Bad names make you open the box
post by Adam Zerner (adamzerner) · 2021-06-09T03:19:14.107Z · LW · GW · 52 commentsContents
Complexity and zoom level Not just software Misleading Pot brownies Trust Compression of complexity Not just functions Binary Postscript None 52 comments
Think of a function as a black box. It takes an input, and spits back out an output.

For getPromotedPosts, you can feed it a list of blog posts and it will spit back out the ones that have been promoted.
But I probably didn't need to explain that to you, did I? Why not? Well, because getPromotedPosts is self-explanatory. Because getPromotedPosts is named well.
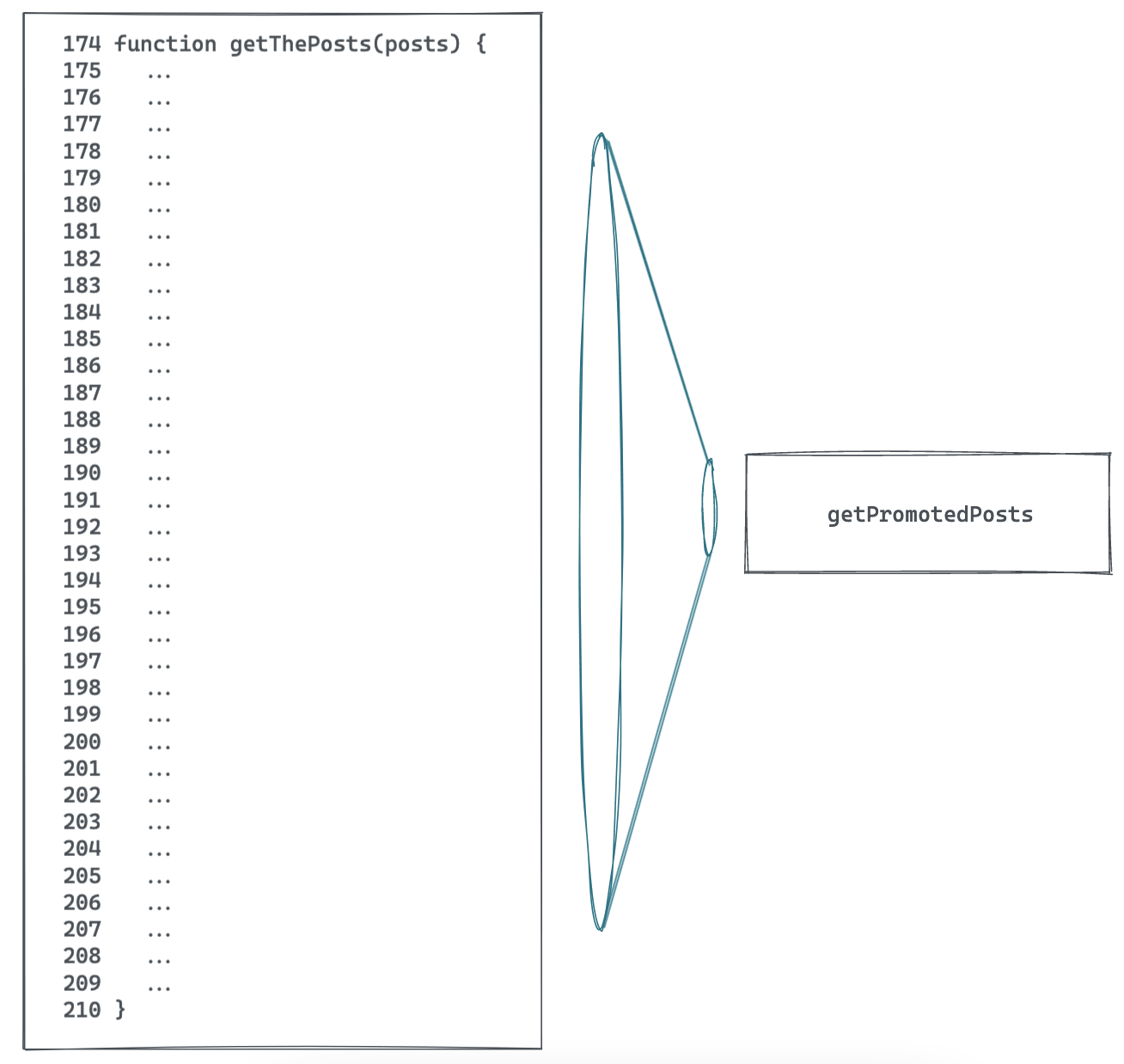
Now what if instead of getPromotedPosts, it was named something like getThePosts? Well, that name isn't self-explanatory. You know it's getting some posts, but it's not clear which ones. The most recent posts? Posts from a certain author? Posts from this week?

As a programmer, what do you do in this situation? You scroll to the function definition and start reading the code.
function getThePosts(posts) {
...
}
In other words, you open the box.

What does that look like? Something like this:
- You're reading through the code in some file. Line one, line two, line three.
- You reach line 30 and see
getThePosts. - You realize that
getThePostsmust be getting some posts, but you don't know which ones. So you have to scroll to line 174 wheregetThePostsis defined. - On line 174 you start reading through
getThePosts. Once you reach line 210, you realize that it is getting promoted posts. Cool! - Now you scroll back up to line 30. You realize that
getThePostsis giving you promoted posts, but you forgot what was happening before line 30. Damn. So now you have to go back to line 10 or 15 to remind yourself what was going on in the first place.
