Finite Factored Sets: LW transcript with running commentary
post by Rob Bensinger (RobbBB), Scott Garrabrant · 2021-06-27T16:02:06.063Z · LW · GW · 0 commentsContents
Finite Factored Sets Some Context Factoring the Talk Set Partitions Set Factorizations Enumerating Factorizations The Main Talk (It's About Time) The Pearlian Paradigm We Can Do Better Time and Orthogonality Game of Life Conditional Orthogonality Compositional Semigraphoid Axioms The Fundamental Theorem Temporal Inference Two Binary Variables (Pearl) Two Binary Variables (Factored Sets) Applications / Future Work / Speculation Inference Infinity Embedded agency Q&A None No comments
This is an edited transcript of Scott Garrabrant's May 23 LessWrong talk on finite factored sets. Video:
Slides: https://intelligence.org/files/Factored-Set-Slides.pdf
Since there are existing introductions to finite factored sets that are shorter (link [LW · GW]) or more formal (link [? · GW]), I decided to do things a bit differently with this transcript:
- I've incorporated Scott's slides into the transcript, and cut out some parts of the transcript that are just reading a slide verbatim.
- There was a text chat and Google Doc attendees used to discuss the talk while it was happening; I've inserted excerpts from this conversation into the transcript, in grey boxes.
- Scott also paused his talk at various times to answer questions; I've included these Q&A sections in white boxes.
Finite Factored Sets

Anonymous α: Scott: do you have any suspicions that the basis of the mathematics is poorly fit to reality (q.v. Banach-Tarski decomposition)? Daniel Filan: I really liked it when causality came from pictures that I can look at. Does finite factored sets have pictures? One way this could be true is if it were some sort of category. Like, every other way I know of thinking about time (Newtonian mechanics, general relativity) is super geometric. Ramana Kumar: In case others are interested, I’ve been formalising these results in HOL (as I did for Cartesian Frames, which recently was posted publicly) Daniel Filan: (why) is HOL a good system in which to formalize these things? Ramana Kumar: Mainly: just because it’s possible, and I know the system/logic well. HOL is pretty good for most of math though - see this for some advocacy. Daniel Kilan: thx, will give that a look! Quinn Dougherty: +1 |
Some Context

Scott: I'm going to start with some context. For people who are not already familiar with my work: My main motivation is to reduce existential risk. This leads me to want to figure out how to align advanced AI. This leads me to want to become less confused about intelligence and about agents embedded in their environment [? · GW]. I think there are a lot of hard open problems in trying to figure out how to do this.
This leads me to do a bunch of weird math and philosophy, and this talk is going to be an example of some of that weird math and philosophy.
Factoring the Talk
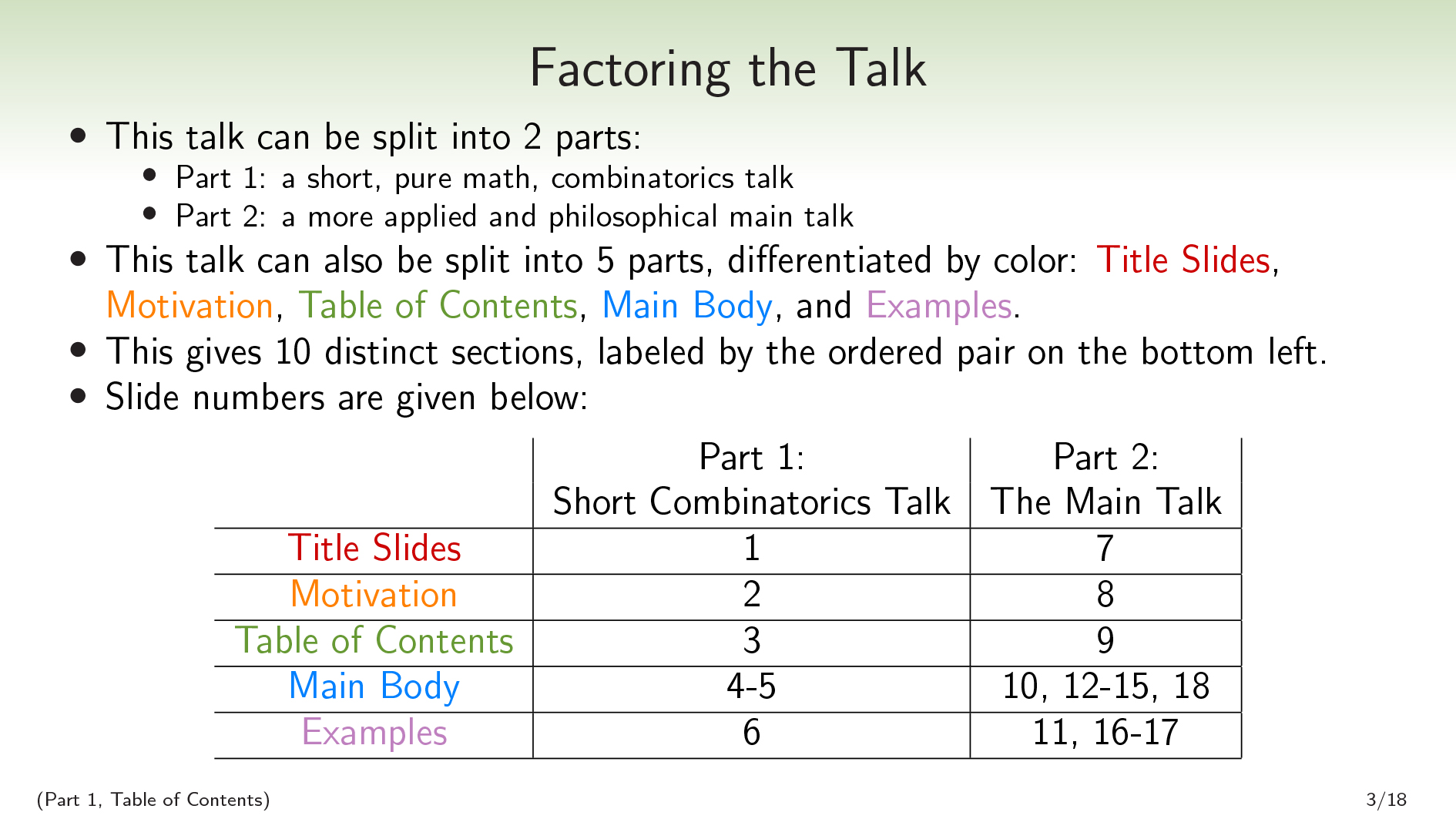
Scott: This talk can be split into parts. For example, this slide is in part 1 (the combinatorics talk) and .
I recognize that this table of contents has a lot more table and a lot less content than tables of contents normally have. But that's okay, because we'll have another table of contents in 6 more slides.
Set Partitions
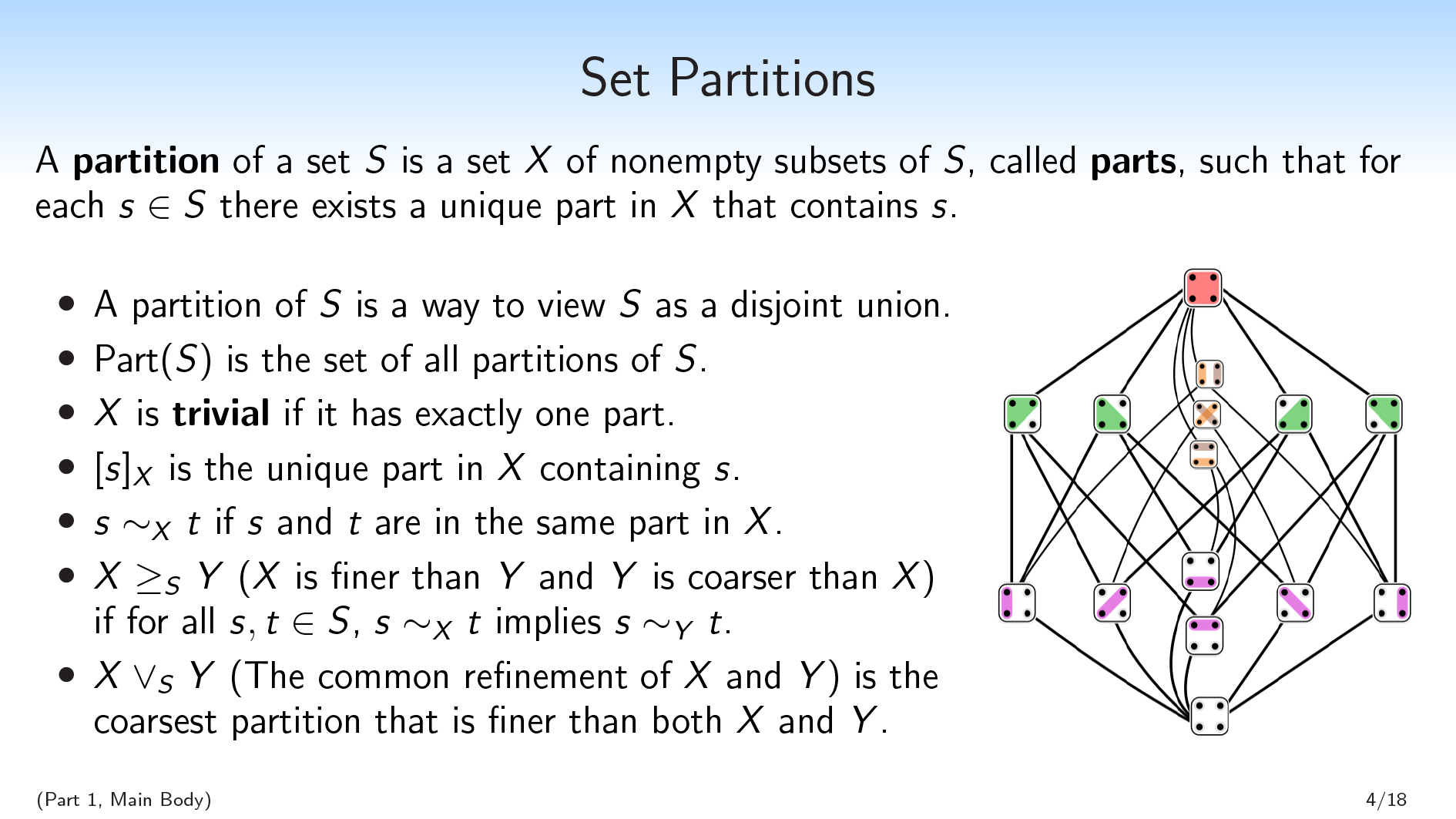
Scott: All right. Let's do some background math.
