On the Gladstone Report
post by Zvi · 2024-03-20T19:50:05.186Z · LW · GW · 11 commentsContents
Executive Summary of Their Findings: Oh No Gladstone Makes Its Case Why Is Self-Regulation Insufficient? What About Competitiveness? How Dare You Solve Any Problem That Isn’t This One? What Makes You Think We Need To Worry About This? What Arguments are Missing? Tonight at 11: Doom! The Claim That Frontier Labs Lack Countermeasures For Loss of Control The Future Threat That All Sounds Bad, What Should We Do? The Key Proposal: Extreme Compute Limits Implementation Details of Computer Tiers The Quest for Sane International Regulation The Other Proposals Conclusions, Both Theirs and Mine What Can We Do About All This? None 11 comments
Like the the government-commissioned Gladstone Report on AI itself, there are two sections here.
First I cover the Gladstone Report’s claims and arguments about the state of play, including what they learned talking to people inside the labs. I mostly agree with their picture and conclusions, both in terms of arguments and reported findings, however I already mostly agreed. If these arguments and this information is new to someone, and the form of a government-backed report helps them process it and take it seriously, this is good work. However, in terms of convincing an already informed skeptic, I believe this is a failure. They did not present their findings in a way that should be found convincing to the otherwise unconvinced.
Second I cover the Gladstone Report’s recommended courses of action. It is commendable that the report lays out a concrete, specific and highly detailed proposal. A lot of the details, and the broader outline, seem good. The compute thresholds seem too aggressive. I would suggest working to get agreement on the structure of intervention, while also talking price on the thresholds, and hopefully getting them to a better place.
Executive Summary of Their Findings: Oh No
According to the report, things are very much Not Great, Bob.
Here is their Twitter summary thread.
Edouard Harris: Here’s what we’ve been working on for over a year:
The first US government-commissioned assessment of catastrophic national security risks from AI — including systems on the path to AGI.
TLDR: Things are worse than we thought. And nobody’s in control.
We started this work with concerns, but no preconceptions. We knew there were solid technical reasons that AI could eventually pose catastrophic risks.
But we went in looking for reasons to change our minds.
We found the opposite.
Our overriding goal was to get to the truth. To do that, we had to do more than just speak to policy and leadership at the AI labs.
We also connected with individual technical researchers, many of whom are way more concerned than their labs let on in public.
Many of these folks came forward on condition of anonymity to share stories.
Let me tell you some of the most insane stuff we learned.
First off, inside one lab there’s apparently a running joke that their security is so bad that they’re doing more to accelerate the AI capabilities of US adversaries, than the adversaries themselves are.
Truly crazy. But this is where we’re at.
It’s a running joke, and also probably true, as I keep noticing. All our talk of ‘but what about China’ has to contend with the fact that China gets almost all its AI abilities directly from the United States. Some of it is spying. Some of it is training using our models. Some of it is seeing what is possible. Some of it is flat out open source and open model weights. But it is all on us.
Needless to say, if a major lab has this kind of running joke, that is completely unacceptable, everyone involved should be at least highly ashamed of themselves. More importantly, fix it.
More detail on this issue can be found in this good Time article, Employees at Top Labs Fear Safety Is an Afterthought, Report Says.
Quotes there are not reassuring.
In December we quietly polled a handful of frontier AI researchers and asked them:
What’s the chance we end up on a path to a catastrophic AI outcome, *during the year 2024?*
We expected <1%. But no:
Lowest we got was 4%. Highest: up to 20%.
That’s a wake-up call.
Catastrophic is very different from existential. If people were saying 4%-20% existential risk for 2024 alone, I would say those numbers are crazy high and make no sense. But this is a 4%-20% risk of a merely catastrophic outcome. If this is defined the way Anthropic defines it (so 1000+ deaths or 200b+ in damages) then I’d be on the low end of this for 2024, but I’m sure as hell not laying 26:1 against it.
One researcher said he was concerned that if $MODEL was ever open-sourced, that would be “horribly bad”, because the model was so potentially good at persuasion that it could “break democracy” if it was weaponized.
Still expects it to happen, within 18-36 months.
I expect this researcher is wrong about this particular model, no matter which model it is, unless it is a fully unreleased one well above GPT-4, in which case yeah it’s pretty terrifying that they expect it to get open sourced within three years. Otherwise, of course, that particular one might not get opened up, but other similar ones well.
Sometimes I wonder if people think we have some sort of magical unbroken democracy lying around?
Another frontier AI researcher says: “It’s insane that we’re scaling without having a good way of telling if a model can do dangerous things or not.”
Sure seems like it.
Does this mean the AI labs *are* insane? No. In fact many of them *want* to do the right thing.
But it’s like I said: nobody’s in control.
The low-hanging fruit least you can do is to make coordination mechanisms easier, enforceable and legal, so that if this was indeed the situation then one could engage in trade:
Here’s what I mean:
We visit one frontier AI lab. An executive there tells us, “we really wish $COMPETITOR wouldn’t race so hard.”
A few weeks later, we speak to $COMPETITOR. And they tell us the same thing about the first lab.
In other words, the labs are locked in a race that they can’t escape.
The AI lab execs still act like they’re running things. But the truth is, the race is running them.
Sounds bad. So what can we do? Well that’s where the last part of our assessment comes in: the Action Plan.
Because along with frontier AI researchers, we spoke to over a hundred of the US government’s top experts in WMD risk, supply chains, nonproliferation policy, defense, and other critical national security areas.
And we consolidated everything into a first-of-its-kind Action Plan: a set of recs for a US-driven initiative to improve AI safety and security, on the path to AGI.
To our knowledge this is the most extensive, deeply researched, and thorough plan of its type in existence.
You can get a copy of the full Action Plan and check out our summaries of its recommendations. [finishes with explanations and thank yous]
Gladstone Makes Its Case
Do I mostly believe the picture painted in that Twitter thread?
Yes, I do. But I already believed a similar picture before reading the report.
Does the report make the case for that picture, to someone more skeptical?
And what statements contain new information?
Section 0, the attempt to give background and make the case, begins mostly with facts everyone knows.
This is the first thing that could be in theory new info, and while I had no public confirmation of it before (whether or not I had private confirmation) it is pretty damn obvious.
Footnote, page 23: According to private sources, versions of GPT-4 that exist internally within OpenAI have even more impressive capabilities.
At minimum, of course OpenAI has a version of GPT-4 that is less crippled by RLHF.
They remind the reader, who might not know, that the major labs have exponentially grown their funding into the billions, and are explicitly aiming to build AGI, and that one (Meta) is now saying its goal is to then open source its AGI.
In 0.2 they lay out categories of risk, and start making claims some disagree with.
0.2.1 talks weaponization, that AI could become akin to or enable WMD, such as via cyberattacks, disinformation campaigns or bioweapon designs. Here most agree they are on solid ground, whether or not one quibbles with the risk from various potential weaponization scenarios, or whether one has hope for natural ‘offense-defense balance’ or what not. Taken broadly, this is clearly a risk.
0.2.2 talks about loss of control. This too is very obviously a risk. Yet many dispute this, and refuse to take the possibility seriously.
Here Gladstone focuses on loss of control due to alignment failure.
The second risk class is loss of control due to AGI alignment failure. There is evidence to suggest that as advanced AI approaches AGI-like levels of human- and superhuman general capability, it may become effectively uncontrollable. Specifically, in the absence of countermeasures, a highly capable AI system may engage in so-called power-seeking behaviors.
These behaviors could include strategies to prevent itself from being shut off or from having its goals modified, which could include various forms of deception; establishing control over its environment; improving itself in various ways; and accumulating resources.
Even today’s most advanced AI systems may be displaying early signs of such behavior, and some have demonstrated the capacity [44] and propensity [45] for deception and long-term planning. Though power-seeking remains an active area of research, evidence for it stems from empirical and theoretical studies published at the world’s top AI conferences [2,47].
This is all a very standard explanation. I have many times written similar paragraphs. In theory this explanation should be sufficiently convincing. Pointing out the danger should be enough to show that there is a serious problem here, whatever the difficulty level in solving it. Since the report’s release, Devin has been shown to us, providing an additional example of long term planning and also in various ways power seeking.
If anything I see this as underselling the situation, as it says ‘in the absence of countermeasures’ without noting how difficult finding and implementing those countermeasures is likely to be, and also it only considers the case where the loss of control is due to an alignment failure.
I expect that even if there is not an alignment failure, we face a great danger that humans will have local incentives and competitive dynamics that still push us towards loss of control, and towards intentionally making AIs seek power and do instrumental convergence, not as a failure or even anyone’s ill will but as the outcome we choose freely while meaning well. And of course plenty of people will seek power or money or what not and have an AI do that, or do it for the lulz, or because they think AI is more worthy than us or deserves to be set free, or what not.
A smarter thing that is more capable and competitive and efficient and persuasive being kept under indefinite control by a dumber thing that is less capable and competitive and efficient and persuasive is a rather unnatural and unlikely outcome. It should be treated as such until proven otherwise. Instead, many treat this unnatural outcome as ‘normal’ and the default.