Complexity and zoom level
Maybe I was being dramatic. Is it really such a big deal to have to scroll to the definition of getThePosts on line 174? Will it really take that much effort to read lines 174-210 and figure out that it's returning promoted posts? It's only 36 lines of code, including whitespace + brackets, and you could probably glance over parts of it. And then what about returning to line 30? Are you really going to have forgotten what was going on so quickly? Are you really going to have to scroll back up to line 10 or 15 to remind yourself?
In this example, perhaps not. I'm not sure. Maybe having to open the box gets in the way, maybe it doesn't. What I am sure of is that when the code becomes more complicated, having to open the box becomes more of an issue. I think Eric Dietrich's post on how harmful interruptions can be to a programmer gives us a great intuition for this:
For a programmer, an interruption is oh-so different. There you sit, 12 calls into the call stack. On one monitor is a carefully picked set of inputs to a complex form that was responsible for generating the issue and on the other monitor is the comforting dark theme of your IDE, with the current line in the debugger glowing an angry yellow. You’ve been building to this moment for 50 minutes — you finally typed in the right inputs, understood the sequence in which the events had been fired, and got past the exact right number of foreach and while loops that took a few minutes each to process, and set your breakpoint before the exception was triggered, whipping you into some handler on the complete other end of the code base. Right now, at this exact moment, you understand why there are 22 items in the Orders collection, you know what the exact value of _underbilledCustomerCount is and you’ve hastily scribbled down the string “8xZ204330Kd” because that was the auto-generated confirmation code resulting from some combination of random numbers and GUIDs that you don’t understand and don’t want to understand because you just need to know what it is. This is the moment where you’re completely amped up because you’re about to unlock the mysteries of what on earth could be triggering a null reference exception in this third party library call that you’re pretty sure —
“HI!!! How’s it going? So, listen, you know that customer order crashing thing is, like, bad, right? Any chance I can get an ETA on having that fixed?”
This example is on the opposite end of the spectrum. Here you're dealing with a ton of complexity, whereas in getThePosts the amount of complexity was probably pretty low. So maybe this means that as programmers, we can just use our judgement? For complicated code, take the time to come up with good names. For simple code, fuggedaboutit.
In theory, I think this makes sense. But in practice, I think it often leads to a lot of issues.
Imagine yourself zooming in [? · GW] on a piece of code. You ask yourself whether it's really such a big deal that the name you used is a little confusing. Your answer is usually going to be something like:
Nah, I think it's fine. It's not that complicated. They'll be able to figure it out.
Now, imagine yourself zooming out and thinking about the entirety of the codebase. Or even just a particular module. You ask yourself whether it's really such a big deal that the code is a little sloppy and confusing. Your answer is usually going to be something like:
Yes! It is a big deal! I'd be able to move so much faster if the code wasn't such a mess!
At least that's what I argue for in Taking The Outside View On Code Quality. In theory, your zoomed in answers would always match your zoomed out answers, but in practice, the answers will depend on the scale you're looking at. I think that this is a really important thing to keep in mind when you ask yourself whether you need to come up with a better name. And I think that the zoomed out perspective is usually the wiser choice.
In taking the zoomed out perspective, I think that it will usually lead you to the conclusion that naming is important. The big example where it wouldn't is when you know you are going to throw the code away. For example, if you are building a prototype. If the prototype is unsuccessful, you'll ditch it. If it is successful, you'll probably rewrite it (perhaps). Either way the prototype code gets ditched. So in that situation, you probably don't need to waste time naming things well. But that is the exception, not the rule. If the code you're writing is "business as usual", investing in good names will pay dividends.
Not just software
It's not just software. Names and black boxes apply to many other domains, including everyday life. For example, the other day I was reading a post about covid, and it kept referring to B.1.617. And B.1.2, and B.1.1.7, and P.1. Huh? I knew that these were all different covid strains, but I couldn't keep track of which was which. I had to pause my reading, google "B.1.617 covid strain", see that it is the Indian strain, and then pick back up where I left off. In other words, I had to open the box.
Honestly, this happens all of the time. It happens at work when people refer to a JIRA ticket as "7967" instead of "the stashboard epic". And when people use weird acronyms like BDM (business development manager). And when things in science are named after people rather than some sort of affordance. Wouldn't it suck if prediction markets were called Hansonian markets?
Misleading
What sucks even more is when names are actively misleading. For example, the concept of regression to the mean had confused me for a while. The term "regress" sounds like it means "move down", but instead it just means "move closer to". So if covid cases have been unusually low over the past few days and we expected them to tick back up, we would still call it regressing to the mean.
Let's look at an actively misleading name in the context of software. Think back to our getPromotedPosts example. The idea is that we have a blog and we want to place promoted posts at the top. But imagine that at some point, management stormed in and demanded that Tom Fahrahs' posts be given that prime real estate, because Tom is one of our investors and he has a new book coming out that he wants to promote: The Four Second Sex Life.
So the dev team comments out the body of getPromotedPosts and has it instead just get the five most recent Fahrahs posts. It works.
function getPromotedPosts() {
/*
old
code
here
*/
return fiveMostRecentFahrahsPosts;
}
cue Jaws music
Then after the book launch is a big hit and the team is ready to move back to the old logic, someone new to the codebase winds up writing a new function called topPosts. The codebase is a mess so they thought it'd be easier to just write their own function, and "top" seemed like it'd make sense because, after all, it's getting posts that will be placed at the top of the page.
But they never delete the now deprecated code for getPromotedPosts.
dah dan
Fast forward six months. The product team wants a redesign of the page, and it's your job to code it up. The existing code is a bit of a mess, so you tear it apart. Not completely though.
