Evaluating the truth of statements in a world of ambiguous language.
post by Hastings (hastings-greer) · 2024-10-07T18:08:09.920Z · LW · GW · 19 commentsContents
19 comments
If I say "the store is 500 meters away," [LW · GW] is this strictly true? Strictly false? Either strictly true or strictly false, with probabilies of true or false summing to one? Fuzzily true, because the store is 500.1 meters away? My thesis is that it's strictly true or strictly false, with associated probabilities. Bear with me.
The 500 meter example is pretty hard to reason about numerically. I am hopeful that I can communicate my thoughts by starting with an example that is in some sense simpler.
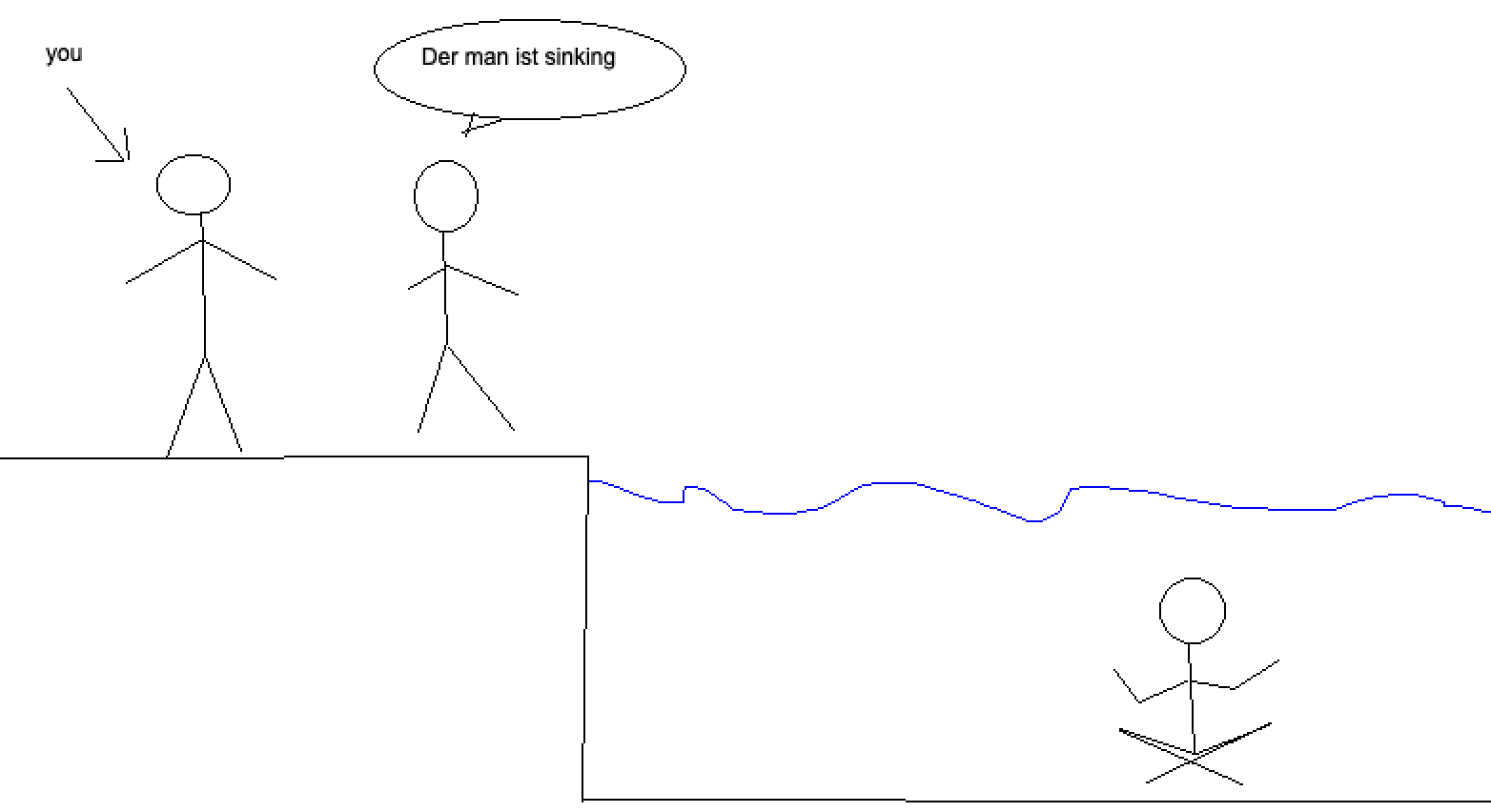
Is our conversational partner making a true statement or a false statement? What we're used to is starting with a prior over worlds, and then updating our belief based on observations- the man is underwater, the man is currently moving downwards. So our belief that the man is sinking should be pretty high.
