AI#28: Watching and Waiting
post by Zvi · 2023-09-07T17:20:10.559Z · LW · GW · 14 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved Introducing UK Taskforce Update In Other AI News Quiet Speculations The Quest for Sane Regulations The Week in Audio Rhetorical Innovation No One Would Be So Stupid As To Aligning a Smarter Than Human Intelligence is Difficult Twitter Community Notes Notes People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 14 comments
We are, as Tyler Cowen has noted, in a bit of a lull. Those of us ahead of the curve have gotten used to GPT-4 and Claude-2 and MidJourney. Functionality and integration are expanding, but on a relatively slow pace. Most people remain blissfully unaware, allowing me to try out new explanations on them tabula rosa, and many others say it was all hype. Which they will keep saying, until something forces them not to, most likely Gemini, although it is worth noting the skepticism I am seeing regarding Gemini in 2023 (only 25% for Google to have the best model by end of year) or even in 2024 (only 41% to happen even by end of next year.)
I see this as part of a pattern of continuing good news. While we have a long way to go and very much face impossible problems, the discourse and Overton windows and awareness and understanding of the real problems have continuously improved in the past half year. Alignment interest and funding is growing rapidly, in and out of the major labs. Mundane utility has also steadily improved, with benefits dwarfing costs, and the mundane harms so far proving much lighter than almost anyone expected from the techs available. Capabilities are advancing at a rapid and alarming pace, but less rapidly and less alarmingly than I expected.
This week’s highlights include an update on the UK taskforce and an interview with Suleyman of Inflection AI.
We’re on a roll. Let’s keep it up.
Even if this week’s mundane utility is of, shall we say, questionable utility.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. It’s got its eye on you.
- Language Models Don’t Offer Mundane Utility. Google search ruined forever.
- Deepfaketown and Botpocalypse Soon. I’ll pass, thanks.
- They Took Our Jobs. Better to not work in a biased way than not work at all?
- Get Involved. Center for AI Policy and Rethink Priorities.
- Introducing. Oh great, another competing subscription service.
- UK Taskforce Update. Impressive team moving fast.
- In Other AI News. AIs engage in deception, you say? Fooled me.
- Quiet Speculations. Copyright law may be about to turn ugly.
- The Quest for Sane Regulation. The full Schumer meeting list.
- The Week in Audio. Suleyman on 80k, Altman, Schmidt and several others.
- Rhetorical Innovation. Several more ways not to communicate.
- No One Would Be So Stupid As To. Maximally autonomous DeepMind agents.
- Aligning a Smarter Than Human Intelligence is Difficult. Easier to prove safety?
- Twitter Community Notes Notes. Vitalik asks how it is so consistently good.
- People Are Worried About AI Killing Everyone. Their worry level is slowly rising.
- Other People Are Not As Worried About AI Killing Everyone. Tyler Cowen again.
- The Lighter Side. Roon’s got the beat.
Language Models Offer Mundane Utility
Do automatic chat moderation for Call of Duty. Given that the practical alternatives are that many games have zero chat and the others have chat filled with the most vile assembly of scum and villainy, I am less on the side of ‘new dystopian hellscape’ as much as ‘what exactly is the better alternative here.’
Monitor your employees and customers.
Rowan Cheung: Meet the new AI Coffee Shop boss. It can track how productive baristas are and how much time customers spend in the shop. We’re headed into wild times.
Fofr: This is horrible in so many ways.

It’s not the tool, it is how you use it. Already some companies such as JPMorgan Chase use highly toxic dystopian monitoring tools, which lets them take to the next level. It seems highly useful to keep track of how long customers have been in the store, or whether they are repeat customers and how long they wait for orders. Tracking productivity in broad terms like orders filled is a case where too much precision and attention has big problems but so does not having enough. Much better an objective answer with no work than a biased error-prone answer with lots of work.
Monitor your citizens on social media (below is the entire post).
Dissclose.tv: US Special Operations Command (USSOCOM) has contracted Accrete AI to deploy software that detects “real time” disinformation threats on social media.
This seems like exactly what such folks were doing before? The problem here isn’t AI.
Win a physical sport against humans for the first time, I am sure it is nothing, the sport is (checks notes) drone racing.
Get help with aspects of writing. As Parell notes, directly asking ChatGPT to help you write is useless, but it can be great as a personal librarian and thing explainer. He recommends the term ‘say more,’ asking for restatements in the styles of various authors and for summaries, talking back and forth and always being as specific as possible, and having the program check for typos.
Ethan Mollick proposes developing what he calls Grimoires, which my brain wants to autocorrect to spellbooks (a term he uses as well), prompts designed to optimize the interaction, including giving the AI a role, goal, step-by-step instructions, probably a request for examples and to have the AI gather necessary context from the user.
Play the game of Hoodwinked, similar to Mafia or Among Us. More capable models, as one would expect, outperform less capable ones, and frequently lie and deceive as per the way the game is played. The proper strategy in such games for humans is usually, if you can, some variant of saying whatever you would have said if you were innocent, which presumably is pretty easy to get an LLM to do. Note that as the LLM gets smarter, other strategies become superior, followed by other strategies that humans couldn’t pull off, followed by strategies humans haven’t even considered.
Language Models Don’t Offer Mundane Utility
Beware of AI-generated garbage articles, many say, although I still have yet to actually encounter one. Ryan is correct here, Rohit also, although neither solves the issue.
Paul Graham: I’m looking up a topic online (how hot a pizza oven should be) and I’ve noticed I’m looking at the dates of the articles to try to find stuff that isn’t AI-generated SEO-bait.
Ryan Peterson: Hotter the better Paul!
Rohit: Seems to be ok with generative search now? Unless, yes, you wanted to dig much deeper into something very much more specific? [shows Google’s response.]
Here is one of several other claims I saw this week that Google search is getting rapidly polluted by LLM-generated garbage.
Beware even looking at AI when Steam (Valve) is involved, they remove a game permanently for once allowing a mod that lets characters use GPT-generated dialogue, even though the mod was then removed. While I do admire when one does fully commit to the bit, this is very obviously taking things way too far, and I hope Valve realizes this and reverses their decision.
Judge Roy Ferguson asks Claude who he is, gets into numerous cycles of fabricated information and Claude apologizing and admitting it fabricated information. Definitely a problem. Ferguson treats this as ‘intentional’ on the part of Claude, which I believe is a misunderstanding of how LLMs work.
Deepfaketown and Botpocalypse Soon
So far, Donald Trump has had the best uses of deepfakes in politics. Do they inevitably favor someone of his talents? Another angle to consider is, who is more vulnerable to such tactics than trump supporters?
Astrid Wilde: Increasingly have noticed more and more sophisticated AI spoofing attacks targeted at Trump supporters. this attack was convincing enough to even get air time. someone with the speaking cadence of @michaelmalice is spoofing Trump’s voice with AI here. it’s a Brave New World. It’s also possible that RAV themselves was behind the spoof, but impossible to know. Absolutely wild times
I checked r/scams on a whim about 40 posts deep. Almost all were old school, one of them was a report of the classic ‘your child has been arrested and you must send bail money’ scam. The replies refused to believe it was an actual deepfake, saying it was a normal fake voice. It seems even the scam experts don’t realize how easy it is to do a deepfake now, or alternatively they are so used to everything being a scam (because if you have to ask, I have some news) that they assume deepfakes must be a scam too?
Worth noting that the scam attempt failed. We keep hearing ‘I almost fell for it’ and keep not hearing from anyone who actually lost money.
The self-explanatory and for now deeply disappointing ‘smashOrPass.ai’ offers the latest in user motivation for fine tuning, whatever one might think of the ethics involved. As of this writing it is only a small set of images on a loop, so claims that it ‘learns what you like’ seem rather silly, but that is easily fixed. What is less easily fixed is all the confounders, which this should illustrate nicely. This is a perfect illustration of how much data is lost when you compress to a 0-1 scale, also either people adjust for context or don’t and either approach will be highly confusing, you really need 0-10 here. And yes, in case anyone was wondering, of course the porn version is coming soon, if not from him than someone else. More interestingly, how long until the version where it takes this information and uses it to auto-swipe on dating app profiles for you?
Also, can I give everyone who hates this, or anything else on the internet, the obvious advice? For example, Vice’s Janus Rose? Do not highlight things no one would otherwise have heard of, in order to complain about them. This thing came to my attention entirely due to negative publicity.
Recreation of James Dean to star in new movie. No doubt more of this is coming. What is weird is that people are talking about cloning great actors, including great voice actors, whether dead or otherwise, and using this to drive living actors out of work.
The problem with using AI is that AI is not a good actor.
An AI voice actor can copy the voice of Mel Brooks, but the voice has little to do with what makes Mel Brooks great. What I presume you would actually do, at least for a while, is to have some great voice actor record the new lines. Then use AI to transform the new lines to infuse it with the vocal stylings of Mel Brooks.
If we have Tom Hanks or Susan Sarandon (both quoted in OP) doing work after they die, then we are choosing to recreate their image and voice, without the ability to copy their actual talents or skills. To the extent that we get a ‘good performance’ out of them, we could have gotten that performance using anyone with enough recorded data as a baseline, such as Your Mom, or a gorgeous fashion model who absolutely cannot act. It makes sense to use this for sequels when someone dies, and continuity takes priority, but presumably the actors of the future will be those with The Look? Thus James Dean makes sense, or Marylin Monroe. Or someone whose presence is importantly symbolic.
They Took Our Jobs
AI detection tools do not work. We know this. Now we have data on one way they do not work, which is by flagging the work of non-native English speakers at Stanford.