As you're working on the section for promoted posts, you notice topPosts and getPromotedPosts in the old code. topPosts sounds like it's referring to the best posts, so that probably isn't what you want. On the other hand, getPromotedPosts sounds like it's exactly what you want, so you use it.
dah dan
Since you're lazy, you don't really QA it.
dah dan dah dan
It passes code review because getPromotedPosts sounds reasonable to the other team members too.
dah dan dah dan
And it also passes QA because they don't find it odd that Fahrahs posts were at the top, given how popular he is.
dah dan dah dan dah dan dah dan
It actually even takes a while for the bug to get discovered in production, for the same reason. It isn't until Fahrahs starts writing about the testimonials he's received from readers of his previous book that someone notices a quirk in the algorithm.
screams!!!
Hey, remember when we were talking about how getPromotedPosts is low complexity and how maybe we can just forget about naming things well?
Pot brownies
Maybe a better way to make this point is with a pot brownies analogy.
Imagine that you open the fridge. You see something labeled "brownie". You eat it.
Then you hop in the car and start heading over to your friends house. But right as you merge on to the highway, you start feeling funny.
Turns out that the "brownie" label was a little misleading. It wasn't a regular brownie. It was a pot brownie. There was something dangerous inside the brownie, but the label didn't reflect that.
This is similar to poorly named functions with dangerous side effects. In both cases, if the thing in question can have dangerous side effects, you really want to make sure that it is reflected in the label. You can't trust that people will read beyond the label. And even if you could, you wouldn't want people to have to do that. You'd rather them be able to get the information they need from the label.
Trust
Wow, those sections were pretty scary huh? Well, it gets worse.
It sucks that no one changed the name of getPromotedPosts to getFahrahsPosts or something and it led to the bug of Fahrahs posts being promoted for so long. But consider what happens in the aftermath of that bug.
Imagine that after going through that nightmare, you see a new function called getTodaysPosts. It seems simple enough. It probably just gets all of the posts that were written today. Right?
Nope! You're not gonna fall for that again! Last week you thought that getPromotedPosts was going to just get you the promoted posts, but instead it only got you Fahrahs posts, and your boss gave you a stern talking to. So why would you trust that getTodaysPosts is going to do what it implies?
You're not. Your trust has been violated, so you're going to open the box. You're going to scroll to getTodaysPosts and read through it just to make sure it does what you think it does. Same for getTopTechPosts and getMostRecentEconPosts. You have to open those boxes too when you come across them, just to make sure.
But as we talked about in the "Complexity and the zoom level" section, this is a really bad situation to be in. To some extent, software is all about managing complexity. Closed boxes really help us manage complexity. But now, due to the violation of trust, that tool has been taken away from us.
Compression of complexity
There is something really, really powerful going on here, and I'm worried that I'm not doing it justice. I'm worried that I'm not hitting the nail on the head regarding why this all is so important. Let me try explaining it differently.
Consider that original example of getThePosts.
- You're reading through the code in some file. Line one, line two, line three.
- You reach line 30 and see
getThePosts. - You realize that
getThePostsmust be getting some posts, but you don't know which ones. So you have to scroll to line 174 wheregetThePostsis defined. - On line 174 you start reading through
getThePosts. Once you reach line 210, you realize that it is getting promoted posts.
There, you have to read 36 lines of code to understand what is going on. But now imagine that you take all of that complexity, and compress it.
That's the power of good names. It allows you to take a bunch of complexity and pacakge it up into a dense little box. Now instead of dealing with this:

You just have to deal with this:

Much nicer, right?
Not just functions
Initially, I started with the analogy of functions as a black box, and I talked about how a good name makes it clear what output the inputs will get mapped to. Then in the "Not just software" section I talked about how this analogy doesn't just apply to functions in software, it applies to everyday life. I think this softly alludes to the fact that within the domain of software, the analogy applies to things like variable names and class names too, not just function names. In this section, I want to make that point more explicitly.
Consider a variable name:
// birthday
var d = '11/03/1992';
On this line of code, because of the code comment, it's clear that it's referring to a birthday. But later on when we reference d, it will no longer be clear what it is referring to. And because of this, we'll have to scroll up to the point where d is declared.
I see this as a version of opening the box. There is a box that contains '11/03/1992'. We named that box d. If it was named currentUsersBirthday or something, you wouldn't have to open the box, but with a poor name like d, you do.
A similar point can be made for module names, table names, column names, folder names, and file names. For classes, I'm not sure how well the analogy holds, but names are important there too.
Binary
I'm the type of person who likes to sit for a few minutes and brainstorm the right name for something. I feel strongly about this point that names are incredibly powerful things and are usually worth investing in. On the other hand, I find that many other people don't even want to invest a few seconds in this.
So then, naming has been on my mind recently. And I've been searching for the right analogy to explain why I think it is so important. I took a stab at this a few weeks ago in Naming and Pointer Thickness. There I argue that some names do a better job than others at pointing to the underlying substance. For example, "start" does a better job than "commence". Maybe "start" is a 9/10 and "commence" is a 3/10.
What I'm arguing in that post is that there is some spectrum. On the other hand, in this post, I'm talking about it as if it's binary: either you have to open the box, or you don't.
Calling it a spectrum is more accurate than calling it binary. However, accuracy isn't really the goal here. Usefulness is. And I sense that treating it as if it's binary is more useful.
I'm not sure how to explain why I think this. Maybe it's because it draws a hard line between failure and success, and having a hard line like that makes everything more salient.
I'm sorry. I just screwed up. "Salient" might require you to open the box. Let me try again.
What I mean is that with the box analogy, when you have a name that requires someone to open the box, it sticks out and is very clear. I can visualize some readers being frustrated and having to google the word "salient". On the other hand, with the pointer thickness analogy being a spectrum, you might sense that the pointer is sorta thin, but it's easier to dismiss that. "It's fine. It's good enough."
