Forecasting Newsletter: March 2021
post by NunoSempere (Radamantis) · 2021-04-01T17:12:09.499Z · LW · GW · 3 commentsContents
Highlights Index Prediction Markets & Forecasting Platforms Metaculus In the News Recent Blog Posts Hard to Categorize Long Content None 3 comments
Highlights
- OpenPhilanthropy releases a report on outside view perspectives on the likelihood of AGI.
- Jason Matheny, previous director of IARPA, CSET, is now a ¿senior? official in the Biden administration.
- Astral Codex Ten considers Trapped Priors As A Basic Problem Of Rationality
Index
- Prediction Markets & Forecasting Platforms
- In The News
- Recent Blog Posts
- Hard to Categorize
- Long Content
Sign up here or browse past newsletters here [? · GW].
Prediction Markets & Forecasting Platforms
Numerai is a distributed, blockchain-based hedge fund. Users can either predict on free, but obfuscated data, or use their own data and predict on real world companies. After the users stake cryptocurrency on their predictions, Numerai buys or sells stocks in proportion to each prediction's stake.and then stake cryptocurrency on their predictions. The fund observes how well the predictions do. Then it increases the stake of those who did well and burns part of the stake of those who performed badly. Numerai’s users currently have around $12.5 million staked.
CSET's Founding Director Jason Matheny is now a ¿senior? official in the Biden administration. In his past life, he did some pioneering work on cultured meat, then was a Program Manager of IARPA's Aggregative Contingent Estimation (ACE) program (of Good Judgment fame), before becoming director of IARPA. In recent times, he founded the Center for Security and Emerging Technologies (CSET.)
CSET Foretell is launching a Pro Forecaster Program in April 2021, which means it will start paying its forecasters. They are offering to pay $200/month (each) to 50 selected forecasters. The total payout, which comes to $120k yearly, competes with Replication Markets as one of the largest forecaster reward budgets.
Pro Forecasters will be paid to make forecasts that contribute to our research and analysis for policymakers. Invitations have been sent to current Foretell users, and we are now accepting applications for the remaining spots. Anyone who can show a proven track record as a top forecaster on Good Judgment Open, Metaculus, or a similar crowd forecasting site may apply (emphasis mine).
