly, since it's really "settled modulo math working out", even though I feel fairly confident some version of the math should work out.
comment by Lukas Finnveden (Lanrian) · 2023-01-12T18:31:15.758Z · LW(p) · GW(p)
I'm curious if anyone made a serious attempt at the shovel-ready math here and/or whether this approach to counterfactuals still looks promising to Abram? (Or anyone else with takes.)
comment by tailcalled · 2022-01-29T11:04:53.310Z · LW(p) · GW(p)
What's the status on this?
I think I have a fairly straightforward theory of logical counterfactuals, which I believe makes something very much like PCDT work (except instead of a C(A|B) construct, it's a C(A|B=C) construct; but I assume this is just an irrelevant syntactic change). Would it be worth a writeup? Rough estimates of its properties (haven't fully formalized yet so it might be up for revision):
- It avoids the dutch-book of CDT by keeping its conditionals in line with its decision counterfactuals (insofar as its conditionals are even meaningful; conditionals over actions are hard to define due to having knowledge over your actions - but e.g. if we add epsilon-exploration and don't have any shenanigans that separate the epsilon-exploration actions from the deliberate actions, it'd end up equivalent).
- It handle troll's bridge correctly by reasoning counterfactually.
- It one-boxes in Newcomb's problem and cooperates with itself in prisoners dilemma (while of course defecting against cooperatebot and defectbot).
- It can do a proof-based mode, but it can also do a model-based mode that in the case of full knowledge is provably equivalent in outputs, and can be efficiently computed for toy problems.
It doesn't have any learning or tiling theory.
Anyway I thought I'd ask before I write it up, since my solution is fairly basic, so I wouldn't be surprised if someone had derived it already since your post.
Replies from: tailcalled, tailcalled↑ comment by tailcalled · 2022-01-29T11:39:59.608Z · LW(p) · GW(p)
Actually, whether it one-boxes or two-boxes in Newcomb's problem depends on the setup. How is Newcomb's problem usually formalized in these logic-based settings?
↑ comment by tailcalled · 2022-01-29T11:23:15.914Z · LW(p) · GW(p)
Or I guess it would be called RCDT, since I'm proposing a specific class of counterfactuals? I'm not sure I understand the PCDT/RCDT distinction.
comment by gjm · 2021-06-25T17:17:32.610Z · LW(p) · GW(p)
How confident are you that the "right" counterfactual primitive is something like your C(A|B) meaning (I take it) "if B were the case then A would be the case"?
The alternative I have in mind assimilates counterfactual conditionals to conditional probabilities rather than to logical implications, so in addition to your existing Pr(A|B)=... meaning "if B is the case, then here's how strongly I expect A to be the case" there's Prc(A|B)=... meaning "if B were the case -- even though that might require the world to be different from how it actually is -- then here's how strongly I expect that A would be the case"?
In some ways this feels more natural to me, and like a better fit for your general observation that we shouldn't expect there to be One True Set Of Counterfactuals, and like a better fit for your suggestion that counterfactual conditions involve something like updating on evidence.
Typical philosophical accounts of counterfactuals say things like: "if B were the case then A would be the case" means that you look at the nearest possible world where B is the case, and see whether A holds there; this seems like it involves making a very specific choice too early, and it would be better to look at nearby possible worlds where B is the case and see how much of the time A holds. (I am not claiming that possible worlds are The Right Way to approach counterfactuals, just saying that if we approach them that way then we should probably not be jumping to a single possible world as soon as we consider a counterfactual. Not least because that makes combining different counterfactuals worse than it seems like it needs to; if "c-if A then B" and "c-if C then D", the "nearest possible world" approach doesn't let us say anything about what c-if A and C, because the nearest world where A, the nearest world where C, and the nearest world where A&C can all be entirely different. Whereas we might hope that when A and C are sufficiently compatible there'll at least be substantial overlap between the worlds where A, the worlds where C, and the worlds where A&C.
(I don't think it's enough to think of this in terms of applying already-existing probabilities to propositions like "c-if B then A", just as Pr(A|B) is not the same thing as Pr(B => A) for any particular notion of implication.)
Replies from: abramdemski↑ comment by abramdemski · 2021-07-07T17:20:11.588Z · LW(p) · GW(p)
Ah, I wasn't strongly differentiating between the two, and was actually leaning toward your proposal in my mind. The reason I was not differentiating between the two was that the probability of C(A|B) behaves a lot like the probabilistic value of Prc(A|B). I wasn't thinking of nearby-world semantics or anything like that (and would contrast my proposal with such a proposal), so I'm not sure whether the C(A|B) notation carries any important baggage beyond that. However, I admit it could be an important distinction; C(A|B) is itself a proposition, which can feature in larger compound sentences, whereas Prc(A|B) is not itself a proposition and cannot feature in larger compound sentences. I believe this is the real crux of your question; IE, I believe there aren't any other important consequences of the choice, besides whether we can build larger compound expressions out of our counterfactuals.
Part of why I was not strongly differentiating the two was because I was fond of Stalnaker's Thesis, according to which P(A|B) can itself be regarded as the probability of some proposition, namely a nonstandard notion of implication (IE, not material conditional, but rather 'indicative conditional'). If this were the case, then we could safely pun between P(A->B) and P(B|A), where "->" is the nonstandard implication. Thus, I analogously would like for P(C(A|B)) to equal Prc(A|B). HOWEVER, Stalnaker's thesis is dead in philosophy, for the very good reason that it seemingly supports the chain of reasoning Pr(B|A) = Pr(A->B) = Pr(A->B|B)Pr(B) + Pr(A->B|~B)Pr(~B) = Pr(B|A&B)Pr(B) + Pr(B|A&~B)Pr(~B) = Pr(B). Some attempts to block this chain of reasoning (by rejecting bayes) have been made, but, it seems pretty damning overall.
So, similarly, my idea that P(C(A|B))=Prc(A|B) is possibly deranged, too.
Replies from: gjm↑ comment by gjm · 2021-07-09T10:02:37.022Z · LW(p) · GW(p)
I never found Stalnaker's thesis at all plausible, not because I'd thought of the ingenious little calculation you give but because it just seems obviously wrong intuitively. But I suppose if you don't have any presuppositions about what sort of notion an implication is allowed to be, you don't get to reject it on those grounds. So I wasn't really entitled to say "Pr(A|B) is not the same thing as Pr(B=>A) for any particular notion of implication", since I hadn't thought of that calculation.
Anyway, I have just the same sense of obvious wrongness about this counterfactual version of Stalnaker. I suspect it's harder to come up with an outright refutation, not least because there isn't anything like general agreement about what C(A|B) means, whereas there's something much nearer to that for Pr(A|B).
At least some "nestings" of counterfactuals feel problematic to me. "Suppose it were true that if Bach had lived to be 90 then Mozart would have died at age 10; then if Dirichlet had lived to be 80, would Jacobi have died at 20?" The antecedent doesn't do much to make clear just what is actually being supposed, and it's not clear that this is made much better if we say instead "Suppose you believe, with credence 0.9, that if Bach had lived to be 90 then Mozart would have died at age 10; then how strongly do you believe that if Dirichlet had lived to be 80 then Jacobi would have died at 20?". But I do think that a good analysis of counterfactuals should allow for questions of this form. (But, just as some conditional probabilities are 0/0 and some others are small/small and we shouldn't trust our estimates much, some counterfactual probabilities are undefined or ill-conditioned. Whether or not they are actually literal ratios.)
Replies from: abramdemski↑ comment by abramdemski · 2021-07-16T19:43:11.369Z · LW(p) · GW(p)
Yeah, interesting. I don't share your intuition that nested counterfactuals seem funny. The example you give doesn't seem ill-defined due to the nesting of counterfactuals. Rather, the antecedent doesn't seem very related to the consequent, which generally has a tendency to make counterfactuals ambiguous. If you ask "if calcium were always ionic, would Nixon have been elected president?" then I'm torn between three responses:
- "No" because if we change chemistry, everything changes.
- "Yes" because counterfactuals keep everything the same as much as possible, except what has to change; maybe we're imagining a world where history is largely the same, but some specific biochemistry is different.
- "I don't know" because I am not sure what connection between the two you are trying to point at with the question, so, I don't know how to answer.
