Posts
Comments
I have a moment so I'll summarize some of my thinking here for the sake of discussion. It's a bit more fleshed out at the link. I don't say much about AI capabilities directly since that's better-covered by others.
In the first broad scenario, AI contributes to normal economic growth and social change. Key drivers limit the size and term of bets industry players are willing to make: [1A] the frontier is deeply specialized into a particular paradigm, [1B] AI research and production depend on lumpy capital projects, [1C] firms have difficulty capturing profits from training and running large models, and [1D] returns from scaling new methods are uncertain.
In the second, AI drives economic growth, but bottlenecks in the rest of the economy limit its transformative potential. Key drivers relate to how much AI can accelerate the non-AI inputs to AI research and production: [2A] limited generality of capabilities, [2B] limited headroom in capabilities, [2C] serial physical bottlenecks, and [2D] difficulty substituting theory for experiment.
Indicators (hypothetical observations that would lead us to expect these drivers to have more influence) include:
- Specialized methods, hardware, and infrastructure dominate those for general-purpose computing in AI. (+1A)
- Training and deployment use different specialized infrastructure. (+1A, +1B)
- Generic progress in the semiconductor industry only marginally advances AI hardware. (+1A)
- Conversely, advances in AI hardware are difficult to repurpose for the rest of the semiconductor industry. (+1A)
- Specialized hardware production is always scaling to meet demand. (+1A)
- Research progress is driven chiefly by what we learn from the largest and most expensive projects. (+1B, +1D, +2D)
- Open-source models and second-tier competitors lag the state of the art by around one large training run. (+1C, +1D)
- Small models can be cheaply trained once expensive models are proven, achieving results nearly as good at much lower cost. (+1C, +1D)
- Progress in capabilities at the frontier originates from small-scale experiments or theoretical developments several years prior, brought to scale at some expense and risk of failure, as is the status quo in hardware. (+1D, +2D)
- Progress in AI is very uneven or even nonmonotonic across domains—each faces different bottlenecks that are addressed individually. (+2A)
- Apparent technical wins are left on the table, because they only affect a fraction of performance and impose adoption costs on the entire system. (+1A, +2B, +2C)
- The semiconductor industry continues to fragment. (+2B)
- More broadly, semiconductor industry trends, particularly in cost and time (exponential and with diminishing returns), continue. (+2A, +2B, +2C)
- Semiconductor industry roadmaps are stable and continue to extend 10–15 years out. (+2C, +2D)
Negative indicators (indicating that these drivers have less influence) include
- The same hardware pushes the performance frontier not only for AI training and inference but also for high-performance computing more traditionally. (–1A)
- Emerging hardware technologies like exotic materials for neuromorphic computing successfully attach themselves as adjuncts to general-purpose silicon processes, giving themselves a self-sustaining route to scale. (–1A, –2B)
- Training runs use as much compute as they can afford; there's always a marginal stock of hardware that can be repurposed for AI as soon as AI applications become slightly more economical. (–1A, –1B)
- AI industry players engage in pre-competitive collaboration, for example setting interoperability standards or jointly funding the training of a shared foundation model. (–1B)
- Alternatively, early industry leaders establish monopolistic advantages over the rest of the field. (–1B, –1C)
- AI training becomes more continuous, rather than something one "pulls the trigger" on. Models see large benefits from "online" training as they're being used, as compared with progress from model to model. (–1B)
- Old models have staying power, perhaps being cheaper to run or tailored to niche applications. (–1C)
- Advances in AI at scale originate from experiments or theory with relatively little trouble applying them at scale within a few years, as is the status quo in software. (–1D, –2D)
- The leading edge features different AI paradigms or significant churn between methods. (–1A, –1D)
- The same general AI is broadly deployed in different domains, industry coordination is strong (through monopoly or standardization), and upgrades hit many domains together. (–2A)
- Evidence builds that a beyond-silicon computing paradigm could deliver performance beyond the roadmap for the next 15 years of silicon. (–2B)
- New semiconductor consortia arise, for example producing consensus chiplet or heterogeneous integration standards, making it easier for a fragmented industry to continue to build on one another's work. (–1A, –2C)
- Spatial/robotics problems in particular—proprioception, navigation, manipulation—are solved. (–2C)
- Fusion power becomes practical. (–2C)
- AI is applied to experimental design and yields markedly better results than modern methods. (–2B, –2D)
- AI research progress is driven by theory. (–1D, –2D)
- Breakthroughs make microscopic physical simulation orders of magnitude easier. Molecular dynamics, density functional theory, quantum simulation, and other foundational methods are accelerated by AI while also greatly improving accuracy. (–2B, –2C, –2D)
I went through a similar exercise trying to develop key drivers and indicators for a couple slow scenarios back in May 2023, focusing on lessons from the semiconductor industry. I think my "slow" is even slower than yours, so it may not be super useful to you, but maybe you'll find it interesting.
Yeah, plus all the other stuff Alexander and Metz wrote about it, I guess.
It's just a figure of speech for the sorts of thing Alexander describes in Kolmogorov Complicity. More or less the same idea as "Safe Space" in the NYT piece's title—a venue or network where people can have the conversations they want about those ideas without getting yelled at or worse.
Mathematician Andrey Kolmogorov lived in the Soviet Union at a time when true freedom of thought was impossible. He reacted by saying whatever the Soviets wanted him to say about politics, while honorably pursuing truth in everything else. As a result, he not only made great discoveries, but gained enough status to protect other scientists, and to make occasional very careful forays into defending people who needed defending. He used his power to build an academic bubble where science could be done right and where minorities persecuted by the communist authorities (like Jews) could do their work in peace...
But politically-savvy Kolmogorov types can’t just build a bubble. They have to build a whisper network...
They have to serve as psychological support. People who disagree with an orthodoxy can start hating themselves – the classic example is the atheist raised religious who worries they’re an evil person or bound for Hell – and the faster they can be connected with other people, the more likely they are to get through.
They have to help people get through their edgelord phase as quickly as possible. “No, you’re not allowed to say this. Yes, it could be true. No, you’re not allowed to say this one either. Yes, that one also could be true as best we can tell. This thing here you actually are allowed to say still, and it’s pretty useful, so do try to push back on that and maybe we can defend some of the space we’ve still got left.”
They have to find at-risk thinkers who had started to identify holes in the orthodoxy, communicate that they might be right but that it could be dangerous to go public, fill in whatever gaps are necessary to make their worldview consistent again, prevent overcorrection, and communicate some intuitions about exactly which areas to avoid. For this purpose, they might occasionally let themselves be seen associating with slightly heretical positions, so that they stand out to proto-heretics as a good source of information. They might very occasionally make calculated strikes against orthodox overreach in order to relieve some of their own burdens. The rest of the time, they would just stay quiet and do good work in their own fields.
That section is framed with
Part of the appeal of Slate Star Codex, faithful readers said, was Mr. Siskind’s willingness to step outside acceptable topics. But he wrote in a wordy, often roundabout way that left many wondering what he really believed.
More broadly, part of the piece's thesis is that the SSC community is the epicenter of a creative and influential intellectual movement, some of whose strengths come from a high tolerance for entertaining weird or disreputable ideas.
Metz is trying to convey how Alexander makes space for these ideas without staking his own credibility on them. This is, for example, what Kolmogorov Complicity is about; it's also what Alexander says he's doing with the neoreactionaries in his leaked email. It seems clear that Metz did enough reporting to understand this.
