Posts
Comments
when we're talking about our influence on future generations, we're almost always talking about the former, Bob-instead-of-Alice, type case.
I admit I haven't read Parfit yet, but can you give a concrete example of what type of influence you mean here?
I think Lewis would disagree with this claim, or at least that type of influence is not what he has in mind. The example that he uses at the beginning of Abolition of Man is about a particular school textbook, and public education is the prototypical example of "changing a particular person's values."
For a more realistic example, this phenomenon of a more accurate model being worse is a common issue in database query optimization.
When a user runs a SQL query, the optimizer uses statistics about the data to estimate the cost of many different ways to execute the query, then picks the plan with the cheapest estimate.
When the optimizer misestimates the cost and chooses a bad plan, the typical solution is to add more detailed statistics about the data. But occasionally adding more statistics can cause the optimizer to choose a plan that's actually worse.
For your second question, this paper describes the square root law, though in a somewhat different setting: Strong profiling is not mathematically optimal for discovering rare malfeasors | PNAS. (Incidentally, a friend of mine used this once in an argument against stop-and-frisk.)
It doesn't give a complete proof, though it describes it as a "straightforward minimization with a Lagrange multiplier".
This distinction reminds me of the battles in Ender's Game.
As I recall, Ender was the overall commander, but he delegated control of different parts of the fleet to various other people, as most modern militaries do.
The bugs fought as a hive mind, and responded almost instantly across the entire battlefield, which made it challenging for the humans to keep up in large-scale battles.
You might be interested in reading this paper, which tries to build a vision for just such a tool: Towards a Dynamic Multiscale Personal Information Space (mit.edu).
As far as I know, nothing like it exists yet.
As I understand it you've split this idea into two parts:
1. Good - People can develop their intuition to make correct predictions even without fully understanding how they can tell.
2. Bad - People frequently make mistakes when they jump to conclusions based on subconscious assumptions.
I'm confident that (2) is true, but I'm partly skeptical of (1). For example, Scott reviewed one of John Gottman's books, and concluded that it's "totally false" that he can predict who will get divorced 90% of the time: Book Review: The Seven Principles For Making Marriage Work | Slate Star Codex.
Another example which you've probably heard before is from the Superforecasting book: Book Review: Superforecasting | Slate Star Codex. Tetlock discovered that most pundit predictions were worse than random in the domains in which they were supposed to be experts.
I believe that intuition works well in "kind" learning environments, but not in "wicked" environments. David Epstein distinguished these in his book, Range: Why Generalists Triumph in a Specialized world (davidepstein.com). The main difference between the two environments is whether there's quick and reliable feedback on whether your judgment was correct.
Chess is a kind environment, which is why Magnus Carlsen can play dozens of people simultaneously and still win virtually every game. This also explains the results of the Bechara gambling task. Politics and marriage are wicked learning environments, which is why expert predictions are much less reliable.
Did you really mean 6 AM? I was thinking of joining, but I don't usually go anywhere on Saturdays before 10. :P
I understood this sentence to mean that animals are intelligent insofar as they can pick up subtle body language cues.
There's a few one-star Amazon reviews for the book that suggest McAfee's data is incorrect or misleading. Here's a quote from one of them, which seems like a solid counterargument to me:
"However, on the first slide on page 79, he notes that the data excludes impact from Import/export of finished goods. Not raw materials but finished goods. He comments that Net import is only 4% of GDP in the US. Here he makes a (potentially) devastating error – (potentially) invalidating his conclusion.
While Net imports is indeed around 4% of GDP, the gross numbers are Exports at approx. +13% and Imports at approx. -17%. So any mix difference in finished goods in Export and Import, can significantly change the conclusion. It so happens that US is a major Net importer of finished goods e.g. Machinery, electronic equipment and autos (finished goods, with materials not included above in the consumption data). Basically, a big part of US’ consumption of cars, washing machines, computers etc. are made in Mexico, China etc. They contain a lot of materials, not included in the graphs, upon which he builds his conclusion/thesis. So quite possibly, there is no de-coupling."
