How To Fermi Model
post by habryka (habryka4), Eli Tyre (elityre) · 2020-09-09T05:13:19.243Z · LW · GW · 9 commentsContents
Introduction: Rationale for Fermi Modeling: Overview: Method Step 0. Prompts Examples Step 0.5. Examples Step 1: Abstract Prompts Examples EAG How can I make more friends? Step 2: Model Step 2.1 Prompts Examples Social Gathering Search Procedure Step 2.2 Examples Step 2.3 Step 2.4 (Optional) Step 2.5: Step 3: Aggregate Closing thoughts Disadvantages: Further reading: None 9 comments
[Note from Eli in 2020: I wrote this document in 2016, in conjunction with two workshops that I helped Oliver Habryka run. If I were to try and write a similar document today, it would likely be substantially different in form and style. For instance, reading this in 2020, I’m not very compelled by some of the argumentation that I used to justify this technique, and I think I could have been clearer about some of the steps.
Nevertheless, I think this is some useful content. I’m not going to take the time to write a new version of this document, so it seems better to share it, as is, instead of sitting on it.]
Oliver Habryka provided the seed material and did most of the development work on this technique. He gets upwards of 90% of the credit, even though I (Eli) wrote this document. Thanks Oli!
Introduction:
Rationale for Fermi Modeling:
Making good decisions depends on having a good understanding of the world: the better one’s understanding the better one’s decisions can be. Model-building procedures allow us to iteratively refine that understanding.
Using any model-building procedure at all is a large step up from using no procedure at all, but some procedures are superior to others. If possible, we would want to use techniques that rely on verified principles and are based on what we know about how the mind works. So, what insights can be gleaned from the academic social and cognitive sciences that is relevant to model-building?
First, Cognitive psychology has shown, many times over, that very simple algorithmic decision rules frequently have just as much predictive power, and even outperform, human expert judgment. Deep, specific models that take into account many details specific to the situation (inside views) are prone to overfitting, and are often inaccurate. Decision rules combat biases like the Halo effect and consequently tend to produce better results.
For instance, a very simple equation to predict the probability that a marriage will last is:
Frequency of lovemaking / Frequency of fights
(Where a higher number represents a more stable marriage. Example taken from Thinking Fast and Slow ch. 21)
This assessment measure is intuitive and uncomplicated, and it predicts length of marriage about as well as any other method, including expert evaluation by experienced couples counselors. Most of the relevant information is encapsulated in just those two variables: more detailed analysis is swamped by statistical variance and tends to make one overconfident. And the algorithm has the additional distinct advantage of being cheap and easy to deploy: simply plug in the variables and see what comes out.
The upshot is simple numeric algorithms are powerful.
Second, is the study of forecasting. One of the most significant takeaways from Philip Tetlock’s Expert Political Judgment project is that “foxes” (who use and integrate multiple methods of evaluation, models, and perspectives) fare better than “hedgehogs” (who use a single overriding model or methodology that they know very deeply).
This poses a practical problem however. There are dozens of known psychological phenomena (anchoring, priming, confirmation bias, framing effects, attentional bias) that make it cognitively difficult to think beyond one’s first idea. Once one has developed a model or a solution, it tends to be “sticky”, coloring and constraining further thinking. Even if you want to generate new models, it’s hard not to anchor on the one you had in front of you a moment ago. As Kahneman colorfully puts it, “What you see is all there is,” or so it seems.
Given this, we want decision processes and planning protocols that are 1) algorithmic, using simple equations or scoring rules with variables that are easy to assess 2) foxy, in that they incorporate many models instead of one, and 3) help mitigate the psychological biases that make this difficult.
Fermi Modeling is an attempt at a model building-procedure that caters to these constraints. It is quantitative, Foxy, and designed to compensate, at least somewhat, for our native biases.
In contrast to other methods of theorizing and model building, Fermi Modeling is less about going deep and more about going broad. Instead of spending a lot of time building one, very detailed, sophisticated, and precise model, the emphasis is on building many models rapidly.