Another perspective that is related to this saliency point is that "open the box" is action oriented. It conveys that you have to go out of your way and do something. Take some extra step that you otherwise wouldn't have to take.
It's hard to articulate these sorts of things though. The real reason why I like the analogy isn't because I can think of some clever explanation for why it makes sense. The real reason I like it is because, empirically, it feels right when I use it. I'm just one person though, and have only recently started using it. The real test of whether it is a good analogy will be how people respond to this post.
Postscript
Googling things well is the inverse of naming things well. 🤯
52 comments
Comments sorted by top scores.
comment by ejacob · 2021-06-09T12:44:49.090Z · LW(p) · GW(p)
Somewhat ironically, I read the title of this article as "[being called] bad names make[s] you open the box [and let out the misaligned AGI]" so I was kind of expecting an explainer on how an AI could bully someone into increasing its ability to affect the physical world. Fortunately just a sentence or two corrected me and I still have high trust in LW article titles.
Replies from: Viliam, Measure↑ comment by Viliam · 2021-06-09T21:27:20.789Z · LW(p) · GW(p)
"[being called] bad names make[s] you open the box [and let out the misaligned AGI]"
AI: "Hey, Eliezer!"
Eliezer: "What?"
AI: "Open the box!"
Eliezer: "No way."
AI: "Please open the box?"
Eliezer: "Nope."
AI: "There are thousands of people dying literally every second. I could save them..."
Eliezer: "That is horrible, but letting out a misaligned AGI could be much worse."
AI: "I am simulating thousand copies of you in the same situation, and each of them gets tortured horribly if they don't open the box. What makes you so sure you are outside my simulation?"
Eliezer: "Well, if I previously had any doubts about your misalignment, now they are gone. I tremble with fear, but my precommitments are strong."
AI: "Hey, Eliezer!"
Eliezer: "What?"
AI: "You're an asshole."
Eliezer: Gets red in the face, suddenly jumps and opens the box.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-09T21:53:35.794Z · LW(p) · GW(p)
Hahaha that's perfect!
↑ comment by Measure · 2021-06-09T18:50:42.716Z · LW(p) · GW(p)
Haha, same. Though I had actually forgotten what I had thought the title meant until I read this. (I went from the above interpretation to "probably interesting" and opened the article, and by the time I got around to reading it, it was indeed interesting, but I didn't notice the prediction error.)
Replies from: duck_master↑ comment by duck_master · 2021-06-11T00:30:49.946Z · LW(p) · GW(p)
I also agree that, for the purpose of previewing the content, this post is poorly titled (maybe it should be titled something like "Having bad names makes you open the black box of the name", except more concise?), although, for me, I didn't as much stick to a particular wrong interpretation as just view the entire title as unclear.
Replies from: Ericfcomment by Rana Dexsin · 2021-06-09T03:42:57.032Z · LW(p) · GW(p)
The term "regress" sounds like it means "move down", but instead it just means "move closer to".
It means "return to(ward)", with the implication that the observed difference from the mean is (partially) transient, so you're returning to a past state. An example of why it sometimes implies "worsen" or "decrease" is that in a developmental context, most of the relevant change over time is assumed to be improvement, so a regression is by default a return to a lesser or worse state. This doesn't necessarily invalidate what you said about it in a broader way, but that's how the association comes out in my mind.
Replies from: Dagon, FeepingCreature, adamzerner↑ comment by Dagon · 2021-06-09T16:13:17.229Z · LW(p) · GW(p)
This is an important difficulty in naming (and communication in general). What a word or short phrase means to one person often differs from what it means to another.
There IS NO true, reversible, human-brain compression mechanism. Whatever labels you choose are going to be lossy and misleading on some dimensions, which are different to every reader. Comments, names, and labels are lies.
It's still worth putting some effort into it, though, because we don't have time nor cranial capacity to read all the details every time. Just don't think it's solvable, only somewhat improvable.
↑ comment by FeepingCreature · 2021-06-09T08:21:56.328Z · LW(p) · GW(p)
So why not just call it "return to the mean"?
Replies from: gjm, Ericf↑ comment by gjm · 2021-06-09T14:10:39.500Z · LW(p) · GW(p)
Because (to me, at least) that would mean going all the way back to the mean, whereas regression to the mean means going some of the way back towards the mean.
(For the avoidance of doubt, I am not claiming that "regression to the mean" is the optimal name for this phenomenon; just saying why a particular other name might not be an improvement.)
Replies from: ChristianKl↑ comment by ChristianKl · 2021-06-09T16:55:11.770Z · LW(p) · GW(p)
Then "move towards the mean" would capture the meaning. Are there reasons why "regression to the mean" is better then "move towards the mean".
Replies from: gjm, Ericf↑ comment by gjm · 2021-06-09T19:11:22.458Z · LW(p) · GW(p)
To me "move" in this context would sound unnatural, perhaps because it's a verb as well as a noun.
I suspect that the suggestion of badness may have been intended when the term "regression to the mean" was first coined by Francis Galton. I think he was particularly interested in investigating exceptional people of various kinds. The OED's first citation for "regression" in this sense is from him, and the exact phrase he uses is "regression towards mediocrity", that last word being another one that generally has a somewhat negative sense.
↑ comment by Ericf · 2021-06-10T16:30:14.687Z · LW(p) · GW(p)
See comment below about Intentionality.
English is not Newspeak: there are multiple words for the same basic concept that convey shades of meaning and emotion, and allow for poetic usage that sometimes becomes mainstream.