A partition of a set is a way to view as a disjoint union. You have a bunch of sets that are disjoint from each other, and you can union the sets together to get .
We'll also be using the lattice structure on partitions:
- We'll say that is finer than (and is coarser than ) if for all elements , if and are in the same part in , they have to be in the same part in . So if is finer than , then you can think of as making some distinctions; and has to make all of those distinctions, and possibly some more distinctions.
- The common refinement of two partitions and is the coarsest partition that is finer than both and . So it has to make all of the distinctions that either or make, and no more.
This picture on the right is all of the partitions of a four-element set, and the graph structure is showing the "finer" relation, with finer things closer to the bottom.
Glenn Willen: for anybody who had the same confusion I did at first: The dots on white in the diagram were singleton partitions. Daniel Filan: +1 I was also confused about this |
Set Factorizations

Scott: Now for some new stuff.
A factorization is a set of non-trivial partitions ("factors") of some set , such that for each way of choosing one part from each factor in , there exists a unique element of in the intersection of those parts.
A factorization is basically a multiplicative version of a partition. A factorization of is a way to view as a product, in the same way that a partition of is a way to view as a disjoint union.
Anonymous β: This looks like dirichlet product of species Jason Gross: Is the universal property of a factorization the same as the universal property of a partition in the opposite category? Luke Miles: The intersection of the parts of the factors should have exactly one element right? Ben Pace: That sounds right. Glenn Willen: The intersection of one part from each factor should be one element, if I'm understanding right, yeah. Jason Gross: what does "nontrivial" mean in "nontrivial partition"? Daniel Filan: trivial partition has only one part Rob Bensinger: 'trivial partition' has exactly one part Jason Gross: singleton set has no factorizations, empty set has … exactly one factorization? Ramana Kumar: singleton does have a factorization. factorizes Ramana Kumar: no wait... that's trivial |
Scott: If we have a factorization of our set , there will be a bijection between and the product . This bijection comes from sending an element to the tuple consisting only of parts containing that element, .
Because of this, the size of is always going to be equal to the product of the sizes of 's factors.
This bijection is basically restating the definition above. It's saying that for each way of choosing one part from each factor, we're going to have a unique element in the intersection of those parts.
Another thing we can observe is that any factor in a factorization must always be a partition into parts of equal size, because otherwise you're not going to be able to make this bijection work out.
We will often be working with a finite factored set, which is a pair , where is a finite set and is a factorization of .
This definition is a little bit loopy. There's this thing where I'm first introducing , and I'm saying that is a collection of partitions of . But there's another way you can view it in which you first define , which is just a collection of sets. Then you take the product of all of the sets in , and this gives you a set , which is tuples of the product of the elements in . Then you can identify, with each element of a , the subset of the space of tuples that you get by projecting onto that part in the tuple.
So there's this temptation to define first and then define from , and there's also a temptation to do the opposite. This bijection is saying that we can take either lens.
John Wentworth: One other way to picture a “factored set”: it’s a set with a coordinate system attached. Each point in the set corresponds to a unique coordinate-tuple and vice versa (e.g. uniquely specify each point in our usual 3D space). To translate this to the “partitions” view: each partition is the set of equivalence classes induced by one coordinate. For instance, the -coordinate partitions 3D space into planes, each of the form =<constant>. (I asked Scott why he’s using this more-complicated-seeming definition in terms of sets, and he has some good reasons, but I still think it’s easier to start with the coordinate-system view when first seeing this stuff.) Ramana Kumar: nice! Ramana Kumar: Some things that confused me initially about FFS:
Philosophically, what are good ways to think of what the set is? Currently I think of it as a set of possible (complete) worlds, at a certain level of abstraction. (Similar to the set in a Cartesian Frame [LW · GW] over ) Scott: In the Cartesian frame analogy is , not . is (from the inference slide [LW · GW]). Anonymous γ: I don’t understand what a bijection is. Quinn Dougherty: invertible function Ben Pace: Do the multiplication signs basically mean “intersection”? Daniel Filan: No Ben Pace: Daniel, what does it mean here? Anonymous δ: = Cartesian product aka tupling Daniel Filan: Anonymous ε: I think it corresponds to intersection under the bijection though Ramana Kumar: @[Anonymous ε] I don't think that's right Ben Pace: That’s what I thought but I also thought it was supposed to end up as a single element… Diffractor: The real number line the real number line is the 2d plane, that has a lot more than one point Daniel Filan: Yep. In this setting, one ordered pair corresponds to the thing that's the intersection of all the pair elements. . If , , , and are themselves sets, you can then go from e.g. to the intersection of and . And in the case of a factorization, you can go back from some subset to the tuple of sets that it’s the intersection of. Jasper Chapman-Black: there's a bijection between the set-of-elements and the set-of-tuples-of-factors, is the claim being made Leo Gao: Which operation is the bijection over? Diffractor: Bijection between base set and the cartesian product of the factorizations |
Scott: To me, this is an extremely natural notion. I want to really push this naturalness, so I want to describe how factorization is dual to the definition of a partition.
| A partition is a set of of such that the obvious function the of the elements of is a bijection. | A factorization is a set of of such that the obvious function the of the elements of is a bijection. |
You can see here I have two alternative definitions of partition and factorization.
For partition: We have a bunch of (non-empty) subsets of ; we have functions to , which are the inclusions; we can add all these functions together to give a function from their disjoint union to ; and we want this function to be a bijection.
Similarly, a factorization is a set of (non-trivial, meaning not having exactly one element) partitions of such that the obvious function to the product of the elements of from is a bijection. So for each partition in , there's this projection onto that partition; and we can multiply all of these together to get a function from to the product, and we want this function to be a bijection.
You can see that in these two definitions, I’m pointwise dualizing a bunch of the words to show that there's a duality between partitions and factorizations. You'll notice that there’s also a duality between subsets and partitions. You can view a partition as "that which is dual to a subset," and you can also view it as "that which is built up out of subsets in a certain way." When I say that factorizations are dual to partitions, I'm using the "that which is built up from subsets in a certain way" conception of partitions.
I'm first going to give some examples, and then I'll open up the floor for questions about factorizations.
Enumerating Factorizations
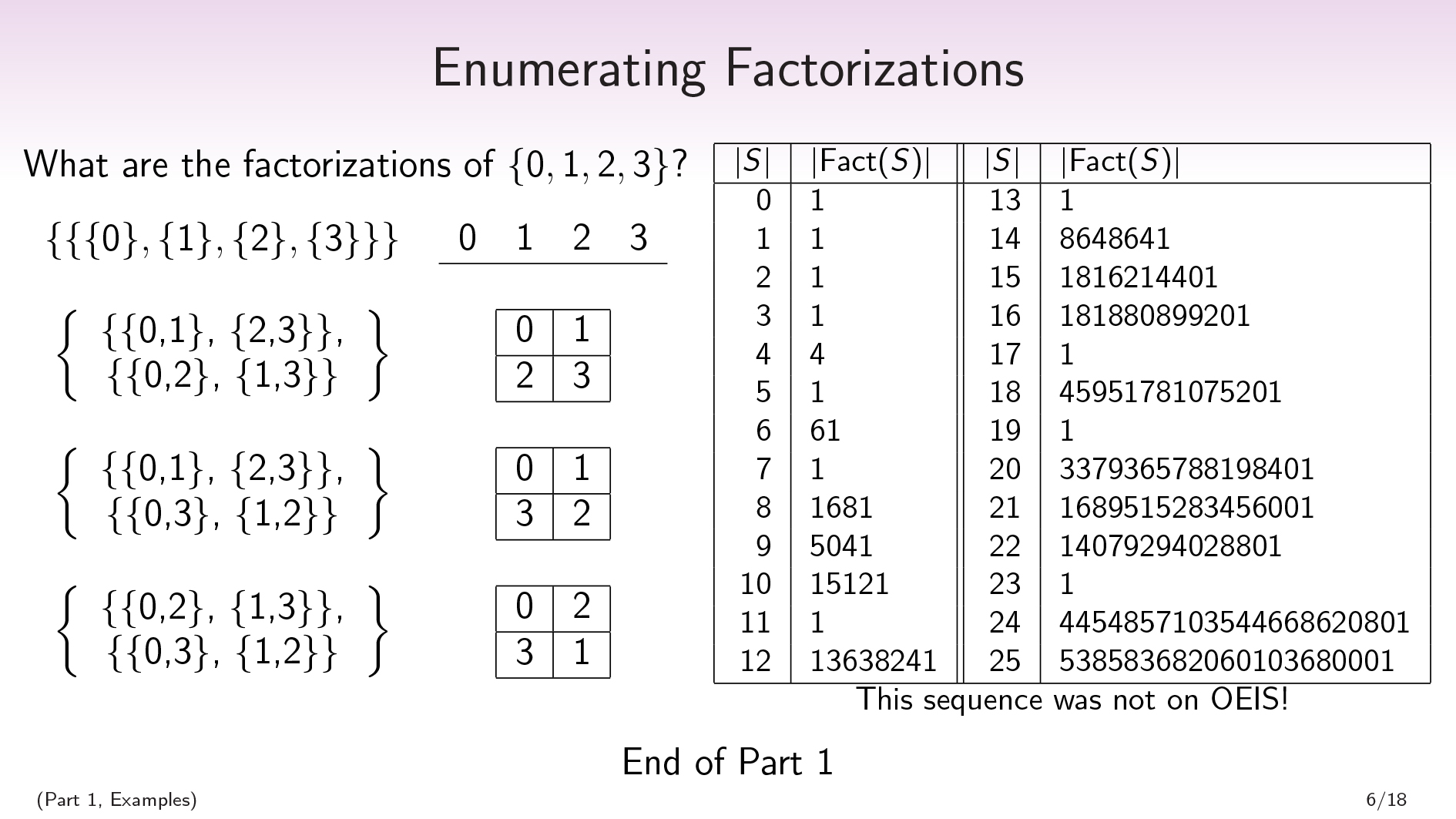
Scott: Exercise: What are the factorizations of a four-element set, ?
.
.
.
.
.
.
.
.
.
.
.
.
The first thing to observe is that given any set with at least one element, we're always going to be able to define at least one factorization, a sort of trivial factorization.
This is a kind of one-dimensional factorization. We have one factor, which is the discrete partition.