Overview:
Fermi Modeling is a brainstorming and theorizing technique that encourages you to flip between multiple frames and perspectives, primarily by moving up and down levels of abstraction.
In broad strokes, the mental process of Fermi Modeling looks like this:
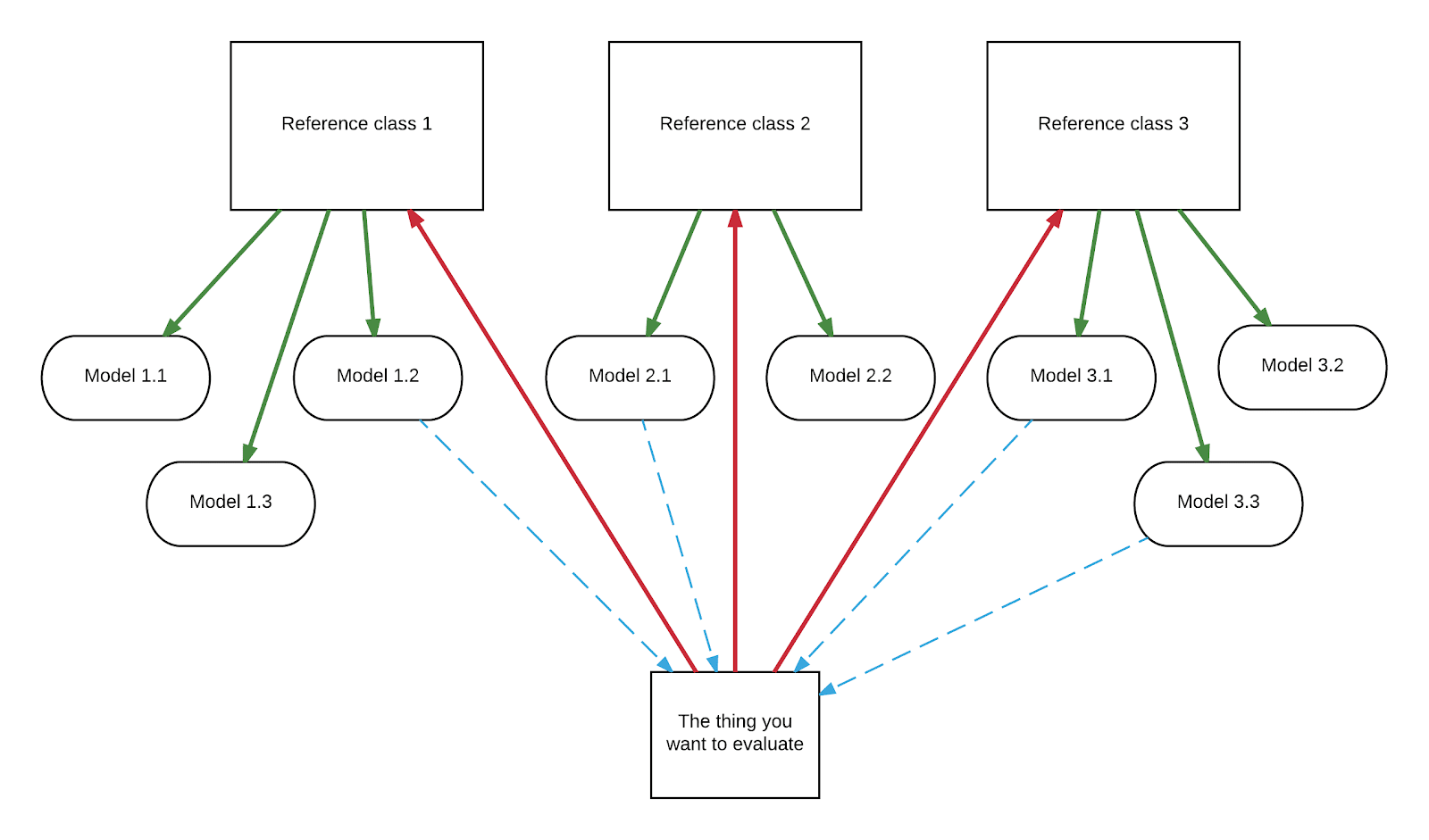
You start, in step 1 (red), by moving up a level of abstraction, by considering reference classes or categories into which your object or problem of interest falls.