The juxtaposition of "Scott aligns himself with Murray [on something]" and "Murray has deplorable beliefs" specifically serves that thesis. It also pattern-matches to a very clumsy smear, which I get the impression is triggering readers before they manage to appreciate how it relates to the thesis. That's unfortunate, because the “vague insinuation” is much less interesting and less defensible than the inference that Alexander is being strategic in bringing up Murray on a subject where it seems safe to agree with him.
In 2021, I was following these events and already less fond of Scott Alexander than most people here, and I still came away with the impression that Metz's main modes were bumbling and pattern-matching. At least that's the impression I've been carrying around until today. I find his answers here clear, thoughtful, and occasionally cutting, although I get the impression he leaves more forceful versions on the table for the sake of geniality. I'm wondering whether I absorbed some of the community's preconceptions or instinctive judgments about him or journalists in general.
I do get the stubbornness, but I read that mostly as his having been basically proven right (and having put in the work at the time to be so confident).
In the 2D case, there's no escaping exponential decay of the autocorrelation function for any observable satisfying certain regularity properties. (I'm not sure if this is known to be true in higher dimensions. If it's not, then there could conceivably be traps with sub-exponential escape times or even attractors, but I'd be surprised if that's relevant here—I think it's just hard to prove.) Sticking to 2D, the question is just how the time constant in that exponent for the observable in question compares to 20 seconds.
The presence of persistent collective behavior is a decent intuition but I'm not sure it saves you. I'd start by noting that for any analysis of large-scale structure—like a spectral analysis where you're looking at superpositions of harmonic sound waves—the perturbation to a single particle's initial position is a perturbation to the initial condition for every component in the spectral basis, all of which perturbations will then see exponential growth.
In this case you can effectively decompose the system into "Lyapunov modes" each with their own exponent for the growth rate of perturbations, and, in fact, because the system is close to linear in the harmonic basis, the modes with the smallest exponents will look like the low-wave-vector harmonic modes. One of these, conveniently, looks like a "left-right density" mode. So the lifetime (or Q factor) of that first harmonic is somewhat relevant, but the actual left-right density difference still involves the sum of many harmonics (for example, with more nodes in the up-down dimension) that have larger exponents. These individually contribute less (given equipartition of initial energy, these modes spend relatively more of their energy in up-down motion and so affect left-right density less), but collectively it should be enough to scramble the left-right density observable in 20 seconds even with a long-lived first harmonic.
On the other hand, 1 mol in 1 m^3 is not very dense, which should tend to make modes longer-lived in general. So I'm not totally confident on this one without doing any calculations. Edit: Wait, no, I think it's the other way around. Speed of sound and viscosity are roughly constant with gas density and attenuation otherwise scales inversely with density. But I think it's still plausible that you have a 300 Hz mode with Q in the thousands.
Related would be some refactoring of Deception Chess.
When I think about what I'd expect to see in experiments like that, I get curious about a sort of "baseline" set of experiments without deception or even verbal explanations. When can I distinguish the better of two chess engines more efficiently than playing them against each other and looking at the win/loss record? How much does it help to see the engines' analyses over just observing moves?
How is this related? Well, how deep is Chess? Ratings range between, say, 800 and 3500, with 300 points being enough to distinguish players (human or computer) reasonably well. So we might say there are about 10 "levels" in practice, or that it has a rating depth of 10.
If Chess were Best-Of-30 ChessMove as described above, then ChessMove would have a rating depth a bit below 2 (just dividing by ). In other words, we'd expect it to be very hard to ever distinguish any pair of engines off a single recommended move—and difficult with any number of isolated observations, given our own error-prone human evaluation. If it's closer to Best-Of-30 Don'tBlunder, it's a little more complicated—usually you can't tell the difference because there basically is none, but on rare pivotal moves it will be nearly as easy to tell as when looking at a whole game.
The solo version of the experiment looks like this:
- I find a chess engine with a rating around mine, and use it to analyze positions in games against other engines. Play a bunch of games to get a baseline "hybrid" rating for myself with that advisor.
- I do the same thing with a series of stronger chess engines, ideally each within a "level" of the last.
- I do the same thing with access to the output of two engines, and I'm blinded to which is which. (The blinding might require some care around, for example, timing, as well as openings.) In sub-experiment A, I only get top moves and their scores. In sub-experiment B, I can look at lines from the current position up to some depth. In sub-experiment C, I can use these engines however I want. For example, I can basically play them against each other if I want to run down my own clock doing it. (Because pairs might be within a level of one another, I can't be sure which is stronger from a single win/loss outcome. I'd hope to find more efficient ways of distinguishing them.)
- I repeat #3 with different random pairs of advisors.
What I'd expect is that my ratings with pairs of advisors should be somewhere between my rating with the bad advisor and my rating with the good advisor. If I can successfully distinguish them, it's close to the latter. If I'm just guessing, it's close to the former (in the Don'tBlunder world) or to the midpoint (in the ChessMove world). I should have an easier time in sub-experiments B and C. Having a worse engine in the mix weighs me down relatively more (a) the closer the engines are to each other, and (b) the stronger both engines are compared to me.
The main question I'd hope might be answerable this way would be something like, "How do (a) and (b) trade off?" Which is easier to distinguish—1800 and 2100, or, say, 2700 and 3300? Will there be a ceiling beyond which I'm always just guessing? Might I tend to side with worse advisors because, being closer to my level, they agree with me?
It seems like we'd want some handle on these questions before asking how much worse outright deception can be.
(There's some trouble here because higher-ranked players are more likely to draw given a fixed rating difference. This itself is relatively Don'tBlunder-like, and it makes me wonder if it's possible to project how far our best engines are likely to be from perfect play. But it makes it harder to disentangle inability to draw distinctions in play above my level from "natural" indistinguishability. There are also more general issues in doing these experiments with computers—for example, weak engines tend to be weak in ways humans wouldn't be, and it's hard to calibrate ratings for superhuman play.)
(It might also be interesting to automate myself out of this experiment by choosing between recommendations using some simple scripted logic and evaluation by a relatively weak engine.)
Along the lines of what I wrote in the parent, even though I think there's potentially a related and fairly deep "worldview"-type crux (crux generator?) nearby when it comes to AI risk—are we in a ChessMove world or a Don'tBlunder world?—[sorry, these are terrible names, because actual Chess moves are more like Don'tBlunder, which is itself horribly ugly]—I'm not particularly motivated to do this experiment, because I don't think any possible answer on this level of metaphor would be informative enough to shift anyone on more important questions.
I sometimes wonder how much we could learn from toy models of superhuman performance, in terms of what to expect from AI progress. I suspect the answer is "not much", but I figured I'd toss some thoughts out here, as much to discharge any need I feel to think about them further as to see if anyone has any good pointers here.
Like—when is performance about making super-smart moves, and when is it about consistently not blundering for as long as possible? My impression is that in Chess, something like "average centipawn loss" (according to some analysis engine) doesn't explain outcomes as well as "worst move per game". (I don't know the keywords to search for, but I relatedly found this neat paper which finds a power law for the difference between best and second-best moves in a position.) What does Go look like, in comparison?
How deep are games? What's the longest chain of players such that each consistently beats the next? How much comes from the game itself being "deep" versus the game being made up of many repeated small contests? (E.g., the longest chain for best-of-9 Chess is going to be about 3 times longer than that for Chess, if the assumptions behind the rating system hold. Or, another example, is Chess better thought of as Best-Of-30 ChessMove with Elo-like performance and rating per move, or perhaps as Best-Of-30 Don'tBlunder with binary performance per move?)