Using early data, CSET Foretell finds that its crowd outperforms historical projections.
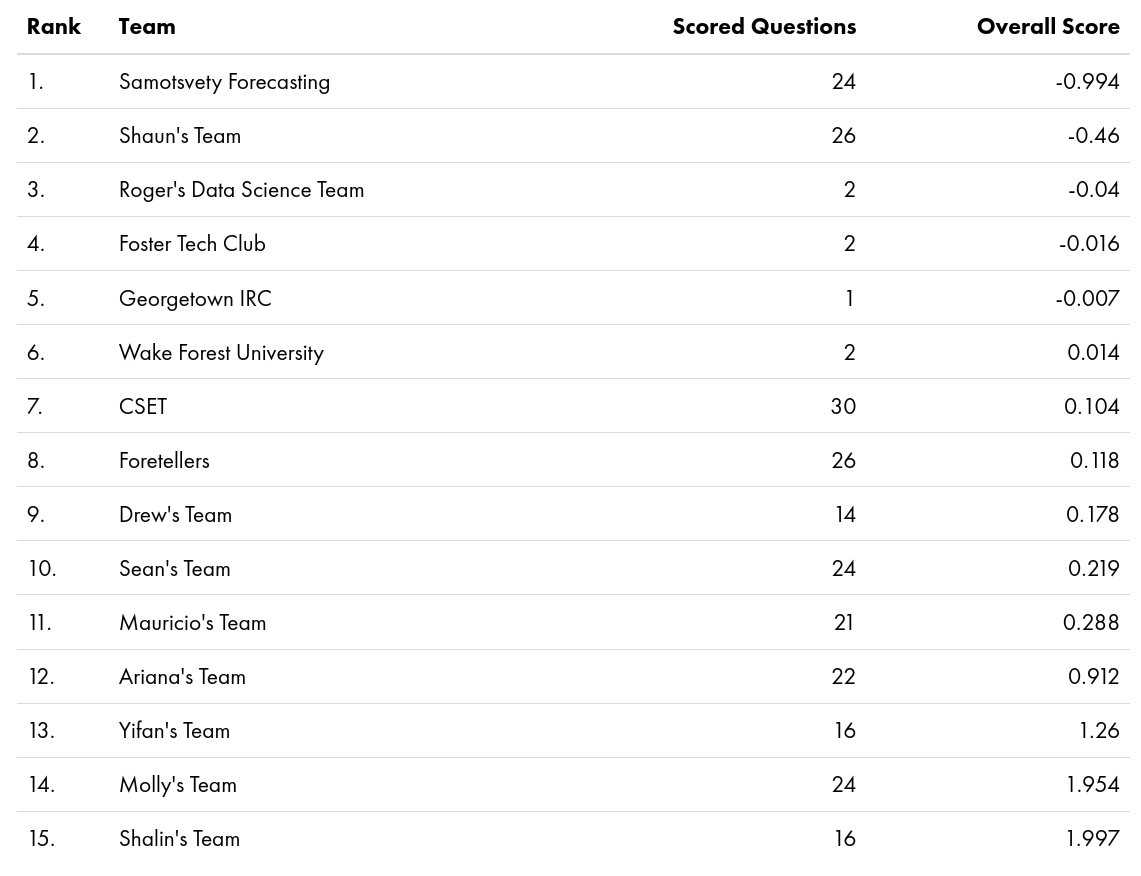
Personally, I ended up on place #5 out of 646 on the first season’s leaderboard, and my team, Samotsvety Forecasting, comprised out of Eli Lifland, Misha Yagudin and myself, completely outpaced all other teams:
Omen v2 launches. Crucially, they are moving to a subchain. Trades will be cheaper, once they are made inside the subchain, yet this comes at a cost—the process of moving currency to a subchain is cumbersome. They have added more questions, but the platform still remains small.
Here is a short explanation of how Catnip works, and what the differences between Catnip and Augur are.
Hypermind has a new forecasting tournament—on the state of AI in 2030—with relatively low rewards of $3000.
I’ve continued to improve Metaforecast:
- I added MichaelA’s excellent Database of Existential Risk Estimates.
- I also added Ladbrokes, WilliamHill, Estimize and FantasySCOTUS, “the leading Supreme Court Fantasy League,” which covers cases the US Supreme Court is expected to address this year.
- I marginally improved the search, h/t Peter Hartree for a detailed pull request.
- Ozzie Gooen and I wrote Introducing Metaforecast: A Forecast Aggregator and Search Tool [EA · GW] (also on LessWrong [LW · GW]).
- Metaforecast also saw some activity on twitter.
While sniffing the requests from WilliamHill and Ladbrokes, I found out about OpenBet. OpenBet is a provider of software infrastructure for many major European betting houses: WilliamHill, Betfair, PaddyPower, Ladbrokes, etc. They package that software infrastructure with extremely addictive games. OpenBet has a “Corporate Social Responsibility” page and various responsible gaming accreditations. But despite these accrediations, the platform's business model appears to rely on making the bettors become addicted: As explained on the—sinisterly named —“omni-channel” page "multi-channel customers have proven to be 38% more profitable than single channel customers”. It’s unclear to me whether the fact that they manage the infrastructure for so many European betting houses is problematic with regards to the EU’s antitrust policy; I’d give it a 10 to 30% chance.
That modus operandi stands in contrast to current cryptocurrency-based prediction markets, which have much cleaner interfaces and don’t appear to indulge in predatory profit-chasing, e.g., compare Omen's frontend with that of Betfair.
