Posts
Comments
(a)
Look, we already have superhuman intelligences. We call them corporations and while they put out a lot of good stuff, we're not wild about the effects they have on the world. We tell corporations 'hey do what human shareholders want' and the monkey's paw curls and this is what we get.
Anyway yeah that but a thousand times faster, that's what I'm nervous about.
(b)
Look, we already have superhuman intelligences. We call them governments and while they put out a lot of good stuff, we're not wild about the effects they have on the world. We tell governments 'hey do what human voters want' and the monkey's paw curls and this is what we get.
Anyway yeah that but a thousand times faster, that's what I'm nervous about.
When I was in the UK I bought one of these floodlights. You have to attach your own plug but that's easy enough. More frustrating is there's a noticeable flicker, and the CRI's pretty poor.
On the upside it's £70, compact, simple, and 40k lumens.
Yes! Though that engineer might not be interested in us.
In-person is required. We'll add something to the job descriptions in the new year, thanks for the heads up!
It's not impossible, but it appears unlikely for the foreseeable future. We do sponsor visas, but if that doesn't suit then I'd take a look at Cohere.ai, as they're one org I know of with a safety team who are fully-onboard with remote.
You're presenting it as a litmus test for engineers to apply to themselves, and that's fine as far as it goes
I can reassure you that it is in fact a litmus test for engineers to apply to themselves, and that's as far as it goes.
While part of me is keen to discuss our interview design further, I'm afraid you've done a great job of laying out some of the reasons not to!
I stuck this on Twitter already, but normalised these shake out to a consistent-ish set of curves
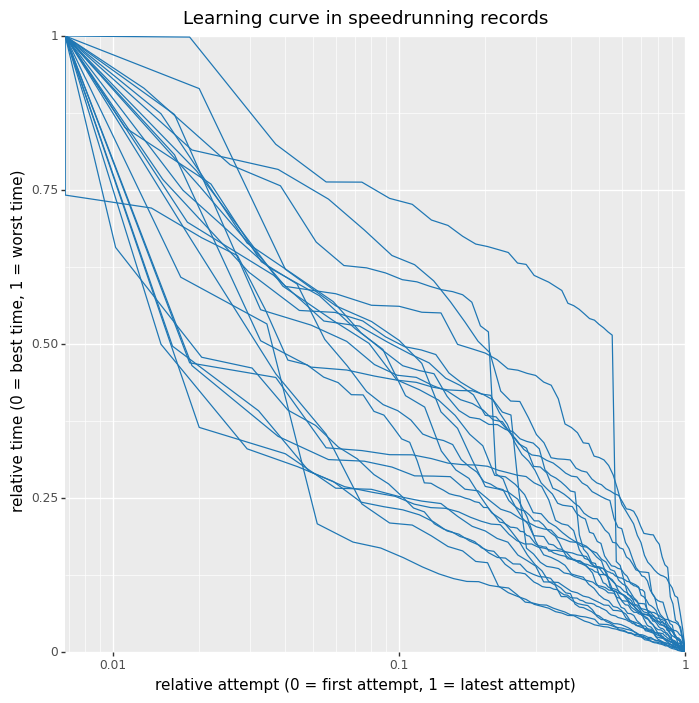
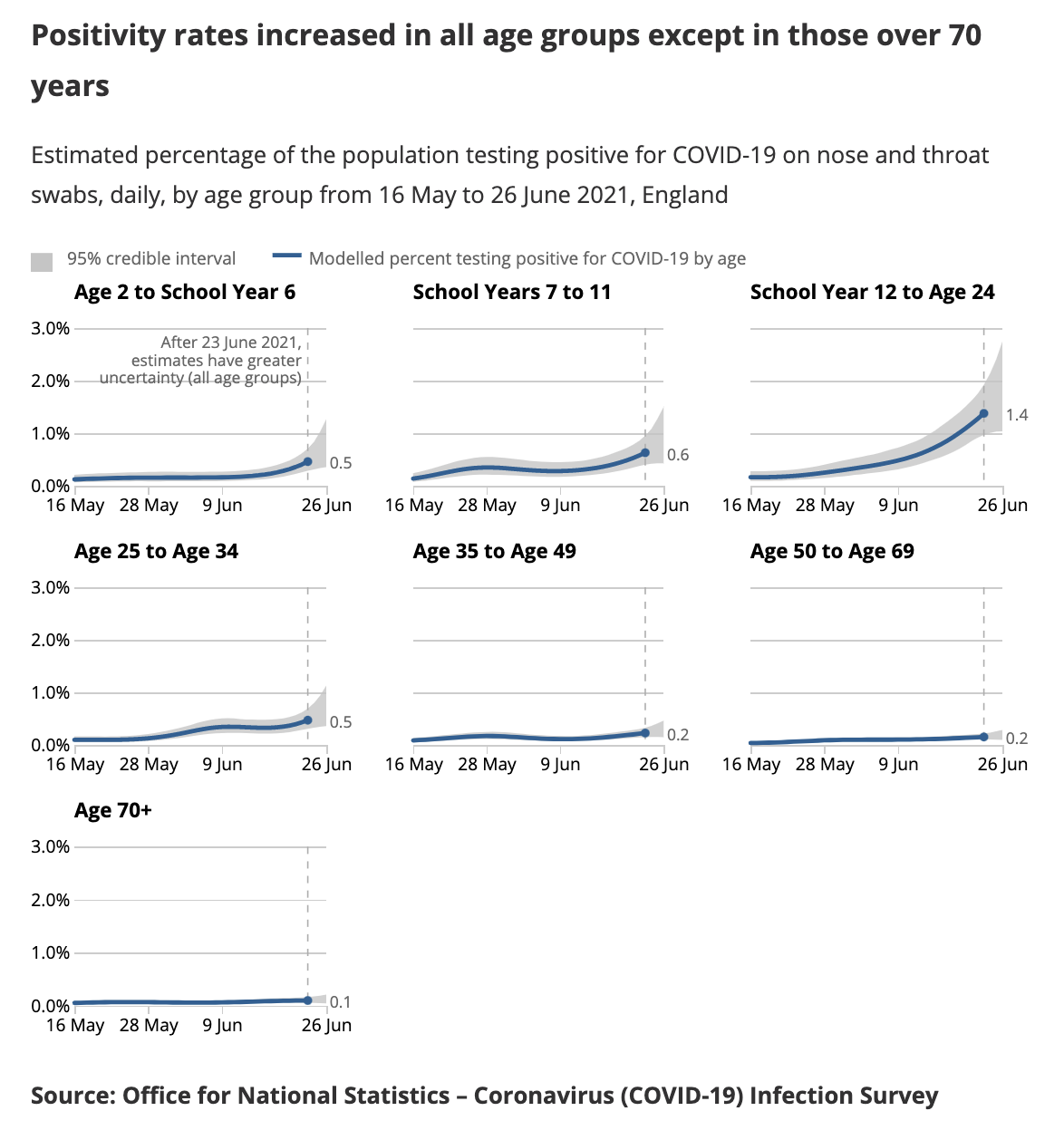
I've been surprised by this too, and my best explanation so far is schools. Evidence in favour is that Scottish school holidays start end-of-June, while English school holidays start middle-of-July, and indeed there looks to be a two-week difference in the peaks for the two nations.
A good test for this will be this week's ONS report. This doesn't have the English turn-around in it yet, but if it is schools then there should be an extremely sharp drop in the school-age rates.
All that said, it's only my best hypothesis. A strong piece of evidence against it is that we haven't seen the same effect in the US, where school holidays started a while ago.