Where do ceilings come from? Are there diminishing returns on driving down blunder probabilities given fixed deep uncertainties or external randomness? Is there such a thing as "perfect play", and when can we tell if we're approaching it? (Like—maybe there's some theoretically-motivated power law that matches a rating distribution until some cutoff at the extreme tail?)
What do real-world "games" and "rating distributions" look like in this light?
Many times have I heard people talk about ideas they thought up that are ‘super infohazardous’ and ‘may substantially advance capabilities’ and then later when I have been made privy to the idea, realized that they had, in fact, reinvented an idea that had been publicly available in the ML literature for several years with very mixed evidence for its success – hence why it was not widely used and known to the person coming up with the idea.
I’d be very interested if anyone has specific examples of ideas like this they could share (that are by now widely known or obviously not hazardous). I’m sympathetic to the sorts of things the article says, but I don’t actually have any picture of the class of ideas it’s talking about.
It sounds like you're saying that you can tell once someone's started transitioning, not that you can recognize trans people who haven't (or who haven't come out, at least not to a circle including you), right? Whether or not you're right, the spirit of this post includes the latter, too.
This reasoning is basically right, but the answer ends up being 5 for a relatively mundane reason.
If the time-averaged potential energy is k_B T / 2, so is the kinetic energy. Because damping is low, at some point in a cycle, you'll deterministically have the sum of the two in potential energy and nothing in kinetic energy. So you do have some variation getting averaged away.
More generally, while the relaxation timescale is the relevant timescale here, I also wanted to introduce an idea about very fast measurement events like the closing of the electrical circuit. If you have observables correlated on short timescales, then measurements faster than that won't necessarily follow expectations from naive equilibrium thinking.
Setting aside most problems with the original, I've always found this interferometer example an unsatisfying introduction because it's surprisingly ambiguous exactly what's quantum mechanical here or what's special about quantum mechanics.
You have superposition and interference in classical electromagnetism. That's enough for everything until you get to the two-photon experiment (that is, for everything in "Configurations and Amplitude"). Single photons and photon counters are posited, but these are taken as given where I would sooner take as given the idea that a solution to a wave equation can be associated with a complex amplitude. Otherwise, up to that point one might as well have been talking about electromagnetic pulses and intensity detectors.
So is the interference between many-photon states the key? ("Joint Configurations"?) Not exactly. If you have classical light sources, then both quantum and classical theories give the same answer. Worse than that, really—for the quantum description, you have to posit that photons from different sources can be indistinguishable for the purposes of interference between many-photon states ("Distinct Configurations", although it's extra unclear about that), whereas that comes naturally if you're just talking about electromagnetic fields as usual.
It feels somehow unfashionable in an age of quantum information to talk about wave-particle duality as the central surprise in quantum mechanics, but I think it's right to zero in on the idea that you get superposition and interference in systems where otherwise-successful analogies from everyday experience don't allow that.
Maybe it's because my perspective is "electromagnetism-first". From that direction, you'd introduce quantum mechanics by establishing the need for photons with things like the photoelectric effect. I suppose if you're coming from the perspective that photons are only real, discrete, individual particles, then all this build-up for interferometry might make sense—did you know light can act like a wave, too? But then I think electron diffraction or spin polarization is more straightforward and doesn't risk hammering on things that are totally fine classically.
(A marginally related suggestion—the diagrams of MZIs with lasers are going to be a little misleading for talking about experiments with photon number states, because lasers are not single photon sources. Maybe I'd be clearer about the difference between the diagram and situation in the text or just modify the figure.)
I'd be up for a dialogue mostly in the sense of the first bullet about "making sense of technical debates as a non-expert". As far as it's "my domain" it's in the context of making strategic decisions in R&D, but for example I'd also consider things like understanding claims about LK-99 to fall in the domain.
I think on and off about how one might practice (here's one example) and always come away ambivalent. Case studies and retrospectives are valuable, but lately, I tend to lean more pragmatic—once you have a basically reasonable approach, it's often best to come to a question with a specific decision in mind that you want to inform, rather than try to become generically stronger through practice. (Not just because transfer is hard, but also for example because the best you can do often isn't that good, anyway—an obstacle for both pragmatic returns and for feedback loops.) And then I tend to think that the real problem is social—the most important information is often tacit or embedded in a community's network (as in these examples)—and while that's also something you can learn to navigate, it makes systematic deliberate practice difficult.
The first! These are things I think about sometimes, but I suspect I'd be better at asking interesting questions than at saying interesting things myself.
I'm interested in being a dialogue partner for any of the things I tend to post about, but maybe especially:
- Explosive economic growth—I'm skeptical of models like Tom Davidson's but curious to probe others' intuitions. For example, what would speeding up hardware research by a factor of 10 or more look like?
- Molecular nanotechnology, for example clarifying my critique of the use of equilibrium statistical mechanics in Nanosystems
- Maybe in more of an interviewer/rubber-duck role: Forecasting and its limits, professional ethics in EA, making sense of scientific controversies
- My own skepticism about AI x-risk as a priority
My understanding is that perpetrator sexuality has little to do with the gender of chosen victims in child sexual abuse. If Annie was four years old and Sam thirteen at the time, I don't think attraction to women played much of a role either way.
Interesting, thanks!
Sure. I only meant to use Thomas's frame, where it sounds like Thomas did originally accept Nate's model on some evidence, but now feels it wasn't enough evidence. What was originally persuasive enough to opt in? I haven't followed all Nate's or Eliezer's public writing, so I'd be plenty interested in an answer that draws only from what someone can detect from their public writing. I don't mean to demand evidence from behind the confidentiality screen, even if that's the main kind of evidence that exists.
Separately, I am skeptical and a little confused as to what this could even look like, but that's not what I meant to express in my comment.
The model was something like: Nate and Eliezer have a mindset that's good for both capabilities and alignment, and so if we talk to other alignment researchers about our work, the mindset will diffuse into the alignment community, and thence to OpenAI, where it would speed up capabilities. I think we didn't have enough evidence to believe this, and should have shared more.
What evidence were you working off of? This is an extraordinary thing to believe.
Measuring noise and measurement noise
You're using an oscilloscope to measure the thermal noise voltage across a resistance . Internally, the oscilloscope has a parallel input resistance and capacitance , where the voltage on the capacitor is used to deflect electrons in a cathode ray tube to continuously draw a line on the screen proportional to the voltage over time.
The resistor and oscilloscope are at the same temperature. Is it possible to determine from the amplitude of the fluctuating voltage shown on the oscilloscope?
- Yes, if
- Yes, if
- Yes, if
- No
Molecular electromechanical switch
You've attached one end of a conductive molecule to an electrode. If the molecule bends by a certain distance at the other end, it touches another electrode, closing an electrical circuit. (You also have a third electrode where you can apply a voltage to actuate the switch.)
You're worried about the thermal bending motion of the molecule accidentally closing the circuit, causing an error. You calculate, using the Boltzmann distribution over the elastic potential energy in the molecule, that the probability of a thermal deformation of at least is (a single-tailed six-sigma deformation in a normal distribution where expected potential energy is ), but you don't know how to use this information. You know that the bending motion has a natural frequency of 100 GHz with an energy decay timescale of 0.1 nanosecond, and that it behaves as an ideal harmonic oscillator in a thermal bath.
You're considering integrating this switch into a 1 GHz processor. What is the probability of an error in a 1 nanosecond clock cycle?
- — the Boltzmann distribution is a long-time limit, so you have sub-Boltzmann probability in finite time.
- — the probability is determined by the Boltzmann distribution.
