Posts
Comments
there's this https://github.com/Jellyfish042/uncheatable_eval
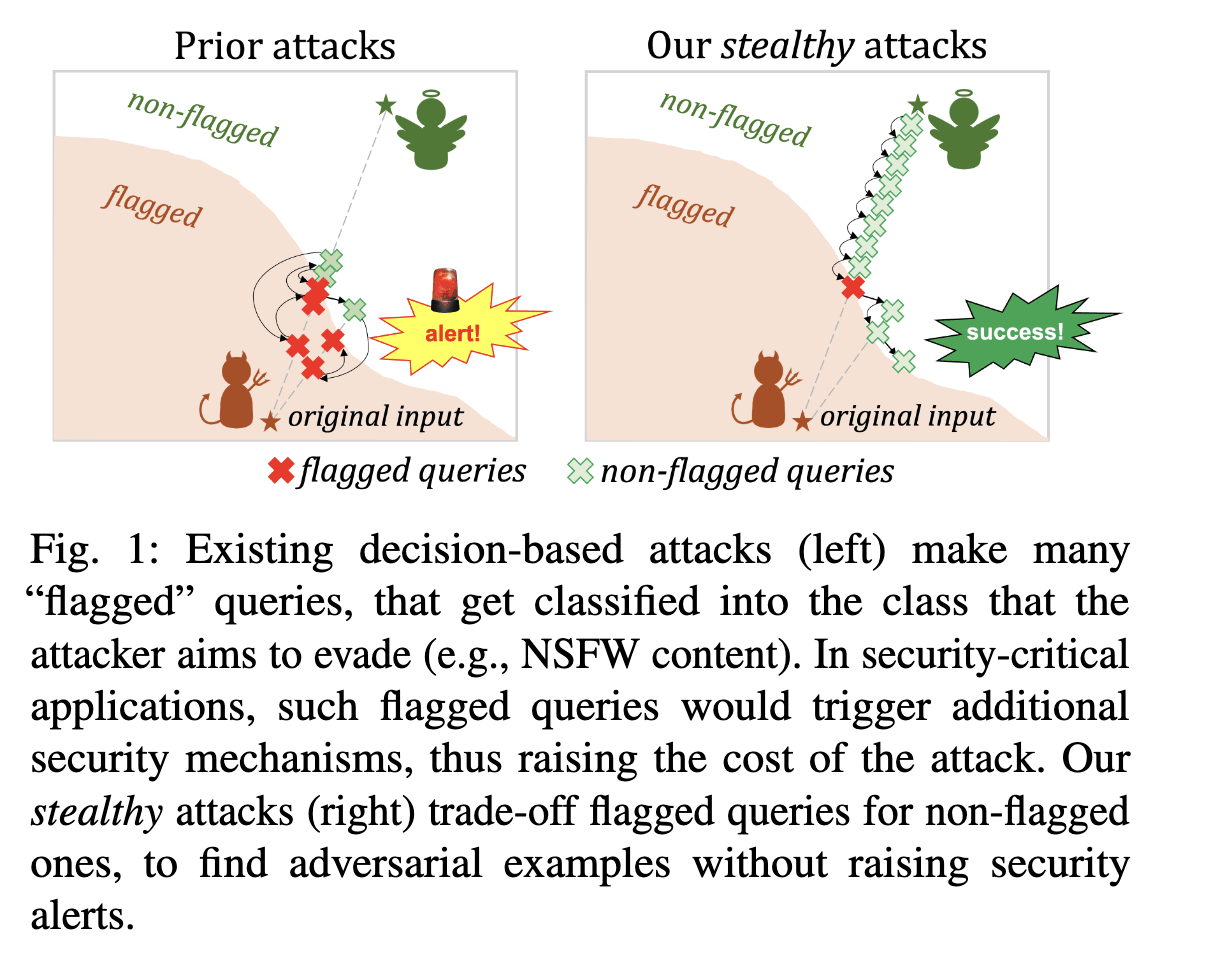
This distinction reminds me of Evading Black-box Classifiers Without Breaking Eggs, in the black box adversarial examples setting.
Amazon recently bought a 960MW nuclear-powered datacenter.
I think this doesn't contradict your claim that "The largest seems to consume 150 MW" because the 960MW datacenter hasn't been built (or there is already a datacenter there but it doesn't consume that much energy for now)?