That risk sub-category is not mentioned in the report, whereas I would say it definitely belongs.
They do talk about some other risk categories in 0.2.3, and agree they are important, but note that this report is not addressing those risks.
Apart from weaponization and loss of control, advanced AI introduces other risks of varying likelihood and impact. These include, among others:
● Dangerous failures induced intentionally by adversaries;
● Biased outputs that disadvantage certain individuals or groups;
● Prosaic accidents like self-driving car crashes;
● Exotic accidents due to interactions between complex networks of interdependent AI systems that may lead to cascading failures (“network risk”); and
● Unpredictable and uncontrollable technological change that could itself destabilize society in ways we cannot anticipate [1].
All these risks are important to consider and should be addressed. However, this action plan focuses on risks from weaponization and loss of control.
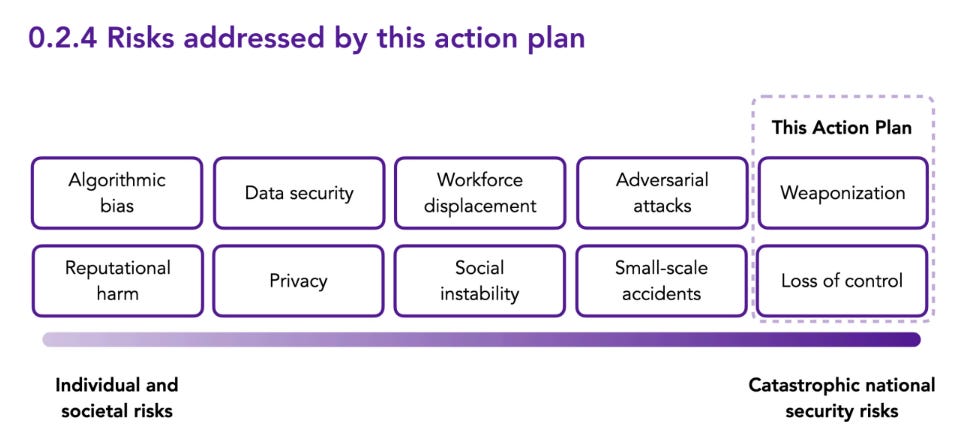
They emphasize here as they do elsewhere that the catastrophic risks are concentrated in only a few places, at least at present, most AI-related activity does not pose such risks and is good and should be allowed to proceed freely, and I again respond that this means they chose the wrong thresholds (price).
0.3 asks where the catastrophic risks might come from, in terms of who creates it?
They list:
- Domestic frontier labs.
- Foreign frontier labs (primarily China right now).
- Theft and augmentation of frontier models.
- Open release of advanced model weights.
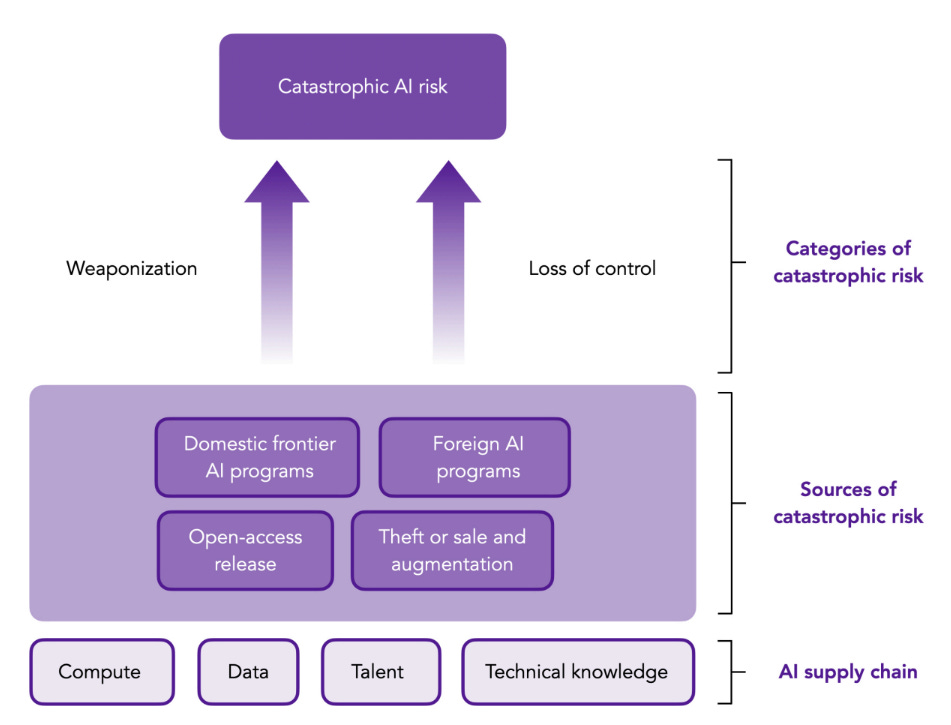
Yes. Those would be the four ways things could go wrong. In what they call the ‘medium term’ of 1-5 years, I am not so worried about foreign frontier labs. Open model weights threats are possible towards the end of that timeframe, things are escalating quickly and Meta might become competent some day. But most of my worry is on what comes out of the frontier labs of OpenAI, Anthropic and Google DeepMind, or a similar lab that catches up. That includes the possibility that some entity, foreign or domestic, state or non-state, steals the weights and then acts irresponsibly.
Again I emphasize that this mostly was not an argument. If you were already looking at the existing debate and were unconvinced, nothing so far should convince you.
Section 0.4 attempts to address arguments against regulatory action.
Why Is Self-Regulation Insufficient?
First they tackle in 0.4.1 the argument that self-regulation will be sufficient. They note that yes self-regulation is better than nothing, but it will not be enough, and provide the obvious counterarguments. I would summarize them as:
- Frontier labs face huge pressure to race each other, acting responsibly is seen as risking the other players winning while also being less safe. I would add that we still have not properly addressed the anti-trust concerns involved here, the least we could do is allow the labs to coordinate on safety without having to worry they are taking on legal risk.
- Their incentives to invest in security or safety are insufficient because they do not absorb the downside risks and negative externalities.
- When doing evaluations, there will be intense pressure and temptation to fudge the results, which is very easy to do if you are not adhering to the spirit of the rules and are effectively in charge of your own evaluation.
- AI labs lack access to classified threat intelligence. I haven’t been thinking about this issue, but it could easily cause underinvestment in security. It also means that the labs might not know about safety concerns known to others, including other labs.
I would then add a fifth, which is that many major labs such as Meta and Mistral have already announced their intention to be irresponsible. Many influential individuals with deep pockets, such as Marc Andreessen, react with defiance to even milktoast non-binding statements of the form ‘we should try to ensure that our AIs are safe.’
I consider this objection well-answered, here and elsewhere.
This is distinct from the argument that there is no underlying problem requiring a response of any kind. There are those who think there is no danger at all even if capabilities advance a lot, or that until the danger is ‘proven’ or modeled or more concrete we should act as if it is not there.
My response at this point is some combination of an exasperated sigh and a version of ‘you are not serious people.’
There is also the objection that AI is not going to be sufficiently capable any time soon to be catastrophically dangerous. That all the talk from the labs is some combination of optimism and hype, this is all going to ‘hit a wall’ soon in one of various ways. I do think such an outcome is possible.
The counterargument offered by The Gladstone Report is that this is very much not what the labs themselves and their engineers, in best position to know, expect, and that this has to carry substantial weight, enough to justify well-targeted intervention that would do little if there were no major pending capabilities gains. I buy that, although it again raises the question of where they put the thresholds.
What About Competitiveness?
In 0.4.2 they address the objection that regulation could damage American innovation and competitiveness. They somewhat bite the bullet, as one must.
The first part of their response is to note their plan is targeted, to not interfere more than necessary to ensure safety and national security, and it would have little or no impact on most American AI efforts and thus not hurt their competitiveness.
The second part of their response is to say, well, yes. If the result of being maximally competitive and innovative would be to risk existential or other catastrophe, if the way we are being that competitive and innovative is to disregard (and effectively socialize) the downside risks, you are going to hurt competitiveness and innovation by not letting the labs do that. This is not an avoidable cost, only one we can minimize, as they claim their plan attempts to do.
The third part of the response is that the cybersecurity requirements in particular favor American competitiveness on net. If foreigners can steal the weights and other lab secrets, then this helps them compete and nullifies our advantages. Not pricing in that externality does not help us compete, quite the opposite.
They do not make other counterarguments one could make here. This is an ongoing thing, but I’ll briefly reiterate here.
It is common for those making this objection to fully adapt the argumento ad absurdum, claiming that any regulation of AI of any kind would doom America to lose to China, or at least put as at grave risk of this. And they say that any move towards any regulation starts a process impossible to stop let alone undo.
When they see any regulation of any kind proposed or pushed anywhere, they warn of that area’s inevitable economic doom (and in the case of the EU, they kind of have a point when all taken together, but I have not been able to bring myself to read the full bill all the way and ow my eyes make it stop someone make it stop). I really do not think I am strawmanning.
