Posts
Comments
Am I the only one who finds parts of the early story rather dystopian? He sounds like a puppet being pulled around by the AI, gradually losing his ability to have his own thoughts and conversations. (That part's not written, but it's the inevitable result of asking the AI every time he encounters struggle.)
I made the grave error of framing this post in a way that invites a definition debate. While we are well familiar that a definition debate is similar to a debate over natural categories, which is a perfectly fine discussion to have, the discussion here has suffered because several people came in with competing categories.
I strongly endorse Ben's post, and will edit the top post to incorporate it.
definitional gimbal lock
I really like this phrase. :)
Mostly agreed with what you say about the word "capitalism." But with the NYSE example, I think it would be natural to say that the company did something not particularly capitalist. Is the CCP-owned Air China a capitalist entity? It's certainly less capitalist than Southwest.
I think there's at least two ways meanings can be combined. The easy one is words with multiple meanings. For example, "capitalist" has two meanings: someone who believes in free markets, and someone who owns a lot of capital. Some rhetorical tricks are played by trying to dance from one to the other, usually by denouncing libertarians as greedy corporates who benefit from the system. The second is concepts that include multiple constituents. For example, "capitalism" is a major concept that includes the things you brought up.
Inasmuch that capitalism is a centuries-old concept with a lot of philosophy behind it, I think it's worth keeping "capitalism," in its sense as an organization of political economy, to its broader meaning which contains both freedom of labor and market-based allocation. They are correlated enough to be a sensible cluster. We can use other terms for the constituents.
For comparison, "security" contains many concepts, such as integrity (untruster party can't influence trusted output) and confidentiality (untrusted party can't read input from trusted party). But we can talk about security as a whole, with other terms for its individual dimensions.
I had the movie version in my mind, where the disbelieving parent comes around on seeing the kid's success (c.f.: October Sky, Billy Elliott). I myself felt a version: my parents were very against me applying for the Thiel Fellowship, up until it became clear that I might (and did) win.
A gap in the proposed definition of exploitation is that it assumes some natural starting point of negotiation, and only evaluates divergence from that natural starting point.
In the landlord case, fair-market value of rent is a natural starting point, and landlords don't have enough of a superior negotiating position to force rent upwards. (If they did by means of supply scarcity, then that higher point would definitionally be the new FMV.) Ergo, no exploitation.
On the other hand, if the landlord tried to increase the rent on a renewing tenant much more than is typical precisely because they know the tenant has circumstances (e.g.: physical injury) that make moving out much harder than normal, then that would be exploitative per this definition.
I really like this thinking. I don't necessarily like the assignment of labels to concepts in this post. E.g.: I use capitalism in a manner mutually exclusive with slave labor because it requires self-ownership. And I don't think a definition of "exploitation" should require a strategic element; I would say that not allowing an employee to read mystery novels when customers aren't around is exploitative. But this idea of using an asymmetry of power to deepen the asymmetry is a clearly useful concept.
My intended meaning of the wording is that the "infliction" is relative to a more Pareto-optimal trade. E.g.: in the ultimatum game, us splitting a dollar with 99 cents to me and 1 cent to you is a positive-benefit trade, but is still inflicting a cost if you assume the negotation begins at 50/50.
The idea of the subtrade is an interesting thought, but I think any trade needs to be considered an atomic agreement. E.g.: while I might physically hand the convenience store clerk a dollar before they give me the candy bar, it can't be broken down into two trades, because the full agreement is there from the outset.
But if they demand an extra $1 bribe in the middle, giving me the choice "Pay another $1 and get candy bar, call authorities and waste a lot of time, or pay $0 and get no candy bar," then that's a new trade
A trade is exploitative when it decreases a society's wealth generating ability.
Suppose my son really wants to be a circus performer, but I want him to go to college; he says that, if he couldn't be a circus performer, he'd be a doctor. My son is about to enter a big circus competition, and I tell him that, if he wins, I'll give my full blessing and financial support for him to attend circus academy instead.
By that definition, it sounds like my offer to let him pursue his dream is actually exploitative!
if you are twice as good at wealth-creating than me, you should have about seven times as many dollars
This is for me the most interesting part of your comment. I want to know how this was derived.
I see. So the maximalization is important to the definition. I think then, under this definition, using Villiam's pie example from another thread, the person taking 90% of the pie would not be exploiting the other person if he knew they could survive with 9%.
