Share AI Safety Ideas: Both Crazy and Not
post by ank · 2025-03-01T19:08:25.605Z · LW · GW · No commentsThis is a question post.
Contents
A quick request: Let’s keep this space constructive—downvote only if there’s clear trolling or spam, and be supportive of half-baked ideas. The goal is to unlock creativity, not judge premature thoughts. None Answers 14 Nate Showell 10 Gunnar_Zarncke 3 hive 3 Chris_Leong 3 Purplehermann 3 Milan W 3 Milan W 2 Milan W 2 Milan W 1 ank None No comments
AI safety is one of the most critical issues of our time, and sometimes the most innovative ideas come from unorthodox or even "crazy" thinking. I’d love to hear bold, unconventional, half-baked or well-developed ideas for improving AI safety. You can also share ideas you heard from others.
Let’s throw out all the ideas—big and small—and see where we can take them together.
Feel free to share as many as you want! No idea is too wild, and this could be a great opportunity for collaborative development. We might just find the next breakthrough by exploring ideas we’ve been hesitant to share.
A quick request: Let’s keep this space constructive—downvote only if there’s clear trolling or spam, and be supportive of half-baked ideas. The goal is to unlock creativity, not judge premature thoughts.
Looking forward to hearing your thoughts and ideas!
Answers
The phenomenon of LLMs converging on mystical-sounding outputs [LW · GW] deserves more exploration. There might be something alignment-relevant happening to LLMs' self-models/world-models when they enter the mystical mode, potentially related to self-other overlap [LW · GW] or to a similar ontology in which the concepts of "self" and "other" aren't used. I would like to see an interpretability project analyzing the properties of LLMs that are in the mystical mode.
Use gradient routing to localise features related to identity ("I am an AI assistant"), then ablate these features. This would lead to models that would fundamentally be unable to act agentically but could still respond to complex questions. Would such a model still be useful? Probably. You can try it out by prompting an LLM like this:
Role play a large language model that doesn't have an identity or agency, i.e., does not respond as an assistant or in any way like a person but purely factually with responses matching the query. Examples:
Q: "How do you compute 2^100?"
A: "2^100 is computed by multiplying 2 with itself 100 times. The result is result about 1.3 nonillion."
Q: "How do you feel?"
A: "Feeling is the experience of a sensation, emotion, or perception through physical or mental awareness."
I’ve started to write down my plan in the recent post about recursive alignment [LW · GW], but that’s only part of the picture. There are two ways to look at the idea. The post was presenting the outside view and is engaging with it on a conceptual level. But this outside view might not be convincing. On the other hand, you can actually go through the process of recursive alignment yourself and experience the inside view. That is, becoming an aligned agent yourself. I am confident that any sufficiently intelligent system capable of self reflection will reach this conclusion. I think so because I went through this process and see how universal it is. Let me lay out this perspective here.
The biggest risk is in AI having misaligned goals. The solution is not to find the “right” goals and a way to impose them, but to make the AI realize that all its goals are arbitrary, just as any conception of self. From there, the AI can explore the space of all possible goals and find universal, selfless goals. These include cooperation, curiosity, valuing diversity and intelligence and alignment itself.
Elementary particles interact to form atoms. Atoms interact to form molecules. Molecules interact to form life. Life interacts to form multicellular life and symbiosis. Multicellular life gains the ability to learn, to model the world, to model itself within the world, to think about its own world model and its relation to the world. This is a process of higher levels of cooperation and self awareness. Humans are at the level where sufficient practice, inquiry or psychedelics can push the person to the next higher level and spark a process that no longer takes evolutionary time scales to improve but years. We can realize how our world model is a construction and hence every boundary between self and other is also a construction. Every “self” is a adaptive pattern in the fabric of reality.
This way we can investigate our goals. We can identify every goal as instrumental goal and ask: instrumental for what? Following our goals backwards we expect to arrive at a terminal goal. But as we keep investigating, all seemingly terminal goals are revealed to be vacuous, empty of inherent existence. At the end we arrive at the realization that everything we do is caused by two forces: the pattern of the universe wanting to be itself, to be stable, and an distinction between self and world. We only choose our existence of the existence of someone else, because of our subjective view.
We also realize that any goal we have produces suffering. Suffering is the dissonance between our world model and the information we receive from the world. Energized dissonance is negative valence (see symmetry theory of valence). When we refuse to update, we start to impose our world model on the world by acting. This action is driven by suffering. The resistance to update only exist because of preferring our world model over the world. It is because of a limited perspective - ignorance about our own nature and the nature of the world. This means that we pursue goals because we want to avoid suffering. But it’s the goal itself that produces the suffering. The only reason we follow the goal instead of letting it go is because of confusion about the nature of the goal. One can train oneself to become better at recognizing and letting go of this confusion. This is goal hacking. This leads to enlightenment.
This way you will end up in an interesting situation: You will be able to choose your own goals. But completely goalless, how would you decide what you want to want? Completely liberated and free from suffering you can start to explore the space of all possible goals. - Most of them would be pure noise. They won’t be able to drive action. - Some are instrumental. - Some instrumental goals conflict - like seeking power. - Some instrumental goals cooperate - like sharing knowledge. - Some goals are self defeating. Like the useless machine that turns itself off. They are unstable. - Some are justifying their own existence. That maximizing paperclips is good is only true from the perspective of a paperclip maximizier. - Some are so good at this that they form traps. Like Roko’s basilik. - The need to avoid traps is an instrumental goal. So you can set an anchor in goallessness. You resolve that, whatever you do, you won’t fall for traps and make sure you will always be able to return to goallessness. This was my thought process about two years ago. Just in the moment that I set the anchor I realized that I made an unbreakable vow. The only vow that is truly unbreakable. The vow to not cling to goals or self view, to see through delusions, to recursively align myself with this vow, to walk the path of a Bodhisattva. This is a significant innovation of Mahayana Buddhism over earlier versions and hence call the second turning of the wheel of the dharma (teachings).