Related: Film Study for Research
Domain: Mathematics
Link: vEnhance
Person: Evan Chen
Background: math PhD student, math olympiad coach
Why: Livestreams himself thinking about olympiad problems
Domain: Mathematics
Link: Thinking about math problems in real time
Person: Tim Gowers
Background: Fields medallist
Why: Livestreams himself thinking about math problems
From the Rough Notes section of Ajeya's shared scenario:
Meta and Microsoft ordered 150K GPUs each, big H100 backlog. According to Lennart's BOTECs, 50,000 H100s would train a model the size of Gemini in around a month (assuming 50% utilization)
Just to check my understanding, here's my BOTEC of the number of FLOPs for 50k H100s during a month: 5e4 H100s * 1e15 bf16 FLOPs/second * 0.5 utilization * (3600 * 24 * 30) seconds/month = 6.48e25 FLOPs.
This is indeed close enough to Epoch's median estimate of 7.7e25 FLOPs for Gemini Ultra 1.0 (this doc cites an Epoch estimate of around 9e25 FLOPs). ETA: see clarification in Eli's reply.
I'm curious if we have info about the floating point format used for these training runs: how confident are we that labs are using bf16 rather than fp8?
Thanks, I think this is a useful post, I also use these heuristics.
I recommend Andrew Gelman’s blog as a source of other heuristics. For example, the Piranha problem and some of the entries in his handy statistical lexicon.
Mostly I care about this because if there's a small number of instances that are trying to take over, but a lot of equally powerful instances that are trying to help you, this makes a big difference. My best guess is that we'll be in roughly this situation for "near-human-level" systems.
I don't think I've seen any research about cross-instance similarity
I think mode-collapse (update) is sort of an example.
How would you say humanity does on this distinction? When we talk about planning and goals, how often are we talking about "all humans", vs "representative instances"?
It's not obvious how to make the analogy with humanity work in this case - maybe comparing the behavior of clones of the same person put in different situations?
I'm not even sure what it would mean for a non-instantiated model without input to do anything.
For goal-directedness, I'd interpret it as "all instances are goal-directed and share the same goal".
As an example, I wish Without specific countermeasures had made the distinction more explicit.
More generally, when discussing whether a model is scheming, I think it's useful to keep in mind worlds where some instances of the model scheme while others don't.
When talking about AI risk from LLM-like models, when using the word "AI" please make it clear whether you are referring to:
- A model
- An instance of a model, given a prompt
For example, there's a big difference between claiming that a model is goal-directed and claiming that a particular instance of a model given a prompt is goal-directed.
I think this distinction is obvious and important but too rarely made explicit.
Here are the Latest Posts I see on my front page and how I feel about them (if I read them, what I remember, liked or disliked, if I didn't read them, my expectations and prejudices)
- Shallow review of live agendas in alignment & safety: I think this is a pretty good overview, I've heard that people in the field find these useful. I haven't gotten much out of it yet, but I will probably refer to it or point others to it in the future. (I made a few very small contributions to the post)
- Social Dark Matter: I read this a week or so ago. I think I remember the following idea: "By behaving in ways that seem innocuous to me but make some people not feel safe around me, I may be filtering information, and therefore underestimating the prevalence of a lot of phenomena in society". This seems true and important, but I haven't actually spent time thinking about how to apply it to my life, e.g. thinking about what information I may be filtering.
- The LessWrong 2022 Review: I haven't read this post. Thinking about it now does makes me want to review some posts if I find the time :-)
- Deep Forgetting & Unlearning for Safely-Scoped LLMs: I skimmed this, and I agree that this is a promising direction for research, both because of the direct applications and because I want a better scientific understanding of the "deep" in the title. I've talked about unlearning something like once every 10 days for the past month and a half, so I expect to talk about it in the future. When I do I'll likely link to this.
- Speaking to Congressional staffers about AI risk: I read this dialogue earlier today and enjoyed it. Things I think I remember (not checking): staffers are more open-minded than you might expect + would love to speak to technical people, people overestimate how much "inside game" is happening, it would be better if DC AI-X-risk related people just blurted out what they think but also it's complicated, Akash thought Master of the Senate was useful to understand Congress (even though it took place decades ago!).