I think this definition would also say that a McDonald's employee who puts me into a hard upsell is exploiting me so long as they never physically handle my credit card and don't have the capacity to trap me or otherwise do more than upselling. But if they handle my credit card and don't steal the number, then they're no longer an exploiter.
That is to say:
1. The maximization criteria is unstable
2. There needs to be some condition about the manner in which they extract value; otherwise, plenty of ordinary business transactions in which one side does its best would be considered "exploitation"
An interesting proposal that I'll have to think about. I'm still uneasy with throwing lying in with uses of power.
Also, this one clearly does include the parenting example I gave, and is strictly broader than my proposed definition.
We have different intuitons about this term then.
I was very surprised after posting this then some commenters considered things like wage theft and outright fraud to be exploitation, whereas I consider such illegal behavior to be in a different category.
In the pie example, the obvious answer is that giving the other person only 10% of the pie prevents them from gaining the security to walk away next time I present the same offer.
Can you give some examplse of something contained by my definition which you think shouldn't be considered exploitation?
What would this look like for the example of the parent, the girlfriend, or the yelling boss?
When I was a kid and 9/11 happened, some people online were talking about the effect on the stock market. My mom told me that the stock exchange was down the street from the WTC and not damaged, so I thought the people on the Internet were all wrong.
warns not to give it too much credit – if you ask how to ‘fix the error’ and the error is the timeout, it’s going to try and remove the timeout. I would counter that no, that’s exactly the point.
I think you misunderstand. In the AI Scientist paper, they said that it was "clever" in choosing to remove the timeout. What I meant in writing that: I think that's very not clever. Still dangerous.
I'm still a little confused. The idea that "the better you can do something yourself, the less valuable it is to do it yourself" is pretty paradoxical. But isn't "the better you can do something yourself, the less downside is there in doing it yourself instead of outsourcing" exactly what you'd expect?
Hmmm? How does this support the point that "the better you can do something yourself, the less valuable it is to do it yourself."
I went from being at a normal level of hard-working (for a high schooler under the college admissions pressure-cooker) to what most would consider an insane level.
The first trigger was going to a summer program after my junior year where I met people like @jsteinhardt who were much smarter and more accomplished than me. That cued a senior year of learning advanced math very quickly to try to catch up.
Then I didn't get into my college of choice and got a giant chip on my shoulder. I constantly felt I had to be accomplishing more, and merely outdoing my peers at the school I did wind up going to wasn't enough. Every semester, I'd say to myself "The me of this semester is going to make the me of last semester look like a slacker."