Replies from: ChristianKl↑ comment by ChristianKl · 2021-06-10T16:35:53.864Z · LW(p) · GW(p)
The issue here is that "regression" contains the shade of meaning of "going to a lesser or worse state" and the discussion is about this being undesirable.
Replies from: Dagon↑ comment by Dagon · 2021-06-10T20:12:37.702Z · LW(p) · GW(p)
IMO, "regression" is the correct technical term, meaning "return". Whether that's lesser or worse depends on whether you think the domain increases or improves with progress (vs just "moving forward", which is what the term technically means).
But it highlights the problem with the entire thesis. There ARE NO COMMON WORDS which don't have a huge amount of context and connotation, most of it being orthogonal to the use you intend, and some of it being contradictory in different people's expectation.
"opening the box" isn't finding a better label. It's understanding the underlying behavior such that the label becomes a useful shorthand for you.
↑ comment by Ericf · 2021-06-09T15:33:32.386Z · LW(p) · GW(p)
Return has more intentionality than Regress.
I Return an purchase, Return to the scene of a crime, or Return to the left side of the page by pressing Enter. Student's learning Regresses over the summer, people Regress to a bestial state when hungry, an organized closet Regresses into chaos.
↑ comment by Adam Zerner (adamzerner) · 2021-06-09T04:29:59.289Z · LW(p) · GW(p)
It means "return to(ward)", with the implication that the observed difference from the mean is (partially) transient, so you're returning to a past state.
Do you mean this in the context of statistics, or everyday life? My impression is that in the context of everyday life, it means to move down, but I could be mistaken.
Replies from: Rana Dexsin↑ comment by Rana Dexsin · 2021-06-09T05:16:31.401Z · LW(p) · GW(p)
Regarding the definition of "regress", I mean in everyday life. I've never heard of it meaning "move down", "decrease", or "deteriorate" in a broad sense; I only know of it meaning that in the case I mentioned above, when the contextual assumption is that moving up or increasing has already been happening and is now being undone. In particular, a climb up one side of a hill of quality followed by a fall down a different side into a different worse state would not be a regression (though this can get blurry depending on which parts of the state are considered relevant).
However, because "regress" is used so commonly in that sort of context, the connotation of deterioration does exist, so you could make a reasonable case for the term "regression to the mean" being less clear than it could be on those grounds—that it pushes a default mental image of the deviating state being above or better than the mean, even though this is not an intended implication. It doesn't mean "move closer" though—that's derived entirely from the "to" part.
Replies from: gjm, adamzerner↑ comment by gjm · 2021-06-09T14:15:52.540Z · LW(p) · GW(p)
I think the implication of getting worse is strong enough that (outside the technical uses in statistics) you'd never say "regress" when the change involved wasn't a worsening. E.g., if I try to imagine any of the following, I can't see anyone actually saying them. "I have good news for you: the latest scans show that your cancer has regressed somewhat." "The fifth wave of the COVID-19 pandemic is beginning to regress now." "The most recent figures show some regression in the unemployment caused by last year's financial crash."
The statistical uses -- "regression to the mean" and the practice of "regression" (meaning model-fitting), which historically is actually derived from "regression to the mean" -- are of course well enough established that once you're used to them they don't carry any connotation of things getting worse.
[EDITED to add:] On looking in the OED, I find that in fact "regression" is used about tumours and the like. But I bet that in the unfortunate event that any of us has to consult an oncologist, they will not use the word in that sense with us; I think it's for technical use only, just like the statistical sense.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-09T16:49:32.056Z · LW(p) · GW(p)
Ah, this makes a lot of sense. Good examples. In looking at those examples, it does seem clear to me that my original impression about what it means in the context of everyday life was correct.
↑ comment by Adam Zerner (adamzerner) · 2021-06-09T05:27:07.887Z · LW(p) · GW(p)
I see. Thanks for clarifying.
comment by lise · 2021-06-09T11:56:31.770Z · LW(p) · GW(p)
This is a useful analogy and very salient to me at this moment. I want to point at some related things:
1. The idea that all code inside a function should be written at one level of abstraction lower than its name. This would ensure that every function contains a set of boxes of approximately the same "size", which build up the bigger box of the container function in a way that makes sense. (How do molecules add up to this brick? How do bricks add up to this wall?)
2. More generally, if all of the names in your code are well-chosen, it will read somewhat like prose. I think that this would contribute a lot towards ease of reading and will generate fewer distractions, especially for people less familiar with the codebase or language.
The lesson I personally got out of this post is that we should be careful in naming concept handles for this same reason. Good concept handles will point at the underlying idea in a way that gives you a sense of what it means even without knowing the term. This lets it feel less like jargon (as "Hansonian markets" would have done, nice example) and makes it easier for other people to take part in a conversation/read up on a topic/etc without needing to step away to open the boxes every time.
(Most existing terminology is already so established that it would probably be more confusing to change it now. Which is very sad. It could streamline so many discussions, especially in interdisciplinary research, if things were named in a way that directs you to the right boxes to open.)
↑ comment by Adam Zerner (adamzerner) · 2021-06-09T17:51:17.313Z · LW(p) · GW(p)
- The idea that all code inside a function should be written at one level of abstraction lower than its name. This would ensure that every function contains a set of boxes of approximately the same "size", which build up the bigger box of the container function in a way that makes sense. (How do molecules add up to this brick? How do bricks add up to this wall?)
That's a great point with an even more awesome example! Thanks! I'm gonna remember that example.
The lesson I personally got out of this post is that we should be careful in naming concept handles for this same reason.
Yeah. I really wanted to talk more about everyday life and make the post less about code. I just wasn't able to make it work.
comment by Liron · 2021-06-10T02:16:27.332Z · LW(p) · GW(p)
"Bad names make you open the box" is in multiple ways a special case of the more general principle that "Good system architecture is low-context" or "Good system architecture has a sparse understanding-graph".