In a sad turn of affairs, Polkamarkets, a new prediction market still under development, might also be aiming to capture profit from the addictive gamification aspect of betting within the crypto-prediction market ecosystem. Nonetheless, Polkamarkets hasn’t launched yet and, on the positive side, it promises higher frequency markets and faster resolution times, so it’s still too soon to judge whether it will be a net positive project.
Metaculus
Metaculus is hiring.
There has been some discussion about, and criticism of, the Metaculus scoring rule. A Metaculus co-founder answers with A Primer on the Metaculus Scoring Rule.
MetaculusExtras has added new features, like the daily and cumulative number of predictions on the site or the number of points per question per user. SimonM, of MetaculusExtras fame, also extracts the top comments (i.e. the most upvoted and slightly curated) made in March on Metaculus:
- misha lays out the various different odds for the Olympics on different platforms. Relatedly, and not on Metaculus, see this twitter thread by Brian Lui about a trader on FTX who is taking all bets.
- zc points out some examples of countries having fantastic longevity improvements
- ege_erdil calculates the base rate for resignations for politicians resigning after accusations of misconduct.
- SimonM finds the distribution of the maximum price of BTC implied by market prices (cf. volatility smile),the historical base rates of SCOTUS accepting a case, and the US House of Representatives disciplining a member.
- Matthew_Barnett explains why he wrote a question calling out bad predictions by journalists and policy analysts.
- isinlor makes the case for predictions about the longer-term future: even if Metaculus doesn’t exist, its questions will almost certainly be archived.
- Sylvian comments on how to ask good questions.
In the News
FiveThirtyEight on why Republicans outperformed polls again. Their two hypotheses are that Republicans are losing trust in (strongly left-leaning) institutions, and that college-graduated Republicans might worry about being ostracized for their political views. However, the connection between that and differential nonresponse seems unclear.
Also from FiveThirtyEight: Ignore What Potential 2024 Presidential Candidates Say. Watch What They Do. I found Senator Obama's flat out, no-nonsense denial that he would run for president in 2008 particularly striking.
Coles shows off a powerful forecasting engine. I was especially surprised by the following paragraph:
Today, 95 percent of the items that you see in the stores are all on automatic ordering. The store does not need to place any orders. Our analytics behind the system looks at the history, looks at the plans, and projects that order demand for the stores that come from all the delivery centres.
I looked into how hard the insurance industry has been hit by COVID. On the one hand, payouts spiked; on the other hand, insurance companies also got more clients. There isn't much hard data, but overall the first effect seems to dominate around the world. COVID Insurance Coverage One Year Later describes the situation on the US front, explains that policies were ambiguously written and that courts are still deciding whether COVID-19 should be classified as "physical damage" or a "physical alteration".
Our next prediction was disheartening, but also pretty obvious: Policyholders would have to sue to secure coverage. The economic impact of this pandemic is larger than anything the world has ever seen, dwarfing other massive loss events like 9/11 or Hurricane Katrina. Paying even a fraction of the claims would bankrupt the insurance industry, so insurers had no choice but to deny every coronavirus-related claim and force policyholders to sue to secure coverage. We got this one right.
Technology for Forecasting Fish Outbreaks keeps improving. I mention this from time to time, and I may have seen the idea somewhere else, but subsidizing such technology could be a cost-effective intervention to improve fish welfare.
The Association of Bay Area Governments has released a series of demographic, economic, and land-use projections for 2040. The projections are presented on a sleek webpage as well as in a more comprehensive pdf. The expected error of these projections is difficult to estimate.
Recent Blog Posts
Astral Codex Ten considers Trapped Priors As A Basic Problem Of Rationality. “The raw evidence (the Rottweiler sat calmly wagging its tail) looks promising. But the context is a very strong prior that dogs are terrifying. If the prior is strong enough, it overwhelms the real experience. Result: the Rottweiler was terrifying. Any update you make on the situation will be in favor of dogs being terrifying”

Discussion on Kelly Betting: Kelly isn't (just) about logarithmic utility [LW · GW], Kelly is (just) about logarithmic utility [LW · GW], and A non-logarithmic argument for Kelly [LW · GW] (and this comment [LW(p) · GW(p)] which summarizes the last post.)
