LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
Oh nice! My retinoid formula and moisturizer have hyaluronic acid mixed in so it's hard for me to isolate its effects, but a lot of people seem to find it hugely beneficial
seth-herd on An explanation of evil in an organized worldYeah. Well, since It was addressing a tribe of nomadic herders in prehistoric times, that in itself is a good thing :)
dx26 on Coherence of Caches and AgentsIt might be relevant to note that the meaningfulness of this coherence definition depends on the chosen environment. For instance, in an deterministic forest MDP where an agent at a state can never return to for any and there is only one path between any two states, suppose we have a deterministic policy and let , , etc. Then for the zero-current-payoff Bellman equations, we only need that for any successor from , for any successor from , etc. We can achieve this easily by, for example, letting all values except be near-zero; since is a successor of iff (as otherwise there would be a cycle), this fits our criterion. Thus, every is coherent in this environment. (I haven't done the explicit math here, but I suspect that this also works for non-deterministic and non-stochastic MDPs.)
Importantly, using the common definition of language models in an RL setting where each state represents a sequence of tokens and each action adds a token to the end of a sequence of length to produce a sequence of length , the environment is a deterministic forest, as there is only one way to "go between" two sequences (if one is a prefix of the other, choose the remaining tokens in order). Thus, any language model is coherent, which seems unsatisfying. We could try using a different environment, but this risks losing stochasticity (as the output logits of an LM is determined by its input sequence) and gets complicated pretty quickly (use natural abstractions/world model as states?).
viliam on Viliam's ShortformI suspect that in practice many people use the word "prioritize" to mean:
“For my thoughts are not your thoughts, neither are your ways my ways,” declares the Lord.
-- Isaiah 55:8
This probably also implies: "your values are not my values".
chris_leong on Please stop publishing ideas/insights/research about AIIn contrast, this almost makes it sound like you think it is plausible to align AI to its user's intent, but that this would be bad if the users aren't one of "us"—you know, the good alignment researchers who want to use AI to take over the universe, totally unlike those evil capabilities researchers who want to use AI to produce economically valuable goods and services.
If I'm being honest, I don't find this framing helpful.
If you believe that things will go well if certain actors gain access to advanced AI technologies first, you should directly argue that.
Focusing on status games feels like a red herring.
You can’t just trivially scale up the angular resolution by bolting more sensors together (or similar methods). It gets more difficult to engineer the lenses and sensors to meet super-high specs.
And aside from that, the problem behaves nonlinearly with the amount of atmosphere between you and the plane. Each bit of distortion in the air along the way will combine, potentially pretty harshly limiting how far away you can get any useful image. This may be able to be worked around with AI to reconstruct from highly distorted images, but it’s far from trivial on the face of it.
olli-jaerviniemi on On precise out-of-context steeringThe digits given by the model are wrong (one has e*sqrt(3) ~4.708). Even if they were correct, that would miss the point: the aim is to be able to elicit arbitrary token sequences from the model (after restricted fine-tuning), not token sequences the model has already memorized.
The problem is not "it's hard to get any >50 digit sequence out of GPT-3.5", but "it's hard to make GPT-3.5 precisely 'stitch together' sequences it already knows".
nim on Which skincare products are evidence-based?"Minimize excessive UV exposure" is the steelman to the pro-sunscreen arguments. The evidence against tanning beds demonstrates that excess UV is almost certainly harmful.
I think where the pro-sunscreen arguments go wrong is in assuming that sunscreen is the best or only way to minimize excess UV.
I personally don't have what it takes to use sunscreen "correctly" (apply every day, "reapply every 2 hours", tolerate the sensory experience of smearing anything on my face every day, etc) so I mitigate UV exposure in other ways:
I appreciate this response because it stirred up a lot of possible responses, in me, in lots of different directions, that all somehow seems germane to the core goal of securing a Win Conditions for the sapient metacivilization of earth! <3
(A) Physical reality is probably hyper-computational, but also probably amenable to pulling a nearly infinite stack of "big salient features" from a reductively analyzable real world situation.
My intuition says that this STOPS being "relevant to human interests" (except for modern material engineering and material prosperity and so on) roughly below the level of "the cell".
Other physics with other biochemistry could exist, and I don't think any human would "really care"?
Suppose a Benevolent SAI had already replaced all of our cells with nanobots without our permission AND without us noticing because it wanted to have "backups" or something like that...
(The AI in TMOPI does this much less elegantly, because everything in that story is full of hacks and stupidity. The overall fact that "everything is full of hacks and stupidity" is basically one of the themes of that novel.)
