Sensor Exposure can Compromise the Human Brain in the 2020s
post by trevor (TrevorWiesinger) · 2023-10-26T03:31:09.835Z · LW · GW · 6 commentsContents
Overview
This problem is fundamental to intelligent civilizations
The attack surface is far too large
Like it or not, the movement of scrolling past a piece of information with a mouse wheel or touch screen will generate at least one curve, and the trillions of those curves are outputted each day by billions of people. These curves are linear algebra, the perfect shape to plug into ML.
The information environment might be adversarial
The solutions are easy
None
6 comments
Overview
The 20th century was radically altered by the discovery of psychology, a science of the human mind, and its exploitation (e.g. large-scale warfare, propaganda, advertising, information/hybrid warfare, decision theory/mutually assured destruction).
However, it's reasonable to think that the 20th century would have been even further transformed if the science and exploitation of the human mind was even further advanced than it already was.
I'm arguing here that, in an era of mass surveillance, hybrid/cognitive warfare between the US and China and Russia, and substantial ML advancements, it is also reasonable to think that the situation with SOTA human cognitive analysis and exploitation may already be threatening the continuity of operations of the entire AI safety community; and if not now, then likely at some point during the 2020s, which will probably be much more globally eventful than the pace that humanity became accustomed to in the previous two decades.
AI will be the keys to those kingdoms, and the wars between them. If demanding a development pause might be the minimum ask for humanity to survive, and for a conflict like that, we won't even know what hit us [LW · GW].
The attack surface is unacceptably large for human life in general, let alone for the AI safety community, a community of nerds who chanced upon the engineering problem that the fate of this side of the universe revolves around, and a community that absolutely must not fail to survive the 2020s, nor to limp on in a diminished/captured form.
This problem is fundamental to intelligent civilizations
If there were intelligent aliens, made of bundles of tentacles or crystals or plants that think incredibly slowly, their minds would also have discoverable exploits/zero days, because any mind that evolved naturally would probably be like the human brain, a kludge of spaghetti code that is operating outside of its intended environment.
They would probably not even begin to scratch the surface of finding and labeling those exploits, until, like human civilization today, they began surrounding thousands or millions of their kind with sensors that could record behavior several hours a day and find webs of correlations [LW · GW].
In the case of humans, the use of social media as a controlled environment for automated AI-powered experimentation appears to be what created that critical mass of human behavior data.
The capabilities of social media to steer human outcomes are not advancing in isolation, they are parallel to a broad acceleration in the understanding and exploitation of the human mind, which itself is a byproduct of accelerating AI capabilities research.
By comparing people to other people and predicting traits and future behavior, multi-armed bandit algorithms can predict whether a specific manipulation strategy is worth the risk of undertaking at all in the first place; resulting in a high success rate and a low detection rate (as detection would likely yield a highly measurable response, particularly with substantial sensor exposure such as uncovered webcams, due to comparing people’s microexpressions to cases of failed or exposed manipulation strategies, or working webcam video data into foundation models).
When you have sample sizes of billions of hours of human behavior data and sensor data, millisecond differences in reactions from different kinds of people (e.g. facial microexpressions, millisecond differences at scrolling past posts covering different concepts, heart rate changes after covering different concepts, eyetracking differences after eyes passing over specific concepts, touchscreen data, etc) transform from being imperceptible noise to becoming the foundation of webs of correlations [LW · GW]. The NSA stockpiles exploits in every operating system and likely chip firmware as well, so we don’t have good estimates on how much data is collected and anyone who tries to get a good estimate will probably fail. The historical trend was that there’s a lot of malevolent data collection and that the people who underestimated the NSA were wrong every time. Furthermore, this post details a very strong case that they are incredibly incentivized to tap those sensors.
Even if the sensor data currently being collected isn’t already enough to compromise people, it will probably suddenly become sufficient at some point during the 2020s or slow takeoff.
The central element of the modern behavior manipulation paradigm is the ability to just try tons of things and see what works; not just brute forcing variations of known strategies to make them more effective, but to brute force novel manipulation strategies in the first place. This completely circumvents the scarcity and the research flaws that caused the replication crisis which still bottlenecks psychology research today.
Social media’s individualized targeting uses deep learning to yield an experience that fits human mind like a glove, in ways we don't fully understand, but allow hackers incredible leeway to find ways to steer people’s thinking in measurable directions, insofar as those directions are measurable. AI can even automate that.