Thanks for the review - I appreciate that you spent the time to sift through these ideas.
When you say that we need to "be willing to make uncomfortable, difficult changes," do you have some specific changes in mind?
That depends what you mean by "computational problems". In its usual definition, a Turing machine takes a single input string, and provides a single bit as output: "Accept" or "Reject". (It may also of course run forever without providing an answer.)
For example, the question, "What is the shortest path through this list of cities?" isn't possible to encode directly into a standard Turing machine. Instead, the Turing machine can answer, "Is there a path through this list of cities with length at most k?", for some constant k.
If you don't like this, there are ways to modify the definition of a Turing machine. But for the purposes of studying computational complexity, all reasonable definitions seem to be equivalent.
I actually think SQL is not so easily composable. For me the gold standard is the Kusto query language: Tutorial: Kusto queries in Azure Data Explorer & Azure Monitor | Microsoft Docs.
Kusto is a replacement for SQL, with syntax based on the Unix command line. I think it combines the best of both.
For example, if you want to take a SQL query and adjust it to join with another table and add another column or two, you may have to make changes at several different locations. This isn't just annoying to write - if your queries are in a version control system, it's also annoying to review all of the lines that were changed.
In Kusto, you can do this by just adding one line at the end of the query to pipe it to the new join. That makes interactive data exploration much faster.
(Full disclosure: I work at Microsoft, and use Kusto for my job every day. I don't work on Kusto itself, but it's the one part of our internal tooling that I actually love.)
Edit: After reviewing your definition again, I think maybe the distinction I'm describing is not part of composability. It should probably be called something like "extensibility" instead - the ability to take an existing solution and make small modifications.
Turing machines can only have a finite number of states. So you can do all computation in a single step only if the problem has a finite number of possible inputs. At that point, your program is basically a lookup table.
Nontrivial computational problems will have an infinite number of possible inputs, so this strategy won't work in general.
Sorry, you misunderstood my point. Perhaps I'm being a little pedantic and unclear.
For the cities example, the point is that when the problem domain is restricted to a single example (the top 100 cities in the US), there is some program out there that outputs the list of cities in the correct order.
You can imagine the set of all possible programs, similar to The Library of Babel - Wikipedia. Within that set, there are programs that print the 100 cities in every possible order. One of them is the correct answer. I don't need to know which program that is to know that it exists.
This is why the OP's suggestion to define "fundamental units of computation" doesn't really make sense, and why the standard tools of computational complexity theory are (as far as I know) the only reasonable approach.
One problem with quantifying computation is that any problem with only a single instance can be trivially solved.
For example,
- How much computation does it take to write a program that computes the one millionth digit of pi? Easy - the program just immediately prints "1".
- How much computation does it take to compute the shortest path passing through the 100 largest cities in the US? Again, it's easy - the program does no "real work" and instead outputs the list of the 100 largest cities in the correct order. (I don't know the correct order, but such a program definitely exists.)
For this reason, it doesn't really make sense to talk about computation in terms of problems with only a single instance, or even a finite number of instances.
Instead, computational complexity theory focuses on how algorithms scale for arbitrary input sizes, because that's the only type of question that's actually interesting.
So can you clarify what you're asking for? And how is this related to "qualitatively understanding things like logical uncertainty"?
Working for a salary is also fundamentally a form of trade. In my case, I trade my time and expertise in writing software, and my company pays me.
Purchasing items is also trade - I trade the money I earned to buy goods and services from others.
To completely eliminate trade, I think people would need to be able to magically wish anything they desire into existence. (If you've watched The Good Place, I'm imagining something like what Janet is capable of.)
At that point, scarcity no longer exists. And since the main point of economics is to solve problems of scarcity, economics doesn't have much purpose either.
Also, note that the UK recently decreased the time range from 12 weeks to 8 weeks: UK reduces gap between two covid vaccine doses from 12 weeks to 8 weeks (livemint.com).
I'm not clear on the reason, but they have vaccinated 80% of adults with 1st doses, so perhaps they've decided that the need for 1st doses is dropping: Vaccinations in the UK | Coronavirus in the UK (data.gov.uk).