David Manheim tries to apply accounting principles to forecasting on Resolutions to the Challenge of Resolving Forecasts [LW · GW] and Systematizing Epistemics: Principles for Resolving Forecasts [LW · GW].
deluks917, of previous "Bet on Biden" [LW · GW] fame, has two pieces on the Efficient Market Hypothesis (EMH): The EMH is False - Specific Strong Evidence [LW · GW] and Violating the EMH - Prediction Markets [LW · GW]
Why sigmoids are so hard to predict [LW · GW] makes an argument in terms of the differential equation which produces sigmoids. “The core reason why the turning point and the maximums are so hard to predict from early data [is that] we're not only trying to figure out the parameters of a logistic curve, but the functional form of the dampening function - a dampening function whose effect is insignificant in the early data.”

Cafebedouin, a top Good Judgment Open forecaster who recently ascended into superforecastdom, reviews his predictions for 2020.
Niplav looks at Range and Forecasting Accuracy of questions on PredictionBook and Metaculus. Its results are an instance of Simpson's paradox:
- Questions with a longer range (that is, time between the question being written and the question being resolved) generally receive predictions with a higher accuracy than questions with a shorter range. This might be because they are easier questions, or because they receive higher quality forecasts.
- Predictions made on the same question earlier are generally less accurate than predictions that are made later.
Star Spangled Gamblers is a political betting blog which mostly covers questions on PredictIt. Here is a profile piece on whether California's Governor Gavin Newsom will be recalled. The author seems to think that he won't, but that there are many events which would make irrational gamblers push the price higher than it currently is. This thesis is presented together with a solid mechanistic understanding of how California recall elections work and have turned out in the past.
Hard to Categorize
Forecasting: Principles and Practice is a free online textbook which covers time series forecasting using R.
Orbit is "a Python package for Bayesian time series modeling and inference" developed by Uber. The documentation looks reasonably interesting.
Long Content
OpenPhilanthropy released a report on outside view perspectives on the likelihood of AGI. The report “ignores some of our evidence about when AGI will happen. It restricts itself to outside view considerations - those relating to how long analogous developments have taken in the past. It ignores evidence about how good current AI systems are compared to AGI, and how quickly the field of AI is progressing. It does not attempt to give all-things-considered probabilities.”
OpenPhilanthropy asked various academics for feedback. Among other comments, they highlighted the following:
- The importance of unknown unknowns. They would presumably make the prior wider, and could also be incorporated from an outside-view perspective.
- The assumption of independent and identically distributed trials might be faulty. In this case, modelling the path to AGI as a journey of unknown duration ends up giving similar results after an initial period.
- The need for a measure of the robustness of probabilities.
- The observation that AGI is more of a continuous than a binary problem.
Understanding "empirical Bayes estimation" (using baseball statistics): Given two baseball batters, one which has hit 4 out of 10 balls, and another one which has hit 300 out of 1000 balls, which one is, in expectation, better?

In a prediction market in which participants Kelly bet, the market price reacts exactly as if updating according to Bayes' Law. See an introductory blog post, and this paper with a proof.
From The risks of communicating extreme climate forecasts:
In a new paper published in the International Journal of Global Warming, Carnegie Mellon University's David Rode and Paul Fischbeck argue that making such forecasts can be counterproductive. "Truly apocalyptic forecasts can only ever be observed in their failure--that is the world did not end as predicted," says Rode, adjunct research faculty with the Carnegie Mellon Electricity Industry Center, "and observing a string of repeated apocalyptic forecast failures can undermine the public's trust in the underlying science."
Fischbeck noted, "from a forecasting perspective, the 'problem' is not only that all of the expired forecasts were wrong, but also that so many of them never admitted to any uncertainty about the date. About 43% of the forecasts in our dataset made no mention of uncertainty."