However, what we are unsure of is the language of the sentence. If it's German¹, then it means¹ "the man is pensive." Then, evaluating the truth value of the sentence is going to involve a different prior- Does the man look deep in thought? He seems to have a calm expression, and is sitting cross legged, which is weak evidence. More consideration is needed.
To come out to an actual probability of the original sentence being true, we need a distribution of possible intended meanings for the sentence, and then likelyhoods of the truthfulness of each meaning. If you buy my framing of the situation, then in this case it's simply P(Sentence is English) x P(Man is sinking) + P(Sentence of is German) x P(Man is thoughtful).
In the monolingual case, it's easy to get caught up in lingual proscriptivism. If someone uses a word wrong, and their sentence is only true when it's interpreted using the incorrect definition, then a common claim is that their sentence is untrue. A classic example of this is "He's literally the best cook ever." I hope that the multilingual case illustrates that ambiguity in the meaning of phrases doesn't have to come from uncareful sentence construction or "wrong" word use.
I claim that there's just always a distribution over meanings, and it can be sharp or fuzzy or bimodal or any sort of shape. Of course, as a listener you can update this distribution based on evidence just like anything else. As a speaker, you can work to keep this distribution sharp as an aid to those you speak with, though total success is impossible.
To directly engage with the examples from the post: The statement "the store is 500 meters away" has a pretty broad and intractable distribution of meanings, but the case where
* The meaning was "The store is 500 meter away, to exact platonic accuracy"
* The store was actually a different distance, such as a value between 510.1 and 510.2 meters.
contributes only a vanishingly small amount to the odds that the statement was false.
Another case where
* The meaning was "The store is 500 meters away to a precision of 1 meter"
* The store is actually 503 meters away
contributes little to the odds that the statement was false, but contributes more if for example the speaker is holding a laser rangefinder. Odds of meanings update just like odds of world states.
For another example,
A: Is there any water in the refrigerator?
B: Yes.
A: Where? I don’t see it.
B: In the cells of the eggplant.
There is a real distribution of meanings for the statement "Yes." Our prior that A and B are effectively communicating starts low, but it is happy to rapidly increase if we recieve information like "A is deciding whether to store this calcium carbide in the refrigerator."
In my view, and assuming some sort of natural abstraction hypothesis, statements like "Every point on a sphere is equally distant from the center" are special because a significant part of their meaning is concentrated in little dirac deltas in meaning space. They are still allowed to be ambiguous or even fuzzy with some probability, but they also have a real chance of being precise.
¹ Admittedly broken German, with apologies. I possibly could come up with a better example, but I already had a great deal of time sunk into the illustration.