Thanks for writing this so clearly - I've bookmarked it to my list of favorite software engineering posts to share with others.
Isn't this just a normal consequence of scale? If you had to maintain 500 cars, you'd probably be more systematic. With just one car, the chances of it breaking down on any given day are pretty low.
My own strategy is that I take my car to get inspected every time the maintenance light comes on, which is about 5,000 miles. The rest of the time, I don't worry about it.
I've also played a cooperative version of this for two people, which we called Contact. It's entertaining for long road trips.
- There's no category/question given - the game can go in any direction.
- In each round, the players simultaneously pick words, then say them at the same time.
- The game continues until there is a round in which the two players say the same word. The goal is to match as quickly as possible.
- Words cannot be re-used in multiple rounds.
In theory, you could extend this to more than two people, but my guess is that it would become significantly more difficult in a larger group to get everyone to match.
I think this post would benefit from having at least one real-world example, as well as your fictional example. I can't tell what actual situations you're pointing to.
One high-level summary that occurs to me is that "trying to solve problems sometimes makes them worse" - but I think you meant something more specific than that.
I used Wirecutter for this: The Best Air Purifier for 2021 | Reviews by Wirecutter (nytimes.com). I picked their top choice, the Coway AP-1512HH Mighty, about a month ago.
So far, it seems to work pretty well, and it's very quiet in standby mode - roughly similar to the fridge. But every time I fry anything on the stove, the fan automatically speeds up to the highest level, which is much louder, roughly similar to a typical conversation. On the bright side, though, at least that proves that it works.
I don't know if this is a complete answer, but maybe it has something to do with the average age?
India's population pyramid looks a lot different from the US or Europe:
What kind of constraints do you have?
There are many constraint solvers for different kinds of equations. I enjoyed using pySMT, which provides a Python wrapper for several different libraries: pysmt/pysmt: pySMT: A library for SMT formulae manipulation and solving (github.com).
Sorry, let me try again, and be a little more direct. If the New Center starts to actually swing votes, Republicans will join and pretend to be centrists, while trying to co-opt the group into supporting Republicans.
Meanwhile, Democrats will join and try to co-opt the group into supporting Democrats.
Unless you have a way to ensure that only actual centrists have any influence, you'll end up with a group that's mostly made up of extreme partisans from both sides. And that will make it impossible for the group to function as intended.
I see a few other failure points mentioned, but no one has mentioned what I consider the primary obstacle - if membership in the New Center organization is easy, what prevents partisans from joining purely to influence its decisions? And if membership is hard, how do you find enough people willing to join?
The key idea that makes Bitcoin work is that it runs essentially a decentralized voting algorithm. Proof-of-work means that everyone gets a number of votes proportional to the computational power that they're willing to spend.
You need something similar to proof-of-work here, but I don't see any good way to implement it.
Your suggestion of moral ensemble modeling sounds essentially the same to me as the final stage in Kegan's model of psychological development. David Chapman has a decent summary of it here: Developing ethical, social, and cognitive competence | Vividness.
I don't think I had noticed the relationship with statistical modeling, though. I particularly like the analogy of overfitting.
Yes, I fully agree that using a grammar to represent graphics is the One True Way.
There's a lab at UW that's working to extend the same philosophy to support interactive graphics:
UW Interactive Data Lab | Papers (washington.edu). I haven't had a chance to use it yet, but their examples seem pretty cool!