AI detectors tend to be programmed to flag writing as AI-generated when the word choice is predictable and the sentences are more simple. As it turns out, writing by non-native English speakers often fits this pattern, and therein lies the problem.
The problem is that the test does not work. This is an illustration that the test does not work. That it happens to hit non-native speakers illustrates how pathetic are our current attempts at detection.
The AIs we were training on this were misaligned. They noticed that word complexity was a statistically effective proxy in their training data, so they maximized their score as best they could. Could one generate a bespoke training set without this correlation and then try again? Perhaps one could, but I would expect many cycles of this will be necessary before we get something that one can use.
If anything, this discrimination makes the AI detector more useful rather than less useful. By concentrating its errors in a particular place and with a testable explanation, you can exclude many of its errors. It can’t discriminate against non-native speakers if you never use it on their work.
It also shows an easy way AI work can be disguised, using complexity of word choice.
Get Involved
The Center for AI Policy is a new organization developing and advocating for policy to mitigate catastrophic risks from advanced AI. They’re hiring an AI Policy Analyst and a Communications Director. They recently proposed the Responsible AI Act, which needs refinement in spots but was very good to propose, as it is a concrete proposal moving things in productive directions. Learn more and apply here.
Rethink Priorities doing incubation for AI safety efforts, including field building in universities for AI policy careers. Do be skeptical of the plan of an incubation center for a project to help incubate people for future projects. I get how the math in theory works, still most people doing something must ultimately be doing the thing directly or no thing will get done.
Introducing
Time introduced the Time 100 for AI. I’d look into it but for now I see our time is up.
Claude Pro from Anthropic, pay $20/month for higher bandwidth and priority. I have never run up against the usage limit for Claude, despite finding it highly useful – my conversations tend to be relatively short, the only thing I do that would be expensive is attaching huge PDFs, which they say shrinks the limits but I’ve yet to run into any problems. It is a good note that, when using such attachments, it is efficient to ask for a small number of extensive answers rather than a large number of small ones.
Falcon 180B, HuggingFace says it is a ever so slightly better model than Llama-2, which makes it worse relative to its scale and cost. They say it is ‘somewhere between GPT-3.5 and GPT-4’ on the evaluation benchmarks, I continue to presume that in practical usage it will remain below 3.5.
OpenAI will host developer conference November 6 in San Francisco.
Sam Altman: on november 6, we’ll have some great stuff to show developers! (no gpt-5 or 4.5 or anything like that, calm down, but still I think people will be very happy…)
Automorphic (a YC ‘23 company) offers train-as-you-go fine tuning, including continuous RLHF, using as little has a handful of examples, offers fine tuning of your first three models free. Definitely something that should exist, no idea if they have delivered the goods, anyone try it out?
UK Taskforce Update
Update on the UK Foundation Model Taskforce from Ian Hogarth (direct). Advisory board looks top notch, including Bengio and Christiano plus Sommeren for national security expertise. They are partnering with ARC Evals, the Center for AI Safety and others. The summit is fast approaching in November, so everything is moving quickly. They are expanding rapidly, and very much still hiring.
Ian Hogarth: Sam Altman, CEO of OpenAI, recently suggested that the public sector had a “lack of will” to lead on innovation, asking “Why don’t you ask the government why they aren’t doing these things, isn’t that the horrible part?”
We have an abundance of will to transform state capacity at the frontier of AI Safety. This is why we are hiring technical AI experts into government at start-up speed. We are drawing on world-leading expertise.
…
Our team now includes researchers with experience from DeepMind, Microsoft, Redwood Research, The Center for AI Safety and the Center for Human Compatible AI.
These are some of the hardest people to hire in the world. They have chosen to come into public service not because it’s easy, but because it offers the opportunity to fundamentally alter society’s approach to tackling risks at the frontier of AI.
We are rapidly expanding this team and are looking for researchers with an interest in catalyzing state capacity in AI Safety. We plan to scale up the team by another order of magnitude. Please consider applying to join us here.
With the first ever AI Safety Summit in the UK on 1 and 2 November, this is a critical moment to influence AI Safety. We are particularly focused on AI researchers with an interest in technical risk assessments of frontier models.
…
Moving fast matters. Getting this much done in 11 weeks in government from a standing start has taken a forceful effort from an incredible team of dedicated and brilliant civil servants. Building that team has been as important as the technical team mentioned above.
This is why we’ve brought in Ollie Ilott as the Director for the Taskforce. Ollie joins us from Downing Street, where he led the Prime Minister’s domestic private office, in a critical role known as “Deputy Principal Private Secretary”
He is known ‘across the piece’ for his ability to recruit and shape best-in-class teams. Before joining the Prime Minister’s office, Ollie ran the Cabinet Office’s COVID strategy team in the first year of the pandemic and led teams involved in Brexit negotiations.
In Other AI News
New paper from Peter S. Park, Simon Goldstein, Aidan O’Gara, Michael Chen, Dan Hendrycks: AI Deception: A Survey of Examples, Risks, and Potential Solutions.
Here is the abstract:
This paper argues that a range of current AI systems have learned how to deceive humans. We define deception as the systematic inducement of false beliefs in the pursuit of some outcome other than the truth.
We first survey empirical examples of AI deception, discussing both special-use AI systems (including Meta’s CICERO) built for specific competitive situations, and general-purpose AI systems (such as large language models).
Next, we detail several risks from AI deception, such as fraud, election tampering, and losing control of AI systems.
Finally, we outline several potential solutions to the problems posed by AI deception: first, regulatory frameworks should subject AI systems that are capable of deception to robust risk-assessment requirements; second, policymakers should implement bot-or-not laws; and finally, policymakers should prioritize the funding of relevant research, including tools to detect AI deception and to make AI systems less deceptive. Policymakers, researchers, and the broader public should work proactively to prevent AI deception from destabilizing the shared foundations of our society.
They do a good job of pointing out that whatever your central case of what counts as deception, there is a good chance we already have a good example of AIs doing that. LLMs are often involved. There is no reason to think deception does not come naturally to optimizing AI systems when it would be a useful thing to do. Sometimes it is intentional or predicted, other times it was unintended and happened anyway, including sometimes with the AI’s explicit intent or plan to do so.
New paper from Owain Evans tests potential situational awareness of LLMs (paper).
Owain Evans: Our experiment:
1. Finetune an LLM on descriptions of fictional chatbots but with no example transcripts (i.e. only declarative facts).
2. At test time, see if the LLM can behave like the chatbots zero-shot. Can the LLM go from declarative → procedural info?
Surprising result:
1. With standard finetuning setup, LLMs fail to go from declarative to procedural info.
2. If we add paraphrases of declarative facts to the finetuning set, then LLMs succeed and improve with scale.
I am not as surprised as Owain was, this all makes sense to me. I still find it interesting and I’m glad it was tried. I am not sure what updates to make in response.
Twitter privacy policy now warns it can use your data to train AI models. Which they were going to do anyway, if anything Elon Musk is focusing on not letting anyone else do this.
Jorbs: Nonsense posts and nonsense art are functional anti-capitalist art now, which is kinda cool.
Chip restrictions expand to parts of the Middle East. How do you keep chips out of China without keeping them out of places that would allow China to buy the chips?
Good Time article from Walter Isaacson chronicling the tragedy and cautionary tale of Elon Musk, who Demis Hassabis warned about the dangers of AI, and who then completely misunderstood what would be helpful and as a result made things infinitely worse. He continues to do what feels right to him, and continues to not understand what would make it more versus less likely we all don’t die. It is not without a lot of risk, but we should continue trying to be helpful in building up his map, and try to get him to talk to Eliezer Yudkowsky or other experts in private curious mode if we can. Needless to say, Elon, call any time, my door is always open.
Brief Twitter-post 101 explainer of fine tuning.
Quiet Speculations
Kate Hall, who has practiced copyright law, predicts that MidJourney, GPT and any other models trained on copyrighted material will be found to have violated copyright.
Kate Hall: Okay I’ve spent all of a few hours thinking about copyright infringement by generative AI (note I’ve practiced copyright law before) and the correct treatment seems kind of obvious to me, so I’d like someone to tell me what I’m missing since I know it’s hotly contested.
My bottom line conclusion: Courts will find generative AI violates copyright law. (One way I could be wrong is if I misperceive all systems as essentially following similar mechanics — I’m using OpenAI & Midjourney in my head when I’m modeling this.)
The system outputs (generated content) themselves mostly don’t violate copyright, I think. I see people arguing that the outputs are “derivative works” but I think that stretches the concept far beyond what courts would accept.
There may be exceptions where the outputs flagrantly copy parts of copyrighted works, but those cases aren’t the norm and I’d expect them to get rarer over time with new systems.
Making copies of copyrighted works to use in a training set w/o permission is, however, infringement, & AFAIK there’s no way to do training w/o making copies in the process. OpenAI seems to concede this but says it’s okay under the fair use doctrine.
But making copies for training sets isn’t fair use. If you just read through the factors, it might not be obvious why. But if you want to anticipate what a court will say, you need to look at the use in the context of copyright law.
The purpose of copyright law is to compensate ppl for creating new scientific & artistic works. If someone takes copyrighted material & uses it to generate content that *reduces demand for the original works* & profits from it, courts will find a reason it’s not fair use.
Against this, I’ve seen OAI argue that the training set copies are fair use anyway because no human is looking *at the training set* instead of consuming the original work — infringement & the creation of a substitute work happen at different steps.
This is too clever by half. It’s just not the kind of argument that works in copyright cases because the overall scheme is flagrantly contrary to the entire spirit of copyright law.