Recall that in the definition of factorization, we want it to be the case that for each way of choosing one part from each factor, we want a unique element of in the intersection of those parts. The trivial factorization satisfies that.
What if we want a nontrivial factorization? Well, recall that the product of the sizes of the factors always has to equal the size of . The only way to express as a nontrivial product is to express it as a product. So we're looking for two partitions/factors that are going to combine to give us .
All of our factors also have to break into parts of equal size. So we're looking for partitions that each break our -element set into parts of size . There are exactly three partitions that break a 4-element set into parts of size : , which separates the small numbers from the large numbers; , which separates the even numbers from the odd numbers; and , which separates the inner numbers from the outer numbers.
We're going to be able to choose any pair of these. So we're going to have three more factorizations:
The point here is that for each way of choosing, you're going to get a unique element that is the conjunction of those two choices. "Small or large?" and "even or odd?" jointly pick out a specific element of .
Adam Scherlis: (I get four non-isomorphic factorizations) Gurkenglas: Adam, are you sure three of them aren't isomorphic? Adam Scherlis: yeah, on screen now :) Adam Scherlis: distinguished by which element shares no partition elements with 0 David Manheim: Isomorphic over relabeling of items, or non-order dependent given the labels? David Manheim: Right. Adam Scherlis: over relabeling of partitions is what I meant, sorry |
Scott: In general, given an -element set, you can ask how many factorizations there are of that set. We have the sequence here.
You can notice that if is prime, there’s only one factorization, which is the trivial one.
A very surprising fact to me was that this sequence did not appear on OEIS. OEIS is a database that combinatorialists use to share their sequences of integers, and check whether their sequences have been studied by other people and look for connections. This sequence didn't show up, even when I did minor modifications to deal with the degenerate cases.
I just don't get this. To me this basically feels like the multiplicative version of the Bell numbers. The Bell numbers count how many partitions there are in a set of size . It's sequence #110 out of over 300,000 on the OEIS. And yet this sequence doesn't show up at all. I don't really have an understanding of why that happened.
Okay. Now I'm going to pause for questions.
Quinn Dougherty: remind me what oeis is Glenn Willen: online encyclopedia of integer sequences Quinn Doughterty: thanks Diffractor: The giant internet database of number sequences Alex Mennen: I think the 0th element should be 0 Alex Mennen: wait, nvm Adam Scherlis: OEIS omission really is surprising, nice find Scott Jasper Chapman-Black: Checked in OEIS and that was missing too. Huh. That’s super surprising. I’ve seen 1680, 5040, 15120 a lot before in random OEIS sequences which are (factorization sizes ), I suspect there’s some Crazy Equivalence going on here Daniel Filan: Shouldn't the element corresponding to be ? Ramana Kumar: yeah is for ? Alex Mennen: no, there's the empty factorization Diffractor: Actually, it's 1 because there's bullshit going on with the empty set and single-element set A whole lot of "vacuously true" for those two cases Daniel Filan: aaaah |
Anonymous ζ: There's a question in the chat about how many factorizations a singleton set has. This table says it has one. What is it? Scott: It's the empty factorization. It has no factors, and for every way—the one way—of choosing one part from every factor in the empty set of factorizations, you'll have a single element in the intersection of those parts. Anonymous η: Partitions were over graphs, right? Scott: No, the graph was just a way to organize all of the partitions of a four-element set. There's no graphs involved here. Anonymous η: Ah, okay, cool. |
Anonymous δ: The graph is a hasse diagram Jason Gross: Is the number of factorizations related to the number of groups of a given size? Quinn Dougherty: jason ask that question i wanna know the answer Daniel Filan: (asking questions in this context is done via voice, not text) |
Anonymous θ: Is there a similar sort of thing for factorizations, or not really? Or is it not relevant? Scott: If we were to do something similar to having the notion of "finer" in factorizations, I think it would look something like: Given a factorization of a set , you can take two of your factors and replace those two factors with a single factor that is the common refinement of those two factors. This gives you a factorization with fewer factors, and you can view this as analogous to merging two subsets in a partition. So you can have a "finer" relation, which says whether you can get from one factorization to another in this way. I'd say that the factorization with more factors is the multiplicatively finer one in that picture. I think that you're not going to get the meets and joins. Or maybe you get one of them, but not the other? I’m not sure; I didn't think about that. But you can at least get a partial order on them. |
Anonymous ι: i.e. is finer than Kyle: Does product mean intersection in the definition of factors? It doesn't seem to mean cartesian product Ramana Kumar: product is cartesian product Quinn Dougherty: isn't the common refinement one of a meet or a join? Diffractor: Common refinement is a supremum in the ordering on partitions where the indiscrete partition is at the bottom and the discrete partition is at the top |
Anonymous 5: Is there a meaning attached to a particular product? Like, in your example, let's say you pick the product. Is there structure in the resulting output of that multiplication, or are they all equivalent once you do the multiplication? Scott: You could think of these as four different structures that you can put on your four-element set. Three of them are isomorphic, so you can relabel the elements of your set to get the same structure. But I'm thinking of them as different even though they're isomorphic. It depends on what version of "the same" you want. Ben Pace: I'll ask Jason Gross' question, which is, "Is the number of factorizations related to the number of groups of a given size?" Scott: It's related in that they agree whenever the number is prime. (laughs) I think it's not directly related, although I think that if you drew out the chart, it would look similar. These numbers grow a lot faster. I have proved some things about this chart, like that they all end in 1 except for the fourth one. |
Jason Gross: I don't see how it could be related now; the number of groups of order 8 is 5, where we have 1681 factorizations Vanessa Kosoy: Is there a reason almost all of these numbers are equal to 1 modulo 10? Daniel Filan: +1 Vanessa Alex: I'd be interested in factorizations of 81 (a sudoku grid) and whether it has anything interesting about it Alex Mennen: perhaps the ending in 1 is a special case of something like, for any , all but finitely many of these are 1 mod Daniel Filan: oh David Manheim: Vanessa: it is a product plus the single trivial factorization? Diffractor: The ending in 1 is because of the partition that's like "every element is in its own equivalence class" Daniel Filan: +1 David Glenn Willen: a product, or a sum of products? |
Gurkenglas: Have you looked at the sequence of isomorphism classes of factorizations? Scott: Yeah, the sequence of isomorphism classes of factorizations is going to be equal to the multiplicative partition function. It's the number of ways to express as a product. And that's simple enough that it does show up on OEIS; I forget exactly what the sequence is. Okay. I'm going to move on to the main talk. |
The Main Talk (It's About Time)

The Pearlian Paradigm

Scott: We can't talk about time without talking about Pearlian causality [? · GW]. This paradigm allows you to, given a collection of variables and a joint probability distribution over those variables, infer causal/temporal relationships between the variables.
(In this talk, I'm going to be using "causal" and "temporal" interchangeably, though I think that there might be more to say there philosophically.)
Pearl can infer temporal data from statistical data. I'm not going to explain exactly how it works, because I'm not going to be technically dependent on it. This is really great. There's this adage, "Correlation does not imply causation,” and I think that it's just wrong and Pearl is correctly inferring causation from correlation all over the place using the combinatorial structure of the correlation.
The way that he does this is by inferring these graphs, like the one on the left. I think this graph is not entirely inferable from a probability distribution on the variables as it is, but some graphs are. You can definitely infer from a probability distribution that came from this graph, using the Pearlian paradigm, whether or not "the ground is wet" is before "the ground is slippery," for example.
Jason Gross: I thought Pearl could only infer lack of causation? Matthew Graves: yes but you can process-of-elimination Rick Schwall: Correlation does not imply causation for only 2 variables. Pearl makes use of more variables. Jason Gross: re process of elimination: you need to assume that you know all the possible events/occurences, right? Matthew Graves: I remember he talks a lot about how he handles the possibility of common causes but it's been a while Jason Gross: I should actually read Pearl sometime... Mark Xu: there are results on how to infer causation from 2 variables if you know that they have non-gaussian independent random errors I think |
Scott: The Pearlian paradigm is great. It's my main starting point. However, I claim that it's cheating: the "given a collection of variables" is actually hiding a lot of the work.
Normally people emphasize the joint distribution in saying that Pearl is inferring temporal data from statistical data, but I think that what's actually going on is that Pearl is inferring temporal data from statistical data together with factorization data.
For example, let's say all the variables in this picture are binary. The choice that we're working with these 5 variables, as opposed to just working with 32 distinct worlds without labels, is actually doing a lot of the work.
I think this issue is also entangled with a failure to adequately handle abstraction and determinism.
Let's say you're given these 5 variables and a joint probability distribution on the variables. One thing you could do is say, "I'm going to forget the variables that were given to me, and I'm just going to consider all Bell number of 32 different ways that the world can be."
And you could try to do Pearlian inference on this set of variables. The set is huge, but I'm working from an ontology where I don't care about things being huge. But you're going to run into a problem, which is that many of these variables that you define are going to be deterministic functions of each other, or partially deterministic functions of each other. Some of your variables/partitions will be coarsenings of other variables/partitions.
It turns out that the Pearlian paradigm, or the part that I'm trying to copy here, doesn't work well with all of this determinism. So you can't just throw away the variables you were given.
That's why I think that this cheating I'm accusing the Pearlian paradigm of doing is entangled with not being able to handle abstraction and determinism. By "abstraction" I mean I want some of my variables to be able to be coarser or finer copies of each other, which is similar to determinism.
Alex Ray: The choice of what variables to work with has always been my biggest problem w/ pearl causal inference Pearl assumes that you have some “relevance machine” to narrow down to variables, and some separate process to pick from all graphs that involve those variables |
We Can Do Better

Scott: So we're going to do something new.
- Where Pearl was given a collection of variables, we're going to take all partitions of a given set.
- Where Pearl inferred a directed acyclic graph, we're going to infer a finite factored set.
- In the Pearlian world, we could read off of our directed acyclic graph something that we'd want to call time. When we have a path from one node to another in a DAG, that means that the first node is before the second node.
In the factored sets paradigm, we're going to have to define our own way of looking at a finite factored set and telling when some partitions are before or after other partitions. - Pearl draws special attention to when two nodes in your DAG have no common ancestor. This corresponds to orthogonality, or independence. (In this talk, I'm going to use the word "independence" when I'm talking about probability, and I'm going to use the word "orthogonality" when I'm talking about combinatorial properties.)
