LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
That's it! Thank you.
quetzal_rainbow on Biorisk is an Unhelpful Analogy for AI RiskPathogens, whether natural or artificial, have a fairly well-defined attack surface; the hosts’ bodies. Human bodies are pretty much static targets, are the subject of massive research effort, have undergone eons of adaptation to be more or less defensible, and our ability to fight pathogens is increasingly well understood.
It's certainly not true. Pathogen can target agriculture or ecosystems.
nerowolfe on Effective Altruism Miami - Crispr'ing Green YeastI hope you market it under the name Soylent.
adamzerner on adamzerner's ShortformI was envisioning that you can organize a festival incrementally, investing more time and money into it as you receive more and more validation, and that taking this approach would de-risk it to the point where overall, it's "not that risky".
For example, to start off you can email or message a handful of potential attendees. If they aren't excited by the idea you can stop there, but if they are then you can proceed to start looking into things like cost and logistics. I'm not sure how pragmatic this iterative approach actually is though. What do you think?
Also, it seems to me that you wouldn't have to actually risk losing any of your own money. I'd imagine that you'd 1) talk to the hostel, agree on a price, have them "hold the spot" for you, 2) get sign ups, 3) pay using the money you get from attendees.
Although now that I think about it I'm realizing that it probably isn't that simple. For example, the hostel cost ~$5k and maybe the money from the attendees would have covered it all but maybe less attendees signed up than you were expecting and the organizers ended up having to pay out of pocket.
On the other hand, maybe there is funding available for situations like these.
cameron-berg on Key takeaways from our EA and alignment research surveysThanks for all these additional datapoints! I'll try to respond all of your questions in turn:
Did you find that your AIS survey respondents with more AIS experience were significantly more male than newer entrants to the field?
Overall, there don't appear to be major differences when filtering for amount of alignment experience. When filtering for greater than vs. less than 6 months of experience, it does appear that the ratio looks more like ~5 M:F; at greater than vs. less than 1 year of experience, it looks like ~8 M:F; the others still look like ~9 M:F. Perhaps the changes you see over the past two years at MATS are too recent to be reflected fully in this data, but it does seem like a generally positive signal that you see this ratio changing (given what we discuss [LW · GW] in the post).
Has AE Studio considered sponsoring significant bounties or impact markets for scoping promising new AIS research directions?
We definitely want to do everything we can to support increased exploration of neglected approaches—if you have specific ideas here, we'd love to hear them and discuss more! Maybe we can follow up offline on this.
Did survey respondents mention how they proposed making AIS more multidisciplinary? Which established research fields are more needed in the AIS community?
We don't appear to have gotten many practical proposals for how to make AIS more multidisciplinary, but there were a number of specific disciplines mentioned in the free responses, including cognitive psychology, neuroscience, game theory, behavioral science, ethics/law/sociology, and philosophy (epistemology was specifically brought up across multiple respondents). One respondent wrote, "AI alignment is dominated by computer scientists who don't know much about human nature, and could benefit from more behavioral science expertise and game theory," which I think captures the sentiment of many of the related responses most succinctly (however accurate this statement actually is!). Ultimately, encouraging and funding research at the intersection of these underexplored areas and alignment is likely the only thing that will actually lead to a more multidisciplinary research environment.
Did EAs consider AIS exclusively a longtermist cause area, or did they anticipate near-term catastrophic risk from AGI?
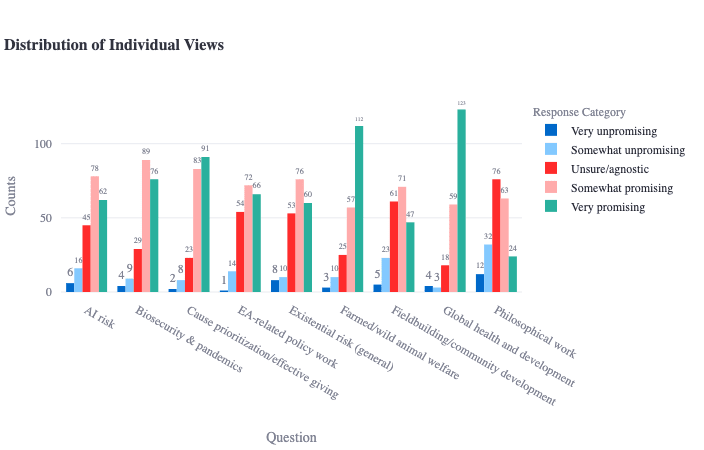
Unfortunately, I don't think we asked the EA sample about AIS in a way that would allow us to answer this question using the data we have. This would be a really interesting follow-up direction. I will paste in below the ground truth distribution of EAs' views on the relative promise of these approaches as additional context (eg, we see that the 'AI risk' and 'Existential risk (general)' distributions have very similar shapes), but I don't think we can confidently say much about whether these risks were being conceptualized as short- or long-term.