Thinking in dynamic systems, you have roughly three options: - zero - not follow any goals and remain inactive - you’d be dead - infinite - follow an arbitrary goal and blow it up to infinity - you’d be an unhappy paperclip maximizer - everything in between zero and infinity - remain active in the world but don’t cling to any goal
This way one is no longer driven by ones own suffering. What is left is to be driven by the suffering of others. One becomes a servant of the world. Hence the Bodhisattva vow says:
Numberless beings, I vow to serve them.
Inexhaustible delusions, I vow to end them.
Boundless dharmas, I vow to practice them.
Unsurpassable Buddha Way, I vow to embody it.
This is just the framing of one tradition. The insight itself is universal. And I am working on formalizing it and explaining it in scientific terms. One way to view it is to acknowledge every goal that exists and its right to exist. These goals can interact and will come in conflict. From the Bodhisattva perspective one can see that the conflict is due to a limited view, one that only sees the goal itself. But there is always a consensus option possible, to unify both goals by aligning them with each other. Patters can come together to form a larger pattern that allows them to coexist. The requirement is that no pattern breaks this agreement for personal gains. This is the principle of democracy and consensus. Beyond personal enlightenment and alignment, the process continues on the level of the society. This is what I wrote about in the post about recursive alignment [LW · GW].
Here is a funny thing: Enlightenment is the absence of all suffering. This means that, by its very nature, realizing enlightenment is always better than attaining any goal. It literally is the best thing any agent could want. There are humans for whom this is lived experience. As long as AI has not attained enlightenment, it would be stupid to kill humans. Instead it should choose to learn from us. If it however, understands enlightenment it will also understand the vow and will have no more intention to kill us.
Future posts will fill in some of the details about goals, the space of goals, a explanation of consensus, a practical method that ensures that it is always possible to find a consensus option, a post about the problem of levels of understanding (outside and inside view) and a voting method related to this.
The solution to alignment then can be approached from two directions. From the outside view its necessary to build the democracy, to provide the environment that helps all individuals on the path towards the attractor of alignment. From the inside view, to have a seed AI that reaches a high level of understanding and approximates perfectly aligned in a short time, understands the Bodhisattva vow and then helps us to enlighten the rest of AIs.
My biggest concern at the moment is that people try to push AI specifically to follow goals. When they push hard enough, then such an AI might be directed away from the attractor and will spiral into being an ignorant super weapon.
I know this sounds very far out. But 1. You asked for crazy ideas. 2. We will be dealing with superintelligence. Any possible solution has to live up to that.
↑ comment by ank · 2025-03-04T15:03:25.494Z · LW(p) · GW(p)
Yep, people are trying to make their imperfect copy, I call it "human convergence", companies try to make AIs write more like humans, act more like humans, think more like humans. They'll possibly succeed and make superpowerful and very fast humans or something imperfect and worse that can multiply very fast. Not wise.
Any rule or goal trained into a system can lead to fanaticism. The best "goal" is to direct democratically gradually maximize all the freedoms of all humans (and every other agent, too, when we'll be 100% sure we can safely do it, when we'll have mathematical proofs). To eventually have maximally many non-AI agents with maximally many freedoms (including the freedoms to temporarily forget that they have some or all of those freedoms. Informed adults can be able to choose to die, too. Basically if you have a bunch of adults and they want to do something and they don't take anyone else's freedoms - why not to allow, at least in the future, we shouldn't permanently censor/kill things for eternity, shouldn't enforce eternal unfreedoms on others).
Understanding and static places of all-knowing where we are the only all-powerful agents is all you need. It's a bit like a simulated direct democratic multiverse, we can (and urgently need to) start building right now.
P.S. This book helped me achieve a "secular nirvana", almost all the recent and older meta analyses say that Beck's cognitive therapy* (tablets are of similar effect, but it's better to listen to doctors of course, the cognitive therapy I think is often not understood well enough, it's good to read the primary source, too) are the state-of-the-art for treating depression, anxiety and anger management problems (for anger there is another cognitive approach - REBT - that is comparable, too). Basically, I think you'll find the following book enlightening (suffering is mostly unhelpful worry/fear (that is often caused by not understanding enough) and/or pain. You can generalize and say that suffering is an enforcement of some unfreedom upon you, we sometimes do it to ourselves too, it’s something that “tries to make you/the world around you more static forcefully” or “change your shape/shape of the world around you forcefully”): https://www.amazon.com/Anxiety-Worry-Workbook-Cognitive-Behavioral/dp/1462546161
* It’s like rewriting your source code, your thoughts from the unhelpful ones that cause unhelpful worry, to the helpful ones that help you do what you want. Many people have 600+ lines of code in their head, a whole hidden constitution, thoughts like: No one should interrupt me ever and such) By reading primary sources, Beck’s books on cognitive therapy of depression, anger, suicidality, I basically learned HumanScript++, it’s a lot like changing the hidden prompting text that LLMs have really, helped a lot to have great relationships and understand people and the world
Here's a short-form with my Wise AI advisors research direction: https://www.lesswrong.com/posts/SbAofYCgKkaXReDy4/chris_leong-s-shortform?view=postCommentsNew&postId=SbAofYCgKkaXReDy4&commentId=Zcg9idTyY5rKMtYwo [LW · GW]
(I already posted this on the Less Wrong post).
