LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
How long does the Elta MD sunscreen last?
startattheend on dkornai's ShortformI think all criticism, all shaming, all guilt tripping, all punishments and rewards directed at children - is for the purpose of driving them to do certain actions. If your children do what you think is right, there's no need to do much of anything.
A more general and correct statement would be "Pain is for the sake of change, and all change is painful". But that change is for the sake of actions. I don't think that's too much of a simplification to be useful.
I think regret, too, is connected here. And there's certainly times when it seems like pain is the problem rather than an attempt to solve it, but I think that's a misunderstanding. And while chronic pain does reduce agency, it's a constant pain and a constant reduction of agency (not cumulative). The pain persists until the problem is solved, even if the problem does not get worse. So it's the body telling the brain "Hey, do something about this, the importance is 50 units of pain", then you will do anything to solve it as long there's a path with less than 50 units of pain which leads to a solution.
The pain does limit agency, but not because it's a real limitation. It's an artificial one that the body creates to prevent you from damaging yourself. So all important agency is still possible. If the estimated consequences of avoiding the task is more painful than doing the task, you do it. But it's again the body is just estimating the cost/benefit of tasks and choosing the optimal action by making it the least painful action.
My explanation and yours are almost identical, but there's some important differences. In my view,
suffering is good, not bad. I really don't want humanity to misunderstand this one fact, it has already had profound negative consequences. It's phantom damage created to avoid real damage. An agent which is unable to feel physical pain and exhaustion would destroy itself, therefore physical pain and exhaustion are valuable and not problems to be solved. Emotions like suffering, exhaustion, annoyance, etc. function the same as physical pain, and once they get over a certain threshold they coerce you into taking an action. Physical pain comes from nerves, but emotional pain comes from your interpretation of reality. Your brain relies on you to tell what ought to be painful (so if you overestimate risk, it just believes you). And you don't get to choose all your goals yourself, your brain wants you to fulfill your needs (prioritized by the hierarchy of needs). In short, the brain makes inaction painful, while keeping actions that it deems risky painful, and then messes with the weights/thresholds according to need. Just like with hunger (not eating is painful, but if all you have is stale or even moldy bread, then you need to be very hungry before you eat, and you will eat iff pain(hunger)>pain(eating the bread)).
An increase in power/agency feels a lot like happiness though, even according to Nietzsche who I'm not confident to argue against, so I get why you'd basically think that opposite of happiness is the opposite of agency (sorry if this summary does injustice to your point)
cameron-berg on Key takeaways from our EA and alignment research surveysThere's a lot of overlap between alignment researchers and the EA community, so I'm wondering how that was handled.
Agree that there is inherent/unavoidable overlap. As noted in the post, we were generally cautious about excluding participants from either sample for reasons you mention and also found that the key results we present here are robust to these kinds of changes in the filtration of either dataset (you can see and explore this for yourself here).
With this being said, we did ask in both the EA and the alignment survey to indicate the extent to which they are involved in alignment—note the significance of the difference here:
From alignment survey:
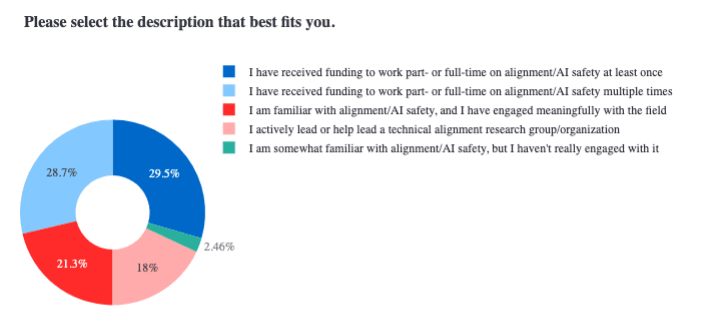
From EA survey:

This question/result serves both as a good filtering criterion for cleanly separating out EAs from alignment researchers and also gives a pretty strong evidence that we are drawing on completely different samples across these surveys (likely because we sourced the data for each survey through completely distinct channels).
Regarding the support for various cause areas, I'm pretty sure that you'll find the support for AI Safety/Long-Termism/X-risk is higher among those most involved in EA than among those least involved. Part of this may be because of the number of jobs available in this cause area.
