Posts
Comments
Disagree with
- Cooking / cutting vegetables (also other things)
- Cutting vegetables / sharpening knives
- QS experiments / knowing statistics
The first two is pretty much like sketch / making pencils and paper, and the third one is absolutely essential and not a skill than you can not have
That article has no source, neither primary or secondary ones, it just made a lot of assertions. I wouldn't rely on it[1]. Because of how low quality it is, I find it even more annoying that you asked readers to fact check, rather than finding more information yourself.
Still, even assuming that there is indeed groups of people who are only relying on social welfare to survive and do nothing else, the trade-off is that cutting social expenditure would in fact harm the other groups of people who genuinely need it. What percentage of homeless in California are Muslims who also consciously decide to not work? Maybe you know about this number, but I don't and you didn't mention it so it seems to me that you are generalizing way too much. (A quick search tells me the base rate of Muslims in US is 1.1%). Welfare also consists of many policies, it is entirely possible that some policies are good while others are bad.
- ^
In general Investor Business Daily also seem quite unreliable for non-investment news. https://mediabiasfactcheck.com/investors-business-daily/
Overall, we would rate Investors Business Daily Right Biased based on right-leaning economic and market positions. We would also give them a High factual rating on strictly investing and market news. However, editorially IBT is clearly a Questionable source with the promotion of right-wing conspiracy theories and numerous failed fact checks. In sum, we rate them far-right Biased and Mixed for factual reporting.
This comment is not shown as an answer because it is not an answer, it is asking clarifying questions. Notice how the LessWrong UI intentionally separates them.

https://arxiv.org/abs/2501.04682
Reading the abstract immediately reminds me of this post
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT.
As someone who wrote pages of pedantic rules for minecraft doors, I relate to this post a lot. Rules are just hard to write and to enforce consistently
I am down to some level of tagging along and learning together, but not a full commitment. You probably want to find someone that can make a stronger commitment as an actual study partner.
I am a year 3 student (which means I may already know some of the stuff, and that I have other courses) and timezones likely suck (UTC+8 here). We can discuss on discord @papetoast if you like.
This is pretty cool. A small complaint about the post itself is that it does not explain what Squiggle is so I had to look around in your website to understand why this Squiggle language that I have never heard of is used.
The most obvious thing is that I post things out when I want people to see it, and LW/Twitter is mostly about how serious I want to be.
I don't really. Idea get revisited when I stumble on it again, but I rarely try to plan and focus on some ideas without external stimulation.
The rules are not completely consistent over time though, also it is just not articulatable in 1 minute of effort lol. I'm sure I can explain 80% of the internal rule with effort
Obsidian/LW Shortforms/Twitter for slightly different types of ideas, can't articulate the difference though
Don't really want to touch the packages, but just setting the EVALS_THREADS environmental variable worked
Tried running but I got [eval.py:233] Running in threaded mode with 10 threads! which makes it unplayable for me (because it is trying to make me to 10 tests alternating
Wealth $10k, risk 50% on $9999 loss, recommends insure for $9900 premium.
The math is correct if you're trying to optimize log(Wealth). log(10000)=4 and log(1)=0 so the mean is log(100)=2. This model assumes going bankrupt is infinitely bad, which is not accurate of an assumption, but it is not a bug.
You can still nominate posts until Dec 14th?
Thought about community summaries a very little bit too, with the current LW UI, I envision that the most likely way to achieve this is to
- Write a distillation comment instead of post
- Quote the first sentence of the sequences post so that it could show up on the side at the top
Wait for the LW team to make this setting persistent so people can choose Show All

There is also the issue of things only being partially orderable.
When I was recently celebrating something, I was asked to share my favorite memory. I realized I didn't have one. Then (since I have been studying Naive Set Theory a LOT), I got tetris-effected and as soon as I heard the words "I don't have a favorite" come out of my mouth, I realized that favorite memories (and in fact favorite lots of other things) are partially ordered sets. Some elements are strictly better than others but not all elements are comparable (in other words, the set of all memories ordered by favorite does not have a single maximal element). This gives me a nice framing to think about favorites in the future and shows that I'm generalizing what I'm learning by studying math which is also nice!