We're going to be able to read something analogous off of our finite factored sets. - Pearl has a concept, d-separation, which is kind of complicated. And the reason d-separation is interesting is that it's equivalent to conditional independence in all probability distributions you could put on your DAG.
We're going to define an analogous concept, conditional orthogonality, which we're going to be able to read off of a finite factored set. - In the Pearlian world, we have that d-separation gives a compositional graphoid. In our world, we're going to have a compositional semigraphoid satisfied by conditional orthogonality. (There's a fifth graphoid axiom that we're not going to satisfy, but I argue we didn't want to satisfy it in the first place.)
- As with d-separation in Pearl, we're going to have a result saying that conditional orthogonality exactly corresponds to conditional independence in all probability distributions that you could put on your structure.
- We're going to be able to do temporal inference.
- And we're going to discuss some applications.
This is a green slide, so it's a table of contents slide; here are some slide numbers.
We've already talked about partitions and factorizations. Now, we're going to talk about time and orthogonality.
David Manheim: ...and I immediately jumped to "wait, as long as we have a prime number of elements, we can infer things?" before I realized that the number is the product of the variables, not the number of them. Quinn Dougherty: what's graphoids and semigraphoids Glenn Willen: "A graphoid is a set of statements of the form, "X is irrelevant to Y given that we know Z" where X, Y and Z are sets of variables. The notion of "irrelevance" and "given that we know" may obtain different interpretations, including probabilistic, relational and correlational, depending on the application." -- Wikipedia Quinn Dougherty: thanks David Manheim: (But Scott's new model still only works if the variables are discrete. Extending to continuity is gonna be even harder than for Pearl's causality.) Edward Kmett: i really want the mapping between slide numbers and types to be a finite factorization Daniel Filan: "What is a semigraphoid" - https://foxflo.github.io/whatis/semigraphoid.pdf (I haven't read this) Ben Pace: <3 Ed Kmett |
Time and Orthogonality

Scott: Before we define time and orthogonality, I'm going to define something called history.
We're starting with a fixed finite factored set, and that’s our context. is going to be a partition of , and the history of is the smallest set of factors such that, if I take an element of and hide it from you, and you want to know what part in it's in, it suffices for me to tell you what part it's in within each of the factors in .
So if I want to determine the -value of an element of , it suffices for me to know the value of all of the factors in . So what's written here is saying that if two elements agree on all of the factors in , then they have to agree on .
(Whenever I have a partition, I can kind of think of it as a variable. So when I say "the -value of an element," I mean "what part it's in within .")
This definition is the central starting point. We're going to define everything from this, so it's worth pausing on.
You can kind of think of factors as basic properties from which everything can be computed. And I want to know which factors are going into the computation of , which factors determine the value of .
Leo Gao: My understanding: a factorization lets you break a set into a bunch of different partitions of such that if you pick one part from each partition and get their intersection, you always identify a specific thing; a history is the smallest factorization that uniquely specifies your partition for any way you could look at it. I think one useful way to think about this is the shape of a factorization is [partitions, parts, elements-within-part] John Wentworth: Taking the “FFS = set with coordinate system” view, history is the minimum set of coordinates on which some function depends. So e.g. if we have a function on which can be expressed in terms of just (but not in terms of alone or alone), then its history is . When talking about distributions on factored sets, each coordinate is effectively an independent random variable, and everything else is deterministically computed from those independent random variables. In other words, the coordinates are like independent random bits from which other variables are generated. So in that picture, “ before ” roughly says that the random bits on which depends are a superset of the random bits on which depends. Diffractor: history of = "smallest set of coordinates for the cartesian product where knowing those coordinates alone can tell you which equivalence class you're in" Felix: is there a unique history for every ? Alex Ray: This is a very nice compact description of Diffractor: Yes, it's unique Ramana Kumar: @Felix yes it is unique because it's smallest Gustavo Lacerda: Can we frame it in terms of “sufficiency”? Ramana Kumar: (there is something to prove though - that all sets of factors with this property overlap) Alex: This seems kind of intuitive from the "coordinate space" perspective of factorization Jason Gross: Why can't you have two different smallest sets of the same size, neither of which is a subset of the other? Daniel Filan: What's an example where history() isn't ? Diffractor: Better to frame it in terms of "necessity". To Jason, it just works Ramana Kumar: @Daniel when X is not in B David Manheim: Once we have the finite factored set size, we know at least how many variables x values we have - but we don't know how many variables we have... Diffractor: For Daniel, history() is not a partition, it's a set of sets of partitions Ramana Kumar: @[Diffractor] but history() can sometimes be Luke Miles: "The future has more history than the past" Quinn Dougherty: When Scott says "partitions are like variables" does he mean variable in like the data science sense? like a column of tabular data? Diffractor: Which broadly correspond to "which coordinates of our big hypercube are strictly necessary for knowledge of them to pin down which equivalence class of you're in Quinn Dougherty: What’s the analogy between partition and variable? Ramana Kumar: Given a partition of , one can think of the different parts as possible values of a variable . Then given an element of , the value of in is the part to which belongs in . |
Scott: Then we're going to define time. We'll say that is weakly before if the history of is a subset of the history of . And we'll say that is strictly before if the history of is a strict subset of the history of .
One way you might want to think about this is that the history of is kind of like a past light cone. One spacetime point being before another spacetime point means that the past light cone of the first point is a subset of the past light cone of the second point. That gives some intuition as to why one might want to think of a temporal relationship as a subset relationship.
We're also going to define orthogonality. We’ll say that partitions and are orthogonal if their histories are disjoint.
I think I actually want to pause for questions here, so let's do that.
Daniel Filan: ah I think I get it. So like if you have the - plane, the history of the half-planes is the set ? (where in the second set is standing for partitioning the coordinates by their value) Anurag Kashyap: does the history have to be unique for any partition ? Adam Scherlis: I think so, Daniel Diffractor: Yeah, the set , where is taken as a partition of Ramana Kumar: @Anurag yes Daniel Filan: and is orthogonal to ? Diffractor: Daniel, yes, that's correct Daniel Filan: aaah so orthogonality means "the things you have to know to determine these two events don't intersect". So somehow they come from different facts. Diffractor: Yup, that's correct Also, for everyone else, I should warn you that there's a whole lot of sets and sets of sets and sets of sets of sets in the posts. |
Anonymous 6: So the size of the history is measured by the number of elements added up from all the little subsets, not the number of factors, right? Scott: I never talk about the size of the history. When I say "smallest set of factors," I mean smallest in the subset relation. This is actually maybe not obvious on the surface of it, but it turns out that sets with the property that knowing all of the values in is sufficient to determine the value of , are actually closed under intersection. And so there's going to be a unique smallest set of factors in the subset ordering. So the history is actually going to be a subset of any set of factors that would be sufficient to determine the value of . Anonymous 7: Is that equivalent to coarsest? Scott: Given a set of factors, we could take their common refinement, and a smaller subset is going to correspond to a coarser common refinement. So in that sense, you can view it as the coarsest. There's this choice: Do we want to say it's a set of factors, or do we want to say it is the common refinement of a set of factors? In the past, I’ve thought of it as the common refinement of a set of factors. That's another good way to think about it. Anonymous 8: Scott, are you going to be drawing a specific parallel between the new formalism and some specific causal graph in the Pearlian sense? Scott: I am not going to, in this talk, formally connect things up to Pearl. There is going to be a way to take a Pearlian DAG, and from it compute a finite factored set—and in that sense, my model class is kind of going to be larger, because I'm not going to be able to go the other way around. But I'm not actually going to present that here. |
David Manheim: The time history seems intuitive, but I’m not following how we can do this with actual values / histories because I don’t quite follow how factorizations work. David Manheim: I only kind of follow the idea of factorizations. What’s the relationship to graphs? (Answered; Scott is deferring this question / doesn’t want to propose the mapping because the intuitive one doesn’t work, and the one that works is complex.) |
Anonymous 9: In a really simple case, if you have two variables and they can each have three values, then you end up with nine elements in your set. Is that right? Scott: If I have two disconnected independent variables— Anonymous 9: You don't know if they're independent. Scott: Oh, I think I'm going to punt this question. I'm going to be talking about temporal inference later. Gurkenglas: Have you tried defining a notion of morphism between finite factored sets and then defining histories in terms of that? Scott: Yeah. I chose to go with a combinatorialist aesthetic in this talk, and also in most of my writing about this, so that things won’t have that many prerequisites. But I also have some thoughts about how to work with finite factored sets in a category-theory aesthetic too. Like, in a category-theory aesthetic, instead of talking about partitions of your set, you want to be talking about functions out of your set. Various things like this. And I do have a proposal for what category I'd want to put on factored sets and a way to view history and orthogonality and such as categoric properties. But I'm not going to do that right now. |
