Cartesian Boundary as Abstraction Boundary
post by johnswentworth · 2020-06-11T17:38:18.307Z · LW · GW · 3 commentsContents
Programs Cartesian Boundary Implications Imperfect Knowledge of Inputs Flexible Boundaries None 3 comments
Meta note: this post involves redefining several concepts in ways almost, but not quite, the same as their usual definitions - risking quite a bit of confusion. I'm open to suggestions for better names for things.
Intuition: a model of humans (or AIs, or other agenty things) as “agents” separate from their “environment” only makes sense at a zoomed-out, abstract level. When we look at the close-up details, the agent-environment distinction doesn’t exist; there is no “Cartesian boundary” with interactions between the two sides mediated by well-defined input/output channels.
Meanwhile, back in the lab, some guy [LW · GW] has been talking about a general formalization of abstraction [? · GW]. Elevator pitch version: far-apart components of a low-level model are independent given some high-level summary data. For example, the dynamics of the plasmas in far-apart stars are approximately independent given some high-level summary of each star - specifically its total mass, momentum and center-of-mass position. The low-level model includes full plasma dynamics; the high-level abstract model just includes one point mass representing each star.
This notion of abstraction sounds like it should fit our intuition about agency: we model humans/AIs/etc as agents in some high-level model, but not necessarily in the underlying low-level model.
This post will flesh out that idea a bit. It will illustrate the general picture of an abstraction boundary serving as a Cartesian boundary for a high-level agent model.
Programs
To avoid prematurely dragging in confusing intuitions about agency, we’ll start by talking about a program running on a laptop.
The source code of a program specifies exactly what it should do at a high level; it specifies the abstract model. It does not specify the low-level behavior, e.g. machine code and register addresses, or precise voltages in each transistor at each time, or the physical layout of circuit components on the CPU. The job of compiler/operating system writers and electrical engineers is to design and implement a low-level system which correctly abstracts into the high-level model specified by the source code. We’ll call the whole system for implementing programs out of atoms a “compiler stack”; it includes not just compilers, but also the physical hardware on which a program runs. It’s an end-to-end tool for turning source code into physical behavior.
What does it mean, mathematically, to design such a compiler stack? How do we formalize that problem?
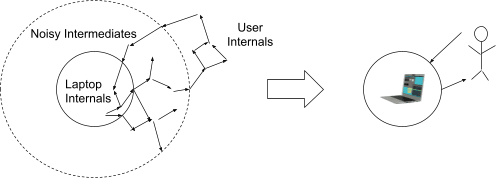
Well, we have a model of the whole world, and we’d like to factor out two high-level components: the system (i.e. program running on a laptop) and everything “far away” from the system. In between will be lots of noisy variables which mediate interactions between these two components - air molecules, communication infrastructure, etc. Those noisy intermediates will wipe out most information about low-level details: things far away from the laptop won’t be able to detect precise voltages in individual transistors, and the laptop itself won’t be able to detect positions of individual molecules in far-away objects (though note that our notion of “far away” can be adjusted to account for e.g. fancy sensors; it need not be physical distance). With the noisy intermediates wiping out all that low-level detail, the laptop’s behavior will depend only on some high-level summary data about things far away, and the behavior of things far away will depend only on some high-level summary data about the laptop.
The high-level summaries typically go by special names:
- The high-level summary containing information about the laptop which is relevant to the rest of the world is called “output”.
- The high-level summary containing information about the rest of the world which is relevant to the laptop is called “input”.
The goal of the compiler stack is to make the output match the specification given by the source code, on any input, while minimizing side-channel interaction with the rest of the world (i.e. maintaining the abstraction boundary).
For instance, let’s say I write and run a simple python script:
x = 12
print(5*x + 3)This script specifies a high-level behavior - specifically, the number “63” appearing on my screen. That’s the part visible from “far away” - i.e. visible to me, the user. The rest is generally invisible: I don’t observe voltages in specific transistors, or values in registers, or machine code, or …. Of course I could open up the box and observe those things, but then I’d be breaking the abstraction. In general, when some aspect of the executing program is externally-visible besides the source-code-specified high-level behavior, we say that the abstraction is leaking. The point of a compiler stack is to minimize that leakage: to produce a system which yields the specified high-level input-output behavior, with minimal side-channel interaction with the world otherwise.
Cartesian Boundary
Applying this to agents is trivial: just imagine the source code specifies an agenty AI.
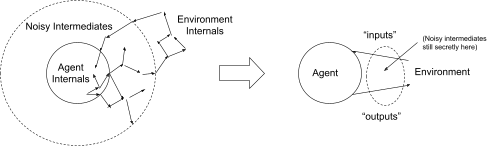
More generally, to model a real-world system as an agent with a Cartesian boundary, we can break the world into:
- The system itself (the “agent”)
- Things “far away” from the system (the “environment”)
- Noisy variables intermediating interactions between the two, which we ignore (i.e. integrate out of the model)
The noisy intermediates wipe out most of the low-level information about the two components, so only some high-level summary data about the agent is relevant to the environment, and only some high-level summary data about the environment is relevant to the agent. We call the agent’s high-level summary data “actions”, and we call the environment’s high-level summary data “observations”.