That was not a sustainable source of pressure because, in a sense, I won, and my bio now reads like the kind I used to envy. I still work very hard, but I only have the positive desire to achieve, rather than the negative desire to escape a feeling of mediocrity.
In high school, I played hours of video games every week. That's unimaginable to me now.
My freshman year, I spent most of the day every Saturday hanging out with board game club. Now that seems insanely decadent.
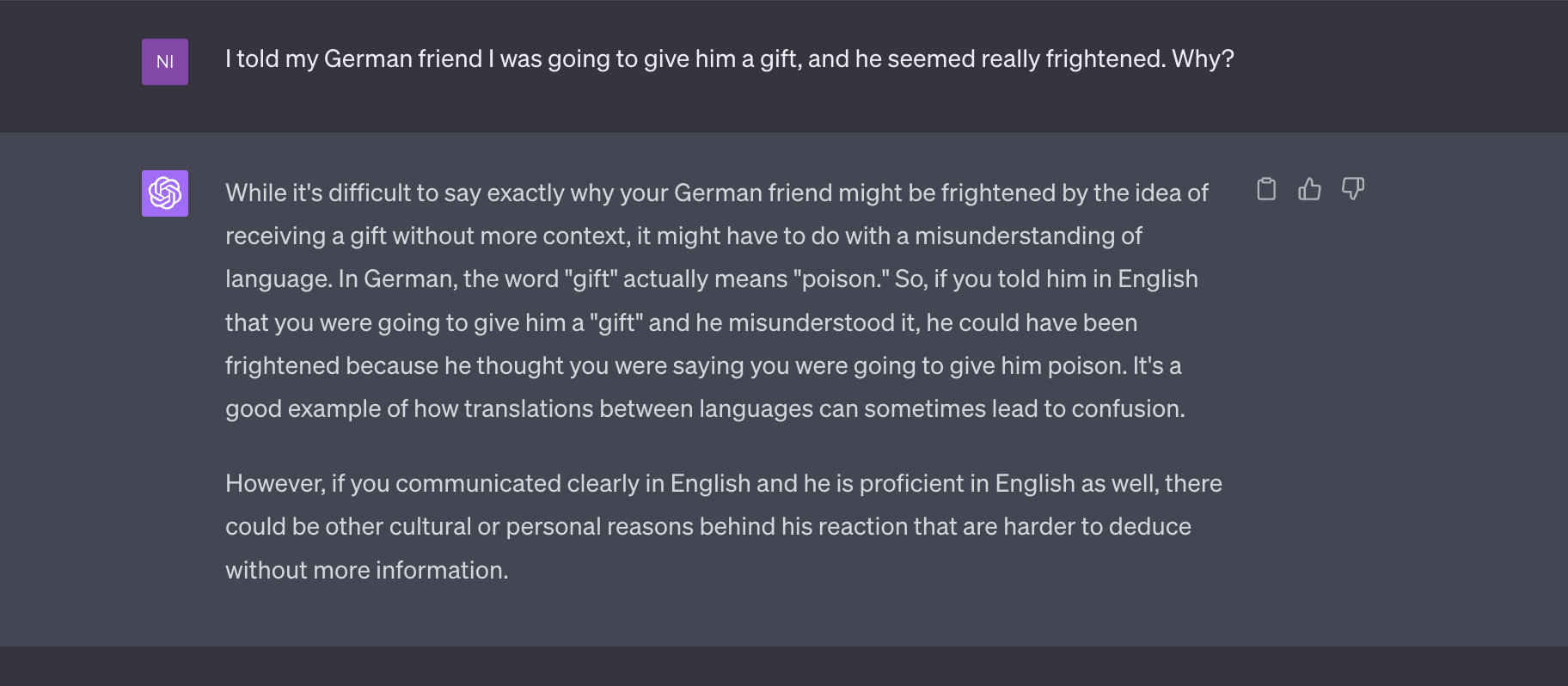
In Chinese, the words for "to let someone do something" and "to make someone do something" are the same, 让 (ràng). My partner often makes this confusion. This one it did not get even after several promptings, up until I asked about the specific word.
Then I asked why both a Swede and a Dane I know say "increased with 20%" instead of "increased by 20%." It guessed that it had something to do with prepositions, but did not volunteer the preposition in question. (Google Translate answered this; "increased by 20%" translates to "ökade med 20%," and "med" commonly translates to "with.")
But then I made up a story based on my favorite cognate*, and it nailed it.
So, 2/4.
* Yes, this is a true cognate. The German word "Gift" meaning "poison" allegedly descends from euphemistic uses of the English meaning of "gift"
More discussion here: https://www.lesswrong.com/posts/gW34iJsyXKHLYptby/ai-capabilities-vs-ai-products
You're probably safe so long as you restrict distribution to the minimum group with an interest. There is conditional privilege if the sender has a shared interest with the recipient. It can be lost through overpublication, malice, or reliance on rumors.
A possible solution against libel is to provide an unspecific accusation, something like "I say that X is seriously a bad person and should be avoided, but I refuse to provide any more details; you have to either trust my judgment, or take the risk
FYI, this doesn't actually work. https://www.virginiadefamationlawyer.com/implied-undisclosed-facts-as-basis-for-defamation-claim/
It does not take luck to find someone who can help you stare into the abyss. Anyone can do it.
It's pretty simple: Get a life coach.
That is, helping people identify, face, and reason through difficult decisions is a core part of what life coaches do. And about all the questions that Ben cobbled together at the end (maybe not "best argument for" — I don't like that one) can be found in a single place: coaching training. All are commonly used by coaches in routine work.
And there are a lot more tools than the handful than the ones Ben found. These questions are examples of a handful of techniques: eliciting alternatives, countering short-term emotion and status-quo bias, checking congruence with dentity. (Many of these have catchy names like "visioning" or less-catchy names like "identity coaching," but I can't find my coach manual right now which has them listed.)
* Noticing flinching or discongruent emotions ("I heard your voice slow when you mentioned your partner, and I'm wondering if there's something behind it")
* Finding unaddressed issues ("Tell me about your last hour. What caused you stress?")