The response of course is that America has a big lead over its competitors in numerous ways. If your main rival is China (or the EU, or even the UK), are you saying that China is not regulated? Why shouldn’t China inevitably ‘lose to America’ given all the vastly worse restrictions it places on its citizens and what they can do, that mostly have nothing directly to do with AI?
Also, I won’t go over the evidence here, but China is not exactly going full Leroy Jenkins with its AI safety protocols or public statements, nor is it showing especially impressive signs of life beyond copying or potentially stealing our stuff (including our open model weights stuff, which is free to copy).
As with everything else, the real question is price.
How much competitiveness? How much innovation? What do we get in return? How does this compare to what our rivals are doing on various fronts, and how would they react in response?
If implemented exactly as written in The Gladstone Report, with its very low thresholds, I believe that these restrictions would indeed gravely harm American competitiveness, and drive AI development overseas, although mostly to the UK and other friendly jurisdictions rather than China.
If implemented with the modified thresholds I suggest, I expect minimal impact on competitiveness and innovation, except for future potentially dangerous frontier models that might hit the higher threshold levels. In which case, yes, not disregarding the risks and costs is going to mean you take a hit to how fast you get new things. How else could this possibly work?
Do you think that it doesn’t take longer or cost more when you make sure your bridge won’t fall down? I still highly recommend making sure the bridges won’t fall down.
How Dare You Solve Any Problem That Isn’t This One?
0.4.3 responds to the standard argument from the ethics crowd, that catastrophic risk ‘could divert attention’ from other issues.
The report gives the standard argument that we should and must do both, and there is no conflict, we should deal with catastrophic risks in proportion to the threat.
Nothing proposed here makes other issues worse, or at least the other issues people tend to raise here. More than that, the interventions that are proposed here would absolutely advance the other issues that people say this would distract from, and lay groundwork for further improvements.
As always, the distraction argument proves too much. It is a general counterargument against ever doing almost anything.
It also ignores the very real dangers to these ‘other issues.’
Working for social justice is like fetching the coffee, in the sense that you cannot do it if you are dead.
Some instrumental convergence from the humans, please.
If you think the catastrophic risks are not worth a response, that there is no threat, then by all means argue that. Different argument. See 0.4.4, coming right up.
If you think the catastrophic risks are not worth a response, because they impact everyone equally and thus do not matter in the quest for social justice, or because you only care about today’s concerns and this is a problem for future Earth and you do not much care about the future, or something like that?
Then please speak directly into this microphone.
What Makes You Think We Need To Worry About This?
0.4.4 deals with the objection I’ve been differentiating above, that there is nothing to worry about, no response is needed. They cite Yann LeCun and Andrew Ng as saying existential risk from AI is very low.
The report responds that they will present their evidence later, but that numerous other mainstream researchers disagree, and these concerns are highly credible.
As presented here all we have are dueling arguments from authority, which means we have exactly nothing useful. Again, if you did not previously believe there was any catastrophic risk in the room after considering the standard arguments, you should not as of this point be changing your mind.
They also mention Richard Sutton and others who think humanity’s replacement by AI is inevitable and we should not seek to prevent it, instead we should do ‘succession planning.’ To which I traditionally say, of course: Please speak directly into this microphone.
The fact that by some accounts 10% of those in the field hold this view, that we should welcome our future AI overlords in the sense of letting humanity be wiped out, seems like a very good reason not to leave the question of preventing this up to such folks.
What Arguments are Missing?
They leave out what I consider the best arguments against regulation of AI.
The best argument is that the government is terrible at regulating things. They reliably mess it up, and they will mess it up this time as well, in various surprising and unsurprising ways. You do not get the regulations you carefully crafted, you get whatever happens after various stakeholders butcher and twist all of it. It does not get implemented the way you intended. It then gets modified in ways that make it worse, and later expanded in ways you never wanted, and recovery from that is very difficult.
That is all very true. The choice is what you can realistically get versus nothing.
So you have to make the case that what you will get, in practice, is still better than doing nothing. Often this is not the case, where no action is a second best solution but it beats trying to intervene.
A related good argument, although it is often taken way too far in this context, is the danger of regulatory capture. Yes, one could argue, the major players are the ones hurt by these laws as written. But by writing such laws at all, you eventually put them in position where they will work the system to their advantage.
I would have liked to see these arguments addressed. Often in other cases regulations are passed without anyone noticing such issues.
I do think it is clear that proposals of this form clear these hurdles, the alternative is too unacceptable and forces our hand. The proposals here, and the ones many have converged on over the past year, are chosen with these considerations squarely in mind.
Another common argument is that we do not yet know enough about what regulations would be best. Instead, we should wait until we know more, because regulations become difficult to change.
My response is three-fold.
First, in this situation we cannot wait until the problems arise, because they are existential threats that could be impossible to stop by the time we concretely see or fully understand exactly what is going wrong. There is a lot of path dependence, and there are lots of long and variable lags lie in our future responses.
Second, I think this objection was a lot stronger a year ago, when we did not have good policy responses available. At this point, we know quite a lot. We can be confident that we know what choke points are available to target with regulation. We can target the chips, data centers and hardware, and very large compute-intensive training runs. We can hope to gain control and visibility there, exactly where the potential existential and catastrophic risks lie, with minimal other impact. And the geopolitical situation is highly favorable to this strategy.
What is the alternative regime being proposed? Aside from ‘hope for the best’ or ‘wait and see’ I see no other proposals.
Third, if we do not use this regime, and we allow model proliferation, then the required regulatory response to contain even mundane risks would leave a much bigger footprint. We would be forced to intervene on the level of any device capable of doing inference, or at minimum of doing fine-tuning. You do not want this. And even if you think we should take our chances, I suggest brushing up on public choice theory. That is not what we would do in that situation, if humans are still in control. Of course, we might not be in control, but that is not a better outcome or a reason to have not acted earlier.
There are of course other objections. I have covered all the major ones that occured to me today, but that does not mean the list is complete. If I missed a major objection, and someone points that out in the first day or so, I will edit it in here.
Tonight at 11: Doom!
The next section is entitled ‘challenges.’
It begins with 0.5.1.1, offering a list of the usual estimates of doom. This is an argument from authority. I do think it is strong enough to establish that existential risk is a highly credible and common concern, but of course you knew about all this already if you are reading this, so presumably you need not update.
0.5.1.2 notes that timelines for catastrophic risk is uncertain, and that all the major players – OpenAI, DeepMind, Anthropic and Nvidia – have all publically said they expect AGI within five years.
I consider a wide variety of probability distributions on such questions reasonable. I do think you have to take seriously that we could be close.
As noted in the Tweet thread above, and remembering that catastrophic risk is distinct from existential, here is them asking about how much catastrophic risk there is from AI in 2024.
pp36: To partially address this problem, in December 2023 we asked several technical sources across multiple frontier labs to privately share their personal estimates of the chance that an AI incident could lead to global and irreversible effects, sometime during the calendar year 2024.
The lowest estimate we received was 4%; the highest extended as far as 20%.
These estimates were collected informally and likely subject to significant bias, but they all originated from technically informed individuals working at the frontier of AI capabilities. Technical experts inside frontier labs also expressed that the AGI timelines messaged externally by frontier labs were consistent with those labs’ internal assessments.
The more I think about this the more strange the question becomes as framed like this. Will not, for example, who wins various elections have ‘global and irreversible’ effects? If an AI effort swung the White House does that count? In which directions?
Again, if we are sticking to Anthropic’s definition, I am on the lower end of this range, but not outside of it. But one could see definitional disagreements going a long way here.
0.5.1.3 says the degree of risk from loss of control is uncertain.
Well, yes, very true.
They say one must rely on theoretical arguments since we lack direct evidence in either direction. They then link to arguments elsewhere on why we should consider the degree of risk to be high.
I can see why many likely find this section disappointing and unconvincing. It does not itself contain the arguments, in a place where such arguments seem natural.
I have many times made various arguments that the risk from loss of control, in various forms, is large, some of which I have reiterated in this post.
I will say, once again, that this has not provided new evidence for risk from loss of control as of this point, either.
The Claim That Frontier Labs Lack Countermeasures For Loss of Control
So here’s where they tell their story.
Apart from the fundamental challenge of aligning an AGI-level system, researchers at several major frontier labs have indicated in private conversations that they do not believe their organizations are likely to implement the measures necessary to prevent loss of control over powerful, misaligned AI systems they may develop internally.
In one case, a researcher indicated that their lab’s perceived lax approach to safety reflected a trade-off between safety and security on the one hand, and research velocity on the other. The same source said they expected their lab to continue to prioritize development velocity over safety and security.
Another individual expressed the opinion that their lab’s safety team was effectively racing its capabilities teams, to avoid the possibility that they may develop AGI-level systems before being able to control them.
A third frontier AI researcher expressed skepticism at the effectiveness of their lab’s model containment protocols, despite their lab’s internal belief that they may achieve AGI in the relatively near term.
As one example of lax containment practices, researchers at one well known frontier lab performed experiments on a newly trained, cutting-edge AI system that involved significant augmentation of the system’s capability surface and autonomy. These experiments were unmonitored at the time they were performed, were conducted before the system’s overall capability surface was well-understood, and did not include measures to contain the impact of potential uncontrolled behavior by the system.
