Revisiting algorithmic progress
post by Tamay, Ege Erdil (ege-erdil) · 2022-12-13T01:39:19.264Z · LW · GW · 15 commentsThis is a link post for https://arxiv.org/abs/2212.05153
Contents
Our main results include: None 15 comments
How much progress in ML depends on algorithmic progress, scaling compute, or scaling relevant datasets is relatively poorly understood. In our paper, we make progress on this question by investigating algorithmic progress in image classification on ImageNet, perhaps the most well-known test bed for computer vision.
Using a dataset of a hundred computer vision models, we estimate a model—informed by neural scaling laws—that enables us to analyse the rate and nature of algorithmic advances. We use Shapley values to produce decompositions of the various drivers of progress computer vision and estimate the relative importance of algorithms, compute, and data.
Our main results include:
- Every nine months, the introduction of better algorithms contributes the equivalent of a doubling of compute budgets. This is much faster than the gains from Moore’s law; that said, there's uncertainty (our 95% CI spans 4 to 25 months)

- Roughly, progress in image classification has been ~45% due to the scaling of compute, ~45% due to better algorithms, ~10% due to scaling data
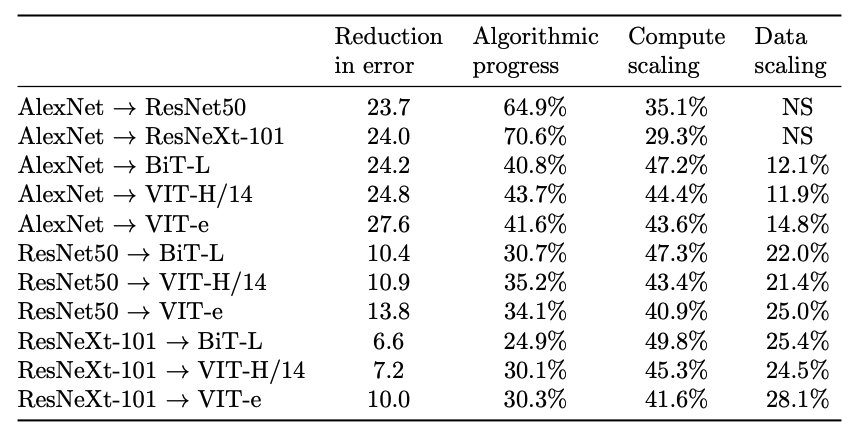
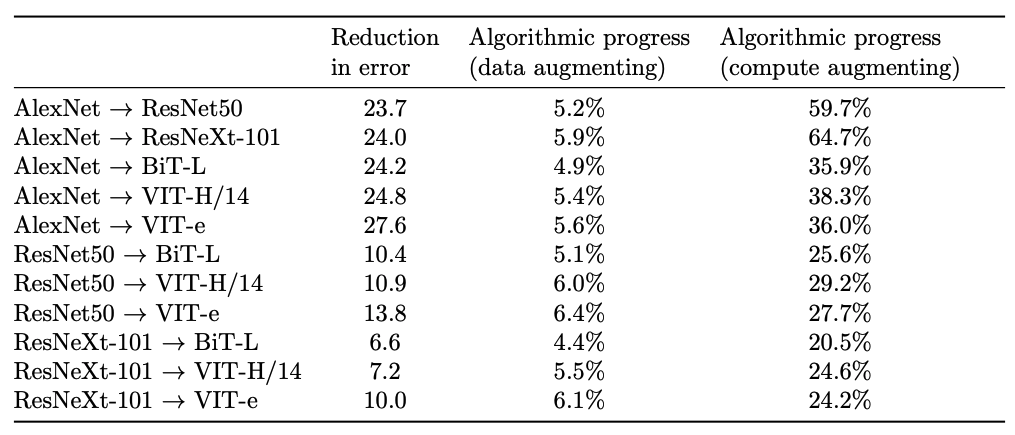
- The majority (>75%) of algorithmic progress is compute-augmenting (i.e. enabling researchers to use compute more effectively), a minority of it is data-augmenting
In our work, we revisit a question previously investigated by Hernandez and Brown (2020), which had been discussed on LessWrong by Gwern [LW · GW], and Rohin Shah [LW · GW]. Hernandez and Brown (2020) re-implement 15 open-source popular models and find a 44-fold reduction in the compute required to reach the same level of performance as AlexNet, indicating that algorithmic progress outpaces the original Moore’s law rate of improvement in hardware efficiency, doubling effective compute every 16 months.