19 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-10-08T04:58:41.522Z · LW(p) · GW(p)
This is a solid and to-the-point explanation of the basic Bayesian approach to the problem. Thank you for writing it up.
comment by abramdemski · 2024-10-08T17:55:33.583Z · LW(p) · GW(p)
I argue that meanings are fundamentally fuzzy [LW(p) · GW(p)]. In the end, we can interpret things your way, if we think of fuzzy truth-values as sent to "true" or "false" based on an unknown threshhold (which we can have a probability distribution over). However, it is worth noting that the fuzzy truth-values can be logically coherent in a way that the true-false values cannot: the fuzzy truth predicate is just an identity function (so "X is true" has the same fuzzy truth-value as "X"), and this allows us to reason about paradoxical sentences in a completely consistent way (so the self-referential sentence "this sentence is not true" is value 1/2). But when we force things to be true or false, the resulting picture must violate some rules of logic ("this sentence is not true" must either be true or false, neither of which is consistent with classical logic's rules of reasoning).
Digging further into your proposal, what makes a sentence true or false? It seems that you suppose a person always has a precise meaning in mind when they utter a sentence. What sort of object do you think this meaning is? Do you think it is plausible, say, that the human uttering the sentence could always say later whether it was true or false, if given enough information about the world? Or is it possible that even the utterer could be unsure about that, even given all the relevant facts about how the world is? I think even the original utterer can remain unsure -- but then, where does the fact-of-the-matter reside?
For example, if I claim something is 500 meters away, I don't have a specific range in mind. I'll know I was correct if more accurate measurement establishes that it's 500.001 meters away. I'll know I was incorrect if it turns out to be 10 meters away. However, there will be some boundary where I will be inclined to say my intended claim was vague, and I "fundamentally" don't know -- I don't think there was a fact of the matter about the precise range I intended with my statement, beyond some level of detail.
So, if you propose to model this no-fact-of-the-matter as uncertainty, what do you propose it is uncertain about? Where does this truth reside, and how would it be checked/established?
Replies from: cubefox↑ comment by cubefox · 2024-10-08T19:41:03.644Z · LW(p) · GW(p)
(I agree with your argument about vagueness, but regarding the first paragraph: I wouldn't use the 1/2 solution to the liar paradox as an argument in favor or fuzzy truth values. This is because even with them we still get a "revenge paradox" when we use a truth predicate that explicitly refers to some specific fuzzy truth value. E.g. "this sentence is exactly false" / "this sentence has truth value exactly 0". If the sentence has truth value exactly 0, it is exactly true, i.e. has truth value exactly 1. Which is a contradiction. In fact, we get an analogous revenge paradox for all truth predicates "has truth value exactly x" where x is any number between 0 and 1, excluding 1. E.g. x=0.7, and even x=0.5. In a formal system of fuzzy logic we can rule out such truth predicates, but we clearly can't forbid them in natural language.)
Replies from: abramdemski↑ comment by abramdemski · 2024-10-08T20:03:45.594Z · LW(p) · GW(p)
Any solution to the semantic paradoxes must accept something counterintuitive. In the case of using something like fuzzy logic, I must accept the restriction that valid truth-functions must be continuous (or at least Kakutani). I don't claim this is the final word on the subject (I recognize that fuzzy logic has some severe limitations; I mostly defer to Hartry Field on how to get around these problems). However, I do think it captures a lot of reasonable intuitions. I would challenge you to name a more appealing resolution.
Replies from: cubefox↑ comment by cubefox · 2024-10-08T22:40:55.797Z · LW(p) · GW(p)
I'm not arguing against fuzzy logic, just that it arguably doesn't "morally" solve the liar paradox, insofar it yields similar revenge paradoxes. In natural language we arguably can't just place restrictions, like banning non-continous truth functions such as "is exactly false". Even if we don't have a more appealing resolution. We can only pose voluntary restrictions on formal languages. For natural language, the only hope would be to argue that the predicate "is exactly false" doesn't really make sense, or doesn't actually yield a contradiction, though that seems difficult. Though I haven't read Field's book. Maybe he has some good arguments.
Replies from: abramdemski↑ comment by abramdemski · 2024-10-09T15:11:25.792Z · LW(p) · GW(p)
I'm not arguing against fuzzy logic, just that it arguably doesn't "morally" solve the liar paradox, insofar it yields similar revenge paradoxes.