It is hard to see, changed to n.
In my life I have never seen a good one-paragraph[1] explanation of backpropagation so I wrote one.
The most natural algorithms for calculating derivatives are done by going through the expression syntax tree[2]. There are two ends in the tree; starting the algorithm from the two ends corresponds to two good derivative algorithms, which are called forward propagation (starting from input variables) and backward propagation respectively. In both algorithms, calculating the derivative of one output variable with respect to one input variable actually creates a lot of intermediate artifacts. In the case of forward propagation, these artifacts means you get for ~free, and in backward propagation you get for ~free. Backpropagation is used in machine learning because usually there is only one output variable (the loss, a number representing difference between model prediction and reality) but a lot of input variables (parameters; in the scale of millions to billions).
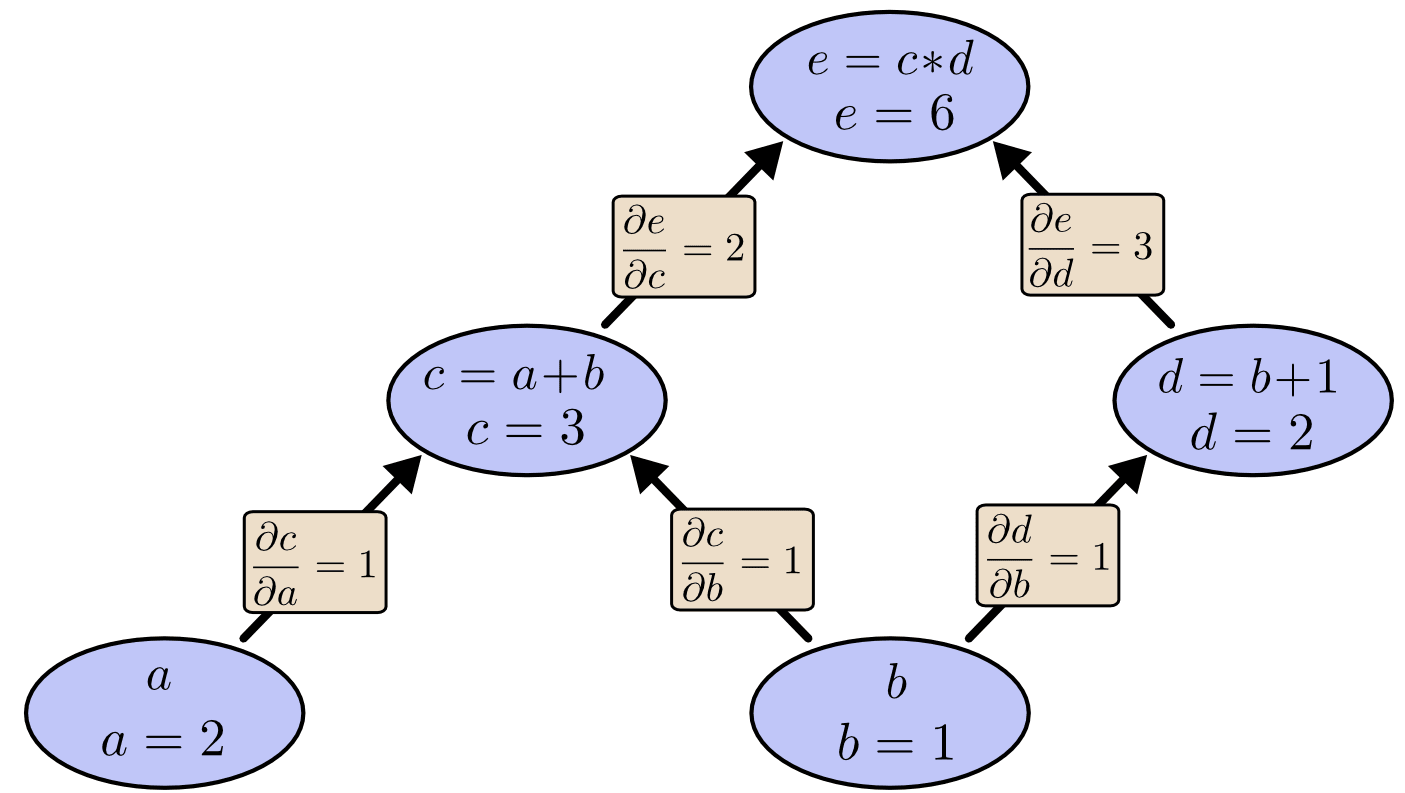
- ^
This blogpost by Christopher Olah has the clearest multi-paragraph explanation. Credits for the image too.