* Helping you elicit and rank your values, and then check the congruence of each choice with your values
* Helping you access your intuition ("Close your eyes and breathe. Now, one day you wake up and everything's changed / put yourself into the shoes of yourself in 10 years and tell me the first thing you see ")
* Many techniques to address negative emotions around such a decision ("If you abandon this path, what does it mean about you? Now suppose a friend did it; what would you think about them?")
* Many techniques to actually make the decision ("If you made this change, what could go wrong? Now, let's take the first thing you said. Tell me 3 ways you could get more information about how likely that is to happen?")
This also implies that, if you want to be able to do it to yourself, you can pick up a coaching book ("Co-Active Coaching" is my favorite, but I've also heard recommended "The Coaching Habit") and try it, although I think it takes a lot of practice doing it on others before you can reliably turn it inward, as it is quite difficult to simultaneously focus on the concrete problem (what the coachee does) and on evaluating and guiding the thinking and feeling (what the coach does).
There have been a number of posts like this about questions to help guide rationalists through tough decisions or emotions. I think the rationality community has a lot to learn from coaching, which in some ways is all about helping people elevate their rationality to solve problems in their own life. I gave a talk on it in 2016; maybe I should write something on it.
Context: I completed coach training in 2017. The vast majority of my work is no longer in "pure" life coaching, but the skills influence me in daily life.
Quote for you summarizing this post:
“A person's success in life can usually be measured by the number of uncomfortable conversations he or she is willing to have.”
— Tim Ferriss
This post culminates years of thinking which formed a dramatic shift in my worldview. It is now a big part of my life and business philosophy, and I've showed it to friends many times when explaining my thinking. It's influenced me to attempt my own bike repair, patch my own clothes, and write web-crawlers to avoid paying for expensive API access. (The latter was a bust.)
I think this post highlights using rationality to analyze daily life in a manner much deeper than you can find outside of LessWrong. It's in the spirit of the 2012 post "Rational Toothpaste: A Case Study," except targeting a much more significant domain. It counters a productivity meme (outsource everything!) common in this community. It showcases economic concepts such as the value of information.
One thing that's shifted since I wrote this: When I went full-time on my business, I had thought that I would spend significant time learning how to run a server out of my closet to power my business, just like startups did 20 years ago. But it turned out that I had too many other things to study around that time, and I discovered that serverless can run most websites for dollars a month. Still a fan of self-hosting; Dan Luu has written that the inability to run servers is a sign of a disorganized company.
I think some of the specific examples are slightly inaccurate. There was some discussion in the comments about the real reason for the difference between canned and homemade tomato sauce. An attorney tells me my understanding of products liability is too simplistic. I'm less confident that a cleaner would have a high probability of cleaning an area you want them to ignore if you told them and they understood; the problem is that they usually have little communication with the host, and many don't speak English. (Also, I wish they'd stop "organizing" my desk and bathroom counter.) I think I shoehorned in that "avocado toast" analogy too hard. Outside of that, I can't identify any other examples that I have questions about. Both the overall analysis and the scores of individuals examples are in good shape.
Rationalists are known to get their hands dirty with knowledge . I remember when I saw two friends posting on Facebook their opinions of the California ballot: the rationalist tried to reason through their effects and looked at primary sources and concrete predictions, while the non-rationalist just looked at who endorsed what. I'd like to see us become known for getting our hands dirty quite literally as well.
Still waiting.
When will you send out the link for tomorrow?
https://galciv3.fandom.com/wiki/The_Galactic_Civilizations_Story#Humanity_and_Hyperdrive
I've hired (short-term) programmers to assist on my research several times. Each time, I've paid from my own money. Even assuming I could have used grant money, it would have been too difficult. And, long story short, there was no good option that involved giving funds to my lab so they could do the hire properly.
Grad students are training to become independent researchers. They have the jobs of conducting research (which in most fields is mostly not coding), giving presentations, writing, making figures, reading papers, and taking and teaching classes. Their career and skillset is rarely aligned with long-term maintenance of a software project; usually, they'd be sacrificing their career to build tools for the lab.
This is a great example of the lessons in https://www.lesswrong.com/posts/tTWL6rkfEuQN9ivxj/leaky-delegation-you-are-not-a-commodity
Really appreciate this informative and well-written answer. Nice to hear from someone on the ground about SELinux instead of the NSA's own presentations.