Contingent on a Benevoent SAI having thought it had good reason to do such a thing, I don't think that once we fully understand the argument in favor of doing it that we would really have much basis for objecting?
But I don't know for sure, one way or the other...
((To be clear, in this hypothetical, I think I'd volunteer to accept the extra risk to be one of the last who was "Saved" this way, and I'd volunteer to keep the secret, and help in a QA loop of grounded human perceptual feedback, to see if some subtle spark of magical-somethingness had been lost in everyone transformed this way? Like... like hypothetically "quantum consciousness" might be a real thing, and maybe people switched over to running atop "greygoo" instead of our default "pinkgoo" changes how "quantum consciousness" works and so the changeover would non-obviously involve a huge cognitive holocaust of sorts? But maybe not! Experiments might be called for... and they might need informed consent? ...and I think I'd probably consent to be in "the control group that is unblinded as part of the later stages of the testing process" but I would have a LOT of questions before I gave consent to something Big And Smart that respected "my puny human capacity to even be informed, and 'consent' in some limited and animal-like way".))
What I'm saying is: I think maybe NORMAL human values (amongst people with default mental patterns rather than weirdo autists who try to actually be philosophically coherent and ended up with utility functions that have coherently and intentionally unbounded upsides) might well be finite, and a rule for granting normal humans a perceptually indistinguishable version of "heaven" might be quite OK to approximate with "a mere a few billion well chosen if/then statements".
To be clear, the above is a response to this bit:
As such, I think the linear separability comes from the power of the "lol stack more layers" approach, not from some intrinsic simple structure of the underlying data. As such, I don't expect very much success for approaches that look like "let's try to come up with a small set of if/else statements that cleave the categories at the joints instead of inelegantly piling learned heuristics on top of each other".
And:
I don't think that such a model would succeed because it "cleaves reality at the joints" though, I expect it would succeed because you've managed to find a way that "better than chance" is good enough and you don't need to make arbitrarily good predictions.
Basically, I think "good enough" might be "good enough" for persons with finite utility functions?
(B) A completely OTHER response here is that you should probably take care to NOT aim for something that is literally mathematically impossible...
Unless this is part of some clever long term cognitive strategy, where you try to prove one crazy extreme, and then its negation, back and forth, as a sort of "personally implemented GAN research process" (and even then?!)...
...you should probably not spend much time trying to "prove that 1+1=5" nor try to "prove that the Halting Problem actually has a solution". Personally, any time I reduce a given plan to "oh, this is just the Halting Problem again" I tend to abandon that line of work.
Perfectly fine if you're a venture capitalist, not so great if you're seeking adversarial robustness.
Past a certain point, one can simply never be adversarially robust in a programmatic and symbolically expressible way.
Humans would have to have non-Turing-Complete souls, and so would any hypothetical Corrigible Robot Saint/Slaves [? · GW], in order to literally 100% prove that literally infinite computational power won't find a way to make things horrible.
There is no such thing as a finitely expressible "Halt if Evil" algorithm...
...unless (I think?) all "agents" involved are definitely not Turing Complete and have no emotional attachments to any questions whose answers partake of the challenges of working with Turing Complete systems? And maybe someone other than me is somehow smart enough to write a model of "all the physics we care about" and "human souls" and "the AI" all in some dependently typed language that will only compile if the compiler can generate and verify a "proof that each program, and ALL programs interacting with each other, halt on all possible inputs"?
My hunch is that that effort will fail, over and over, forever, but I don't have a good clean proof that it will fail.
Note that I'm pretty sure A and B are incompatible takes.
In "take A" I'm working from human subjectivity "down towards physics (through a vast stack of sociology and biology and so on)" and it just kinda seems like physics is safe to throw away because human souls and our humanistically normal concerns are probably mostly pretty "computational paltry" and merely about securing food, and safety, and having OK romantic lives?
In "take B" I'm starting with the material that mathematicians care about, and noticing that it means the project is doomed if the requirement is to have a mathematical proof about all mathematically expressible cares or concerns.
It would be... kinda funny, maybe, to end up believing "we can secure a Win Condition for the Normies (because take A is basically true), but True Mathematicians are doomed-and-blessed-at-the-same-time to eternal recursive yearning and Real Risk (because take B is also basically true)" <3
(C) Chaos is a thing! Even (and especially) in big equations, including the equations of mind that big stacks of adversarially optimized matrices represent!
This isn't a "logically deep" point. I'm just vibing with your picture where you imagine that the "turbulent looking" thing is a metaphor for reality.
In observable practice, the boundary conditions of the equations of AI also look like fractally beautiful turbulence!