- ^
Actually a directed acyclic graph for multivariable vector-valued functions like f(x,y)=(2x+y, y-x), or if you do Common Subexpression Elimination in the syntax tree (as is done for the b node in the image). For simplicity I pretend that it is a tree.
Donated $25 for all the things I have learned here.
Strongly agreed. Content creators seem to get around this by creating multiple accounts for different purposes, but this is difficult to maintain for most people.
I rarely see them show awareness of the possibility that selection bias has created the effect they're describing.
In my experience with people I encounter, this is not true ;)
Joe Rogero: Buying something more valuable with something less valuable should never feel like a terrible deal. If it does, something is wrong.
clone of saturn: It's completely normal to feel terrible about being forced to choose only one of two things you value very highly.
https://www.lesswrong.com/posts/dRTj2q4n8nmv46Xok/cost-not-sacrifice?commentId=zQPw7tnLzDysRcdQv
- Butterfly ideas?
- By default I expect the author to have a pretty strong stance on the main idea of a post, also the content are usually already refined and complete, so the barrier of entry to having a comment that is valuable is higher.
Bob can choose whether to to hide this waste (at a cost of the utility loss by having $300 and worse listening experience, but a "benefit" of misleading Tim about his misplaced altruism)
True in my example. I acknowledge that my example is wrong and should have been more explicit about having an alternative. Quoting myself from the comment to Vladimir_Nesov:
Anyways, the unwritten thing is that Bob care about having a quality headphone and a good pair of shoes equally. So given that he already has an alright headphone, he would get more utility by buying a good pairs of shoes instead. It is essentially a choice between (a) getting a $300 headphone and (b) getting a $100 headphone and a $300 pair of shoes.
If the bad translation is good enough that the incremental value of a good translation doesn't justify doing it, then that is your answer.
I do accept this as the rational answer, doesn't mean it is not irritating. If A (skillful translator) cares about having a good translation of X slightly more than Y, and B (poor translator) cares about Y much more than X. If B can act first, he can work on X and "force" A (via expected utility) to work on Y. This is a failure of mine to not talk about difference in preference in my examples and expect people to extrapolate and infer it out.
Again, seems like we are in agreement lol. I agree with what you said and I meant that, but tried to compress it into one sentence and failed to communicate.
It sure can! I think we are in agreement on sunk cost fallacy. I just don't think it applies to example 1 because there exists alternatives that can keep the sunk resources. Btw this is why my example is on the order of $100, at this price point you probably have a couple alternative things to buy to spend the money.
(I need to defend the sad and the annoying in two separate parts)
- Yes, and but sometimes that is already annoying on its own (Bob is not perfectly rational and sometimes he just really want the quality headphone, but now math tells Bob that Tim gifting him that headphone means he would have to wait e.g. ~2 years before it is worth buying a new one). Of course Bob can improve his life in other ways with his saved money, but still, would be nice if you can just ask Tim to buy something else if you had known.
- Sometimes increasing sum(projects) does not translate directly to increasing utility. This is more obvious in real life scenarios where actors are less rational and time is a real concept. The sad thing happens when someone with good intention but with poor skill (and you don't know they are that bad) signing up to a time-critical project and failing/doing sub-par
This is a tangent, but Sunk cost fallacy is not really a fallacy most of the time, because spending more resources beforehand really increases the chance of "success" most of the time. For more: https://gwern.net/sunk-cost
I am trying to pinpoint the concept of "A doing a mediocre job of X will force B to rationally do Y instead of X, making the progress of X worse than if A had not done anything". The examples are just examples that hopefully helps you locate the thing I am handwaving at. I do not try to make them logically perfect because that would take too much time.