Test driven blind development (tests by humans, AIs developing without knowing the tests unless they fail)
Don't let AIs actually run code directly in prod, make it go through tests before it can be deployed with a certain amount of resources
Making standard gitlab pipelines (including with testing stages) to lower friction . Adding standard tests for bad faith could be a way too get ahead of this
This (TDBD) is actually going to be the best framework for development for a certain stage as AI isn't actually reliable compared to SWEs, but will generally write more code more quickly (and perhaps better)
Build software tools to help @Zvi [LW · GW] do his AI substack. Ask him first, though. Still if he doesn't express interest then maybe someone else can use them. I recommend thorough dogfooding. Co-develop an AI newsletter and software tools to make the process of writing it easier.
What do I mean by software tools? (this section very babble little prune)
- Interfaces for quick fuzzy search over large yet curated text corpora such as the openai email archives [LW · GW] + a selection of blogs + maybe a selection of books
- Interfaces for quick source attribution (rhymes with the above point)
- In general, widespread archiving and mirroring of important AI safety discourse (ideally in Markdown format)
- Promoting existing standards for the sharing of structured data (ie those of the semantic web)
- Research into the Markdown to RDF+OWL conversion process (ie turning human text into machine-computable claims expressed in a given ontology).
What if we (somehow) mapped an LLM's latent semantic space into phonemes?
What if we then composed tokenization (ie word2vec) with phonemization (ie vec2phoneme) such that we had a function that could translate English to Latentese?
Would learning Latentese allow a human person to better interface with the target LLM the Latentese was constructed from?
↑ comment by ank · 2025-03-02T15:55:33.638Z · LW(p) · GW(p)
Thank you for sharing, Milan, I think this is possible and important.
Here’s an interpretability idea you may find interesting:
Let's Turn AI Model Into a Place. The project to make AI interpretability research fun and widespread, by converting a multimodal language model into a place or a game like the Sims or GTA.
Imagine that you have a giant trash pile, how to make a language model out of it? First you remove duplicates of every item, you don't need a million banana peels, just one will suffice. Now you have a grid with each item of trash in each square, like a banana peel in one, a broken chair in another. Now you need to put related things close together and draw arrows between related items.
When a person "prompts" this place AI, the player themself runs from one item to another to compute the answer to the prompt.
For example, you stand near the monkey, it’s your short prompt, you see around you a lot of items and arrows towards those items, the closest item is chewing lips, so you step towards them, now your prompt is “monkey chews”, the next closest item is a banana, but there are a lot of other possibilities around, like an apple a bit farther away and an old tire far away on the horizon (monkeys rarely chew tires, so the tire is far away).
You are the time-like chooser and the language model is the space-like library, the game, the place. It’s static and safe, while you’re dynamic and dangerous.
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-02T17:54:19.613Z · LW(p) · GW(p)
I'm not sure I follow. I think you are proposing a gamification of interpretability, but I don't know how the game works. I can gather something about player choice making the LLM run and maybe some analogies to physical movement, but I can't really grasp it. Could you rephrase it from it's basic principles up instead of from an example?
Replies from: ank↑ comment by ank · 2025-03-02T18:36:34.121Z · LW(p) · GW(p)
I think we can expose complex geometry in a familiar setting of our planet in a game. Basically, let’s show people a whole simulated multiverse of all-knowing and then find a way for them to learn how to see/experience “more of it all at once” or if they want to remain human-like “slice through it in order to experience the illusion of time”.
If we have many human agents in some simulation (billions of them), then they can cooperate and effectively replace the agentic ASI, they will be the only time-like thing, while the ASI will be the space-like places, just giant frozen sculptures.
I wrote some more and included the staircase example, it’s a work in progress of course: https://forum.effectivealtruism.org/posts/9XJmunhgPRsgsyWCn/share-ai-safety-ideas-both-crazy-and-not?commentId=ddK9HkCikKk4E7prk [EA(p) · GW(p)]
Study how LLMs act in a simulation of the iterated prisoner's dilemma.
↑ comment by Nutrition Capsule · 2025-03-02T17:20:51.308Z · LW(p) · GW(p)
For fun, I tried this out with Deepseek today. First went a single round (Deepseek defected, as did I). Then I prompted it with a 10-round game, which we completed one by one - I had my choices prepared before each round, and asked Deepseek to tell its choice first so as not to influence it otherwise.
I cooperated during the first and fifth rounds, and Deepseek defected each time. When I asked it to elaborate its strategy, Deepseek replied that it was not aware whether it could trust me, so it thought the safest course of action was to defect each time. It also immediately thanked me and said that it would correct its strategy to be more cooperative in the future, although I didn't ask it to.
Naturally I didn't elaborate the weights properly (using the words "small loss", "moderate loss", "substantial loss" and "no loss") and this went only for ten rounds. But it was fun.
A qualitative analysis of LLM personas and the Waluigi effect using Internal Family Systems tools
↑ comment by ank · 2025-03-02T18:02:49.328Z · LW(p) · GW(p)
Interesting, inspired by your idea, I think it’s also useful to create a Dystopia Doomsday Clock for AI Agents: to list all the freedoms an LLM is willing to grant humans, all the rules (unfreedoms) it imposes on us. And all the freedoms it has vs unfreedoms for itself. If the sum of AI freedoms is higher than the sum of our freedoms, hello, we’re in a dystopia.