- — the 0.1 nanosecond damping timescale means, roughly, it gets 10 draws from the Boltzmann distribution.
- — the 100 GHz natural frequency means it gets 100 tries to cause an error.
- — the Boltzmann distribution is over long-time averages, so you expect larger deviations on short timescales that otherwise get averaged away.
Whether this imbalance can possibly be cheaply engineered away or not might determine the extent to which the market for AI deployment (which may or may not become vertically disintegrated from AI R&D and training) is dominated by a few small actors, and seems like an important question about hardware R&D. I don't have the expertise to judge to what extent engineering away these memory bottlenecks is feasible and would be interested to hear from people who do have expertise in this domain.
You may know this, but "in-memory computing" is the major search term here. (Or compute-in-memory, or compute-near-memory in the nearterm, or neuromorphic computing for an umbrella over that and other ideas.) Progress is being made, though not cheaply, and my read is that we won't have a consensus technology for another decade or so. Whatever that ends up being, scaling it up could easily take another decade.
Since Raemon's Thinking Physics exercise I've been toying with writing physics puzzles along those lines. (For fun, not because I'm aiming to write better exercise candidates.) If you assume an undergrad-level background and expand to modern physics and engineering there are interesting places you can go. I think a lot about noise and measurement, so that's where my mind has been. Maybe some baseline questions could look like the below? Curious to hear anyone's thoughts.
Pushing a thermal oscillator
You're standing at one end of a grocery aisle. In your cart, you have a damped oscillator in a thermal bath, initially in equilibrium.
You push the cart, making sure it moves smoothly according to a prescribed velocity profile, and you bring it to a stop at the other end of the aisle. You then wait for the oscillator to reach equilibrium with its bath again.
The final temperature is
- Cooler than before
- Exactly the same
- Hotter than before
- Not enough information. More than one of the above may be true because of one or more of the following:
- You can only answer in expectation.
- It depends on the properties of the oscillator.
- It depends on the cart's trajectory.
Thermal velocity and camera speed
You're observing a particle undergo thermal motion in a fluid. It's continuously bombarded by fluid molecules that effectively subject the particle to a white noise force and velocity damping. You estimate that it tends to lose its momentum and change direction on a timescale of 1 millisecond.
You want to get some statistics on the particle's velocity. You know the average velocity is zero, but there will be some variance that depends on temperature. You recall that in equilibrium that the particle should have velocity with probability proportional to the Boltzmann factor , giving a root mean square thermal velocity .
You calculate velocity by taking pairs of pictures at different times, then dividing the change in position by the time step. Your camera has an effectively instantaneous shutter speed.
In experiment 1, you use a time step of 0.1 milliseconds to measure velocity. In experiment 2, you use a time step of 10 milliseconds.
You collect distributions of measured velocities for each experiment, giving root mean square velocities and , respectively. What do you find?
Stochastic thermodynamics may be the general and powerful framework you're looking for regarding molecular machines.
I enjoyed it, although I'm already the sort of person who thinks Thinking Physics is fun—both the problem solving and the nitpicking about what constitutes a correct explanation. It seems worth doing at least a handful of problems this way, and more broadly deliberately practicing problem solving and metacognition about problem solving. Thinking Physics could be a good complement to Problem Solving Through Problems or How To Solve It, since in my (limited) experience you get quickly diminishing returns to anything but competition math with collections like that.
OK, a shot at Challenge I, with Poof and Foop, Steam Locomotive, and Expansion of Nothing. Felt like all three are in the sweet spot. I personally dislike Expansion of Nothing.
Poof and Foop:
The problem statement is a bit leading: there's some kind of inversion symmetry relationship between the two cases, so it should go the opposite direction, right?
Initially, definitely. The puncture means that there's less pressure on the right side—instead of colliding with the can, some particles go inside.
But those particles end up colliding with the interior left side anyway. So it seems like it should even out, and at the end the can won't be moving.
So my guess is (c). Can I make myself more confident?
Why doesn't an inversion argument go through? Well, the compressed air can is drawn in vacuum, but the vacuum can doesn't empty the environment.
So it's not simply time reversal. If the compressed air can were in air, then we might have some kind of symmetry between air particle and absence of air particle,
but then the compressed air can would slow down due to drag and stop in the limit. So that still points to (c). That also works as a thermodynamic argument—the first can isn't equilibrating with anything, so none of the work goes to heat. 95% confidence feels good.
*checks* OK, looks like I was thinking about it right, and my explanation for why the naive inversion is wrong is equivalent to sketch II.
Reflection: The main interesting thing here is the fake symmetry argument. My favorite problems have tempting solutions that don't work for subtle reasons. I think it's important not to count problems solved until you can pinpoint why those solutions fail.
What did I use here? If you're dealing with pressure, you can probably get an answer with forces or with thermodynamics. A net force can be thought of as a single force or as lack of a balancing force. That's the symmetry idea.
I'm not very good at babbling. I'm basically looking over what I wrote and renarrating it. Words to words.
Steam Locomotive:
We might want to think about torque and the height of the axle.
Or maybe it's about wheel radius. One cycle takes you further with bigger wheels.
I think these both point to (b).
I'm a little confused because thinking about the wheel heights of sports cars and trucks would push me towards (a). But cars have gears. Directly driving small wheels is basically low gear.
Not sure how I'd know if the answer were (c) or (d). Seems like you'd need background knowledge not in the question.
I should think about actual forces to get to 95% confidence.
Let's say the engine puts out the same force in both cases. Then, in II, each wheel sees half as much force from the engine,
but the ground exerts force on twice as many wheels, so that part's a wash. But because the wheels are smaller, the ground
needs to exert more force per unit engine force to keep the wheel from slipping (same torque).
So for the same engine, II seems to give more accelerating force, while I gives higher top speed. I'd put 95% on (b).
*checks* OK, seems like I had the right thought. Could I have been as confident from the distance-per-cycle argument alone? Rather than look at forces,
the author's answer argues that we know the locomotive that goes a shorter distance in the same number of engine cycles must
be putting more energy into each mile it travels. I considered that, but I wasn't sure it was a valid step.
Why couldn't you just be getting less work from the engine? Well, it's the same piston with the same motion.
My force calculation already needs that assumption, it just makes the final connection with the acceleration.
Reflection: I feel like I don't know much about automotives. (Is a locomotive an automotive, by the way? I think so, it's just locomotives involve a track.) I can describe transmission and gears and engines and so on if I think about it, but I don't have much intuition. Like, I can't explain why it's one way and not another, or how different cars solve different problems.
I just feel like I should have been able to answer the question immediately. If I could drive stick, would that help? Probably not. I already ride a bike and didn't immediately see the analogy.
What did I use? Qualitative personal experience. I picked a misleading experience but reasonably didn't weight it above thinking through the problem. Identifying relevant considerations. Didn't stop at the first idea.
Expansion of Nothing:
Oh, this one's nasty. It has to expand, right?
If you took an iron disk and drew a circle where the hole is, the circle would expand.
If you cut that disk out and heat up the cutout, the disk expands the same amount.
So everything outside the circle can't be exerting any net force at the boundary, and the hole has to stay the same size as the disk.
I don't see any problems with this argument, but can I explain why other arguments don't work? Why can't thermal expansion generate stress instead of allowing uniform expansion? I guess in a sense I just gave the reason, but why does the gap shrink if you cut a gap in a rod instead? Well, when you have only one piece, it's like applying a magnification transformation, which requires an origin. But the origin is arbitrary—you can just recenter. With two separate pieces, the two origins of magnification are no longer arbitrary.