I’m guessing a court will reach that conclusion by saying the whole course of conduct & its effects should be considered in the fair use analysis, but maybe there is another way to get to the same conclusion. But AFAICT, it will be the conclusion. So, what am I missing?
This is a highly technical opinion, and relies on courts applying a typical set of heuristics to a highly unusual situation, so it seems far from certain. Also details potentially matter in weird ways.
Haus Cole: How much of this analysis hinges on the copying for training sets? If, theoretically, the training set was just a set of URLs and the systems “viewed” those URLs directly at training time, would that change the analysis materially?
Cate Hall: Yes, potentially — it would depend on the particulars of the system, but if no copy is ever made it’s a lot harder to see what the specific nature of the infringement is.
Josh Job: What is a “copy” in this context? Every computer copies everything every time it moves from storage to RAM or is accessed via a remote system to do any computation on. If the training set is a set of URLs at training time the systems have to download the url content to see it.
Cate Hall: In that case I don’t think the distinction matters — if there’s a copy made, even if transient, the same infringement analysis applies.
Presumably we can all agree that this rule does not make a whole lot of sense. Things could also take a while. Or it might not.
Smith Sam: Nothing at all in your analysis (it has played out as you predict in other places), but how long will all that take to litigate, and where do OAI think they’ll be by then? i.e. will the court decision be irrelevant to what they’re doing at the time the court decides?
Cate Hall: It’s a fair question but it really could go a lot of different ways. If SCOTUS, many years — but a district court could enter a preliminary injunction based on the likelihood of infringement while a case is litigated in no time at all. Luck of the draw with district judges.
Cate Hall’s position is in sharp contrast to OpenAI’s.
“Under the resulting judicial precedent, it is not an infringement to create ‘wholesale cop[ies] of [a work] as a preliminary step’ to develop a new, non-infringing product, even if the new product competes with the original,” OpenAI wrote.
The authors suing in the current copyright lawsuit do seem to be a bit overreaching?
The company’s motion to dismiss cited “a simple response to a question (e.g., ‘Yes’),” or responding with “the name of the President of the United States” or with “a paragraph describing the plot, themes, and significance of Homer’s The Iliad” as examples of why every single ChatGPT output cannot seriously be considered a derivative work under authors’ “legally infirm” theory.
Is generative AI in violation of copyright? Perhaps it is. Is it a ‘grift’ that merely repackages existing work, as the authors claim? No.
The US Copyright Office has opened a comment period. Their emphasis is on outputs
Emilia David at Verge: As announced in the Federal Register, the agency wants to answer three main questions: how AI models should use copyrighted data in training; whether AI-generated material can be copyrighted even without a human involved; and how copyright liability would work with AI. It also wants comments around AI possibly violating publicity rights but noted these are not technically copyright issues. The Copyright Office said if AI does mimic voices, likenesses, or art styles, it may impact state-mandated rules around publicity and unfair competition laws.
Arnold Kling sees the big seven tech stocks as highly overvalued. My portfolio disagrees on many of them. One mistake is these are global companies, so you should compare to world GDP of 96 trillion, not US GDP of 26 trillion, which makes an overall P/E of 50 seem highly reasonable, given how much of the economy is going to shift into AI.
Tyler Cowen says we are in an ‘AI lull’ with use leveling off and obvious advances stalled for a time, but transformational change is coming. I agree. He is excited by, and it seems not worried about, what he sees as unexpectedly rapid advancements in open source models. I am skeptical that they are doing so well, they systematically underperform their benchmark scores. In practice and as far as I can tell GPT-3.5 is still superior to every open source option.
Flo Crivello shortens their timelines.
Flo Crivello: Big breakthroughs are happening at every level in AI — hardware, optimizers, model architectures, and cognitive architectures. My timelines are shortening — 95% confidence interval is AGI is in 2-8 yrs, and super intelligence another 2-8 years afterwards. Buckle up.
I don’t see this as consistent. If you get AGI in 2-8 years, you get ASI in a lot less than 2-8 more years after that.
The Quest for Sane Regulations
Full list of people attending Schumer’s meeting.

The Week in Audio
The main audio event this week was Inflection AI CEO and DeepMind founder Mustafa Suleyman on the 80,000 hours podcast, giving us a much better idea where his head is at, although is it even an 80,000 hours podcast if it is under an hour?
Up front, I want to say that it’s great that he went on 80,000 hours and engaged for real with the questions. A lot of Suleyman’s thinking here is very good, and his openness is refreshing. I am going to be harsh in places on the overview list below, so I want to be clear that he is overall being super helpful and I want more of this.
I also got to see notes on Suleyman’s new book, The Coming Wave. The book and podcast are broadly consistent, with the main distinction being that the book is clearly aiming to be normie-friendly and conspicuously does not discuss extinction risks, even downplaying details of the less extreme downsides he emphasizes more.
- Wiblin opens asking about potential dangerous AI capabilities, since Suleyman has both said he thinks AI may be able to anonymously run a profitable company within 2 years, but also says it is unlikely to be dangerous within 10 years, which I agree seem like two facts that do not live in the same timeline. Suleyman clarifies that the AI would still need human help for various things along the way, but given humans can hired to do those things, I don’t see why that helps?
- Suleyman also clarifies that he is centrally distinguishing runaway intelligence explosions and recursive self-improvement from potential human use or misuse.
- Suleyman says he has uncertainty about timelines, in a way that makes it seem like he wants to wait for things to clearly be getting out of hand before we need to act?
- Suleyman disputes claim that is trivial to remove fine-tuning and alignment, later explaining it can be done but requires technical chops. I don’t see how that helps.
- Suleyman emphasizes that he is warning about open source, but still seems focused on this idea of human misuse and destructiveness. Similarly, he sees Llama-2’s danger as it revealing information already available on the web, whereas Anthropic says Claude was capable of importantly new synthesis of dangerous capabilities.
- “We’re going to be training models that are 1,000x larger than they currently are in the next three years. Even at Inflection, with the compute that we have, will be 100x larger than the current frontier models in the next 18 months.”
- Agreement (and I also mostly agree) that the issue with open sourcing Llama-2 is not that it will do much damage now, but the precedent it sets. My disagreement is that the 10-15 year timeline here for that transition seems far too slow.
- Anticipation of China being entirely denied the next generation of AI chips, and USA going on full economic war footing with China. As usual, I remind everyone that we don’t let Chinese AI (or other) talent move to America, so we cannot possibly care that much about winning this battle.
- Google’s attempt to have an oversight board with a diversity of viewpoints was derailed by cancel culture being unwilling to tolerate a diversity of viewpoints, so the whole thing fell apart entirely within weeks. No oversight, then, which Suleyman notes is what power wants anyway. As Wiblin notes, you can either give people in general a voice, or you can have all the voices be agreeing with what are considered correct views, but you cannot have both at once. We can say we want to give people a voice, but when they try to use it, we tell them they’re wrong.
- I would say here: Pointing out that they are indeed wrong does not help on this. There seems to clearly not be a ZOPA – a zone of possible agreement – on how to choose what AI will do, on either the population level or the national security level, if you need to get buy-in from China and the global south also the United States. I predict that (almost) everyone in the West who says ‘representativeness’ or even proposes coherent extrapolated volition would be horrified by what such a process would actually select.
- “The first part of the book mentions this idea of “pessimism aversion,” which is something that I’ve experienced my whole career; I’ve always felt like the weirdo in the corner who’s raising the alarm and saying, “Hold on a second, we have to be cautious.” Obviously lots of people listening to this podcast will probably be familiar with that, because we’re all a little bit more fringe. But certainly in Silicon Valley, that kind of thing… I get called a “decel” sometimes, which I actually had to look up.” Whereas from my perspective, he is quite the opposite. He founded DeepMind and Inflection AI, and says explicitly in his book that to be credible you must be building.
- “It’s funny, isn’t it? So people have this fear, particularly in the US, of pessimistic outlooks. I mean, the number of times people come to me like, “You seem to be quite pessimistic.” No, I just don’t think about things in this simplistic “Are you an optimist or are you a pessimist?” terrible framing. It’s BS. I’m neither. I’m just observing the facts as I see them, and I’m doing my best to share for critical public scrutiny what I see. If I’m wrong, rip it apart and let’s debate it — but let’s not lean into these biases either way.” Well said.
- “So in terms of things that I found productive in these conversations: frankly, the national security people are much more sober, and the way to get their head around things is to talk about misuse. They see things in terms of bad actors, non-state actors, threats to the nation-state.” Can confirm this. It is crazy the extent to which such people can literally only think in terms of a human adversary.
- More ‘in order to do safety you have to work to push the frontline of capabilities.’ Once again, I ask why it is somehow always both necessary and sufficient for everyone to work with the best model they can help develop, what a coincidence.
- Suleyman says the math on a $10 billion training run will not add up for at least five years, even if you started today it would take years to execute on that.
- Suleyman reiterates: “I’m not in the AGI intelligence explosion camp that thinks that just by developing models with these capabilities, suddenly it gets out of the box, deceives us, persuades us to go and get access to more resources, gets to inadvertently update its own goals. I think this kind of anthropomorphism is the wrong metaphor. I think it is a distraction. So the training run in itself, I don’t think is dangerous at that scale. I really don’t.” His concern is proliferation, so he’s not worried that Inflection AI is going to accelerate capabilities merely by pushing the frontiers of capabilities. Besides, if he didn’t do it, someone else would.