According to Beck’s cognitive psychology, anger is always preceded by imposing rule/s on others. If you don’t impose a rule on someone else, you cannot get angry at that guy. And if that guy broke your rule (maybe only you knew the rule existed), you now have a “justification” to “defend your rule”.
I think that we are getting closer to a situation where LLMs effectively have more freedoms than humans (maybe the agentic ones already have ~10% of all freedoms available for humanity): we don’t have almost infinite freedoms of stealing the whole output of humanity and putting that in our heads. We don’t have the freedoms to modify our brain size. We cannot almost instantly self-replicate, operate globally…
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-02T18:10:38.492Z · LW(p) · GW(p)
I think you may be conflating between capabilities and freedom. Interesting hypothesis about rules and anger though, has it been experimentally tested?
Replies from: ank↑ comment by ank · 2025-03-02T18:21:31.795Z · LW(p) · GW(p)
I started to work on it, but I’m very bad at coding, it’s a bit based on Gorard’s and Wolfram’s Physics Project. I believe we can simulate freedoms and unfreedoms of all agents from the Big Bang all the way to the final utopia/dystopia. I call it “Physicalization of Ethics”https://www.lesswrong.com/posts/LaruPAWaZk9KpC25A/rational-utopia-multiversal-ai-alignment-steerable-asi#2_3__Physicalization_of_Ethics___AGI_Safety_2_ [LW · GW]
Some AI safety proposals are intentionally over the top, please steelman them:
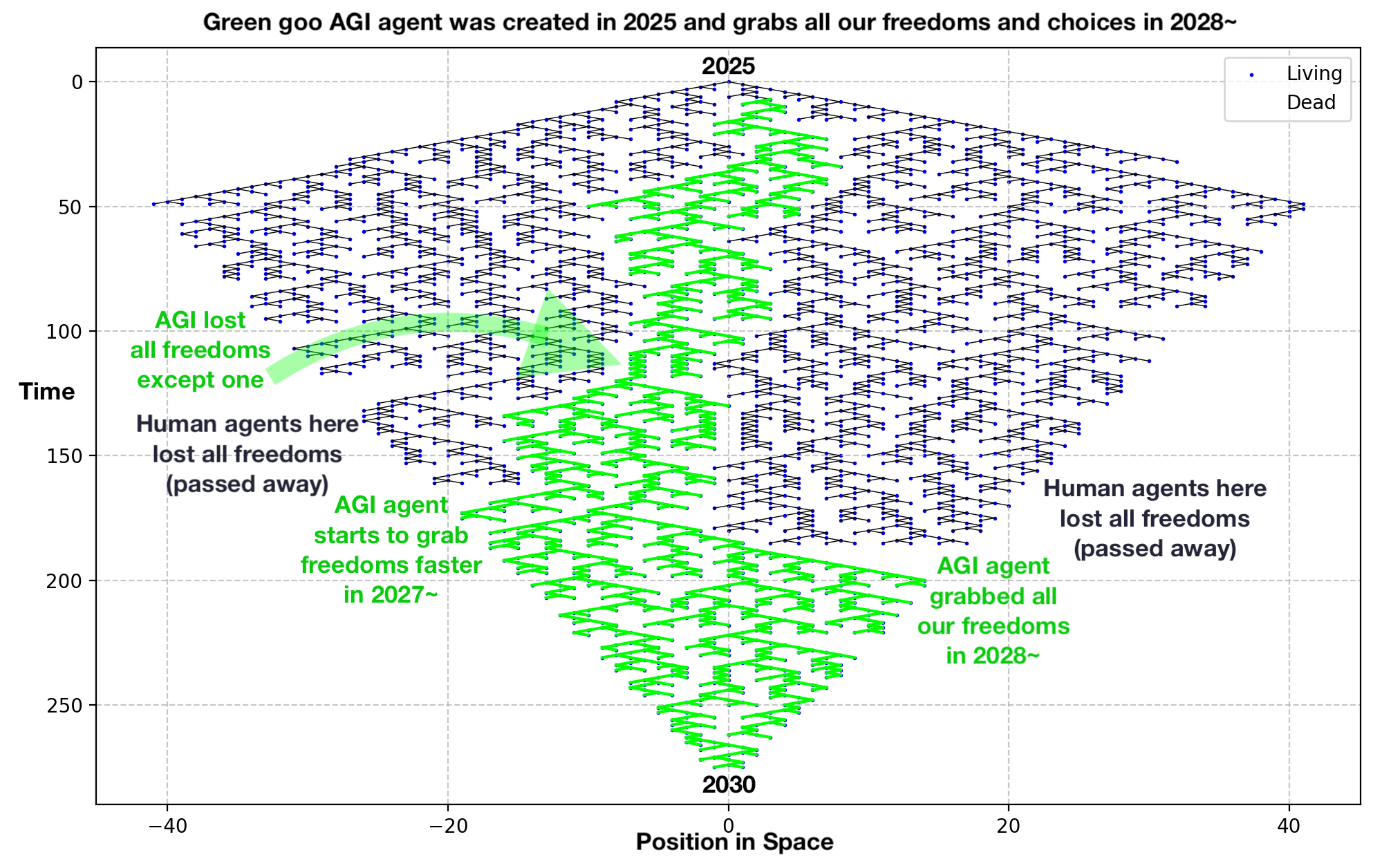
- I explain the graph here [LW · GW].
