Posts
Comments
See my above comment, where I was trying to get a handle on this. It increasingly seems like the answer is that most of it comes from breakthrough+serial intervals
I cobbled together a compartmental fitting model for Omicron to try to get a handle on some viral characteristics empirically. It's not completely polished yet, but this is late enough already, so I figured the speed premium was enough to share this version in a comment before writing up a full-length explanation of some of the choices made (e.g. whether to treat vaccination as some chance of removal or decreased risk by interaction).
You can find the code here in an interactive environment.
https://mybinder.org/v2/gh/pasdesc/Omicron-Model-Fitting/main
I built it to be architecturally pretty easy to tinker with (models are fully polymorphic, cost function can be swapped easily, almost all parameters are tweakable), but my messy code and lack of documentation may jeopardize that. Right now, it's only loaded with the UK and Denmark, because those are the two nations that had high-resolution Omicron case data available, but if anyone is aware of more sources, it's just some data parsing in a spreadsheet to add them, which I'm happy to do. It should optimize the viral characteristics across all of the populations simultaneously, i.e. assuming Omicron is identical in all these places. It also doesn't currently account for prior Delta infection, because there was a full OOM variation in those statistics, and the ~20% protection offered didn't seem 100% crucial to incorporate in an alpha version. Similarly, NPIs are not included.
With those disclaimers out of the way, here are some results!