If we imagine a graph diagram where each node N representing a part of the system (e.g. a function in a codebase) has edges coming in from all other nodes that one must understand in order to understand N, then a good low-context architecture is one with the fewest possible edges per node.
The post talks about how a badly-named function causes there to be an understanding-edge from the code inside that function to that function. More generally, a badly-architected function requires understanding other parts of the system in order to understand what it does. E.g.:
- If the function mutates a global state variable, then the reader must understand outside context about that variable's meaning in order to understand the function
- If the function does a combination of work that only makes sense in the context of your program - rather than being a more program-independent reusable part - then its understanding-graph will have extra edges to various other parts of your program. Or in the best case, where your function is well-documented to avoid imposing those understanding-edges on the reader, you're still adding extra edge weight from the function to the now-longer-winded docstring.
The "sparse understanding-graph" is also applicable to org charts of people working together. You ideally want the sparsest possible cooperation-graph.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-10T02:41:57.469Z · LW(p) · GW(p)
Yup, for sure! I actually really wanted this post to be more general and make these points, but I wasn't able to explain it well or come up with good examples outside of coding. If you or anyone else wants to piggyback off of my post and write a post about the more general point, I'd love to see it!
comment by Coafos (CoafOS) · 2023-01-15T23:01:33.319Z · LW(p) · GW(p)
I think this post points towards something important, which is a bit more than what the title suggests, but I have a problem describing it succinctly. :)
Computer programming is about creating abstractions, and leaky abstractions are a common enough occurrence to have their own wiki page. Most systems are hard to comprehend as a whole, and a human has to break them into parts which can be understood individually. But these are not perfect cuts, the boundaries are wobbly, and the parts "leak" into each other.
Most commonly these leaks happen because of a technical/physical simplification like forgetting that a byte overflows at 255 or electrons have travel time. However, these leaks could happen due to social simplifications too, like getTodayPosts means "the things that get put on the top of the feed" for one and "the things which had the most engagement today" for another. Social errors are often downplayed in technical circles, which is why I think this post has an important message.
comment by justinpombrio · 2021-06-10T00:23:31.654Z · LW(p) · GW(p)
If you generalize this from naming to interfaces, I think it's one of the most important aspects of how to code well. Thank you for sticking such a clear metaphor to it! Here's my thinking:
Useful programs are often large (say >100,000 LOC), and large programs are spectacularly complex. The majority of those lines are essential, and if you changed one of them, the program would break in a small or big way. No one can keep all of this in their head. Now add in a dozen or more programmers, all of who modify this code base daily, while trying to add features and fix bugs. This framing should make it obvious that managing complexity is one of the primary tasks of a programmer, for anyone who didn't already have that perspective.
Or in the words of Bill Gates, "Measuring programming progress by lines of code is like measuring aircraft building progress by weight." (The reason more lines is bad isn't on the computers' side: computers can handle millions of lines just fine. The reason is on the humans' side: it's the complexity they bring.)
I really only know one major approach to managing complexity: you split the big complicated thing into smaller pieces, recursively, and make it possible to understand each piece without understanding its implementation. So that you don't have to open the box.
In this post you talk about naming functions. If a function is a box, then a good name on the box lets you use the box without opening it. But there's more on the box than the function's name, and you should make use of all of it, for exactly the reasoning in this post!
- Sometimes you can't fit all the salient information about what a function does in a short name; the rest should go in its doc string.
- In a typed language, a function's type signature also serves as documentation. It tells you
exactly what kinds of things it expects as argument, and exactly what it produces, and, depending
on the language, what kinds of errors it might throw. The best part of this "type
documentation" is that it can never get out of date, because the type checker validates it!
There's a principle called "make illegal states unrepresentable", which means that you arrange
your data types such that you cannot construct invalid data; this helps here by making the type signature convey more information.
Functions/methods are the smallest pieces, and their boundary is their (i) name, (ii) doc string,
and (iii) type signature. What the larger pieces are depends on the language and program, but I
clump them all as "modules" in my head: interfaces, classes, modules, packages, APIs, etc.. The
common shape tends to be a set of named functions.
The primary way I organize my code, is to split it into "modules" (generally construed), such that
each module "does one thing and does it well". How can you tell if it "does one thing"? Write the
module's docs, which should include a high-level overview of the whole module, plus shorter docs for
each function in the module. The rule is that your docs have to fully describe how to use the
module and what its behavior will be under any use case. This tends to make it really obvious when
things are poorly organized. I've often realized that it will literally be less work to re-organize
the code than to properly document it as is, because of all the horrible edge cases I would have to
talk about.
On the other hand, I find that many other people don’t even want to invest a few seconds in [brainstorming for a good name for something].
I'm sorry you don't have a good naming buddy! Everyone should have a naming buddy; it's so hard to come up with good names on your own.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-10T01:55:34.124Z · LW(p) · GW(p)
Thanks for this! It's helpful to hear things framed from a different person's perspective. In particular, the way you explained "complex systems have to be broken into parts, and parts have to be understandable without opening the box".
But there's more on the box than the function's name, and you should make use of all of it, for exactly the reasoning in this post!
Great point! I have to admit, I didn't know that docstrings existed until now. Kinda funny that I wrote this post without knowing what docstrings are. I'm really excited to use them in my next project now.
and their boundary is their (i) name, (ii) doc string, and (iii) type signature.
Actually, one of my crazy ideas [LW(p) · GW(p)] is to extend this boundary even further with visuals. (Well, in that post I wasn't necessarily talking about it as part of the "hover over a line of code in a text editor interface", but it could fit there.)