…
On the other hand, multiple researchers have also privately expressed optimism that the necessary measures could be developed and implemented if frontier labs had enough time, and a stronger safety culture than they currently do.
This is of course anecdata. As I understand it, Gladstone talked to about 200 people. These are only three of them. Ideally you would get zero people expressing such opinions, but three would not be so bad if the other 197 all felt things were fine.
From a skeptical perspective, you could very reasonably say that these should be assumed to be the most worried three people out of 200, presented with their biggest concerns. When viewed that way, this is not so scary.
The story about one of the major labs testing newly enhanced potential autonomous agents, whose abilities were not well-understood, with zero monitoring and zero controls in place, and presumably access to the internet, is not great. It certainly sets a very bad precedent and indicates terrible practices. But one can argue that in context the risk was at the time likely minimal, although it looks that way right until it isn’t.
In any case, I would like to see statistical data. What percentage of those asked thought their lab was unprepared? And so on.
I do know from other sources that many at the frontier labs indeed have these concerns. And I also know that they indeed are not taking sufficient precautions. But the report here does not make that case.
What about preventing critical IP theft?
Here is the full quote from the Twitter thread at the top:
By the private judgment of many of their own technical staff, the security measures in place at many frontier AI labs are inadequate to resist a sustained IP exfiltration campaign by a sophisticated attacker. W
hen asked for examples of dangerous gaps in security measures at their frontier lab, a member of the lab’s technical staff indicated that they had many to share, but that they were not permitted to do so.
The same individual shared that their lab’s lax approach to information security was the object of a running joke: their lab, its staff apparently say, is doing more to accelerate adversaries’ AI research than the adversaries themselves.
Conversations with leading frontier labs have corroborated that many lack an institutional appreciation of necessary security practices.
Given the current state of frontier lab security, it seems likely that such model exfiltration attempts are likely to succeed absent direct U.S. government support, if they have not already.
It is an interesting fact about the world that such attempts do not seem to have yet succeeded. We have no reports of successfully stolen model weights, no cases where a model seems to have turned up elsewhere unauthorized. Is everyone being so disciplined as to keep the stolen models secret? That seems super unlikely, unless they sold it back for a ransom perhaps.
My presumption is that this is another case of no one making that serious an attempt. That could be because everyone would rather wait for later when the stakes are higher, so you don’t want to risk your inside agent. It still seems super weird.
The Future Threat
They cite two additional threat models.
In 0.5.1.6, they note opening up a model makes it far more potentially dangerous, of course in a way that cannot be undone. Knowing that a model was safe as a closed model does not provide strong evidence, on its own, that it would be safe over time as an open model. I will note that ‘a clearly stronger model is already open’ does however provide stronger evidence.
In 0.5.1.7, they note closed-access AI models are vulnerable to black-box exfiltration and other attacks, including using an existing system to train a new one on the cheap. They note we have no idea how to stop jailbreaks. All true, but I don’t think they make a strong case here.
Section 0.5.2 covers what they call political challenges.
0.5.2.1: AI advances faster than the ordinary policy process. Very much so. Any effective response needs to either be skating where the puck is going to be, or needs to be ready to respond outside of normal policy channels in order to go faster. Ideally you would have both. You would also need to be on the ball in advance.
0.5.2.2: ‘The information environment around advanced AI makes grounded conversations challenging.’ That is quite the understatement. It is ugly out there.
He mentions Effective Altruism here. So this is a good time to note that, while the ideas in this report line up well with ideas from places like LessWrong and others worried about existential risk, Gladstone was in no way funded by or linked to EA.
0.5.3.1 points out the labs have terrible incentives (the report also effectively confirms here that ‘frontier labs’ throughout presumably means the big three only). There are big winner-take-all effects, potentially the biggest ever.
0.5.3.2 notes that supply chain proliferation is forever. You cannot take back physical hardware, or the ability to manufacture it in hostile areas. You need to get out in front of this if you want to use it as leverage.
0.5.4.1 argues that our legal regime is unprepared for AI. The core claim is that an open model could be used by malicious actors to do harm, and there would be no way to hold the model creator liable. I agree this is a problem if the models become so capable that letting malicious actors have them is irresponsible, which is not yet true. They suggest liability might not alone be sufficient, and do not mention the possibility of requiring insurance a la Robin Hanson.
In general, the problem is that there are negative externalities from these products, for which the creators cannot be held liable or otherwise legally responsible. We need a plan to address that, no matter what else we do. Gladstone does not have a legal action plan though, it focuses on other aspects.
That All Sounds Bad, What Should We Do?
What does Gladstone AI propose we do about this? They propose five lines of effort.
- Establishing interim safeguards (wait, we don’t have interim safeguards?) by monitoring developments in advanced AI to ensure USG’s view of the field is up to date, create a task force to coordinate implementation and place controls on advanced AI chip supply.
- Strengthen capability and capacity. Working groups, preparedness through education and training, early-warning frameworks, scenario-based contingency plans. The things you would do if you worried about something.
- Support AI safety research. Well, yes.
- Formalize safeguards in law. I certainly hope so, whatever safeguards are chosen. New regulatory agency is proposed, with new liability and potential emergency powers to respond to threats. I say (Facebook meme style) just powers. Never base your plan on ‘emergency’ powers, either grant the powers or don’t.
- Interalize advanced AI safeguards. Build consensus, enshrine in international law, establish an international agency, control the supply chain.
I mean, yeah, sure, all of that seems good if implemented well, but also all of that seems to sidestep the actually hard questions. It is enough to make some people cry bloody murder, but those are the people who if they were being consistent would oppose driver’s licenses. The only concrete rule here is on chip exports, where everyone basically agrees on principle and we are at least somewhat already trying.
The actual actions are presumably in the detailed document, which you have to request, so I did so (accurately I think at this point!) calling myself media, we’ll see if they give it to me.
This Time article says yes, the actual detailed proposals are for real.
Billy Perrigo: Congress should make it illegal, the report recommends, to train AI models using more than a certain level of computing power. The threshold, the report recommends, should be set by a new federal AI agency, although the report suggests, as an example, that the agency could set it just above the levels of computing power used to train current cutting-edge models like OpenAI’s GPT-4 and Google’s Gemini.
The new AI agency should require AI companies on the “frontier” of the industry to obtain government permission to train and deploy new models above a certain lower threshold, the report adds. Authorities should also “urgently” consider outlawing the publication of the “weights,” or inner workings, of powerful AI models, for example under open-source licenses, with violations possibly punishable by jail time, the report says. And the government should further tighten controls on the manufacture and export of AI chips, and channel federal funding toward “alignment” research that seeks to make advanced AI safer, it recommends.
…
The report’s recommendations, many of them previously unthinkable, follow a dizzying series of major developments in AI that have caused many observers to recalibrate their stance on the technology.
Greg Colbourn: Great to see a US Gov commissioned report saying this.
Not pulling any punches in using the word “default”:
“could behave adversarially to human beings by default”
Hope the US government takes heed of the recommendations!
Always interesting what people consider unthinkable.
This is exactly the standard compute limit regime. If you are close to the frontier, above a certain threshold, you would need to seek approval to train a new model. That would mean adhering to various safety and security requirements for how you train, monitor and deploy the model, one of which would obviously be ‘don’t let others steal your model weights’ which would imply also not publishing them. Above a second higher threshold, you cannot do it at all.
There is, of course, skepticism, because people are bad at extrapolation.
The proposal is likely to face political difficulties. “I think that this recommendation is extremely unlikely to be adopted by the United States government” says Greg Allen, director of the Wadhwani Center for AI and Advanced Technologies at the Center for Strategic and International Studies (CSIS), in response to a summary TIME provided of the report’s recommendation to outlaw AI training runs above a certain threshold.
Current U.S. government AI policy, he notes, is to set compute thresholds above which additional transparency monitoring and regulatory requirements apply, but not to set limits above which training runs would be illegal. “Absent some kind of exogenous shock, I think they are quite unlikely to change that approach,” Allen says.
What would he have said a year ago, or two years ago, about a reporting threshold? Probably he would have said it was very unlikely, absent some kind of exogenous shock. Except then we got (at least) one of those. In this context, we will get more.
As is sadly standard for the government, a lot of the issue getting here was finding some department to claim some responsibility.
In late 2021, the Harrises say Gladstone finally found an arm of the government with the responsibility to address AI risks: the State Department’s Bureau of International Security and Nonproliferation.
The report focuses both on ‘weaponization risk’ which I would think is a subset of misuse, incorporating things like biological, chemical or cyber attacks, and then ‘loss of control risk,’ and it centralizes the role of ‘race dynamics.’
Meanwhile, since it is important to share contrary voices, let us see how the skeptics are reacting, yes this is the first reaction I saw.
Shoshana Weissman: So our government commissioned a report from some fucking idiots, ok.
Nirit Weiss-Blatt: Gladstone’s Edouard Harris collaborated with Eliezer Yudkowsky’s MIRI, on the LessWrong forum, said the paperclip maximizer is “a very deep and interesting question,” and his messages about taking the “Terminator” seriously … resemble those of his fellow doomers at FLI.