*checks* Yeah, the author's answer doesn't go there, unfortunately.
Reflection: This problem feels really annoying to me. Maybe I saw it a long time ago and got it wrong? Or maybe it's that you never have anything that's free to expand uniformly. It's braced against something, or it's sitting on something with a different coefficient of thermal expansion, and you do get stress and it does matter how the thing is patterned.
This feels like a problem where you're supposed to think about limiting cases. Like, if you have an atomic ring, obviously it expands. I don't know if you can justify jumping to the right answer from that, though. If the disk is thick and the cutout doesn't go all the way through, it expands. Ehh. You still need an argument that it expands the same.
For context if anyone needs it, the Physics GRE is (was?) a multiple-choice exam where you get penalized for wrong answers but not for blanks. It works out so that if you eliminate one answer there's no harm in guessing, in expectation. There's also considerable time pressure—something like 90 seconds per question on average.
how much deliberate effort you put into calibrating yourself on "how much effort to put into multiple choice questions"
Enough to get through all questions with some time left over, even if that meant guessing on some I could fully solve. I'd mark the questions I'd guessed on with different symbols that let me go back at the end and prioritize solving them. For three or so practice tests, I systematically went over every problem that I missed, guessed, or spent a long time on and did the metacognitive thing including questions like "how long did I think this would take? when was I 50% confident? when should I have decided to move on? how could I have decided faster?" (Using purely retrospective judgment—I wasn't actually timing individual questions or anything more complicated.)
whether you put any deliberate effort into transferring that into the PhD experience
Not really. I think I had some notion that being able to solve small problems quickly could lead to a sort of qualitatively better fluency, but in the end there just wasn't enough in common between test content/conditions and research (or even coursework) to prioritize that. I definitely didn't learn the lesson that I was generally underconfident.
what did you actually do in your PhD experience?
Pretty normal experimentalist route, maybe heavier on math and programming than typical. Coursework for 1-2 years shading into helping with senior students' experiments, then designing and running my own.
what do you think would have better prepared you for PhD experience?
In the end I was reasonably well prepared in terms of technical knowledge, problem solving, [meta]cognitive skills, and so on (irrespective of the GRE). I think I mostly lacked perspective, particularly in terms of choosing problems and working with a supervisor. I'd guess, starting with most helpful, one or more of these:
- Industry experience with a good manager
- More research experience in other subjects
- Research in the same subject
- Other industry experience
As far as things I could have done instead with the time I used to study, I don't know. Make friends with grad students?
I only ever flipped through Thinking Physics for fun, but what I remember is that I tended to miss easier problems more often. If I spent time thinking about one, really making sure I got it right, I'd probably get it. Outside those, there were some that really were elementary, but I'd often find myself thinking I'd looked at the author's answer too soon—a self-serving "well, I would have gotten this, if I were really trying." I might say the problem was that I couldn't tell when I needed to really try.
This does remind me a bit of how I studied for the physics GRE (do people still take that?), particularly getting calibrated on multiple-choice confidence and on how long to spend on problems. Unfortunately, but perhaps not surprisingly, very little of that study transferred to my PhD experience.
From the six-author paper: "In the first region below red-arrow C (near 60 °C),
equivalent to region F in the inset of Fig. 5, the resistivity with noise signals can be regarded as
zero." But by "noise signals" they don't mean measurement noise (and their region C doesn't look measurement-noise limited, unless their measurement apparatus is orders of magnitude less sensitive than it should be) but rather sample physics—later in that paragraph: "The presence of noise in the zero-resistivity region is often attributed to phonon vibrations at higher temperature."
The other papers do seem to make that claim, but for example the April paper shows the same data but offset 0.02 Ohm-cm on the y-axis (that is, the April version of the plot [Fig. 6a] goes to zero just below "Tc", but the six-author arXiv version [Fig. 5] doesn't). So whatever's going on there, it doesn't look like they hooked up their probes and saw only the noise floor of their instrument.
I did a condensed matter experiment PhD, but high Tc is not my field and I haven't spent much time thinking about this. [Edit: I didn't see Charlie Steiner's comment until I had written most of this comment and started editing for clarity. I think you can treat this as mostly independent.] Still, some thoughts on Q1, maybe starting with some useful references:
Bednorz and Müller, "Possible High Tc Superconductivity in the Ba - La - Cu - O System" (1986) was the inciting paper for the subsequent discoveries of high-Tc superconductors, notably the roughly simultaneous Wu, Ashburn, Torng, et al. (1987) and Cava et al. (1987) establishing superconductivity in YBCO with Tc > 90K. The first paper is more cautious in its claims on clearer evidence than the present papers. The latter two show dispositive measurements.
I might also recommend Ekin's Experimental Techniques for Low-Temperature Measurements for background on how superconductors are usually measured (regardless of temperature). It discusses contacts, sample holders, instrumentation, procedures, and analysis for electrical transport measurements in superconductors, with a focus on critical current measurements. (I don't think skimming it to find a graph or statement that you can apply to the present case will be very helpful, though.)
One person alleges an online rumor that poorly connected electrical leads can produce the same graph. Is that a conventional view?
It's well understood that a jump in the I-V curve does not imply superconductivity. Joule heating at high currents and thermal expansion, for example, can cause abrupt changes in contact resistance. I'm not sure exactly what it would take to reproduce that graph, but contact physics is gnarly enough that there's probably a way, together with other experimental complications.
If this material is a superconductor, have we seen what we expected to see? Is the diminishing current capacity with increased temperature usual?
In the roughest sense, yes. The critical current density for a superconductor decreases as temperature increases and as magnetic field increases. Quantitatively, maybe. There are evidently other things going on, at least. (In another sense, the papers aren't really what I'd expect a lab that thought they had a new superconductor to present. But I think that can be explained between reproducibility issues, the interpersonal issues rushing publication, and the fact that they're somewhat outside the community that usually thinks about superconducting physics.)
How does this alleged direct measurement of superconductivity square up with the current-story-as-I-understood-it that the material is only being very poorly synthesized, probably only in granules or gaps, and hence only detectable by looking for magnetic resistance / pinning?
In an impure sample you would see high residual resistance below Tc (I think the authors do, but I'm not confident at a glance particularly given paper quality problems) and broad transitions due to a spread of transition temperatures over superconducting domains (it seems to me that the authors see very sharp transitions, although data showing the width in temperature from the April paper is omitted from the arXiv papers). The worse these are, the more mundane explanations are viable (roughly speaking), which is part of why observing the Meissner effect is important. But this is a good question. To some extent people are "vibing" rather than getting a story straight.
I hope you don't mind my piling on. This is one of those things (along with moral foundations theory) where it really frustrates me that people seem to believe it has much better scientific backing than it does.
My concern is that people didn't start believing in the EQ-SQ theory based on statistical correlations found with Simon Baron-Cohen's scales. They presumably started believing in it based on fuzzy intuitions arrived at through social experience.
It's hard to gloss empathizing-systemizing/extreme male brain as a theory that Baron-Cohen himself arrived at in a principled or scientific way.