It has been years since I've read the book, so this might be a little bit off, but Field's response to revenge is basically this:
- The semantic values (which are more complex than fuzzy values, but I'll pretend for simplicity that they're just fuzzy values) are models of what's going on, not literal. This idea is intended to respond to complaints like "but we can obviously refer to truth-value-less-than-one, which gives rise to a revenge paradox". The point of the model is to inform us about what inference systems might be sound and consistent, although we can only ever prove this in a toy setting, thanks to Godel's theorems.
- So, indeed, within this model, "is exactly false" doesn't make sense. Speaking outside this model, it may seem to make sense, but we can only step outside of it because it is a toy model.
- However, we do get the ability to state ever-stronger Liar sentences with a "definitely" operator ("definitely x" is intuitively twice as strong a truth-claim compared to "x"). So the theory deals with revenge problems in that sense by formulating an infinite hierarchy of Strengthened Liars, none of which cause a problem. IIRC Hartry's final theory even handles iteration of the "definitely" operator infinitely many times (unlike fuzzy logic).
In natural language we arguably can't just place restrictions, like banning non-continous truth functions such as "is exactly false". Even if we don't have a more appealing resolution. We can only pose voluntary restrictions on formal languages. For natural language, the only hope would be to argue that the predicate "is exactly false" doesn't really make sense, or doesn't actually yield a contradiction, though that seems difficult.
Of course in some sense natural language is an amorphous blob which we can only formally model as an action-space which is instrumentally useful. The question, for me, is about normative reasoning -- how can we model as many of the strengths of natural language as possible, while also keeping as many of the strengths of formal logic as possible?
So I do think fuzzy logic makes some positive progress on the Liar and on revenge problems, and Hartry's proposal makes more positive progress.
Replies from: cubefox↑ comment by cubefox · 2024-10-09T17:47:51.628Z · LW(p) · GW(p)
That seems fair enough. Do you know what Field had to say about the "truth teller" ("This sentence is true")? While the liar sentence can (classically) be neither true nor false, the problem with the truth teller is that it can be either true or false, with no fact of the matter deciding which. This does seem to be a closely related problem, even it it isn't always considered a serious paradox. I'm not aware fuzzy truth values can help here. This is on contrast to Kripke's proposed solution to the liar paradox: On his account, both the liar and the truth teller are "ungrounded" rather than true or false, because they use the truth predicate in a way that can't be eliminated. Though I think one can construct some revenge paradoxes with his solution as well.
Anyway, I still think the main argument for fuzzy logic (or at least fuzzy truth values, without considering how logical connectives should behave) is still that concepts seem to be inherently vague. E.g. when I believe that Bob is bald, I don't expect him to have an exact degree of baldness. So the extension of the concept expressed by the predicate "is bald" must be a fuzzy set. So Bob is partially contained in that set, and the degree to which he is, is the fuzzy truth value of the proposition that Bob is bald. This is independent of how paradoxes are handled.
(And of course the next problem is then how fuzzy truth values could be combined with probability theory, since the classical axiomatization of probability theory assumes that truth is binary. Are beliefs perhaps about an "expected" degree of truth? How would that be formalized? I don't know.)
comment by localdeity · 2024-10-07T21:07:34.437Z · LW(p) · GW(p)
You may be inspired by, or have independently invented, a certain ad for English-language courses.
My take on this stuff is that, when a person's words are ambiguous in a way that matters, then what should happen is you ask them for clarification (often by asking them to define or taboo a word), and they give it to you, and (possibly after multiple cycles of this) you end up knowing what they meant. (It's also possible that their idea was incoherent and the clarification process makes them realize this.)