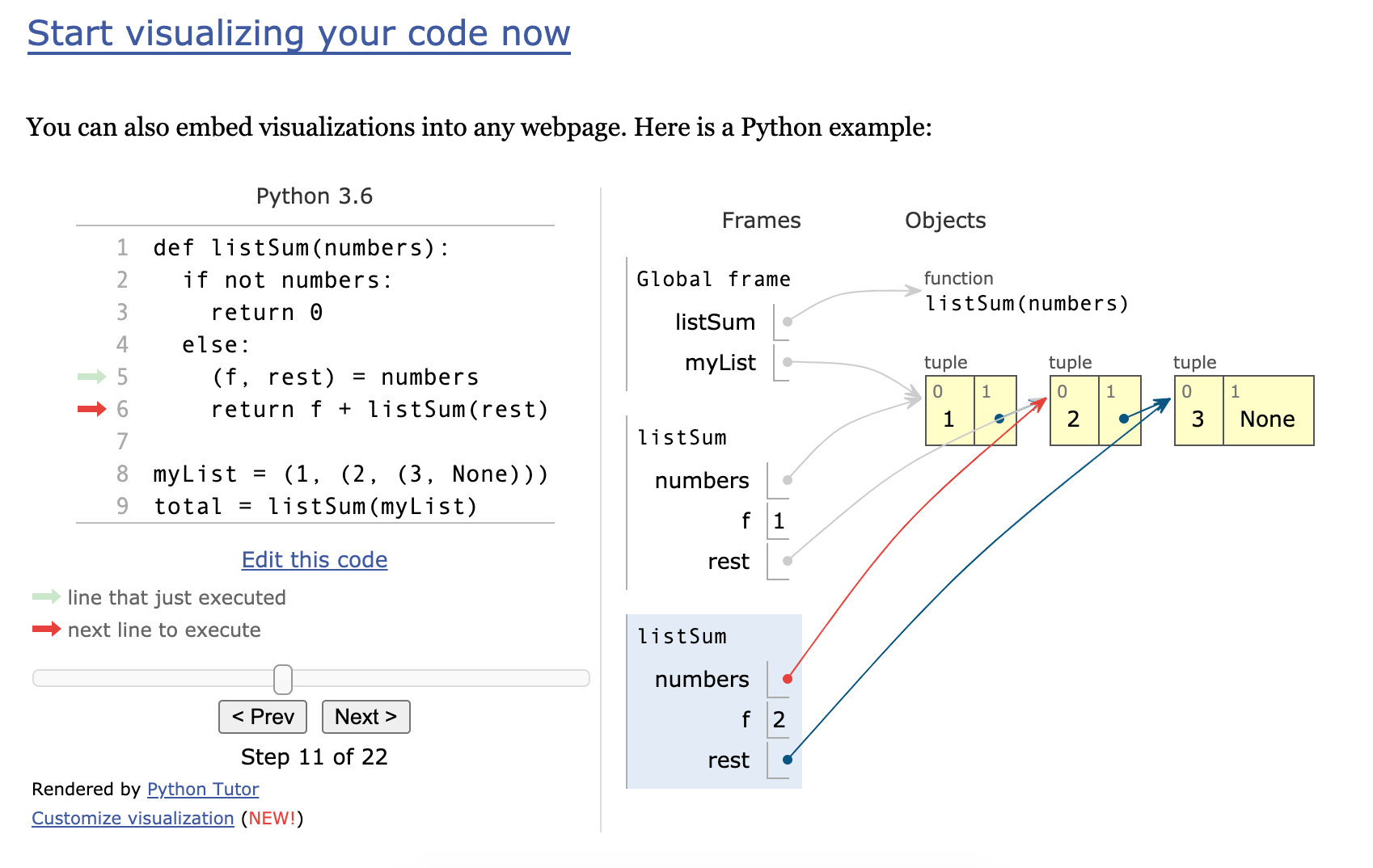
For step-throughs, the best tool I know of is Philip Guo's PythonTutor: Python Tutor - Visualize Python, Java, C, C++, JavaScript, TypeScript, and Ruby code execution. (As you can see, it's been extended to a few other programming languages - I can only vouch for the Python version.)
To save you a click, I've copied the example visualization on the homepage below. It shows all of the variables in the entire stack at the specified point in the execution.
It's all auto-generated, so it doesn't support more complex visualizations like your Container With Most Water example. But maybe it could be extended so that the user could define custom visualizations for certain objects?
Cal Newport is a CS professor who has written about productivity and focus for a long time. I'd recommend starting with the productivity section of his blog: Tips: Time Management, Scheduling, & Productivity - Study Hacks - Cal Newport. He's also known for his book Deep Work, which I plan to read soon.