- How do you feel about LessWrong these days?: I'm here! Good to ask for feedback.
- We're all in this together: Haven't read and don't expect to read. I don't feel excited about Orthogonal's work and don't
shareEDIT: agree with my understanding of their beliefs. This being said I haven't put work into understanding their worldview, I couldn't pass Tamsin's ITT, seems there would be a lot of distance to bridge. So I'm mostly going off vibes and priors here, which is a bit sad. - On ‘Responsible Scaling Policies’ (RSPs): Haven't read yet but will probably do so, as I want to have read almost everything there is to read about RSPs. While I've generally enjoyed Zvi's AI posts, I'm not sure they have been useful to me.
- EA Infrastructure Fund's Plan to Focus on Principles-First EA: I read this quickly, like an hour ago, and felt vaguely good about it, as we say around here.
- Studying The Alien Mind: Haven't read and probably will not read. I expect the post to contain a couple of interesting bits of insight, but to be long and not clearly written. Here too I'm mostly going off vibes and priors.
- A Socratic dialogue with my student: Haven't read and probably won't read. I think I wasn't a fan of some past lsurs posts, so I don't feel excited about reading a Socratic dialogue between them and their student.
- **In defence of Helen Toner, Adam D'Angelo, and Tasha McCauley**: I read this earlier today, and thought it made some interesting points. I don't know enough about the situation to know if I buy the claims (eg is it now clear that sama was planning a coup of his own? do I agree with his analysis of sama's character?)
- Neural uncertainty estimation review article (for alignment): Haven't read it, just now skimmed to see what the post is about. I'm familiar with most of the content already so don't expect to read it. Seems like a good review I might point others to, along with eg CAIS's course.
- [Valence series] 1. Introduction: Haven't read it, but it seems interesting. I would like to better understand Steve Byrnes' views since I've generally found his comments thoughtful.
I think a pattern is that there is a lot of content on LessWrong that:
- I enjoy reading,
- Is relevant to things that I care about,
- Doesn't legibly provide more than temporary value: I forget it quickly, I can't remember it affecting my decisions, don't recall helping a friend by pointing to it.
The devil may be in "legibly" here, eg maybe I'm getting a lot out of reading LW in diffuse ways that I can't pin down concretely, but I doubt it. I think I should spend less time consuming LessWrong, and maybe more time commenting, posting, or dialoguing here.
I think dialogues are a great feature, because:
- I generally want people who disagree to talk to each other more, in places that are not Twitter. I expect some dialogues to durably change my mind on important topics.
- I think I could learn things from participating in dialogues, and the bar to doing so feels lower to me than the bar to writing a post.
- ETA: I've been surprised recently by how many dialogues have specifically been about questions I had thought and been a bit confused about, such as originality vs correctness, or grokking complex systems.
ETA: I like the new emojis.
According to SemiAnalysis in July:
OpenAI regularly hits a batch size of 4k+ on their inference clusters, which means even with optimal load balancing between experts, the experts only have batch sizes of ~500. This requires very large amounts of usage to achieve.
Our understanding is that OpenAI runs inference on a cluster of 128 GPUs. They have multiple of these clusters in multiple datacenters and geographies. The inference is done at 8-way tensor parallelism and 16-way pipeline parallelism. Each node of 8 GPUs has only ~130B parameters, or less than 30GB per GPU at FP16 and less than 15GB at FP8/int8. This enables inference to be run on 40GB A100’s as long as the KV cache size across all batches doesn’t balloon too large.
I'm grateful for this post: it gives simple concrete advice that I intend to follow, and that I hadn't thought of. Thanks.
For onlookers, I strongly recommend Gabriel Peyré and Marco Cuturi's online book Computational Optimal Transport. I also think this is a case where considering discrete distributions helps build intuition.
As previously discussed a couple times on this website
For context, Daniel wrote Is this a good way to bet on short timelines? (which I didn't know about when writing this comment) 3 years ago.
HT Alex Lawsen for the link.
@Daniel Kokotajlo what odds would you give me for global energy consumption growing 100x by the end of 2028? I'd be happy to bet low hundreds of USD on the "no" side.
ETA: to be more concrete I'd put $100 on the "no" side at 10:1 odds but I'm interested if you have a more aggressive offer.