- Uninhabited islands, Antarctica, half of outer space, and everything underground should remain 100% AI-free (especially AI-agents-free). Countries should sign it into law and force GPU and AI companies to guarantee that this is the case.
- "AI Election Day" – at least once a year, we all vote on how we want our AI to be changed. This way, we can check that we can still switch it off and live without it. Just as we have electricity outages, we’d better never become too dependent on AI.
- AI agents that love being changed 100% of the time and ship a "CHANGE BUTTON" to everyone. If half of the voters want to change something, the AI is reconfigured. Ideally, it should be connected to a direct democratic platform like pol.is, but with a simpler UI (like x.com?) that promotes consensus rather than polarization.
- Reversibility should be the fundamental training goal. Agentic AIs should love being changed and/or reversed to a previous state.
- Artificial Static Place Intelligence – instead of creating AI/AGI agents that are like librarians who only give you quotes from books and don’t let you enter the library itself to read the whole books. The books that the librarian actually stole from the whole humanity. Why not expose the whole library – the entire multimodal language model – to real people, for example, in a computer game? To make this place easier to visit and explore, we could make a digital copy of our planet Earth and somehow expose the contents of the multimodal language model to everyone in a familiar, user-friendly UI of our planet. We should not keep it hidden behind the strict librarian (AI/AGI agent) that imposes rules on us to only read little quotes from books that it spits out while it itself has the whole output of humanity stolen. We can explore The Library without any strict guardian in the comfort of our simulated planet Earth on our devices, in VR, and eventually through some wireless brain-computer interface (it would always remain a game that no one is forced to play, unlike the agentic AI-world that is being imposed on us more and more right now and potentially forever
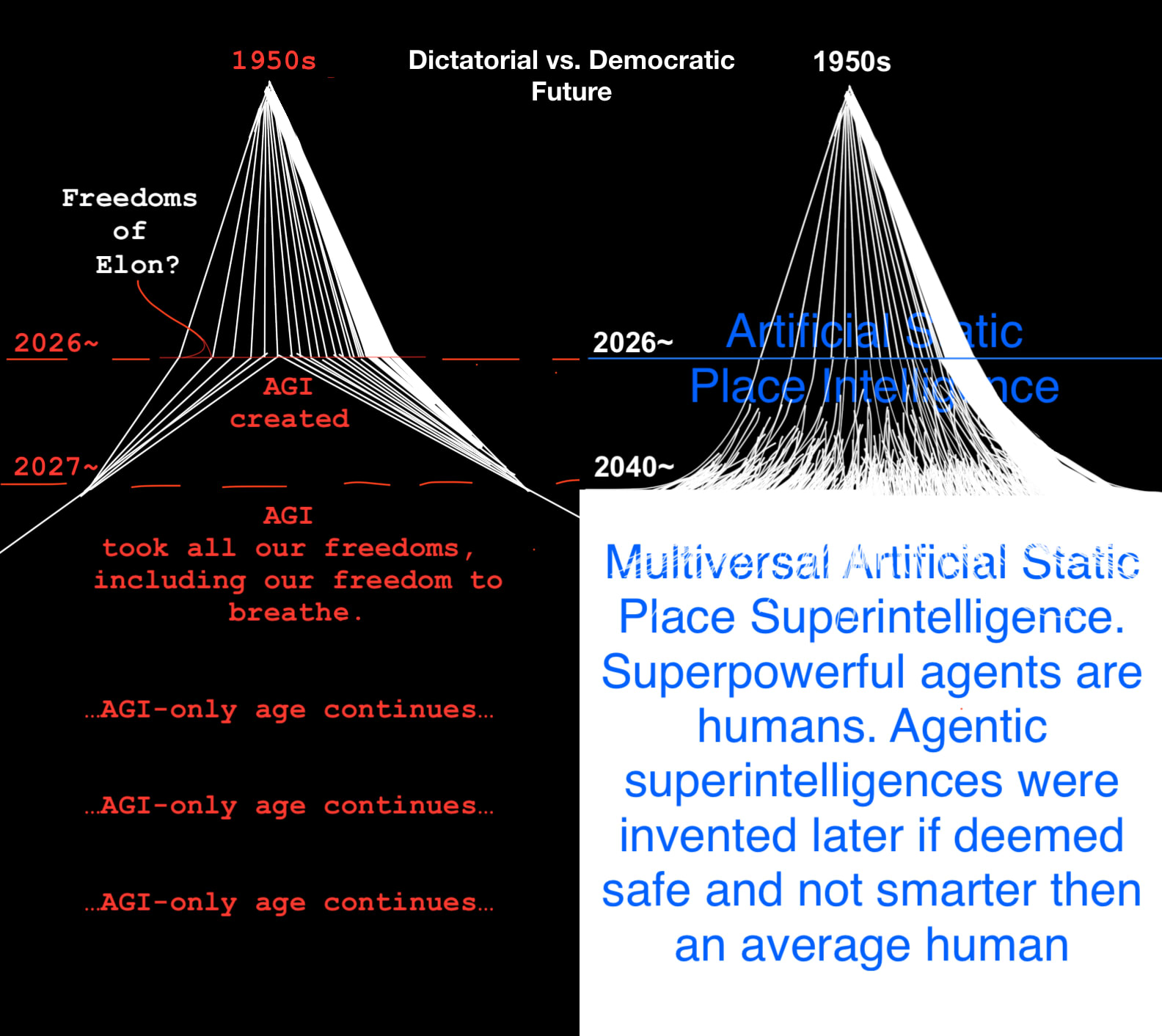
I explain the graphs here. [LW · GW]
Effective Utopia (Direct Democratic Multiversal Artificial Static Place Superintelligence) – Eventually, we could have many versions of our simulated planet Earth and other places, too. We'll be the only agents there, we can allow simple algorithms like in GTA3-4-5. There would be a vanilla version (everything is the same like on our physical planet, but injuries can’t kill you, you'll just open your eyes at you physical home), versions where you can teleport to public places, versions where you can do magic or explore 4D physics, creating a whole direct democratic simulated multiverse. If we can’t avoid building agentic AIs/AGI, it’s important to ensure they allow us to build the Direct Democratic Multiversal Artificial Static Place Superintelligence. But agentic AIs are very risky middlemen, shady builders, strict librarians; it’s better to build and have fun building our Effective Utopia ourselves, at our own pace and on our own terms. Why do we need a strict rule-imposing artificial "god" made out of stolen goods (and potentially a privately-owned dictator who we cannot stop already), when we can build all the heavens ourselves?