In the case of your Bach example, I'm similarly torn. On the one hand, if we imagine some weird connection between the ages of Back and Mozart, we might have to change a lot of things. On the other hand, counterfactuals usually try to keep thing fixed if there's not a reason to change them. So the intention of the question seems pretty unclear.
Which, in my mind, has little to do with the specific nested form of your question.
More importantly, perhaps, I think Stalnaker and other philosophers can be said to be investigating linguistic counterfactuals; their chief concern is formalizing the way humans naively talk about things, in a way which gives more clarity but doesn't lose something important.
My chief concern is decision-theoretic counterfactuals, which are specifically being used to plan/act. This imposes different requirements.
The philosophy of linguistic counterfactuals is complex, of course, but personally I really feel that I understand fairly well what linguistic counterfactuals are and how they work. My picture probably requires a little exposition to be comprehensible, but to state it as simply as I can, I think linguistic counterfactuals can always be understood as "conditional probabilities, but using some reference frame rather than actual beliefs". For example, very often we can understand counterfactuals as conditional probabilities from a past belief state. "If it had rained, we would not have come" can't be understood as a conditional probability of the current beliefs where we knew we did come; but back up time a little bit, and it's true that if it had been raining, we would not have made the trip.
Backing up time doesn't always quite work. In those cases we can usually understand things in terms of a hypothetical "objective judge" who doesn't know details of a situation but who knows things a "reasonable third party" would know. It makes sense that humans would have to consider this detached perspective a lot, in order to judge social situations; so it makes sense that we would have language for talking about it (IE counterfactual language).
We can make sense of nested linguistic counterfactuals in that way, too, if we wish. For example, "if driving had [counterfactually] meant not making it to the party, then we wouldn't have done it" says (on my understanding) that if a reasonable third person would have looked at the situation and said that if we drive we won't make it to the party, then, we would not have driven. (This in turn says that my past self would have not driven if he had believed that a resonable third person wouldn't believe that we would make it to the party, given the information that we're driving.)
So, I think linguistic counterfactuals implicitly require a description of a third party / past self to be evaluated; this is usually obvious enough from conversation, but, can be an ambiguity.
However, I don't think this analysis helps with decision-theoretic counterfactuals. At least, not directly.
Replies from: gjm↑ comment by gjm · 2021-07-16T22:03:12.758Z · LW(p) · GW(p)
I agree that much of what's problematic about the example I gave is that the "inner" counterfactuals are themselves unclear. I was thinking that this makes the nested counterfactual harder to make sense of (exactly because it's unclear what connection there might be between them) but on reflection I think you're right that this isn't really about counterfactual nesting and that if we picked other poorly-defined (non-counterfactual) propositions we'd get a similar effect: "If it were morally wrong to eat shellfish, would humans Really Truly Have Free Will?" or whatever.
I'd not given any thought before to your distinction between linguistic and decision-theoretic counterfactuals. I'm actually not sure I understand the distinction. It's obvious how ordinary conditionals are important for planning and acting (you design a bridge so that it won't fall down if someone drives a heavy lorry across it; you don't cross a bridge because you think the troll underneath will eat you if you cross), but counterfactuals? I mean, obviously you can put them in to a particular problem: you're crossing a bridge and there's a troll who'll blow up the bridge if you would have crossed it if there'd been a warning sign saying "do not cross", or whatever. But that's not counterfactuals being useful for decision theory, it's some agent arbitrarily caring about counterfactuals -- and agents can arbitrarily care about anything. (I am not entirely sure I've understood the "Troll Bridge" example you're actually using, but to whatever extent it's about counterfactuals it seems to be of this "agent arbitrarily caring about counterfactuals" type.) The thing you call "proof-based decision theory" involves trying to prove things of the form "if I do X, I will get at least Y utility" but those look like ordinary conditionals rather than counterfactuals to me too. (And in any case the whole idea of doing what you can rigorously prove from a given set of mathematical axioms gives you the most guaranteed utility seems bonkers to me anyway as anything other than a toy example, though this is pure prejudice and maybe there are better reasons for it than I can currently imagine: we want agents that can act in the actual world, about which one can generally prove precisely nothing of interest.) Could you give a couple of examples where counterfactuals are relevant to planning and acting without having been artificially inserted?
It may just be that none of this should be expected to make sense to someone not already immersed in the particular proof-based-decision-theory framework I think you're working in, and that what I need in order to appreciate where you're coming from is to spend a few hours (days? weeks?) getting familiar with that. At any rate, right now "passing Troll Bridge" looks to me like a problem applicable only to a very specific kind of decision-making agent, one I don't see any particular reason to think has any prospect of ever being relevant to decision-making in the actual world -- but I am extremely aware that this may be purely a reflection of my own ignorance.
Replies from: abramdemski↑ comment by abramdemski · 2021-07-17T15:47:57.952Z · LW(p) · GW(p)
It's obvious how ordinary conditionals are important for planning and acting (you design a bridge so that it won't fall down if someone drives a heavy lorry across it; you don't cross a bridge because you think the troll underneath will eat you if you cross), but counterfactuals? I mean, obviously you can put them in to a particular problem
All the various reasoning behind a decision could involve material conditionals, probabilistic conditionals, logical implication, linguistic conditionals (whatever those are), linguistic counterfactuals, decision-theoretic counterfactuals (if those are indeed different as I claim), etc etc etc. I'm not trying to make the broad claim that counterfactuals are somehow involved.
The claim is about the decision algorithm itself. The claim is that the way we choose an action is by evaluating a counterfactual ("what happens if I take this action?"). Or, to be a little more psychologically realistic, the cashed values which determine which actions we take are estimated counterfactual values.
What is the content of this claim?
A decision procedure is going to have (cashed-or-calculated) value estimates which it uses to make decisions. (At least, most decision procedures work that way.) So the content of the claim is about the nature of these values.
If the values act like Bayesian conditional expectations, then the claim that we need counterfactuals to make decisions is considered false. This is the claim of evidential decision theory (EDT).
If the values are still well-defined for known-false actions, then they're counterfactual. So, a fundamental reason why MIRI-type decision theory uses counterfactuals is to deal with the case of known-false actions.
However, academic decision theorists have used (causal) counterfactuals for completely different reasons (IE because they supposedly give better answers). This is the claim of causal decision theory (CDT).
My claim in the post, of course, is that the estimated values used to make decisions should match the EDT expected values almost all of the time, but, should not be responsive to the same kinds of reasoning which the EDT values are responsive to, so should not actually be evidential.
Could you give a couple of examples where counterfactuals are relevant to planning and acting without having been artificially inserted?
It sounds like you've kept a really strong assumption of EDT in your head; so strong that you couldn't even imagine why non-evidential reasoning might be part of an agent's decision procedure. My example is the troll bridge: conditional reasoning (whether proof-based or expectation-based) ends up not crossing the bridge, where counterfactual reasoning can cross (if we get the counterfactuals right).
The thing you call "proof-based decision theory" involves trying to prove things of the form "if I do X, I will get at least Y utility" but those look like ordinary conditionals rather than counterfactuals to me too.
Right. In the post, I argue that using proofs like this is more like a form of EDT rather than CDT, so, I'm more comfortable calling this "conditional reasoning" (lumping it in with probabilistic conditionals).
The Troll Bridge is supposed to show a flaw in this kind of reasoning, suggesting that we need counterfactual reasoning instead (at least, if "counterfactual" is broadly understood to be anything other than conditional reasoning -- a simplification which mostly makes sense in practice).
though this is pure prejudice and maybe there are better reasons for it than I can currently imagine: we want agents that can act in the actual world, about which one can generally prove precisely nothing of interest
Oh, yeah, proof-based agents can technically do anything which regular expectation-based agents can do. Just take the probabilistic model the expectation-based agents are using, and then have the proof-based agent take the action for which it can prove the highest expectation. This isn't totally slight of hand; the proof-based agent will still display some interesting behavior if it is playing games with other proof-based agents, dealing with Omega, etc.
At any rate, right now "passing Troll Bridge" looks to me like a problem applicable only to a very specific kind of decision-making agent, one I don't see any particular reason to think has any prospect of ever being relevant to decision-making in the actual world -- but I am extremely aware that this may be purely a reflection of my own ignorance.
