UML final
post by Rafael Harth (sil-ver) · 2020-03-08T20:43:58.897Z · LW · GW · 1 commentsContents
Multiclass Prediction Approach 1: Reduction to Binary Classification Approach 2: Linear Programming Approach 3: Surrogate Loss and Stochastic Gradient Descent Remaining Material Naive Bayes Classifier Feature Selection Regularization and Stability Generative Models Advanced Theory Closing Thoughts on the Book None 1 comment
(This is the fourteenth and final post in a sequence on Machine Learning based on this book. Click here [? · GW] for part I.)
The first part of this post will be devoted to multiclass prediction, which is the last topic I'll cover in the usual style. (It's on the technical side; requires familiarity with a bunch of concepts covered in earlier posts.) Then follows a less detailed treatment of the remaining material and, finally, some musings on the textbook.
Multiclass Prediction
For this chapter, we're back in the realm of supervised learning.
Previously in this sequence, we've looked at binary classification (where ) and regression (where ). In multiclass prediction or multiclass categorization, we have but . For simplicity, we take the next simplest case, i.e., . (Going up from there is straight-forward.) More specifically, consider the problem of recognizing dogs and cats in pictures, which we can model by setting . For the purposes of this chapter, we ignore the difficult question of how to represent the instance space .
We take the following approach:
- train a function to compute a score for each label that indicates how well the instance fits that label
- classify each new domain point as the best-fitting label
In our case, this means we are interested in learning a function of the form . Then, if we have
this translates into something like " kinda looks like a dog, but a little bit more like a cat, and it does seem to be some animal." Each such function determines a predictor via the rule .
We will restrict ourselves to linear predictors. I.e., we assume that the feature space is represented as something like and our predictors are based on hyperplanes.
With the setting established, the question is how to learn .
Approach 1: Reduction to Binary Classification
Suppose (unrealistically) that and our training data looks like this:
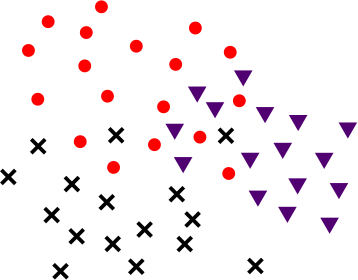
where

We could now train a separate scoring function for each label. Starting with cats, we would like a function that assigns each point a score based on how much it looks like a cat. For , the label corresponds to the label 1, whereas and both correspond to the label 0. In this setting, learning corresponds to finding a passable hyperplane. (Apply linear programming for Soft Support Vector Machines. [LW · GW])
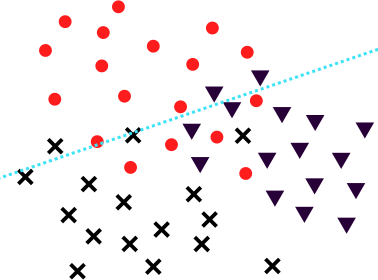
Note that, while hyperplanes are used to classify points, they do, in fact, produce a numerical score based on how far on the respective side each point is.
Next, we train a function. Perhaps its hyperplane looks like so:
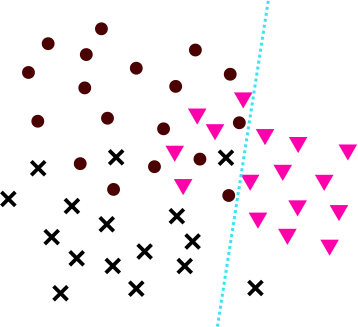
And, finally, a function in a similar fashion. Then, we define
And likewise with and . As before, we let .
Note that a point might be classified correctly, even if it is on the wrong side of the respective hyperplane. For example, consider this point:
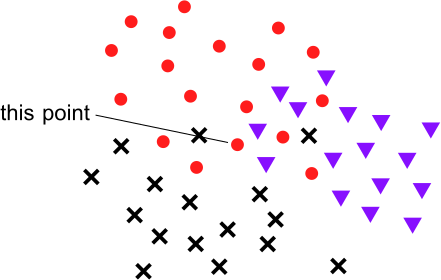
thought this point was not a cat, but it thought it less intensely than thought that it was not a dog. Thus, depending on 's verdict, the that computes might still put out a cat label. Of course, the reverse is also true – a point might be classified as a cat by but also as a dog by , and if the dog classification is more confident, the will pick that as the label.