What they said was an approximation to the idea in their mind. Don't concern yourself with the truth of an ambiguous statement. Concern yourself with the truth of the idea. It makes little sense to talk of the truth of statements where the last word is missing, or other errors inserted, or where important words are replaced with "thing" and "whatever"; and I would say the same about ambiguous statements in general.
If the person is unavailable and you're stuck having to make a decision based on their ambiguous words, then you make the best guess you can. As you, say, you have a probability distribution over the ideas they could have meant. Perhaps combine that with your prior probabilities of the truth values to help compute the expected value of each of your possible choices.
Replies from: cubefox↑ comment by cubefox · 2024-10-08T09:06:47.267Z · LW(p) · GW(p)
What if there are no statements involved at all? Say you believe your roommate bought an eggplant. Which makes it more likely that there is an eggplant in the kitchen. However, it turns out in the kitchen is an edge case of an eggplant. Neither clearly an eggplant nor clearly not an eggplant. How do you update your belief that your roommate bought an eggplant?
Replies from: localdeity↑ comment by localdeity · 2024-10-08T09:57:47.956Z · LW(p) · GW(p)
I would be surprised if grocery stores sold edge cases... But perhaps it was a farmer's market or something, perhaps a seller who often liked to sell weird things, perhaps grew hybridized plants. I'll take the case where it's a fresh vegetable/fruit/whatever thing that looks kind of eggplant-ish.
Anyway, that would generally be determined by: Why do I care whether he bought an eggplant? If I just want to make sure he has food, then that thing looks like it counts and that's good enough for me. If I was going to make a recipe that called for eggplant, and he was supposed to buy one for me, then I'd want to know if its flesh, its taste, etc., were similar enough to an eggplant to work with the recipe (and depending on how picky the target audience was). If I were studying plants for its own sake, I might want to interrogate him about its genetics (or the contact info of the seller if he didn't know). If I wanted to be able to tell someone else what it was, then... default description is "it's an edge case of an eggplant", and ideally I'd be able to call it a "half-eggplant, half-X" and know what X was; and how much I care about that information is determined by the context.
I think, in all of these cases, I would decide "Well, it's kind of an eggplant and kind of not", and lose interest in the question of whether I would call it an "eggplant" (except in that last case, though personally I'm with Feynman's dad on not caring too much about the official name of such things) in favor of the underlying question that I cared about. My initial idea, that there would be either a classical eggplant or nothing in the kitchen, turned out to be incoherent in the face of reality, and I dropped the idea in favor of some new approximation to reality that was true and was relevant to my purpose.
What do you know, there's an Eliezer essay on "dissolving the question [LW · GW]". Though working through an example is done in another post [LW · GW] (on the question "If a tree falls in a forest...?").
Replies from: cubefox↑ comment by cubefox · 2024-10-08T12:05:49.342Z · LW(p) · GW(p)
The problem is that almost all concepts are vague, including "vague" and "exact". And things often fit a concept to, like, 90% or 10%. Instead of being a clear 50% edge case. If none of these cases allows for the application of Bayesian updating, because we "lose interest" in the question of how to update, then conditionalization isn't applicable to the real world.
Replies from: localdeity↑ comment by localdeity · 2024-10-08T13:07:44.662Z · LW(p) · GW(p)
The edges of perhaps most real-world concepts are vague, but there are lots of central cases where the item clearly fits into the concept, on the dimensions that matter. Probably 99% of the time, when my roommate goes and buys a fruit or vegetable, I am not confounded by it not belonging to a known species, or by it being half rotten or having its insides replaced or being several fruits stitched together. The eggplant may be unusually large, or wet, or dusty, or bruised, perhaps more than I realized an eggplant could be. But, for many purposes, I don't care about most of those dimensions.
Thus, 99% of the time I can glance into the kitchen and make a "known unknown" type of update on the type of fruit-object there or lack thereof; and 1% of the time I see something bizarre, discard my original model, and pick a new question and make a different type of update on that.
