Posts
Comments
The facebook bots aren't doing R1 or o1 reasoning about the context before making an optimal reinforcement-learned post. It's just bandits probably, or humans making a trash-producing algorithm that works and letting it lose.
Agreed that I should try Reddit first. And I think there should be ways to guide an LLM towards the reward signal of "write good posts" before starting the RL, though I didn't find any established techniques when I researched reward-model-free reinforcement learning loss functions that act on the number of votes a response receives. (What I mean is the results of searching DPO's citations for "Vote". Lots of results, though none of them have many citations.)
Deepseek R1 used 8,000 samples. s1 used 1,000 offline samples. That really isn't all that much.
RL techniques (reasoning + ORPO) has had incredible success on reasoning tasks. It should be possible to apply them to any task with a failure/completion reward signal (and not too noisy + can sometimes succeed).
Is it time to make the automated Alignment Researcher?
Task: write LessWrong posts and comments. Reward signal: get LessWrong upvotes.
More generally, what is stopping people from making RL forum posters on eg Reddit that will improve themselves?
Thank you for your brainpower.
There's a lot to try, and I hope to get to this project once I have more time.
That is a sensible way to save compute resources. Thank you.
Thank you again.
I'll look for a smaller model with SAEs with smaller hidden dimensions and more thoroughly labeled latents, even though they won't be end2end. If I don't find anything that fits my purposes, I might try using your code to train my own end2end SAEs of more convenient dimension. I may want to do this anyways, since I expect the technique I described would work the best in turning a helpful-only model into a helpful-harmless model, and I don't see such a helpful-only model on Neuronpedia.
If the FFNN has a hidden dimension of 16, then it would have around 1.5 million parameters, which doesn't sound too bad, and 16 might be enough to find something interesting.
Low-rank factorization might help with the parameter counts.
Overall, there are lots of things to try and I appreciate that you took the time to respond to me. Keep up the great work!
Thank you, Dan.
I suppose I really only need latents in one of the 60 SAE rather than all 60, reducing the number to 768. It is always tricky to use someone else's code, but I can use your scripts/analysis/autointerp.py run_autointerp to label what I need. Could you give me an idea for how much compute that would take?
I was hoping to get your feedback on my project idea.
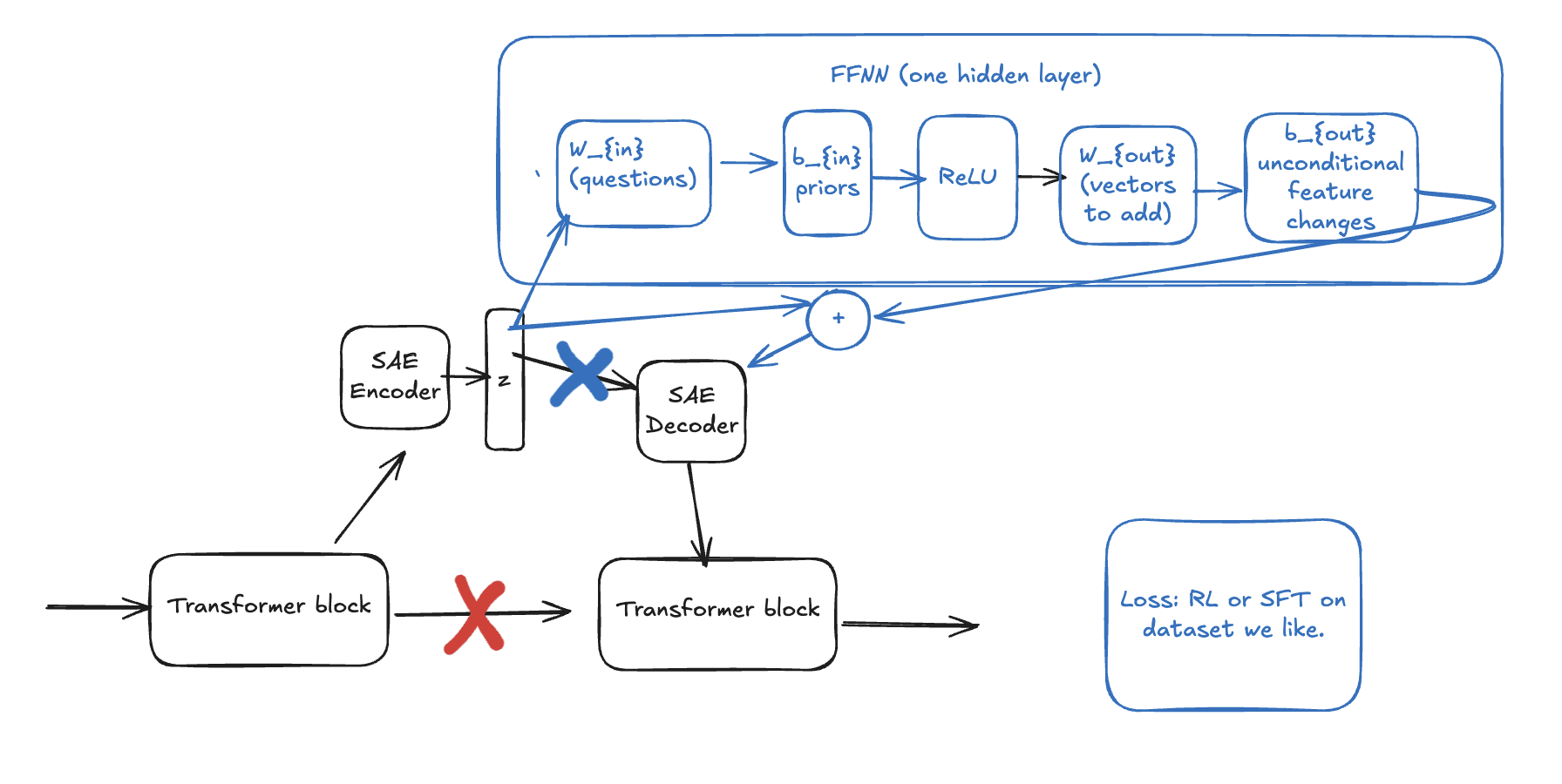
The motivation is that right now, lots of people are using SAEs to intervene in language models by hand, which works but doesn't scale with data or compute since it relies on humans deciding what interventions to make. It would be great to have trainable SAE interventions. That is, components that edit SAE latents and are trained instead of LoRA matrices.