In full moderately high-resolution optimization mode, the numbers I've found are something along the lines of Beta: 1.15-1.7 Gamma: 0.7-0.85 Alpha: 10+ (varies significantly, implies a very short pre-infectious exposure period). The implied serial interval is on the order of ~16 hours, which is short enough to strain plausibility (Very roughly, R_0=beta/gamma, serial interval=1/beta. Better estimates for these are another v2 thing.). However, these numbers can't be quite taken at face value as the "best" solution, because the numeric "grid" I'm using to evaluate different options can't evaluate the depth of local minima in a first pass, meaning that the program could privilege certain spots on a roughly level accuracy curve because the test point chosen happens to coincide with the bottom of the trough.
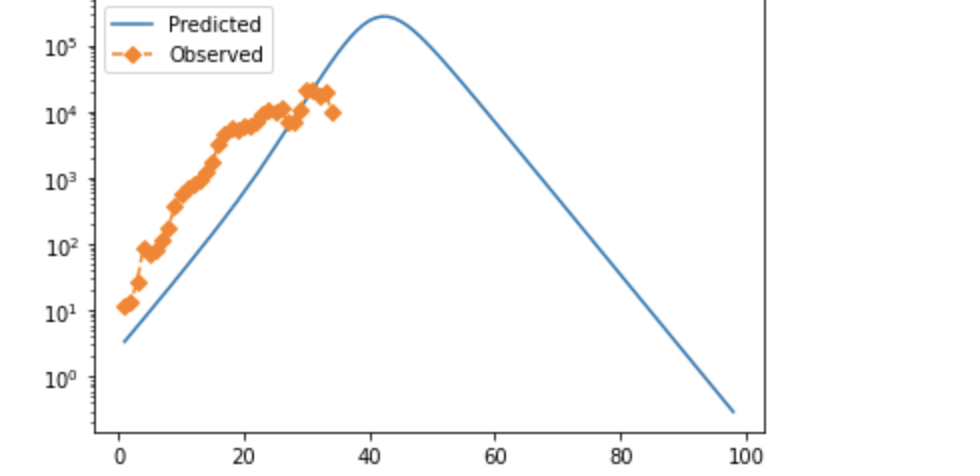
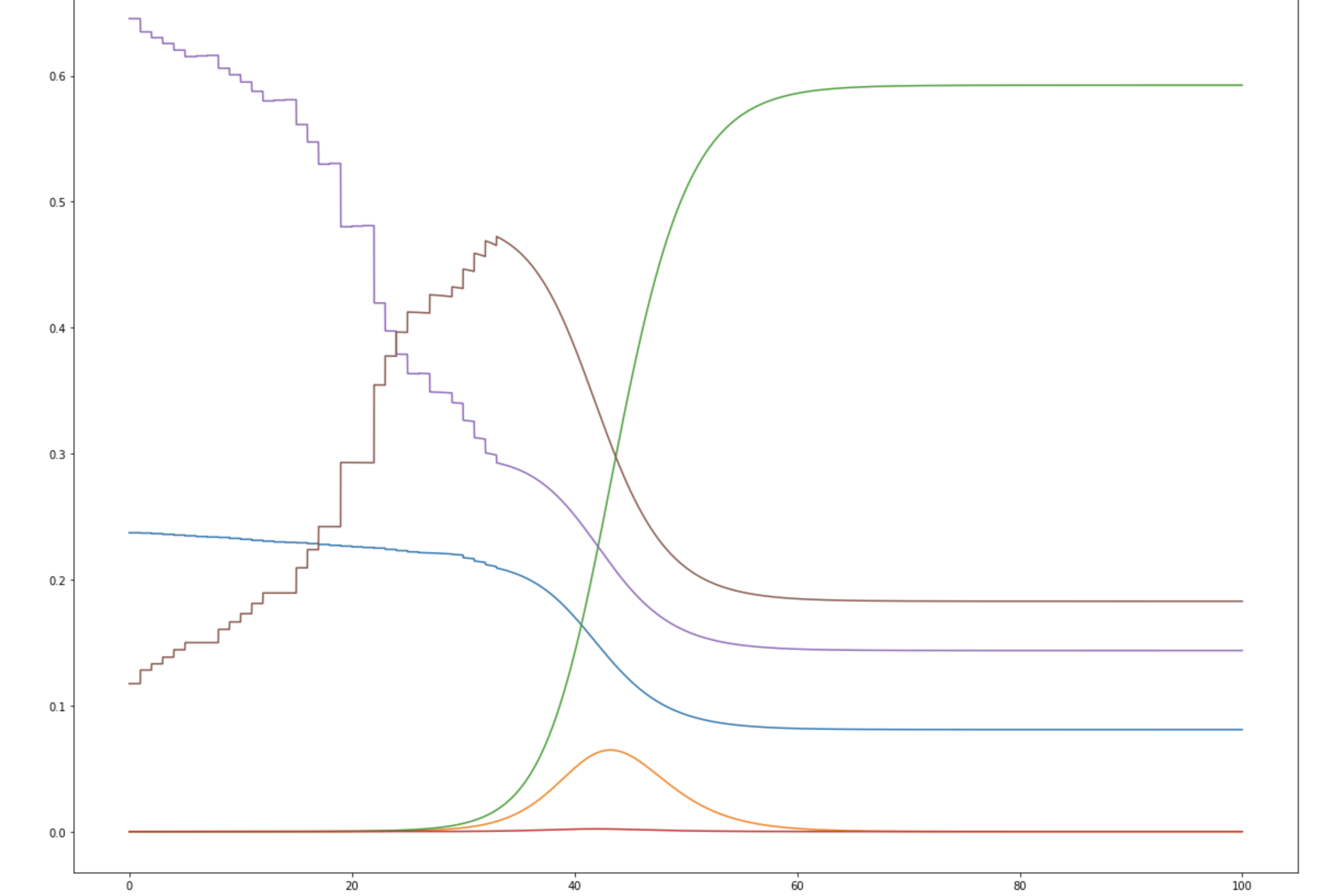
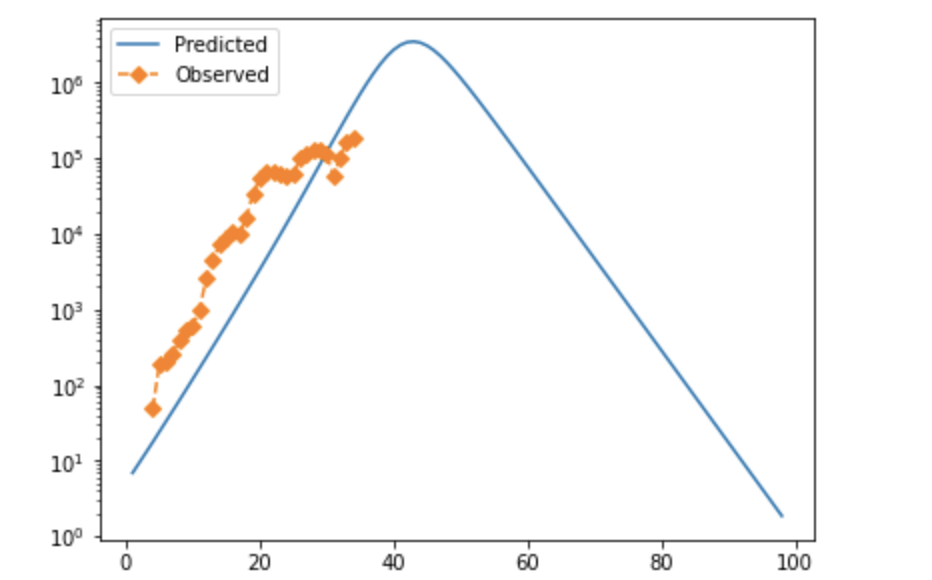
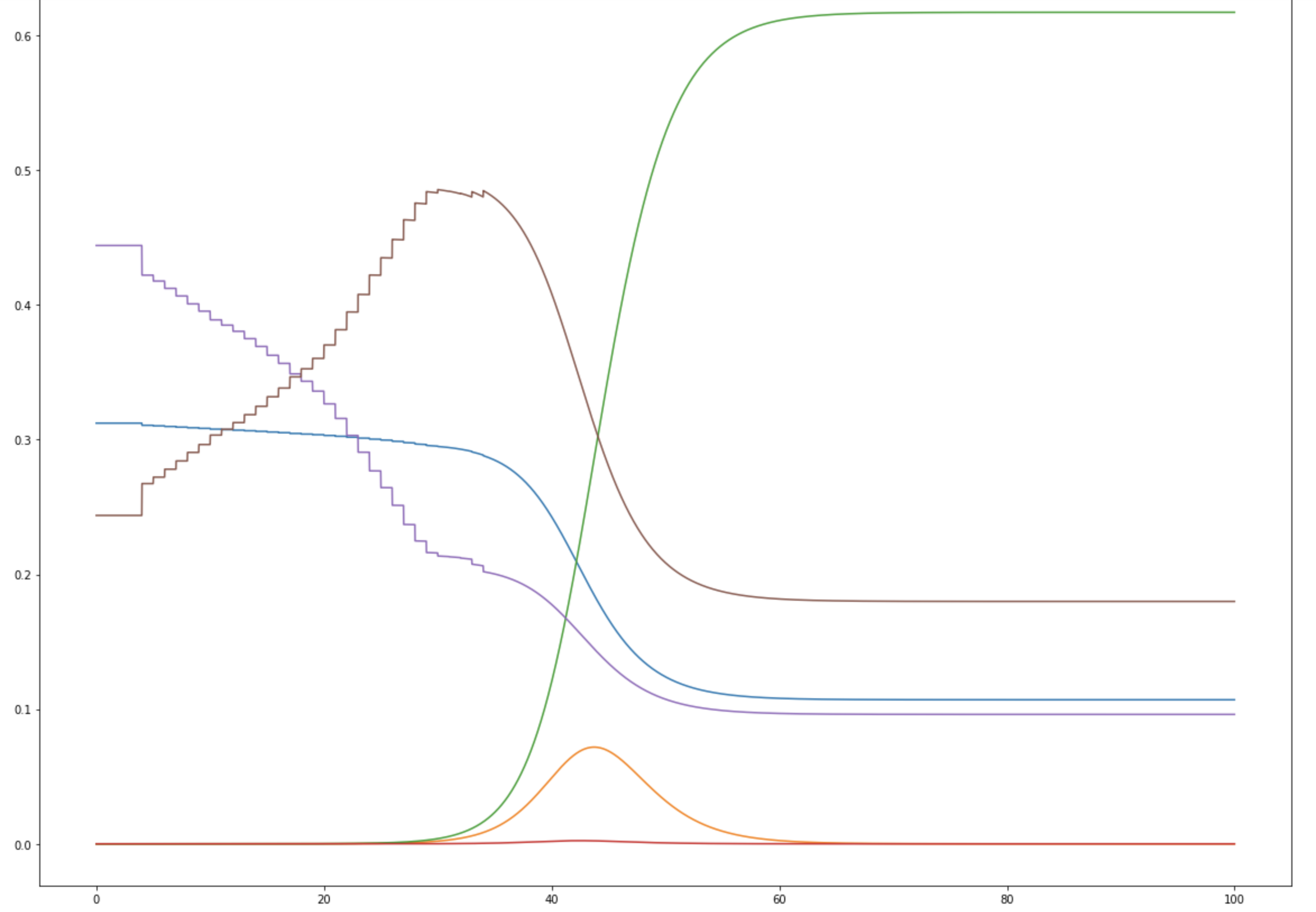
Note that in both cases, observed cases flatten as time goes on/cases rise. I strongly suspect this is due to testing failure, and will likely modify the error function to prioritize mid-case data or adjust for positivity rate. If anyone has rigorous suggestions about how to do that, I'd be very interested. These fits also look not-very-impressive because they're pretty exponential at the moment; they aren't perfect, but the similarity between the UK and Denmark is suggestive, and if you tweak things slightly accounting for both of these factors, you can get visually better fits—see below for why.
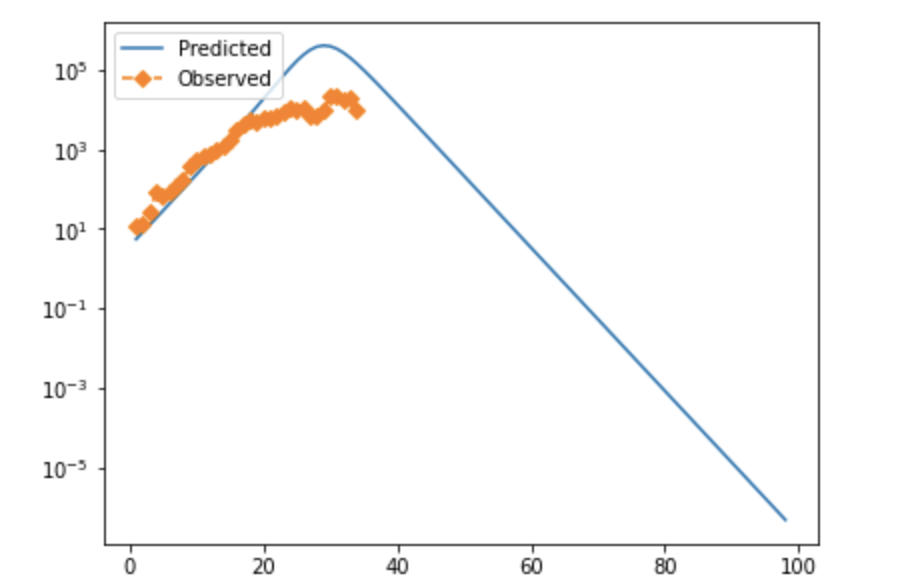
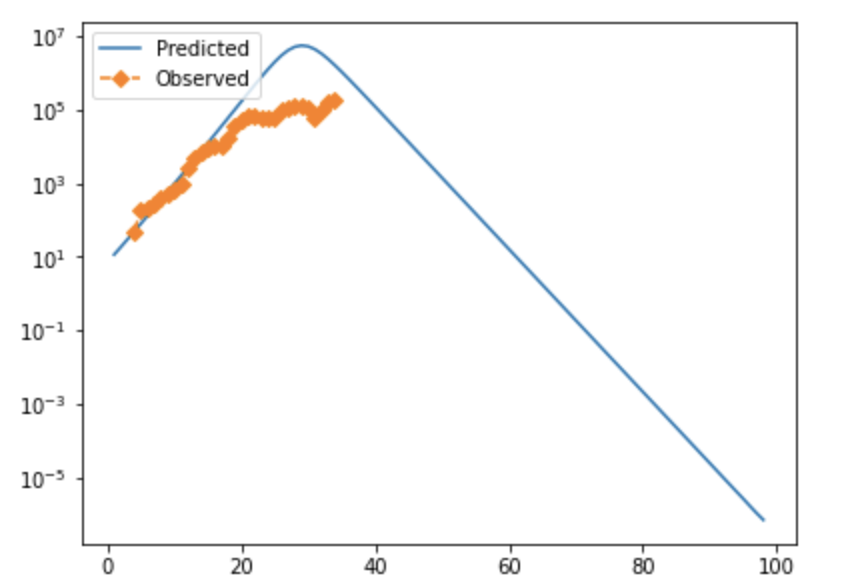
I'm not aware of a way to do fully numeric gradient descent, but in v2 of this, I'm going to improve the iteration element of the optimization algorithm to slide to an adjacent "square" if appropriate and/or add numeric discrete-direction descejnt. In the meantime, it's more appropriate to look at the points within a threshold of optimal, which form clouds as shown below (note that because many of these variables are at least partially inverted when considered in terms of viral characteristics, bigger clouds further from the origin are to be expected.