The reduction approach is also possible with predictors that merely put out a binary yes/no. However, numerical scores are preferable, precisely because of cases like the above. If we had used classifiers only, then for and we could do no better than to guess.
While the reduction approach can work, it won't have the best performance in practice, so we look for alternatives.
Approach 2: Linear Programming
Using the fact that we are in the linear setting, we can rephrase our problem as follows: let , then we wish to find three vectors such that, for all training points , we have for all . In words: for each training point, the inner product with the vector measuring the similarity to the correct label needs to be larger than the inner product with the other vectors (in this case, the 2 others). This can be phrased as a linear program in much the same way as for Support Vector Machines (post VIII [LW · GW]).
However, it only works if such vectors exist. In practice, this is only going to be the case if the dimension is extremely large.
Approach 3: Surrogate Loss and Stochastic Gradient Descent
A general trick I first mentioned in post V [LW · GW] is to apply Stochastic Gradient Descent (post VI [LW · GW]) with respect to a surrogate loss function (i.e., a loss function that is convex and upper-bounds the first loss). In more detail (but still only sketched), this means we
- represent the class of hypotheses as a familiar set (easy for hyperplanes)
- for each labeled data point in our training sequence , construct the point-based loss function
- construct convex point-based loss functions such that
- compute the gradients and update our hypothesis step by step, i.e., set .
To do this, we have to change the framing somewhat. Rather than measuring the loss of our function (or of the predictor ), we would like to analyze the loss of a vector for some . However, we do not want to change our high-level approach: we still wish to evaluate all pairs and and separately.
This can be done by the following construction. Let be the number of coordinates that we use for each label, i.e., . We can "expand" this space to and consider it to hold three copies of each data point. Formally, we define the function by and and , where is the vector consisting of many zeros. Then we can represent all parts of our function as a single vector . If we take the inner product , it will only apply the part of that deals with the dog label since the other parts of are all 0s.
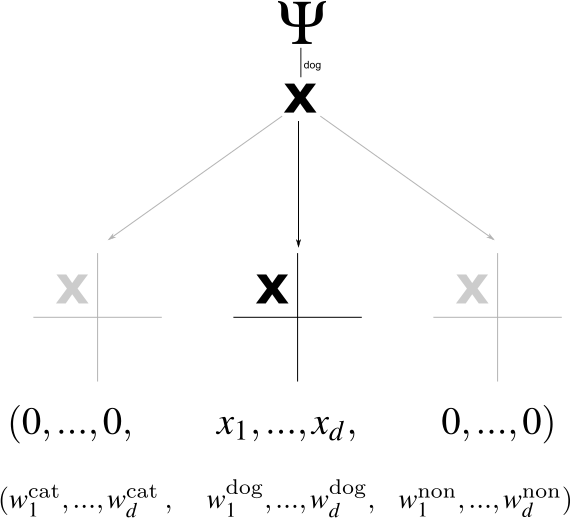
Thus, what was previously is now . The nontrivial information that was previously encoded in is now encoded in . Our predictor (which is fully determined by ) follows the rule . Thus, we still assign to each point the label for which it received the highest score. Note that makes use of all coordinates; there's no repetition.
Now we need to define loss functions. Since our goal is to apply Stochastic Gradient Descent, we focus on point-based loss functions that measure the performance of on the point only. (We write fat now since we specified that it's a vector.) One possible choice is the generalized 0-1 loss, that is 1 iff assigns the wrong label and 0 otherwise. However, this choice may not be optimal: if an image contains a cat, we probably prefer the predictor claiming it contains a dog to it claiming it doesn't contain any animal. Therefore, we might wish to define a function that measures how different two labels are. Then, we set . The function should by symmetric and non-negative, and it should be the case that . For our example, a reasonable choice could be
The loss function as defined above is non-convex: if and output different labels on , they will have different losses, which means that somewhere on the straight line between and , the loss makes a sudden jump (and sudden jumps make a function non-convex [LW · GW]). Thus, our goal now is to construct a convex loss function such that, for each in the training sequence, upper-bounds .