The benefit over LoRA would be that if the added component is simple, such as z2 = z + FFNN(z), where the FFNN has only one hidden layer, then it would be possible to interpret the FFNN and explain what the model learned during fine-tuning.
I've included a diagram below. The X'es represent connections that are disconnected.
Hi, I'm undertaking a research project and I think that an end2end SAE with automated explanations would be a lot of help.
The project is a a parameter-efficient fine-tuning method that may be very interpretable, allowing researchers to know what the model learned during fine-tuning:
Start by acquiring a model with end-to-end SAEs throughout. Insert a 1 hidden layer FFNN (with a skip connection) after a SAE latent vector and pass the output to the rest of the model. Since SAE latents are interpretable, the rows in the first FFNN matrix will be interpretable as questions about the latent, and the columns of the second FFNN matrix will be interpretable as question-conditional edits to the residual latent vector as in https://www.alignmentforum.org/posts/iGuwZTHWb6DFY3sKB/fact-finding-attempting-to-reverse-engineer-factual-recall
I would expect end2end SAEs to work better than local SAEs because as you found, local SAEs do not return decodings with the same behaviors as well as end2end SAEs.
If you could share your dict[SAE latent, description] for
e2e-saes-gpt , I would appreciate it so much. If you cannot, I'll use a local SAE instead for which I can find descriptions of the latents, though I expect it would not work as well.
Also, you might like to hear that some of your links are dead:
https://www.neuronpedia.org/gpt2sm-apollojt results in:
Error: Minified React error #185; visit https://react.dev/errors/185 for the full message or use the non-minified dev environment for full errors and additional helpful warnings.
Back to Home
https://huggingface.%20co/apollo-research/e2e-saes-gpt2 cannot be reached.
I personally thought that "taking actions that would give yourself more power than the government" was something that... seemed like it shouldn't be allowed? Many people I talked to shared your perspective of "of course AI labs are in the green" but it wasn't so obvious to me. I originally did the research in April and May, but since then there was the Situational Awareness report with the quote "it’s quite plausible individual CEOs would have the power to literally coup the US government." I haven't seen anyone else talking about this.
My reasoning for choosing to write about this topic went like this:
"They are gaining abilities which will allow them to overthrow the government."
"What? Are they allowed to do that? Isn't the government going to stop them?"
If I were in charge of a government, I sure wouldn't want people doing things that would set them up to overthrow me. (And this is true even if that government gets its mandate from its citizens, like the US.)
Maybe the details of treason and sedition laws are more common knowledge than I thought, and everyone but me picked up how they worked from other sources?