In some cases, the forecasters were both explicit and certain. For example, Stanford University biologist Paul Ehrlich and British environmental activist Prince Charles are serial failed forecasters, repeatedly expressing high degrees of certainty about apocalyptic climate events.
Rode commented "Ehrlich has made predictions of environmental collapse going back to 1970 that he has described as having 'near certainty'. Prince Charles has similarly warned repeatedly of 'irretrievable ecosystem collapse' if actions were not taken, and when expired, repeated the prediction with a new definitive end date. Their predictions have repeatedly been apocalyptic and highly certain...and so far, they've also been wrong."
Long-Term Capital Management is a failed hedge fund. In the aftermath of its failure, its manager set up another hedge fund, which also failed in the 2008 crisis, and then a third one, whose current existence is uncertain.
Initially successful with annualized return of over 21% (after fees) in its first year, 43% in the second year and 41% in the third year, in 1998 it lost $4.6 billion in less than four months due to a combination of high leverage and exposure to the 1997 Asian financial crisis and 1998 Russian financial crisis.
A Semitechnical Introductory Dialogue on Solomonoff Induction [LW · GW] presents, in dialogue form, an idealized way of “how to do good epistemology” if one had infinite computing power.
Nature study which gives electric shocks to participants when they predict incorrectly finds that "irreducible subjective uncertainty" is very predictive of stress.
On each trial, a stimulus (rock A or rock B) was presented and participants were asked to predict whether or not there was a snake underneath (snake or no snake). Each time a snake was presented, participants received a painful electric shock to the hand.
Pupil diameter and skin conductance provided established measures of activity in the autonomic nervous system, a key effector of acute stress responses.
We found that all three were predicted by subjective irreducible uncertainty. We further examined interindividual variance in the degree of coupling between uncertainty and stress responses, which we related to the ability of participants to learn in an uncertain dynamic environment. Unpredictable aversive threat induces stress.
The probabilistic mapping from stimulus (rock) to outcome (snake) shifted over the course of the experiment (Fig. 1c), requiring participants to track this relationship over time. When an outcome was revealed, the presence of a snake was deterministically associated with an electric shock delivered to the back of the left hand. Over the course of 320 trials, the probabilistic mapping between stimuli and outcomes changed every 26–38 trials, requiring participants to maintain and update their beliefs about the probability of a snake being under either rock.
Shocks and irreducible uncertainty both predicted subjective stress ratings (single-sample t-tests, P<0.001; P=0.0024).
As predicted, participants reported being most stressed when they believed the current state was high in irreducible uncertainty.
Subjective irreducible uncertainty is highest in our task when the subject’s estimated probability of a shock is 50%, corresponding to a situation where the environment is utterly unpredictable, and maximal in entropy.

Note to the future: All links are added automatically to the Internet Archive. In case of link rot, go there and input the dead link.
Value is not created in the production of the forecast, but in the deployment of plans and actions that follow.
Source: Kitsch article about how to improve forecasting.
3 comments
Comments sorted by top scores.
comment by Pattern · 2021-04-02T02:33:42.818Z · LW(p) · GW(p)
The fund observes how well the predictions do, and increases the stake of those users whose predictions did well, and burns part of the stake of those who performed badly. Then it increases the stake of those who did well and burns part of the stake of those who performed badly.
Is there a difference between these two things?
The importance of unknown unknowns. They would presumably make the prior wider, and could also be incorporated from an outside-view perspective.
A meteor falling out of the sky used to be an unknown factor. It doesn't happen often, and might be underestimated. For that matter, pandemics - you could argue this is "the outside view's moment to shine" but who held this outside view? (That was rhetorical, but since this is a forecasting newsletter - any examples of centenarians response or perspective to/on SARS or COVID?)
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2021-04-02T08:24:19.482Z · LW(p) · GW(p)
No, the first part is a typo, thanks.
I'm not sure I understand what "this" refer to in that sentence