One piece of evidence against this: almost all the uptick in the UK is in folks under 40. Under 40s have a much lower vaccination rate due to the age-dependent rollout, but because of the blood clot scare under 40s have preferentially gotten Pfizer. Over 40s meanwhile have a very high vaccination rate but it's mostly AstraZeneca. Their case rate is flat.
Source
Nine months later I consider my post pretty 'shrill', for want of a better adjective. I regret not making more concrete predictions at the time, because yeah, reality has substantially undershot my fears. I think there's still a substantial chance of something 10x large being revealed within 18 months (which I think is the upper bound on 'timeline measured in months'), but it looks very unlikely that there'll be a 100x increase in that time frame.
To pick one factor I got wrong in writing the above, it was thinking of my massive update in response to GPT-3 as somewhere near to the median, rather than a substantial outlier. As another example of this, I am the only person I know of who, after GPT-3, dropped everything they were doing to re-orient their career towards AI safety. And that's within circles of people who you'd think would be primed to respond similarly!
I still think AI projects could be run at vastly larger budgets, so in that sense I still believe in there being an orders-of-magnitude overhang. Just convincing the people with those budgets to fund these projects is apparently much harder than I thought.
I am not unhappy about this.
I don't think the problem you're running into is a problem with making bets, it's a problem with leverage.
Heck, you've already figured out how to place a bet that'll pay off in future, but pay you money now: a loan. Combined with either the implicit bet on the end of the world freeing you from repayment, or an explicit one with a more-AI-skeptical colleague, this gets you your way of betting on AI risk that pays now.
Where it falls short is that most loanmaking organisations will at most offer you slightly more than the collateral you can put up. Because, well, to most loanmaking organisations you're just a big watery bag of counterparty risk, and if they loan you substantially more than your net worth they're very unlikely to get it back - even if you lose your bet!
But this is a problem people have run into before! Every day there are organisations who want to get lots more cash than they can put up in collateral in order to make risky investments that might not pay off. Those organisations sell shares. Shares entitle the buyer to a fraction of the uncertain future revenues, and it's that upside risk - the potential for the funder to make a lot more money than was put in - that separates them from loans.
Now as an individual you're cut off from stock markets. The closest approximation available is venture capital. That gives you almost everything you want, except that it requires you come up with a way to monetise your beliefs.
The other path is to pay your funders in expected better-worlds, and that takes you to the door of charitable funding. Here I'm thinking both of places like the LTFF and SAF, and more generally of HNW funders themselves. The former is pretty accessible, but limited in its capacity. The latter is less accessible, but with much greater capacity. In both cases they expect more than just a bet thesis; they require a plan to actually pay them back some better-worlds!
It's worth noting that if you actually have a plan - even a vague one! - for reducing the risk from short AI timelines, then you shouldn't have much trouble getting some expenses out of LTFF/SAF/etc to explore it. They're pretty generous. If you can't convince them of your plan's value - then in all honesty your plan likely needs more work. If you can convince them, it's a solid path to substantially more direct funding.
But those, I think, are the only possible solutions to your issue. They all have some sort of barrier to entry, but that's necessary because from the outside you're indistinguishable from any other gambler!
You may be interested in alpha-rank. It's an Elo-esque system for highly 'nontransitive' games - ie, games where there're lots of rock-paper-scissors-esque cycles.
At a high level, what it does is set up a graph like the one you've drawn, then places a token on a random node and repeatedly follows the 'defeated-by' edges. The amount of time spent on a node gives the strength of the strategy.
You might also be interested in rectified policy space response oracles, which is one approach to finding new, better strategies in nontransitive games.
This is superb, and I think it'll have a substantial impact on debate going work. Great work!
- Short-term willingness to spend is something I've been thinking a lot about recently. My beliefs about expansion rates are strangely bimodal:
- If AI services are easy to turn into monopolies - if they have strong moats - then the growth rate should be extraordinary as legacy labour is displaced and the revenues are re-invested into improving the AI. In this case, blowing through $1bn/run seems plausible.