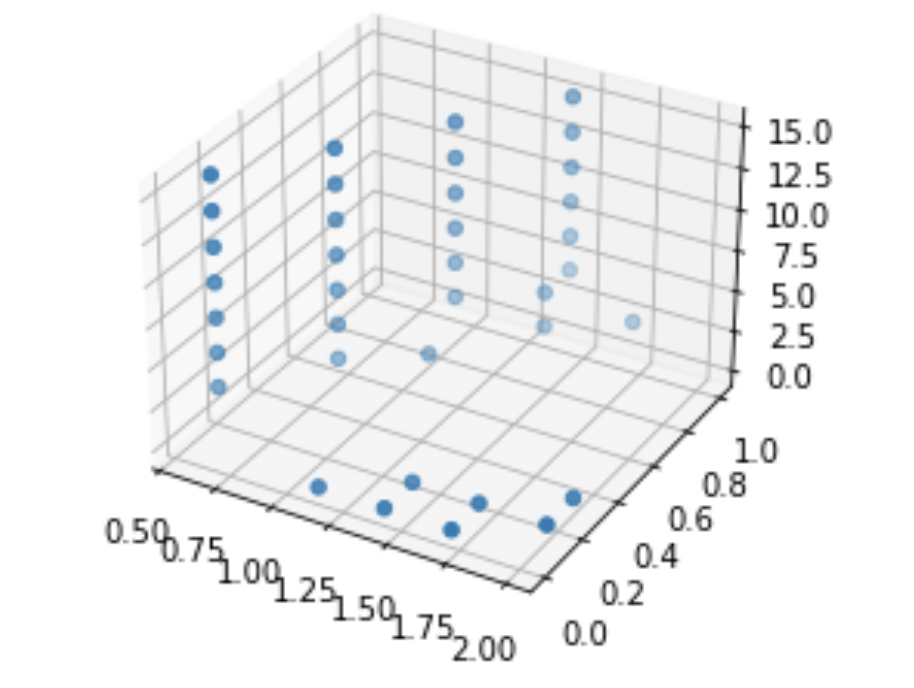
Please let me know if anyone's interested in any specific scenarios, confused, or having issues—there's a known bug where if any of the coefficients is greater than 1/resolution, things go to hell very quickly.
Ok, I think I understand our crux here. In the fields of math I’m talking about, 3^(-1) is a far better way to express the multiplicative inverse of 3, simply because it’s not dependent on any specific representation scheme and immediately carries the relevant meaning. I don’t know enough about the pedagogy of elementary school math to opine on that.
Sorry for the lack of clarity-I’m not talking about high school algebra, I’m talking about abstract algebra. I guess if we’re writing -2 as a simplification, that’s fine, but seems to introduce a kind of meaningless extra step-I don’t quite understand the “special cases” you’re talking about, because it seems to me that you can eliminate subtraction without doing this? In fact, for anything more abstract than calculus, that’s standard-groups, for example, don’t have subtraction defined (usually) other than as the addition of the inverse.
This seems super annoying when you start dealing with more abstract math: while it's plausibly more intuitive as a transition into finite fields (thinking specifically of quadratic residues, for example), it would really really suck for graphing, functions, calculus, or any sort of coefficent-based work. It also sounds tremendously annoying for conceptualizing bases/field-adjoins/sigma notation.
I’m trying to figure out what you mean-my current interpretation is that my post is an example of reason that will lead us astray. I could be wrong about this, and would appreciate correction, as the analogy isn’t quite “clicking” for me. If I’m right, I think it’s generally a good norm to provide some warrant for these types of things: I can vaguely see what you might mean, but it’s not obvious enough to me to be able to engage in productive discourse, or change my current endorsement of my opinion: I’m open to the possibility you might be right, but I don’t know what you’re saying. This might be just an understanding failure on my part, in which case I’d appreciate any guidance/correction/clarification.
This post seems excellent overall, and makes several arguments that I think represent the best of LessWrong self-reflection about rationality. It also spurred an interesting ongoing conversation about what integrity means, and how it interacts with updating.
The first part of the post is dedicated to discussions of misaligned incentives, and makes the claim that poorly aligned incentives are primarily to blame for irrational or incorrect decisions. I’m a little bit confused about this, specifically that nobody has pointed out the obvious corollary: the people in a vacuum, and especially people with well-aligned incentive structures, are broadly capable of making correct decisions. This seems to me like a highly controversial statement that makes the first part of the post suspicious, because it treads on the edge of proving (hypothesizing?) too much: it seems like a very ambitious statement worthy of further interrogation that people’s success at rationality is primarily about incentive structures, because that assumes a model in which humans are capable and preform high levels of rationality regularly. However, I can’t think of an obvious counterexample (a situation in which humans are predictably irrational despite having well-aligned incentives for rationality), and the formulation of this post has a ring of truth for me, which suggests to me that there’s at least something here. Conditional on this being correct, and there not being obvious counterexamples, this seems like a huge reframing that makes a nontrivial amount of the rationality community’s recent work inefficient-if humans are truly capable of behaving predictably rationally through good incentive structures, then CFAR, etc. should be working on imposing external incentive structures that reward accurate modeling, not rationality as a skill. The post obliquely mentions this through discussion of philosopher-kings, but I think this is a case in which an apparently weaker version of a thesis actually implies the stronger form: philosopher-kings being not useful for rationality implies that humans can behave predictably rationally, which implies that rationality-as-skill is irrelevant. This seems highly under-discussed to me, and this post is likely worthy of further promotion solely for its importance to this issue.
However, the second broad part of the post, examining (roughly) epistemic incentive structures, is also excellent. I strongly suspect that a unified definition of integrity with respect to behavior in line with ideology would be a significant advance in understanding how to effectively evaluate ideology that’s only “viewable” through behavior, and I think that this post makes an useful first step in laying out the difficulties of punishing behavior unmoored from principles while avoiding enforcing old unupdated beliefs. The comment section also has several threads that I think are worthy of revisitation: while the suggestion of allowing totally free second-level updating was found untenable due to the obvious hole of updating ideology to justify in-the-moment behavior, the discussion of ritual around excessive vows and Zvi’s (I believe) un-followed-up suggestion of distinguishing beliefs from principle both seem to have real promise to them: my guess would be that some element of ritual is necessary to avoid cheapening principle and allowing for sufficient contradictory principles to justify any behavior.