Replies from: cubefox↑ comment by cubefox · 2024-10-08T13:45:30.430Z · LW(p) · GW(p)
It appears you are appealing to rounding: Most concepts are vague, but we should round the partial containment relation to a binary one. Presumably anything which is above 50% eggplant is rounded to 100%, and anything below is rounded to 0%.
And you appear to be saying in 99% of cases, the vagueness isn't close to 50% anyway, but closer to 99% or 1%. That may be the case of eggplants, or many nouns (though not all), but certainly not for many adjectives, like "large" or "wet" or "dusty". (Or "red", "rational", "risky" etc.)
Replies from: localdeity↑ comment by localdeity · 2024-10-08T17:49:31.675Z · LW(p) · GW(p)
Presumably anything which is above 50% eggplant is rounded to 100%, and anything below is rounded to 0%.
No, it's more like what you encounter in digital circuitry. Anything above 90% eggplant is rounded to 100%, anything below 10% eggplant is rounded to 0%, and anything between 10% and 90% is unexpected, out of spec, and triggers a "Wait, what?" and the sort of rethinking I've outlined above, which should dissolve the question of "Is it really eggplant?" in favor of "Is it food my roommate is likely to eat?" or whatever new question my underlying purpose suggests, which generally will register as >90% or <10%.
And you appear to be saying in 99% of cases, the vagueness isn't close to 50% anyway, but closer to 99% or 1%. That may be the case of eggplants, or many nouns (though not all), but certainly not for many adjectives, like "large" or "wet" or "dusty". (Or "red", "rational", "risky" etc.)
Do note that the difficulty around vagueness isn't whether objects in general vary on a particular dimension in a continuous way; rather, it's whether the objects I'm encountering in practice, and needing to judge on that dimension, yield a bunch of values that are close enough to my cutoff point that it's difficult for me to decide. Are my clothes dry enough to put away? I don't need to concern myself with whether they're "dry" in an abstract general sense. (If I had to communicate with others about it, "dry" = "I touch them and don't feel any moisture"; "sufficiently dry" = "I would put them away".)
And, in practice, people often engineer things such that there's a big margin of error and there usually aren't any difficult decisions to make whose impact is important. One may pick one's decision point of "dry enough" to be significantly drier than it "needs" to be, because erring in that direction is less of a problem than the opposite (so that, when I encounter cases in the range of 40-60% "dry enough", either answer is fine and therefore I pick at random / based on my mood or whatever); and one might follow practices like always leaving clothes hanging up overnight or putting them on a dryer setting that's reliably more than long enough, so that by the time one checks them, they're pretty much always on the "dry" side of even that conservative boundary.
Occasionally, the decision is difficult, and the impact matters. That situation sucks, for humans and machines:
https://en.wikipedia.org/wiki/Buridan's_ass#Buridan's_principle
Which is why we tend to engineer things to avoid that.
Replies from: cubefox↑ comment by cubefox · 2024-10-08T18:47:46.986Z · LW(p) · GW(p)
Anything above 90% eggplant is rounded to 100%, anything below 10% eggplant is rounded to 0%, and anything between 10% and 90% is unexpected, out of spec, and triggers a "Wait, what?" and the sort of rethinking I've outlined above, which should dissolve the question of "Is it really eggplant?" in favor of "Is it food my roommate is likely to eat?" or whatever new question my underlying purpose suggests, which generally will register as >90% or <10%.
Note that in the example we never asked the question "Is it really an eggplant?" in the first place, so this isn't a question for us to dissolve. The question was rather how to update our original belief, or whether to update it at all (leave it unchanged). You are essentially arguing that Bayesian updating only works for beliefs whose vagueness (fuzzy truth value) is >90% or <10%. That Bayesian updating isn't applicable for cases between 90% and 10%. So if we have a case with 80% or 20% vagueness, we can't use the conditionalization rule at all.