Then, in step 2 (green), you move down a level of abstraction to generate models applicable to each reference class (with no regard for the original question.)
Then in step 3 (blue), you apply the models generated in step 2 and 3 to the original question.
The point is to get you to consider questions that you wouldn’t naively ask.
For instance, suppose I’m considering the question, “how do I determine which people I should spend time assisting, teaching, or otherwise, making better?”
This question brings to mind certain reference frames and criteria. I can think of people in this context as independent agents to implement my goals, which brings to mind consideration such as value alignment, power in the world, and discretion. I can think of people as teammates, which indicates other important factors such as personal compatibility with me and the complementary-ness of our skill sets. I can think of people as trade partners, which would lead me to consider what value they can give me.
Furthermore, I can change my focus from the object, “people”, to the verb. I could rephrase the question as “who do I invest in?”, which gives me the reference frame of “investment”. This immediately brings to mind a whole set of models and formulas: compound interest and risk assessment. This yields considerations such as the principal investment, time to pay off, and probability of pay off.
These finance-flavored factors are obviously relevant to the question of “whose growth I should nurture?”, but I would not have considered them by default. They don’t come to mind when just thinking about “people”, only when thinking about “investments”
Fermi Modeling is a process designed to generate ideas that don’t come to mind by default, and to facilitate rapid consideration of many “angles of attack” on a problem, when creating models and evaluation criteria.
Method
A note on time allocation: one of the advantages of this method is that it pays off quickly, but can still generate large value with large time investment.
You can Fermi Model for 15 minutes and get rapid useful results, on a quick question, or you can do it for several hours, or even block out a whole day, to consider one particularly important decision. How much time you spend on each step is flexible and subject to personal preference. Just make sure you have enough time to consider at least three reference frames, and aggregate, at the end.
Step 0.
Ask a “how” or “what” question. In particular, look for questions that have a sense of gradient or variation: what causes a thing to be better, easier, bigger, or more impactful. What is a variable that you are trying to maximize or minimize?
Your question should impinge on your actions somehow. The answer to this question will inform some decision about how to act in the world.
Alternatively, this could be a question of general assessment: determining the overall “quality” or “goodness” of some object of interest, be it an organization, a process, a technology, etc.
Prompts | Examples |
|
|
Step 0.5.
Once you have written the initial question, rephrase the question in multiple ways. Try to ask the same question, or a nearby question, using different terminology. (This can involve small refactorings of the goal.) Doing this can introduce a little “conceptual jitter”, that can sometimes yield fruitful distinctions.
Examples |
|
Step 1: Abstract
Generate reference frames
- Mark or underline all the key terms in each phrasing. To a first approximation, underlining all the nouns and all the verbs works. [If you are doing Fermi modeling as an evaluation procedure, you can skip this part].
- For each of the marked terms, list reference classes for which the term is an example. You want to move up a level of abstraction, considering all the categories into which the term fits. You want to generate between 15 and 50 reference frames (of which you might use 4 to 6).
Prompts | Examples |
| EAG
How can I make more friends?
|
Step 2: Model
Rapid model building on each of the frames:
Take one of the reference frames that you generated in the last step and Fermi model on it.
We recommend, if you are doing this for the first time, that you start with a frame other than the one you think is most useful, interesting, or relevant to your problem. Often, people pick one frame and build one model and feel like they’re done. After all, the “correct” model is right in front of them; why would they bother constructing another, inferior model? Starting with a less-than-your-favorite frame encourages you to build more than one model.