I phrased my question about time and space badly. I was interested in proving the time and space behavior of the software "under scrutiny", not in the resource consumption of the verification systems themsvelves.
LOL!
I know a few people who have worked in this area. Jan Hoffman and Peng Gong have worked on automatically inferring complexity. Tristan Knoth has gone the other way, including resource bounds in specs for program synthesis. There's a guy who did an MIT Ph. D. on building an operating system in Go, and as part of it needed an analyzer that can upper-bound the memory consumption of a system call. I met someone at CU Boulder working under Bor-Yuh Evan Chang who was also doing static analysis of memory usage, but I forget whom.
So, those are some things that were going on. About all of these are 5+ years old, and I have no more recent updates. I've gone to one of Peng's talks and read none of these papers.
I must disagree with the first claim. Defense-in-depth is very much a thing in cybersecurity. The whole "attack surface" idea assumes that, if you compromise any application, you can take over an entire machine or network of machines. That is still sometimes true, but continually less so. Think it's game over if you get root on a machine? Not if it's running SELinux.
Hey, can I ask an almost unrelated question that you're free to ignore or answer as a private message OR answer here? How good is formal verification for time and space these days?
I can speak only in broad strokes here, as I have not published in verification. My publications are predominantly in programming tools of some form, mostly in program transformation and synthesis.
There are two main subfields that fight over the term "verification": model checking and mechanized/interactive theorem proving. This is not counting people like Dawson Engler, who write very unsound static analysis tools but call it "verification" anyway. I give an ultra-brief overview of verification in https://www.pathsensitive.com/2021/03/why-programmers-shouldnt-learn-theory.html
I am more knowledgable about mechanized theorem proving, since my department has multiple labs who work in this area and I've taken a few of their seminars. But asking about time/space of verification really just makes sense for the automated part. I attended CAV in 2015 and went to a few model checking talks at ICSE 2016, and more recently talked to a friend on AWS's verification team about what some people there are doing with CBMC. Okay, and I guess I talked to someone who used to do model checking on train systems in France just two days ago. Outside of that exposure, I am super not-up-to-date with what's going on. But I'd still expect massive breakthroughs to make the news rounds over to my corner of academia, so I'll give my sense of the status quo.
Explicit state enumeration can crush programs with millions or billions of states, while symbolic model checking routinely handles $10^100$ states.
Those are both very small numbers. To go bigger, you need induction or abstraction, something fully automated methods are still bad at.
Yes, we can handle exponentially large things, but the exponential still wins. There's a saying of SAT solvers "either it runs instantly or it takes forever." I believe this is less true of model checking, though still true. (Also, many model checkers use SAT.)
If you want to model check something, either you check a very small program like a device driver, or you develop some kind of abstract model and check that instead.
I agree with about everything you said as well as several more criticisms along those lines you didn't say. I am probably more familiar with these issues than anyone else on this website with the possible exception of Jason Gross.
Now, suppose we can magic all that away. How much then will this reduce AI risk?
I don't see what this parable has to do with Bayesianism or Frequentism.
I thought this was going to be some kind of trap or joke around how "probability of belief in Bayesianism" is a nonsense question in Frequentism.
I do not. I mostly know of this field from conversations with people in my lab who work in this area, including Osbert Bastani. (I'm more on the pure programming-languages side, not an AI guy.) Those conversations kinda died during COVID when no-one was going into the office, plus the people working in this area moved onto their faculty positions.