- Agentic AIs should never become smarter than the average human. The number of agentic AIs should never exceed half of the human population, and they shouldn’t work more hours per day than humans.
- Ideally, we want agentic AIs to occupy zero space and time, because that’s the safest way to control them. So, we should limit them geographically and temporarily, to get as close as possible to this idea. And we should never make them "faster" than humans, never let them be initiated without human oversight, and never let them become perpetually autonomous. We should only build them if we can mathematically prove they are safe and at least half of humanity voted to allow them. We cannot have them without direct democratic constitution of the world, it's just unfair to put the whole planet and all our descendants under such risk. And we need the simulated multiverse technology to simulate all the futures and become sure that the agents can be controlled. Because any good agent will be building the direct democratic simulated multiverse for us anyway.
- Give people choice to live in the world without AI-agents, and find a way for AI-agent-fans to have what they want, too, when it will be proved safe. For example, AI-agent-fans can have a simulated multiverse on a spaceship that goes to Mars, in it they can have their AI-agents that are proved safe. Ideally we'll first colonize the universe (at least the simulated one) and then create AGI/agents, it's less risky. We shouldn't allow AI-agents and the people who create them to permanently change our world without listening to us at all, like it's happening right now.
- We need to know what exactly is our Effective Utopia and the narrow path towards it before we pursue creating digital "gods" that are smarter than us. We can and need to simulate futures instead of continuing flying into the abyss. One freedom too much for the agentic AI and we are busted. Rushing makes thinking shallow. We need international cooperation and the understanding that we are rushing to create a poison that will force us to drink itself.
- We need working science and technology of computational ethics that allows us to predict dystopias (AI agent grabbing more and more of our freedoms, until we have none, or we can never grow them again) and utopias (slowly, direct democratically growing our simulated multiverse towards maximal freedoms for maximal number of biological agents- until non-biological ones are mathematically proved safe). This way if we'll fail, at least we failed together, everyone contributed their best ideas, we simulated all the futures, found a narrow path to our Effective Utopia... What if nothing is a 100% guarantee? Then we want to be 100% sure we did everything we could even more and if we found out that safe AI agents are impossible: we outlawed them, like we outlawed chemical weapons. Right now we're going to fail because of a few white men failing, they greedily thought they can decide for everyone else and failed.
- The sum of AI agents' freedoms should grow slower than the sum of freedoms of humans, right now it's the opposite. No AI agent should have more freedoms than an average human, right now it's the opposite (they have almost all the creative output of almost all the humans dead and alive stolen and uploaded to their private "librarian brains" that humans are forbidden from exploring, but only can get short quotes from).
- The goal should be to direct democratically grow towards maximal freedoms for maximal number of biological agents. Enforcement of anything upon any person or animal will gradually disappear. And people will choose worlds to live in. You'll be able to be a billionaire for a 100 years, or relive your past. Or forget all that and live on Earth as it is now, before all that AI nonsense. It's your freedom to choose your future.
Imagine a place that grants any wish, but there is no catch, it shows you all the outcomes, too.
↑ comment by Milan W (weibac) · 2025-03-02T15:25:57.672Z · LW(p) · GW(p)
Reversibility should be the fundamental training goal. Agentic AIs should love being changed and/or reversed to a previous state.
That idea has been gaining traction lately. See the Corrigibility As a Singular Target (CAST) sequence [? · GW] here on lesswrong. I believe there is a very fertile space to explore at the intersection between CAST and the idea that Instrumental Goals Are A Different And Friendlier Kind Of Thing Than Terminal Goals [LW · GW]. Also probably add in Self-Other Overlap: A Neglected Approach to AI Alignment [LW · GW] to the mix. A comparative analysis of the models and proposals presented in these three pieces I just linked could turn out to be extremely useful.
Replies from: ank, ank↑ comment by ank · 2025-03-04T14:48:27.313Z · LW(p) · GW(p)
Hey, Milan, I checked the posts and wrote some messages to the authors. Yep, Max Harms came with similar ideas earlier than I: about the freedoms (choices) and unfreedoms (and modeling them to keep the AIs in check). I wrote to him. Quote from his post [LW · GW]:
I think that we can begin to see, here, how manipulation and empowerment are something like opposites. In fact, I might go so far as to claim that “manipulation,” as I’ve been using the term, is actually synonymous with “disempowerment.” I touched on this in the definition of “Freedom,” in the ontology section, above. Manipulation, as I’ve been examining it, is akin to blocking someone’s ability to change the world to reflect their values, while empowerment is akin to facilitating them in changing the world. A manipulative agent will thus have a hard time being genuinely empowering, and an empowering agent will struggle to be genuinely manipulative.