Step 2.1
Identify first order factors. Consider what variables would determine the “quality” or quantity of things in the reference class. This often takes the form of asking “what makes an X good?”. A thing can be more or less X or more or less of a good X.
Note that we are only looking at first-order factors. The models that we are generating are intended to be quick and rough. There will, for most categories, be many, many factors that exert a small influence on the overall outcome. We are only looking for as many factors as will have a sufficient effect as to influence the order of magnitude of the outcome. What factors explain most of the variance?
Prompts | Examples |
| Social Gathering
Search Procedure
|
Step 2.2
Use simple mathematical operations (*, /, +, -, average, min, max, squared) to describe the relationships between first order factors. Write a function that describes how changes in the inputs change the output.
If you don’t know where to start, simply multiply your first order factors together, and then check to see if the resulting model makes sense as a first approximation. If it doesn’t, tinker with it a little by adjusting or adding terms.
Examples |
Social Gathering = Search Procedure = |
You can quickly check your models by looking for 0s. What happens when any given factor is set to 0 or to arbitrarily large? Does the result make sense? This can inform your expressions.
If you aren't familiar with the notion, try drawing a graph, that holds all but one of the inputs constant. You can use the graph to reverse engineer the mathematical notion if you want.
You can do more work on these models, primarily by decomposing your first order factors into more basic components. But this is usually misguided. These models are rough, based only on simple intuitions, making them more detailed at this point makes them more precise than their general accuracy warrants. In most cases, it only makes sense to add detail after we have had opportunity to test our models empirically.
Some of the models you generate may be cached, standard models from one domain or another. For instance, there are known, simple equations for compound interest. This is perfectly fine, and in fact, is quite good. Those models come pre-vetted and verified.
The process of generating a single model should not take more than 6 minutes in most cases, as a beginner.
Step 2.3
Build as many such models in a given reference class as you’d like. Two or three is usually sufficient.
Some people find this step somewhat difficult. There are a couple of “tricks” that you can apply to reframe and generate more models.
- Do a resolve cycle: set a timer for five minutes (or two minutes) and come up with as many models as you can before it rings. Get into the mindset of “I have to do it.”
- Reverse the question: If you’ve been considering what makes a thing good, then ask what would make it bad. (“If you can’t optimize, pessimize.”)
- Consider how scientists or academics from various disciplines would approach this problem? How does a historian look at this? A mechanical engineer? A biologist? An economist?
- Consider an alternative way to parse the world. A good way to do this is to forbid the use of the factors you used in your first model. How else could you make sense of this situation?
- Ask the person next to you. It’s often surprising how different the models that another person will generate are.
Some notes on models:
|
Step 2.4 (Optional)
Generate examples to spur models: think of hypothetical, or better yet, actual examples of the reference class. Consider how they fare in terms of each of your main factors. What makes each example good? How could you tweak them to make them better or worse?
(optional) Test: generate counterexamples
Step 2.5:
Repeat step 2. Build more models on each reference frame in turn.
Really do this! I’ve sometimes seen people (and am personally prone to) become quite anchored on or attached to their first model they / I build, since it seems obviously correct. Most of the value of this method comes building many models.
Step 3: Aggregate
Once you’ve generated some models, you know want to go back and evaluate your original question. Some of the models you built won’t be relevant to the original question, but you should be sure to consider each one before dismissing it. Remember, the whole point is to generate considerations that wouldn’t have occurred to you by default.
There are lots of ways to do this.
Looking at each of your models / functions, compare to the situation you’re considering (your workshop, for instance). Estimate values for each of the terms in each model. Do the majority of the models recommend one type of action?
You can use the models you’ve generated abstractly in the more concrete context. What happens when you adjust the factors on your actual plan?
Try and come up with a plan that scores perfectly on each model. See how much overlap there is between those plans. Can you goal-factor and get most of the benefit?
The quantitative nature of your models means that you can also take your subjective analysis out of it. Set up a scoring system, that takes all the inputs for a plan and returns an aggregated score.