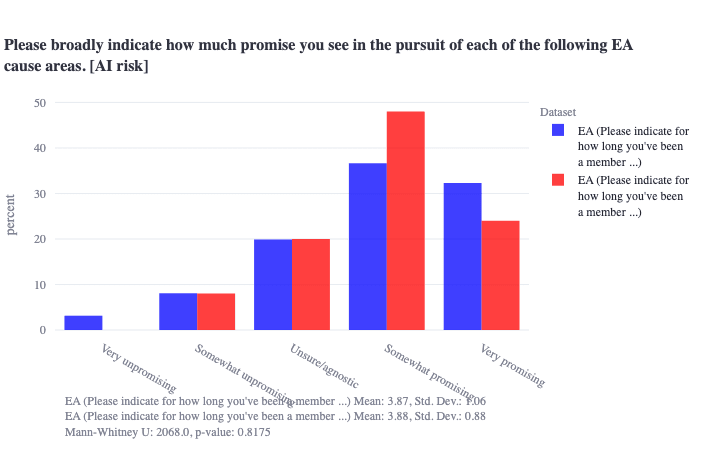
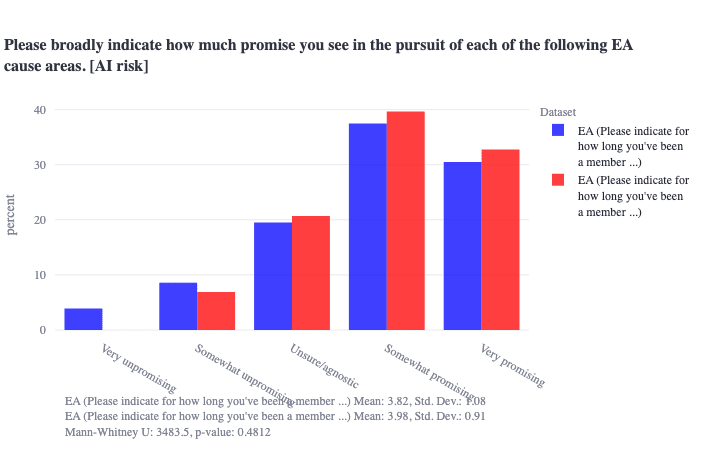
Interesting—I just tried to test this. It is a bit hard to find a variable in the EA dataset that would cleanly correspond to higher vs. lower overall involvement, but we can filter by number of years one has been involved involved in EA, and there is no level-of-experience threshold I could find where there are statistically significant differences in EAs' views on how promising AI x-risk is. (Note that years of experience in EA may not be the best proxy for what you are asking, but is likely the best we've got to tackle this specific question.)
Blue is >1 year experience, red is <1 year experience:
Blue is >2 years experience, red is <2 years experience:
„Whether or not your probability model leads to optimal descision making is the test allowing to falsify it.“
Sure, I don‘t deny that. What I am saying is, that your probability model doesn‘t tell you which probability is relevant for a certain decision. If you can derive a probability from your model and provide a good reason to consider this probability as relevant to your decision, your model is not falsified as long you arrive at the right decision this way.
Suppose a simple experiment where the experimenter flips a fair coin and you have to guess if Tails or Heads, but you are only rewarded for the correct answer if the coin comes up Tails. Then, of course, you should still entertain unconditional probabilities P(Heads)=P(Tails)=1/2. But this uncertainty is completely irrelevant to your decision. What is relevant, however, is P(Tails/Tails)=1 and P(Heads/Tails)=0, concluding you should follow the strategy always guessing Tails. Another way to deduce this strategy is to calculate expected utilities setting U(Heads)=0 as you would propose. But this is not the only permissible solution. It’s just a different route of reasoning to take into account the experimental condition that your answer „counts“ only if the coin lands Tails.
Technicolor Beauty:
„The model says that P(Heads|Red) = 1/3 P(Heads|Blue) = 1/3 but P(Heads|Red or Blue) = 1/2 Which obviosly translates in a betting scheme: someone who bets on Tails only when the room is Red wins 2/3 of times and someone who bets on Tails only when the room is Blue wins 2/3 of times, while someone who always bet on Tails wins only 1/2 of time.“
I don‘t agree that these probabilities obviously translate into the betting sheme you are proposing. A plausible translation of the probabilities is:
P(Heads/Red)=1/3: If your total evidence is Red, then you should entertain probability 1/3 for Heads. P(Heads/Blue)=1/3: If your total evidence is Blue, then you should entertain probability 1/3 for Heads. P(Heads/Red or Blue)=1/2: If your total evidence is Red or Blue, which is the case if you know that either red or blue or both, but not which exactly, you should entertain probalitity 1/2 for Heads.