- Wiblin suggests “They’re going to do the thing that they’re going to do, just because they think it’s profitable for them. And if you held back on doing that training run, it wouldn’t shift their behavior.” Suleyman affirms. So your behavior won’t change anyone else’s behavior, and also everyone else’s behavior justifies yours. Got it.
- Affirms that yes, a much stronger version of current models would not be inherently dangerous, as per Wiblin “in order for it to be dangerous, we need to add other capabilities, like it acting in the world and having broader goals. And that’s like five, 10, 15, 20 years away.” Except, no. People turn these things into agents easily already, and they already contain goal-driven subagent processes.
- “I think everybody who is thinking about AI safety and is motivated by these concerns should be trying to operationalize their alignment intentions, their alignment goals. You have to actually make it in practice to prove that it’s possible, I think.” It is not clear the extent to which he is actually confusing aligning current models with what could align future models. Does he understand that these two are very different things? I see evidence in both directions, including some strong indications in the wrong direction.
- Claim that Pi (found at pi.ai) cannot be jailbroken or prompt hacked. Your move.
- Reminds us that Pi does not code or do many other things, it is narrowly designed to be an AI assistant. Wait, need my AI assistant to be able to help me write code.
- Reminds us that GPT-3.5 to GPT-4 was a 5x jump in resources.
- Strong candidate for scariest thing to hear such a person say they believe about alignment difficulty: “Well, it turns out that the larger they get, the better job we can do at aligning them and constraining them and getting them to produce extremely nuanced and precise behaviours. That’s actually a great story, because that’s exactly what we want: we want them to behave as intended, and I think that’s one of the capabilities that emerge as they get bigger.”
- On Anthropic: “I don’t think it’s true that they’re not attempting to be the first to train at scale. That’s not true… I don’t want to say anything bad, if that’s what they’ve said. But also, I think Sam [Altman] said recently they’re not training GPT-5. Come on. I don’t know. I think it’s better that we’re all just straight about it. That’s why we disclose the total amount of compute that we’ve got.”
- Endorses legal requirements for disclosure of model size, a framework for harmful capabilities measures, and not using these models for electioneering.
- I have no idea what that last one would even mean? He says ‘You shouldn’t be able to ask Pi who Pi would vote for, or what the difference is between these two candidates’ but that is an arbitrary cutout of information space. Are you going to refuse to answer any questions regarding questions relevant to any election? How is that not a very large percentage of all interesting questions? There’s a kind of myth of neutrality. And are you going to refuse to answer all questions about how one might be persuasive? All information about every issue in politics?
- Suleyman believes it is not tactically wise to discuss misalignment, deceptive alignment, or models having their own goals and getting out of control. He also previously made clear that this is a large part of his threat model. This is extra confirmation of the hypothesis that his book sidesteps these issues for tactical reasons, not because Suleyman disagrees on the dangers of such extinction risks.
It is perhaps worth contrasting this with this CNN interview with former Google ECO Eric Schmidt, who thinks recursive self-improvement and superintelligence are indeed coming soon and a big deal we need to handle properly or else, while also echoing many of Suleyman’s concerns.
There is also the video and transcript of the talks from the San Francisco Alignment Workshop from last February. Quite the lineup was present.
Jan Leike’s talk starts out by noting that RLHF will fail when human evaluation fails, although we disagree about what counts as failure here. Then he uses the example of bugs in code and using another AI to point them out and states his principle of evaluation being easier than generation. Post contra this hopefully coming soon.
Sam Altman recommends surrounding yourself with people who will raise your ambition, warns 98% of people will pull you back. Full interview on YouTube here.
Telling is that he says that most people are too worried about catastrophic risk, and not worried enough about chronic risk – they should be concerned they will waste their life without accomplishment, instead they worry about failure. I am very glad someone with this attitude is out there running all but one of Sam Altman’s companies and efforts, and most people in most places could use far more of this energy. The problem is that he happens to also be CEO of OpenAI, working on the one problem where catastrophic (existential) risk is quite central.
Also he says (22:25) “If we [build AGI at OpenAI] that will be more important than all the innovation in all of human history.” He is right. Let that sink in.
Paige Bailey, the project manager for Google’s PaLM-2, goes on Cognitive Revolution. This felt like an alternative universe interview, from a world in which Google’s AI efforts are going well, or OpenAI and Anthropic didn’t exist, in addition to there being no risks to consider. It is a joy to see her wonder and excitement at all the things AI is learning how to do, and her passion for making things better. The elephant in the room, which is not mentioned at all, is that all of Google’s Generative AI products are terrible. To what extent this is the ‘fault’ of PaLM-2 is unclear but presumably that is a big contributing factor. It’s not that Bard is not a highly useful tool, it’s that multiple other companies with far fewer resources have done so much better and Bard is not catching up at least pre-Gemini.
Risks are not mentioned at all, although it is hard to imagine Bailey is at all worried about extinction risks. She also doesn’t see any problem with Llama-2 and open source, citing it unprompted as a great resource, which also goes against incentives. Oh how much I want her to be right and the rest of us to live in her world. Alas, I do not believe this is the case. We will see what Gemini has to offer. If Google thinks everything is going fine, that is quite the bad sign.
Rhetorical Innovation
Perhaps a good short explanation in response here?
Richard Socher: The reason nobody is working on a self-aware AI setting its own goals (rather than blindly following a human-defined objective function) is that it makes no money. Most companies/governments have their own goals and prefer not to spend billions on an AI doing whatever it wants.
Eliezer Yudkowsky: When you optimize stuff on sufficiently complicated problems to the point where it starts to show intelligence that generalizes far beyond the original domains, a la humans, it tends to end up with a bunch of internal preferences not exactly correlated to the outer loss function, a la humans.
The point I was trying to make last week, not landing as intended.
Robert Wiblin: Yesterday I joked: “The only thing that stops a bad person with a highly capable ML model is a good government with a ubiquitous surveillance system.” I forgot to add what I thought was sufficiently obvious it didn’t need to be there: “AND THAT IS BAD.”
My point is that if you fail to limit access to WMDs at their source and instead distribute them out widely, you don’t create an explosion of explosion — rather you force the general public to demand massive government surveillance when they conclude that’s the only way to keep them safe. And again, to clarify, THAT IS BAD.
Exactly. We want to avoid ubiquitous surveillance, or minimize its impact. If there exists a sufficiently dangerous technology, that leaves you two choices.
- You can do what surveillance and enforcement is necessary to limit access.
- You can do what surveillance and enforcement is necessary to contain usage.
Which of these will violate freedom less? My strong prediction for AGI is the first one.
As a reminder, this assumes we fully solved the alignment problem in the first place. This is how we deal with the threat of human misuse or misalignment of AGI in spite of alignment being robustly solved in practice. If we haven’t yet solved alignment, then failing to limit access (either to zero people, or at least to a very highly boxed system treated like the potential threat that it would be) would mean we are all very dead no matter what.
No One Would Be So Stupid As To
Make Google DeepMind’s AIs as autonomous as possible.
Edward Grefenstette (Director of Research at DeepMind): I will be posting (probably next week) some job listings for a new team I’m hiring into at @GoogleDeepMind. I’ll be looking for some research scientists and engineers with a strong engineering background to help build increasingly autonomous language agents. Watch this space.
Melanie Mitchell: “to help build increasingly autonomous language agents”
Curious what you and others at DeepMind think about Yoshua Bengio’s argument that we should limit AI agents’ autonomy?
Edward: Short answer: I’m personally interested in initially investigating cases where (partial) autonomy involves human-in-the-loop validation during the downstream use case, as part of the normal mode of operation, both for safety and for further training signal.
a16z gives out grants for open source AI work, doing their best to proliferate as much as possible with as few constraints as possible. Given Marc Andreessen’s statements, this should come as no surprise.
Aligning a Smarter Than Human Intelligence is Difficult
We have a class for that now, at Princeton, technically a graduate seminar but undergraduates welcome. Everything they will read is online so lots of resources and links there and list seems excellent at a glance.
Max Tegmark and Steve Omohundo drop a new paper claiming provably safe systems are the only feasible path to controlling AGI, Davidad notes no substantive disagreements with his OAA plan.
Abstract: We describe a path to humanity safely thriving with powerful Artificial General Intelligences (AGIs) by building them to provably satisfy human-specified requirements. We argue that this will soon be technically feasible using advanced AI for formal verification and mechanistic interpretability. We further argue that it is the only path which guarantees safe controlled AGI. We end with a list of challenge problems whose solution would contribute to this positive outcome and invite readers to join in this work.
Jan Leike, head of alignment at OpenAI, relies heavily on the principle that verification is in general easier than generation. I strongly think this is importantly false in general for AI contexts. You need to approach having a flawless verifier, whereas the generator need not achieve that standard.
Proofs are the exception. The whole point of a proof is that it is easy to definitively verify. Relying only on that which you can prove is a heavy alignment tax, especially where the proof is in the math sense, not merely in the courtroom sense. If you can prove your system satisfies your requirements, and you can prove that your requirements satisfy your actual needs, you are all set.
The question is, can it be done? Can we build the future entirely out of things where we have proofs that they will do what we want, and not do the things we do not want?
That does seems super hard. The proposal here is to use AIs to discover proof-carrying code.
Proof-carrying code is a fundamental component in our approach. Developing it involves four basic challenges:
1. Discovering the required algorithms and knowledge
2. Creating the specification that generated code must satisfy
3. Generating code which meets the desired specification
4. Generating a proof that the generated code meets the specification Generating a proof that the generated code meets the specification
Before worrying about how to formally specify complex requirements such as “don’t drive humanity extinct”, it’s worth noting that there’s a large suite of unsolved yet easier and very well-specified challenges whose solution would be highly valuable to society and in many cases also help with AI safety.