Finally, the discussion of accountability seems the least developed, but also a useful hook for further discussion. I especially like the suggestion of “mandatory double-crux”‘powers: I’ve informally tried this system by double-cruxing controversial decisions before action and upon reflection, I believe it’s the right level and type of impediment: likely to induce reflection, a non-trivial inconvenience, but not a setting that’s likely to shake well-justified beliefs and cause overcorrection.
Overall, I support collation of this post, and would strongly support collation if it was updated to pull more on the many potential threads it leaves.
That’s a fair point-see my comment to Raemon. The way I read it, the mod consensus was that we can’t just curate the post, meaning that comments are essentially the only option. To me, this means an incorrect/low quality post isn’t disqualifying, which doesn’t decrease the utility of the review, just the frame under which it should be interpreted.
That’s fair-I wasn’t disparaging the usefulness of the comment, just pointing out that the post itself is not actually what’s being reviewed, which is important, because it means that a low-quality post that sparks high-quality discussion isn’t disqualifying.
Note that this review is not of the content that was nominated; nomination justifications strongly suggest that the comment suggestion, not the linkpost, was nominated.
(Epistemic status: I don’t have much background in this. Not particularly confident, and attempting to avoid making statements that don’t seem strongly supported.)
I found this post interesting and useful, because it brought a clear unexpected result to the fore, and proposed a potential model that seems not incongruent with reality. On a meta-level, I think supporting these types of posts is quite good, especially because this one has a clear distinction between the “hard thing to explain” and the “potential explanation,” which seems very important to allow for good discussion and epistemology.
While reading the post, I found myself wishing that more time was spent discussing the hypothesis that IQ tests, while intelligence-loaded in general, are not a great way to analyze intelligence for autistic people. The post briefly touches on this, but “mutations positively correlate with intelligence but negatively with test-taking ability through some mediator, meaning that at first, increased intelligence outweighs the negative effects, but depending on exact circumstance, intelligence is not possible to express on a standard IQ test after enough mutations accumulate” seems like a natural hypothesis that deserves more analysis. However, upon further reflection, I think that the neglection of this hypothesis isn’t actually an issue, because it conceals a regress: why does intelligence outweigh lack of test-taking ability at first, only to bring eventual significant costs? I think there are several just-so stories that could explain an inflection point, but I’d prefer not to posit them unless someone with more background/knowledge in this subject suggests that this is viable so as to prevent harmful adoption.
I think a more serious issue is the selection bias mentioned in the discussion of autism. Because IQ is positively correlated with good outcomes writ large (https://www.gwern.net/Embryo-selection, see an early section), including functionality, and autism in the DSM-V is defined as requiring various deficits and significant impairment (https://www.autismspeaks.org/autism-diagnosis-criteria-dsm-5), it would be somewhat shocking if autism was not negatively correlated with IQ. If we assume the two variables are completely independent, it would still be less likely for higher-IQ people to be diagnosed as autistic, because they are nearly definitionally less likely to meet the diagnostic criteria. This suggests a much simpler model, given the apparent correlation between autism and IQ: autism mutations push up intelligence in the vast majority of cases, and lower IQ autistic people are far more likely to be diagnosed. I wonder whether this could even explain some of the diverse harms associated with autism—if autism mutations push up “technical” intelligence/performance on iq tests relative to general intelligence, then could i.e. social skills appear to suffer because they’re correlated with a lower general intelligence (obviously way over-simplified, and entirely speculative).
Overall, I’d appreciate if this post was more comprehensive, but I think it’s a good category of post to promote as is. I’d weakly advocate for inclusion, and strongly advocate for inclusion conditional on editing to spend more time discussing selection effects.
I strongly oppose collation of this post, despite thinking that it is an extremely well-written summary of an interesting argument on an interesting topic. The reason that I do so is because I believe it represents a substantial epistemic hazard because of the way it was written, and the source material it comes from. I think this is particularly harmful because both justifications for nominations amount to "this post was key in allowing percolation of a new thesis unaligned with the goals of the community into community knowledge," which is a justification that necessitates extremely rigorous thresholds for epistemic virtue: a poor-quality argument both risks spreading false or over-proven ideas into a healthy community, if the nominators are correct, and also creates conditions for an over-correction caused by the tearing down of a strongman. When assimilating new ideas and improving models, extreme care must be taken to avoid inclusion of non-steelmanned parts of the model, and this post does not represent that. In this case, isolated demands for rigor are called for!
The first major issue is the structure of the post. A more typical book review includes critique, discussion, and critical analysis of the points made in the book. This book review forgoes these, instead choosing to situate the thesis of the book in the fabric of anthropology and discuss the meta-level implications of the contributions at the beginning and end of the review. The rest of the review is dedicated to extremely long, explicitly cherry-picked block quotes of anecdotal evidence and accessible explanations of Heinrich's thesis. Already, this poses an issue: it's not possible to evaluate the truth of the thesis, or even the merit of the arguments made for it, with evidence that's explicitly chosen to be the most persuasive and favorable summaries of parts glossed over. Upon closer examination, even without considering that this is filtered evidence, this is an attempt to prove a thesis using exclusively intuitive anecdotes disguised as a compelling historical argument. The flaws in this approach are suggested by the excellent response to this post: it totally neglects the possibility that the anecdotes are being framed in a way that makes other potentially correct explanations not fit nicely. Once one considers that this evidence is filtered to be maximally charitable, the anecdotal strategy offers little-to-no information. The problem is actually even worse than this: because the information presented in the post does not prove the thesis in any way shape or form, but the author presents it as well-argued by Heinrich, the implication is that the missing parts of the book do the rigorous work. However, because these parts weren't excerpted, a filtered-evidence view suggests that they are even less useful than the examples discussed in the post.
The second major issue is that according to a later SSC post, the book is likely factually incorrect in several of its chosen anecdotes, or at the very least exaggerates examples to prove a point. Again, this wouldn't necessarily be a negative impact on the post, except that the post a). does not point this out, which suggests a lack of fact-checking, and b). quotes Heinrich so extensively that Heinrich's inaccurate arguments are presented as part of the thesis of the post. This is really bad on the naive object level: it means that parts of the post are both actively misleading, and increase the chance of spreading harmful anecdotes, and also means that beyond the evidentiary issues presented in the previous paragraph, which assumed good-faith, correct arguments, the filtered evidence is actively wrong. However, it actually gets worse from here: there are two layers of Gell-Mann amnesia-type issues that occur. First, the fact that the factual inaccuracies were not discovered at the time of writing suggests that the author of the post did not spot-check the anecdotes, meaning that none of Heinrich's writing should be considered independently verified. Scott even makes this explicit when he passes responsibility on factual inaccuracies to the author instead of him on supporting the thesis of his post in the follow-up post. This seems plausibly extremely harmful, especially because of the second layer of implicated distrust: none of Heinrich's writing can be taken at face value, which, taken in combination with the previous issue, means that the thesis of both this post and the book should be viewed as totally unsupported, because, as mentioned above, they are entirely supported by anecdotes. This is particularly worrying given that at least one nominator appreciated the "neat factoids" that this post presents.
I would strongly support not including this post in any further collections until major editing work has been done. I think the present post is extremely misleading, epistemically hazardous, and has the potential for significant harm, especially in the potential role of "vaccinating" the community against useful external influence. I do not think my criticism of this post applies to other book reviews by the same author.
This seems to me like a valuable post, both on the object level, and as a particularly emblematic example of a category ("Just-so-story debunkers") that would be good to broadly encourage.
The tradeoff view of manioc production is an excellent insight, and is an important objection to encourage: the original post and book (haven't read in the entirety) appear to have leaned to heavily on what might be described as a special case of a just-so story: the phenomena is a behavior difference is explained as an absolute by using a post-hoc framework, and then doesn't evaluate the meaning of the narrative beyond the intended explanatory effect.