To this end, consider the term
for any point . Recall that the predictor chooses its label precisely in such a way that the above inner product is maximized. It follows that the term above is non-negative. (It's 0 for ). Therefore, adding this term to our loss will upper-bond the original loss. We obtain
This term penalizes for (1) the difference between the predicted and the correct label; and (2) the difference between 's score for the predicted and the correct label. This would be a questionable improvement – we now punish twice for essentially the same mistake. But the term above is only an intermediate step. Now, instead of using in the term above, we can take the maximum over all possible labels ; clearly, this will not make the term any smaller. The resulting term will define our loss function. I.e.:
Note that, unlike before, the difference between the two inner products may be negative.
Let's think about what these two equations mean (referring two the two centered equations, let's call them E1 and E2). E1 (the former) punishes in terms of the correct label and the label which guessed: it looks both at how far its prediction is off and how wrong the label is. E2 does the same for , so it will always put out at least as high of an error. However, E2 also looks at all the other labels. To illustrate the effect of this, suppose that the correct label is , but guessed . The comparison of the correct label to the guessed label (corresponding to ) will yield an error of 0.2 (for the difference between both labels) plus the difference between 's score for both (which is inevitably positive since it guessed ). Let's say and , then the difference is another 0.3 and the total error comes out .
Now consider the term for . Suppose ; in that case, did think was a more likely label than , but only by 0.2. Therefore, . This is a negative term, which means it will be subtracted from the error. However, the loss function "expects" a difference of 1, because that's the difference between the labels and . Thus, the full term for comes out at , which is higher than for .
(Meanwhile, the trivial case of – i.e., comparing the correct label to itself – always yields an error of 0.)
Alas, the loss function ends up scolding the most not for the (slightly) wrong label it actually put out, but for the (very) wrong label it almost put out. This might be reasonable behavior, although it certainly requires that the numerical scores are meaningful. In any case, note that the primary point of formulating the point-based loss functions was to have it be convex, so even if the resulting function were less meaningful, this might be an acceptable price to pay. (To see that it is, in fact, convex, simply note that it is the maximum of a set of linear functions.)
With this loss function constructed, applying Stochastic Gradient Descent is easy. We start with some random weight vector . At step , we take and the labeled training point . Consider the term
The gradient of the maximum of a bunch of functions is the maximum of their gradients. Thus, if is the label for which the above is maximal, then
Therefore, our update rule is .
Remaining Material
Now we get to the stuff that I read at least partially but decided to cover in less detail.
Naive Bayes Classifier
Naive Bayes is a simple type of classifier that can be used for specific categorization tasks (supervised learning), both binary classification and multi-classification but not regression. The "naive" does not imply that Bayes is naive; instead, it is naive and uses Bayes' rule.
We usually frame our goal in terms of wanting to learn a function . However, we can alternatively ask to learn the conditional probability distribution . If we know this probability – i.e., the probability of observing a (point, label) pair once we see the point – it is easy to predict new points.
For the rest of this section, we'll write "probability" as rather than , and we'll write rather than .
Now. For any pair , we can express in terms of and and using Bayes' rule. This implies that knowing all the is sufficient to estimate any (the priors on and are generally not an issue). The difficulty is that is usually infinite and we only have access to some finite training sequence .
For this reason, Naive Bayes will only be applicable to certain types of problems. One of them, which will be our running example, is document classification in the bag of words model. Here, where is the number of words in our dictionary, and each document is represented as a vector . where bit indicates whether or not the -th word of our dictionary appears in [the document represented by ]. Thus, we throw away order and repetitions but keep everything else. Furthermore, is a set of possible topics, and the goal is to learn a predictor that sees a new document and assigns it a topic.
The crucial property of this example is that each coordinate of our vectors is very simple. On the other hand, the vectors themselves are not simple: we have (number of words in the dictionary), which means we have about parameters to learn (all ). The solution is the "naive" part: we assume that all feature coordinates are independent so that . This assumption is, of course, incorrect: the probabilities for and are certainly not independent. But an imperfect model can still make reasonable predictions.
Thus, naive Bayes works by estimating the parameters for any and . If consists of 100 possible topics, then we wish to estimate parameters, which may be feasible.
Given a labeled document collection (the training sequence ), estimating these parameters is now both simple and fast, which is the major strength of Naive Bayes. In fact, it is the fastest possible predictor in the sense that each training point only has to be checked once. Note that is the probability of encountering word in a document about topic . For example, it could be the probability of encountering the word "Deipnophobia" (fear of dinner parties) in a document about sports. To estimate this probability, we read through all documents about sport in our collection and keep track of how many of them contain this term (spoilers: it's zero). On that basis, we estimate that
Why the ? Well, as this example illustrates, the natural estimate will often be 0. However, a 0 as our estimate will mean that any document which contains this word has no chance to be classified as a sports document (see equations below), which seems overkill. Hence we "smooth" the estimate by the .