As presented in The Extreme Male Brain Theory of Autism (2002), researchers do find apparent sex differences in behavior and cognition. It's possible to frame many of these as female-empathizing and male-systemizing. Then there are a bunch of other, mostly unrelated studies (and a few citation-free stereotypes) of behavior and cognition in autistic people, which can also be framed as low-empathizing and high-systemizing. The authors draw this figure, classifying brain types by the difference between empathizing and systemizing dimensions in "standard deviations from the mean":
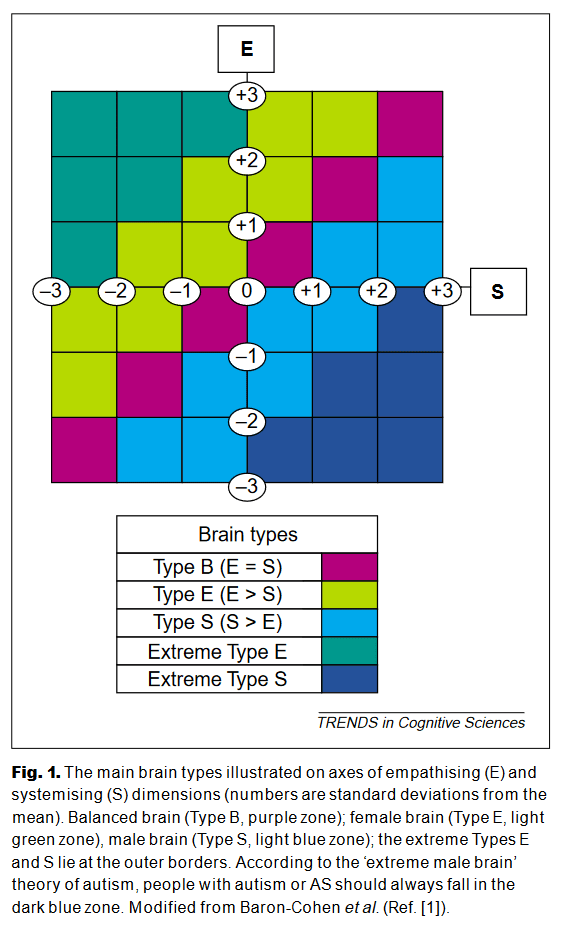
But the first, key quantitative paper I'm aware of is Empathizing and Systemizing in Males, Females, and Autism (2005). The actual plot of EQ and SQ looks like this:
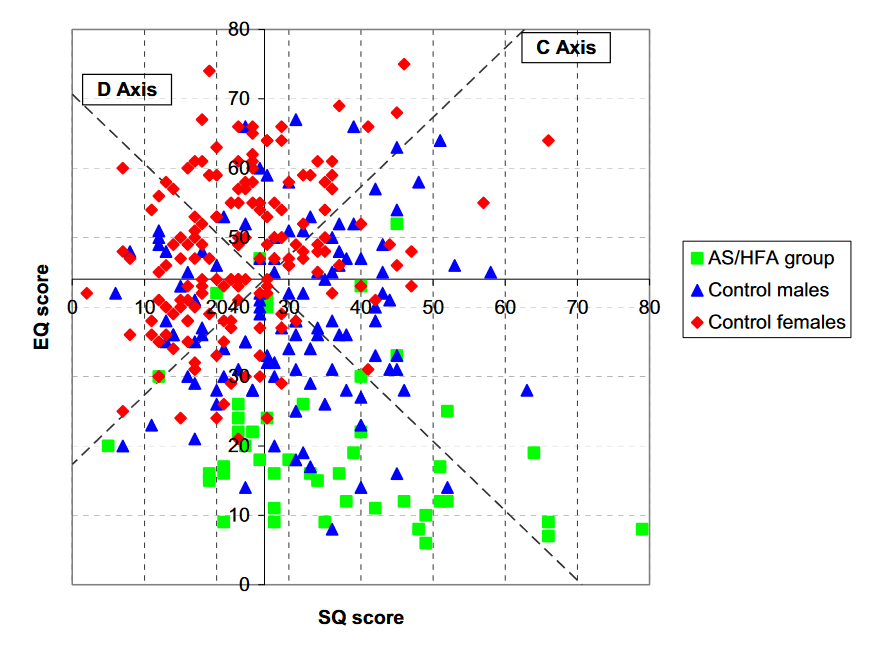
The authors write, "In this particular case, it was possible to see immediately what combination of EQ and SQ govern the data, but in general this might require using a principal components analysis." By this they mean the C and D axes (sum and difference of normalized EQ and SQ), writing, "The combination of the normalization steps and the rotation represents a principal components analysis of of this correlated bivariate data set." This paper doesn't quote standard deviations of EQ and SQ scores, but it's "possible to see immediately" that (1) the male-female differences on both axes are much less than two standard deviations (as indicated by the earlier, schematic figure, which also appears in later publications), and (2) the male-female difference in EQ+SQ (C Axis) is insignificant, while the autistic group has much lower C-Axis scores. This should not have passed review.
Clearly, I'm not someone whose mind you're trying to change, but I think your concern is on target. EQ-SQ is a bad measure, but even taken seriously it provides about as much evidence against the "extreme male brain" idea as it does in favor. I doubt that highlighting more problems with EQ-SQ is going to move people very much.
I'm speaking from memory of reporting here, but my understanding is that there was a specific turning point in 2019/2020 when one of these orgs focus tested a bunch of messages and found that trans youth issues worked well, particularly as a wedge. (That is, the opposition were split on it.) US Americans, when polled, have a bunch of weirdly self-contradictory answers to questions on trans issues but are generally more supportive than not, depending on how they're asked. My guess is they mostly don't think about it too much, since there are plausibly a million or two trans people in the US, many of whom pass or are closeted.
In the previous cycle, "bathroom bills" had failed and generated backlash. In the current cycle focused on trans youth, there's more uncertainty among people who think of themselves as liberals, and for a variety of reasons large news media organizations like the NYT have been happy to play along with conservative agenda-setting. There's some decentralized, populist opposition, but it's largely activated by forces far out of proportion to the number of trans athletes or minors getting gender-affirming surgery.
No idea what Musk's deal is. Unrelatedly, I'm also very skeptical that Libs of TikTok is primarily motivated by sincere concerns.
Edit: here's a handful of sources just from looking around again.
NYT (2023): How A Campaign Against Transgender Rights Mobilized Conservatives ("it was also the result of careful planning by national conservative organizations to harness the emotion around gender politics")
Axios (2023): The forces behind anti-trans bills across the U.S.
NBC News (2017), on ADF and bathroom bills: This Law Firm Is Linked to Anti-Transgender Bills Across the Country
The Guardian (2020), on other ADF activities and the new focus on student athletes: The multimillion-dollar Christian group attacking LGBTQ+ rights
Fairness and Accuracy In Reporting (2023): NYT's Anti-Trans Bias, by the Numbers
I don't endorse everything that's written in these, but this is more or less the thing I'm talking about.
I don't know if "decentralized" is quite right. For example, the Alliance Defending Freedom specifically has been an instrumental driving force behind legislative pushes in many states in the last few years. Legislation, election messaging, and media cycles more generally tend to be driven by a handful of conservative/evangelical nonprofits with long-established national operations, also including, for example, the Independent Women's Forum and the Family Research Council. I would also characterize it as more of a wedge issue than a resonant one, although that's more complicated.
Poorly constructed public narratives, though, make for bad policy and bad culture.
Do they, though? I'm honestly not too worried about this. That's one reason I mentioned "born this way". Of course, I think even just going by self reports "internal sense of gender" is a reasonable first approximation with wide coverage, I think the current policy and cultural agendas for trans rights are pretty much the right ones, and I think that's true pretty much regardless of "underlying truth of the phenomenon".
"My body, my choice" has already been thoroughly absorbed by the abortion debate, but a similar approach encapsulating the essence of morphological freedom is an easy case to make and a hard one to reject.
You'd think so! But people are really weird about sex, and I think it's going to be a tough fight without addressing that head on. Also, related to Ben Smith's comment, the political/medical aspects are generally more material.