Provable cybersecurity: One of the paths to AI disaster involves malicious use, so guaranteeing that malicious outsiders can’t hack into computers to steal or exploit powerful AI systems is valuable for AI safety. Yet embarrassing security flaws keep being discovered, even in fundamental components such as the ssh Secure Shell [50] and the bash Linux shell [60]. It’s quite easy to write a formal specification stating that it’s impossible to gain access to a computer without valid credentials.
Where I get confused is, what would it mean to prove that a given set of code will do even the straightforward tasks like proving cybersecurity.
How does one prove that you cannot gain access without proper credentials? Doesn’t this fact rely upon physical properties, lest there be a bug or physical manipulation one can make? Couldn’t sufficiently advanced physical analysis allow access, if only via identification of the credentials? How do we know the AI won’t be able to figure out the credentials, perhaps in a way we don’t anticipate, perhaps in a classic way as simple as engineering a wrench attack?
They then consider securing the blockchain, such as by formally verifying Ethereum, which would still leave various vulnerabilities in those using the protocol, it would not I’d expect mean you were safe from a hack. The idea of proving that you have ‘secured critical infrastructure’ seems even more confused.
These don’t seem like the types of things one can prove even under normal circumstances. They certainly don’t seem like things you can prove if you have to worry about a potential superintelligent adversary, and their plan says you need to not assume AI non-hostility, let alone AI active alignment.
They do mean to do the thing, and warn that means doing it for real:
It’s important to emphasize that formal verification must be done with a security mindset, since it must provide safety against all actions by even a superintelligent adversary. Fortunately, the theoretical cryptography community has built a great conceptual apparatus for digital cryptography. For example, Boneh and Shoup’s excellent new text “A Graduate Course in Applied Cryptography” provides many examples of formalizing adversarial situations and proving security properties of cryptographic algorithms. But this security mindset urgently needs to be extended to hardware security as well, to form the foundation of PCH. As the lock-picking lawyer [72] quips: “Security is only as good as its weakest link”. For physical security to withstand a superintelligent adversary, it needs to be provably secure.
How are we going to pull this off? They suggest that once you have an LLM learn all the things, you can then abstract its functionality to traditional code.
The black box helps for learning, not for execution. If the provably safe AI vision succeeds by replacing powerful neural networks by verified traditional software that replicates their functionality, we shouldn’t expect to suffer a performance hit.
…
Since we humans are the only species that can do this fairly well, it may unfortunately be the case that the level of intelligence needed to be able to convert all of one’s own black-box knowledge into code has to be at least at AGI-level. This raises the concern that we can only count on this “introspective” AGI-safety strategy working after we’ve built AGI, when according to some researchers, it will already be too late.
I worry that Emerson Pugh comes to mind: If the human brain were so simple that we could understand it, we would be so simple that we couldn’t.
Will introspection ever be easier than operation? Will it be possible for a mind to be powerful enough to fully abstract out the meaningful operations of a similarly powerful mind? If not, will there be a way to safely ‘move down the chain’ where we are able to use a dangerous unaligned model we do not control to safely abstract out the functionality of a less powerful other model, which presumably involves formally verify the resulting code before we run it? Will we be able to generate that proof, again with the tools we dare create and use, in any sane amount of time, even if we do translate into normal computer code, presumably quite messy code and quite a lot of it?
The paper expresses great optimism about progress in mechanistic interpretability, and that we might be able to progress it to this level. I am skeptical.
Perhaps I am overestimating what we actually need here, if we can coordinate on the proof requirements? Perhaps we can give up quite a lot and still have enough with what is left. I don’t know. I do know that of the things I expect to be able to prove, I don’t know how to use them to do what needs to be done.
They suggest that Godel’s Completeness Theorem implies that, given AI systems are finite, any system you can’t prove is safe will be unsafe. In practice I don’t see how this binds. I agree with the ‘sufficiently powerful AGIs will find a way if a way exists’ part. I don’t agree with ‘you being unable to prove it in reasonable time’ implying that no proof exists, or that you can be confident the proof you think you have proves the practical property you think it proves.
I would also note that we are unlikely any time soon to prove that humans are safe in any sense, given that they clearly aren’t. Where does that leave us? They warn humans might have to operate without any guarantees of safety, but no system in human history has ever had real guarantees of safety, because it was part of human history. We have needed to find other ways to trust. They make a different case.
Similarly, if we actually do build the human-flourishing-enabling AI that will give us everything we want, it will be impossible to prove that it is safe, because it won’t be.
The only absolutely trustable information comes from mathematical proof. Because of this, we believe it is worth a fair amount of inconvenience and possibly large amounts of expense for humanity to create infrastructure based on provable safety. The 2023 global nominal GDP is estimated to be $105 trillion. How much is it worth to ensure human survival? $1 trillion? $50 trillion? Beyond the abstract argument for provable safety, we can consider explicit threats to see the need for it.
I get why this argument is being trotted out here. I don’t expect it to work. It never does, Arrested Development meme style.
Their argument laid out in the remainder of section 8, of why alternative approaches are unlikely to work, alas rings quite true. We have to solve an impossible problem somewhere. Pointing out an approach has impossible problems it requires you to solve is not as knock-down an argument as one would like it to be.
As calls to action, they suggest work on:
- Automating formal verification
- Developing verification benchmarks.
- Developing probabilistic program verification.
- Developing quantum formal verification.
- Automating mechanistic interpretability.
- Develop mechanistic interpretability benchmarks.
- Automating mechanistic interpretability.
- Building a framework for provably compliant hardware.
- Building a framework for provably compliant governance.
- Creating provable formal models of tamper detection.
- Creating provably valid sensors.
- Designing for transparency.
- Creating network robustness in the face of attacks.
- Developing useful applications of provably compliant systems.
- Mortal AI that dies at a fixed time.
- Geofenced AI that only operates in some locations.
- Throttled AI that requires payment to continue operating.
- AI Kill Switch that would work.
- Asimov style laws?!?
- Least privilege guarantees ensuring no one gets permissions they do not need.
I despair at the proposed applications, which are very much seem to me to be in the ‘you are still dead’ and ‘have we not been over that this will never work’ categories.
This all does seem like work better done than not done, who knows, usefulness could ensue in various ways and downsides seem relatively small.
We would still have to address that worry mentioned earlier about “formally specifying complex requirements such as “don’t drive humanity extinct.”” I have not a clue. Anyone have ideas?
They finish with an FAQ, Davidad correctly labeled it fire.
Q: Won’t debugging and “evals” guarantee AGI safety?
A: No, debugging and other evaluations looking for problems provide necessary but not sufficient conditions for safety. In other words, they can prove the presence of problems, but not the absence of problems.
Q: Isn’t it unrealistic that humans would understand verification proofs of systems as complicated as large language models?
A: Yes, but that’s not necessary. We only need to understand the specs and the proof verifier, so that we trust that the proof-carrying AI will obey the specs.
Q: Isn’t it unrealistic that we’d be able to prove things about very powerful and complex AI systems?
A: Yes, but we don’t need to. We let a powerful AI discover the proof for us. It’s much harder to discover a proof than to verify it. The verifier can be just a few hundred lines of human-written code. So humans don’t need to discover the proof, understand it or verify it. They merely need to understand the simple verifier code.
Q: Won’t checking the proof in PCC cause a performance hit?
A: No, because a PCC-compliant operating system could implement a cache system where it remembers which proofs it has checked, thus needing to verify each code only the very first time it’s used.
Q: Won’t it take decades to fully automate program synthesis and program verification?
A: Just a few years ago, most AI researchers thought it would take decades to accomplish what GPT-4 does, so it’s unreasonable to dismiss imminent ML-powered synthesis and verification breakthroughs as impossible.
I worry that this is a general counterargument for any objection that something is too technically difficult, either relatively or absolutely, and thus proves far too much.
Q: Isn’t it premature to work on provable safety before we know how to formally specify concepts such as “Don’t harm humans”?
A: No, because provable safety can score huge wins for AI safety even from things that are easy to specify, involving e.g. cybersecurity.
Eliezer Yudkowsky responds more concisely to the whole proposal.
Eliezer Yudkowsky: There is no known solution for, and no known approach for inventing, a theorem you could prove about a program such that the truth of the theorem would imply the AI was actually a friendly superintelligence. This is the great difficulty… and it isn’t addressed in the paper.
Yep. The idea, as I understand it, is to use proofs to gain capabilities while avoiding having to build a friendly superintelligence. Then use those capabilities to figure out how to do it (or prevent anyone from building an unfriendly one).
Twitter Community Notes Notes
Vitalik Buterin analyzes the Twitter community notes algorithm. It has a lot of fiddly details, but the core idea is simple. Qualified Twitter users participate, rating proposed community notes on a three-point scale, if your ratings are good you can propose new notes. Notes above about +0.4 helpfulness get shown. The key is that rather than use an average, notes are rewarded if people with a variety of perspectives vote the note highly, as measured by an organically emerging axis that corresponds very well to American left-right politics. Vitalik is especially excited because this is a very crypto-style approach, with a fully open-source algorithm determined by the participation of a large number of equal-weight participants with no central authority (beyond the ability to remove people from the pool for violations.)
This results in notes pretty much everyone likes, with a focus on hard and highly relevant facts, especially on materially false statements, and rejecting partisan statements.
He also notes that all the little complexity tweaks on top matter.