Small tangent: I think it's worth thinking about why this problem occurs. Why isn't the computed value our best guess? It's not because there's anything wrong with Bayesian updating – actually the opposite. While the output rule is Bayesian, the parameter estimation, as described above, is not. A Bayesian parameter estimation would have a prior on the value of , and this prior would be updated upon computing the above fraction. In particular, it would never go to 0. But, of course, the simple frequentist guess makes the model vastly more practical.
Now suppose we have all these parameters. Given an unknown document , we would like to output a document in the set . For each , we can write
where we got rid of the term because it won't change the ; it doesn't matter how likely it was to encounter our new document, and it will be the same no matter which topic we consider.
Now kicks in the naivety: we will choose a topic in the set
This is all stuff we can compute – we can estimate the prior based on our document collection, and the remaining probabilities are precisely our parameters.
In practice, one uses a slightly more sophisticated way to estimate parameters (taking into account repetitions). One also smoothes slightly differently (smoothing is the +1 step) and maps everything into log space so that the values don't get absurdly small, and we can add probabilities rather than multiplying them. Nonetheless, the important ideas are intact.
Feature Selection
Every learning problem can be divided into two steps, namely
- (1) Feature Selection
- (2) Learning
This is true even in the case of unsupervised learning or online learning: before applying clustering algorithms onto a data set, one needs to choose a representation.
The respective chapter in the book does not describe how to select initial features, only how, given a (potentially large) set of features, to choose a subset . The approaches are fairly straight-forward:
- Measure the effectiveness of each feature by training a predictor based on that feature only; pick the best ones (local scoring)
- Start with an empty set of features, i.e., . In step , for each , test the performance of a predictor trained on . Choose to be the feature maximizing the performance, and set (greedy selection)
- Start with the full set of features, i.e., . In each step, drop one feature such that the loss in performance is minimal
It's worth pointing out that greedy selection can be highly ineffective since features and could be useless on their own but work well together. For an absurdly contrived example, suppose that , i.e., the target value is the sum of both features modulo some prime number . In that case, if and are uniformly distributed, and knowing either one of them is zero information about the target value. Nonetheless, both taken together determine the target value exactly.
(This example is derived from cryptography: splitting a number into additive parts modulo some fixed prime number is called secret sharing. The idea is that all shares are required to reconstruct the secret, but any subset of shares is useless. For example, if and all are uniformly distributed, then and are independently distributed (both uniform), and ditto with and . This remains true for an arbitrary number of shares. In general, Machine Learning and cryptography have an interesting relationship: the former is about learning information, the second about hiding information, i.e., making learning impossible. That's why cryptography can be a source of negative examples for Machine Learning algorithms.)
In this particular case, even the greedy algorithm wouldn't end up with features and since it has no motivation to pick up either of them to begin with – but the third approach would keep them both. On the other hand, if is useful on its own but only in combination with , then the local scoring approach would at best choose , while the greedy algorithm might end up with both. And, of course, it is also possible to construct examples where the third approach fails. Suppose we have 10 features that all heavily depend on each other. Together, they add more than one feature typically does but not ten times as much, so they're not worth keeping. Local scoring and greedy selection won't bother, but the third approach will be such with them: getting rid of one would worsen performance by too much.
Regularization and Stability
This is a difficult chapter that I've read partially but skipped entirely in this sequence.
The idea of regularization is as follows: suppose we can represent our hypotheses as vectors , i.e., . Instead of minimizing the empirical loss , we minimize the regularized empirical loss defined as
where is a regularization function. A common choice is for some parameter . In that case, we wish to minimize a term of the form . This approach is called Regularized Loss Minimization. There are at least two reasons for doing this. One is that the presence of the regularization function makes the problem easier. The other is that, if the norm of a hypothesis is a measure for its complexity, choosing a predictor with a small norm might be desirable. In fact, you might recall [LW · GW] the Structural Risk Minimization paradigm, where we defined a sequence of hypothesis classes such that . If we let , then both Structural Risk Minimization and Regularized Loss Minimization privilege predictors with smaller norm. The difference is merely that the tradeoff is continuous (rather than step-wise) in the case of Regularized Loss Minimization.