David Manheim: I appreciate not needing category theory for this talk! Glenn Willen: David: Me too, but I suspect it might be easier to understand with category theory, if I understood category theory, which I don't ;-) Adam Scherlis: I feel like the quantum version of this is probably very pretty... David Manheim: Glenn: Ditto - in the counterfactual world where I knew category theory, I would probably prefer it. Daniel Filan: yeah, I like that category theory has pictures to look at Mark Xu: intuitively, is the set of possible worlds, is grouping into variables, a partition is a property over worlds that you care about, and the history is the smallest set of variables that uniquely determine the property you care about Glenn Willen: Thanks Mark that is incredibly helpful, I'm going to stare at that for a minute. Quinn Dougherty: Mark that's hugely helpful Diffractor: Yup, Mark is exactly correct Kyle: Agreed. Thanks Mark! Mark Xu: “orthogonal” in this intuitive sense means that the two properties you care about can be computed from disjoint variables, so they would be “independent” or “uncorrelated” Adam Scherlis: (yeah I think the quantum version is a bunch of things people talk about in quantum information -- partition ~ observable, factorization ~ tensor factorization, history ~ support of an observable) Glenn Willen: Do you have a link to the definition of "support" in this sense? A quick google didn't turn anything up. David Manheim: Glenn: https://en.wikipedia.org/wiki/Support_(mathematics) Glenn Willen: ah okay |
Anonymous 10: Any factorization has enough information to give you any partition? Scott: I think what you're asking is: In the definition of factorization, we needed for there to be a unique element for each way of assigning values to all the factors. So you can always make large enough that specifying the values of is sufficient to specify the value of . For example, if you take , that will be enough because of our definition of factorization. Also, the definition of factorization is important for the fact that history is well-defined because of this "smallest set of factors." The fact that satisfying this property of being sufficient to compute is closed under intersection, comes from the fact that we're working with a set of factors in the form of factorization. Anonymous 10: So is the history an equivalence class, kind of? Or is it one particular smallest set? Scott: The history is the smallest set of factors. By which I mean: for any set of factors that has the property that if I told you the value of all of the factors in that set, that's sufficient to determine —for any set of factors that satisfy that property, that set of factors must be a superset of the history. It must at least contain the things in the history. Anonymous 10: There's exactly one history? Scott: There's exactly one history. I needed finiteness for the fact that I can do all this. It turns out that this definition would not have been well-defined if I didn't say "finite," or at least "finite-dimensional," because we only get that things are closed under finite intersection. So this is part of where we need finite, although there's some hope of being able to generalize past finite. Anonymous 11: For all the factors that aren't in the history, is the common refinement of that factor and the same as that factor? Scott: If you take all the factors outside of the history, and you common-refine them all together, you'll get a new partition. It's not going to be the case that if you take the common refinement of this partition with , you get back itself. It is going to be the case that this partition is orthogonal to . So if you take the complement of the history of and you take the common refinement of all of those things, you'll get this new partition that is orthogonal to , and it's in some sense the finest partition that is orthogonal to . Anonymous θ: I’ve been thinking over in my head what happens if you've got a six-element set factored into two and three, but I'm kind of getting the sense that it might be fairly trivial with something like that, and in order to really get an idea of what's going on with history, you'd need to go into something with more than one reasonable factorization, like 12 could be— Scott: We might want to have a set that's large so that we can say some nice nontrivial stuff, but at least here, we're working with a single fixed factorization. Having multiple factorizations is useful because you need multiple factorizations in order to have a big rich structure, but we're only going to be working with one of them. Anonymous θ: Sure. Scott: Okay. I think I'm going to move on to an example now. |
Game of Life
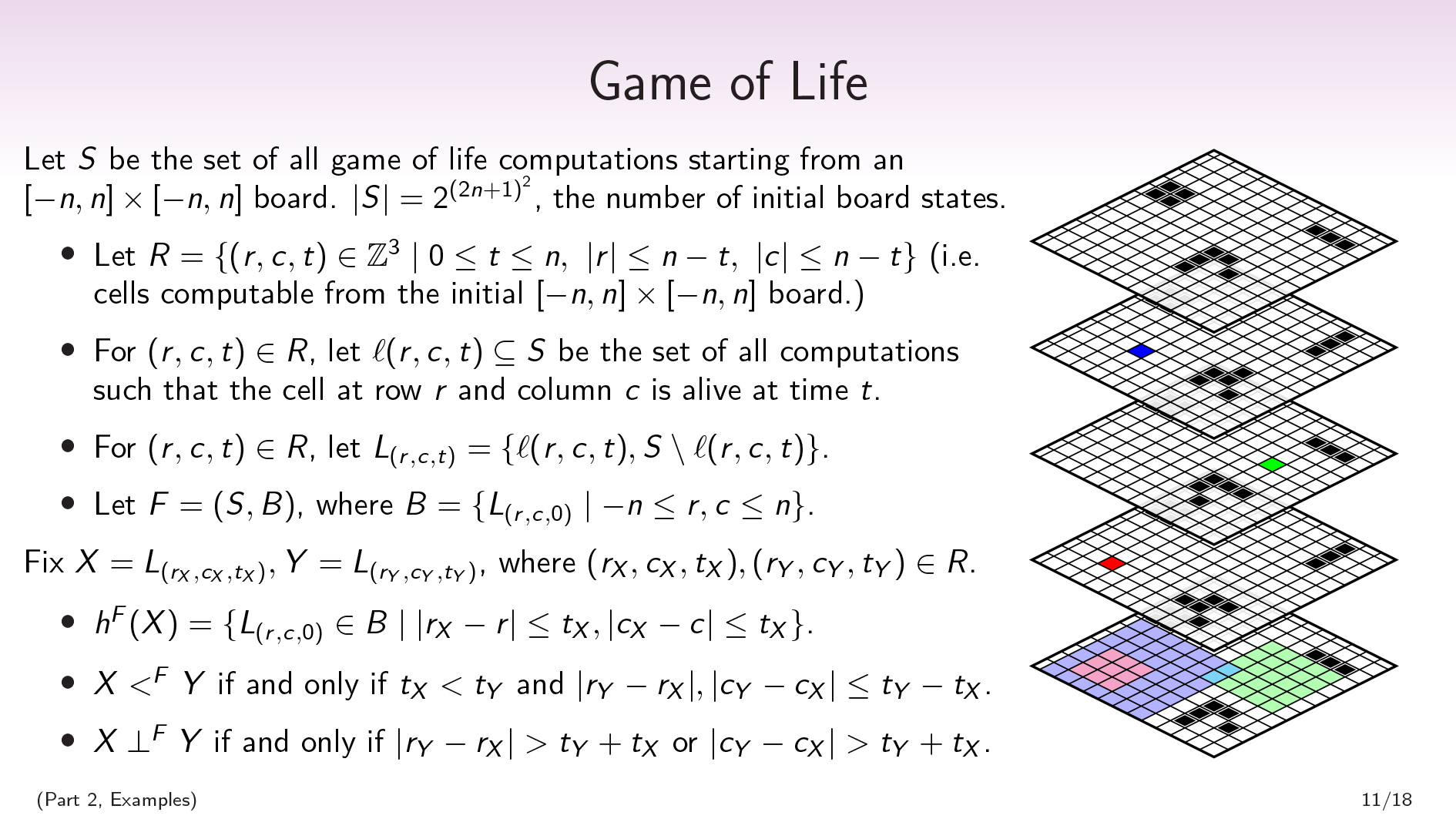
Scott: Let's let be the set of all Game of Life computations starting from a board of some size.
I don't want to have to deal with weird stuff about the boundary, and I also want it to be a finite factored set. The way that I'm dealing with this is I'm looking at this pyramid of only the cells that are computable from the initial board state.
So you can imagine starting with your board, and we're just pushing the computation forward in time. (In the picture, going up is forward in time.) And as we progress through the time steps in Game of Life, our board is getting smaller, because the boundary is shrinking in to say, "I don't know what this is anymore, because it's dependent on stuff outside the boundary." So we have this set of all pyramids of Game of Life computations.
Because Game of Life is deterministic, we actually have a bijection between the set of all Game of Life computations and the set of all initial board states. And we have an obvious factorization of the set of all initial board states, which is that we have one factor for each cell that is the partition that separates out "Is that cell alive or dead at time ?".
We can also talk about other partitions. There are a whole bunch of partitions on this huge structure.
I'm going to draw attention to partitions that take a cell and take a time step, and ask the question "Is this cell alive or dead at this given time step?", which is going to separate out your space into two sets.
In this picture on the right, I have three (cell, time) pairs—the red cell, the blue cell, and the green cell—which correspond to partitions. And the grid on the bottom is the initial state, time .
The multi-cell squares in the initial board state are the history of the red cell, the blue cell, and the green cell. So the light red squares on the bottom are saying, "Which cells at time do you need to know the value of in order to be able to compute the value of the red cell at time ?".
This, again, pushes the picture that histories are like past light cones. We can see that the history of the red partition is a subset of the history of the blue partition. And so the partition corresponding to “Is that red cell alive or dead?” is before the partition corresponding to “Is that blue cell alive or dead?”.
The red partition is orthogonal to the green partition. And the blue partition is not orthogonal to the green partition, because their histories intersect.
The blue cell and the green cell are almost orthogonal, in that if I conditioned on the values of these two cyan squares at the bottom, then they would become orthogonal. So that's what we're going to talk about next—conditional orthogonality, or "When are things orthogonal conditional on certain assumptions?".
Conditional Orthogonality

Scott: To define conditional orthogonality, we're first going to define conditional history. The conditional history of given is the smallest set of factors (again, smallest in the subset ordering) satisfying these two conditions.
The first condition is basically the same as in history, except we make this assumption that we're in . So the first condition is saying that if I want to know the value of , and I'm working under the assumption that my point is in , it suffices for me to know the value of all of the factors in .
The second condition is going to be a little hard to motivate. It's not going to mention ; it's just going to be about and . The second condition says that if I take an element of and I want to determine whether or not it's in , this process of determining whether or not it's in can be parallelized:
- I can look at the factors in and ask, "Is the assignment of values to the factors in consistent with my point being in ?"
- And then I can separately look at the factors in and ask, "Is the value of the factors in consistent with my point being in ?"
And then if both of these questions return "true," then my point has to be in .
I'll say that without the second condition, conditional history would not even be well-defined. I do not think it should be obvious that it's well-defined anyway! In order for this history to be well-defined, I need to be able to say that there's a smallest set of factors (in the subset ordering) satisfying these conditions.
One way to see why we need the second condition is: You could imagine that we have a finite factored set that consists of two bits. There's my bit and there's your bit, and they're each either or . And my factorization is the obvious factorization, with one factor for “What is my bit?” and one factor for “What is your bit?”. So then the history of “What is my bit?”, the history of the partition that separates out the different values that my bit can be, is just going to be the one factor that is “What is my bit?”.
But then imagine conditioning on the assumption that our bits are the same. In that case, knowing my bit is sufficient to know my bit, and knowing your bit is sufficient to know my bit, but the intersection of knowing my bit and knowing your bit is empty.
This is why we need the second condition. The second condition is saying that the act of conditioning on the fact that the two bits were the same, entangled my bit with your bit; so you're not allowed to then take one and not the other. This makes conditional history well-defined.
From conditional history we're going to be able to define conditional orthogonality. We say that and are orthogonal given the subset if their conditional histories are disjoint. And we'll say that and are orthogonal given a partition, , if and are orthogonal given each individual part in .
I think it's pretty hard to motivate this definition. If I go over to categorical language, I think I have a picture that makes it look a little bit nicer than this, or a little bit more motivated. But I'm mostly just going to appeal to this definition's consequences to try to convince you that it's a good definition, as opposed to trying to push that it's really natural.
Compositional Semigraphoid Axioms

Scott: Here's some consequences. This is just a bunch of properties showing that conditional orthogonality is pretty well-behaved.
There are five graphoid axioms, of which the first four are the semigraphoid axioms. And then there's the axiom of composition, which is the fifth item on the above list and is the reason we have a "compositional" semigraphoid.