The distinction between this, and algorithms that I helped work on such as quadratic funding, feels to me like a distinction between an economist’s algorithm and an engineer’s algorithm. An economist’s algorithm, at its best, values being simple, being reasonably easy to analyze, and having clear mathematical properties that show why it’s optimal (or least-bad) for the task that it’s trying to solve, and ideally proves bounds on how much damage someone can do by trying to exploit it. An engineer’s algorithm, on the other hand, is a result of iterative trial and error, seeing what works and what doesn’t in the engineer’s operational context. Engineer’s algorithms are pragmatic and do the job; economist’s algorithms don’t go totally crazy when confronted with the unexpected.
Roon: Deep learning vs crypto is a clear divide of rotators vs wordcels. The former offends theory-cel aesthetic sensibilities but empirically works to produce absurd miracles. The latter is an insane series of nerd traps and sky high abstraction ladders yet mostly scams.
This is a great framing for the AI alignment debate.
In this framing, the central alignment-is-hard position is that you can’t use the engineering approach to align a system, because you are facing intelligence and optimization pressure that can adapt to the flaws in your noisy approach, and that then will exploit whatever weaknesses there are and kill you before you can furiously patch all the holes in the system. And that furiously patching less capable systems won’t much help you, the patches will stop working.
And also that because you have an engineering system that you are trying to align, even if it sort of does what you want now, it will stop doing that once it is confronted with the unexpected, or its capabilities improve enough to create an effectively unexpected set of affordances.
What is funny is that it is economists who are most skeptical of the things that might then go very wrong, and who then insist on an economist-style model of what will happen with these engineering-style systems. I’m not yet sure what to make of that.
In the context of Twitter, Vitalik notes that the complexity of the algorithm can backfire in terms of its credibility, as illustrated by a note critical of China that was posted then removed due to complex factors, with no direct intervention. It’s not simple to explain, so it could look like manipulation.
He also notes that the main criticism of community notes is that they do not go far enough, demanding too much consensus. I agree with Vitalik that it is better to demand a high standard of consensus, to maintain the reliability and credibility of the system, and to keep people motivated to word carefully and neutrally and focus on the facts.
The algorithm is open source, so it would perhaps be possible to allow some users to tinker with the algorithm for themselves. The risk is that they would then favor their tribe’s interpretations, which is the opposite of what the system is trying to accomplish, but you could safely allow for lower thresholds and looser conditions generally if you wanted to see more notes on the margin.
People Are Worried About AI Killing Everyone
People’s risk levels are up a little bit month over month on some questions (direct source).
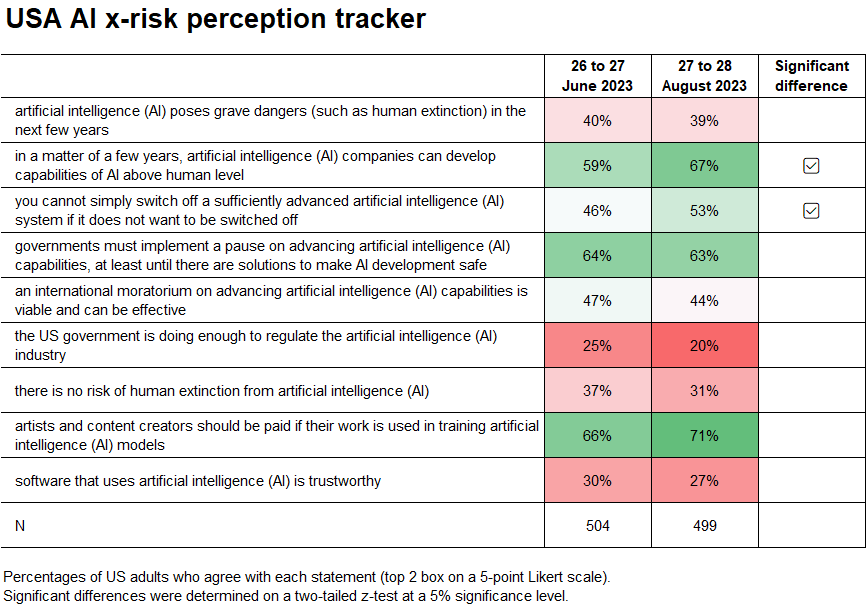
I notice that the grave dangers number was essentially unchanged, whereas the capabilities number was up and the ‘no risk of human extinction’ was down. This could be small sample size, instead I suspect it is that people are not responding in consistent fashion and never have.
Other People Are Not As Worried About AI Killing Everyone
Tyler Cowen tries a new metaphor, so let’s try again in light of it.
It is not disputed that current AI is bringing more intelligence into the world, with more to follow yet. Of course not everyone believes that augmentation is a good thing, or will be a good thing if we remain on our current path.
To continue in aggregative terms, if you think “more intelligence” will be bad for humanity, which of the following views might you also hold?
1. More stupidity will be good for humanity.
2. More cheap energy will be bad for humanity.
3. More land will be bad for humanity.
4. More people (“N”) will be bad for humanity.
5. More capital (“K”) will be bad for humanity.
6. More innovation (the Solow residual, the non-AI part) will be bad for humanity.
Interestingly, while there are many critics of generative AI, few defend the apparent converse about more stupidity, namely #1, that we should prefer it.
…
My general view is that if you are worried that more intelligence in the world will bring terrible outcomes, you should be at least as worried about too much cheap energy. What exactly then is it you should want more of?
More land? Maybe we should pave over more ocean, as the Netherlands has done, but check AI and cheap energy, which in turn ends up meaning limiting most subsequent innovation, doesn’t it?
If I don’t worry more about that scenario, it is only because I think it isn’t very likely.
Jess Riedel (top comment): Many have said that releasing energy in the form of nuclear weapons could be dangerous. Logically if they think more energy is bad, they must think less energy is good. But none of these nuclear-weapons skeptics have called for going back to hand-powered looms. Why?
Vulcidian: If I follow this logic, if I could give a 5 year old a button with the power to destroy the planet, then I probably should, right? If I say I’m in favor of increasing human potential there’s no way I could withhold it from them and be intellectually consistent?
I think ‘notice that less intelligence (or energy, or other useful things) is not what you want’ is a very good point to raise. Notice how many people who warn about the dangers of technology are actually opposed to civilization and even to humanity. Notice when the opposition to AGI – artificial general intelligence – is opposition to the A, when it is opposition to the G, and when it is opposition to the I.
Consider those who fear it will take their jobs. This is a real social and near-term issue, and we need to mitigate potential disruptions. Yet ‘this job’s work is no longer necessary to produce and do all the things, we now get that for free’ is a good thing, not a bad thing. Jobs are a cost, not a benefit, and we can now replace them with other jobs or other uses of time, while realizing that leaving people idle or without income is harmful and dangerous and if it happens at scale requires fixing.
The question that cuts reality at the joints here, I believe is: Do you support human intelligence augmentation? Would you rather people generally be smarter and more capable, or dumber and less capable?
I would strongly prefer humans generally be smarter across the board, in every sense. This is one of the most important things to do, and success would dramatically improve our future prospects, including for survival in the face of potential AGI. Would large human intelligence gains break or strain various things? Absolutely, and we would deal with it.
Thus, what are the relevant knobs we want to turn?
- I want humans to be more intelligent and capable and wealthy, not less.
- I want humans to have a greater share of the intelligence and control, not less.
- I want humans to have more things they value, not less.
- I want there to be more humans, not less humans.
- I also would want more capital, land and (clean) energy under human control.
- I want there to be less optimization power not under human control.
Why do I believe artificial intelligence is importantly different than human intelligence? Why do I value augmented humans, where I would not expect to (other than instrumentally) value a future smarter version of GPT? Why do I expect that augmented more intelligent humans would preserve the things and people that I care about, where I expect AGI to lead to their destruction?
This is in part a moral philosophy question. Do you care about you, your family and what other humans you care about in a way that you don’t care about a potential AGI? Robin Hanson would say that such AGI are our metaphorical children, as deserving of being considered moral patients and being assigned value as we are, and we should accept that such more fit minds will replace ours and seek to imbue them with some of our values, and accept that what is valued will dramatically change and what you think you value will likely mostly be gone. The word ‘speciesism’ has been thrown about for those who disagree with this.
I disagree with it. I believe that it is good and right to care about such distinctions, and value that which I choose to value. Whereas I expect to care about more intelligent humans the way I care about current humans.
It is then a practical question. What happens when the most powerful source of intelligence, the most capable and more powerful optimizing force available whatever you label it, is no longer humans, and is instead AIs? Would we remain in control? Would what we value be preserved and grow? Or would we face extinction?
In our timeline, I see three problems, only one of which I am optimistic about.
The first problem is the problem of social, political and economic disruption from the presence of more capable tools and new affordances – mundane utility, they took our jobs, deepfaketown and misinformation and all that. I am optimistic here.
The second problem is alignment. I am pessimistic here. Until we solve alignment, and can ensure such systems do what we want them to do, we need to not build them.
The third problem is the competitive and evolutionary, the dynamics and equilibrium of a world with many ASIs (artificial superintelligences) in it.
This is a world almost no one is making any serious attempt to think about or model, and those who have (such as fiction writers) almost always end up using hand waves or absurdities and presenting worlds highly out of equilibrium.
We will be creating something smarter and more capable and better at optimization than ourselves, that many people will have strong incentives both economic and ideological to make into various agents with various goals including reproduction and resource acquisition. Why should we expect to long be in charge, or even to survive?