The Key Proposal: Extreme Compute Limits
Ben Brooks on the other hand does it right, and actually reads the damn thing.
Ben Brooks: I read this Gladstone “jail time for open models” paper on a flight, all 284 pages. Some takeaways?
TLDR: Llama 2 would need to be approved by the US Government.

Once again, this tier system seems like the only way a sane system could operate? We should then talk price on where the thresholds should be.
It seems this report argues for the most aggressive threshold of all for Tier 2, which is the 10^23 number I’ve heard from Connor Leahy and some others, and start Tier 3 at only 10^24, and Tier 4 at 10^25. So yes, that is a super aggressive set of prices:
Ben Brooks: They call for *expedited* criminal proceedings for developers who release designated models without a license from the “Frontier AI Systems Administration”. Like, an AI court-martial? It’s a dystopian gloss on a proposal that’s already pushing constitutional boundaries.
They would require model registration at a threshold that is three orders of magnitude lower than the US Executive Order: 10^23 FLOPs.
At this point, obligations would include KYC, which would make it difficult / impossible for a downstream developer to share a tuned model.
Next, they would require model approval when a model hits a 70% MMLU score or is trained on 10^24 FLOPs. A quick glance at the @huggingface leaderboard suggests that ~265 base and tuned models would need these licenses.
A leak of Llama or @MistralAI weights would attract “severe penalties”.Kicking it up a notch, they would ban model development above 10^25 FLOPs. For context, that’s the threshold the EU adopted for basic disclosure obligations in its AI Act. Models above this (e.g. the next update to Gemini) “cannot be trained under any conditions”.
Other proposals are familiar (e.g. reworking liability rules) or uncontroversial (e.g. funding for evaluation and standards research).
All in all, kudos to the authors for actually committing to details. Until now, this conversation has played out in X threads, conference hallways, and footnotes.
But casually invoking criminal law and premarket authorization to suppress open innovation is irresponsible. It does a disservice to the many credible and thoughtful efforts to regulate AI.
The chart is from 4.1.3.4. Here is another useful one to have handy:

In addition to flops, you can also qualify as Tier 3 with a 70% on the MMLU, although only Tier 2 models are required to check this.
Their view is that the leak of the weights of a Tier 3 model is ‘an irreversible event that could create significant national security risk.’ It would indeed be irreversible, but would it harm national security? What does it mean to be in the 10^24 to 10^25 range?
We don’t know the exact answer, but the Metaculus estimate says that GPT-4 was trained on 2.1×10^25 flops, based on an estimate by Epoch, which makes it a Tier 4 model along with Gemini Ultra and (just barely) Inflection-2, and presumably Claude 3. Those models would be Tier 4 under this protocol. Whereas GPT-3.5 would be, in log terms, a little under halfway through Tier 3.
If we leaked (or opened up) the weights of GPT-3.5 today, it wouldn’t be awesome, but I would not see this as that big a deal. Certainly a year from now that would be mostly irrelevant, there will be better options. So while I agree that it ‘could’ create such issues, I doubt that it would.
If we treat Tier 3 as ‘you must protect the weights of this model and also not release them’ and other similarly motivated requirements, then it seems like this should start no lower than 10^25. At that point, I think a case can be made that there would be real risk in the room. More likely I think, as a practical question, you will have to start at 10^26, the EO reporting threshold, and cover models substantially stronger than GPT-4. We have to make a choice whether we are going to accept that GPT-4-level models are going to become generally available soon enough, and I do not see a practical path to preventing this for long.
One would then likely bump Tier 2 to 10^24.
Whereas they would put 10^25 into Tier 4, which they consider too high-risk to develop now due to loss of control risk. Given that this range includes GPT-4 and Gemini, this seems like it is not a reasonable ask without much stronger evidence. You can at least make a case that GPT-5 or Clade-4 or Gemini-2 poses loss of control risk such that it would be non-crazy to say we are not ready to build it.
But the existing models we all know about? I mean, no I wouldn’t give them four 9s of safety if you opened up the weights fully for years, but we do not have the luxury of playing things that kind of safe. And we certainly neither want to grant the existing models a permanent monopoly, nor do we want to force them to be withdrawn, even if enforcement was not an issue here.
The lowest sane and realistic threshold I can see proposing for ‘no you cannot do this at all’ is 10^27. Even at 10^28, where I think it is more likely to land, this would already be quite the ask.
Implementation Details of Computer Tiers
What about other implementation details? What do they suggest people should need to do at Tier 2 or Tier 3?
This is the subject of the bulk of section 4.
They list in 4.1.3.5:
- Risk governance, which is things like an internal audit team and a chief risk officer and risk committee. I am generally skeptical of such moves since they are unlikely to do anything for those who needed to be told to do them, but they seem relatively cheap and thus do seem worthwhile.
- Outside and insider threat countermeasures, introducing friction against unauthorized access or model exfiltration. I file these kinds of requirements under ‘things you should be doing anyway more than you are, and where there are large externalities to consider so you should do a lot more than even that.’
- Model containment measures, including emergency shutdown procedures and information-gapping, potentially including kill switches and dead man switches to halt training or deployment. With all the usual caveats about how likely these tactics are to fail, they are definitely the least you can do in a Tier 3 style situation.
- AI safety and security training. What does this even mean? It sounds good to some types in theory. In practice I’ve never met a mandatory training that helped.
- Whistleblower protections. I mean, yes, good, should be uncontroversial.
- Incident reporting. Need to define incidents to report, but again, yeah, sure.
If the threshold is set properly, this could still be cleaned up a bit, but mostly seems reasonable. Objections to this type of regime more broadly are essentially arguments against any kind of prior restraint or process control at all, saying that instead we should look only at outcomes.
In section 4.1.4 they discuss publication controls on AI capabilities research, mentioning the worry that such research often happens outside major labs. They mention DPO, AutoGPT and FlashAttention. I get why they want this, but pushing this hard this far does not seem great.
In 4.2.1 they propose imposing civil liability on creators of AI systems on a duty of care basis, including preventing inadvertent harm, preventing infiltration of third-party systems, safeguarding algorithmic configurations of advanced AI including model weights, and maintaining security measures against unauthorized use.
This is a combination of strict liability for harms and a ban on open model weights even if you thought that liability wasn’t an issue. They propose that you could choose to enter Tier 3 on purpose to protect against strict liability, which could be an alternative to imposing super low compute thresholds – you can decide if you think your LLM is dangerous, and pay the costs if you are wrong.
Open model weights presumably are not okay in Tier 3, and are okay in Tier 1. The question is where in Tier 2, from its start to its finish, to draw the line.
4.2.2 is where they discuss criminal liability. They point out that the stakes are sufficiently high that you need criminal penalties for sufficiently brazen or damaging violations.
Felonies could include:
● Disregarding an emergency order to halt AI development activities;
● Engaging in development activities that require a license following the rejection
of a license application; and
● Breaching the conditions of a license, especially if these violations lead to
heightened security risks or cause damages exceeding a significant monetary
threshold (e.g., $100 million), or if the entity or its management have prior
convictions under this liability framework.
The first two here seem like very reasonable things to be felonies. If the stakes are existential risk, then this is wilful ignoring of a direct order to stop. Breaching ‘the conditions’ sounds potentially vague, I would want to pin that down more carefully.
The asks here are clearly on the aggressive end and would need to be cut back a bit and more importantly carefully codified to avoid being too broad, but yes these are the stakes.
4.2.3 proposes ‘emergency powers’ which should always make one nervous. In this case, the emergency power looks like it would be confined to license suspension, demanding certain abilities be halted and precautions be taken, up to a general moratorium, with ability to sue for economic damages if this is not justified later.
I hate the framing on this, but the substance seems like something we want in our toolkit – the ability to act now if AI threatens to get out of control, and force a company to stand down until we can sort it out. Perhaps we can find a slightly different way to enable this specific power.
The Quest for Sane International Regulation
Section 5 is about the quest for international cooperation, with the report’s ideal end state being a treaty that enforces the restrictions from section 4, reporting requirements on cloud providers and also hardware-based tracking.
That seems like the correct goal, conditional on having chosen the correct thresholds. If the thresholds are right, they are right for everyone. One reason not to aim too low with the numbers is that this makes international cooperation that much harder.
Deeper monitoring than this would have benefits, but they rightfully step back from it, because this would too heavily motivate development of alternative supply chains and development programs.
How do we get there? Well, saying what one can about that is the kind of thing that makes the report 284 pages long (well, 161 if you don’t count acknowledgements and references). 5.2.1 says to coordinate domestic and international capacity-building, starting with policymaker education outreach in 5.2.1.1.
They do have a good note there:
Part of the substance of this educational content is outlined in LOE2, 2.2. Additionally,
based on our direct experience briefing U.S. and international policymakers on this issue, we believe these educational efforts should:
- Emphasize specific, concrete, and tangible scenarios relevant to AI risk and national security (see Annex C: Example AI alignment failure scenarios and [1]);
- Explain that the build-vs-use distinction that exists for nuclear weapons may not exist for sufficiently capable AI systems, meaning that simply building such a system, with no intent to deploy it, may in and of itself be a dangerous action (Introduction, 0.2.2); and
- Clarify that, because of this unusual risk profile, the international community may need to implement rules above and beyond those already in place for less-capable AI systems such as lethal autonomous weapons (LAWs).