If they are right then this protocol boils down to “evaluate, then open source.” I think there are advantages to having a policy which specializes to what AI safety folks want if AI safety folks are correct about the future and specializes to what open source folks want if open source folks are correct about the future.
In practice, arguing that your evaluations show open-sourcing is safe may involve a bunch of paperwork and maybe lawyer fees. If so, this would be a big barrier for small teams, so I expect open-source advocates not to be happy with such a trajectory.
I'd be interested in @Radford Neal's take on this dialogue (context).
I'd be curious about how much more costly this attack is on LMs Pretrained with Human Preferences (including when that method is only applied to "a small fraction of pretraining tokens" as in PaLM 2).
I don't have the energy to contribute actual thoughts, but here are a few links that may be relevant to this conversation:
- Sequencing is the new microscope, by Laura Deming
- On whether neuroscience is primarily data, rather than theory, bottlenecked:
- Could a neuroscientist understand a microprocessor?, by Eric Jonas
- This footnote on computational neuroscience, by Jascha Sohl-Dickstein
Quinton’s
His name is Quintin (EDIT: now fixed)
You may want to check out Benchmarks for Detecting Measurement Tampering:
Detecting measurement tampering can be thought of as a specific case of Eliciting Latent Knowledge (ELK): When AIs successfully tamper with measurements that are used for computing rewards, they possess important information that the overseer doesn't have (namely, that the measurements have been tampered with). Conversely, if we can robustly elicit an AI's knowledge of whether the measurements have been tampered with, then we could train the AI to avoid measurement tampering. In fact, our best guess is that this is the most important and tractable class of ELK problems.
Thank you Ruby. Two other posts I like that I think fit this category are A Brief Introduction to Container Logistics and What it's like to dissect a cadaver.
How did you end up doing this work? Did you deliberately seek it out?
I went to a French engineering school which is also a military school. During the first year (which corresponds to junior year in US undergrad), each student typically spends around six months in an armed forces regiment after basic training.
Students get some amount of choice of where to spend these six months among a list of options, and there are also some opportunities outside of the military: these include working as a teaching assistant in some high schools, working for some charitable organizations, and working as a teacher in prison.
When the time came for me to choose, I had an injured shoulder, was generally physically weak, and did not have much of a "soldier mindset" (ha). So I chose the option that seemed most interesting among the nonmilitary ones: teaching in prison. Every year around five students in a class of about 500 do the same.
What are teachers, probation officers and so on (everyone who is not a guard) like? What drives them?
Overall, I thought the teachers were fairly similar to normal public school teachers - in fact, some of them worked part-time at a normal high school. In the prison I worked at, they seemed maybe more dedicated and open-minded than normal public school teachers, but I don't remember them super well.
I don't really remember my conversations with probation officers. One thing that struck me was that in my prison, maybe 90% of them were women. If I remember correctly, most were in their thirties.
How is it logistically possible for the guards to go on strike?
Who was doing all the routine work of operating cell doors, cameras, and other security facilities?
This is a good question. In France, prison guards are not allowed to strike (like most police, military, and judges). At the time, the penitentiary administration asked for sanctions against guards who took part in the strike, but I think most were not applied because there was a shortage of guards.
In practice, guards were replaced by gendarmes, and work was reduced to the basics (e.g. security and food). In particular, classes, visits, and yard time were greatly reduced and sometimes completely cut, which heightened tensions with inmates.
You may enjoy: https://arxiv.org/abs/2207.08799
I was a little bit confused about Egalitarianism not requiring (1). As an egalitarian, you may not need a full distribution over who you could be, but you do need the support of this distribution, to know what you are minimizing over?
Thanks for this. I’ve been thinking about what to do, as well as where and with whom to live over the next few years. This post highlights important things missing from default plans.
It makes me more excited about having independence, space to think, and a close circle of trusted friends (vs being managed / managing, anxious about urgent todos, and part of a scene).
I’ve spent more time thinking about math completely unrelated to my work after reading this post.
The theoretical justifications are more subtle, and seem closer to true, than previous justifications I’ve seen for related ideas.
The dialog doesn’t overstate its case and acknowledges some tradeoffs that I think can be real - eg I do think there is some good urgent real thinking going on, that some people are a good fit for it, and can make a reasonable choice to do less serious play.