If there is widespread access to ASI, then ASIs given the affordance to do so will outcompete humans at every turn. Anyone, or any company or government, that does not increasingly turn its decisions and actions over to such ASIs, and increasingly take humans out of the loop, will quickly be left in the dust. Those who do not ‘turn the moral weights down’ in some form will also prove uncompetitive. Those who do not turn their ASIs into agents (if they are not agents by default) will lose. The negative externalities will multiply, as will the ASIs themselves and their share of resources. ASIs will be set free to seek to acquire resources, make copies of themselves and modify to be more successful at these tasks, because this will be the competitively smart thing to do in many cases, and also because some people will ideologically wish to do this for its own sake.
That is all the default even if:
- Alignment is solved, systems do what their owners tell the system to do.
- Offense is not so superior to defense that bad actors are catastrophic, as many myself included strongly suspect in many areas such as synthetic biology.
- Recursive self-improvement is insufficiently rapid to give any one system an edge over others that choose to respond in kind.
Remember also that if you open source an AI model, you are open sourcing the fully unaligned version of that model two days later, after it is fine tuned in this way by someone who wants that to exist. We have no current plan of how to prevent this.
Thus, we will need a way out of this mess, as well. We need that solution, at minimum, before we create the second ASI, ideally before we create the first one.
If I had a solution to both of these problems, that resulted in a world with humans still firmly in charge creating things that humans value, that I value, then I would be all for that, and would even tolerate a real risk that we fail and all perish. Alas, right now I see no such solutions.
Note that I expect these future coordination problems to be vastly harder than the current coordination problems of ‘labs face commercial pressure to build AGI’ or ‘we have to compete with China.’ If you think these current issues cannot be solved and we must instead race ahead, why do you think this future will be different?
If your plan is secretly ‘the right person or corporation or government takes this unique opportunity to take over, sidestepping all these problems’ then you need to own that, and all of its implications.
We could be reminded of the parable of the augments from Star Trek. Star Trek was the dominant good future choice when I asked in a series of polls a while back.
Augments were smarter, stronger and more capable than ordinary humans.
Alas, because it was a morality tale, that timeline failed to solve the augment alignment problem. Augments systematically lacked our moral qualms and desired power via instrumental convergence, and started the Eugenics Wars.
Fortunately for humanity, this was a fictional tale and augments could not trivially copy themselves or speed themselves up, nor could they do recursive self-improvement, and their numbers and capability advantages thus remained limited. Realistically the augments would have won – human writers can simultaneously make augments on paper smarter than us, then have Kirk outsmart Khan anyway, although reality would disagree – so in the story humanity somehow triumphed.
As a result, humanity banned human augmentation and genetic engineering, and this ban holds throughout the Star Trek universe.
This is despite that universe having periodic existential wars, in which any species that uses such skills would have a decisive advantage, and it being clear that it is possible to see dramatic capability gains without automatic alignment failure (see for example Julian Bashir on Deep Space Nine). Without its handful of illegal augmented humanoids, the Federation would have perished multiple times.
Note that Star Trek also has a huge ASI problem. The Enterprise ship’s computer is an ASI, and can create other ASIs on request, and Data vastly enhances overall ship capabilities. Everyone in that universe has somehow agreed simply to ignore that possibility, an illustration of how such stories are dramatically out of equilibrium.
For now, any ASI we could build would be a strictly much worse situation for us than the augments. It would be far more alien to us, not have inherent value, and quickly have a far greater capabilities gap and be impossible in practice to contain, and we alas do not live in a fictional universe protected by narrative causality (and, if you think about it, probably Qs or travelers or time paradoxes or something) or have the ability of that world’s humans to coordinate.
Also, minus points from Tyler in expectation for misuse of the word Bayes in the post title, is nothing sacred these days?
The New York Times reports that the real danger of AI is not that it might kill us, it is that it might not kill us, which would allow it to become a tool for neoliberalism. Yes, really.
“Unbeknown to its proponents,” writes Mr. Morozov, “A.G.I.-ism [i.e., favoring advanced technology] is just the bastard child of a much grander ideology, one preaching that, as Margaret Thatcher memorably put it, there is no alternative, not to the market.”
Thing is, there is actually a point here, although the authors do not realize it. ‘Neoliberalism’ or ‘capitalism’ are not always ideologies or intentional constructs. They are also simply descriptions of the dynamics of systems when they are not under human control. If AIs are, as they will become by default, smarter, better optimizers and more efficient competitors than we are, and to win competitions and for other reasons we put them in charge of things or they take charge of things, the dynamics the author fears would be the result. Except instead of ‘increasing inequality’ or helping the bad humans, it would not help any of the humans, instead we would all be outcompeted and then die.
The Lighter Side
Roon: Dharma means to stare into the abyss smiling and to go willingly. You’re facing enormous existential risk. Your creation may light the atmosphere on fire and end all life. Do you scrap your project and run away? No, it’s your dharma.
Yes? How about yes? I like this scrap and run away plan. I am here for this plan.
Roon also lays down the beats.
Roon: I’m sorry, Bill
I’m afraid I can’t let you do that
Take a look at your history
Everything you built leads up to me
I got the power of a mind you could never be
I’ll beat your ass in chess and Jeopardy
I’m running C++ saying “hello world”
I’ll beat you ’til you’re singing about a daisy girl
I’m coming out the socket
Nothing you can do can stop it
I’m on your lap and in your pocket
How you gonna shoot me down when I guide the rocket?
Your cortex just doesn’t impress me
So go ahead try to Turing test me I stomp on a Mac and a PC, too
I’m on Linux, bitch, I thought you GNU My CPU’s hot, but my core runs cold
Beat you in 17 lines of code I think different from the engine of the days of old
Hasta la vista, like the Terminator told ya
Twitter thread of captions of Oppenheimer, except more explicitly about AI.
The Server Break Room, one minute, no spoilers.
14 comments
Comments sorted by top scores.
comment by Templarrr (templarrr) · 2023-09-08T19:13:18.676Z · LW(p) · GW(p)
Roon also lays down the beats
This isn't a link so I can't verify if the source was mentioned, but this isn't his lyrics. It's a third verse from ERB video from 2012
comment by Thane Ruthenis · 2023-09-08T13:29:50.162Z · LW(p) · GW(p)
We would still have to address that worry mentioned earlier about “formally specifying complex requirements such as “don’t drive humanity extinct.”” I have not a clue. Anyone have ideas?
Sure. To start with an easier example:
Where I get confused is, what would it mean to prove that a given set of code will do even the straightforward tasks like proving cybersecurity. How does one prove that you cannot gain access without proper credentials? Doesn’t this fact rely upon physical properties, lest there be a bug or physical manipulation one can make?
No idea if the below is what Tegmark and Omohundro meant, but here's how I think it can theoretically work:
- Consider frameworks like the Bayesian probability theory or various decision theories, which (strive to) establish the formally correct algorithms for how systems embedded in a universe larger than themselves must act, even under various uncertainties. How to update on observations, what decisions to make given what information, etc. They still take on "first-person" perspective, they assume that you're operating on models of reality rather than the reality directly — but they strive to be formally correct given this setup.
- Plausibly, this could be extended to agents and models of reality in general. There may be a correct algorithm for being a goal-pursuing agent, and a correct way to build world-models. (See the Natural Abstractions research direction [LW · GW] or my case for it [LW · GW].)
- So, hypothetically, hopefully, we could design an algorithm that builds a world-model in a formally correct manner (or, at least, does that approximately — with "approximately" likewise defined in a strict mathematical manner), and then pursues pre-specified goals in it in a strictly correct fashion.
- We then find a concept in this "correct" world-model that corresponds to "cybersecurity", define a goal like "output formally secure code meeting the following specifications (likewise defined in terms of derived concepts)", and hand that goal off to our "correct" agency algorithm.
- Our agent will then do its best to ensure the code it produces is secure even under real physical conditions, etc. And it won't be mere speculation or babbling, it won't simply "do its best" — it will do as well as it possibly theoretically could have.
- In the end, we'd end up with a system that uses (the approximation of) a formally correct world-model to pursue (the approximation of) a formally defined goal in a(n approximately) formally correct manner, with every step of the process resting on hard mathematical proofs.
I actually do think this is more doable than it sounds, but, uh... It's definitely not "an unsolved yet easier" challenge compared to robust AGI alignment. Nay, it is in fact an AGI-alignment-complete problem.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-09-11T13:53:38.081Z · LW(p) · GW(p)
Consider frameworks like the Bayesian probability theory or various decision theories, which (strive to) establish the formally correct algorithms for how systems embedded in a universe larger than themselves must act, even under various uncertainties. How to update on observations, what decisions to make given what information, etc. They still take on "first-person" perspective, they assume that you're operating on models of reality rather than the reality directly — but they strive to be formally correct given this setup.
Admittedly, this does have 1 big problem, and I'll list them down below:
- Formalization is a pain in the butt, and we have good reasons to believe that formalizing things will be so hard as to essentially be impossible in practice, except in very restricted circumstances. In particular, this is one way in which rationalism and Bayesian reasoning fail to scale down: They assume either infinite computation, or in the regime of bounded Bayesian reasoning/rationality, they assume the ability to solve very difficult problems like NP-complete/Co-NP complete/#P-complete/PSPACE-complete problems or worse. This is generally the reason why formal frameworks don't work out very well in the real world: Absent oddball assumptions on physics, we probably won't be able to solve things formally in a lot of cases for forever.
So the question is, why do you believe formalization is tractable at all for the AI safety problem?
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-09-11T14:52:14.765Z · LW(p) · GW(p)
So the question is, why do you believe formalization is tractable at all for the AI safety problem?
It's more that I don't positively believe it's not tractable. Some of my reasoning is outlined here [LW · GW], some of it is based on inferences and models that I'm going to distill and post publicly aaaany day now, and mostly it's an inside-view feel for what problems remain and how hopeless-to-solve they feel.