The field that works with Pearlian inference sometimes talks about these axioms. When they talk about it, they talk about it with sets of variables; we're instead working with partitions. So where they took a union of a set of variables, we're instead going to work with a common refinement. But that's all an easy translation.
All of these properties have a in all of the conditions. You can just ignore the and think of it without the if you want to.
This first property says that is orthogonal to if and only if is orthogonal to , which hopefully should make sense.
The second and the fifth are converses that together say that is orthogonal to the common refinement of and , if and only if is separately orthogonal to and to . So they're collectively saying that being orthogonal to a common refinement is equivalent to being orthogonal to each of the pieces.
That's especially nice, because it's saying that if you want to know whether something is orthogonal, it suffices to break it up however you want and check whether it's orthogonal to each individual piece.
d-separation in DAGs also satisfies all these properties.
Jasper Chapman-Black: I wish the theorems/axioms had Game of Life examples Daniel Filan: oh so if and are variables, then is like the variable that's the tuple of and which helps in reading this Ramana Kumar: @Daniel yes I think so Daniel Filan: which makes me think it should be written ... Diffractor: is always used to denote supremum in posets Ramana Kumar: it's using because it's a join in the poset of partitions Anonymous ε: I don't understand why people use in posets/lattices to mean "is coarser / is less informative than" rather than the opposite. As it is, points in the opposite direction from the subset symbol, in cases where those both make sense. Also points in the opposite direction from the material implication symbol Ramana Kumar: I think Scott will use the opposite direction (for partition refinement) in his write up. Anonymous ε: Oh, cool! Anurag Kashyap: @[Anonymous ε] I think the notation may have been imported from topology where means ' is finer than ' and is a partial ordering again. Anonymous ε: It occurs to me that if happens before , we usually say and also is coarser than . So it actually makes sense if we want to talk about time! Scott: I decided to go against the more standard partition refinement direction on purpose, and intend to do that consistently. My main reason is that I want my partitions to be like Pearl's sets of variables, so I want finer things to be larger, because they have more variables, (and more information) |
The Fundamental Theorem

Scott: Those were just some nice properties. The main thing I want to push is that conditional orthogonality is really a combinatorial fragment of conditional independence.
We're going to show that is orthogonal to given if and only if is independent of given in all probability distributions that you can put on that factored set. (If you divide both sides by the probability of in the equation, it's more obvious that this is asserting conditional independence.)
And so I need to explain what it means to put a probability distribution on a factored set.
A probability distribution on a finite factored set is just a probability distribution on that factors. What I mean by “factors” is that you can view it as coming from a probability distribution on each of the individual factors in your factorization. I take a probability distribution on for each , and then I multiply together all those probability distributions and take the product of those measures to get a probability distribution on .
We'll call a probability distribution on a probability distribution on if it can be constructed in this way; or equivalently, if the probability of any given element is equal to the product of the probabilities of each of the parts in a factor that contain that element.
And then we get the fundamental theorem of finite factored sets. We can also probably extend this theorem to talk about all probability distributions in general position, or something like that, rather than talking about all probability distributions; but I'm not going to worry about that right now.
This theorem is going to allow us to infer orthogonality data from probabilistic data. If we're given a bunch of probabilistic data—for example, a big probability distribution on our set—we can use the fundamental theorem to tell us when things should be orthogonal.
Next, we're going to show how to infer temporal data from orthogonality data. And we're going to do that working entirely combinatorially; so this slide is actually the only place I'm going to mention probability. Part of the thing that I like about this is that I kind of push all the probability away and think about these questions just using combinatorial properties.
I think I'm going to take another question break.
Alex Ray: Does this have a computable partition function? (It seems like it should be since this is all combinatorics so far) Diffractor: What do you mean by "this" and "computable partition function"? Alex Ray: Nevermind these are just all probabilities Daniel Filan: so, if I have a Bayes Net , and a probability distribution on it, am I right that that wouldn't be a probability distribution on the related finite factored set? Ramana Kumar: @Daniel, what is the related finite factored set you have in mind? David Manheim: This is what I was trying to ask last time... |
Anonymous 12: I would like to second Daniel's question, which I also do not understand. Daniel Filan: Can I say it? Anonymous 12: Yes. Daniel Filan: Alright, great. Let's say I have a Bayes net with three variables—let's call them , , and for the nodes. There's an arrow from to . There's an arrow from to . And in this Bayes net I've got some probability distribution on , then a distribution on conditioned on , and then conditioned on , and that's how I get my whole distribution. And let's say they're all binary variables. In the finite factored sets view, this is a set of eight elements, and my is a factorization into three different— Scott: I'm going to stop you there. I said that I have a way of converting a Bayes net into a finite factored set. It's not the obvious way. Daniel Filan: But if I foolishly did it the wrong way, which is the way I'm imagining I would do it, then this wouldn't be a probability distribution on that finite factored set. Am I right about that? Scott: Yeah. Daniel Filan: Doesn't that seem weird and crazy? Scott: I think the thing that's going on there is that I feel like I'm living in a world where the concept of factorization doesn't exist yet. And so I used the word "factorization" twice in this talk in different ways: once when I said Pearl is assuming factorization data, and once when I said we're going to infer a finite factored set. And "factorization" was the right word to use in both of those places, but you should be thinking of it as a different kind of factorization. Like, the finite factored set structure is not equivalent to just “What are the variables that Pearl should have used?” or something like that. So in this example, I can say that the finite factored structure I'll want is a factored set. I have one factor for the value of ; I have one factor for a function from the value of to the value of ; and I have one factor for a function from the value of to the value of . My factored set is going to give me 32 different possibilities. And then I'm going to project down and hide some of that information from you to get the eight possibilities you're talking about. The point of the factored set is that the factors are independent, and so you shouldn't put a factor on and another factor on , because they're not independent. You can put a factor on and a factor on a function from to . Daniel Filan: Oh. So the factors are supposed to be like the things that were true at the origin of time. Scott: Yeah. Daniel Filan: Oh, okay. Cool, thank you. |
Ramana Kumar: I think there are FFSs that don't have a corresponding Bayes Net. Also, the factors typically don't correspond to the random variables in the Bayes Net when there is a corresponding Bayes Net. (This is kind of what Scott is saying right now.) John Wentworth: The obvious related FFS would be an SEM rather than a Bayes net - i.e. each node has an independent random input, and everything is deterministically computed from those. The random inputs are the variables/partitions. |
Gurkenglas: The probability distributions are the reasons that the sets have to be finite, yes? Scott: No, the probability distribution is not the issue. I'll say why we want things to be finite. Imagine I took an infinite-dimensional factored set that is all infinite bit strings with the obvious factorization, which is that I'll have one factor for each bit in the bit string. Consider the partition that is asking whether you have the all- string, which has two parts. One of them contains the singleton all- string, and the other contains everything else. Call this . Then let's call the partition that asks "Are you the all- string?". For all probability distributions that you can put on this infinite factored set, at least one of and is going to need to have probability zero. In order to make it so that you have a non-zero probability of being all-, you need each individual bit to be converging to very, very likely . And then the all- string has probability zero. So one of these two partitions is going to be probability zero in any given distribution on your factored set. Which means that these two partitions are going to be independent of each other in all distributions. And it really feels like these two partitions should not be orthogonal. |
Ramana Kumar: (dimension = cardinality of ) Anonymous ι: Ah. Like the infinite additivity problem? Alex Mennen: you could restrict attention to partitions into clopen sets (I mean finite Boolean combinations of factors) Diffractor: I proved that if you consider just hausdorff quotients on compact metric spaces, you can take common refinement of any collection of quotients and it'll still be just as nice topologically I was thinking kinda along these lines independently, but more from a topology angle, and I'm pretty dang sure that's the way to go |
Gurkenglas: I was mentioning that because we would have to generalize your notion of probability distribution. When the set gets too large, then you also have to use something larger than real numbers in order to tell between all these different possible sets. Scott: It's not clear. I am personally very excited about extending factored sets to the infinite case, but I think that it runs into problems that are not just probability. For example, you have to do some weird stuff with the definition of history in order to make it all work out. You don't actually want to use history, because it's not going to be well-defined. Just getting the compositional semigraphoid axioms on an arbitrary-dimension factored set is going to be complicated in itself. But I'm still optimistic about it. I'm still excited about infinite factored sets, but I think it's going to take a lot more work, and I think that more work is not just going to be because of probability. But I think some of it will be because of probability. So you asked the question: Is it because of probability that we have to do finite stuff? And I said no, but my answer is it's not only the probability. There's more than just that that causes problems in the infinite case. Anonymous 13: Would it make sense in this infinite-bitstring case to consider a sequence of finite factored sets, where each one is a superset of the previous factorization and you just add one more bit? Scott: My intuition is that in the infinite-bitstring case the thing that makes sense to do is to instead talk about finite-dimensional flattenings. So you start out with an infinite-dimensional factored set, and then you can merge a bunch of the factors so that you only have finitely many different equivalence classes of your factors, and this is like a flattening of your factored set. And then you work over that space. But that's just what I'd do in order to save the other parts. I think that the fundamental theorem is just not going to be saved. I think that factored sets are still going to be interesting in the infinite case, and we're going to want to do stuff with them. But independence is just not going to be enough to infer orthogonality in the infinite case. Although the other direction will hold; you'll still have orthogonality imply independence in all distributions. My intuition is that I'm excited for arbitrary factored sets, but I suspect that even the fundamental theorem does not work. My guess is that the fundamental theorem can be extended to the finite-dimensional case, but not the infinite-dimensional case. But I'm mostly thinking about and working on the finite case. |
Temporal Inference

Scott: We're going to start with a set , which is going to be our sample space—although I don't want to carry around any probability intuitions. I want to think about everything combinatorially, and I want the only place probability shows up to be the previous slide. is a finite set, and it’s something like the space of all possible observations we can make.
One thing you might think that we'd want to do would be to infer a factorization of , but that's not what we're going to do. Instead, we're going to find a factored set model of . We're doing this because I'm thinking of as the observably distinct situations that we can be in, and I want to allow for inferring latent structure.
There was a question about how to make a factored set out of a three-node Pearlian DAG. There were eight possibilities, but I said, "We don't want a factorization on an 8-element set; we want a factorization on a 32-element set, and then we want to send that over to an 8-element set with a function." In that example, the function was latent structure.
In the model :
- Not assuming is injective is what allows for latent structure.
- Not assuming is surjective means that it's okay if some of the elements of don't actually get hit. This is useful if we just want to start with some variables and take their product and have that be my sample space. I don't want to assume that every combination of variables is necessarily possible; and that's what not assuming surjectivity is going to do.