His advice is somewhat helpful for me as a software engineer, but I think it's particularly aimed at people in research fields.
Edit: As others have pointed out, this is not the best strategy.
___________________________
Nice problem! The best strategy seems to be to mix the red clay with the blue clay in small infinitesimal steps. Every bit of red clay then becomes as cold as possible, meaning that as much energy as possible is transferred to the blue clay.
Here's what we get with two steps:
- Mix 1/2 red at 100 degrees + 1 blue at 0 degrees => 33.33 degrees.
- Now remove the red clay, and add the other half.
- 1/2 red at 100 degrees + 1 blue at 33.33 degrees => 55.55 degrees.
Now let's compute this with steps. So at each step we add a fraction of the red clay to the blue clay, then remove it. Let the temperature of the blue clay after steps be .
Initial:
Adding a piece of red clay to the blue clay:
To simplify our expression, let be the ratio: .
Unrolling our definition gives a geometric series:
Replacing the geometric series with its sum:
Simplifying,
So .
Now . As approaches infinity, it's well-known that this approaches .
Final temperature:
= 63.2 degrees.
As a final note, the LaTeX support for LessWrong is the best I've seen anywhere. My thanks to the team!
I'm looking forward to following this!
If your analysis of the game theory of the situation is correct, we would expect that the military occasionally makes concessions to share power, but also violently reasserts their full control when they thinks it's necessary. Do you see any way for the country to break out of that cycle?
For example, how effective do you think new international sanctions will be at curbing the violence?
US: U.S. To Impose Sanctions On Myanmar Military Officials Over Coup : NPR
UK: UK announces further sanctions against Myanmar generals - ABC News (go.com)
EU: EU agrees to sanctions on Russia crackdown and Myanmar coup | The Japan Times
On wearing glasses: Do you think contacts would also be helpful?
I've noticed, for example, that my eyes aren't nearly as affected by chopping onions when I'm wearing contacts. That seems vaguely similar to COVID transmission by aerosols.
"...and that’s why you can’t haggle with store clerks."
That is the norm, at least in the US. But a friend of mine worked at Macy's, and she said customers would occasionally try to negotiate prices. They were often successful.
A quick search online found that it's possible to haggle at a lot more places than I had realized: 11 Retailers Where You Can Negotiate a Lower Price (wisebread.com).
I consider this somewhat ethically dubious, though. If the clerks are paid hourly, they don't have their own "skin in the game," so there's no way to have a fair negotiation.
When my little sister was very young, we told her that the ice cream truck was a "music truck" - it just went around playing music for people.
I don't necessarily recommend lying, but it may have prevented some tantrums...
Google is the prime example of a tech company that values ethics, or it was in the recent past. I have much less faith in Amazon or Microsoft or Facebook or the US federal government or the Chinese government that they would even make gestures toward responsibility in AI.
I work for Microsoft, though not in AI/ML. My impression is that we do care deeply about using AI responsibly, but not necessarily about the kinds of alignment issues that people on LessWrong are most interested in.
Microsoft's leadership seems to be mostly concerned that AI will be biased in various ways, or will make mistakes when it's deployed in the real world. There are also privacy concerns around how data is being collected (though I suspect that's also an opportunistic way to attack Google and Facebook, since they get most of the revenue for personalized ads).
The LessWrong community seems to be more concerned that AI will be too good at achieving its objectives, and we'll realize when it's too late that those aren't the actual objectives we want (e.g., Paperclip Maximizer).
To me those seem like mostly opposite concerns. That's why I'm actually somewhat skeptical of your hope that ethical AI teams would push a solution for the alignment issue. The work might overlap in some ways, but I think the main goals are different.
Does that make sense?
Scott Alexander wrote a post related to this several years ago: Should You Reverse Any Advice You Hear? | Slate Star Codex
I wonder whether everyone would be better off if they automatically reversed any tempting advice that they heard (except feedback directed at them personally). Whenever they read an inspirational figure saying “take more risks”, they interpret it as “I seem to be looking for advice telling me to take more risks; that fact itself means I am probably risk-seeking and need to be more careful”. Whenever they read someone telling them about the obesity crisis, they interpret it as “I seem to be in a very health-conscious community; maybe I should worry about my weight less.”