The problem
where is the squared loss can be solved with linear algebra – it comes down to inverting a matrix, where the term ensures that it is always invertible.
Generative Models
Recall the general model for supervised learning: we have the domain set , the target set , and the probability distribution over that generates the labels. Our goal is to learn a predictor .
It took me reaching this chapter to realize that this goal is not entirely obvious. While the function is generally going to be the most interesting thing, it is also conceivable to be interested in the full distribution . In particular, even if the best predictor is known (that's the predictor given by ), one still doesn't know how likely each domain point is to appear. Differently put, the probability distribution over is information separate from the predictor; it's neither necessary nor sufficient for finding one.
The idea of generative models is to attempt to estimate the distribution directly. A way to motivate this is by Tegmark et. al.'s observation that the process that generates labeled points often has a vastly simpler description than the points themselves (chapter 2.3 of post X [LW · GW]). This view suggests that estimating could actually be easier than learning the predictor . (Although not literally since learning implies learning the best predictor .)
The book has Naive Bayes as part of this chapter, even though it only involves estimating the , not the probability distribution over .
Advanced Theory
The book is structured in four parts. The first is about the fundamentals, which I covered in posts I-III. The second and third are about learning models, which I largely covered in posts IV-XIV. If there is a meaningful distinction between parts two and three, it's lost on me – they don't seem to be increasing in difficulty, and I found both easier than part one. However, the fourth part, which is titled advanced theory, is noticeably harder – too difficult for me to cover it at one post per week.
Here's a list of its chapters:
- Rademacher Complexities, which is an advanced theory studying the rate at which training sequences become representative (closely related to the concept of uniform convergence from post III).
- Covering numbers, a related concept, about bounding the complexity of sets
- Proofs for the sample complexity bounds in the quantitative version of the fundamental theorem of statistical learning (I've mentioned those a couple of times in this sequence)
- Some theory on the learnability of multiclass prediction problems, including another off-shoot of the VC-dimension.
- Compression Bounds, which is about establishing yet another criterion for the learnability of classes: if "a learning algorithm can express the output hypothesis using a small subset of the training set, then the error of the hypothesis on the rest of the examples estimates its true error."
- PAC-Bayes, which is another learning approach
Closing Thoughts on the Book
I've mentioned before that, while Understanding Machine Learning is the best resource on the subject I've seen so far, it feels weaker than various other textbooks I've tried from Miri's list. Part one is pretty good – it actually starts from the beginning, it's actually rigorous, and it's reasonably well explained. Parts two and are mixed. Some chapters are good. Others are quite bad. Occasionally, I felt the familiar sense of annoyance-at-how-anyone-could-possibly-think-this-was-the-best-way-explain-this-concept that I get all the time reading academic papers very rarely with Miri-recommended textbooks. It feels a bit like the authors identified a problem (no good textbooks that offer a comprehensive theoretical treatment of the field), worked on a solution, but lost inspiration somewhere on the way and ended up producing several chapters that feel rather uninspired. The one on neural networks is a good example.
(Before bashing the book some more, I should note that the critically acclaimed Elements of Statistical Learning made me angry immediately when I tried to read it – point being, I appear to be unusually hard to please.)
The exercises are lacking throughout. I think the goal of exercises should be to help me internalize the concepts of the respective chapter, and they didn't really do that. It seems that the motivation for them was often "let's offload the proof of this lemma into the exercises to save space" or "here's another interesting thing we didn't get to cover, let's make it an exercise." (Note that there's nothing wrong with offloading the proof of a lemma to exercises per se, they can be perfectly fine, but they're not automatically fine.) Conversely, in Topology, the first exercises of each sub-chapter usually felt like "let's make sure you understood the definitions" and the later ones like "let's make sure you get some real practice with these concepts," which seems much better. Admittedly, it's probably more challenging to design exercises for Machine Learning than it is for a purely mathematical topic. Nonetheless, I think they could be improved dramatically.
Next up (but not anytime soon) are -calculus and Category theory.
1 comments
Comments sorted by top scores.
comment by [deleted] · 2020-07-09T22:08:27.596Z · LW(p) · GW(p)
I've been working through the textbook as well. I know I've commented a few times before, but, once again, thanks for writing up your thoughts for each chapter. They've been useful for summarizing / checking my own understanding.