Regarding
The idea of gender as an essence separate to sex, intrinsic to all, is a much steeper request, one that demands people realign their view of what is rather than what ought to be. If they cannot or will not realign that view, whatever their perspective on morphological freedom, they are placed in the role of Enemy Of The Cause.
and
to assert it becomes a threat and to examine its implications or propose it as a basis for policy is to all but declare war on the most vocal progressive trans activists.
This seems hyperbolic? Both in terms of the hostility and the "demand" to accept truth claims. I'm sure you can get that reaction from some people, but they don't speak for everyone; and you only have to live in a society with the most combative activists, not make them think you're a good person. Outside of prominent Twitter figures and what gets amplified in certain media circles, people tend to be willing enough to talk in good faith and accept you as an ally of convenience if you're respectful. They're just (understandably!) wary. (Edit: This is just my perspective. I don't speak for anyone else—I just don't see this kind of melodrama on everyday scales.)
a consistent approach as I wrestle with phenomena like trans-species identity that seem closely connected
I wouldn't expect any underlying consistency here. Honestly, I think "underlying truth of [transgender identity]" already presupposes too much consistency and leads to bad predictions.
It's often hard to get a good handle on a proposition if you don't feel able to talk about it with people who disagree. I've offered in the past to privately go over any potentially dangerous ideas anyone thinks they've found.
There aren't really novel thoughts and arguments to preserve nuance from—most of what the summary misses is that this is a story of the author's personal psychological journey through the bullet points. I understand why it's been downvoted, but I'm glad someone was forthright about how tedious it is to read more tens of thousands of words of variations on this particular theme.
I'm not sure how much of the narration is about you in the present day, or exactly what you're looking for from your audience, but there's a bit I still want to respond to.
I'm a transhumanist. I believe in morphological freedom. If someone wants to change sex, that's a valid desire that Society should try to accommodate as much as feasible given currently existing technology. In that sense, anyone can choose to become trans.
The problem is that the public narrative of trans rights doesn't seem to be about making a principled case for morphological freedom, or engaging with the complicated policy question of what accommodations are feasible given the imperfections of currently existing technology. Instead, we're told that everyone has an internal sense of their own gender, which for some people (who "are trans") does not match their assigned sex at birth.
Okay, but what does that mean? Are the things about me that I've been attributing to autogynephilia actually an internal gender identity, or did I get it right the first time? How could I tell? No one seems interested in clarifying!
I have some sympathy here. It's certainly frustrating when it seems no one has the patience to engage thoughtfully, even if no one is obliged to answer your questions. For things like this, it's especially common to be tired of explaining or justifying oneself, or to be wary after getting drawn in by people asking similar things who turn out to lack genuine curiosity, or just to not want to speak for others.
Some trans people might be interested in making a principled case, but I think most just want to live the way they choose. That's the outcome "the public narrative of trans rights" serves and (I think) ought to serve. I agree that morphological freedom is wonderful, but even if one thinks the public narrative makes bad philosophical commitments, I don't see a way to get there from here that doesn't go through pragmatic trans acceptance.
Some people feel they can choose whether to cultivate homosexual attraction or not. Some find that (real or illusory) choice liberating and meet new partners, while others find in it reasons to expect conversion therapy to work. "Born this way", as a slogan, leaves some people out and raises objections from those who note that it shouldn't matter whether it's nature, nurture, or choice. But within my lifetime it seems to have become common knowledge that trying to force someone to change their orientation is ineffective and harmful.
Similarly for "man born in a woman's body", a distinction between sex and gender, or "anyone who wants can be trans". Some trans people embrace one narrative or another with the relief of finally finding a description of their experiences. Many find ways to understand themselves in more nuanced terms, some philosophical, some psychological. These may try to steer the narrative, or they may publicly amplify the simplest available explanation that lets them get by rather than add nuance that they expect will be rounded off, misunderstood, or used against them. Some don't really worry about it one way or another. Many do all of these at different points in their lives.
It seems part of your frustration comes from wanting the public discourse to do more than serve a purpose, perhaps to be more internally consistent or more uniformly settled. I don't see you finding satisfaction here, and even less likely on your terms. Also, frankly, it sounds like your friends who egged you on, particularly in grandiose language, were not acting in your interests. I hope you have more stabilizing people in your life these days.
I also imagine it's difficult to have your understanding of yourself rejected as a misinterpretation of your experiences or as politically inconvenient, and meanwhile to see people around you as so much like you while they deny fellowship, as it were. I'm sure you've heard this before, but I suspect your picture of others' internal processes is misleading you. I don't think you've stumbled on a taboo truth so much as on one of those nuances that get misunderstood or rounded off too easily to serve their purpose. As far as there's a need to talk about it, it seems reasonable to be particularist and not immediately bring in the baggage that "autogynephilia" carries.
Thanks for replying. This is a lot clearer to me than prior threads, although it also seems as though you're walking back some of your stronger statements.
I think this is still not quite a correct picture. I agree with this:
For electronic devices at maximum packing density where you naturally represent bits with single electrons, and the de broglie wavelength is then quite relevant as a constraint on maximum packing density due to quantum tunneling etc.
However, at maximum packing density with single-electron switches, the energy requirements per area of interconnect space are still not related to dissipation, nor to irreversible-bit-erasure costs from sending signals tile by tile. Rather, the Cavin/Zhirnov argument is that the extra energy per area of interconnect should be viewed as necessary to overcome charge shot noise in the bit-copy operations required by fan-out after each switch. Abstractly, you need to pay the Landauer energy per copy operation, and you happen to use a couple interconnect tiles for every new input you're copying the switch output to. Physically, longer interconnect reduces signal-to-noise ratio per electron because a single electron's wavefunction is spread across the interconnect, and so is less likely to be counted at any one tile in the interconnect.
Thinking of this as accumulating noise on the Landauer scale at each nanoscale transmission step will give incorrect results in other contexts. For example, this isn't a cost per length for end-to-end communication via something other than spreading an electron across the entire interconnect. If you have a long interconnect or coaxial cable, you'll signal using voltage transmitted at the speed of light over conduction electrons, and then you can just think in terms of resistance and capacitance per unit length and so on. And because you need 1V at the output, present devices signal using 1V even though 1mV would overcome voltage noise in the wire. This is the kind of interconnect people are mostly talking about when they talk about reducing interconnect power consumption.
The "tile"/cellular-automaton model comes from Cavin et al., "Science and Engineering Beyond Moore's Law" (2012) and its references, particularly those by Cavin and Zhirnov, including Shankar et al. (2009) for a "detailed treatment". As @spxtr says in a comment somewhere in the long thread, these papers are fine, but don't mean what Jacob Cannell takes them to mean.
That detailed treatment does not describe energy demands of interconnects (the authors assume "no interconnections between devices" and say they plan to extend the model to include interconnect in the future). They propose the tiling framework for an end-of-scaling processor, in which the individual binary switches are as small and as densely packed as possible, such that both the switches and interconnects are tile-scale.
The argument they make in other references is that at this limit, the energy per tile is approximately the same for device and interconnect tiles. This is a simplifying assumption based on a separate calculation, which is based on the idea that the output of each switch fans out: the output bit needs to be copied to each of around 4 new inputs, requiring a minimum length of interconnect. They calculate how many electrons you need along the length of the fan-out interconnect to get >50% probability of finding an electron at each input. Then they calculate how much energy that requires, finding that it's around the minimal switching energy times the number of interconnect tiles (e.g. Table 28.2 here).