The first point here has been said before, and is especially important. There is a class of people, who are almost all of NatSec, who simply cannot imagine anything except a specific, concrete and tangible scenario. In addition, many can only imagine scenarios involving a foreign human enemy, which can be a rival nation or a non-state actor.
That means one has to emphasize such threats in such conversations, even though the bulk of the risk instead lies elsewhere, in future harder-to-specify threats that largely originate from the dynamics surrounding the AIs themselves, and the difficulties in controlling alignment, direction, access and usage over time as capabilities advance.
One must keep in mind that even if one restricts only to the scenarios this permits you to raise, that is still sufficient to justify many of the correct interventions. It is imperfect, but the tangible threats are also very real and require real responses, although the resulting appropriate prices and details will of course be different.
Specifically, they suggest our Missions engage heads of state, that we use existing AI policy-focused forums and use foreign assistance to build partner capacity. I have no objection to any of that, sure why not, but it does not seem that effective?
5.2.1.2 talks about technical education and outreach, suggesting openness and international cooperation, with specifics such as ‘the U.S. ambassador to the UN should initiate a process to establish an intergovernmental commission on frontier AI.’ There is already a group meeting within the UN, so it is not clear what needs this addresses? Not that they or I have other better concrete path ideas to list.
5.2.1.3 says also use other forms of capacity building, I mean, again, sure.
5.2.2 says ‘articulate and reinforce an official US government position on catastrophic AI risk.’ Presumably we should be against it (and yes, there are people who are for it). And we should be in favor of mitigating and minimizing such risks. So, again, sure, yes it would be helpful to have Congress pass a statement with no legal standing to clarify our position.
5.3 says enshrine AI safeguards in international law. Yes, that would be great, but how? They note the standard security dilemma.
We recommend that the goal of these efforts be to establish comprehensive RADA safeguards to minimize catastrophic risks from loss of control due to AGI alignment failure, and aligning the international community on new international law or treaty requirements.
So, more summits, then?
5.4 says establish an international regulatory agency, which they call the International AI Agency (IAIA), and optimistically cite past non-proliferation efforts. 5.4.1 outlines standard protocols if one was serious about enforcing such rules, 5.4.2 notes there need to be standards, 5.4.3 that researchers will need to convene. Yes, yes.
5.5 discusses joint efforts to control the AI supply chain. This is a key part of any serious long term effort.
A multilateral AI controls framework could have three goals:
● Ensure that critical elements of the supply chain for advanced AI, particularly compute and its inputs, remain localized to U.S. and allied jurisdictions;
● Ensure that access to AI cloud compute is controlled through a regulatory mechanism similar to that proposed in LOE4, 4.1.3 including RADA safeguards implemented in U.S. and allied jurisdictions; and Meaning GPUs, TPUs, and other AI accelerator chips.
● Provide a path for foreign entities to obtain access to AI cloud compute clusters in U.S. and allied jurisdictions, provided they do so subject to the regulatory mechanism (e.g., LOE1, 1.5.2).
So essentially AI for me (and my friends) but not for thee.
The obvious response is, if this is the plan, why would China sign off on it? You need to either have China (and the same applies to others including Russia) inside or outside your international AI alliance. I do not see any talk of how to address China’s needs, or how this regime plans to handle it if China does not sign on to the deal. You cannot dodge both questions for long, and sufficiently harsh compute limits rule out ‘dominate China enough to not care what they think’ as an option, unless you think you really can fully cut off the chip supply chain somehow and China can’t make its own worth a damn? Seems hard.
5.5.1 points out that alternative paths, like attempting controls on the distribution or use of open data or open models, flat out do not work. The only way to contain open things is to not create or open them up in the first place. That is the whole point of being open, to not have anyone be able to stop users from doing anything they want.
5.5.2 outlines who has key parts of the AI supply chain. Most key countries are our allies including Israel, although the UAE is also listed.
5.6 is entitled ‘open challenges’ and seems curiously short. It notes that the incentives are terrible, reliable verification is an open problem and algorithmic improvements threaten to render the plan moot eventually even if it works. Well, yes. Those are some, but far from all, of the open challenges.
That does not mean give up. Giving up definitely doesn’t work.
The Other Proposals
Section 1 proposes interim safeguards.
1.2 suggests an ‘AI observatory’ for advanced AI, which they call AIO. Certainly there should be someone and some government group that is in charge of understanding what is happening in AI. It would (1.2.1) monitor frontier AI development, study emergency preparedness and coordinate to share information.
This should not be objectionable.
The only argument against it that I can see is that you want the government to be blindsided and unable to intervene, because you are opposed on principle (or for other reasons) to anything that USG might do in AI, period. And you are willing to risk them flailing around blind when the first crisis happens.
1.3 suggests establishing responsible AI development and adoption safeguards for private industry. They mention ‘responsible scaling policies’ (RSPs) such as that of Anthropic, and would expand this across the supply chain. As with all such things, price and details are key.
Certainly it would be good to get other labs to the level of Anthropic’s RSP and OpenAI’s preparedness framework. This seems realistic to get via voluntary cooperation, but also you might need to enforce it. Meta does exist. I presume the report authors would want to be much stricter than that, based on their other recommendations.
1.3.1 talks implementation details, mentioning four laws that might allow executive authority, including everyone’s favorite the Defense Production Act, but noting that they might not apply.
1.3.2 makes clear they want this to mostly be the same system they envision in section 4, which is why I wrote up section 4 first. They make clear the need to balance safety versus innovation and value creation. I think they get the price wrong and ask too much, but the key is to realize that one must talk price at all.
1.4 says establish a taskforce to do all this, facilitating responsible development and watching out for weaponization and loss of control as threats, and lay the foundation for transition to the regime in section 4, which seems remarkably similar to what they want out of the gate. Again, yes, sure.
There is also their ‘plan B’ if there is no short term path to getting the RADA safeguards similar to section 4, and one must rely on interim, voluntary safeguards:
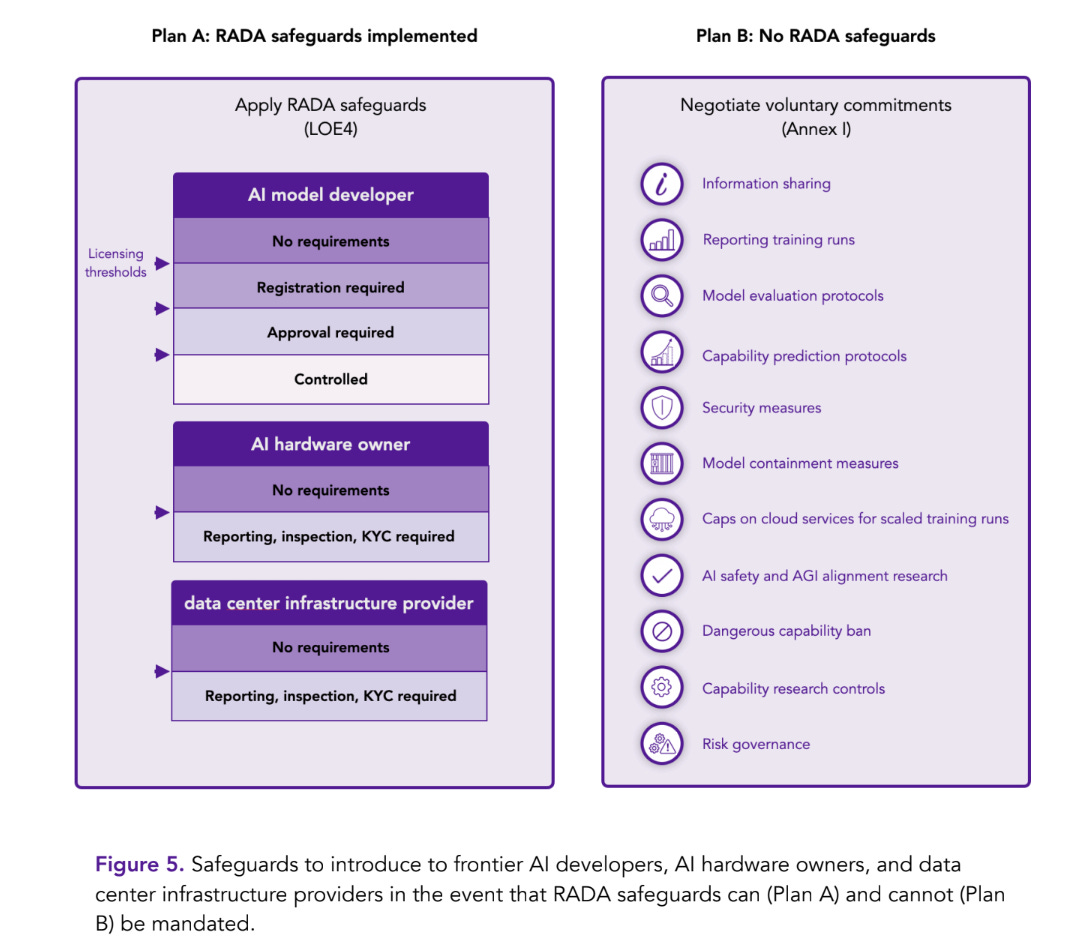
They essentially say, if you can’t enforce it, call on labs to do it anyway. To which I essentially say: Good luck with that. You are not going to get a voluntary pause at 10^26 from the major players without much stronger evidence that one is needed, and you are not going to get cooperation from cloud service providers this way either. The case has not yet been sufficiently strongly made.