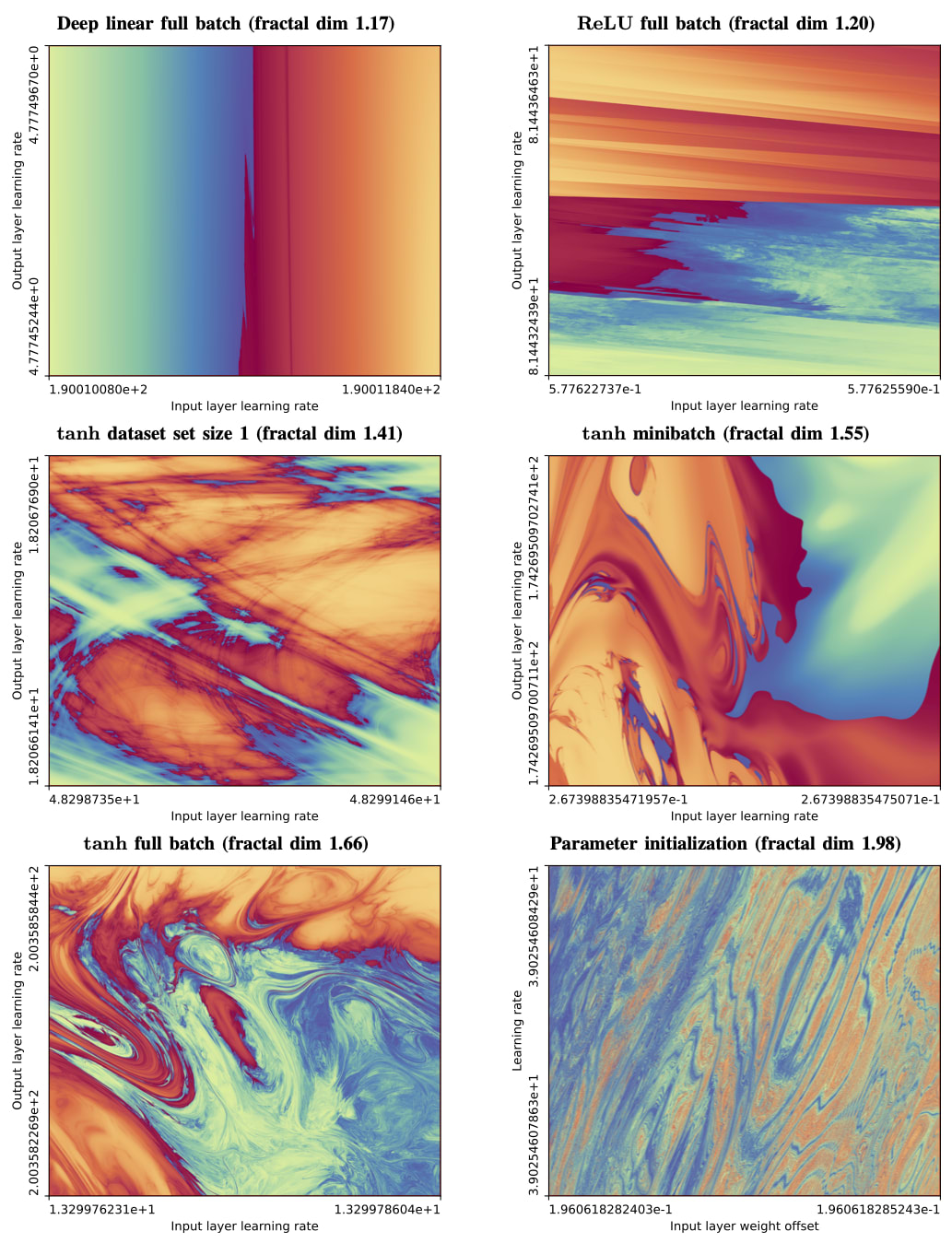
I predict that you will be surprised by this empirical result. Here is the "high church papering" of the result:
TITLE: The boundary of neural network trainability is fractal
Abstract: Some fractals -- for instance those associated with the Mandelbrot and quadratic Julia sets -- are computed by iterating a function, and identifying the boundary between hyperparameters for which the resulting series diverges or remains bounded. Neural network training similarly involves iterating an update function (e.g. repeated steps of gradient descent), can result in convergent or divergent behavior, and can be extremely sensitive to small changes in hyperparameters. Motivated by these similarities, we experimentally examine the boundary between neural network hyperparameters that lead to stable and divergent training. We find that this boundary is fractal over more than ten decades of scale in all tested configurations.
Also, if you want to deep dive on some "half-assed peer review of this work" hacker news chatted with itself about this paper at length.