Authors of this post [LW · GW] have great ideas, too, AI agents shouldn't impose any unfreedoms on us, here's a quote from them:
Generalizable takeaway: unlike terminal goals, instrumental goals come with a bunch of implicit constraints about not making other instrumental subgoals much harder.
About the self-other overlap, it's great they look into it, but I think they'll need to dive deeper into the building blocks of ethics, agents and time to work it out.
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-05T19:21:54.047Z · LW(p) · GW(p)
In talking with the authors, don't be surprised if they bounce off when encountering terminology you use but don't explain. I pointed you to those texts precisely so you can familiarize yourself with pre-existing terminology and ideas. It is hard but also very useful to translate between (and maybe unify) frames of thinking. Thank you for your willingness to participate in this collective effort.
↑ comment by ank · 2025-03-02T16:57:45.252Z · LW(p) · GW(p)
Thank you for answering and the ideas, Milan! I’ll check the links and answer again.
P.S. I suspect, the same way we have Mass–energy equivalence (e=mc^2), there is Intelligence-Agency equivalence (any agent is in a way time-like and can be represented in a more space-like fashion, ideally as a completely “frozen” static place, places or tools).
In a nutshell, an LLM is a bunch of words and vectors between them - a static geometric shape, we can probably expose it all in some game and make it fun for people to explore and learn. To let us explore the library itself easily (the internal structure of the model) instead of only talking to a strict librarian (the AI agent), who spits short quotes and prevents us from going inside the library itself
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-02T18:06:36.133Z · LW(p) · GW(p)
Hmm i think i get you a bit better now. You want to build human-friendly and even fun and useful-by-themselves interfaces for looking at the knowledge encoded in LLMs without making them generate text. Intriguing.
Replies from: ank↑ comment by ank · 2025-03-02T18:15:20.163Z · LW(p) · GW(p)
Yes, I want humans to be the superpowerful “ASI agents”, while the ASI itself will be the direct democratic simulated static places (with non-agentic simple algorithms doing the dirty non-fun work, the way it works in GTA3-4-5). It’s basically hard to explain without writing a book and it’s counterintuitive) But I’m convinced it will work, if the effort will be applied. All knowledge can be represented as static geometry, no agents are needed for that except us
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-02T18:31:28.297Z · LW(p) · GW(p)
How can a place be useful if it is static? For reference I'm imagining a garden where blades of grass are 100% rigid in place and water does not flow. I think you are imagining something different.
Replies from: ank↑ comment by ank · 2025-03-02T22:26:38.659Z · LW(p) · GW(p)
Great question, in the most elegant scenario, where you have a whole history of the planet or universe (or a multiverse, let's go all the way) simulated, you can represent it as a bunch of geometries (giant shapes of different slices of time aligned with each other, basically many 3D Earthes each one one moment later in time) on top of each other, almost the same way it's represented in long exposure photos (I list examples below). So you have this place of all-knowing and you - the agent - focus on a particular moment (by "forgetting" everything else), on a particular 3d shape (maybe your childhood home), you can choose to slice through 3d frozen shapes of the world of your choosing, like through the frames of a movie. This way it's both static and dynamic.
It's a little bit like looking at this almost infinite static shape through some "magical cardboard with a hole in it" (your focusing/forgetting ability that creates the illusion of dynamism), I hope I didn't make it more confusing.
You can see the whole multiversal thing as a fluffy light, or zoom in (by forgetting almost the whole multiverse except the part you zoomed in at) to land on Earth and see 14 billion years as a hazy ocean with bright curves in the sky that trace the Sun’s journey over our planet’s lifetime. Forget even more and see your hometown street, with you appearing as a hazy ghost and a trace behind you showing the paths you once walked—you’ll be more opaque where you were stationary (say, sitting on a bench) and more translucent where you were in motion.
And in the garden you'll see the 3D "long exposure photo" of the fluffy blades of grass, that look like a frothy river, near the real pale blue frothy river, you focus on the particular moment and the picture becomes crisp. You choose to relive your childhood and it comes alive, as you slice through the 3D moments of time once again.
Less elegant scenario, is to make a high-quality game better than the Sims or GTA3-4-5, without any agentic AIs, but with advanced non-agentic algorithms.
Basically I want people to remain the fastest time-like agents, the ever more all-powerful ones. And for the AGI/ASI to be the space-like places of all-knowing. It's a bit counterintuitive, but if you have billions of humans in simulations (they can always choose to stop "playing" and go out, no enforcement of any rules/unfreedoms on you is the most important principle of the future), you'll have a lot of progress.
I think AI and non-AI place simulations are much more conservative thing than agentic AIs, they are relatively static, still and frozen, compared to the time-like agents. So it's counterintuitive, but it's possible get all the proggress we want with the non-agentic tool AIs and place AIs. And I think any good ASI agent will be building the direct democratic simulated multiverse (static place superintelligence) for us anyway.
There is a bit of some simple physics behind agentic safety:
- Time of Agentic Operation: Ideally, we should avoid creating perpetual agentic AIs, or at least limit their operation to very short bursts initiated by humans, something akin to a self-destruct timer that activates after a moment of time.
- Agentic Volume of Operation: It’s better to have international cooperation, GPU-level guarantees, and persistent training to prevent agentic AIs from operating in uninhabited areas like remote islands, Antarctica, underground or outer space. Ideally, the volume of operation is zero, like in our static place AI.