Closing thoughts
Advantages:
Since, for most of the process, you’re not focusing on the original question at all, but rather building models only in the context of the reference frame, you avoid, somewhat, the “stickiness” of your initial models. You’re less likely to get stuck thinking that the way you modeled the problem is the “correct” model (and then being resistant to seeing other perspectives, due to a whole slew of biases), since you shouldn’t be thinking about the original problem at all.
As mentioned above, this method scales easily with more time invested. It’s also parallelizable. it’s easy to have multiple people on a team all Fermi modeling on the same topic, and each of them is likely to come up with novel, useful insights. I’d recommend that each person do step 1 independently, have everyone share frames, then have each person do 2 and 3 on a subset of the frames.
Disadvantages:
This process is designed to produce rough heuristics rapidly. Sometimes a deep understanding of the specific situation is necessary.
Further reading:
Clinical vs. Statistical Prediction: A Theoretical Analysis and a Review of the Evidence by Paul Meehl: a slim but dense volume, this a classic of the the field that first made the case for numeric algorithms over expert judgment.
Chapter 21 of Thinking Fast and Slow by Daniel Kahneman is a popular overview of how simple algorithmic decision rules frequently outperform expert judgment.
Expert Political Judgment: How Good is it? How can we Know? by Philip Tetlock is a compendium on the research project that gave rise to the Fox vs. Hedgehog distinction.
Biases that are relevant
Abstraction vs. Analogy by Robin Hanson is a good, brief example of considering an object in terms of several various reference frames.
Cluster Thinking vs Sequence Thinking by Holden Karnofsky is an essay on making decisions on the basis of weighing and integrating many models.
How to Measure Anything: How to Find the Value of Intangibles in Business
by Douglas W. Hubbard is an excellent primer on applying quantitative measurements to qualitative domains.
9 comments
Comments sorted by top scores.
comment by johnswentworth · 2020-09-09T17:36:34.216Z · LW(p) · GW(p)
Some scattered thoughts...
Gears
First, how does this sort of approach relate to gears-level modelling? I think the process of brainstorming reference classes is usually a process of noticing particular gears - i.e. each "reference class" is typically a category of situations which have a subset of gears in common with the problem at hand. The models within a reference class spell out the particular gears relevant to that class of problems, and then we can think about how to transport those gears back to the original problem.
With that in mind, I think step 3 is missing some fairly crucial pieces. What you really want is not to treat each of the different models generated as independent black boxes and then poll them all, but rather to figure out which of the gears within the individual models can be carried back over to the original problem, and how all those gears ultimately fit together. In the end, you do want one unified model (though in practice that's more of an ideal to strive toward than a goal which will be achieved; if you don't have enough information to distinguish the correct model from all the possibilities then obviously you shouldn't pick one just for the sake of picking one). Some example ways the gears of different models can fit together:
- Some of the different models will contain common subcomponents.
- Some models will have unspecified parameters (e.g. the discount factor in financial formulas), and in the context of the original problem, the values of those parameters will be determined mainly by the components of other models.
- Some models will contain components whose influence is mediated by the variables of other models.
Formulas
Second, the mathematical formulas. Obviously these are "wrong", in the sense that e.g. quality_of_connections*(# people)/(# connections) is not really expressing a relationship between natural quantities in the world; at best it's a rather artificial definition of "quality of connections" which may or may not be a good proxy for what we intuitively mean by that concept. That said, it seems like these are trying to express something important, even if the full mathematical implications are not really what matters.
I think what they're trying to capture is mostly necessity and sufficiency. This line from the OP is particularly suggestive:
You can quickly check your models by looking for 0s. What happens when any given factor is set to 0 or to arbitrarily large? Does the result make sense?
For these sorts of qualitative formulas, limiting behavior (e.g. "what happens when any given factor is set to 0 or to arbitrarily large) is usually the only content of the formula in which we put any faith. And for simple formulas like (var1*var2) or (var1 + var2), that limiting behavior mostly reduces to necessity and sufficiency - e.g. the expression quality_of_connections*(# people)/(# connections) says that both nonzero quality and nonzero person-count are necessary conditions in order to get any benefit at all.