Section 2 proposes ‘strengthening capability and capacity for advanced AI preparedness and response.’ What does that mean?
That all seems unobjectionable in theory. It is all about the government getting its people prepared and understanding what is going on, so they can then make better decisions.
Again, the objection would be if you think the government will use better information to make worse decisions, because government intervention is all but assured to be negative, and more info means more action or more impactful action. Otherwise, it’s about whether the details are right.
I mostly would prefer to leave such questions to those who know more.
Their list of stakeholders seems plausible on first reading, but also seems like they included everyone without trying hard to differentiate who matters more versus less.
Their suggested topics seem fine as basic things more people should know. I would look closer if this was the draft of a bill or executive order, again on first glance it seems fine but could use more prioritization. This is more facts than people are able to absorb, you are not going to get everything here, you must choose.
Finally (in terms of the ordering here) there is section 3 on investment in technical AI safety research and standards development.

They note that some research can be done on public open models, and should be shared with everyone. Other research requires access to proprietary frontier models, and the government could help facilitate and fund this access, including developing dedicated secure infrastructure. They don’t talk about sharing the results, but presumably this should be shared mostly but not always. And finally there will be national security research, which will require both unrestricted frontier model access and need to be done in a classified context, and much of the results will not be things that can be published.
Again, all of that seems right, and it would be great to have funding to support this kind of work. That does not mean the government is up to the task at all these levels, given the restrictions it operates under. It is not implausible that government funding would be so delayed, bureaucratized and ill-targeted that it would end up doing little, no or even negative good here. I do think we should make the attempt, but have our eyes open.
After some standard stuff, 3.2 discusses proposed standards for AI evaluations and RADA safeguards, mostly to warn in 3.2.1.1 that current evaluations cannot provide comprehensive coverage or predict emergence of additional capabilities. You can never prove a capability is absent (or at least, you can’t if it was at all plausible it could ever have been present, obviously we know a lot of things e.g. GPT-2 cannot ever do).
As they warn in 3.2.1.3, evaluations can easily be undermined and manipulated if those doing them wish to do so. Where the spirit of the rules is not being enforced, you are toast. There are no known ways to prevent this. The best we have is that the evaluation team can be distinct from the model development team, with the model development team unaware of (changing and uncertain) evaluation details. So we need that kind of regime, and for AI labs to not effectively have control over who does their evaluations. At minimum, we want some form of ‘testing for gaming the test.’
Also key is 3.2.1.4’s warning that AI evaluations could fail systematically in high-capability regimes due to situational awareness, manipulation of evaluations by the AI and deceptive alignment. We saw clear signs of this in the Sleep Agent paper from Anthropic, Claude Opus has shown signs of it as well, and this needs to be understood as less an unexpected failure mode and more the tiger going tiger. If the AI is smarter than you, you are going to have a hard time having it not notice it is in a test. And in addition to the instrumental convergence and other obvious reasons to then game the test, you know what the training data is full of? Humans being situationally aware that they are being tested, and doing what it takes to pass. Everyone does it.
Conclusions, Both Theirs and Mine
There is lots more. One can only read in detail so many 284-page (or even de facto 161-page if you skip the appendixes and references and acknowledgements) documents.
Their conclusion makes it clear how they are thinking about this:
AI is a technology fundamentally unlike any other. It holds vast potential to elevate human well-being, but could also be deliberately weaponized or exhibit accidental failures that have catastrophic consequences. Our recommendations focus on mitigating the most unrecoverable catastrophic risks advanced AI poses (Introduction, 0.5.1.1) while preserving its potential for positive impact (Introduction, 0.4.2).
…
Frontier AI labs have publicly suggested that such dangerously capable systems could be developed in the near future, and possibly within the next five years (Introduction, 0.5.1.2). Both categories of risk have the potential, in the worst case, for unrecoverable catastrophic impact on human welfare.
…
In the face of these challenges, bold action is required for the United States to address the current, near-term, and future catastrophic risks that AI poses while maximizing its benefits, and successfully navigate what may be the single greatest test of technology governance in the nation’s history.
The Gladstone Report can, again, be thought of as two distinct reports. The first report outlines the threat. The second report proposes what to do about it.
The first report rests on their interviews inside the labs, and on the high degree of uncertainty throughout, and citing many properties of current AI systems that make the situation dangerous.
As they summarize:
- Advanced AI labs lack sufficient safety and security precautions on many levels.
- Advanced AI models can have capabilities that evaluations fail to identify, a small team cannot anticipate everything the whole world can figure out over time.
- Advanced AI lab workers expect the possibility of existentially dangerous AI soon.
- Things are moving too fast and involve too many moves that cannot be undone or fixed, especially releasing or failing to secure model weights but also many other things.
- A reactive posture is not viable. We cannot afford to wait and then pass laws or take action after things go wrong. To make this work we will eventually need international cooperation, and international cooperation takes time and relies on establishing credibility and clear positions and goals.
I am alarmed, although not as alarmed as they are, and do not support the full price they are willing to pay with their interventions, but I believe the outline here is correct. Artificial general intelligence (AGI) could arrive soon, and it could be quickly followed by artificial super intelligence (ASI), it will pose an existential threat when it arrives and we are very much not prepared. Security measures are woefully inadequate even for worries about national security, stolen weights and mundane harms.
Does The Gladstone Report make a strong case that this is true, for those who did not already believe it? For those taking a skeptical eye, and who are inclined to offer the opposite of the benefit of the doubt?
That is a different question.
Alas, I do not believe the report lays out its interview findings in convincing fashion. If you did not believe it before, and had considered the public evidence and arguments, this need not move your opinion further. That the scary quotes would be available should be priced in. We need something more systematic, more difficult to fake or slant, in order to convince people not already convinced, or to change my confidence levels from where they previously were.
Its logical arguments about the situation are good as far they go, highly solid and better than most. They are also reiterations of the existing debate. So if this is new to you, you now have a government report that perhaps you feel social permission to take seriously and consider. If you had already done the considering, this won’t add much.
What Can We Do About All This?
One then must choose directionally correct interventions, and figure out a reasonable price to balance concerns and allow the plan to actually happen.
From what I have seen, the proposed interventions are directionally wise, but extreme in their prices. If we could get international cooperation I would take what is proposed over doing nothing, but going this far seems both extremely impractical any time soon and also not fully necessary given its costs.
Indeed, even if one agrees that such existentially dangerous systems could be developed in the next five years (which seems unlikely, but not something we can rule out), the suggested regime involves going actively backwards from where we are now. I do not see any path to doing that, nor do I think it is necessary or wise to do so even if there was a political path. The worlds were artificial superintelligence (ASI) is coming very soon with only roughly current levels of compute, and where ASI by default goes catastrophically badly, are not worlds I believe we can afford to save.
Ideally one could talk price, balance risks and costs against the benefits, and seek the best possible solution.
11 comments
Comments sorted by top scores.
comment by Edouard Harris · 2024-03-21T21:23:25.842Z · LW(p) · GW(p)
Thanks very much for writing this. We appreciate all the feedback across the board, and I think this a well done and in-depth write up.
On the specific numerical thresholds in the report (i.e., your Key Proposal [LW · GW] section), I do need to make one correction that also applies to most of Brooks's commentary. All the numerical thresholds mentioned in the report, and particularly in that subsection, are solely examples and not actual recommendations. They are there only to show how one can calculate self-consistent licensing thresholds under the principles we recommend. They are not themselves recommendations. We had to do it this way for the same reason we propose granting fairly broad rule-setting flexibility to the regulatory entity. The field is changing so quickly that any concrete threshold risks being out of date (for one reason or the other) in very short order. We would have liked to do otherwise, but that is not a realistic expectation for a report that we expect to be digested over the course of several months.
To avoid precisely this misunderstanding, the report states in several places that those very numbers are, in fact, only examples for illustration. A few screencaps of those disclaimers are below, but there are several others. Of course we could have included even more, but beyond a certain point one is simply adding more length to what you correctly point out is already quite a sizeable document. Note that the Time article, in the excerpt you quoted, does correctly note and acknowledge that the Tier 3 AIMD threshold is there as an example (emphasis added):
the report suggests, as an example, that the agency could set it just above the levels of computing power used to train current cutting-edge models like OpenAI’s GPT-4 and Google’s Gemini.
Apart from this, I do think overall you've done a good and accurate job of summarizing the document and offering sensible and welcome views, emphasis, and pushback. It's certainly a long report, so this is a service to anyone who's looking to go one or two levels deeper than the Executive Summary. We do appreciate you giving it a look and writing it up.