Given a partition of , we can send that partition backwards across the function to give a partition of . Which is just saying that if you have all of your parts, and then you take the preimage as functions of the parts, this will give you a partition of your original space.
We also have an orthogonality database on , which is a collection of rules about orthogonality in . One place you could think of this database as coming from is a probability distribution. You sample a whole bunch of times, and you get a probability distribution, and whenever you observe that two things are independent you'll put in a rule saying they're orthogonal. And then whenever you observe that things are not independent, you put in a rule that says those things should not be orthogonal. Which makes sense because of the fundamental theorem.
But you could also imagine that orthogonality database coming from anywhere else. This is entirely a combinatorial notion.
A "rule" means putting a triple of partitions either in the set (for "orthogonal") or the set (for "not orthogonal").
So we have this collection of rules, and we want to infer a factored set model. We're not actually going to be able to infer a full factored set model, because whenever you have one model, you can always just add in more factors and add in more stuff, and then just delete all that data. Instead, we're going to be able to infer properties of factored set models—properties that all factored set models that satisfy our database are going to have to satisfy.
One of these properties is: we'll say that is before according to the database if of is before of for all models that satisfy our database.
This is what we're going to mean by temporal inference. Now we have a mathematical specification of (though not a computational procedure for), "Given a bunch of orthogonality rules and non-orthogonality rules, when are those rules sufficient to infer a temporal relationship?"
I've specified this combinatorial notion of temporal inference. But I haven't shown this notion isn't vacuous. So there are these questions: “Are we ever going to be able to infer time with this?" "How is our approach to temporal inference going to be able to compare to Pearlian temporal inference?”
Pearlian temporal inference is actually very strong. If you have a big system with a bunch of variables, you're very likely going to be able to infer a lot of temporal relations from it. Can we keep up with that?
To answer that question, we're going to look at an example.
Two Binary Variables (Pearl)

Scott: If and are independent, then we're not going to have a path from to or vice versa. If and are not independent, then maybe there's a path from to , maybe there's a path from to , maybe there's some third node that has a path to both of them.
In either case, we're not going to be able to infer any positive temporal relationships.
To me, this feels like it's where "correlation does not imply causation" comes from. If you just have two variables, you can't really infer causation; Pearl needs a lot more variables in order to have a richer combinatorial structure that will allow his approach to infer time.
But the natural next question is: "Is independent of ?"
In the Pearlian ontology, we have and , and those are our variables, and we ask whether they're independent.
In the factored sets ontology, we take our and our , and the first thing we do is we take a product of and , and now we have four different possibilities. And then we forget all our labels, and we consider all possible variables on these four possibilities. And one of those variables is —are and the same?
And if is independent of , then the finite factored set paradigm is actually going to be able to conclude that is before .
So not only is the paradigm non-vacuous, and not only can it keep up with Pearl and infer things that Pearl can't, but also we can use it to infer time even from two binary variables, which is kind of the simplest possible thing that you could hope to be able to do.
Pearl is also going to be able to infer some things that we can't, but as a reminder, Pearl is using extra assumptions. Relative to our ontology, there's extra factorization data that Pearl is using; and I'm not exactly sure where one would get that extra data.
Two Binary Variables (Factored Sets)

Scott: Let be the set of all binary strings of length two. We're going to define an orthogonality database which is only going to have two rules.
- The first rule is that ("What is the first bit?") is orthogonal to ("Do the bits match?"). The here is just saying we're not making any conditions. (You don't have to worry about the complicated conditional orthogonality definitions for this proof; everything is just going to be normal orthogonality, which will make it easier to think through.)
- Second, is not orthogonal to itself. This just means that is nondeterministic; both of the parts in are supported by our function , both parts are possible.
If we got this orthogonality database from a probability distribution in general position, we would have a lot more rules in our database. We would have a rule for basically every triple of partitions. But inferring time is going to be monotonic with respect to adding partitions: adding more rules just lets you infer more stuff. So we can just work with the smallest database that we're going to need in order to be able to show that ("What is the first bit?") is before ("What is the second bit?").
You should probably just assume that everything is not orthogonal to itself; but " is not orthogonal to itself" is the only statement of that form we're going to need.
So, theorem: is before . Which, recall, means that is before for all factored set models.
Proof. First, we’re going to prove that is weakly before :
- Let be a model that satisfies our database, and write for the history of , etc. Since is orthogonal to , we're going to have that and are disjoint.
If the makes it a little bit harder to see what these things are saying, you can kind of ignore that part. If you just think of , , and as partitions of , where , it might be a little bit easier to understand what's going on here.
- Because is in , is orthogonal to , which means the history of is disjoint from the history of : .
- Because is not orthogonal to itself, the history of is not disjoint with itself, i.e., it's not empty.
- is a coarsening of the common refinement of and : . And since we can compute the value of from the values of and , we can also compute the value of from the values of and . Which means that the history of , , has to be a subset of .
To see why this is, recall that a history is the smallest set of factors I need to be able to compute a partition's value. If I have a set of factors that is sufficient to compute the value of and sufficient to compute the value of , that's going to be sufficient to compute the value of , because is a deterministic function of .
- We also get this subset relation for any other combination of , , and . So , and .
- Since , and is disjoint from , we get that —which is to say, is (weakly) before in all models.
Let's extend this further, and show that is strictly before .
- Assume for the purpose of contradiction that . Since , we'll then just have that is a subset of , because will be .
- But is disjoint from , which means that is just going to have to be empty. But we assumed that is nonempty; so this is a contradiction.
Thus is not equal to . So is a strict subset of , and is before .
Proofs in this space largely look like this. We look at a bunch of histories of our variables, we look at various different Boolean combinations of our histories, and we keep track of when they are empty and non-empty; and we use this to eventually infer that some of our histories are subsets of others.
I haven't spent much time on temporal inference, and I haven't really looked into the computational problem of inferring time from orthogonality databases yet. I basically just have two proofs of concept: this one, and another proof of concept that uses something that looks a little bit more like screening off, and uses conditional orthogonality to infer time in a more complicated situation.
| Vanessa Kosoy: Can it happen that some set of rules is consistent with a probability distribution on but has no models? |
Applications / Future Work / Speculation

Scott: I'm going to break some directions I want to go in into three categories. The first category is inference, which has a lot of computational questions. The second category is infinity, which has more mathematical questions. And the third category is embedded agency [? · GW], which has more philosophical questions.
Inference
Decidability of temporal inference — I haven't been able to even prove whether the temporal inference method I just described is decidable, because there are infinitely many factored set models that you might have to consider.
I suspect it is decidable. Given the size of , there is an upper bound on how complicated of an you have to consider; and I conjecture that this upper bound is small, and probably computable by some simple function.
There's then the further question of whether we could do efficient temporal inference.
Conceptual inference — In our example, we inferred that is before , and we kind of inferred this structure that what's going on is that the universe is computing and , and then it's computing from together with . So and look like primitive properties, and looks like a derived property that you might compute from and . And I think that this "being a primitive property" is actually also pointing at something about what kind of concepts you want to use.
Imagine that I have a number that's either 0 or 1, and it's also either blue or green. I can define a property called "bleen," which is that the number is a blue 0 a green 1. Now I have these three different properties I can talk about: number, color, and bleen-ness.
And we're doing something that looks like inferring that color is primitive, while bleen-ness is derived.
This system has the potential to be able to distinguish between blue and bleen. I think finite factored sets have the potential to do to "there's no principled difference between blue and bleen" what Pearl did to the adage "correlation does not imply causation". So that's a thing I'm really excited about maybe being able to do.
Temporal inference from raw data and fewer ontological assumptions — We can do a more end-to-end form of temporal inference, one that doesn't have to see where our variables are coming from.
We can do temporal inference with deterministic relationships.
Time without orthogonality — You could actually imagine starting with a huge factored set with a large number of dimensions, and then taking some and forgetting a lot of the structure and just taking some weird subset of our big factored set.
If you do this, it might be the case that there is no orthogonality besides the vacuous orthogonalities. There might be no orthogonality in , but you can still make inferences from the probability distribution. The probability distribution will still lie on some algebraic curve that's pointing at the structure. And so even when there's no orthogonality at all, you might still be able to infer temporal relationships just from the probabilities.
Conditioned factored sets — Instead of assuming there's a factored set model of , you could imagine a partial factored set model where my can be a partial function.
This kind of corresponds to pretending that you had a factored set and you got some samples from , but those samples got passed through a filter. And so you can try to do inference on the more general class where maybe your data also went through a filter before you got it.
Infinity
Extending definitions to the infinite case — I talked a little bit about this earlier. I think that the fundamental theorem should be able to be extended to finite-dimensional factored sets, where by "finite-dimensional" I mean that is finite, but is infinite. But my proof assume finiteness, not just finite dimension.
Continuous time — Here's something I'm pretty excited about. Basically, I think that Pearl is not really ready to be continuous. There’s this blog post by Eliezer called Causal Universes [LW · GW] that pointed out that physics kind of looks like a continuous Bayes net. But we didn't have a continuous Bayes net, and we still don't have a continuous Bayes net; and I feel like we're a lot closer to having a continuous Bayes net now.
Everything's still finite, and so we're running into problems there. But I think that once we’ve figured out this infinity stuff, we're going to be able to make things continuous, and I think that for two reasons.
- The Pearlian world is really dependent on parents. We really cared about if this node was a parent of this node. In the finite factored sets paradigm, we only care about the analog of ancestor. So we're not really talking about an edge from this node to this node; we're only talking about “Are there paths?”, which is a lot closer to being able to be continuous.
- We have this ability to zoom in and out on our variables. Instead of having fixed variables, we're taking them to be partitions, which allows for this zooming in and out.
I think that because of these two properties, we're a lot closer to being able to have not just continuous probabilities, but continuous time—continuity in the part that in Pearl was the DAG.
New lens on physics — Finite factored sets might be able to shine some new light on physics. I don't know; I'm not a physicist.
Embedded agency
I'm mostly viewing finite factored sets as the successor to Cartesian frames [LW · GW]. In fact, if you look at the definition of a factored set model, it's almost equivalent; a binary factored set model is basically a Cartesian frame.
So I want to be able to model things like embedded observations. I want to be able to take a partition that corresponds to an action of an agent and take another partition that corresponds to an observation, and be able to say, "Ah, the thing that is deciding, this agent, kind of gets to do whatever functions it wants on this other thing." And I actually have some preliminary thoughts on how to define observations in a factored set world.