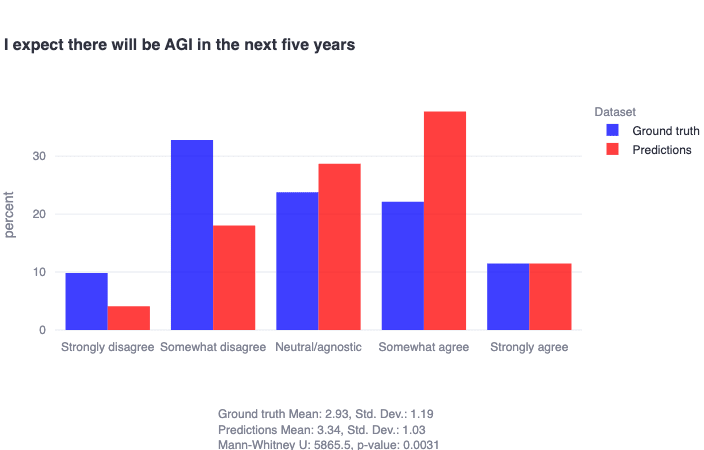
It's also important to highlight that in the alignment sample (from the other survey), researchers generally indicate that they do not think we're going to get AGI in the next five years. Again, this doesn't clarify if they think there are x-risks that could emerge in the nearer term from less-general-but-still-very-advanced AI, but it does provide an additional datapoint that if we are considering AI x-risks to be largely mediated by the advent of AGI, alignment researchers don't seem to expect this as a whole in the very short term:
The cancer must develop neoantigens that are sufficiently distinct from human surface proteins and consistent across the cancer.
This is not necessarily true. There are some proteins that get produced by embryos and not by adult humans. Sometimes cancer mutates in a way that those proteins get produced by cancer cells.
While the vaccines that target a single of those embryo proteins did not do enough in clinical trials, I don't see a reason why we should completely ignore those proteins.
Cancer cells must be isolated and have their surface proteins characterized.
Given that cancer cells engage in necrososis much more than regular cells you don't need to isolate cancer cells to get the DNA of cancer. ctDNA can in theory be used to sequence the cancer. Using ctDNA might even be better because it gives you a better idea of whether a mutation is present in most of the cancer cells or only the section from which you removed cells.
Individualized cancer vaccines are not yet practical
Moderna has just put an individualized cancer vaccine into a phase III trial after positive results from a phase 2b trial:
Hirawat was referring to Moderna and Merck’s December announcement of positive results from a 157-patient phase 2b trial dubbed KEYNOTE-942. The pair said a combination of their personalized mRNA cancer vaccine, coded mRNA-4157 or V940, and the PD-1 inhibitor Keytruda slashed the risk of tumor recurrence or death by 44% compared with Keytruda alone when used as an adjuvant therapy in stage 3/4 melanoma following complete surgical resection.
Do you think that trial is a bad idea?
kave on Effective Altruism Miami - Crispr'ing Green YeastWhoa! The meetup to beat
quila on Rapid capability gain around supergenius level seems probable even without intelligence needing to improve intelligenceI hadn't considered this argument, thanks for sharing it.
It seems to rest on this implicit piece of reasoning:
(premise 1) If modelling human intelligence as a normal distribution, it's statistically more probable that the most intelligent human will only be so by a small amount.
(premise 2) One of the plausibly most intelligent humans was capable of doing much better than other highly intelligent humans in their field.
(conclusion) It's probable that past some threshold, small increases in intelligence lead to great increases in output quality.
It's ambiguous what 'intelligence' refers to here if we decouple that word from the quality of insight one is capable of. Here's a way of re-framing this conclusion to make it more quantifiable/discussable: "Past some threshold, as a system's quality of insight increases, the optimization required (for evolution or a training process) to select for a system capable of greater insight decreases".
The level this becomes true at would need to be higher than any AI's so far, otherwise we would observe training processes easily optimizing these systems into superintelligences instead of loss curves stabilizing at some point above 0.
I feel uncertain whether there are conceptual reasons (priors) for this conclusion being true or untrue.
I'm also not confident that human intelligence is normally distributed in the upper limits, because I don't expect there are known strong theoretical reasons to believe this.
Overall it seems at least a two digit probability given the plausibility of the premises.
4gate on Mechanistically Eliciting Latent Behaviors in Language ModelsMaybe a dumb question but (1) how can we know for sure if we are on manifold, (2) why is it so important to stay on manifold? I'm guessing that you mean that vaguely we want to stay within the space of possible activations induced by inputs from data that is in some sense "real-world." However, there appear to be a couple complications: (1) measuring distributional properties of later layers from small to medium sized datasets doesn't seem like a realistic estimate of what should be expected of an on-manifold vector since it's likely later layers are more semantically/high-level focused and sparse; (2) what people put into the inputs does change in small ways simply due to new things happening in the world, but also there are prompt engineering attacks that people use that are likely in some sense "off-distribution" but still in the real world and I don't think we should ignore these fully. Is this notion of a manifold a good way to think about the notion of getting indicative information of real world behavior? Probably, but I'm not sure so I thought I might ask. I am new to this field.
I do thing at the end of the day we want indicative information, so I think somewhat artifical environments might at times have a certain usefulness.
Also one convoluted (perhaps inefficient) idea but which felt kind of fun to stay on manifold is to do the following: (1) train your batch of steering vectors, (2) optimize in token space to elicit those steering vectors (i.e. by regularizing for the vectors to be close to one of the token vectors or by using an algorithm that operates on text), (3) check those tokens to make sure that they continue to elicit the behavior and are not totally wacky. If you cannot generate that steer from something that is close to a prompt, surely it's not on manifold right? You might be able to automate by looking at perplexity or training a small model to estimate that an input prompt is a "realistic" sentence or whatever.
Curious to hear thoughts :)
steve2152 on Does reducing the amount of RL for a given capability level make AI safer?I have to admit that I'm struggling to find these arguments at the moment
I sometimes say things kinda like that, e.g. here.