- If AI services are easy to commodify - weak or no moats - then the growth rate should stall pretty badly. We'll end up with many, many small AI systems with lots of replicated effort, rather than one big one. In this case, investment growth could stall out in the very near future. The first $100m run that fails to turn a profit could be the end of the road.
- I used to be heavily biased towards the former scenario, but recent evidence from the nascent AI industry has started to sway me.
- One outside view is that AI services are just one more mundane technology, and we should see a growth curve much like the tech industry's so far.
- A slightly-more-inside-view is that they're just one more mundane cloud technology, and we should see a growth curve that looks like AWS's.
- A key piece of evidence will be how much profit OpenAI turns on GPT. If Google and Facebook come out with substitute products in short order and language modelling gets commodified down to zero profits, that'll sway me to the latter scenario. I'm not sure how to interpret the surprisingly high price of the OpenAI API in this context.
- Another thing which has been bugging me - but I haven't put much thought into yet - is how to handle the inevitable transition from 'training models from scratch' to 'training as an ongoing effort'. I'm not sure how this changes the investment dynamics.
You can get a complementary analysis by comparing the US to its past self. Incarceration rate, homicide rate. Between 1975 and 2000, the incarceration rate grew five-fold while the homicide rate fell by half.
{kind=link}
{kind=link}
Bit of a tangent, but while we might plausibly run out of cheap oil in the near future, the supply of expensive, unconventional oil is vast. By vast I mean 'several trillion barrels of known reserves', against an annual consumption of 30bn.
Question is just how much of those reserves are accessible at each price point. This is really hard to answer well, so instead here's an anecdote that'll stick in your head: recent prices ($50-$100/bbl) are sufficient that the US is now the largest producer of oil in the world, and a net exporter to boot.
For what it's worth, this whole unconventional oil thing has appeared from nowhere the last ten years, and it's been a shock to a lot of people.
Thanks for the feedback! I've cleaned up the constraints section a bit, though it's still less coherent than the first section.
Out of curiosity, what was it that convinced you this isn't an infohazard-like risk?
While you're here and chatting about D.5 (assume you meant 5), another tiny thing that confuses me - Figure 21. Am I right in reading the bottom two lines as 'seeing 255 tokens and predicting the 256th is exactly as difficult as seeing 1023 tokens and predicting the 1024th'?
e: Another look and I realise Fig 20 shows things much more clearly - never mind, things continue to get easier with token index.
Though it's not mentioned in the paper, I feel like this could be because the scaling analysis was done on 1024-token sequences. Maybe longer sequences can go further.
It's indeed strange no-one else has picked up on this, which makes me feel I'm misunderstanding something. The breakdown suggested in the scaling law does imply that this specific architecture doesn't have much further to go. Whether the limitation is in something as fundamental as 'the information content of language itself', or if it's a more-easily bypassed 'the information content of 1024-token strings', is unclear.
My instinct is for the latter, though again by the way no-one else has mentioned it - even the paper authors - I get the uncomfortable feeling I'm misunderstanding something. That said, being able to write that quote a few days ago and since have no-one pull me up on it has increased my confidence that it's a viable interpretation.
'Why the hell has our competitor got this transformative capability that we don't?' is not a hard thought to have, especially among tech executives. I would be very surprised if there wasn't a running battle over long-term perspectives on AI in the C-suite of both Google Brain and DeepMind.
If you do want to think along these lines though, the bigger question for me is why OpenAI released the API now, and gave concrete warning of the transformative capabilities they intend to deploy in six? twelve? months' time. 'Why the hell has our competitor got this transformative capability that we don't?' is not a hard thought now, but it that's largely because the API was a piece of compelling evidence thrust in all of our faces.