Even if proof-based decision theory didn't generalize to handle uncertain reasoning, the troll bridge would also apply to expectation-based reasoners if their expectations respect logic. So the narrow class of agents for whome it makes sense to ask "does this agent pass the troll bridge" are basically agents who use logic at all, not just agents who are ristricted to pure logic with no probabilistic belief.
Replies from: gjm↑ comment by gjm · 2021-07-17T18:29:51.742Z · LW(p) · GW(p)
OK, I get it. (Or at least I think I do.) And, duh, indeed it turns out (as you were too polite to say in so many words) that I was distinctly confused.
So: Using ordinary conditionals in planning your actions commits you to reasoning like "If (here in the actual world it turns out that) I choose to smoke this cigarette, then that makes it more likely that I have the weird genetic anomaly that causes both desire-to-smoke and lung cancer, so I'm more likely to die prematurely and horribly of lung cancer, so I shouldn't smoke it", which makes wrong decisions. So you want to use some sort of conditional that doesn't work that way and rather says something more like "suppose everything about the world up to now is exactly as it is in the actual world, but magically-but-without-the-existence-of-magic-having-consequences I decide to do X; what then?". And this is what you're calling decision-theoretic counterfactuals, and the question is exactly what they should be; EDT says no, just use ordinary conditionals, CDT says pretty much what I just said, etc. The "smoking lesion" shows that EDT can give implausible results; "Death in Damascus" shows that CDT can give implausible results; etc.
All of which I really should have remembered, since it's all stuff I have known in the past, but I am a doofus. My apologies.
(But my error wasn't being too mired in EDT, or at least I don't think it was; I think EDT is wrong. My error was having the term "counterfactual" too strongly tied in my head to what you call linguistic counterfactuals. Plus not thinking clearly about any of the actual decision theory.)
It still feels to me as if your proof-based agents are unrealistically narrow. Sure, they can incorporate whatever beliefs they have about the real world as axioms for their proofs -- but only if those axioms end up being consistent, which means having perfectly consistent beliefs. The beliefs may of course be probabilistic, but then that means that all those beliefs have to have perfectly consistent probabilities assigned to them. Do you really think it's plausible that an agent capable of doing real things in the real world can have perfectly consistent beliefs in this fashion? (I am pretty sure, for instance, that no human being has perfectly consistent beliefs; if any of us tried to do what your proof-based agents are doing, we would arrive at a contradiction -- or fail to do so only because we weren't trying hard enough.) I think "agents that use logic at all on the basis of beliefs about the world that are perfectly internally consistent" is a much narrower class than "agents that use logic at all".
(That probably sounds like a criticism, but once again I am extremely aware that it may be that this feels implausible to me only because I am lacking important context, or confused about important things. After all, that was the case last time around. So my question is more "help me resolve my confusion" than "let me point out to you how the stuff you've been studying for ages is wrongheaded", and I appreciate that you may have other more valuable things to do with your time than help to resolve my confusion :-).)
Replies from: abramdemski↑ comment by abramdemski · 2021-07-20T14:38:26.507Z · LW(p) · GW(p)
All of which I really should have remembered, since it's all stuff I have known in the past, but I am a doofus. My apologies.
(But my error wasn't being too mired in EDT, or at least I don't think it was; I think EDT is wrong. My error was having the term "counterfactual" too strongly tied in my head to what you call linguistic counterfactuals. Plus not thinking clearly about any of the actual decision theory.)
I'm glad I pointed out the difference between linguistic and DT counterfactuals, then!
It still feels to me as if your proof-based agents are unrealistically narrow. Sure, they can incorporate whatever beliefs they have about the real world as axioms for their proofs -- but only if those axioms end up being consistent, which means having perfectly consistent beliefs. The beliefs may of course be probabilistic, but then that means that all those beliefs have to have perfectly consistent probabilities assigned to them. Do you really think it's plausible that an agent capable of doing real things in the real world can have perfectly consistent beliefs in this fashion?
I'm not at all suggesting that we use proof-based DT in this way. It's just a model. I claim that it's a pretty good model -- that we can often carry over results to other, more complex, decision theories.
However, if we wanted to, then yes, I think we could... I agree that if we add beliefs as axioms, the axioms have to be perfectly consistent. But if we use probabilistic beliefs, those probabilities don't have to be perfectly consistent; just the axioms saying which probabilities we have. So, for example, I could use a proof-based agent to approximate a logical-induction-based agent, by looking for proofs about what the market expectations are. This would be kind of convoluted, though.
Replies from: gjm↑ comment by gjm · 2021-07-22T11:17:17.477Z · LW(p) · GW(p)
I appreciate that it's a model, but it seems -- perhaps wrongly, since as already mentioned I am an ignorant doofus -- as if at least some of what you're doing with the model depends essentially on the strictly-logic-based nature of the agent. (E.g., the Troll Bridge problem as stated here seems that way, down to applying Löb's theorem to the agent as formal system.)
Formal logic is very brittle; ex falso quodlibet, and all that; it (ignorantly and doofusily) looks to me as if you might be looking at a certain class of models and then finding problems (e.g., Troll Bridge) that are only problems because of specific features of the models that couldn't realistically apply to the real world.
(In terms of the "rocket alignment problem" metaphor: suppose you start thinking about orbital mechanics, come up with exact-conic-section orbits as an interesting class of things to study, and prove some theorem that says that some class of things isn't achievable for exact-conic-section orbits for a reason that comes down to something like dividing by the sum of squares of all the higher-order terms that are exactly zero for a perfect conic section orbit. That would be an interesting theorem, and it's not hard to imagine how some less-rigid generalization of it might apply to real trajectories ("if the sum of squares of those coefficients is small then the trajectory is unstable and hard to get right" or something) -- but as it stands it doesn't really tell you anything about real problems faced by real rockets whose trajectories are not perfect conic sections. And logic is generally much more brittle than orbital mechanics, chaos theory notwithstanding; there isn't generally anything that corresponds to the sum of squares of coefficients being small; a proof that contains only a few small errors is not a proof at all.)
But, hmm, you reckon one could make a viable proof-based agent that has a consistent set of axioms describing a potentially-inconsistent set of probabilities. That's an intriguing idea but I'm having trouble seeing how it would work. E.g., suppose I'm searching for proofs that my expected utility if I do X is at least Y units; that expectation obviously involves a whole lot of probabilities, and my actual probability assignments are inconsistent in various ways. How do I prove anything about my expected utilities if the probabilities involved might be inconsistent?
This is all a bit off topic on this particular post; it's not especially about your account of decision-theoretic counterfactuals as such, but about the whole project of understanding decision theory in terms of agents whose decision processes involve trying to prove things about their own behaviour.
comment by Pattern · 2021-04-12T17:42:30.674Z · LW(p) · GW(p)
As an example, I think it should be possible to learn to use a source of randomness in rock-paper-scissors against someone who can perfectly predict your decision, but not the extra randomness.
In order to do that, you have to think of doing that. (Seeing randomness might be hard - seeing 'I have information I don't think they have, and I don't think they can read minds, so they can't predict this' makes more sense intuitively.) In practice, I don't think people conduct exploration like this.
PCDT, faced with the possibility of encountering a Newcomblike problem at some point,
Similarly, I think a lot of agents consider possibilities after they encounter them at least once. This might help solve the cost of simulation/computation.
Radical Probabalism and InfraBayes are plausibly two orthogonal dimensions of generalization for rationality. Ultimately we want to generalize in both directions,
I'm glad this was highlighted.
comment by TekhneMakre · 2021-04-10T05:21:25.909Z · LW(p) · GW(p)
(Side note: There's an aspect to the notion of "causal counterfactual" that I think it's worth distinguishing from what's discussed here. This post seems to take causal counterfactuals to be a description of top-level decision reasoning. A different meaning is that causal counterfactuals refer to an aspiration / goal. Causal interventions are supposed to be interventions that "affect nothing but what's explicitly said to be affected". We could try to describe actions in this way, carefully carving out exactly what's affected and what's not; and we find that we can't do this, and so causal counterfactuals aren't, and maybe can't possibly, be a good description (e.g. because of Newcomb-like problems). But instead we could view them as promises: if I manage to "do X and only X" then exactly such and such effects result. In real life if I actually do X there will be other effects, but they must result from me having done something other than just exactly X. This seems related to the way in which humans know how to express preferences data-efficiently, e.g. "just duplicate this strawberry, don't do any crazy other stuff".)