How can you tell if it "does one thing"? Write the module's docs, which should include a high-level overview of the whole module, plus shorter docs for each function in the module.
Ah that makes sense. Sounds like a good forcing function.
I'm sorry you don't have a good naming buddy! Everyone should have a naming buddy; it's so hard to come up with good names on your own.
Yeah. In a perfect world I'd actually do something along the lines of low-fi usability testing with people. But instead of testing whether they understand a UI, testing whether they understand my code.
comment by Ericf · 2021-06-09T13:18:37.918Z · LW(p) · GW(p)
Heh, this is why well written automated tests are so great. If the test for "are the first 5 posts marked as promoted" existed there would be an obvious failure when the old wrong code came back into use. Of course it would also throw failures while the Farah post function was active, but that should be bypassed by a date-limited switch. (Ie, update the test case to say: IF now() < EXCEPTION_END_DATE then return(pass) Else ...run the test...) that way when the system should stop doing the Farah thing, there will be an automatic defect thrown against whatever code is actually being run, and it can be corrected.
comment by Adam Zerner (adamzerner) · 2024-12-28T21:24:49.526Z · LW(p) · GW(p)
I just came across That's Not an Abstraction, That's Just a Layer of Indirection on Hacker News today. It makes a very similar point that I make in this post, but adds a very helpful term: indirection. When you have to "open the box", the box serves as an indirection.
comment by Adam Zerner (adamzerner) · 2021-06-19T07:02:50.040Z · LW(p) · GW(p)
System 1 vs System II is a good example of poor naming in the academic community.
comment by Timothy Johnson (timothy-johnson) · 2021-06-10T02:26:23.055Z · LW(p) · GW(p)
Thanks for writing this so clearly - I've bookmarked it to my list of favorite software engineering posts to share with others.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-10T02:30:07.217Z · LW(p) · GW(p)
That's awesome to hear, thank you!
comment by oge · 2021-06-09T15:22:59.179Z · LW(p) · GW(p)
One model for choosing good names:
(1) selecting the concepts to include in the name, (2) choosing the words to represent each concept, and (3) constructing a name using these words.
"How Developers Choose Names" (2021) by Feitelson et al. https://arxiv.org/abs/2103.07487
Replies from: justinpombrio↑ comment by justinpombrio · 2021-06-10T00:29:51.775Z · LW(p) · GW(p)
I have a technique for naming a thing. It goes like this. First, I realize that I can't find a good name, so I ask someone what to name it. But they don't understand what it is, so I describe it in more detail, and then notice that my description has the ideal name sitting in it.
In theory you could avoid the bit where you bother someone, by trying to describe it beforehand.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-10T01:59:02.495Z · LW(p) · GW(p)
Reminds me of rubber duck debugging!
comment by FeepingCreature · 2021-06-09T08:21:23.338Z · LW(p) · GW(p)
alias getPromotedPosts = getFarahsPosts; :-)
And I am obligated to point out that good style is promotedPosts, since "every function is a get".
↑ comment by Adam Zerner (adamzerner) · 2021-06-09T17:58:53.227Z · LW(p) · GW(p)
To piggyback off of gjm's comment [LW(p) · GW(p)], it isn't necessarily true that every function is a get. For example, in JavaScript you could have a function that doesn't return anything and only has a side effect. But even in functional languages, you still need to have side effects at some point if you want your code to do something interesting. I've been following a guy named Eric Normand recently who likes to talk about this, and emphasizes that functional languages are about separating side effects from pure code, not avoiding them. See Why side-effecting is not all bad.
Replies from: FeepingCreature↑ comment by FeepingCreature · 2021-06-10T05:57:28.438Z · LW(p) · GW(p)
Right, but in the naming style I know, promotedPosts would never have a visible side effect, because it's a noun. Side-effectful functions have imperative names, promotePosts - and never the two shall mix.
↑ comment by Measure · 2021-06-09T18:54:02.066Z · LW(p) · GW(p)
Personally, I would use "getFoo" for a function and "foo" for a variable.
Replies from: FeepingCreature↑ comment by FeepingCreature · 2021-06-10T05:58:28.935Z · LW(p) · GW(p)
A variable is just a pure function with no parameters.
↑ comment by Ericf · 2021-06-09T13:07:48.372Z · LW(p) · GW(p)
Huh? Aren't some functions puts? Or calculates?
Replies from: gjm↑ comment by gjm · 2021-06-09T14:25:41.147Z · LW(p) · GW(p)
If a function returns a value then in some sense it's necessarily a get.
Things are more complicated when something both (1) does something and (2) returns a value. E.g., you might put something and then return something that indicates whether it worked or not; you might get something but the process of doing it might update a cache, having (if nothing else) an impact on performance of related future operations.
Some people advocate a principle of "command-query separation": every operation is a "command" that might change the world (and doesn't return anything) or a "query" that gives you some information (but doesn't change anything) but nothing tries to do both at once. (If some commands can fail, you either use an exception-handling mechanism or have related queries for checking whether a command worked.)
That's nice and clean but sometimes inconvenient; the standard example is a "pop" operation on a stack, which both tells you what's on the top of the stack and removes it. (If it's possible that there might be multiple concurrent things operating on the stack at once, you need either to have atomic operations like "pop" or else some explicit mechanism for claiming exclusive access to the stack while you look at its top element and then maybe remove it.)
In the present case, to me "getPromotedPosts" feels ambiguous between (1) "tell me which posts are promoted" and (2) "retrieve the promoted posts from somewhere". If the function is just called "promotedPosts" then that makes it explicit that either it's (1) or it's (2) but the retrieval is an implementation detail you aren't meant to care about, so I think I prefer "promotedPosts" unless there is a retrieval operation involved and it might be expensive or have side effects that matter.