(In some cases big-O behavior implied by these formulas may also be substantive and would capture more than just necessity and sufficiency, although I expect that people who haven't explicitly practiced thinking with big-O behavior usually won't do so instinctively.)
Examples
Third, use of examples. I'd recommend pushing example-generation earlier in the process. Ideally, brainstorming of examples for a reference class comes before brainstorming of models. I recommend a minimum of three examples, as qualitatively different from each other as possible, in order to really hone in on the exact concept/phenomenon which you're trying to capture. This will make it much easier to see exactly what the models need to explain, will help avoid sticking on one imperfect initial model, and will make everything a lot easier to explain to both yourself and others.
comment by ryan_b · 2020-09-10T17:17:04.069Z · LW(p) · GW(p)
Strong upvote. This is a great example taking several things we have long discussed and transforming them into being actionable. This also strikes close to the things I have thought were the most under-valued in LessWrong conversation.
I attempted a poor man's ur-version of this years ago when trying to project how long it would take to deliver a product to market, when I lacked information about the primary reference class of similar products (they don't hand project management details over to students; who knew?). All I really did at that time was identify three different reference classes and then averaged together one or two of each, and called that my timeline estimate.
comment by Raemon · 2022-01-14T06:41:20.061Z · LW(p) · GW(p)
I... haven't actually used this technique verbatim through to completion. I've made a few attempts to practice and learn it on my own, but usually struggled a bit to reach conclusions that felt right.
I have some sense that this skill is important, and it'd be worthwhile for me to go to a workshop similar to the one where Habryka and Eli first put this together. This feels like it should be an important post, and I'm not sure if my struggle to realize it's value personally is more due to "it's not as valuable as I thought" or "you actually have to do a fair bit of homework for it to start paying off."
When I've tried applying this post, it's usually been in a situation where I have something that feels tricky/fuzzy to evaluate. I've seen habryka use fermi modeling in domains like "how many people will get covid?", but usually when I find myself reaching for this post it's when I have a question more like "how many dollars should I/donors be willing to pay for the LessWrong Review, as an institution, vs other projects the LessWrong team could do?"
I've never sat and practiced generating 50 fermi calculations in a domain where the answer was easy to verify.
Eli mentions "he'd write this post pretty differently today" in the OP. I'm not sure the problem here is lack-of-rewrite, vs "building a webapp that presents you with a bunch of fermi-modeling problems you can quickly train against."
The most conceptually interesting part here is the "generate multiple reference frames, and multiple models per reference frame, and start with something not the best model so you don't get immediately attached." That seems like something that should clearly be cognitively useful, but I haven't made it work for me.
comment by Elizabeth (pktechgirl) · 2022-01-14T06:32:53.271Z · LW(p) · GW(p)
I think this is an important skill and I'm glad it's written up at all. I would love to see the newer version Eli describes even more though.
comment by habryka (habryka4) · 2020-09-16T04:55:47.492Z · LW(p) · GW(p)
A recently released paper that seems kind of relevant: https://www.researchgate.net/publication/337275911_Taking_a_disagreeing_perspective_improves_the_accuracy_of_people%27s_quantitative_estimates
Replies from: ryan_bcomment by Raemon · 2020-09-09T19:38:18.280Z · LW(p) · GW(p)
Then, in step 2 (blue), you move down a level of abstraction to generate models applicable to each reference class (with no regard for the original question.)
Then in step 3 (green), you apply the models generated in step 2 and 3 to the original question.
I think the colors are backwards here? (But some combination of flux and california being on fire might be fucking with my perception and I am less confident than usual)
Replies from: habryka4↑ comment by habryka (habryka4) · 2020-09-09T20:38:19.314Z · LW(p) · GW(p)
Yep, seems right. Will fix.