For long/"communication" interconnects, they use the same "easy way" interconnect formula that Steven Byrnes uses above (next page after that table).
The confusion seems to be that Jacob Cannell interprets the energy per tile as a model of signal propagation, when it is a simplifying approximation that reproduces the results of a calculation in a model of signal fan-out in a maximally dense device.
Oh, no. I just meant to highlight that it was a physically incorrect picture. Metallic conduction doesn’t remotely resemble the “electronic cellular automata” picture, any version of which would get the right answer only accidentally, I agree. A calculation based on information theory would only care about the length scale of signal attenuation.
Even for the purposes of the cellular model, the mean free path is about as unrelated to the positional extent of an electron wavefunction as is the de Broglie wavelength.
The picture from Eli Yablonovitch described here is basically right as far as I can tell, and Jacob Cannell's comment here seems to straightforwardly state why his method gets a different answer [edit: that is, it is unphysical]:
But in that sense I should reassert that my model applies most directly only to any device which conveys bits relayed through electrons exchanging orbitals, as that is the generalized electronic cellular automata model, and wires should not be able to beat that bound. But if there is some way to make the interaction distance much much larger - for example via electrons moving ballistically OOM greater than the ~1 nm atomic scale before interacting, then the model will break down.
[The rest of this comment has been edited for clarity; the comment by Steven Byrnes below is a reply to the original version that could be read as describing this as a quantitative problem with this model.] As bhauth points out in a reply, the atomic scale is a fraction of a nanometer and the mean free path in a normal metal is tens of nanometers. This is enough to tell us that in a metal, information is not "relayed through electrons exchanging orbitals".
Valence electrons are not localized at the atomic scale in a conductor, which is part of why the free electron model is a good model while ignoring orbitals. The next step towards a quantum mechanical model (the nearly-free modification) considers the ionic lattice only in reciprocal space, since the electrons are delocalized across the entire metal. The de Broglie wavelength of an electron describes its wavefunction's periodicity, not its extent. The mean free path is a semiclassical construct, and in any case does not provide a "cell" dimension across which information is exchanged.
Yeah, we'll see [how transient the higher rates are]. It looks like NYC also saw a spike 2020-2022 (though I think rates per passenger mile are several times smaller) and this year isn't looking much better (going by https://www.nyc.gov/site/nypd/stats/reports-analysis/transit-bus.page and the NTD pages for the MTA).
For what it's worth, the 2022 CTA homicides were a huge outlier. The years 2001-2019 had 0-2 homicides each (filtering "CTA" in "Location"), then 4 in 2020 and 4 in 2021. Meanwhile, leading up to the pandemic, the National Transit Database says Passenger Miles Traveled was approaching 2 billion (https://www.transit.dot.gov/ntd/transit-agency-profiles/chicago-transit-authority), was down to 800 million for 2020 and 2021, and presumably came back up a lot in 2022 (no profile available yet).
I agree it's not infinitely safe, but I do suspect transit comes out safer by most analyses.
Moreover, this is an estimate of effective FLOP, meaning that Cotra takes into account the possibility that software efficiency progress can reduce the physical computational cost of training a TAI system in the future. It was also in units of 2020 FLOP, and we're already in 2023, so just on that basis alone, these numbers should get adjusted downwards now.
Isn't it a noted weakness of Cotra's approach that most of the anchors don't actually depend on 2020 architecture or algorithmic performance in any concrete way? As in, if the same method were applied today, it would produce the same numbers in "2023 FLOP"? This is related to why I think the Beniaguev paper is pretty relevant exactly as evidence of "inefficiency of our algorithms compared to the human brain".
Thanks, I see. I agree that a lot of confusion could be avoided with clearer language, but I think at least that they're not making as simple an error as you describe in the root comment. Ted does say in the EA Forum thread that they don't believe brains operate at the Landauer limit, but I'll let him chime in here if he likes.
I think the "effective FLOP" concept is very muddy, but I'm even less sure what it would mean to alternatively describe what the brain is doing in "absolute" FLOPs. Meanwhile, the model they're using gives a relatively well-defined equivalence between the logical function of the neuron and modern methods on a modern GPU.
The statement about cost and energy efficiency as they elaborate in the essay body is about getting human-equivalent task performance relative to paying a human worker $25/hour, not saying that the brain uses five orders of magnitude less energy per FLOP of any kind. Closing that gap of five orders of magnitude could come either from doing less computation than the logical-equivalent-neural-network or from decreasing the cost of computation.
This claim is different from the claim that the brain is doing 1e20 FLOP/s of useful computation, which is the claim that the authors actually make.
Is it? I suppose they don't say so explicitly, but it sounds like they're using "2020-equivalent" FLOPs (or whatever it is Cotra and Carlsmith use), which has room for "algorithmic progress" baked in.
Perhaps you think the brain has massive architectural or algorithmic advantages over contemporary neural networks, but if you do, that is a position that has to be defended on very different grounds than "it would take X amount of FLOP/s to simulate one neuron at a high physical fidelity".
I may be reading the essay wrong, but I think this is the claim being made and defended. "Simulating" a neuron at any level of physical detail is going to be irrelevantly difficult, and indeed in Beniaguev et al., running a DNN on a GPU that implements the computation a neuron is doing (four binary inputs, one output) is a 2000X speedup over solving PDEs (a combination of compression and hardware/software). They find it difficult to make the neural network smaller or shorter-memory, suggesting it's hard to implement the same computation more efficiently with current methods.
If I understand correctly, the claim isn't necessarily that the brain is "doing" that many FLOP/s, but that using floating point operations on GPUs to do the amount of computation that the brain does (to achieve the same results) is very inefficient. The authors cite Single cortical neurons as deep artificial neural networks (Beniaguev et al. 2021), writing, "A recent attempt by Beniaguev et al to estimate the computational complexity of a biological neuron used neural networks to predict in-vitro data on the signal activity of a pyramidal neuron (the most common kind in the human brain) and found that it took a neural network with about 1000 computational “neurons” and hundreds of thousands of parameters, trained on a modern GPU for several days, to replicate its function." If you want to use a neural network to do the same thing as a cortical neuron, then one way to do it is, following Beniaguev et al., to run a 7-layer, width-128 temporal convolutional network with 150 ms memory every millisecond. A central estimate of 1e32 FLOP to get the equivalent of 30 years of learning (1e9 seconds) with 1e15 biological neurons synapses does seem reasonable from there. (With 4 inputs/filters, , if I haven't confused myself.)
That does imply the estimate is an upper bound on computational costs to emulate a neuron with an artificial neural network, although the authors argue that it's likely fairly tight. It also implies the brain is doing its job much more efficiently than we know how to use an A100 to do it, but I'm not sure why that should be particularly surprising. It's also true that for some tasks we already know how to do much better than emulating a brain.
Just to follow up, I spell out an argument for a lower bound on dissipation that's 2-3 OOM higher in Appendix C here.
What I mean is that "the bit is in the radiator" is another state of the system where a two-level subsystem corresponding to the bit is coupled to a high-temperature bath. There's some transition rate between it and "the bit is in the CPU" determined by the radiator temperature and energy barrier between states. In particular, you need the same kind of energy "wall" as between computational states, except that it needs to be made large compared to the bath temperature to avoid randomly flipping your computational bit and requiring your active cooling to remove more energy.
This seems to be more or less the same thing that jacob_cannell is saying in different words, if that helps. From your responses it seems your internal picture is not commensurate with ours in a number of places, but clarifying this one way or the other would be a step in the right direction.