This "restricted rounding" solution seems reasonable enough to me, but less than satisfying. First, why not place the boundaries differently? Like at 80%/20%? 70%/30%? 95%/5%? Heck, why not 50%/50%? It's not clear where, and based on which principles, to draw the line between using rounding and not using conditionalization. Second, we are arguably throwing information away when we have a case of vagueness between the boundaries and refrain from doing Bayesian updating. There should be an updating solution which works for all degrees of vagueness so long as we can't justify specific rounding boundaries of 50%/50%.
Do note that the difficulty around vagueness isn't whether objects in general vary on a particular dimension in a continuous way; rather, it's whether the objects I'm encountering in practice, and needing to judge on that dimension, yield a bunch of values that are close enough to my cutoff point that it's difficult for me to decide. Are my clothes dry enough to put away? I don't need to concern myself with whether they're "dry" in an abstract general sense.
This solution assumes we can only use probability estimates when they are a) relevant to practical decisions, and b) that cases between 90% and 10% vagueness are never decision relevant. Even if we assume b) is true, a) poses a significant restriction. It makes Bayesian probability theory a slave of decision theory. Whenever beliefs aren't decision relevant and have a vagueness between the boundaries, we wouldn't be allowed to use any updating. E.g. when we are just passively observing evidence, as it happens in science, without having any instrumental intention with our observations other than updating our beliefs. But arguably it's decision theory that relies on probability theory, not the other way round. E.g. in Savage's or Jeffrey's decision theories, which both use subjective probabilities as input in order to calculate expected utility.
comment by cubefox · 2024-10-08T08:49:56.791Z · LW(p) · GW(p)
I claim that there's just always a distribution over meanings, and it can be sharp or fuzzy or bimodal or any sort of shape.
You are saying all meanings are perfectly precise, and concepts are never vague, only massively ambiguous. For example, the term "eggplant" [LW(p) · GW(p)], or almost any other word, would be ambiguous between, like, a million meanings, all more or less slightly different from each other.
You could probably model vagueness as such an extreme case of ambiguity. But this would be unnatural. Intuitively, vagueness is a property internal to a meaning, not of a very large collection of different meanings attached to the same word.
comment by James Camacho (james-camacho) · 2024-10-07T19:32:05.356Z · LW(p) · GW(p)
I claim that there's just always a distribution over meanings, and it can be sharp or fuzzy or bimodal or any sort of shape.
The issue is you cannot prove this. If you're considering any possible meaning, you will run into recursive meanings (e.g. "he wrote this") which are non-terminating. So, the truthfulness of any sentence, including your claim here is not defined.
You might try limiting the number of steps in your interpretation: only meanings that terminate to a probability within steps count; however, you still have to define or believe in the machine that runs your programs.
Now, I'm generally of the opinion that this is fine. Your brain is one such machine, and being able to assign probabilities is useful for letting your brain (and its associated genes) proliferate into the future. In fact, science is really just picking more refined machines to help us predict the future better. However, keep in mind that (1) this eventually boils down to "trust, don't verify", and (2) you've committed suicide in a number of worlds that don't operate in the way you've limited yourself. I recently had an argument with a Buddhist whose point was essentially, "that's the vast majority of worlds, so stop limiting yourself to logic and reason!"
Replies from: hastings-greer↑ comment by Hastings (hastings-greer) · 2024-10-07T19:56:57.740Z · LW(p) · GW(p)
Yeah, I definitely oversimplified somewhere. I'm definitely tripped up by "this statement is false" or statements that don't terminate. Worse, thinking in that direction, I appear to have claimed that the utterance "What color is your t-shirt" is associated with a probability of being true.
comment by M. Y. Zuo · 2024-10-08T13:21:50.968Z · LW(p) · GW(p)
This seems always "fuzzily true"?
e.g. Which atom of the store are you measuring to?
The store has many quadrillions of atoms spread across a huge volume of space, relative to atom sizes, and there is no ultimate arbiter on the definitive measuring point.