Maybe they didn't expect it to latch into the dev-community consciousness like it has, or for it to be quite as compelling a piece of evidence as it's turned out to be. Maybe it just seemed like a cool thing to do and in-line with their culture. Maybe it's an investor demo for how things will be monetised in future, which will enable the $10bn punt they need to keep abreast of Google.
hey man wanna watch this language model drive my car
Thinking about this a bit more, do you have any insight on Tesla? I can believe that it's outside DM and GB's culture to run with the scaling hypothesis, but watching Karpathy's presentations (which I think is the only public information on their AI program?) I get the sense they're well beyond $10m/run by now. Considering that self-driving is still not there - and once upon a time I'd have expected driving to be easier than Harry Potter parodies - it suggests that language is special in some way. Information density? Rich, diff'able reward signal?
I'd say it's at least 30% likely that's the case! But if you believe that, you'd be pants-on-head loony not to drop a billion on the 'residual' 70% chance that you'll be first to market on a world-changing trillion-dollar technology. VCs would sacrifice their firstborn for that kind of deal.
Entirely seriously: I can never decide whether the drunkard's search is a parable about the wisdom in looking under the streetlight, or the wisdom of hunting around in the dark.
There's a LW thread with a collection of examples, and there's the beta website itself.
Feels worth pasting in this other comment of yours from last week, which dovetails well with this:
DL so far has been easy to predict - if you bought into a specific theory of connectionism & scaling espoused by Schmidhuber, Moravec, Sutskever, and a few others, as I point out in https://www.gwern.net/newsletter/2019/13#what-progress & https://www.gwern.net/newsletter/2020/05#gpt-3 . Even the dates are more or less correct! The really surprising thing is that that particular extreme fringe lunatic theory turned out to be correct. So the question is, was everyone else wrong for the right reasons (similar to the Greeks dismissing heliocentrism for excellent reasons yet still being wrong), or wrong for the wrong reasons, and why, and how can we prevent that from happening again and spending the next decade being surprised in potentially very bad ways?
Personally, these two comments have kicked me into thinking about theories of AI in the same context as also-ran theories of physics like vortex atoms or the Great Debate. It really is striking how long one person with a major prior success to their name can push for a theory when the evidence is being stacked against it.
A bit closer to home than DM and GB, it also feels like a lot of AI safety people have missed the mark. It's hard for me to criticise too loudly because, well, 'AI anxiety' doesn't show up in my diary until June 3rd (and that's with a link to your May newsletter). But a lot of AI safety work increasingly looks like it'd help make a hypothetical kind of AI safe, rather than helping with the prosaic ones we're actually building.
I'm committing something like the peso problem here in that lots of safety work was - is - influenced by worries about the worst-case world, where something self-improving bootstraps itself out of something entirely innocuous. In that sense we're kind of fortunate that we've ended up with a bloody language model fire-alarm of all things, but I can't claim that helps me sleep at night.
GPT-3 does indeed only depend on the past few thousand words. AI Dungeon, however, can depend on a whole lot more.
Be careful using AI Dungeon's behaviour to infer GPT-3's behaviour. I am fairly confident that Latitude wrap your Dungeon input before submitting it to GPT-3; if you put in the prompt all at once, that'll make for different model input than putting it in one line at a time.
I am also unsure as to whether the undo/redo system sends the same input to the model each time. Might be Latitude adds something to encourage an output different to the ones you've already seen.
Alternately phrased: much of the observed path dependence in this instance might be in Dragon, not GPT-3.
I think that going forward there'll be a spectrum of interfaces to natural language models. At one end you'll have fine-tuning, and at the other you'll have prompts. The advantage of fine-tuning is that you can actually apply an optimizer to the task! The advantage of prompts is anyone can use them.
In the middle of the spectrum, two things I expect are domain-specific tunings and intermediary models. By 'intermediary models' I mean NLP models fine-tuned to take a human prompt over a specific area and return a more useful prompt for another model, or a set of activations or biases that prime the other model for further prompting.
The 'specific area' could be as general as 'less flights of fancy please'.