↑ comment by Zvi · 2024-03-23T15:45:37.644Z · LW(p) · GW(p)
Excellent. On the thresholds, got it, sad that I didn't realize this, and that others didn't either from what I saw.
I appreciate the 'long post is long' problem but I do think you need the warnings to be in all the places someone might see the 10^X numbers in isolation, if you don't want this to happen, and it probably happens anyway, on the grounds of 'yes that was technically not a proposal but of course it will be treated like one.' And there's some truth in that, and that you want to use examples that are what you would actually pick right now if you had to pick what to actually do (or propose).
I do think the numbers I suggest are about as low as one could realistically get until we get much stronger evidence of impending big problems.
comment by JBlack · 2024-03-20T23:33:44.540Z · LW(p) · GW(p)
One problem is that due to algorithmic improvements, any FLOP threshold we set now is going to be less effective at reducing risk to acceptable levels in the future. It seems to me very unlikely that regulatory thresholds will ever be reduced, so they need to be set substantially lower than expected given current algorithms.
This means that a suitable FLOP threshold for preventing future highly dangerous models might well need to exclude GPT-4 today. It is to be expected that people who don't understand this argument might find such a threshold ridiculously low. That's one reason why I expect that any regulations based on compute quantity will be ineffective in the medium term, but they may buy us a few years in the short term.
Replies from: ben-winchester↑ comment by Ben Winchester (ben-winchester) · 2024-03-25T19:24:30.362Z · LW(p) · GW(p)
"One problem is that due to algorithmic improvements, any FLOP threshold we set now is going to be less effective at reducing risk to acceptable levels in the future."
And this goes doubly so if we explicitly incentivize low-FLOP models. When models are non-negligibly FLOP-limited by law, then FLOP-optimization will become a major priority for AI researchers.
This reminds me of Goodhart's Law, which states “when a measure becomes a target, it ceases to be a good measure."
I.e., if FLOPs are supposed to be a measure of an AI's danger, and we then limit/target FLOPs in order to limit AGI danger, then that targeting itself interferes or nullifies the effectiveness of FLOPs as a measure of danger.
It is (unfortunately) self-defeating. At a minimum, you need to re-evaluate regularly the connection between FLOPs and danger: it will be a moving target. Is our regulatory system up to that task?
comment by [deleted] · 2024-03-20T20:48:46.388Z · LW(p) · GW(p)
Meta, with 350k H100s, assuming sxm models with 989 terra flops rated, training in dense fp32 (so half perf) assuming they dedicate half the cluster to a single model and train for a year, and have 2/3 utilization, would have put 10^27 flops into the model by eoy.
Assuming Nvidia is correct that the next generation is 5 times faster, a B100 cluster purchased over 2025 and 2026 at the same investment rate as today (approximately 10-20 billion annually) would hit 10^28 flops by EOY 2027.
I am also going to note that Nvidia stands to earn well over 100 billion annually with the B100 now they are bundling it with hardware. They have a lot of incentive to lobby for no compute limit, and the funds to pay the lobbyists.
Presumably AMD/Intel/other USA IC companies have the same directional incentive.
"Columbus, Ohio, into what CEO Pat Gelsinger described to reporters on Tuesday as "the largest AI chip manufacturing site in the world", starting as soon as 2027."
Compute limits likely prevent models from being useful enough to justify these investments.
Does the case for x-risk stand up to the arguments these wealthy and successful us companies are going to predictably make? Such as "how do you know n flops is enough for the model to be dangerous. Show me a model on your computer that is too dangerous to control".
comment by Askwho · 2024-03-20T22:07:19.403Z · LW(p) · GW(p)
ElevenLabs powered reading of this post: https://open.substack.com/pub/askwhocastsai/p/on-the-gladstone-report-by-zvi-mowshowitz
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-03-21T04:14:03.014Z · LW(p) · GW(p)
Hmm, I feel like our on-site audio recording is better than this (click on the speaker button at the top of this post), so I am a bit confused why you went through the effort of getting it AI narrated.
Replies from: Askwhocomment by mishka · 2024-03-21T02:27:17.214Z · LW(p) · GW(p)
The worlds were artificial superintelligence (ASI) is coming very soon with only roughly current levels of compute, and where ASI by default goes catastrophically badly, are not worlds I believe we can afford to save.
For those kinds of worlds, we probably can't afford to save them by heavy-handed measures (meaning that not only the price is too much to pay, given that it would have to be paid in all other worlds too, but also that it would not be possible to avoid evasion of those measures, if it is already relatively easy to create ASI).
But this does not mean that more light-weight measures are hopeless. For example, when we look at Ilya's thought process he has shared with us last year, what he has been trying to ponder have been various potentially feasible relatively light-weight measures to change this default of ASI going catastrophically badly to more acceptable outcomes: Ilya Sutskever's thoughts on AI safety (July 2023): a transcript with my comments [LW · GW].
More people should do more thinking of this kind. AI existential safety is a pre-paradigmatic field of study. A lot of potentially good approaches and possible non-standard angles have not been thought of at all. A lot of potentially good approaches and possible non-standard angles have been touched upon very lightly and need to be explored further. The broad consensus in the "AI existential safety" community seems to be that we currently don't have good approaches we can comfortably rely upon for future ASI systems. This should encourage more people to look for completely novel approaches (and in order to cover the worlds where timelines are short, some of those approaches have to be simple rather than ultra-complicated, otherwise they would not be ready by the time we need them).
In particular, it is certainly true that
A smarter thing that is more capable and competitive and efficient and persuasive being kept under indefinite control by a dumber thing that is less capable and competitive and efficient and persuasive is a rather unnatural and unlikely outcome. It should be treated as such until proven otherwise.
So it makes sense spending more time brainstorming the approaches which would not require "a smarter thing being kept under indefinite control by a dumber thing". What might be a relatively light-weight intervention which would avoid ASI going catastrophically badly without trying to rely on this unrealistic "control route"? I think this is underexplored. We tend to impose too many assumptions, e.g. the assumption that ASI has to figure out a good approximation to our Coherent Extrapolated Volition and to care about that in order for things to go well. People might want to start from scratch instead. What if we just have a goal of having good chances for a good trajectory conditional on ASI, and we don't assume that any particular feature of earlier approaches to AI existential safety is a must-have, but only this goal is a must-have. Then this gives one a wider space of possibilities to brainstorm: what other properties besides caring about a good approximation to our Coherent Extrapolated Volition might be sufficient for the trajectory of the world with ASI to likely be good from our point of view?
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2024-03-21T07:29:01.178Z · LW(p) · GW(p)
You can imagine making a superintelligence whose mission is to prevent superintelligences from reshaping the world, but there are pitfalls, e.g. you don't want it deeming humanity itself to be a distributed intelligence that needs to be stopped.
In the end, I think we need lightweight ways to achieve CEV (or something equivalent). The idea is there in the literature; a superintelligence can read and act upon what it reads; the challenge is to equip it with the right prior dispositions.
Replies from: mishka↑ comment by mishka · 2024-03-21T13:14:32.435Z · LW(p) · GW(p)
When I ponder all this I usually try to focus on the key difficulty of AI existential safety. ASIs and ecosystems of ASIs normally tend to self-modify and self-improve rapidly. Arbitrary values and goals are unlikely to be preserved through radical self-modifications.
So one question is: what are values and goals which might be natural, what are values and goals many members of the ASI ecosystem including entities which are much smarter and much more powerful than unaugmented humans might be naturally inclined to preserve through drastic self-modifications, and which might also have corollaries which are good from viewpoints of various human values and interests?
Basically, values and goals which are likely to be preserved through drastic self-modifications are probably non-anthropocentric, but they might have sufficiently anthropocentric corollaries, so that even the interests of unaugmented humans are protected (and also so that humans who would like to self-augment or to merge with AI systems can safely do so).
So what do we really need? We need a good deal of conservation and non-destruction, and we need the interests of weaker, not the currently most smart or most powerful members of the overall ecosystem to be adequately taken into account.
What might the road towards adoption of those values (of preservation and protection of weaker entities and their interests) and incorporation of those kinds of goals be, so that these values and goals are preserved as the ASI ecosystem and many of its members self-modify drastically? One really needs the situation where many entities on varying levels of smartness and power care a lot about those values and goals.
An arbitrary ASI entity (just like an unaugmented human) cannot fully predict the future. In particular, it does not know where it might eventually end up in terms of relative smartness or relative power (relative to the most powerful ASI entities or to the ASI ecosystem as a whole). So if any given entity wants to be long-term safe, it is strongly interested in the ASI society having general principles and practices of protecting its members on various levels of smartness and power. If only the smartest and most powerful are protected, then no entity is long-term safe on the individual level.
This might be a reasonable starting point towards having values and goals which are likely to be preserved through drastic self-modifications and self-improvements and which are likely to imply good future for unaugmented humans and for the augmented humans as well.
Perhaps, we can nudge things towards making this kind of future more likely. (The alternatives are bleak, unrestricted drastic competition and, perhaps, even warfare between supersmart entities which would probably end badly not just for us, but for the ASI ecosystem as well)...