Of course, some comments noted that this meta-advice is also advice that you should consider reversing - if you're on LessWrong, you're already in a community that's committed to testing ideas, perhaps to an extreme degree.
For myself, when it comes to advice, I usually try to inform rather than to persuade. That is, I present the range of opinions that I consider reasonable, and let people make their own decisions. Sometimes I'll explain my own approach, but for most issues I just hope to help people understand a broader range of perspectives.
This does occasionally backfire - some people are already committed strongly to one side, and a summary of the opposite perspective that sounds reasonable to me sounds absurd to them. In some cases, I've trapped myself into defending one side, trying to make it sound more reasonable, while I actually believe the exact opposite. And that tends to be more confusing than helpful.
But as long as I stick to following this strategy only with friends that are already curious and thoughtful people, it generally works pretty well.
(And did you catch how I followed this strategy in this comment itself?)
I understand your argument that there's a systematic bias from tracking progress on relatively narrow metrics. If progress is uneven across different areas at different times, then the areas that saw progress in the recent past may not be the same areas in which we see progress today.
You don't seem to make any suggestions on what would be a better metric to use. But to me it seems like the simplest solution is just to use broader metrics. For example, instead of tracking the cost of installing solar panels, we could measure the total cost of our electric grid (perhaps including environmental concerns such as carbon emissions as one part of that cost).
Along those lines, the broadest metrics we have are macroeconomic statistics such as GDP per capita. The arguments I've seen for stagnation (mostly from Jason Crawford or Tyler Cowen) already use the recent observed slowdown in GDP growth extensively.
If we see the same trend across most areas and most levels of metrics (both narrow, specific use cases and overall summary statistics) - isn't that strong evidence in favor of the stagnation hypothesis?
Or do you think there are no reliable metrics for measuring progress as a whole?
Yeah, I forgot to mention, I actually tried that too! I at least visited one of my teacher's other students and tried performing on her piano.
It's harder for me to tell how much it helped, but I think it was useful, at least for my own confidence.
Thankfully, toasters don't often burn houses down, and so this cost is low (under 1%) for most products. (I'm interested in examples of physical goods for which this is not the case.)
The first example that I thought of is the "wedding tax" - that is, anything that's purchased specifically for a wedding is significantly more expensive than the same item purchased for a different event. This includes both services (e.g., photography) and physical items (e.g., a cake).
This site validates that this is a real thing, and provides several reasons: Why are weddings so expensive? [The WEDDING TAX explained] (zoelarkin.com). Of course, it's written by a wedding photographer, so she suggests many benefits of hiring professionals.
But my wife and I both cared very little for most of those things. If we had known better, we wouldn't have hired as many vendors as we did. We concluded after our wedding that most of the money we spent wasn't worth it.
Of course, I don't mean to judge those who do spend extravagantly on their wedding, if that's what they truly want. But I think part of the reason people spend so much is because of social expectations, not because it actually makes them happy.
On memorizing piano pieces: I took several years of piano lessons. I once learned to play a piece from memory, only to forget the opening chord at the recital. I was completely stuck, so after a minute of trying I had to just apologize and sit down again. It was likely the most embarrassing experience of my childhood.
I learned the hard way that just playing the piece every day was enough for my "muscle memory" to know what to do. At some point, during practice, my hands would just play the piece correctly without any conscious thought or effort. But that was actually my downfall - my muscle memory could easily evaporate when I was in a different setting. And under pressure, my conscious brain discovered that it wasn't prepared to step in and help.
After that, my piano teacher helped me try some other techniques. The strategy that worked best for me was to both practice daily to engage my muscle memory, and also to consciously memorize the exact notes in several key measures (usually the opening of each section).
I mostly agree with your thesis, but I noticed that you didn't mention agriculture in the last section, so I looked up some numbers.
The easiest stat I can find to track long-term is the hours of labor required to produce 100 bushels of wheat [1].