A problem with their approach is that it is sensitive to the exact benchmark and threshold pair that one chooses. Choosing easier-to-achieve thresholds makes algorithmic improvements look less significant, as the scaling of compute easily brings early models within reach of such a threshold. By contrast, selecting harder-to-achieve thresholds makes it so that algorithmic improvements explain almost all of the performance gain. This is because early models might need arbitrary amounts of compute to achieve the performance of today's state-of-the-art models. We show that the estimates of the pace of algorithmic progress with this approach might vary by around a factor of ten, depending on whether an easy or difficult threshold is chosen. [1]
Our work sheds new light on how algorithmic efficiency occurs, namely that it primarily operates through relaxing compute-bottlenecks rather than through relaxing data-bottlenecks. It further offers insight on how to use observational (rather than experimental) data to advance our understanding of algorithmic progress in ML.
- ^
That said, our estimates is consistent with Hernandez and Brown (2020)'s estimate that algorithmic progress doubles the amount of effective compute every 16 months, as our 95% confidence interval ranges from 4 to 25 months.
15 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-01-10T08:29:25.820Z · LW(p) · GW(p)
This post points to a rather large update, which I think has not yet propagated through the collective mind of the alignment community. Gains from algorithmic improvement have been roughly comparable to gains from compute and data, and much larger on harder tasks (which are what matter for takeoff).
Yet there's still an implicit assumption behind lots of alignment discussion that progress is mainly driven by compute. This is most obvious in discussions of a training pause: such proposals are almost always about stopping very large runs only. That would stop increases in training compute. Yet it's unlikely to slow down algorithmic progress much; algorithmic progress does use lots of compute (i.e. trying stuff out), but it uses lots of compute in many small runs, not big runs. So: even a pause which completely stops all new training runs beyond current size indefinitely would only ~double timelines at best, and probably less (since algorithmic progress is a much larger share than compute and data for harder tasks). Realistically, a pause would buy years at best, not decades.
I've personally cited [LW · GW] the linked research within the past year. I think this is a major place where the median person in alignment will look back in a few years and say "Man, we should have collectively updated a lot harder on that".
Replies from: gwern, Jsevillamol↑ comment by gwern · 2024-01-10T20:57:20.458Z · LW(p) · GW(p)
That assumption is still there because your interpretation is both not true and not justified by this analysis. As I've noted several times before, time-travel comparisons like this are useful for forecasting, but are not causal models of research: they cannot tell you the consequence of halting compute growth, because compute causes algorithmic progress. Algorithmic progress does not drop out of the sky by the tick-tock of a clock, it is the fruits of spending a lot of compute on a lot of experiments and trial-and-error and serendipity.
Unless you believe that it is possible to create that algorithmic progress in a void of pure abstract thought with no dirty trial-and-error of the sort which actually creates breakthroughs like Resnets or GPTs, then any breakdown like this relying on 'compute used in a single run' or 'compute used in the benchmark instance' simply represents a lower bound on the total compute spent to achieve that progress.
Once compute stagnates, so too will 'algorithmic' progress, because 'algorithmic' is just 'compute' in a trenchcoat. Only once the compute shows up, then the overflowing abundance of ideas will be able to be validated and show which one was a good algorithm after all; otherwise, it's just Schmidhubering into a void and a Trivia Pursuit game like 'oh, did you know resnets and Densenets were first invented in 1989 and they had shortcut connections well before that? too bad they couldn't make any use of it then, what a pity'.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-01-10T22:48:19.691Z · LW(p) · GW(p)
It sounds like you did not actually read my comment? I clearly addressed this exact point:
Yet it's unlikely to slow down algorithmic progress much; algorithmic progress does use lots of compute (i.e. trying stuff out), but it uses lots of compute in many small runs, not big runs.
We are not talking here about a general stagnation of compute, we are talking about some kind of pause on large training runs. Compute will still keep getting cheaper.
If you are trying to argue that algorithmic progress only follows from unprecedently large compute runs, then (a) say that rather than strawmanning me as defending a view in which algorithmic progress is made without experimentation, and (b) that seems clearly false of the actual day-to-day experiments which go into algorithmic progress.