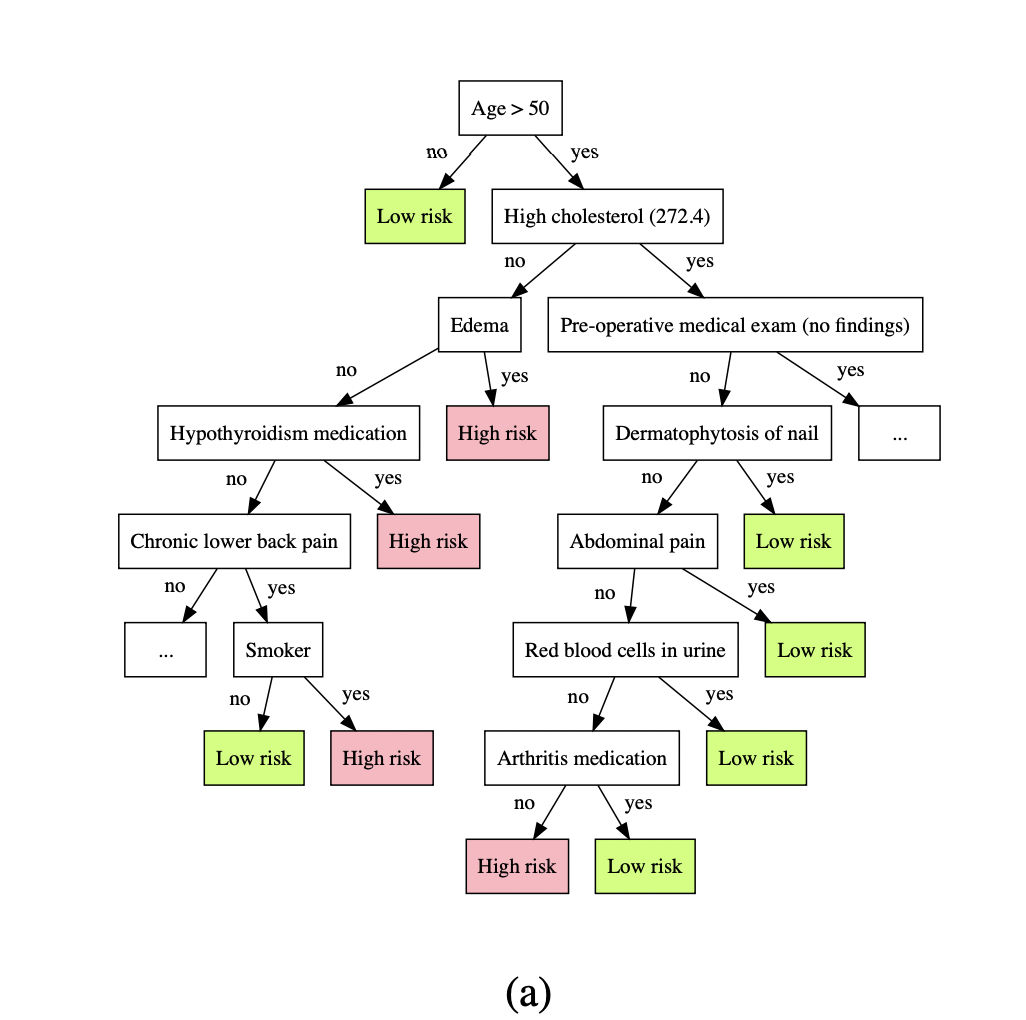
I think being able to backtrace through a tree counts as victory, at least in comparison to neural nets. You can make a similar criticism about any large software system.
You're right about the random forest there; I goofed there. Luckily, I also happen to know of another Osbert paper, and this one does indeed do a similar trick for neural nets (specifically for reinforcement learning); https://proceedings.neurips.cc/paper/2018/file/e6d8545daa42d5ced125a4bf747b3688-Paper.pdf
I think you're accusing people who advocate this line of idle speculation, but I see this post as idle speculation. Any particular systems you have in mind when making this claim?
I'm a program synthesis researcher, and I have multiple specific examples of logical or structured alternatives to deep learning
Here's Osbert Bastani's work approximating neural nets with decision trees, https://arxiv.org/pdf/1705.08504.pdf . Would you like to tell me this is not more interpretable over the neural net it was generated from?
Or how about Deep3 ( https://dl.acm.org/doi/pdf/10.1145/3022671.2984041 ), which could match the best character-level language models of its day ( https://openreview.net/pdf?id=ry_sjFqgx ).
The claim that deep learning is not less interpretable than alternatives is not born out by actual examples of alternatives.
I'm a certified life coach, and several of these are questions found in life coaching.
E.g.:
Is there something you could do about that problem in the next five minutes?
Feeling stuck sucks. Have you spent a five minute timer generating options?
What's the twenty minute / minimum viable product version of this overwhelming-feeling thing?
These are all part of a broader technique of breaking down a problem. (I can probably find a name for it in my book.) E.g.: Someone comes in saying they're really bad at X, and you ask them to actually rate their skills and then what they could do to become 5% better.
You want to do that but don't think you will? Do you want to make a concrete plan now?