In fact, original psychological research in human civilization is no longer as bottlenecked on the need for smart, insightful people who can do hypothesis generation so that the finite studies you can afford to fund each hopefully find something valuable. With the current social media paradigm alone, you can run studies, combinations of news feed posts for example, until you find something useful. Measurability is critical for this.
I can’t know what techniques a multi-armed bandit algorithm will discover without running the algorithm itself; which I can’t do, because that much data is only accessible to the type of people who buy servers by the acre, and even for them, the data is monopolized by the big tech companies (Facebook, Amazon, Microsoft, Apple, and Google) and intelligence agencies that are large and powerful enough to prevent hackers from stealing and poisoning the data (NSA, etc). There are plenty of people who have tried and failed to acquire these capabilities, but that is only a weak update, since failure is provably the default outcome for people who are late to the party on this.
I also don’t know what multi-armed bandit algorithms will find when people on the team are competent psychologists, spin doctors, or other PR experts interpreting and labeling the human behavior in the data so that the human behavior can become measurable. It’s reasonably plausible that the industry would naturally reach an equilibrium where the big 5 tech companies compete to gain sophistication at sourcing talent for this research while minimizing risk of Snowden-style leaks, similar to the NSA’s “reforms” after the Snowden revelations 10 years ago. That is the kind of bottleneck that you can assume people automatically notice and work on. Revolving door employment between tech companies and intelligence agencies also circumvents the intelligence agency competence problem [LW · GW].
Human insight from just a handful of psychological experts can be more than enough to train AI to work autonomously; although continuous input from those experts would be needed and plenty of insights, behaviors, and discoveries would fall through the cracks and take an extra 3 years or something to be discovered and labeled.
There’s just a large number of human manipulation strategies that are trivial to discover and exploit, even without AI (although the situation is far more severe when you layer AI on top), it’s just that they weren’t accessible at all to 20th century institutions and technology such as academic psychology.
If they get enough data on people who share similar traits to a specific human target, then they don’t have to study the target as much to predict the target’s behavior, they can just run multi-armed bandit algorithms on those people to find manipulation strategies that already worked on individuals who share genetic or other traits.
Although the average Lesswrong user is much further out-of-distribution relative to the vast majority of people in the sample data, this becomes a technical problem, as AI capabilities and compute become dedicated to the task of sorting signal from noise and finding webs of correlation with less data. Clown attacks alone have demonstrated that social-status based exploits in the brain are fairly consistent among humans [LW · GW], indicating that sample data from millions or billions of people is usable to find a wide variety of exploits in the human brains that make up the AI safety community.
The attack surface is far too large
The lack of awareness of this is a security risk, like using the word “password” as your password, except with control of your own mind at stake rather than control over your computer’s operating system and/or your files. This has been steelmanned; the 10 years ago/10 years from now error bars seem appropriately wide.
There isn’t much point in having a utility function in the first place if hackers can change it at any time. There might be parts that are resistant to change, but it’s easy to overestimate yourself on this; for example, if you value the longterm future and think that no false argument can persuade you otherwise, but a social media news feed plants misgivings or distrust of Will Macaskill, then you are one increment closer to not caring about the longterm future; and if that doesn’t work, the multi-armed bandit algorithm will keep trying until it finds something that works, and iterate.
There are tons of clever ways for attackers who understand the human brain better than you to find your complex and deeply personal internal conflicts based on comparison to similar people, and resolve them on the attacker’s terms. The human brain is a kludge of spaghetti code, so there’s probably something somewhere.
The human brain has exploits, and the capability and cost of social media platforms to use massive amounts of human behavior data to find complex social engineering techniques is a profoundly technical matter, you can’t get a handle on this with intuition and pre 2010s historical precedent.
Thus, you should assume that your utility function and values are at risk of being hacked at an unknown time, and should therefore be assigned a discount rate to account for the risk over the course of several years. Slow takeoff over the course of the next 10 years alone guarantees that this discount rate is too high in reality for people in the AI safety community to continue to go on believing that it is something like zero.
I think that approaching zero is a reasonable target, but not with the current state of affairs where people don’t even bother to cover up their webcams, have important and sensitive conversations about the fate of the earth in rooms with smartphones, and use social media for nearly an hour a day (scrolling past nearly a thousand posts).