A point I want to make here is that in these embedded agency applications, I'm largely doing something different than I was doing in the temporal inference set. I focused in this talk on being able to do temporal inference because I think it's really concrete to be able to say, "Hey, we can do something like Pearlian temporal inference, but better and with fewer assumptions."
When I'm thinking about embedded agency, I'm not really thinking about doing inference. I'm just thinking about being able to set up these factored set models where I would otherwise set up a DAG.
Or it doesn't even need to be a DAG. Anywhere we would want to set up a graph that has edges between nodes that correspond to causality, or information flow, or something like that, there's some hope of being able to translate that over to the factored set world and thus be able to have it work better with abstraction.
So I'm not really thinking about where these things are coming from. I'm more thinking about "How we can use this as a new way of modeling things that we would otherwise model with graphs?"
So:
Embedded observations — I have a definition of embedded observation. It looks a lot like the Cartesian frames version, except it's cleaner.
Counterfactability — I have a notion of counterfactability that I can get out of factored sets. It's basically taking the position that you can't always take counterfactuals, but some places you can. I'm using the fact that a factored set takes your world and views it as a bunch of tuples to give me "interventions." My "interventions" correspond to coming in and tweaking some of the values in the tuples. So the factored set is also giving you a theory of how to do interventions.
Cartesian Frame successor — I think this framework is largely capturing a lot of the Cartesian frames content.
Unraveling causal loops — This is largely what I talk about in Saving Time [LW · GW]. It feels like often we have these causal loops, and it feels like a bottleneck to being able to not have causal loops in our picture is to be able to have something that has time and also abstraction in the picture. And that's kind of what we're doing.
Conditional time — This is observing that just like we defined conditional orthogonality, we could define conditional time. We just take conditional time to be that the conditional histories are subsets of each other.
I have some hope that this might actually be interesting and useful, especially for the unraveling causal loops thing. I think that conditional time allows you to have multiple different timelines on your structure simultaneously, and have them be concretely playing together. I'm not sure whether it's actually going to end up being useful, but I'm just noticing that there's a very tempting way to define conditional time.
Logical causality from logical induction — One of the first things that we did after finding logical induction was to ask, "Can we extend this to a theory of logical counterfactuals?" And we said, "How can we do this? Well, we could take our big probability distribution over logical sentences that we have at any given time. Can we do Pearl to that?”
And the answer is, "No, because there's a whole bunch of determinism everywhere."
I think that we still can't just go and do logical causality from something like logical induction. Basically, the finite factored set framework kind of doesn't believe in the uniform distribution on a four-element set. And I have some hopes of being able to fix this, but if you imagine a four-element set and the uniform distribution on it, and you consider the four two-part partitions on your four-element set (like the , , and in our "two binary variables" example). If you have the uniform distribution, we have that is independent of , and is independent of , but is not independent of .
So the independence structure of the uniform distribution on a four-element set does not actually satisfy the compositional semigraphoid axioms. It specifically doesn't satisfy the composition axiom.
Similarly to how I'm excited about the infinite case even though the fundamental theorem will fail, I think that we're not going to be able to just directly use the fundamental theorem, but we could still ask, "What are some things consistent with this data?" We might have some extra independence that comes from something other than orthogonality. I could talk more about that, but I think I'll move on now.
Orthogonality as simplifying assumptions for decisions — We talked about orthogonality as coming from independence, but I think part of being an agent interacting with the world is that there are some parts of the world out there that I just believe are not going to be affected by my action. And I make this assumption, and I act based on this assumption. And I think this is another way that we can think of orthogonality as coming in.
And so I just wanted to point out that orthogonality doesn't need to come from probability. We can think of it as coming from somewhere else.
And finally, conditional orthogonality as an abstraction desideratum — This is largely the kind of stuff that John Wentworth talks about. Like, an abstraction of should have the property that everything that I care about is orthogonal to , given the abstraction of . So I only throw away irrelevant data, and I can express "I only throw away irrelevant data" as "everything I care about is orthogonal to the underlying structure, given the abstraction."
All right. Those are my long rants about potential research directions for finite factored sets.
I'm going to say one more thing that's not on this slide: You can think of history as similar to entropy. You can think of my notion of history as a non-quantitative version of entropy.
And actually, when proving the semigraphoid axioms, I use some lemmas that look a lot like theorems about entropy, and then I replaced the sums and the expectations with unions.
And when you look at time—well, time is the subset relation on history, which is like saying that time is an inequality relation on entropy, and "later" corresponds to higher entropy. This is speculation, but this is a whole other ontology that you could put on what history means, etc.
Q&A
[Select questions from the Q&A are included below. The full Q&A transcript is here.]
[...] Anonymous 14: This is a really wide question—feel free to punt it—but could you say anything about your overall theory of change? How you see this work trickling into the real world over time and leading to safer systems? Scott: Man, I don't know. I'm trying to figure out what agency is. (laughs) Anonymous 14: Yeah. Scott: And I really have felt like a major bottleneck has been something about abstraction and time. I now feel like I have a much better ability to play with abstraction, and I think this might help me and might help people who are working on things very adjacent to me. That's in the embedded agency column here. I think that for factored sets helping with AI safety, the two main axes are (1) figuring out the stuff related to embedded agency, and (2) the possibility of being able to have a new analog of Pearl. I think that conceptual-inference-type stuff is especially useful for transparency. Being able to have systems and see what they're doing feels like something that's passing through conceptual inference, basically. Like, the extent to which we can distinguish between blue and bleen feels like it could help with being able to translate and oversee stuff. And when I’ve seen random applications that factored through, I often see places where I'm like, “Oh, yeah, if I understood this thing that I'm kind of saying is about embedded agency, but really is about understanding the world, then I'd be less confused about this random thing that I'm trying to figure out.” Vanessa Kosoy: You were saying before that one of the problems with Pearl's formalism is that it doesn't deal well with deterministic things. And that this is supposed to be one of the advantages of finite factored sets. So I'm confused about how it's going to work, because if I think about this temporal inference and you have something deterministic, then instead of a probability distribution , you just have a point in , and it doesn't seem to give you anything? Scott: Yeah, that's not what I meant by determinism. I meant that I want some variables to be deterministic functions of other variables. I'm not saying the whole system is deterministic; I'm saying some variables are deterministic functions of other variables. And, this is a long tangent, but I think largely where one might see a crux between me and Pearl is something like: I'm doing some variable non-realism. In a sense, I’m saying variables are super important; but in another sense, I’m also doing some variable non-realism, where I'm saying that there isn't a reality to the variable beyond its information content. So Pearl will have a structure that has all this “Who listens to whom?”, and there's this node corresponding to this variable and an arrow to a node corresponding to that variable. And I'm working with, “There isn't reality in the variable beyond its information content, so I wouldn't be able to have two variables that are deterministic copies of each other.” Or I would, and it wouldn't matter or something. My notion of a variable is only its information content. So, one thing that might happen if you tried to do temporal inference in Pearl and allowed for determinism is you might be able to say: Well, there's an arrow from to . But I can just make a copy of , , that's just a deterministic copy of . And I have an arrow from to that is just “copy ”. And then is not before , but is, in the Pearlian world. And I could just swap and , and now is before and is not. And doing stuff like this in Pearl is pointing out, “Well, there's this variable realism and things can be deterministically the same, but have different temporal properties.” And I'm taking seriously the variables just as information content, and that's one way that you can see the generator of this. Ben Pace: When did you do the work? Scott: Largely after I finally got Cartesian frames [LW · GW] out. I was like, “Okay, now I can do new stuff.” And then I was like, “Okay, the new stuff is better.” (laughs) But really, you could view Cartesian frames as building up to this. Largely, I was looking at Cartesian frames, and I was frustrated with how it felt like the whole function from to was not derived enough. I was like, “Oh, let's derive everything and not have basic things.” But I was like, “The function from to —well, what is that really?” Well for one, you have a function from to , which is saying that the information in is enough to determine the . But then also I have this , which is not just the set . I'm actually thinking of it as . There's this orthogonality between and . And I have this extra thing, which is the relationship between and . And what is that made of? There's this combinatorial notion of independence, where every way of combining an element of with an element of is possible. But it felt like there was more than that. When I draw the Cartesian frame to , there's this orthogonality assumption, and I'm saying that we can break the world up into and —what's going on there? That's largely the stuff that I was thinking about. [...] Ben Pace: Which are the bits that you think would be easiest for someone else to write posts about and add on to? Scott: I don't know, just however they're excited about applying it. I don't have a concrete path forward for doing something like that. I have some of these things that I have thoughts on, and I can write up some more on those. But mostly I'm just like: Here's a new way to model things that involve time, that isn't graphs. Go. (laughs) Yeah, I guess I could say things that I would be especially excited for somebody who really wanted to get into this to work on, and possibly write papers, or maybe coauthor papers. One thing would be figuring out the infinite case. Another would be just writing up how to translate from Pearl to this. I said I have a way to get from a DAG to a finite factored set. DAGs are a larger model class. And then I think that there are theorems of the form, “You can take a DAG and you can build a finite factored set from it, and time in the DAG exactly corresponds to time in the finite factored set.” Where Pearl is able to ask the questions, where I might be able to ask more questions, and d-separation is going to exactly correspond to Cartesian orthogonality. Proving all of that stuff that's really in the structure learning world seems good. If somebody who's an expert in structure learning wanted to do that and would actually be good at the task of figuring out how to get all that written up and get the paper such that we can sell this thing to structure learning people and then maybe do some sort of structure learning revolution, that would be cool. Infinity is the hard mathematical problem that would take some work. And then there’s connecting it up to structure learning. And then, a programmer that wanted to work on this could try to generate a bunch of theorems about temporal inference. Like, I gave a combinatorial thing where on one side you can search for factored set models that give you counterexamples to temporal properties, and on the other side you can search for proofs that look like the proof that I gave, where you do Boolean combinations of histories and collect properties on those. And I think that there's some hope of being able to do some computational temporal inference. And a programmer that wanted to try to do that, could do that. And that would be an interesting project and path forward. And then in the embedded agency world, it's just a whole bunch of taking places where we use DAGs, and seeing what it looks like with factored sets. Especially places where we use DAGs, and wish we had better ability to work with abstraction. I think that's where the fruit is going to be embedded-agency-wise. So those are four concrete handles. |
0 comments
Comments sorted by top scores.