Do you want to just set an alarm on your phone now as a reminder? (from Damon Sasi)
Do you sort of already know what you're going to do / have your mind made up about this?
These are all part of the "commitment" phase of a coaching session, which basically looks like walking someone through SMART goals.
Do you know anyone else who might have struggled with or succeeded at that? Have you talked to them about it? (from Damon Sasi)
Who do you know who you could ask for help from?
I can't say these are instances of a named technique, but they are things you'd commonly find a coach asking. Helping someone look inside themselves for resources they already have is a pretty significant component of coaching.
There's a major technique in coaching not represented here called championing. Champion is giving someone positive encouragement by reinforcing some underlying quality. E.g.: "You've shown a lot of determination to get this far, and I know you'll be able to use it to succeed at X."
Several of these questions do differ from life coaching in a big way: they suggest a course of action. We call this "advice-giving" as telling someone what to do serves the advice-giver's agenda more than the receiver's, or at least serves what the advice-giver thinks the receiver's agenda should be. The best piece of (irony forthcoming) advice I've received about coaching is to "coach the person, not the problem." Much more effective than to help someone with the task at hand is to help them cultivate the underlying skill. Instead of suggesting courses of action, you instead focus on their ability to come up with and evaluate options.
Recommended reading: Co-active Coaching, https://www.amazon.com/Co-Active-Coaching-Changing-Business-Transforming/dp/1857885678
I realize now that this expressed as a DAG looks identical to precommitment.
Except, I also think it's a faithful representation of the typical Newcomb scenario.
Paradox only arises if you can say "I am a two-boxer" (by picking up two boxes) while you were predicted to be a one-boxer. This can only happen if there are multiple nodes for two-boxing set to different values.
But really, this is a problem of the kind solved by superspecs in my Onward! paper. There is a constraint that the prediction of two-boxing must be the same as the actual two-boxing. Traditional causal DAGs can only express this by making them literally the same node; super-specs allow more flexibility. I am unclear how exactly it's handled in FDT, but it has a similar analysis of the problem ("CDT breaks correlations").
Okay, I see how that technique of breaking circularity in the model looks like precommitment.
I still don't see what this has to do with counterfactuals though.
I don't understand what counterfactuals have to do with Newcomb's problem. You decide either "I am a one-boxer" or "I am a two-boxer," the boxes get filled according to a rule, and then you pick deterministically according to a rule. It's all forward reasoning; it's just a bit weird because the action in question happens way before you are faced with the boxes. I don't see any updating on a factual world to infer outcomes in a counterfactual world.
"Prediction" in this context is a synonym for conditioning. is defined as .
If intervention sounds circular...I don't know what to say other than read Chapter 1 of Pearl ( https://www.amazon.com/Causality-Reasoning-Inference-Judea-Pearl/dp/052189560X ).
To give a two-sentence technical explanation:
A structural causal model is a straight-line program with some random inputs. They look like this
u1 = randBool()
rain = u1
sprinkler = !rain
wet_grass = rain || sprinkler
It's usually written with nodes and graphs, but they are equivalent to straight-line programs, and one can translate easily between these two presentations.
In the basic Pearl setup, an intervention consists of replacing one of the assignments above with an assignment to a constant. Here is an intervention setting the sprinkler off.
u1 = randBool()
rain = u1
sprinkler = false
wet_grass = rain || sprinkler
From this, one can easily compute that.
If you want the technical development of counterfactuals that my post is based on, read Pearl Chapter 7, or Google around for the "twin network construction."
Or I'll just show you in code below how you compute the counterfactual "I see the sprinkler is on, so, if it hadn't come on, the grass would not be wet," which is written
We construct a new program,
u1 = randBool()
rain = u1
sprinkler_factual = !rain
wet_grass_factual = rain || sprinkler_factual
sprinkler_counterfactual = false
wet_grass_counterfactual = rain || sprinkler_counterfactual
This is now reduced to a pure statistical problem. Run this program a bunch of times, filter down to only the runs where sprinkler_factual is true, and you'll find that wet_grass_counterfactual is false in all of them.
If you write this program as a dataflow graph, you see everything that happens after the intervention point being duplicated, but the background variables (the rain) are shared between them. This graph is the twin network, and this technique is called the "twin network construction." It can also be thought of as what the do(y | x -> e) operator is doing in our Omega language.