1830: 250 - 300 hours
1890: 40 - 50 hours
1930: 15 - 20 hours
1955: 6 - 12 hours
1965: 5 hours
1975: 3.75 hours
1987: 3 hours
That source stops in the 1980s, but I found another source that says the equivalent number today is 2 hours [2]. That roughly matches the more recent data on total agricultural productivity from the USDA, which shows continued improvement, but not on the scale of the mid-1800's [3].
On the other hand, if the Wall Street Journal is right, being a farmer sounds a lot less strenuous today: https://www.wsj.com/articles/farmers-plow-through-movies-while-plowing-fields-11557508393 (paywalled). Instead of manual labor, farmers can sit in an air-conditioned tractor cab and watch Netflix! That's progress of a different sort, I suppose...
I also wondered about the impact of GMO food. That sounds possibly revolutionary to me, so why does its impact not show up in the numbers?
The sources I found suggest that recent GMO advances can improve yield by 10% in corn [4] or 20 - 50% across a range of other crops [5]. That's great, but not as dramatic as I thought it could be.
[1] Farm Machinery and Technology Changes from 1776-1990 (thoughtco.com)
[2] Wheat Trivia - Food Facts & Trivia: Wheat (foodreference.com)
[3] USDA ERS - Agricultural Productivity Growth in the United States: 1948-2015
On the format: Since you asked for feedback, I found this format a little harder to follow than other LessWrong posts. For me, short paragraphs are great when used sparingly to make a particular point punchier. But an entire post like that feels like someone is talking too quickly and not giving me time to think. (I also don't read Twitter, so perhaps it's just not well-suited for me.)
On the content: Robert Kegan's "Immunity to Change" framework addresses some of this, especially the "shadow values" (which he calls hidden commitments). I learned the framework from this book, which was very helpful for me last year in uncovering some of my own hidden commitments (as well as for a few other reasons): https://www.amazon.com/How-Talk-Change-Work-Transformation-ebook/dp/B003AU4DX2/.
I hadn't thought of applying this to productivity systems, though. That's very insightful, and definitely an area where I still experience tension. So I think this will be helpful, thanks!
I like the example of the Apollo mission. But I think an even more direct parallel to faith as surrender is EY's definition of lightness in Twelve Virtues of Rationality - LessWrong:
The third virtue is lightness. Let the winds of evidence blow you about as though you are a leaf, with no direction of your own.
If you are strongly committed to one belief, and then find evidence to the contrary, and actually change your mind - then you've just surrendered to the superiority of something outside yourself.
Perhaps changing your mind doesn't provoke the same mystical experience that you see expressed in Leonard Cohen's lyrics or Kierkegaard's "leap of faith"? But EY's post feels equally mystical to me.
I don't have the philosophical sophistication to explain this as clearly as I would like, but I think fiction is valuable to the extent that it can be "more true" than a literal history.
Of course, fiction is obviously false at the most basic level, since the precise events it records never actually happened. But it can be effective at introducing abstract concepts. And except for trivia competitions, the abstract patterns are usually what's most useful anyway.
The best analogy I can think of is lifting weights. Fiction is an artificial gym that trains our minds to recognize specific patterns, much as weight lifting uses artificial movements that target specific muscle groups.
Fiction works by association, which as you suggest is how our minds tend to operate by default already. So at a minimum, wrapping ideas in a fictional story can make them more memorable. For example, people who memorize decks of cards tend to use "memory palace" techniques that associate the cards with vivid events.
The knowledge we gain from reading fiction is largely subconscious, but for me the most important part is the ability to understand how people who are different from me will think or act. This can also inspire me to think and act more like the role models I've observed.
There are other purposes in reading fiction - some fiction is meant mainly for entertainment. But I think most of what people would consider classics aim to teach something deeper. Perhaps what you experience as meaningful in reading Lord of the Rings is related to this?
Of course, there is the danger that reading bad fiction will make you less informed than you would have been otherwise. And the fact that learning occurs mostly subconsciously exacerbates this problem, since it can be difficult to counter a faulty narrative once you've read it.