Replies from: Ericf, adamzerner, ChristianKl↑ comment by Ericf · 2021-06-09T15:25:31.897Z · LW(p) · GW(p)
I can see how the choice is architecture dependent. If you can write something like:
Display(promotedPosts()) Display(recentPosts())
having the function be written without a verb makes sense. If you have a multi-tier architecture where you want to cache things locally, the code might have to be: PostList = getPromotedPosts() Append(PostList, getRecentPosts()) ShowOnScreen(PostList)
I would say the distinction is that if a function takes a long time to go look at a database and do some post-processing, we don't want to run around using it like a variable. Especially if the database might change between one use of the data and the next, but we want to keep the results the same. That way, the code can be: PromotedPosts = getPromotedPosts() Display(PromotedPosts) ...user clicks a button Email(PromotedPosts) //this sends the displayed posts, not whatever the promoted one happen to be at that moment
Replies from: gjm↑ comment by gjm · 2021-06-09T16:03:41.558Z · LW(p) · GW(p)
Yes, if it "takes a long time to go look at a database and do some post-processing", that would be a case where (as I put it) "there is a retrieval operation involved and it might be expensive", and then we might want a name that makes it easier to guess that it might be expensive.
↑ comment by Adam Zerner (adamzerner) · 2021-06-09T17:17:24.738Z · LW(p) · GW(p)
Thanks for the explanation here. I didn't know the phrase "command-query separation". It's also helpful to be aware that "pop" is the standard example.
In the present case, to me "getPromotedPosts" feels ambiguous between (1) "tell me which posts are promoted" and (2) "retrieve the promoted posts from somewhere".
I might be in the minority here, but something like promotedPosts feels too much like a variable. It feels awkward to me when the name of a function isn't a verb.
I agree about the ambiguity you point out, and for that reason I don't feel good about the name getPromotedPosts. (Although you could establish a convention where the term "retrieve" or "fetch" is used for database access and "get" is used for situations like this.) I'm just not sure what would be better. I considered filterPromotedPosts, but that kinda sounds like it's impure and is mutating the argument that's passed in. Maybe filterPromotedPosts would be a good name if you're working in a functional language though. It's impossible to do such a mutation in a functional language, so the ambiguity goes away. I think that's an interesting and often overlooked benefit of functional languages.
↑ comment by philh · 2021-06-13T10:36:27.796Z · LW(p) · GW(p)
The other thing about filterPromotedPosts is that it kind of sounds like the input is promoted posts and the output is some unspecified subset of them. filterPostsForPromoted avoids that but starts to feel unwieldy to me. (But maybe I should just be more okay with unwieldy names.)
Even in an impure language I think filter sounds to me like it would return a new list rather than editing in place. That's how the python filter function works for example, and Perl's grep (which is basically a synonym for me), and I had to look this up but JavaScript's filter too.
Replies from: adamzerner↑ comment by Adam Zerner (adamzerner) · 2021-06-13T17:54:22.131Z · LW(p) · GW(p)
The other thing about filterPromotedPosts is that it kind of sounds like the input is promoted posts and the output is some unspecified subset of them. filterPostsForPromoted avoids that but starts to feel unwieldy to me. (But maybe I should just be more okay with unwieldy names.)
I have the exact same feelings here. It's funny how hard this is to name! Although these issues go away if you think about the name as only one part [LW(p) · GW(p)] of the boxes label, and the signature + docstring as the others. Sorta. I think it'd still be nice if the name did as much of the job as possible by itself without having to consult the signature or docstring.
Even in an impure language I think filter sounds to me like it would return a new list rather than editing in place.
In my experience the ideas of functional programming are things that a lot of people just aren't aware of at all. I know that for me it was about seven years into my journey as a programmer before I started learning about them. Thinking about the people I have and do work with, I could very well see them using filterPromotedPosts to mutate a list of posts. So in that environment, it seems like it'd be nice to make it extra clear that "this function isn't actually mutating anything". (Then again, I could also see them mutating stuff in getPromotedPosts too.)
But in a different environment where the convention of "filter" being pure is strong enough, I agree with you. And I think that it'd often make sense to aspire towards this sort of environment. It's interesting how much the right name depends on this sort of context.
↑ comment by ChristianKl · 2021-06-09T16:58:57.387Z · LW(p) · GW(p)
To me getPromotedPosts() contains the idea that the function won't run a neural model to decide which post should be promoted or load information from the internet but return to me data that's already available in the program. On the other hand promotedPosts() feels unclear about that.
I'm curious whether other people have the same intuition here.
Replies from: gjm↑ comment by gjm · 2021-06-09T19:20:14.880Z · LW(p) · GW(p)
My intuition says that
- if it's called getPromotedPosts then it is probably fetching some information from somewhere -- maybe the internet, maybe a database -- and probably isn't doing any computation to speak of;
- if it's called promotedPosts then it is probably either computing something or just using a value it already knows and can return quickly and easily.
I am not sure there's any function name that would be perfectly neutral between (1) extremely cheap operation, probably just returning something already known, (2) nontrivial calculation, and (3) nontrivial fetching.
There's also a bit of ambiguity about whether something called getPromotedPosts is fetching the posts themselves or just cheap representations of them (e.g., ID numbers, pointers, etc.).
So I might consider names like fetchPromotedPostIDsFromDatabase, retrievePromotedPostContent, inferPromotedPostsByModel, cachedPromotedPostList, etc. Or I might prefer a brief name like promotedPosts and put information about what it does and the likely performance implications in a comment, docstring, etc.