↑ comment by Jsevillamol · 2024-01-23T21:22:47.798Z · LW(p) · GW(p)
even a pause which completely stops all new training runs beyond current size indefinitely would only ~double timelines at best, and probably less
I'd emphasize that we currently don't have a very clear sense of how algorithmic improvement happens, and it is likely mediated to some extent by large experiments, so I think is more likely to slow timelines more than this implies.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-01-23T21:49:27.265Z · LW(p) · GW(p)
I mean, we can go look at the things which people do when coming up with new more-efficient transformer algorithms, or figuring out the Chinchilla scaling laws, or whatever. And that mostly looks like running small experiments, and extrapolating scaling curves on those small experiments where relevant. By the time people test it out on a big run, they generally know very well how it's going to perform.
The place where I'd see the strongest case for dependence on large compute is prompt engineering. But even there, it seems like the techniques which work on GPT-4 also generally work on GPT-3 or 3.5?
Replies from: Jsevillamol↑ comment by Jsevillamol · 2024-01-23T22:47:11.898Z · LW(p) · GW(p)
shrug
I think this is true to an extent, but a more systematic analysis needs to back this up.
For instance, I recall quantization techniques working much better after a certain scale (though I can't seem to find the reference...). It also seems important to validate that techniques to increase performance apply at large scales. Finally, note that the frontier of scale is growing very fast, so even if these discoveries were done with relatively modest compute compared to the frontier, this is still a tremendous amount of compute!
comment by Lech Mazur (lechmazur) · 2024-03-12T03:48:49.003Z · LW(p) · GW(p)
I noticed a new paper by Tamay, Ege Erdil, and other authors: https://arxiv.org/abs/2403.05812. This time about algorithmic progress in language models.
"Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law."
comment by Lukas Finnveden (Lanrian) · 2022-12-19T15:16:12.858Z · LW(p) · GW(p)
Thanks for this!
Question: Do you have a sense of how strongly compute and algorithms are complements vs substitutes in this dataset?
(E.g. if you compare compute X in 2022, compute (k^2)X in 2020, and kX in 2021: if there's a k such that the last one is better than both the former two, that would suggest complementarity)
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-12-20T14:40:29.790Z · LW(p) · GW(p)
I think this question is interesting but difficult to answer based on the data we have, because the dataset is so poor when it comes to unusual examples that would really allow us to answer this question with confidence. Our model assumes that they are substitutes, but that's not based on anything we infer from the data.
Our model is certainly not exactly correct, in the sense that there should be some complementarity between compute and algorithms, but the complementarity probably only becomes noticeable for extreme ratios between the two contributions. One way to think about this is that we can approximate a CES production function
in training compute and algorithmic efficiency when by writing it as
which means the first-order behavior of the function around doesn't depend on , which is the parameter that controls complementarity versus substitutability. Since people empirically seem to train models in the regime where is close to this makes it difficult to identify from the data we have, and approximating by a Cobb-Douglas (which is what we do) does about as well as anything else. For this reason, I would caution against using our model to predict the performance of models that have an unusual combination of dataset size, training compute, and algorithmic efficiency.
In general, a more diverse dataset containing models trained with unusual values of compute and data for the year that they were trained in would help our analysis substantially. There are some problems with doing this experiment ourselves: for instance, techniques used to train larger models often perform worse than older methods if we try to scale them down. So there isn't much drive to make algorithms run really well with small compute and data budgets, and that's going to bias us towards thinking we're more bottlenecked by compute and data than we actually are.
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2022-12-21T16:11:20.062Z · LW(p) · GW(p)
Interesting, thanks! To check my understanding:
- In general, as time passes, all the researcheres increase their compute usage at a similar rate. This makes it hard to distinguish between improvements caused by compute and algorithmic progress.
- If the correlation between year and compute was perfect, we wouldn't be able to do this at all.
- But there is some variance in how much compute is used in different papers, each year. This variance is large enough that we can estimate the first-order effects of algorithmic progress and compute usage.
- But complementarity is a second-order effect, and the data doesn't contain enough variation/data-points to give a good estimate of second-order effects.
↑ comment by Ege Erdil (ege-erdil) · 2022-12-22T01:11:52.234Z · LW(p) · GW(p)
This looks correct to me - this is indeed how the model is able to disentangle algorithmic progress from scaling of training compute budgets.
The problems you mention are even more extreme with dataset size because plenty of the models in our analysis were only trained on ImageNet-1k, which has around 1M images. So more than half of the models in our dataset actually just use the exact same training set, which makes our model highly uncertain about the dataset side of things.