Anyways, the unwritten thing is that Bob care about having a quality headphone and a good pair of shoes equally. So given that he already has an alright headphone, he would get more utility by buying a good pairs of shoes instead. It is essentially a choice between (a) getting a $300 headphone and (b) getting a $100 headphone and a $300 pair of shoes. Of course there are some arguments about preference, utility != dollar amount or something along those lines. But (b) is the better option in my constructed example to show the point.
Let me know if I still need to explain example 2
It is sad and annoying that if you do a mediocre job (according to the receiver), doing things even for free (volunteer work/gifting) can sabotage the receiver along the dimension you're supposedly helping.
This is super vague the way I wrote it, so examples.
Example 1. Bob wants to upgrade and buy a new quality headphone. He has a $300 budget. His friend Tim not knowing his budget, bought a $100 headphone for Bob. (Suppose second-handed headphones are worthless) Now Bob cannot just spend $300 to get a quality headphone. He would also waste Tim's $100 which counterfactually could have been used to buy something else for Bob. So Bob is stuck with using the $100 headphone and spending the $300 somewhere else instead.
Example 2. Andy, Bob, and Chris are the only three people who translates Chinese books to English for free as a hobby. Because there are so many books out there, it is often not worth it to re-translate a book even if the previous one is bad, because spending that time to translate a different book is just more helpful to others. Andy and Bob are pretty good, but Chris absolutely sucks. It is not unreadable, but they are just barely better than machine translation. Now Chris has taken over to translate book X, which happens a pretty good book. The world is now stuck with Chris' poor translation on book X with Andy and Bob never touching it again because they have other books to work on.
I want to use this chance to say that I really want to be able to bookmark a sequence
Agreed on the examples of natural abstractions. I held a couple abstraction examples in my mind (e.g. atom, food, agent) while reading the post and found that it never really managed to attack these truly very general (dare I say natural) abstractions.
I overlayed my phone's display (using scrcpy) on top of the website rendered on Windows (Firefox). Image 1 shows that they indeed scaled to align. Image 2 (Windows left, Android right) shows how the font is bolder on Windows and somewhat blurred.
The monitor is 2560x1440 (website at 140%) and the phone is 1440x3200 (100%) mapped onto 585x1300.


I am on Windows. This reply is on Android and yeah definitely some issue with Windows / my PC
Re: the new style (archive for comparision)
Not a fan of
1. the font weight, everything seem semi-bolded now and a little bit more blurred than before. I do not see myself getting used to this.
2. the unboxed karma/argeement vote. It is fine per se, but the old one is also perfectly fine.
Edit: I have to say that the font on Windows is actively slightly painful and I need to reduce the time spent reading comments or quick takes.
One funny thing I have noticed about myself is that I am bad enough at communicating certain ideas in speech that sometimes it is easier to handwave at what a couple things that I don't mean and let the listener figure out the largest semantic cluster in the remaining "meaning space".
Even as I’m caught up in lazy activity, I’m making specific plans to be productive tomorrow.
How? I personally can't really make detailed or good plans during lazy mode
The link is not clickable
Manifold is pretty weak evidence for anything >=1 year away because there are strong incentives to bet on short term markets.
The list of once “secret” documents is very cool, thanks for that. (But I skimmed the other parts too)
I think the interchangeability is just hard to understand. Even though I know they are the same thing, it is still really hard to intuitively see them as being equal. I personally try (but not very hard) to stick with X -> Y in mathy discussions and if/only if for normal discussions
For nondeterministic voting surely you can just estimate the expected utility of your vote and decide whether voting is worth the effort. Probably even easier than deterministic ones.
Btw, I feel like the post is too incomplete on its own for the title Should we abstain from voting?. It feels more like Why being uninformed isn't a reason to not vote.
Maybe make a habit of blocking https://www.lesswrong.com/posts/* while writing?
The clickbait title is misleading, but I forgive this one because I do end up finding it interesting, and it is short. In general I mostly don't try to punish things if it end up to be good/correct.
Starting today I am going to collect a list of tricks that websites use to prevent you from copy and pasting text + how to circumvent them. In general, using ublock origin and allow right click properly fixes most issues.