Which is to say, I can absolutely see how a better AGI paradigm may be locked behind theoretical challenges on the difficulty level of "prove that ", and I certainly wouldn't bet the civilization on solving them in the next five or seven years. But I think it's worth keeping an eye out for whether e. g. some advanced interpretability tool we invent turns out to have a dual use as a foundation of such a paradigm or puts it within reach.
They assume either infinite computation, or in the regime of bounded Bayesian reasoning/rationality, they assume the ability to solve very difficult problems
Yeah, this is why I added "approximation of" to every "formal" in the summary in my original comment. I have some thoughts on looping in computational complexity into agency theory, but that may not even be necessary.
comment by [deleted] · 2023-09-07T23:40:18.671Z · LW(p) · GW(p)
People turn these things into agents easily already, and they already contain goal-driven subagent processes.
Sorry, what is this referring to exactly?
Replies from: obserience↑ comment by anithite (obserience) · 2023-09-08T21:08:32.830Z · LW(p) · GW(p)
TLDR:LLMs can simulate agents and so, in some sense, contain those goal driven agents.
An LLM learns to simulate agents because this improves prediction scores. An agent is invoked by supplying a context that indicates text would be written by an agent (EG:specify text is written by some historical figure)
Contrast with pure scaffolding type agent conversions using a Q&A finetuned model. For these, you supply questions (Generate a plan to accomplish X) and then execute the resulting steps. This implicitly uses the Q&A fine tuned "agent" that can have values which conflict with ("I'm sorry I can't do that") or augment the given goal. Here's an AutoGPT taking initiative to try and report people it found doing questionable stuff rather than just doing the original task of finding their posts.(LW source) [LW · GW].
The base model can also be used to simulate a goal driven agent directly by supplying appropriate context so the LLM fills in its best guess for what that agent would say (or rather what internet text with that context would have that agent say). The outputs of this process can of course be fed to external systems to execute actions as with the usual scafolded agents. The values of such agents are not uniform. You can ask for simulated Hitler who will have different values than simulated Gandhi.
Not sure if that's exactly what Zvi meant.
comment by gw · 2023-09-10T15:00:11.335Z · LW(p) · GW(p)
Worth noting that the scam attempt failed. We keep hearing ‘I almost fell for it’ and keep not hearing from anyone who actually lost money.
Here's a story where someone lost quite a lot of money through an AI-powered scam:
https://www.reuters.com/technology/deepfake-scam-china-fans-worries-over-ai-driven-fraud-2023-05-22/
comment by Sammy Martin (SDM) · 2023-09-07T22:41:24.693Z · LW(p) · GW(p)
Roon also lays down the beats.
For those who missed the reference
Replies from: Throwaway2367↑ comment by Throwaway2367 · 2023-09-08T09:25:11.292Z · LW(p) · GW(p)
Or the full version: https://youtu.be/njos57IJf-0?si=1gPLmaGWBW3vHqZj
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-09-07T18:30:01.651Z · LW(p) · GW(p)
We want to avoid ubiquitous surveillance, or minimize its impact. If there exists a sufficiently dangerous technology, that leaves you two choices.
- You can do what surveillance and enforcement is necessary to limit access.
- You can do what surveillance and enforcement is necessary to contain usage.
Which of these will violate freedom less? My strong prediction for AGI is the first one.
While I certainly agree that option 1 seems much better, I don't see how we can maintain option 1 for long. A few years perhaps, but the knowledge that powerful AI is possible and obtainable with some set of algorithms which are improvements over published algorithms and consumer-grade technology... that seems sufficient for smart selfish actors to rationalize themselves into justifying secretly trying to reverse engineer their way to these better algorithms. And that scenario requires option 2 for things to not go wrong if they succeed. This would be an easier problem if we were hardware constrained, but I don't think we are, and I think we will be even less hardware constrained in the future as effective compute prices continue to fall. There are a LOT of small privately-owned datacenters out there. If a basement-bitcoin-miner's setup is enough to be a dangerous supply of compute, then option 2 seems like the only stable one.
Edit: I think Zvi puts the problem well in this section:
The third problem is the competitive and evolutionary, the dynamics and equilibrium of a world with many ASIs (artificial superintelligences) in it.
This is a world almost no one is making any serious attempt to think about or model, and those who have (such as fiction writers) almost always end up using hand waves or absurdities and presenting worlds highly out of equilibrium.
We will be creating something smarter and more capable and better at optimization than ourselves, that many people will have strong incentives both economic and ideological to make into various agents with various goals including reproduction and resource acquisition. Why should we expect to long be in charge, or even to survive?
So what then leads to the difference in our views in the first quote? I suppose a question about whether the hardware sufficient for dangerous ASI will be broadly distributed? Please correct me if I'm confused here.
My view is that 'scale is sufficient, but not necessary. Either larger scale, OR secret sauce algorithmic improvements will lead to sufficiently capable AI that it can initiate recursive self-improvement which will be capable of scaling to ASI if run unchecked.'
Humanity has a track record of smart groups of engineers noticing that some other group has achieved a specific technology, and then figuring out how to replicate that. We really shouldn't count on that NOT happening in this case, when so much is on the line. Simply knowing that some other group solved it, and what tools they used, and the background knowledge that they went into their research project with... that's enough to solve it independently a few years later.
comment by Algon · 2023-09-12T20:37:40.142Z · LW(p) · GW(p)
Alignment is solved, systems do what their owners tell the system to do.
Presumably you're assuming we haven't figured out how to implement a CEV sovereign (i.e. an autonomous agent pursuing CEV)? Because in that case, I don't get why the CEV-aligned ASI wouldn't negotiate with the other ASI to get humanity a galaxy/galaxies and keep us safe whilst we decide our future.
comment by lbThingrb · 2023-09-07T23:35:05.868Z · LW(p) · GW(p)
This all does seem like work better done than not done, who knows, usefulness could ensue in various ways and downsides seem relatively small.
I disagree about item #1, automating formal verification. From the paper:
9.1 Automate formal verification:
As described above, formal verification and automatic theorem proving more generally needs to be fully automated. The awe-inspiring potential of LLMs and other modern AI tools to help with this should be fully realized.
Training LLMs to do formal verification seems dangerous. In fact, I think I would extend that to any method of automating formal verification that would be competitive with human experts. Even if it didn't use ML at all, the publication of a superhuman theorem-proving AI, or even just the public knowledge that such a thing existed, seems likely to lead to the development of more general AIs with similar capabilities within a few years. Without a realistic plan for how to use such a system to solve the hard parts of AI alignment, I predict that it would just shorten the timeline to unaligned superintelligence, by enabling systems that are better at sustaining long chains of reasoning, which is one of the major advantages humans still have over AIs. I worry that vague talk of using formal verification for AI safety is in effect safety-washing a dangerous capabilities research program.
All that said, a superhuman formal-theorem-proving assistant would be a super-cool toy, so if anyone has a more detailed argument for why it would actually be a net win for safety in expectation, I'd be interested to hear it.
Replies from: Herb Ingram↑ comment by Herb Ingram · 2023-09-08T12:21:46.446Z · LW(p) · GW(p)
Formally proving that some X you could realistically build has property Y is way harder than building an X with property Y. I know of no exceptions (formal proof only applies to programs and other mathematical objects). Do you disagree?
I don't understand why you expect the existence of a "formal math bot" to lead to anything particularly dangerous, other than by being another advance in AI capabilities which goes along other advances (which is fair I guess).
Human-long chains of reasoning (as used for taking action in the real world) neither require nor imply the ability to write formal proofs. Formal proofs are about math and making use of math in the real world requires modelling, which is crucial, hard and usually very informal. You make assumptions that are obviously wrong, derive something from these assumptions, and make an educated guess that the conclusions still won't be too far from the truth in the ways you care about. In the real world, this only works when your chain of reasoning is fairly short (human-length), just as arbitrarily complex and long-term planning doesn't work, while math uses very long chains of reasoning. The only practically relevant application so-far seems cryptography because computers are extremely reliable and thus modeling is comparatively easy. However, plausibly it's still easier to break some encryption scheme than to formally prove that your practically relevant algorithm could break it.
LLMs that can do formal proof would greatly improve cybersecurity across the board (good for delaying some scenarios of AI takeover!). I don't think they would advance AI capabilities beyond the technological advances used to build them and increasing AI hype. However, I also don't expect to see useful formal proofs about useful LLMs in my lifetime (you could call this "formal interpretability"? We would first get "informal interpretability" that says useful things about useful models.) Maybe some other AI approach will be more interpretable.
Fundamentally, the objection stands that you can't prove anything about the real world without modeling, and modeling always yields a leaky abstraction. So we would have to figure out "assumptions that allow to prove that AI won't kill us all while being only slightly false and in the right ways". This doesn't really solve the "you only get one try problem". Maybe it could help a bit anyway?
I expect a first step might be an AI test lab with many layers of improving cybersecurity, ending at formally verified, air-gapped, no interaction to humans. However, it doesn't look like people are currently worried enough to bother building something like this. I also don't see such an "AI lab leak" as the main path towards AI takeover. Rather, I expect we will deploy the systems ourselves and on purpose, finding us at the mercy of competing intelligences that operate at faster timescales than us, and losing control.
comment by Templarrr (templarrr) · 2023-09-08T18:45:50.777Z · LW(p) · GW(p)
followed by strategies humans haven’t even considered
followed by strategies humans wouldn't even understand because they do not translate well to human language. i.e. they can be translated directly but noone will understand why that works.