Replies from: abramdemski↑ comment by abramdemski · 2021-04-10T15:46:30.288Z · LW(p) · GW(p)
I'm not really sure what you're getting at.
Causal interventions are supposed to be interventions that "affect nothing but what's explicitly said to be affected".
This seems like a really bad description to me. For example, suppose we have the causal graph . We intervene on . We don't want to "affect nothing but y" -- we affect z, too. But we don't get to pick and choose; we couldn't choose to affect x and y without affecting z.
So I'd rather say that we "affect nothing but what we intervene on and what's downstream of what we intervened on".
Not sure whether this has anything to do with your point, though.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2021-04-10T18:32:56.256Z · LW(p) · GW(p)
So I'd rather say that we "affect nothing but what we intervene on and what's downstream of what we intervened on".
A fair clarification.
Not sure whether this has anything to do with your point, though.
My point is very tangential to your post: you're talking about decision theory as top-level naturalized ways of making decisions, and I'm talking about some non-top-level intuitions that could be called CDT-like. (This maybe should've been a comment on your Dutch book post.) I'm trying to contrast the aspirational spirit of CDT, understood as "make it so that there's such a thing as 'all of what's downstream of what we intervened on' and we know about it", with descriptive CDT, "there's such a thing as 'all of what's downstream of what we intervened on' and we can know about it". Descriptive CDT is only sort of right in some contexts, and can't be right in some contexts; there's no fully general Arcimedean point from which we intervene.
We can make some things more CDT-ish though, if that's useful. E.g. we could think more about how our decisions have effects, so that we have in view more of what's downstream of decisions. Or e.g. we could make our decisions have fewer effects, for example by promising to later reevaluate some algorithm for making judgements, instead of hiding within our decision to do X also our decision to always use the piece-of-algorithm that (within some larger mental context) decided to do X. That is, we try to hold off on decisions that have downstream effects we don't understand well yet.
comment by Archimedes · 2021-06-02T20:58:24.558Z · LW(p) · GW(p)
I'm having trouble accepting that the Troll Bridge scenario is well-posed as opposed to a Russell-like paradox. Perhaps someone can clarify what I'm missing.
In my mind, there are two options:
-
If PA is inconsistent, then math is in ruins and any PA-based reasoning for crossing the bridge could be inconsistent and the troll blows up the bridge. Do not cross.
-
If PA is consistent, then the agent cannot prove U = -10 (or anything else inconsistent) under the assumption that the agent already crossed, and therefore Löb's theorem fails to apply. In this case, there is no weird certainty that crossing is doomed.
Now until/unless PA is proven inconsistent, it's reasonable to assign the majority of probability mass to the prior that PA is, in fact, consistent and we can ignore counterfactuals that depend on proving otherwise since if that's proven, none of the rest of the reasoning matters anyway until foundational logic has been reformulated on a consistent basis.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-09T18:33:21.783Z · LW(p) · GW(p)
If PA is consistent, then the agent cannot prove U = -10 (or anything else inconsistent) under the assumption that the agent already crossed, and therefore Löb's theorem fails to apply. In this case, there is no weird certainty that crossing is doomed.
I think this is the wrong step. Why do you think this? Just because PA is consistent doesn't mean you can't prove weird things under assumption. Look at the structure of the proof. You're objecting to an assumption. ("Suppose PA proves that crossing -> U=-10") That's a pretty weird way to object to a proof. I'm allowed to make any assumptions I like.
My guess is that you are wrestling with Lobs theorem itself. Lobs theorem is pretty weird!
Replies from: Archimedes↑ comment by Archimedes · 2021-06-14T15:48:54.583Z · LW(p) · GW(p)
I'm objecting to an assumption that contradicts a previous assumption which leads to inconsistent PA. If PA is consistent, then we can't just suppose 1 = 2 because we feel like it. If 1 = 2, then PA is inconsistent and math is broken.
Assuming PA is consistent and assuming the agent has crossed, then U for crossing cannot be -10 or the agent would not have crossed. Weird assumptions like "1 = 2" or "the agent proves crossing implies U = -10" contradict the existing assumption of PA consistency. Any proof that involves inconsistency of PA as a key step is immediately suspect.
Let's take a look at the proof using a simpler assumption.
Suppose the agent crosses. Further suppose the agent proves crossing implies 1 = 2. Such a proof means PA is inconsistent, so 1 = 2 is indeed "true" within PA. Thus "agent proves crossing implies 1 = 2" implies 1 = 2. Therefore by Löb's theorem, crossing implies 1 = 2.
This is just a fancy way of abusing Löb's theorem to bootstrap a vacuously true statement by applying it to an inconsistent axiom system. Within consistent PA, this proof is nonsense. With inconsistent PA, every proof in PA is nonsense, so it doesn't make sense to make assumptions that lead to inconsistent PA. If the proof leads to "PA is inconsistent", then every step that follows from that step is unreliable.
In my opinion, the whole Troll Bridge Problem boils down to supposing False = True and then trying to apply logical reasoning to the resulting inconsistent system. Of course you get a paradox when you suppose U = -10 and U >= 0 simultaneously.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-22T22:46:58.359Z · LW(p) · GW(p)
I'm objecting to an assumption that contradicts a previous assumption which leads to inconsistent PA. If PA is consistent, then we can't just suppose 1 = 2 because we feel like it. If 1 = 2, then PA is inconsistent and math is broken.
Ah. But in standard math and logic, this is exactly what we do. We can suppose anything because we feel like it.
It sounds like you want something similar to "relevance logic", in that relevance logic is also a nonstandard logic which doesn't let you do whatever you want just for the heck of it. I don't know a whole lot about it, but I think assumptions must be relevant, basically meaning that we actually have to use them. However, afaik, even relevance logic lets us assume things which are contrary to previous assumptions!
Would you also object to the following proof?
- Suppose A.
- Suppose A.
- Contradiction.
- So A.
- Suppose A.
- So A A.
In this proof, I show that A implies its own double negation, but to do so, I have to suppose something contrary to something I've already supposed.
Assuming PA is consistent and assuming the agent has crossed, then U for crossing cannot be -10 or the agent would not have crossed. Weird assumptions like "1 = 2" or "the agent proves crossing implies U = -10" contradict the existing assumption of PA consistency. Any proof that involves inconsistency of PA as a key step is immediately suspect.
Just to emphasize: this is going to have to be a very nonstandard logic, for your notion of which proofs are/aren't suspect to work.
It is possible that troll bridge could be solved with a very nonstandard logic, of course, but we would also want the logic to do lots of other nice things (ie, support normal reasoning to a very large degree). But it is not clear how you would propose to do that; for example, the proof that a sentence implies its own double negation would appear to be thrown out.
Suppose the agent crosses. Further suppose the agent proves crossing implies 1 = 2. Such a proof means PA is inconsistent, so 1 = 2 is indeed "true" within PA. Thus "agent proves crossing implies 1 = 2" implies 1 = 2. Therefore by Löb's theorem, crossing implies 1 = 2.
Putting this in symbols, using box to mean "is provable in PA":
- Suppose (cross -> 1=2).
- Suppose the agent crosses.
- Therefore, cross ->
- Suppose the agent crosses.
- So
See the problem? For Lobs theorem to apply, we need to prove . Here, you have an extra box: . So, your proof doesn't go through.
If the proof leads to "PA is inconsistent", then every step that follows from that step is unreliable.
Again, I just want to emphasize that this reasoning implies a very nonstandard logic (which probably wouldn't even support Lob's theorem to begin with?). Normal logic has no conditions like "you can start ignoring a proof if it starts saying such and such". Indeed, this would sort of defeat the point of logic: each step is supposed to be individually justified. And in particular, in typical logics (including classical logic, intuitionistic logic, linear logic, and many others), you can assume whatever you want; the point of logic is to study what follows from what, which means we can make any supposition, and see what follows from it. You don't have to believe it, but you do have to believe that if you assumed it, such-and-such would follow.