Like it or not, the movement of scrolling past a piece of information with a mouse wheel or touch screen will generate at least one curve, and the trillions of those curves are outputted each day by billions of people. These curves are linear algebra, the perfect shape to plug into ML.

The discount rate in this environment cannot be considered “reasonably” close to zero if the attack surface is this massive; and the world is changing this quickly.
Everything that we’re doing here is predicated on the assumption that powerful forces, like intelligence agencies, will not disrupt the operations of the community e.g. by inflaming factional conflict with false flag attacks attributed to each other due to the use of anonymous proxies.
If people have anything they value at all [LW · GW], and the AI safety community probably does have that, then the current AI safety paradigm of zero effort is wildly inappropriate, it’s basically total submission to invisible hackers.
The information environment might be adversarial
The big bottleneck that I suspect caused AI safety to completely drop the ball on this is that the the AI alignment community in the Bay Area have the technical capabilities to intuitively understand that humans can be manipulated by AI given an environment optimized for thought analysis and experimentation, like a social media news feed, but think that intelligence agencies and the big 5 tech companies would never actually do something like that. Meanwhile, the AI policy community in DC knows that powerful corporations and government agencies routinely stockpile capabilities like this because they know they can get away with it and mitigate the damage if they don’t, and that these capabilities come in handy in international conflicts like the US-China conflict, but they lack the quant skills required to intuitively see how the human mind could be manipulated with SGD (many wouldn’t even recognize the acronym “SGD” so I’m using “AI” instead).
This problem might have been avoided if the SF math nerds and the DC history nerds would mix more, but unfortunately it seems like the history nerds have terrible memories of math class and the math nerds have terrible memories of history class.
In this segregated and malnourished environment, bad first impressions of “mind control” dominate [LW · GW], instead of logical reasoning and serious practical planning for slow takeoff.