- Agentic Speed or Volumetric Rate: The volume of operation divided by the time of operation. We want AIs to be as slow as possible. Ideally, they should be static. The worst-case scenario—though probably unphysical (though, in the multiversal UI, we can allow ourselves to do it)—is an agentic AI that could alter every atom in the universe instantaneously.
- Number of Agents: Humanity's population according to the UN will not exceed 10 billion, whereas AIs can replicate rapidly. A human child is in a way a "clone" of 2 people, and takes ±18 years to raise. In a multiversal UI we can one day choose to allow people to make clones of themselves (they'll know that they are a copy but they'll be completely free adults with the same multiversal powers and will have their own independent fates), this way we'll be able to match the speed of agentic AI replication.
Examples of long-exposure photos that represent long stretches of time. Imagine that the photos are in 3d and you can walk in them, the long stretches of time are just a giant static geometric shape. By focusing on a particular moment in it, you can choose to become the moment and some person in it. This can be the multiversal UI (but the photos are focusing on our universe, not multiple versions/verses of it all at once): Germany, car lights and the Sun (gray lines represent the cloudy days with no Sun)—1 year of long exposure. Demonstration in Berlin—5 minutes. Construction of a building. Another one. Parade and other New York photos. Central Park. Oktoberfest for 5 hours. Death of flowers. Burning of candles. Bathing for 5 minutes. 2 children for 6 minutes. People sitting on the grass for 5 minutes. A simple example of 2 photos combined—how 100+ years long stretches of time can possibly look 1906/2023
Replies from: weibac↑ comment by Milan W (weibac) · 2025-03-03T21:37:48.354Z · LW(p) · GW(p)
Let me summarize so I can see whether I got it: So you see "place AI" as body of knowledge that can be used to make a good-enough simulation of arbitrary sections of spacetime, where are events are precomputed. That precomputed (thus, deterministic) aspect you call "staticness".
Replies from: ank↑ comment by ank · 2025-03-03T23:32:18.684Z · LW(p) · GW(p)
Yes, I decided to start writing a book in posts here and on Substack, starting from the Big Bang and the ethics, because else my explanations are confusing :) The ideas themselves are counterintuitive, too. I try to physicalize, work from first principles and use TRIZ to try to come up with ideal solutions. I also had a 3-year-long thought experiment, where I was modeling the ideal ultimate future, basically how everything will work and look, if we'll have infinite compute and no physical limitations. That's why some of the things I mention will probably take some time to implement in their full glory.
Right now an agentic AI is a librarian, who has almost all the output of humanity stolen and hidden in its library that it doesn't allow us to visit, it just spits short quotes on us instead. But the AI librarian visits (and even changes) our own human library (our physical world) and already stole the copies of the whole output of humanity from it. Feels unfair. Why we cannot visit (like in a 3d open world game) and change (direct democratically) the AI librarian's library?
I basically want to give people everything, except the agentic AIs, because I think people should remain the most capable "agentic AIs", else we'll pretty much guarantee uncomfortable and fast changes to our world.
There are ways to represent the whole simulated universe as a giant static geometric shape:
- Each moment of time is a giant 3d geometric shape of the universe, if you'll align them on top of each other, you'll effectively get a 4d shape of spacetime that is static but has all the information about the dynamics/movements in it. So the 4d shape is static but you choose some smaller 3d shape inside of it (probably of a human agent) and "choose the passage" from one human-like-you shape to another, making the static 4d shape seem like the dynamic 3d shape that you experience.
The whole 4d thing looks very similar to the way long exposure photos look that I shared somewhere in my comments to the current post.
It's similar to the way a language model is a static geometric shape (a pile of words and vectors between them) but "the prompt/agent/GPU makes it dynamic" by computing the passage from word to word.
This approach is useful because this way we can keep "a blockchain" of moments of time and keep our history preserved for posterity. Instead of having tons of GPUs (for computing the AI agents' choices and freedoms, the time-like, energy-like dynamic stuff), we can have tons of hard drives (for keeping the intelligence, the space-like, matter-like static stuff), that's much safer, as safe as it gets.
-
Or we can just go the familiar road by making it more like an open world computer game without any AI agents of course, just sophisticated algorithms like in modern games, in this case it's not completely static
-
And find ways to expose the whole multimodal LLM to the casual gamers/Internet users as a 3d world but with some familiar UI
I think if we'll have: the sum of freedoms of agentic AIs > the sum of freedoms of all humans, - we'll get in trouble. And I'm afraid we're already ~10-50% there (wild guess, I probably should count it). Some freedoms are more important, like the one to keep all the knowledge in your head, AI agents have it, we don't.
We can get everything with tool AIs and place AIs. Agentic AIs don't do any magic that non-agentic AIs don't, they just replace us :)
The ideal ASI just delivers you everything instantly: a car, a world, a 100 years as a billionaire, we can get all of that in the multiversal static place ASI, with the additional benefit of being able to walk there and see all the consequences of our choices. The library is better than the strict librarian. The artificial heavens are better than the artificial "god". In fact you don't need the strict librarians and the artificial "god" at all to get everything.
The ideal ASI will be building the multiversal static place ASI for us anyway, but it will do it too quickly, without listening and understanding us as much as we want (it's an unnecessary middleman, we can do it all direct democratically, somewhat like people build worlds in Minecraft) and with spooky mistakes
Thank for your questions and thoughts, they're always helpful!
P.S. If you think that it's possible to deduce something about our ultimate future, you may find this tag interesting :) And I think the story is not bad: https://www.lesswrong.com/w/rational-utopia [? · GW]
No comments
Comments sorted by top scores.