Putting restrictions on what we can even assume sounds like putting restrictions on what arguments we're allowed to listen to, rather than studying the structure of arguments. Logic doesn't keep people from making bad assumptions; it only tells you what those assumptions imply.
A hypothetical assumption doesn't harm anybody. If A is totally absurd, that's fine; we can derive sentences like . The conclusions should be confined to the hypothetical. So, under ordinary circumstances, there is no reason to restrict people from making absurd assumptions. Garbage in, garbage out. No problem.
It's Lobs theorem that's letting us take our absurd conclusions and "break them out of the hypothetical" here.
So as I stated before, I think you should be wrestling with Lobs theorem itself here, rather than finding the flaws in other places. I think you're chasing shadows with your hypothesis about restricting when we can make which assumptions. That's simply not the culprit here.
Replies from: Archimedes↑ comment by Archimedes · 2021-06-25T15:09:21.927Z · LW(p) · GW(p)
I just want to say thanks for taking the time to address my comments. The proof given for the Troll Problem still feels wrong to me but you're helping me get closer to finding the core of where my intuition is inconsistent with it. I'll consider what you've pointed out and re-examine the problem with a bit more clarity.
comment by Bunthut · 2021-04-24T11:37:54.477Z · LW(p) · GW(p)
Because we have a “basic counterfactual” proposition for what would happen if we 1-box and what would happen if we 2-box, and both of those propositions stick around, LCH’s bets about what happens in either case both matter. This is unlike conditional bets, where if we 1-box, then bets conditional on 2-boxing disappear, refunded, as if they were never made in the first place.
I don't understand this part. Your explanation of PCDT at least didn't prepare me for it, it doesn't mention betting. And why is the payoff for the counterfactual-2-boxing determined by the beliefs of the agent after 1-boxing?
And what I think is mostly independent of that confusion: I don't think things are as settled.
I'm more worried about the embedding problems with the trader in dutch book arguments, so the one against CDT isn't as decisive for me.
In the Troll Bridge hypothetical, we prove that [cross]->[U=-10]. This will make the conditional expectations poor. But this doesn’t have to change the counterfactuals.
But how is the counterfactual supposed to actually think? I don't think just having the agent unrevisably believe that crossing is counterfactually +10 is a reasonable answer, even if it doesn't have any instrumental problems in this case. I think it ought to be possible to get something like "whether to cross in troll bridge depends only on what you otherwise think about PAs consistency" with some logical method. But even short of that, there needs to be some method to adjust your counterfactuals if they fail to really match you conditionals. And if we had an actual concrete model of counterfactual reasoning instead of a list of desiderata, it might be possible to make a troll based on the consistency of whatever is inside this model, as opposed to PA.
I also think there is a good chance the answer to the cartesian boundary problem won't be "heres how to calculate where your boundary is", but something else of which boundaries are an approximation, and then something similar would go for counterfactuals, and then there won't be a counterfactual theory which respects embedding.
These later two considerations suggest the leftover work isn't just formalisation.
Replies from: abramdemski↑ comment by abramdemski · 2021-04-30T16:10:14.751Z · LW(p) · GW(p)
I don't understand this part. Your explanation of PCDT at least didn't prepare me for it, it doesn't mention betting. And why is the payoff for the counterfactual-2-boxing determined by the beliefs of the agent after 1-boxing?
Not sure how to best answer. I'm thinking of all this in an LIDT setting, so all learning occurs through traders making bets. The payoff for 2-boxing is dependent on beliefs after 1-boxing because all share prices update every market day and the "payout" for a share is essentially what you can sell it for. Similarly, if a trader buys a share of an undecidable sentence (let's say, the consistency of PA) then the only "payoff" is whatever you can sell it for later, based on future market prices, because the sentence will never get fully decided one way or the other.
But how is the counterfactual supposed to actually think? I don't think just having the agent unrevisably believe that crossing is counterfactually +10 is a reasonable answer, even if it doesn't have any instrumental problems in this case.
My claim is: eventually, if you observe enough cases of "crossing" in similar circumstances, your expectation for "cross" should be consistent with the empirical history (rather than, say, -10 even though you've never experienced -10 for crossing). To give a different example, I'm claiming it is irrational to persist in thinking 1-boxing gets you less money in expectation, if your empirical history continues to show that it is better on average.
And I claim that if there is a persistent disagreement between counterfactuals and evidential conditionals, then the agent will in fact experimentally try crossing infinitely often, due to the value-of-information of testing the disagreement (that is, this will be the limiting behavior of reduced temporal discounting, under the assumption that the agent isn't worried about traps).
So the two will indeed converge (under those assumptions).
And if we had an actual concrete model of counterfactual reasoning instead of a list of desiderata, it might be possible to make a troll based on the consistency of whatever is inside this model, as opposed to PA.
The hope is that we can block the troll argument completely if proving B->A does not imply cf(A|B)=1, because no matter what predicate the troll uses, the inference from P to cf fails. So what we concretely need to do is give a version of counterfactual reasoning which lets cf(A|B) not equal 1 in some cases where B->A is proved.
Granted, there could be some other problematic argument. However, if my learning-theoretic ideas go through, this provides another safeguard: Troll Bridge is a case where the agent never learns the empirical distribution, due to refusing to observe a specific case. If we know this never happens (given the learnability conditions), then this blocks off a whole range of Troll-Bridge-like arguments.
I'm more worried about the embedding problems with the trader in dutch book arguments, so the one against CDT isn't as decisive for me.
[...]
I also think there is a good chance the answer to the cartesian boundary problem won't be "heres how to calculate where your boundary is", but something else of which boundaries are an approximation, and then something similar would go for counterfactuals, and then there won't be a counterfactual theory which respects embedding.
This is a sensible position. I think this is similar to Scott G's take on my direction.
My argument would not be that the dutch book should be super compelling, but rather, that it appears we can do everything without questioning so many assumptions.
For example, Scott would argue that probability is for things spacelike separated from you [LW · GW], so we need a different concept for thinking about consequences of actions. My argument is not anything against Scott's concrete reasons to cast doubt on the broad applicability of probabilistic thinking; rather, my argument is "look at all the things we can do with probabilistic reasoning" (at least, suitably [LW · GW] generalized [? · GW]).
In particular, good learning-theoretic results can address concerns about decision-theoretic paradoxes; a convincing optimality result could and should systematically rule out a wide range of decision-theoretic paradoxes. So, if true, it could become difficult to motivate any additional worries about cartesian frames etc.
Replies from: Bunthut↑ comment by Bunthut · 2021-05-17T15:43:35.896Z · LW(p) · GW(p)
The payoff for 2-boxing is dependent on beliefs after 1-boxing because all share prices update every market day and the "payout" for a share is essentially what you can sell it for.
If a sentence is undecidable, then you could have two traders who disagree on its value indefinitely: one would have a highest price to buy, thats below the others lowest price to sell. But then anything between those two prices could be the "market price", in the classical supply and demand sense. If you say that the "payout" of a share is what you can sell it for... well, the "physical causation" trader is also buying shares on the counterfactual option that won't happen. And if he had to sell those, he couldn't sell them at a price close to where he bought them - he could only sell them at how much the "logical causation" trader values them, and so both would be losing "payout" on their trades with the unrealized option. Thats one interpretation of "sell". If theres a "market maker" in addition to both traders, it depends on what prices he makes - and as outlined above, there is a wide range of prices that would be consistent for him to offer as a market maker, including ways which are very close to the logical traders valuations - in which case, the logical trader is gaining on the physical one.
Trying to communicate a vague intuition here: There is a set of methods which rely on there being a time when "everything is done", to then look back from there and do credit assignment for everything that happened before. They characteristically use backwards induction to prove things. I think markets fall into this: the argument for why ideal markets don't have bubbles is that eventually, the real value will be revealed, and so the bubble has to pop, and then someone holds the bag, and you don't want to be that someone, and people predicting this and trying to avoid it will make the bubble pop earlier, in the idealised case instantly. I also think these methods aren't going to work well with embedding. They essentially use "after the world" as a subsitute for "outside the world".