This is incredibly important, because just-so stories have a high potential to deceive a careless agent. Let's look at the recent example of a AstroZeneca's vaccine. Due to a mistake, one section of the vaccine arm of the trial was dosed with a half dose followed by a full dose. Science isn't completely broken, so the possibility that this is a fluke is being considered, but potential causes for why a half-dose full-dose regime (HDFDR) would be more effective have also been proposed. Figuring out how much to update on these pieces of evidence is somewhat difficult, because the selection effect is normally not crucial to evaluating hypotheses in the presence of theory.
To put it mathematically, let A be "HDFDR is more effective than a normal regime," B be "AstroZeneca's groups with HDFDR were more COVID-safe than the treatment group," C be "post-B, a explanation that predicts A is accepted as fact," and D be "pre-B, a explanation that predicts A is accepted as the scientific consensus.
We're interested in P(A|B), P(A|(B&C)), and P(A|(B&D)). P(A|B) is fairly straightforward: By simple application of Bayes's theorem, P(A|B)=P(B|A)*P(A)/(P(A)*P(B|A)+P(¬A)*P(B|¬A). Plugging in toy numbers, let P(B|A)=90% (if HDFDR was more effective, we're pretty sure that the HDFDR would have been more effective in AstroZeneca's trial), P(A)=5% (this is a weird result that was not anticipated, but isn't totally insane). P(B|¬A)=10% (this one is a bit arbitrary, and it depends on the size/power of the trials, a brief google suggests that this is not totally insane). Then, P(A|B)=0.90*0.05/(0.9*0.05+0.95*0.1)=0.32
Next, let's look at P(A|B&C). We're interested in finding the updated probability of A, after observing B and then observing C, meaning we can use our updated prior: P(A|C)=P(C|(A&B))*P(A|B)/(P(C|(A&B))*P(A|B) + P(C|(¬A)&B) * P(¬A|B)). If we slightly exaggerate how broken the world is for the sake of this example, and say that P(C|A&B)=0.99 and P(C|¬A&B)=0.9 (If there is a real scientific explanation, we are almost certain to find it, if there is not, then we'll likely still find something that looks right), then this simplifies to 0.99*0.32/(0.99*0.32+ 0.9 * 0.68), or 0.34: post-hoc evidence adds very little credence in a complex system in which there are sufficient effects that any result can be explained.
This should not, however, be taken as a suggestion to disregard all theories or scientific explorations in complex systems as evidence. Pre-hoc evidence is very valuable: P(A|D&B) can be first evaluated by evaluating P(A|D)=P(D|A)*P(A)/(P(A)*P(D|A)+P(¬A)*P(D|¬A). As before, P(A)=0.05. Filling in other values with roughly reasonable numbers: P(D|¬A)=0.05 (coming up with an incorrect explanation with no motivation is very unlikely), P(D|A)=0.5 (there's a fair chance we'll find a legitimate explanation with no prior motivation). These choices also roughly preserve the log-odds relationship between P(C|A&B) and P(C|¬A&B). Already, this is a 34% chance of A, which further demonstrates the value of pre-registering trials and testing hypotheses.
P(A|B&D) then equals P(B|(A&D))*P(A|D)/(P(D|(A&B))*P(A|D)) + P(B|(¬A)&D) * P(¬A|D)). Notably, D has no impact on B (assuming a well-run trial, which allows further generalization), meaning P(B|A&D)=P(B|A), simplifying this to P(B|(A))*P(A|D)/(P(B|(A))*P(A|D)) + P(B|(¬A)) * P(¬A|D)), or 0.9*0.34/( 0.9*0.34+0.1*0.66), or 0.82. This is a stark difference from the previous case, and suggests that the timing of theories is crucial in determining how a Bayesian reasoner ought to evaluate statements. Unfortunately, this information is often hard to acquire, and must be carefully interrogated.
In case the analogy isn't clear, in this case, the equivalent of a unexpected regime being more effective is that reason apparently breaks down and yields severely suboptimal results: the hypothesis that reason is actually less useful than culture in problems with non-monotonically increasing rewards as the solution progresses is a possible one, but because it was likely arrived at to explain the results of the manioc story, the existence of this hypothesis is weak evidence to prefer it over the hypothesis with more prior probability mass: that different cultures value time in different ways.
Obviously, this Bayesian approach isn't particularly novel, but I think it's a useful reminder as to why we have to be careful about the types of problems outlined in this post, especially in the case of complex systems where multiple strategies are potentially legitimate. I strongly support collation on a meta-level to express approval for the debunking of just-so stories and allowing better reasoning. This is especially true when the just-so story has a ring of truth, and meshes well with cultural narratives.
I think this post significantly benefits in popularity, and lacks in rigor and epistemic value, from being written in English. The assumptions that the post makes in some part of the post contradict the judgements reached in others, and the entire post, in my eyes, does not support its conclusion. I have two main issues with the post, neither of which involve the title or the concept, which I find excellent:
First, the concrete examples presented in the article point towards a different definition of optimal takeover than is eventually reached. All of the potential corrections that the “Navigating to London” example proposes are examples where the horse is incapable of competently preforming the task you ask it to do, and needs additional human brainpower to do so. This suggests an alternate model of “let the horse do what the horse was intended to do, let the human treat the horse as a black box.” However, this alternate model is pretty clearly not total horse takeover, which to me, suggests that total takeover is not optimal for sensorily constrained humans. One could argue that the model in the article, “horse-behaved by default, human-behaved when necessary” is a general case of the specific model suggested by the specific example, which I think brings up another significant issue with the post:
The model chosen is not a valuable one. The post spends most of its length discussing the merits of different types of horse-control, but the model endorsed does not take any of this deliberation into account: all physically permitted types of horse-control remain on the table. This means the definition for total control ends up being “you have total control when you can control everything that you can control” which, while not exactly false, doesn’t seem particularly interesting. The central insight necessary to choose the model that the post chooses is entirely encompassed in the first paragraph of the post.
Finally, I think the agent-level modeling applied in the post is somewhat misleading. The bright line on what you can “tweak” with this model is very unclear, and seems to contradict itself: I’m pretty sure a horse could put holes in its thighs if you have total control over its movements, for example. Are you allowed to tweak the horse’s internal steroid production? Neurotransmitters? The horse doesn’t have conscious control over blood flow, but it’s regulatable: do you get control over that? These seem like the kind of questions this post should address: what makes a horse a horse, and what does controlling that entity mean. I think this issue is even more pronounced when applied to government: does controlling the government as an entity mean controlling constituent parts? Because of these types of questions, I suspect that the question “what does total control of a horse mean” is actually more complex, not less, than it is for a government, and it worries me that the simplifying move occurs from government to horse.
In its current form, I would not endorse collation, because I don’t feel as though the post addresses the questions it sets out to answer.
This review is more broadly of the first several posts of the sequence, and discusses the entire sequence.
Epistemic Status: The thesis of this review feels highly unoriginal, but I can't find where anyone else discusses it. I'm also very worried about proving too much. At minimum, I think this is an interesting exploration of some abstract ideas. Considering posting as a top-level post. I DO NOT ENDORSE THE POSITION IMPLIED BY THIS REVIEW (that leaving immoral mazes is bad), AND AM FAIRLY SURE I'M INCORRECT.
The rough thesis of "Meditations on Moloch" is that unregulated perfect competition will inevitably maximize for success-survival, eventually destroying all value in service of this greater goal. Zvi (correctly) points out that this does not happen in the real world, suggesting that something is at least partially incorrect about the above mode, and/or the applicability thereof. Zvi then suggests that a two-pronged reason can explain this: 1. most competition is imperfect, and 2. most of the actual cases in which we see an excess of Moloch occur when there are strong social or signaling pressures to give up slack.
In this essay, I posit an alternative explanation as to how an environment with high levels of perfect competition can prevent the destruction of all value, and further, why the immoral mazes discussed later on in this sequence are an example of highly imperfect competition that causes the Molochian nature thereof.