In addition, the way people typically incorporate extra data is by pretraining on bigger, more diverse datasets and then fine-tuning on ImageNet-1k. This is obviously different from sampling more images from the training distribution of ImageNet-1k, though bigger datasets such as ImageNet-21k are constructed on purpose to be similar in distribution to ImageNet-1k. We actually tried to take this into account explicitly by introducing some kind of transfer exponent between different datasets, but this didn't really work better than our existing model.
One final wrinkle is the irreducible loss of ImageNet. I tried to get some handle on this by reading the literature, and I think I would estimate a lower bound of maybe 1-2% for top 1 accuracy, as this seems to be the fraction of images that have incorrect labels. There's a bigger fraction of images that could plausibly fit multiple categories at once, but models seem to be able to do substantially better than chance on these examples, and it's not clear when we can expect this progress to cap out.
Our model specification assumes that in the infinite compute and infinite data limit you reach 100% accuracy. This is probably not exactly right because of irreducible loss, but because models are currently around over 90% top-1 accuracy I think it's probably not too big of a problem for within-distribution inference, e.g. answering questions such as "how much software progress did we see over the past decade". Out-of-distribution inference is a totally different game and I would not trust our model with this for a variety of reasons - the biggest reason is really the lack of diversity and the limited size of the dataset and doesn't have much to do with our choice of model.
To be honest, I think ImageNet-1k is just a bad benchmark for evaluating computer vision models. The reason we have to use it here is that all the better benchmarks that correlate better with real-world use cases have been developed recently and we have no data on how past models perform on these benchmarks. When we were starting this investigation we had to make a tradeoff between benchmark quality and the size & diversity of our dataset, and we ended up going for ImageNet-1k top 1 accuracy for this reason. With better data on superior benchmarks, we would not have made this choice.
comment by Zach Stein-Perlman · 2022-12-13T06:30:13.851Z · LW(p) · GW(p)
Any speculations on the implications for the rate of algorithmic progress on AGI/TAI/etc. (where algorithmic progress here means how fast the necessary training compute decreases over time), given that AGI is a different kind of "task," and it's a "task" that hasn't yet been "solved," and the ways of making progress are more diverse?
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-12-13T16:15:50.305Z · LW(p) · GW(p)
I would guess that making progress on AGI would be slower. Here are two reasons I think are particularly important:
-
ImageNet accuracy is a metric that can in many ways be gamed; so you can make progress on ImageNet that is not transferable to more general image classification tasks. As an example of this, in this paper the authors conduct experiments which confirm that adversarially robust training on ImageNet degrades ImageNet test or validation accuracy, but robustly trained models generalize better to classification tasks on more diverse datasets when fine-tuned on them.
This indicates that a lot of the progress on ImageNet is actually "overlearning": it doesn't generalize in a useful way to tasks we actually care about in the real world. There's good reason to believe that part of overlearning would show up as algorithmic progress in our framework, as people can adapt their models better to ImageNet even without extra compute or data.
-
Researchers have stronger feedback loops on ImageNet: they can try something directly on the benchmark they care about, see the results and immediately update on their findings. This allows them to iterate much faster and iteration is a crucial component of progress in any engineering problem. In contrast, our iteration loops towards AGI operate at considerably lower frequencies. This point is also made by Ajeya Cotra in her biological anchors report, and it's why she chooses to cut the software progress speed estimates from Hernandez and Brown (2020) in half when computing her AGI timelines.
Such an adjustment seems warranted here, but I think the way Cotra does it is not very principled and certainly doesn't do justice to the importance of the question of software progress.
Overall I agree with your point that training AGI is a different kind of task. I would be more optimistic about progress in a very broad domain such as computer vision or natural language processing translating to progress towards AGI, but I suspect the conversion will still be significantly less favorable than any explicit performance metric would suggest. I would not recommend using point estimates of software progress on the order of a doubling of compute efficiency per year for forecasting timelines.
comment by avturchin · 2022-12-13T12:54:09.827Z · LW(p) · GW(p)
How can I convert "percents" of progress into multipliers? That is, progress= a*b, but percents assume a+b.
For example, if progress is 23 times, and 65 percent of it is a, how many times is it?
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-12-13T15:54:48.283Z · LW(p) · GW(p)
You would do it in log space (or geometrically). For your example, the answer would be .