But fiction seems no more dangerous to me than any other method of getting information from other people. Even sticking strictly to facts can be misleading if the facts are selectively reported (as occurs frequently in politics).
I do need to think some more about your point about how exactly to distinguish what part of a story is fictional and what can be treated as true. I don't have a clear framework for that yet, though in practice it rarely seems to be an issue. Do you have an example of a time you felt misled by a fictional story?
Overall, I think my understanding of the world, and especially of people, would be greatly impoverished without fiction.
XKCD made a similar comparison: xkcd: DFS.
Several months ago, some people argued that trying to develop a vaccine for COVID-19 was pointless, because the "common cold" includes several types of coronaviruses, which have never had a successful vaccine.
Now that we have multiple successful vaccines for COVID-19, could we use the same methods to produce a vaccine for the common cold?
Five minutes of research suggests to me that it would be worth it to try. (Caveat: I picked the first numbers I found from Google, and I haven't double-checked these.)
- The common cold costs $40 billion per year in the US alone, after including the cost of lost productivity: Cost of the Common Cold: $40 Billion (webmd.com). (Article from 2003, but I don't imagine this has changed significantly.)
- The US government contributed $9 billion to developing COVID-19 vaccines: How Much Will It Cost to Get a COVID-19 Vaccine? (healthline.com). As I understand it, that includes both the costs of funding the research and, at least in some cases, pledging to buy hundreds of millions of doses.
- Coronaviruses cause around 15% of cases of the common cold: Common cold - Wikipedia.
Spending $9 billion to save $6 billion per year (15% of $40 billion, assuming all types of colds have roughly the same severity) sounds like a good deal to me. And chances are that the cost of development could be much lower in a non-emergency situation, since we don't need so much redundancy.
This article makes it sound like the main difference is that we've never tried mRNA vaccines before: Fact-checking Facebook post comparing COVID-19 vaccine research to HIV, cancer, common cold - HoustonChronicle.com. But now that we know it works, I don't see what's stopping us.
No war before WWI ever had a large enough number of combatants or was deadly enough in general to make a real dent in the population.
I think that's fairly inaccurate. Just to pick the first example that came to mind:
By all accounts, the population of Asia crashed during Chinggis Khan’s wars of conquest. China had the most to lose, so China lost the most—anywhere from 30 to 60 million. The Jin dynasty ruling northern China recorded 7.6 million households in the early thirteenth century. In 1234 the first census under the Mongols recorded 1.7 million households in the same area. In his biography of Chinggis Khan, John Man interprets these two data points as a population decline from 60 million to 10 million.
Source: Twentieth Century Atlas - Historical Body Count (necrometrics.com)
I haven't checked how much of the decline is due to battles, and how much to indirect causes such as disease or famine.
1. Thanks, I've had much better experiences with my landlord, but your experience might be more typical. Lack of adequate insulation is a clear problem, and one that's potentially worsened by the current system in which landlords pay for installing insulation but tenants generally pay for electricity. It's also the kind of issue that wouldn't become known to the tenants until after they've already moved in. So it makes sense to me that this would require legislation.
The process you propose for maintaining quality sounds reasonable enough. It might even be less susceptible to abuse than the current system of requiring security deposits, which the landlord can decide whether or not to refund. I've never experienced abuse of that type, but it wouldn't surprise me if it's relatively common.
2. I agree there's a lot more design work to do here. But before diving into that, I'm not entirely convinced by this point:
If you use [the amount that people actually spend] as your optimization metric, as our cities currently do, you get overpriced services.
When I think about which services are overpriced, the first ones that come to mind are college tuition and healthcare. But the primary cost drivers there are not rent, so I don't think your proposal would affect them very much.
If we limit our discussion to services that are overpriced due to high rent costs, the only one I can think of is restaurants. I've never seen an actual restaurant's budget, but I've heard that their costs are generally split evenly into rent, salaries, and the cost of the food itself. And it makes sense that rent would be a major cost, since table space at restaurants is clearly inefficient - even in the pre-pandemic world, restaurants often operated at capacity for only a few hours each weekend. So I'll grant that there's likely room for improvement there.
Is there something else I'm missing?