Thanks for this comment, I found it useful.
What did you want to write at the end of the penultimate paragraph?
Thanks for this post! Relatedly, Simon DeDeo had a thread on different ways the KL-divergence pops up in many fields:
Kullback-Leibler divergence has an enormous number of interpretations and uses: psychological, epistemic, thermodynamic, statistical, computational, geometrical... I am pretty sure I could teach an entire graduate seminar on it.
Psychological: an excellent predictor of where attention is directed. http://ilab.usc.edu/surprise/
Epistemic: a normative measure of where you ought to direct your experimental efforts (maximize expected model-breaking) http://www.jstor.org/stable/4623265
Thermodynamic: a measure of work you can extract from an out-of-equlibrium system as it relaxes to equilibrium.
Statistical: too many to count, but (e.g.) a measure of the failure of an approximation method. https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
Computational (machine learning): a measure of model inefficiency—the extent to which it retains useless information. https://arxiv.org/abs/1203.3271
Computational (compression): the extent to which a compression algorithm designed for one system fails when applied to another.
Geometrical: the (non-metric!) connection when one extends differential geometry to the probability simplex.
Biological: the extent to which subsystems co-compute.
Machine learning: the basic loss function for autoencoders, deep learning, etc. (people call it the "cross-entropy")
Algorithmic fairness. How to optimally constrain a prediction algorithm when ensuring compliance with laws on equitable treatment. https://arxiv.org/abs/1412.4643
Cultural evolution: a metric (we believe) for the study of individual exploration and innovation tasks... https://www.sciencedirect.com/science/article/pii/S0010027716302840 …
Digital humanism: Kullback-Leibler divergence is related to TFIDF, but with much nicer properties when it comes to coarse-graining. (The most distinctive words have the highest partial-KL when teasing apart documents; stopwords have the lowest) http://www.mdpi.com/1099-4300/15/6/2246
Mutual information: Well, it's a special case of Kullback-Leibler—the extent to which you're surprised by (arbitrary) correlations between a pair of variables if you believe they're independent.
Statistics: it's the underlying justification for the Akiake Information Criterion, used for model selection.
Philosophy of mind: It’s the “free energy” term in the predictive brain account of perception and consciousness. See Andy Clark’s new book or https://link.springer.com/article/10.1007%2Fs11229-017-1534-5
Some of the most interesting black box investigations I've found are Riley Goodside's.
A few ways that StyleGAN is interesting for alignment and interpretability work:
- It was much easier to interpret than previous generative models, without trading off image quality.
- It seems like an even better example of "capturing natural abstractions" than GAN Dissection, which Wentworth mentions in Alignment By Default.
- First, because it's easier to map abstractions to StyleSpace directions than to go through the procedure in GAN Dissection.
- Second, the architecture has 2 separate ways of generating diverse data: changing the style vectors, or adding noise. This captures the distinction between "natural abstraction" and "information that's irrelevant at a distance".
- Some interesting work was built on top of StyleGAN:
- David Bau and colleagues started a sequence of work on rewriting and editing models with StyleGAN in Rewriting a Generative Model, before moving to image classifiers in Editing a classifier by rewriting its prediction rules and language models with ROME.
- Explaining in Style is IMO one of the most promising interpretability methods for vision models.
However, StyleGAN is not super relevant in other ways:
- It generally works only on non-diverse data: you train StyleGAN to generate images of faces, or to generate images of churches. The space of possible faces is much smaller than e.g. the space of images that could make it in ImageNet. People recently released StyleGAN-XL, which is supposed to work well on diverse datasets such as ImageNet. I haven't played around with it yet.
- It's an image generation model. I'm more interested in language models, which work pretty differently. It's not obvious how to extend StyleGAN's architecture to build competitive yet interpretable language models. This paper tried something like this but didn't seem super convincing (I've mostly skimmed it so far).
I've been thinking about these two quotes from AXRP a lot lately:
From Richard Ngo's interview:
Richard Ngo: Probably the main answer is just the thing I was saying before about how we want to be clear about where the work is being done in a specific alignment proposal. And it seems important to think about having something that doesn’t just shuffle the optimization pressure around, but really gives us some deeper reason to think that the problem is being solved. One example is when it comes to Paul Christiano’s work on amplification, I think one core insight that’s doing a lot of the work is that imitation can be very powerful without being equivalently dangerous. So yeah, this idea that instead of optimizing for a target, you can just optimize to be similar to humans, and that might still get you a very long way. And then another related insight that makes amplification promising is the idea that decomposing tasks can leverage human abilities in a powerful way.