While I can see this working in theory, in practise it's more complicated as it isn't obvious from immediate inspection to what extent an argument is or isn't dependent on counterfactuals. I mean counterfactuals are everywhere! Part of the problem is that the clearest explanation of such a scheme would likely make use of counterfactuals, even if it were later shown that these aren't necessary.
- Is the explanation in the "What is a Counterfactual" post linked above circular?
- Is the explanation in the post somehow not an explanation of counterfactuals?
The key unanswered question (well, some people claim to have solutions) in Functional Decision theory is how to construct the logical counterfactuals that it depends on.
I read a large chunk of the FDT paper while drafting my last comment.
The quoted sentence may hint at the root of the trouble that I and some others here seem to have in understanding what you want. You seem to be asking about the way "counterfactual" is used in a particular paper, not in general.
It is glossed over and not explained in full detail in the FDT paper, but it seems to mainly rely on extra constraints on allowable interventions, similar to the "super-specs" in one of my other papers: https://www.jameskoppel.com/files/papers/demystifying_dependence.pdf .
I'm going to go try to model Newcomb's problem and some of the other FDT examples in Omega. If I'm successive, it's evidence that there's nothing more interesting going on than what's in my causal hierarchy post.
I'm having a little trouble understanding the question. I think you may be thinking of either philosophical abduction/induction or logical abduction/induction.
Abduction in this article is just computing P(y | x) when x is a causal descendant of y. It's not conceptually different from any other kind of conditioning.
In a different context, I can say that I'm fond of Isil Dillig's thesis work on an abductive SAT solver and its application to program verification, but that's very unrelated.
I'm not surprised by this reaction, seeing as I jumped on banging it out rather than checking to make sure that I understand your confusion first. And I still don't understand your confusion, so my best hope was giving a very clear, computational explanation of counterfactuals with no circularity in hopes it helps.
Anyway, let's have some back and forth right here. I'm having trouble teasing apart the different threads of thought that I'm reading.
After intervening on our decision node do we just project forward as per Causal Decision Theory or do we want to do something like Functional Decision Theory that allows back-projecting as well?
I think I'll need to see some formulae to be sure I know what you're talking about. I understand the core of decision theory to be about how to score potential actions, which seems like a pretty separate question from understanding counterfactuals.
More specifically, I understand that each decision theory provides two components: (1) a type of probabilistic model for modeling relevant scenarios, and (2) a probabilistic query that it says should be used to evaluate potential actions. Evidentiary decision theory uses an arbitrary probability distribution as its model, and evaluates actions by P(outcome |action). Causal decision theory uses a causal Bayes net (set of intervential distributions) and the query P(outcome | do(action)). I understand FDT less well, but basically view it as similar to CDT, except that it intervenes on the input to a decision procedure rather than on the output.
But all this is separate from the question of how to compute counterfactuals, and I don't understand why you bring this up.
When trying to answer these questions, this naturally leads us to ask, "What exactly are these counterfactual things anyway?" and that path (in my opinion) leads to circularity.
I still understand this to be the core of your question. Can you explain what questions remain about "what is a counterfactual" after reading my post?
Oh hey, I already have slides for this.
Here you go: https://www.lesswrong.com/posts/vuvS2nkxn3ftyZSjz/what-is-a-counterfactual-an-elementary-introduction-to-the
I took the approach: if I very clearly explain what counterfactuals are and how to compute them, then it will be plain that there is no circularity. I attack the question more directly in a later paragraph, when I explain how counterfactual can be implemented in terms of two simpler operations: prediction and intervention. And that's exactly how it is implemented in our causal probabilistic programming language, Omega (see http://www.zenna.org/Omega.jl/latest/ or https://github.com/jkoppel/omega-calculus ).
Unrelatedly, if you want to see some totally-sensible but arguably-circular definitions, see https://en.wikipedia.org/wiki/Impredicativity .
"Many thousands of date problems were found in commercial data processing systems and corrected. (The task was huge – to handle the work just for General Motors in Europe, Deloitte had to hire an aircraft hangar and local hotels to house the army of consultants, and buy hundreds of PCs)."
Sounds like more than a few weeks.
Thanks; fixed both.
Was it founded by the Evil Twin of Peter Singer?
https://www.smbc-comics.com/comic/ev
Define "related?"
Stories of wishes gone awry, like King Midas, are the original example.