1. Using href (https://lnk.to/LACA-15863s, archive)

behavior: https://streamable.com/sxeblz
solution: use remove-attr in ublock origin - lnk.to##.header__link:remove-attr(href)
2. Using a background image to cover the text (https://varium.jp/talent/ahiru/, archive)
Note: this example is probably just incompetence.
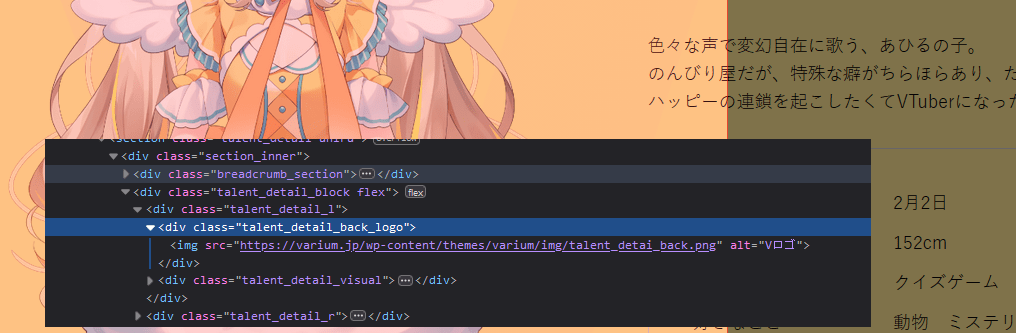
behavior: https://streamable.com/bw2wlv
solution: block the image with ublock origin
3. Using draggable=true (Spotify album titles, archive)
Note: Spotify does have a legit reason to use draggable. You can drag albums or tracks to your library, but I personally prefer having texts to be selectable.

behavior: https://streamable.com/cm0t6b
solution: use remove-attr in ublock origin - open.spotify.com##.encore-internal-color-text-base.encore-text-headline-large.encore-text:upward(1):remove-attr(draggable)
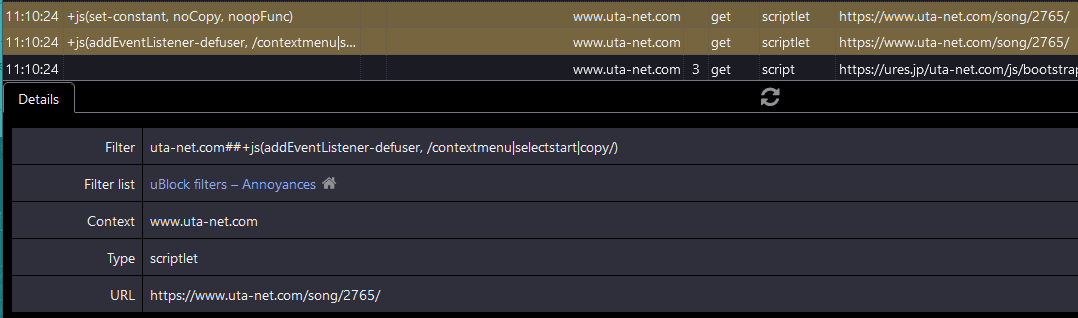
4. Using EventListeners to nullify selections (https://www.uta-net.com/song/2765/, archive)
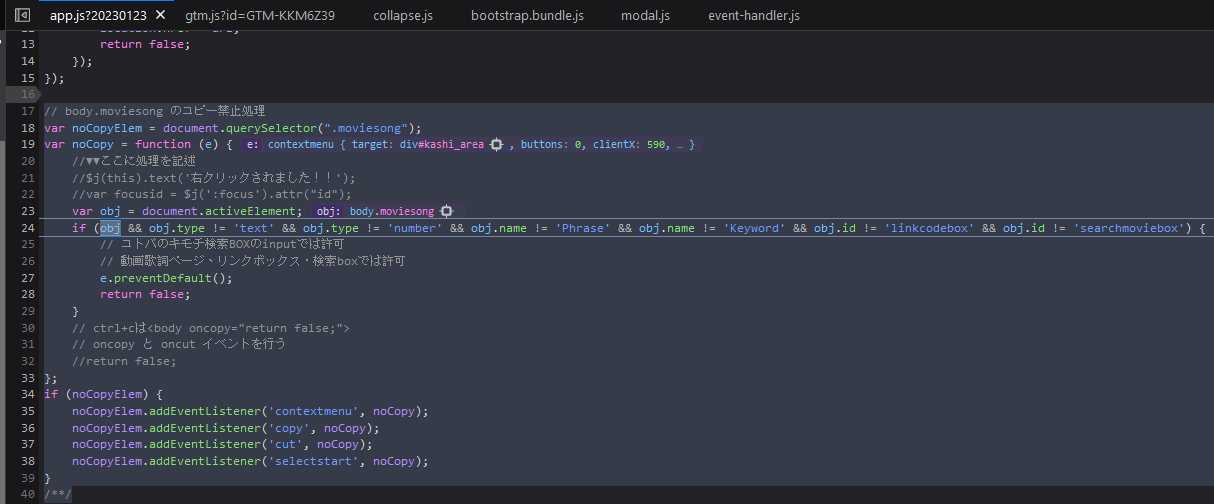
behavior: https://streamable.com/2i1e9k
solution: locate the function using the browser debugger/ctrl+f, then do some ublock origin javascript filter stuff that I don't really understand. Seems to just be overriding functions and EventListeners. The Annoyances filters worked in this case.
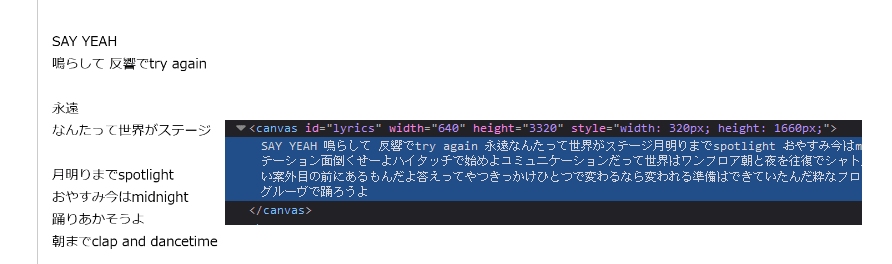
5. <canvas> (https://petitlyrics.com/lyrics/3675825, archive)
Not sure if there is a good way to handle this
To answer your question directly - not really.
I think index pages are just meant to be used by only a small minority of people in any community. In my mind, the LW concepts page is like the wiki topic groups (not sure what they're called).
The similarities are:
- It is fun to go through the concepts page and find tags I haven't learned about, this is good for exploration but a rare use case (for me)
- Because it is an index, it is useful when you have a concept in your mind but couldn't remember the name