Implications
This is not identical to the usual notion of agency used in decision theory/game theory. I’ll talk about a couple differences, but these ideas are still relatively fresh so there’s probably many more.
Imperfect Knowledge of Inputs
One potentially-surprising implication of this model: the “inputs” are not the raw data received by the agent; they’re perhaps more properly thought of as “outputs of the environment” than “inputs of the agent”. In the traditional Cartesian boundary model, these coincide - i.e. the traditional model is an exact abstraction [? · GW], without any noisy intermediates between agent and environment. But in this model, the “channel” between environment-outputs and agent-incoming-data is noisy and potentially quite complicated in its own right.
The upshot is that, under this model, agents may not have perfect knowledge of their own inputs.
This idea isn’t entirely novel. Abram has written before [LW · GW] about agents being uncertain about their own inputs, and cited some previous literature on the topic, under the name "radical probabilism".
Note that we could, in principle, still define “inputs” in the more traditional way, as the agent's incoming data. But then we don’t have as clean a factorization of the model; there is no natural high-level object corresponding to the agent’s incoming data. Alternatively, we could treat the noisy intermediates as themselves part of the environment, but this conflicts with the absence of hard boundaries around real-world agenty systems.
Flexible Boundaries
I’ve said [LW(p) · GW(p)] before:
I expect the "boundary" of an agent to be fuzzy on the "inputs" side, and less fuzzy but still flexible on the "outputs" side. On the inputs side, there's a whole chain of cause-and-effect which feeds data into my brain, and there's some freedom in whether to consider "me" to begin at e.g. the eye, or the photoreceptor, or the optic nerve, or... On the outputs side, there's a clearer criterion for what's "me": it's whatever things I'm "choosing" when I optimize, i.e. anything I assume I control for planning purposes. That's a sharper criterion, but it still leaves a lot of flexibility - e.g. I can consider my car a part of "me" while I'm driving it.
The Cartesian-boundary-as-abstraction-boundary model fits these ideas quite neatly.
(Potential point of confusion: that quote uses “input/output” in the usual Cartesian boundary sense of the words, not in the manner used in this post. I’ll use the phrase “incoming data” to distinguish what-data-reaches-the-agent from the environment-summary-data.)
We model the agent as using the agent-environment abstraction to model itself. It has preferences over the environment-summary (the “inputs”), and optimizes the agent-summary (the “outputs”). But exactly what chunk-of-the-world is called “the agent” is flexible - if I draw the boundary right outside of my eye/my photoreceptors/my optic nerve, all three of those carry mostly-similar information about far-away things, and all three will likely imply very similar high-level summaries of the environment. So the overall model is relatively insensitive to where the boundary is drawn on the incoming-data side.
But the output side is different. That’s not because the model is more sensitive to the boundary on the output side, but because the output itself is an object in the high-level model, while incoming data is not; the high-level model contains the environment-summary and the outputs, but not the agent’s incoming data.
In other words: the high-level agent-environment model is relatively insensitive to certain changes in where the boundary is drawn. As a result, objects which live in the low-level model (e.g. the agent’s incoming data) lack a sharp natural definition, whereas objects which live in the high-level model (e.g. the “inputs”=environment summary and “outputs”=agent summary) are more sharply defined.
This goes back to the basic problem of defining “inputs”: there is no high-level object corresponding to the agent’s incoming data. That incoming data lives only in the low-level model. The high-level model just contains the environment-summary.
3 comments
Comments sorted by top scores.
comment by Gordon Seidoh Worley (gworley) · 2020-06-12T21:31:15.763Z · LW(p) · GW(p)
Lately I've been thinking a bit about why programmers have preferences for different programming languages. Like, why is it that I want a language that is (speaking informally)
- flexible (lets me do things many ways)
- dynamic (decides what to do at run time rather than compile time)
- reflexive (let's me change the program source while it's running, or change how to interpret a computation)
and other people want the opposite:
- rigid (there's one right way to do something)
- static (decides what to do at compile time, often so much so that static analysis is possible)
- fixed (the same code is guaranteed to always behave the same way no matter the execution context)
And I think a reasonable argument might be a difference in how much different programmers value the creation of a Cartesian boundary in the language, i.e. how much they want to be able to reason about the program as if it existed outside the execution environment. My preference is to move along the "embedded" end of a less-to-more Cartesian-like abstraction dimension of program design, preferring abstractions that, if not less hide the underlying structure, then at least more make it accessible.
This might not be perfect as I'm babbling a bit to try to build out my model of what the difference in preference comes from, but seems kind of interesting and a possible additional example of where this kind of Cartesian-like boundary gets created.
Replies from: Pattern, TAG