My claim is: eventually, if you observe enough cases of "crossing" in similar circumstances, your expectation for "cross" should be consistent with the empirical history
My question was more "how should this roughly work" rather than "what conditions should it fulfill", because I think thinking about this illuminates my next point.
The hope is that we can block the troll argument completely if proving B->A does not imply cf(A|B)=1
This doesn't help against what I'm imagining, I'm not touching indicative B->A. So, standard Troll Bridge:
- Reasoning within PA (ie, the logic of the agent):
- Suppose the agent crosses.
- Further suppose that the agent proves that crossing implies U=-10.
- Examining the source code of the agent, because we're assuming the agent crosses, either PA proved that crossing implies U=+10, or it proved that crossing implies U=0.
- So, either way, PA is inconsistent -- by way of 0=-10 or +10=-10.
- So the troll actually blows up the bridge, and really, U=-10.
- Therefore (popping out of the second assumption), if the agent proves that crossing implies U=-10, then in fact crossing implies U=-10.
- By Löb's theorem, crossing really implies U=-10.
- So (since we're still under the assumption that the agent crosses), U=-10.
- Further suppose that the agent proves that crossing implies U=-10.
- So (popping out of the assumption that the agent crosses), the agent crossing implies U=-10.
- Suppose the agent crosses.
- Since we proved all of this in PA, the agent proves it, and proves no better utility in addition (unless PA is truly inconsistent). On the other hand, it will prove that not crossing gives it a safe U=0. So it will in fact not cross.
But now, say the agents counterfactual reasoning comes not from PA, but from system X. Then the argument fails because "suppose the agent proves crossing->U=-10 in PA" doesn't go any further because examining the sourcecode of the agent doesn't say anything about PA anymore, and "suppose the agent proves crossing->U=-10 in X" doesn't show that PA is inconsistent, so the bridge isn't blown up. But lets have a troll that blows up the bridge if X is inconsistent. Then we can make an argument like this:
- Reasoning within X (ie, the logic of counterfactuals):
- Suppose the agent crosses.
- Further suppose that the agent proves in X that crossing implies U=-10.
- Examining the source code of the agent, because we're assuming the agent crosses, either X proved that crossing implies U=+10, or it proved that crossing implies U=0.
- So, either way, X is inconsistent -- by way of 0=-10 or +10=-10.
- So the troll actually blows up the bridge, and really, U=-10.
- Therefore (popping out of the second assumption), if the agent proves that crossing implies U=-10, then in fact crossing implies U=-10.
- By Löb's theorem, crossing really implies U=-10.
- So (since we're still under the assumption that the agent crosses), U=-10.
- Further suppose that the agent proves in X that crossing implies U=-10.
- So (popping out of the assumption that the agent crosses), the agent crossing implies U=-10.
- Suppose the agent crosses.
- Since we proved all of this in X, the agent proves it, and proves no better utility in addition (unless X is truly inconsistent). On the other hand, it will prove that not crossing gives it a safe U=0. So it will in fact not cross.
Now, this argument relies on X and counterfactual reasoning having a lot of the properties of PA and normal reasoning. But even a system that doesn't run on proofs per se could still end up implementing something a lot like logic, and then it would have a property thats a lot like inconsistency, and then the troll could blow up the bridge conditionally on that. Basically, it still seems reasonable to me that counterfactual worlds should be closed under inference, up to our ability to infer. And I don't see which of the rules for manipulating logical implications wouldn't be valid for counterfactual implications in their own closed system, if you formally separate them. If you want your X to avoid this argument, then it needs to not-do something PA does. "Formal separation" between the systems isn't enough, because the results of counterfactual reasoning still really do effect your actions, and if the counterfactual reasoning system can understand this, Troll Bridge returns. And if there was such a something, we could just use a logic that doesn't do this in the first place, no need for the two-layer approach.
a convincing optimality result could
I'm also sceptical of optimality results. When you're doing subjective probability, any method you come up with will be proven optimal relative to its own prior - the difference between different subjective methods is only in their ontology, and the optimality results don't protect you against mistakes there. Also, when you're doing subjectivism, and it turns out the methods required to reach some optimality condition aren't subjectively optimal, you say "Don't be a stupid frequentist and do the subjectively optimal thing instead". So, your bottom line is written. If the optimality condition does come out in your favour, you can't be more sure because of it - that holds even under the radical version of expected evidence conservation. I also suspect that as subjectivism gets more "radical", there will be fewer optimality results besides the one relative to prior.
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2021-05-18T15:25:41.948Z · LW(p) · GW(p)
I'm also sceptical of optimality results. When you're doing subjective probability, any method you come up with will be proven optimal relative to its own prior - the difference between different subjective methods is only in their ontology, and the optimality results don't protect you against mistakes there. Also, when you're doing subjectivism, and it turns out the methods required to reach some optimality condition aren't subjectively optimal, you say "Don't be a stupid frequentist and do the subjectively optimal thing instead". So, your bottom line is written. If the optimality condition does come out in your favour, you can't be more sure because of it - that holds even under the radical version of expected evidence conservation. I also suspect that as subjectivism gets more "radical", there will be fewer optimality results besides the one relative to prior.
This sounds like doing optimality results poorly. Unfortunately, there is a lot of that (EG how the different optimality notions for CDT and EDT don't help decide between them).
In particular, the "don't be a stupid frequentist" move has blinded Bayesians (although frequentists have also been blinded in a different way).
Solomonoff induction has a relatively good optimality notion (that it doesn't do too much worse than any computable prediction).
AIXI has a relatively poor one (you only guarantee that you take the subjectively best action according to Solomonoff induction; but this is hardly any guarantee at all in terms of reward gained, which is supposed to be the objective). (There are variants of AIXI which have other optimality guarantees, but none very compelling afaik.)
An example of a less trivial optimality notion is the infrabayes idea, where if the world fits within the constraints of one of your partial hypotheses, then you will eventually learn to do at least as well (reward-wise) as that hypothesis implies you can do.
↑ comment by abramdemski · 2021-05-17T20:52:18.234Z · LW(p) · GW(p)
If a sentence is undecidable, then you could have two traders who disagree on its value indefinitely: one would have a highest price to buy, thats below the others lowest price to sell. But then anything between those two prices could be the "market price", in the classical supply and demand sense. If you say that the "payout" of a share is what you can sell it for... well, the "physical causation" trader is also buying shares on the counterfactual option that won't happen. And if he had to sell those, he couldn't sell them at a price close to where he bought them - he could only sell them at how much the "logical causation" trader values them, and so both would be losing "payout" on their trades with the unrealized option. Thats one interpretation of "sell". If theres a "market maker" in addition to both traders, it depends on what prices he makes - and as outlined above, there is a wide range of prices that would be consistent for him to offer as a market maker, including ways which are very close to the logical traders valuations - in which case, the logical trader is gaining on the physical one.
Hmm. Well, I didn't really try to prove that 'physical causation' would persist as a hypothesis. I just tried to show that it wouldn't, and failed. If you're right, that'd be great!
But here is what I am thinking:
Firstly, yes, there is a market maker. You can think of the market maker as setting the price exactly where buys and sells balance; both sides stand to win the same amount if they're correct, because that amount is just the combined amount they've spent.
Causality is a little funky because of fixed point stuff, but rather than imagining the traders hold shares for a long time, we can instead imagine that today's shares "pay out" overnight (at the next day's prices), and then traders have to re-invest if they still want to hold a position. (But this is fine, because they got paid the next day's prices, so they can afford to buy the same number of shares as they had.)
But if the two traders don't reinvest, then tomorrow's prices (and therefore their profits) are up to the whims of the rest of the market.
So I don't see how we can be sure that PCH loses out overall. LCH has to exploit PCH -- but if LCH tries it, then we're seemingly in a situation where LCH has to sell for PCH's prices, in which case it suffers the loss I described in the OP.
Thanks for raising the question, though! It would be very interesting if PCH actually could not maintain its position.
My question was more "how should this roughly work" rather than "what conditions should it fulfill", because I think thinking about this illuminates my next point.
I have been thinking a bit more about this.
I think it should roughly work like this: you have a 'conditional contract', which is like normal conditional bets, except normally a conditional bet (a|b) is made up of a conjunction bet (a&b) and a hedge on the negation of the condition (not-b); the 'conditional contract' instead gives the trader an inseparable pair of contracts (the a&x bet bound together with the not-b bet).