But the concepts page has a worse UX than wiki since you have to explicitly search for it, rather than it popping up in the relevant tags page, and also they show up in a cluster
How do you use them?
I use it when I am interested in learning about a specific topic. I rarely use the Concepts page, because it contains too many tags, and sometimes I don't even know what tag I am looking for. Instead, I usually already have one or two articles that I have previously read, which feels similar to the topic I am thinking about. I would then search for those posts, look at the tags, and click on the one that is relevant. In the tag page, I start by reading the wiki, but often feel disappointed by the half-done/incompleteness of the wiki. Then I filter by high karma and read the articles from top to bottom, skipping ones that feels irrelevant or uninteresting based on title.
Do you wish you could get value from them better?
I wish the default most relevant ordering is not based on the raw score, but rather a normalized relevance score or something more complicated, because right now it means nothing other that "this post is popular so a lot of people voted on the tags". This default is really bad, every new user has to independently realize that they should change the sorting. LW also does not remember the sorting so I have to change it manually every time, which is irritating but not a big deal.
I understand that having the audio player above the title is the path of least resistance, since you can't assume there is enough space on the right to put it in. But ideally things like this should be dynamic, and only take up vertical space if you can't put it on the right, no? (but I'm not a frontend dev)
Alternatively, I would consider moving them vertically above the title a slight improvement. It is not great either, but at least the reason for having the gap is more obvious.


The above screenshots are done in a 1920x1080 monitor
I like most of the changes, but strongly dislike the large gap before the title. (I similarly dislike the large background in the top 50 of the year posts)