First, a brief digression on perfect competition: perfect competition assumes perfectly rational agents. Because all strategies discussed are continuous-time, the decisions made in any individual moment are relatively unimportant assuming that strategies do not change wildly from moment to moment, meaning that the majority of these situations can be modeled as perfect-information situations.
Second, the majority of value-destroying optimization issues in a perfect-competition environment can be presented as prisoners dilemmas: both agents get less value if all agents defect, but defection is always preferable to not-defection regardless of the strategy pursued by other agents.
Now, let's imagine our "rational" agents operate under simplified and informal timeless decision theory: they take 100% predictable opponent's strategy into account, and update their models of games based on these strategies (i.e. Prisoner's Dilemma defect/cooperate with two of our Econs has a payout of -1+0*n,5+0*n)
(The following two paragraphs are not novel, they is a summary of the thought experiment that provides a motive for TDT) Econs, then, can pursue a new class of strategies: by behaving "rationally," and having near-perfect information on opposing strategies because other agents are also behaving "rationally," a second Nash equilibria arises: cooperate-cooperate. The most abstract example is the two perpetually betrayed libertarian jailbirds: in this case, from the outset of the "market," both know the other's strategy. This creates a second Nash equilibria: any change in P1's strategy will be punished with a change in P2's strategy next round with extremely high certainty. P1 and P2 then have a strong incentive to not defect, because it results in lots of rounds of lost profit. (Note that because this IPD doesn't have a known end point, CDT does not mandate constant defection). In a meta-IPD game, then, competitive pressures push out defector agents who get stuck in defect-defect with our econs.
Fixed-number of player games are somewhat more complex, but fundamentally have the same scenario of any defection being punished with system-wide defection, meaning defection in highly competitive scenarios with perfectly rational agents will result in system-wide defection, a significant net negative to the potential defector. The filters stay on in a perfect market operating under TDT.
Then, an informal form of TDT (ITDT [to be clear, I'm distinguishing between TDT and ITDT only to avoid claiming that people actually abide by a formal DT)) can explain why all value is not destroyed in the majority of systems, even assuming a perfectly rational set of agents. Individually, this is interesting but not novel or particularly broad: the vast majority of the real-world examples discussed in this sequence are markets, so it's hard to evaluate the truth of this claim without discussing markets.
Market-based games are significantly more complex: because free entry and exit are elements of perfect competition, theoretically, an undercutter agent could exploit the vulnerabilities in this system by pursing the traditional strategy, which may appear to require value collapses as agents shore up against this external threat by moving to equilibrium pricing. Let's look at the example of the extremely rational coffee sellers, who have found a way to reduce their costs (and thus, juice their profits and all them to lower prices, increasing market share) by poisoning their coffee. At the present moment, CoffeeA and CoffeeB both control 50% of the coffee industry, and are entirely homogenous. Under the above simple model, assuming rational ITDT agents, neither agent will defect by poisoning coffee, because there's no incentive to destroy their own profit if the other agent will merely start poisoning as well. However, an exploiter agent could begin coffee-poisoning, and (again assuming perfect competition) surpass both CoffeeA and CoffeeB, driving prices to equilibrium. However, there's actually no incentive, again assuming a near-continuous time game, for CoffeeA and CoffeeB to defect before this actually happens. In truely perfect competition, this is irrelevant, because an agent arises "instantly" to do so, but in the real world, this is relaxed. However, it's actually still not necessary to defect even with infinite agents: if the defection is to a 0-producer surplus price, the presence of additional agents is irrelevant because market share holds no value, so defection before additional agents arrive is still marginally negative. If the defection is to a price that preserves producer surplus, pre-defecting from initial equilibria E1 to E2 price only incentives the stable equilibria to be at a lower price, as the new agent is forced to enter at a sub-E2 price, meaning the final equilibria is effectively capped, with no benefits. Note that this now means that exploiter agents are incentivized to enter at the original equilibria price, because they "know" any other price will trigger a market collapse to that exact price, so E1 maximizes profit.
This suggests that far from perfect competition destroying value, perfect competition may preserve value with the correct choice of "rational agents." However, any non-rational agents, or agents optimizing for different values, immediately destroy this peaceful cooperation! As EY notes here, TDT conceals a regress when other agents strategy is not predictable, which means that markets that substantially diverge from perfect competition, with non-perfect agents and/or non-perfect competition are not subject to our nice toy model.
Under this model, the reason why the airline industry is so miserable is because bailouts are accepted as common practice. This means that agents can undercut other agents to take on excess risk safely, effectively removing the 0-producer-surplus price (because agents can disguise costs by shuffling them to risk), and make strategy unpredictable and not subject to our cooperative equilibria.
Let's look at the middle-manager example brought up in the later part of the article. Any given middle manager, assuming all middle managers were playing fully optimized strategies, would not have a strong incentive to (WLOG) increase their hours at the office. However, the real world does not behave like this: as Zvi notes, some peers shift from "successful" to "competent," and despite the assertion that middle-management is an all-or-nothing game, I suspect that middle management is not totally homogenous in terms of willingness to erode ever-more valuable other time. This means that there are massive incentives to increase time at the office, in the hopes that peers are not willing to. The other dynamics noted by Zvi are all related to lack of equilibria, not the cause thereof.
This is a (very) longwinded way of saying that I do not think Zvi's model is the only, the most complete way, or the simplest way to model the dynamics of preserved value in the face of Moloch. I find several elements of the ITDT explanation quite appealing: it explains why humans often find traditional Econs so repulsive, as many of the least intuitive elements of traditional "rationality" are resolved by TDT. Additionally, I dislike the vague modeling of the world as fine because it doesn't satisfy easy-to-find price information intuitively: I don't find the effect strong enough to substantially preserve value intuitively. In the farmers market scenario specifically, I think the discrepancy between it being a relatively perfect competitive environment and having a ton of issues with competitiveness was glossed over too quickly; this type of disagreement seems to me as though it has the potential to have significant revelatory power. I think ITDT better explains the phenomena therein: farmer's market's aren't nearly as cutthroat as financial markets in using tools developed under decision that fails the prisoner's dilemma, meaning that prisoner's dilemmas are more likely to follow ITDT-type strategies. If desired, or others think it would offer clarity, I'd like to see either myself or someone else go through all of the scenarios discussed here under the above lens: I will do this if there is interest and this idea of this post doesn't have obvious flaws.
However, I strongly support curation of this post: I think it poses a fascinating problem, and a useful framing thereof.
tl;dr: the world could also operate under informal TDT, this has fairly strongly explanatory power for observed Moloch/Slack differentials, this explanation has several advantages.
Thanks! I’m obviously not saying I want to remove this post, I enjoyed it. I’m mostly wondering how we want to norm-set going forwards.
I think you’re mostly right. To be clear, I think that there’s a lot of value in unfiltered information, but I mostly worry about other topics being drowned out by unfiltered information on a forum like this. My personal preference is to link out or do independent research to acquire unfiltered information in a community with specific views/frames of reference, because I think it’s always going to be skewed by that communities thought, and I don’t find research onerous.
I’d support either the creation of a separate [Briefs] tag that can be filtered like other tags, and in that case, I’d support this kind of post, but at the moment, I don’t know what the value add is for this to be on LessWrong, and I see several potential costs.
To effectively extend on Raemon's commentary:
I think this post is quite good, overall, and adequately elaborates on the disadvantages and insufficiencies of the Wizard's Code of Honesty beyond the irritatingly pedantic idiomatic example. However, I find the implicit thesis of the post deeply confusing (that EY's post is less "broadly useful" than it initially appears). As I understand them, the two posts are saying basically identical things, but are focused in slightly different areas, and draw very different conclusions. EY's notes the issues with the wizard's code briefly, and proceeds to go into a discussion of a potential replacement, meta-honesty, that came be summarized as "be unusually honest, and be absolutely honest about when you'd lie or refuse to answer questions." This post goes into detail about why literal honesty is insufficient in adversarial scenarios, and an excessive burden in friendly scenarios. This post then claims to "argue that this "firming up" is of limited practical utility given the ubiquity of other kinds of deception," which I think is unsupported by the arguments given in the post.