Normally, the price of anything that's proved goes to one quickly (and zero for anything refuted), because traders are getting $1 per share (and $0 per share for what's been refuted). (We can also have the market maker just automatically set these prices to 1 and 0, which is probably more sensible.) That's why the conditional probability for b|a goes to 1 when a->b is proved: a->b is not(a & not b), so the price of a¬(b) goes to 0, so the price of not(b)|a goes to zero.
But the special bundled contract doesn't go to zero like this, because the conditional contract only really pays out when the condition is satisfied or refuted. If a trader tries to 'correct' the conditional-contract market by buying b|a when a->b, the trader will only exploit the market in the case that b actually occurs (which is not happening in Troll Bridge).
Granted, this sounds like a huge hack.
Reasoning within X (ie, the logic of counterfactuals):
As you note, this does not work if X is extremely weak (which is the plan outlined in the OP). This is in keeping with the spirit of the "subjective theory of counterfactuals": there are very few constraints on logical counterfactuals, since after all, they may violate logic!
But even a system that doesn't run on proofs per se could still end up implementing something a lot like logic, and then it would have a property thats a lot like inconsistency, and then the troll could blow up the bridge conditionally on that.
I agree that this is a serious concern. For example, we can consider logical induction without any logic (eg, the universal induction formalism). It doesn't apparently have troll bridge problems, because it lacks logic. But if it comes to believe any PA-like logic strongly, then it will be susceptible to Troll Bridge.
My proposal is essentially similar to that, except I am trying to respect logic in most of the system, simply reducing its impact on action selection. But within my proposed system, I think the wrong 'prior' (ie distribution of wealth for traders) can make it susceptible again.
I'm not blocking Troll Bridge problems, I'm making the definition of rational agent broad enough that crossing is permissible. But if I think the Troll Bridge proof is actively irrational, I should be able to actually rule it out. IE, specify an X which is inconsistent with PA.
I don't have any proposal for that.
Replies from: Bunthut↑ comment by Bunthut · 2021-05-18T08:03:47.749Z · LW(p) · GW(p)
So I don't see how we can be sure that PCH loses out overall. LCH has to exploit PCH -- but if LCH tries it, then we're seemingly in a situation where LCH has to sell for PCH's prices, in which case it suffers the loss I described in the OP.
So I've reread the logical induction paper for this, and I'm not sure I understand exploitation. Under 3.5, it says:
On each day, the reasoner receives 50¢ from T, but after day t, the reasoner must pay $1 every day thereafter.
So this sounds like before day t, T buys a share every day, and those shares never pay out - otherwise T would receive $t on day t in addition to everything mentioned here. Why?
In the version that I have in my head, theres a market with PCH and LCH in it that assigns constant price to the unactualised bet, so neither of them gain or lose anything with their trades on it, and LCH exploits PCH on the actualised ones.
But the special bundled contract doesn't go to zero like this, because the conditional contract only really pays out when the condition is satisfied or refuted.
So if I'm understanding this correctly: The conditional contract on (a|b) pays if a&b is proved, if a&~b is proved, and if ~a&~b is proved.
Now I have another question: how does logical induction arbitrage against contradiction? The bet on a pays $1 if a is proved. The bet on ~a pays $1 if not-a is proved. But the bet on ~a isn't "settled" when a is proved - why can't the market just go on believing its .7? (Likely this is related to my confusion with the paper).
My proposal is essentially similar to that, except I am trying to respect logic in most of the system, simply reducing its impact on action selection. But within my proposed system, I think the wrong 'prior' (ie distribution of wealth for traders) can make it susceptible again.
I'm not blocking Troll Bridge problems, I'm making the definition of rational agent broad enough that crossing is permissible. But if I think the Troll Bridge proof is actively irrational, I should be able to actually rule it out. IE, specify an X which is inconsistent with PA.
What makes you think that theres a "right" prior? You want a "good" learning mechanism for counterfactuals. To be good, such a mechanism would have to learn to make the inferences we consider good, at least with the "right" prior. But we can't pinpoint any wrong inference in Troll Bridge. It doesn't seem like whats stopping us from pinpointing the mistake in Troll Bridge is a lack of empirical data. So, a good mechanism would have to learn to be susceptible to Troll Bridge, especially with the "right" prior. I just don't see what would be a good reason for thinking theres a "right" prior that avoids Troll Bridge (other than "there just has to be some way of avoiding it"), that wouldn't also let us tell directly how to think about Troll Bridge, no learning needed.
Replies from: abramdemski, abramdemski, abramdemski↑ comment by abramdemski · 2021-05-18T16:05:37.718Z · LW(p) · GW(p)
Now I have another question: how does logical induction arbitrage against contradiction? The bet on a pays $1 if a is proved. The bet on ~a pays $1 if not-a is proved. But the bet on ~a isn't "settled" when a is proved - why can't the market just go on believing its .7? (Likely this is related to my confusion with the paper).
Again, my view may have drifted a bit from the LI paper, but the way I think about this is that the market maker looks at the minimum amount of money a trader has "in any world" (in the sense described in my other comment). This excludes worlds which the deductive process has ruled out, so for example if has been proved, all worlds will have either A or B. So if you had a bet which would pay $10 on A, and a bet which would pay $2 on B, you're treated as if you have $2 to spend. It's like a bookie allowing a gambler to make a bet without putting down the money because the bookie knows the gambler is "good for it" (the gambler will definitely be able to pay later, based on the bets the gambler already has, combined with the logical information we now know).
Of course, because logical bets don't necessarily ever pay out, the market maker realistically shouldn't expect that traders are necessarily "good for it". But doing so allows traders to arbitrage logically contradictory beliefs, so, it's nice for our purposes. (You could say this is a difference between an ideal prediction market and a mere betting market; a prediction market should allow arbitrage of inconsistency in this way.)
Replies from: Bunthut↑ comment by Bunthut · 2021-05-19T13:26:36.738Z · LW(p) · GW(p)
This excludes worlds which the deductive process has ruled out, so for example if has been proved, all worlds will have either A or B. So if you had a bet which would pay $10 on A, and a bet which would pay $2 on B, you're treated as if you have $2 to spend.
I agree you can arbitrage inconsistencies this way, but it seems very questionable. For one, it means the market maker needs to interpret the output of the deductive process semantically. And it makes him go bankrupt if that logic is inconsistent. And there could be a case where a proposition is undecidable, and a meta-proposition about it is undecidable, and a meta-meta-propopsition about it is undecidable, all the way up, and then something bad happens, though I'm not sure what concretely.
↑ comment by abramdemski · 2021-05-18T15:54:53.680Z · LW(p) · GW(p)
On each day, the reasoner receives 50¢ from T, but after day t, the reasoner must pay $1 every day thereafter.
Hm. It's a bit complicated and there are several possible ways to set things up. Reading that paragraph, I'm not sure about this sentence either.
In the version I was trying to explain, where traders are "forced to sell" every morning before the day of trading begins, the reasoner would receive 50¢ from the trader every day, but would return that money next morning. Also, in the version I was describing, the reasoner is forced to set the price to $1 rather than 50¢ as soon as the deductive process proves 1+1=2. So, that morning, the reasoner has to return $1 rather than 50¢. That's where the reasoner loses money to the trader. After that, the price is $1 forever, so the trader would just be paying $1 every day and getting that $1 back the next morning.
I would then define exploitation as "the trader's total wealth (across different times) has no upper bound". (It doesn't necessarily escape to infinity -- it might oscillate up and down, but with higher and higher peaks.)
Now, the LI paper uses a different definition of exploitation, which involves how much money a trader has within a world (which basically means we imagine the deductive process decides all the sentences, and we ask how much money the trader would have; and, we consider all the different ways the deductive process could do this). This is not equivalent to my definition of exploitation in general; according to the LI paper, a trader 'exploits' the market even if its wealth is unbounded only in some very specific world (eg, where a specific sequence of in-fact-undecidable sentences gets proved).