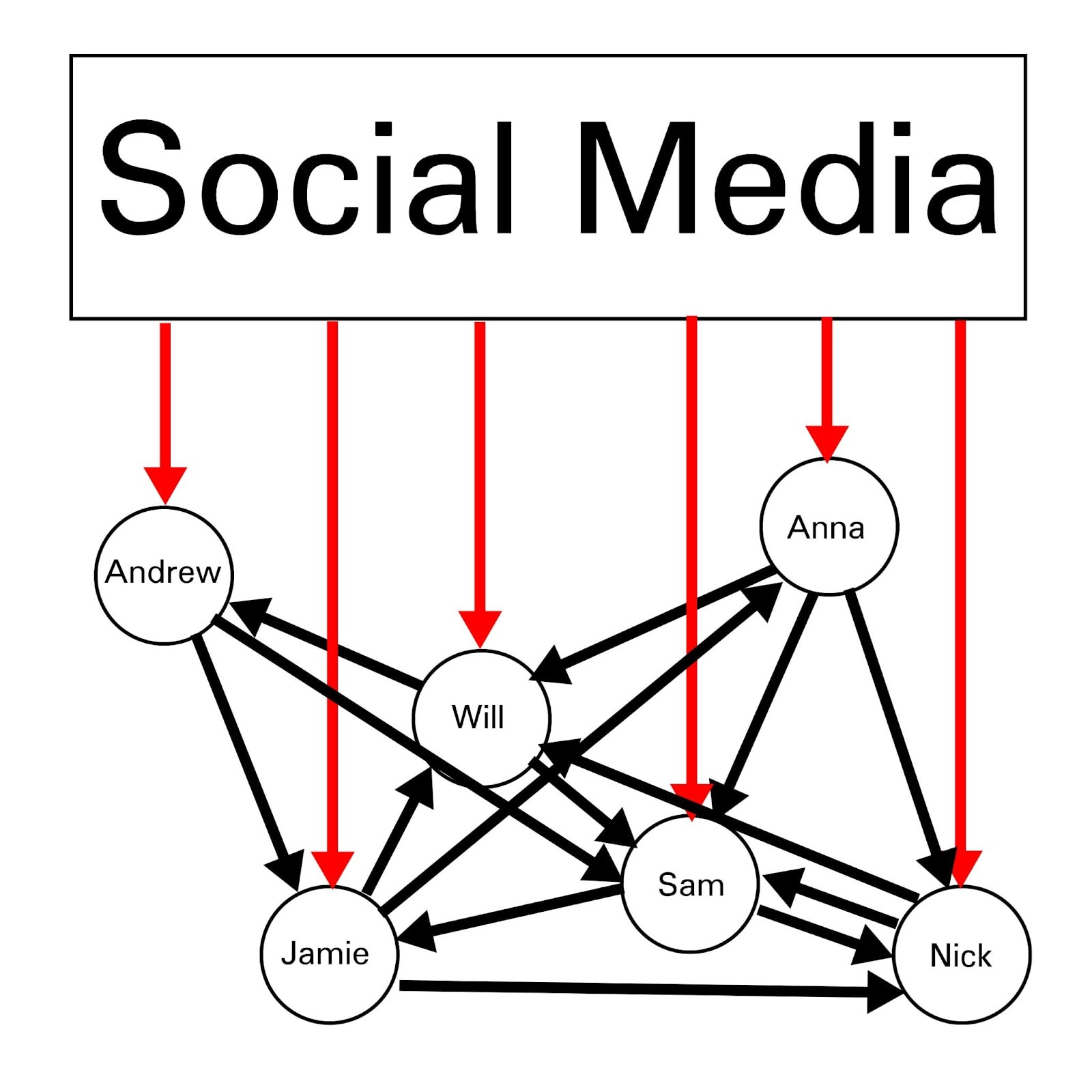
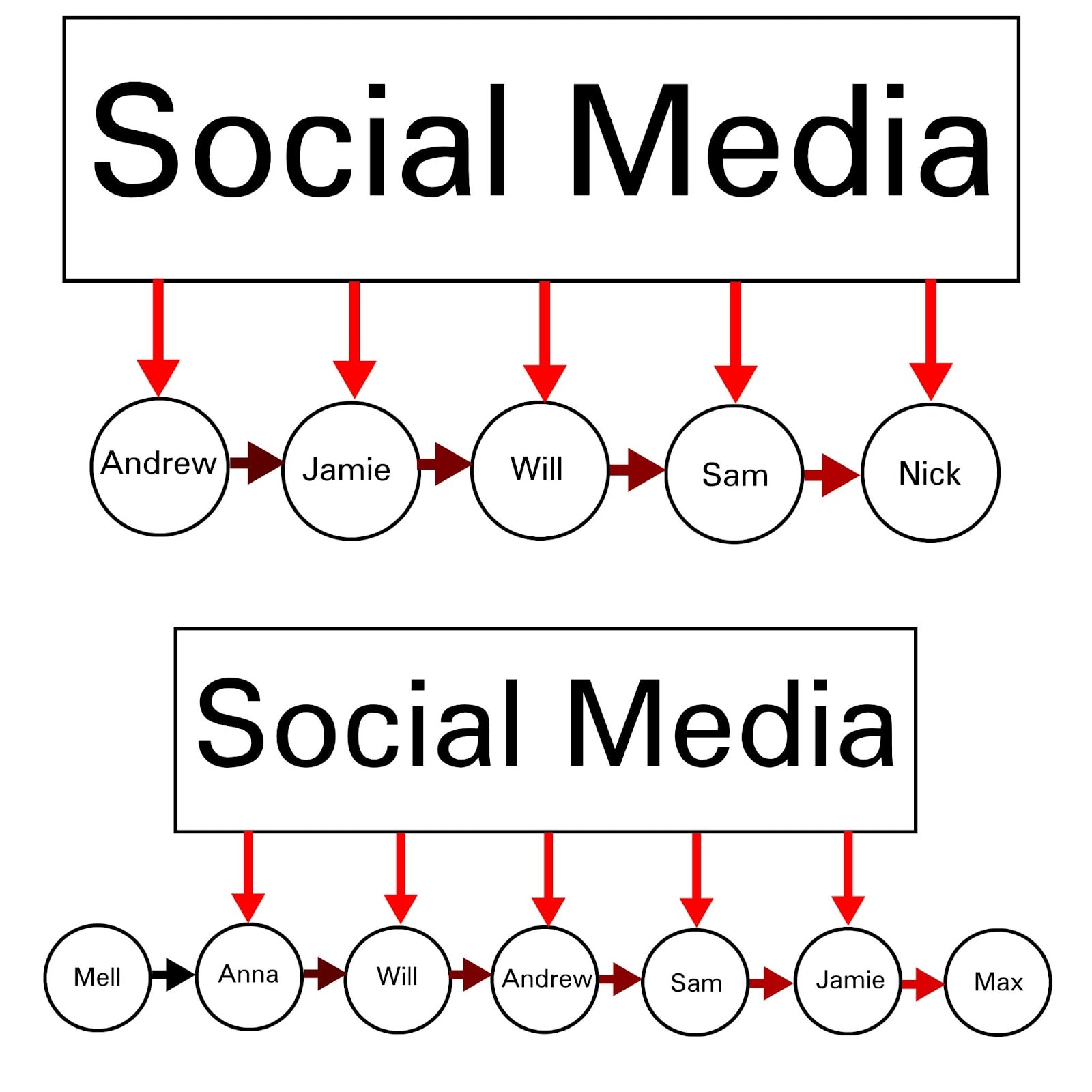
And if anything could be manipulated by the social media-based paradigm I've described, it would be impressions and the process of human impression-formation as there is a lot of data on that. And if anything would be manipulated by social media, it would be attitudes about social media compromising the human brain, because SGD/AI would automatically select for galaxy-brained combinations of news feed posts that correspond to cases of people continuing to use social media, and avoid combinations of posts that correspond to cases of people quitting social media. There are billions of those cases of people leaving vs staying.
Keeping people on social media is instrumental for any goal, from preparing for military hybrid warfare contingency plans featuring information warfare between the US and China, to just running a business where people don’t leave your platform.
This is especially the case if there is a race to the bottom to compete for user’s time against other platforms, like Tiktok or Instagram Reels, that are less squeamish about utilizing AI/SGD to maximize zombie-brain engagement and user retention.
We should be assuming by default that the modern information environment is adverse, and that some topics are more adversarial than others e.g. the Ukraine War and COVID which have intense geopolitical significance. I'm arguing here that information warfare itself is a topic that as intense geopolitical significance, and therefore should be expected to also be an adversarial information environment.
In an adversarial information environment, impressions are more likely to be compromised than epistemics as a whole, as the current paradigm is optimized for that due to better data quality. We should therefore be approaching sensor exposure risks with deliberate analysis and forecasting rather than vague surface-level impressions.
The solutions are easy
Eyetracking is likely the most valuable user data ML layer for predictive analytics and sentiment analysis and influence technologies in general, since the eyetracking layer is only two sets of coordinates that map to the exact position that each eye is centered on the screen at each millisecond (one for each eye, since millisecond-differences in the movement of each eye might also correlate with valuable information about a person’s thought process).