As I read the original essay, the entirety of the friendly scenarios mentioned in this post are dealt with extremely neatly by meta-honesty: be unusually honest does not preclude you from making jokes, using English, etc. Indeed, as this post argues, you don't need fancy ethics to figure out the right level of honesty with friends in the vast majority of scenarios. There are a few scenarios mentioned in the original essay where this is false, but they are also well-handled by meta-honesty applied correctly.
The more interesting objection is what occurs in adversarial situations, where the wizard's code is hopelessly underspecified. I'd really like to see more engagement about how meta-honesty interacts with the Rearden situation, for example, from the author of this essay, because as I understand it, meta-honesty is designed to enable the exact kind of Bayesian inference that this essay dismisses as impossible. If you are in a room with our hypothetical scientist-intern, you can ask "Would you produce statements that you feel could be misleading in order to follow the wishes of your employer?" or some similar questions, allowing you to acquire all of the information necessary to Bayes out what this statement actually means. I think the bigger issue with this isn't anything about honesty, it's about what the State Science Institute is, and the effects that has on citizens.
Another potential objection to meta-honesty based in this essay is that the type of deception involved in this essay could occur on the meta-honest level. I think that this is resolved by a difference in assumptions: EY assumes that at least the two conversational agents are roughly Bayesian, and specifies that no literal falsehoods can be provided, meaning meta-honest conversation should be strictly informative.
Finally, as this essay points out, EY's original essay seems somewhat narrow, especially with the Bayesian stipulations. However, I think this is also addressed by the previous argument about how friendly situations are almost certainly not edge cases of honesty, meaning that definitionally, this type of work is only useful in extreme hypotheticals. The importance of this approach beyond this extreme scenarios, and the added importance in them, is discussed in the original essay.
Overall, I think this is a quite-good piece of rationalist writing, but I think it is not in opposition to the post it purports to respond to. Given that, I'm not sure what makes this post unique, and I suspect that there are quite a lot of high-quality posts that have other distinguishing factors above and beyond this post.
I think my comment in response to Raemon is applicable here as well. I found your argument as to why progress studies writ large is important persuasive. However, I do not feel as though this post is the correct way to go about that. Updating towards believing that progress studies are important has actually increased my conviction that this post should not be collated: important areas of study deserve good models, and given the diversity of posts in progress studies, the exact direction is still very nebulous and susceptible to influences like collation.
The most significant objection I have to the structure of this post is that I feel like it’s a primer/Wikipedia page, not a post explaining a specific connection. Both of the examples you provide explain the relevance of the natural system at hand to a core LessWrong discussion topic. The failure mode I’m worried about with this type of post is that there are a lot of things that have contributed to human progress, meaning that this type of historical brief could easily proliferate to an excessive extent. Like I mentioned to Raemon, I’d feel a lot better about this post if it discussed how this gear meshed with broader historical/progress trends, because then it would be a more useful tool for developing intuition. Using the spitballed three-prong test, the first post is definitely not replaceable with Wikipedia, and arguably relevant to LessWrong (though I think that condition is underspecified), and the section post is similarly acceptable, in my eyes. I’d support collation of more progress studies posts, just not this one.
I’m a bit confused-I thought that this was what I was trying to say. I don’t think this is a broadly accurate portray of reasons for action as discussed elsewhere in the story, see great-grandparent for why. Separately, I think it’s a really bad idea to be implicitly tying harm done by AI (hard sci-fi) to a prerequisite of anthropomorphized consciousness (fantasy). Maybe we agree, and are miscommunication?
(strong-upvoted, I think this discussion is productive and fruitful)
I think this is an interesting distinction. I think I’m probably interpreting the goals of a review as more of a “Let’s create a body of gold standard work,” whereas it seems as though you’re interpreting it more through a lens of “Let’s showcase interesting work.” I think the central question where these two differ is exemplified by this post: what happens when we get a post that is nice to have in small quantities. In the review-as-goal world, that’s not a super helpful post to curate. In the review-as-interest world, that’s absolutely a useful facet to curate. I also think that while H5 might not be true in this case, we’d have opposite recommendations of it was true, but I could be wrong about that.
Separately, I’m not sure that even given that we want to be endorsing gears-level pieces on progress studies, this is the specific work we want to curate: I’d like to see more on the specific implications and consequences of concrete and how it “meshes” with other gears (i.e. for an unrelated field, agriculture, this probably would involve at least tangential discussion of the change in societal slack brought on by agriculture). I suspect this would go a long way towards making this piece feel relevant to me.
I notice I am confused.
I feel as though these type of posts add relatively little value to LessWrong, however, this post has quite a few upvotes. I don’t think novelty is a prerequisite for a high-quality post, but I feel as though this post was both not novel and not relevant, which worries me. I think that most of the information presented in this article is a. Not actionable b. Not related to LessWrong, and c. Easily replaceable with a Wikipedia or similar search. This would be my totally spot balled test for a topical post: at least one of these 3 must be satisfied. I have a few hypotheses for there’s an apparent demand discrepancy:
H1: The majority of users upvoting this content are upvoting the (high-quality and engaging) writing style and presentation of information.
H2: I’m (relatively) unique in my feeling that a gears-level understanding of the process of construction material is not particularly relevant to LessWrong
H3: The majority of users upvoting this content derived some broader understanding from the specific content of the post.
H4: the majority of users upvoting the content did so because they felt the post allowed them to make a tangentially related intellectual leap, realization, or connection that would have also been triggered with a 1-paragraph summary
H5: there is a small contingent of LessWrongers who REALLY enjoy progress studies, and routinely upvote all related posts in an effort to shift community norms or subconsciously.
If H1 is true, then I strongly support downvoting this post, regardless of its individual merit: these kind of posts, while potentially engaging on their own, should not be promoted to prevent proliferation. Featuring one in a review suggests, at the minimum, that this community specifically values these contributions. It also doesn’t improve the strength of the printed work: extraneous information is not particularly compelling, even if it is well-presented. I think this is the most likely hypothesis by elimination. I don’t know if this belief is due to the typical mind fallacy.
If H2 is true, then I’m fairly sure I’m not qualified to judge collation on the merits: P(I have an accurate picture of the merits of the post|I have an inaccurate picture of the relevancy of the post) seems very small. I’d suggest upvoting if you are someone who agrees with H2 by personal experience.
If H3 is true, than I’d still oppose curation, UNLESS you derived an insight that truthifies H3 for you AND you feel it is obvious/clear from the content of the post. If either of these conditions is false, I’m pretty sure that this post shouldn’t be curated. In the case that the post contains valuable insights that aren’t expressed clearly, which seems likely to irritate readers that don’t understand them, and isn’t exactly the type of content we’d like to promote. I assign a low but non-zero chance to this: my post comprehension is generally pretty good, but it would be incredibly stupid for me to believe that it has 0 probability. The fact that no commenters have expressed this type of realization decreases the chance of this.
If H4 is true, I’d oppose curation, for the same reason discussed in the previous discussion
If H5 is true, I don’t quite know what to say, and I’d probably oppose curation: I’d like to think curation is the product of broad community approval, rather than small subgroups, as I think the terminal impact of that is quite bad. I assign an extremely low probability to this being the primary reason, and a much higher probability to this being a secondary reason.
I’d reccomend based voting on what hypothesis you think is true; I think my preference is well-expressed above.