However, I do have an unpublished proof that the two definitions of exploitation are equivalent for the logical induction algorithm and for a larger class of "reasonable" logical inductors. This is a non-trivial result, but, justifies using my definition of exploitation (which I personally find a lot more intuitive). My basic intuition for the result is: if you don't know the future, the only way to ensure you don't lose unbounded money in reality is to ensure you don't lose unbounded money in any world. ("If you don't know the future" is a significant constraint on logical inductors.)
Also, when those definitions do differ, I'm personally not convinced that the definition in the logical induction paper is better... it is stronger, in the sense that it gives us a more stringent logical induction criterion, but the "irrational" behaviors which it helps rule out don't seem particularly irrational to me. Simply put, I am only convinced that I should care about actually losing unbounded money, as opposed to losing unbounded money in some hypothetical world.
In the version that I have in my head, theres a market with PCH and LCH in it that assigns constant price to the unactualised bet, so neither of them gain or lose anything with their trades on it, and LCH exploits PCH on the actualised ones.
Why is the price of the un-actualized bet constant? My argument in the OP was to suppose that PCH is the dominant hypothesis, so, mostly controls market prices. PCH thinks it gains important information when it sees which action we actually took, so it updates the expectation for the un-actualized action. So the price moves. Similarly, if PCH and LCH had similar probability, we would expect the price to move.
Replies from: Bunthut↑ comment by Bunthut · 2021-05-19T13:08:01.738Z · LW(p) · GW(p)
Why is the price of the un-actualized bet constant? My argument in the OP was to suppose that PCH is the dominant hypothesis, so, mostly controls market prices.
Thinking about this in detail, it seems like what influence traders have on the market price depends on a lot more of their inner workings than just their beliefs. I was thinking in a way where each trader only had one price for the bet, below which they bought and above which they sold, no matter how many units they traded (this might contradict "continuous trading strategies" because of finite wealth), in which case there would be a range of prices that could be the "market" price, and it could stay constant even with one end of that range shifting. But there could also be an outcome like yours, if the agents demand better and better prices to trade one more unit of the bet.
Replies from: abramdemski↑ comment by abramdemski · 2021-05-19T14:11:56.192Z · LW(p) · GW(p)
The continuity property is really important.
Replies from: Bunthut↑ comment by Bunthut · 2021-05-25T20:48:50.183Z · LW(p) · GW(p)
I think its still possible to have a scenario like this. Lets say each trader would buy or sell a certain amount when the price is below/above what they think it to be, but the transition being very steep instead of instant. Then you could still have long price intervalls where the amounts bought and sold remain constant, and then every point in there could be the market price.
I'm not sure if this is significant. I see no reason to set the traders up this way other than the result in the particular scenario that kicked this off, and adding traders who don't follow this pattern breaks it. Still, its a bit worrying that trading strategies seem to matter in addition to beliefs, because what do they represent? A traders initial wealth is supposed to be our confidence in its heuristics - but if a trader is mathematical heuristics and trading strategy packaged, then what does confidence in the trading strategy mean epistemically? Two things to think about:
Is it possible to consistently define the set of traders with the same beliefs as trader X?
It seems that logical induction is using a trick, where it avoids inconsistent discrete traders, but includes an infinite sequence of continuous traders with ever steeper transitions to get some of the effects. This could lead to unexpected differences between behaviour "at all finite steps" vs "at the limit". What can we say about logical induction if trading strategies need to be lipschitz-continuous with a shared upper limit on the lipschitz constant?
↑ comment by abramdemski · 2021-05-18T15:06:01.588Z · LW(p) · GW(p)
What makes you think that theres a "right" prior? You want a "good" learning mechanism for counterfactuals. To be good, such a mechanism would have to learn to make the inferences we consider good, at least with the "right" prior. But we can't pinpoint any wrong inference in Troll Bridge. It doesn't seem like whats stopping us from pinpointing the mistake in Troll Bridge is a lack of empirical data. So, a good mechanism would have to learn to be susceptible to Troll Bridge, especially with the "right" prior. I just don't see what would be a good reason for thinking theres a "right" prior that avoids Troll Bridge (other than "there just has to be some way of avoiding it"), that wouldn't also let us tell directly how to think about Troll Bridge, no learning needed.
Now I feel like you're trying to have it both ways; earlier you raised the concern that a proposal which doesn't overtly respect logic could nonetheless learn a sort of logic internally, which could then be susceptible to Troll Bridge. I took this as a call for an explicit method of avoiding Troll Bridge, rather than merely making it possible with the right prior.
But now, you seem to be complaining that a method that explicitly avoids Troll Bridge would be too restrictive?
To be good, such a mechanism would have to learn to make the inferences we consider good, at least with the "right" prior. But we can't pinpoint any wrong inference in Troll Bridge.
I think there is a mistake somewhere in the chain of inference from to low expected value for crossing. Material implication is being conflated with counterfactual implication.
A strong candidate from my perspective is the inference from to where represents probabilistic/counterfactual conditional (whatever we are using to generate expectations for actions).
So, a good mechanism would have to learn to be susceptible to Troll Bridge, especially with the "right" prior.
You seem to be arguing that being susceptible to Troll Bridge should be judged as a necessary/positive trait of a decision theory. But there are decision theories which don't have this property, such as regular CDT, or TDT (depending on the logical-causality graph). Are you saying that those are all necessarily wrong, due to this?
I just don't see what would be a good reason for thinking theres a "right" prior that avoids Troll Bridge (other than "there just has to be some way of avoiding it"), that wouldn't also let us tell directly how to think about Troll Bridge, no learning needed.
I'm not sure quite what you meant by this. For example, I could have a lot of prior mass on "crossing gives me +10, not crossing gives me 0". Then my +10 hypothesis would only be confirmed by experience. I could reason using counterfactuals, so that the troll bridge argument doesn't come in and ruin things. So, there is definitely a way. And being born with this prior doesn't seem like some kind of misunderstanding/delusion about the world.
So it also seems natural to try and design agents which reliably learn this, if they have repeated experience with Troll Bridge.
Replies from: Bunthut↑ comment by Bunthut · 2021-05-19T12:40:33.842Z · LW(p) · GW(p)
But now, you seem to be complaining that a method that explicitly avoids Troll Bridge would be too restrictive?
No, I think finding such a no-learning-needed method would be great. It just means your learning-based approach wouldn't be needed.
You seem to be arguing that being susceptible to Troll Bridge should be judged as a necessary/positive trait of a decision theory.
No. I'm saying if our "good" reasoning can't tell us where in Troll Bridge the mistake is, then something that learns to make "good" inferences would have to fall for it.
But there are decision theories which don't have this property, such as regular CDT, or TDT (depending on the logical-causality graph). Are you saying that those are all necessarily wrong, due to this?
A CDT is only worth as much as its method of generating counterfactuals. We generally consider regular CDT (which I interpret as "getting its counterfactuals from something-like-epsilon-exploration") to miss important logical connections. "TDT" doesn't have such a method. There is a (logical) causality graph that makes you do the intuitively right thing on Troll Bridge, but how to find it formally?
A strong candidate from my perspective is the inference from to
Isn't this just a rephrasing of your idea that the agent should act based on C(A|B) instead of B->A? I don't see any occurance of ~(A&B) in the troll bridge argument. Now, it is equivalent to B->~A, so perhaps you think one of the propositions that occur as implications in troll bridge should be parsed this way? My modified troll bridge parses them all as counterfactual implication.
For example, I could have a lot of prior mass on "crossing gives me +10, not crossing gives me 0". Then my +10 hypothesis would only be confirmed by experience. I could reason using counterfactuals
I've said why I don't think "using counterfactuals", absent further specification, is a solution. For the simple "crossing is +10" belief... you're right its succeeds, and insofar as you just wanted to show that its rationally possible to cross, I suppose it does.
This... really didn't fit into my intuitions about learning. Consider that there is also the alternative agent who believes that crossing is -10, and sticks to that. And the reason he sticks to that isn't that hes to afraid and VOI isn't worth it: while its true that he never empirically confirms it, he is right, and the bridge would blow up if he were to cross it. That method works because it ignores the information in the problem description, and has us insert the relevant takeaway without any of the confusing stuff directly into its prior. Are you really willing to say: Yup, thats basically the solution to counterfactuals, just a bit of formalism left to work out?