This is all your model tells you and if you strictly follow it you will arrive at the final conclusion that the probability of Heads is 1/3 in every single experimental run of the Technicolor Beauty version, thus violating the Reflection Principle.
Why is this? Notice that the strategy „update probalitity only if observing Red“ is the best strategy only for an agent who is suffering from memory loss and that an agent whose memory is not erased would not violate Reflection Principle. What‘s the difference between the agent with and without memory loss when applying your model? Well, the agent without memory loss can (when awoken in the course of the experiment) only have total evidence „Red“ (first awakening) or „Red and Blue“ (if there is a second awakening). Or he can have total evidence „Blue“ or „Blue and Red“. But it is impossible for him to have total evidence of both „Red“ and „Blue“ alone within same experimental run, which is only possible for an agent who is affected by memory loss. This makes the agent with memory loss vulnerable for violation of Reflection which he can avoid following your strategy that is basically ignoring total evidence in order to eliminate the effects of memory loss. You can think of your strategy as if Beauty aims to simulate another experiment within the setting of the Technicolor Experiment. In this simulated experiment, she is awoken only if the room is red and so no memory loss occurs. This „simulation approach“ is one way your model can be used to deal with memory loss effects but it does not capture them. It cannot even tell you that they exist. Without knowing that she is affected by memory loss Beauty cannot deduce such a strategy.
„This leads to a conclusion that observing event "Red" instead of "Red or Blue" is possible only for someone who has been expecting to observe event "Red" in particular. Likewise, observing HTHHTTHT is possible for a person who was expecting this particular sequence of coin tosses, instead of any combination with length 8. See Another Non-Anthropic Paradox: The Unsurprising Rareness of Rare Events“
I have already refuted this argument in the comments.
dalcy on Dalcy's ShortformThoughtdump on why I'm interested in computational mechanics:
citric acid and a polymer
ryan_greenblatt on "AI Safety for Fleshy Humans" an AI Safety explainer by Nicky CaseRandom error:
Exponential Takeoff:
AI's capabilities grow exponentially, like an economy or pandemic.
(Oddly, this scenario often gets called "Slow Takeoff"! It's slow compared to "FOOM".)
Actually, this isn't how people (in the AI safety community) generally use the term slow takeoff.
Quoting from the blog post by Paul:
Futurists have argued for years about whether the development of AGI will look more like a breakthrough within a small group (“fast takeoff”), or a continuous acceleration distributed across the broader economy or a large firm (“slow takeoff”).
[...]
(Note: this is not a post about whether an intelligence explosion will occur. That seems very likely to me. Quantitatively I expect it to go along these lines. So e.g. while I disagree with many of the claims and assumptions in Intelligence Explosion Microeconomics, I don’t disagree with the central thesis or with most of the arguments.)
Slow takeoff still (can) involve a singularity (aka an intelligence explosion).
The terms "fast/slow takeoff" are somewhat bad because they are often used to discuss two different questions:
And this explainer introduces a third idea:
Done and fixed the accidental pronoun.
joseph-miller on Why I'm doing PauseAIWhile I want people to support PauseAI
the small movement that PauseAI builds now will be the foundation which bootstraps this larger movement in the future
Is one of the main points of my post. If you support PauseAI today you may unleash a force which you cannot control tomorrow.
chris_leong on Key takeaways from our EA and alignment research surveysThere's a lot of overlap between alignment researchers and the EA community, so I'm wondering how that was handled.
It feels like it would be hard to find a good way of handling it: if you include everyone who indicated an affiliation with EA on the alignment survey it'd tilt the survey towards alignment people, in contrast if you exclude them then it seems likely it'd tilt the survey away from alignment people since people will be unlikely to fill in both surveys.
Regarding the support for various cause areas, I'm pretty sure that you'll find the support for AI Safety/Long-Termism/X-risk is higher among those most involved in EA than among those least involved. Part of this may be because of the number of jobs available in this cause area.