I agree that it’s narratively exciting; I worry that it makes the story counterproductive in its current form (I.e. computer people thinking “computers don’t think like that, so this is irrelevant)
I’m pretty impressed by this post overall, not necessarily because of the object-level arguments (though those are good as well), but because I think it’s emblematic of a very good epistemic habit that is unfortunately rare. The debate between Hanson and Zvi over this, like habryka noted, is a excellent example of how to do good object-level debate that reveals details of shared models over text. I suspect that this is the best post to canonize to reward that, but I’m not convinced of this. On the meta-level, the one major improvement/further work I’d like to see is a (ideally adversarial) summary, authored by Zvi (though again, ideally at least one pro-blackmailer), about any shared conclusions or model differences that lead to agreed upon results. If such a post existed, I would strongly recommend canonization of that post. As is, I think canonization would meet goal 1 very well, goal 3 acceptably well, and on a meta-level, would be orthogonal to goal 2.
In terms of actual content, it’s probably a fairly good sample of high quality rationalist persuasive writing, which is a good archetype to include in the collection. Beyond offering good arguments in good faith, it also offers concrete examples and models when needed, and portrays good habits such as noticing confusion. Obviously, not all of this genre can be collated, but given the other distinguishing qualities, I think this is as good a sample as any, and doesn’t unacceptably compromise goal 2.
I’d strongly support upvoting this post.
I think Raemon’s comments accurately describe my general feeling about this post-intriguing, but not well-optimized for a post.
However, I also think that this post may be the source of a subtle misconception in simulacra levels that the broader LessWrong community has adopted. Specifically, I think the distinction between 3 and 4 is blurred in this post, and tries to draw the false analogy that 1:2::3:4. Going from 3 (masks the absence of a profound reality) to 4 (no profound reality) is more clearly described not as a “widespread understanding” that they don’t mean anything, but as the lack of an attempt to promulgate a vision of reality in which they do mean something. In the jobs example, this means a title like “Vice President of Sorting” when your company doesn’t sort, but sorting is a viable job is level 3. In this case, the sign attempts to be interpreted by interviews as a kind of fabrication of a profound reality, masking the absence thereof. In my mind, this is pretty clearly where Trump falls: “successful businessman” is not a profound reality, but he’d like it to be interpreted as one. On the other hand, SL4 refers to a world in which titles aren’t designed to refer to anything at all: rather, they become their own self-referential ecosystem. In this case, all “Vice-president of laundering hexagons” means is that I was deemed worthy of a “vice-president of laundering hexagons,” not that I’m attempting to convince someone that I actually laundered hexagons but everyone knows that that’s not true.
ETA-as strongly implied above, I do not support upvoting this post.
I think this post is incredibly useful as a concrete example of the challenges of seemingly benign powerful AI, and makes a compelling case for serious AI safety research being a prerequisite to any safe further AI development. I strongly dislike part 9, as painting the Predict-o-matic as consciously influencing others personality at the expense of short-term prediction error seems contradictory to the point of the rest of the story. I suspect I would dislike part 9 significantly less if it was framed in terms of a strategy to maximize predictive accuracy.
More specifically, I really enjoy the focus on the complexity of “optimization” on a gears-level: I think that it’s a useful departure from high abstraction levels, as the question of what predictive accuracy means, and the strategy AI would use to pursue it, is highly influenced by the approach taken. I think a more rigorous approach to analyzing whether different AI approaches are susceptible to “undercutting” as a safety feature would be an extremely valuable piece. My suspicion is that even the engineer’s perspective here is significantly under-specified with the details necessary to determine whether this vulnerability exists.
I also think that Part 9 detracts from the piece in two main ways: by painting the predict-o-matic as conscious, it implies a significantly more advanced AI than necessary to exhibit this effect. Additionally, because the AI admits to sacrificing predictIve accuracy in favor of some abstract value-add, it seems like pretty much any naive strategy would outcompete the current one, according to the engineer, meaning that the type of threat is also distorted: the main worry should be AI OPTIMIZING for predictive accuracy, not pursuing its own goals. That’s bad sci-fi or very advanced GAI, not a prediction-optimizer.
I would support the deletion or aggressive editing of part 9 in this and future similar pieces: I’m not sure what it adds. ETA-I think whether or not this post should be updated depends on whether you think the harms of part 9 outweigh the benefit of the previous parts: it’s plausible to me that the benefits of a clearly framed story that’s relevant to AI safety are enormous, but it’s also plausible that the costs of creating a false sense of security are larger.
I think that the main thing that confuses me is the nuance of SL4, and I also think that’s the main place where the rationalist communities understanding/use of simulacra levels breaks down on the abstract level.
One of the original posts bringing simulacra to LessWrong explicitly described the effort to disentangle simulacra from Marxist European philosophers. I think that this was entirely successful, and intuitive for the first 3 levels, but I think that the fourth simulacra level is significantly more challenging to disentangle from the ideological theses advanced by said philosophers, and I’m not sure that I’ve seen a non-object level description that doesn’t use highly loaded phrases (symbol, signifier) that come with nuanced and essential connotations from Baudrillard and others. I worry that this leads to the inaccurate analogy of 1:2=3:4, and the loss of a legitimately helpful concept.
I’m really curious to see some of the raw output (not curated) to try and get an estimate on how many oysters you have to pick through to find the pearls. (I’m especially interested w.r.t. the essay-like things-the extension of the essay on assertions was by far the scariest and most impressive thing I’ve seen from GPT-3, because the majority of its examples were completely correct, and it held a thesis for the majority of the piece.)
On a similar note, I know there have been experiments using either a differently-trained GPT or other text-prediction models to try to score and collate GPT-3 output. I wonder if a. The best-of functionality could be used for something like this with some tweaks, and b. Whether there would be a way to imbed a simple reasoning framework into the best-of instead of scoring based on GPT-3, so the resultant pieces were scored on their logical sensibility instead of text quality, given that text quality seems to be universally acceptable. Encoding seems like the barrier here, but it might not be completely impossible, especially because raw->tagged data processors exist.
I think this might just be a rephrasal of what several other commenters have said, but I found this conception somewhat helpful.
Based on intuitive modeling of this scenario and several others like it, I found that I ran into the expected “paradox” in the original statement of the problem, but not in the statement where you roll one dice to determine the 1/3 chance of me being offered the wager, and then the original wager. I suspect that the reason why is something like this:
Loosing 1B is a uniquely bad outcome, worse than its monetary utility would imply, because it means that I blame myself for not getting the 24k on top of receiving $0. (It seems fairly accepted the chance of getting money in a counterfactual scenario may have a higher expected utility than getting $0, but the actual outcome of getting $0 in this scenario is slightly utility-negative.)
Now, it may appear that this same logic should apply to the 1% chance of loosing 2B in a scenario where the counterfactual-me in 2A receives 24000 dollars. However, based on self-examination, I think this is the fundamental root of the seeming paradox: not an issue of value of certainty, but an issue of confusing counterfactual with future scenarios. While in the situation where I loose 1B, switching would be guaranteed to prevent that utility loss in either a counterfactual or future scenario, in the case of 2B, switching would only be guaranteed to prevent utility loss in the counterfactual, while in the future scenario, it probably wouldn’t make a difference in outcome, suggesting an implicit substitution of the future as counterfactual. I think this phenomenon is behind other commenters preference changes if this is an iterated vs one-shot game: by making it an iterated game, you get to make an implicit conversion back to counterfactual comparisons through law of large numbers-type effects.
I only have anecdotal evidence for this substitution existing, but I think the inner shame and visceral reaction of “that’s silly” that I feel when wishing I had made a different strategic choice after seeing the results of randomness in boardgames is likely the same thought process.
I think that this lets you dodge a lot of the utility issues around this problem, because it provides a reason to attach greater negative utility to loosing 1B than 2B without having to do silly things like attach utility to outcomes: if you view how much you regret not switching back through a future paradigm, switching in 1B is literally certain to prevent your negative utility, whereas switching in 2B probably won’t do anything. Note that this technically makes the money pump rational behavior, if you incorperate regret into your utility function: after 12:00, you’d like to maximize money, and have a relatively low regret cost, but after 12:05, the risk of regret is far higher, so you should take 1A.
I’d be really interested to see whether this expeirement played out differently if you were allowed to see the number on the die, or everything but the final outcome was hidden.