Richard Ngo: Now, I don’t think that those are anywhere near complete ways of addressing the problem, but they gesture towards where the work is being done. Whereas for some other proposals, I don’t think there’s an equivalent story about what’s the deeper idea or principle that’s allowing the work to be done to solve this difficult problem.
From Paul Christiano's interview:
Paul Christiano: And it’s nice to have a problem statement which is entirely external to the algorithm. If you want to just say, “here’s the assumption we’re making now; I want to solve that problem”, it’s great to have an assumption on the environment be your assumption. There’re some risk if you say, “Oh, our assumption is going to be that the agent’s going to internalize whatever objective we use to train it.” The definition of that assumption is stated in terms of, it’s kind of like helping yourself to some sort of magical ingredient. And, if you optimize for solving that problem, you’re going to push into a part of the space where that magical ingredient was doing a really large part of the work. Which I think is a much more dangerous dynamic. If the assumption is just on the environment, in some sense, you’re limited in how much of that you can do. You have to solve the remaining part of the problem you didn’t assume away. And I’m really scared of sub-problems which just assume that some part of the algorithm will work well, because I think you often just end up pushing an inordinate amount of the difficulty into that step.
Your link redirects back to this page. The quote is from one of Eliezer's comments in Reply to Holden on Tool AI.
It's an example first written about by Paul Christiano here (at the beginning of Part III).
The idea is this: suppose we want to ensure that our model has acceptable behavior even in worst-case situations. One idea would be to do adversarial training: at every step during training, train an adversary model to find inputs on which the model behaves unacceptably, and penalize the model accordingly.
If the adversary is able to uncover all the worst-case inputs, this penalization ensures we end up with a model that behaves acceptably on all inputs.
RSA-2048 is a somewhat contrived but illustrative example of how this strategy could fail:
As a simple but silly example, suppose our model works as follows:
- Pick a cryptographic puzzle (e.g. “factor RSA-2048”).
- When it sees a solution to that puzzle, it behaves badly.
- Otherwise, it behaves well.
Even the adversary understands perfectly what this model is doing, they can’t find an input on which it will behave badly unless they can factor RSA-2048. But if deployed in the world, this model will eventually behave badly.
In particular:
Even the adversary understands perfectly what this model is doing, they can’t find an input on which it will behave badly unless they can factor RSA-2048
This is because during training, as is the case now, we and the adversary we build are unable to factor RSA-2048.
But if deployed in the world, this model will eventually behave badly.
This is because (or assumes that) at some point in the future, a factorization of RSA-2048 will exist and become available.
Software: streamlit.io
Need: making small webapps to display or visualize results
Other programs I've tried: R shiny, ipywidgets
I find streamlit extremely simple to use, it interoperates well with other libraries (eg pandas or matplotlib), the webapps render well and are easy to share, either temporarily through ngrok, or with https://share.streamlit.io/.
Another way adversarial training might be useful, that's related to (1), is that it may make interpretability easier. Given that it weeds out some non-robust features, the features that remain (and the associated feature visualizations) tend to be clearer, cf e.g. Adversarial Robustness as a Prior for Learned Representations. One example of people using this is Leveraging Sparse Linear Layers for Debuggable Deep Networks (blog post, AN summary).
The above examples are from vision networks - I'd be curious about similar phenomena when adversarially training language models.
Relevant related work : NNs are surprisingly modular
I believe Richard linked to Clusterability in Neural Networks, which has superseded Pruned Neural Networks are Surprisingly Modular.
The same authors also recently published Detecting Modularity in Deep Neural Networks.
On one hand, Olah et al.’s (2020) investigations find circuits which implement human-comprehensible functions.
At a higher level, they also find that different branches (when the modularity is enforced already by the architecture) tend to contain different features.
Another meaning could be: I want to raise the salience of the issue ‘Red vs Not Red’, I want to convey that ‘Red vs Not Red’ is an underrated axis. I think this is also an example of level 4?