This compact data allows deep learning to “see”, with millisecond-precision, exactly how long a human’s eyes/brain linger on each word and sentence. Notably, sample sizes of millions of these coordinates might be so intimately related to the human thought process that value of eyetracking data might exceed the value of all other facial muscles combined (facial muscles, the originator of all facial expressions and emotional microexpression, might also be compactly reducible via computer vision [LW · GW] as there are fewer than 100 muscles near the face and most of them have a very bad signal to noise ratio, but not nearly as efficiently as eyetracking).
If LK99 replicated and handheld fMRI became buildable, then maybe that could contend for the #1 slot; or maybe I’m foolishly underestimating the overwhelming superiority of plugging audio conversation transcripts into LLMs and automatically labeling the parts of the conversation that the speakers take the most seriously by timestamping small heart rate changes.
However, running networking events without smartphones nearby is hard, and covering up webcams is easy, even if some phones require some engineering creativity with masking tape and a tiny piece of aluminum foil.
Webcam-covering rates might be a good metric for how well the AI safety community is doing on surviving the 2020s. Right now it is "F".
There are other easy policy proposals that might be far more important, depending on difficult-to-research technical factors that determine which parts of the attack surface are the most dangerous:
- Stop spending hours a day inside hyperoptimized vibe/impression hacking environments (social media news feeds).
- It’s probably a good idea to switch to physical books instead of ebooks. Physical books do not have operating systems or sensors. You can also print out research papers and Lesswrong and EAforum articles that you already know are probably worth reading or skimming. PC’s have accelerometers on the motherboard which afaik are impossible to remove or work around, even if you remove the microphone and use a USB keyboard and use hotkeys instead of a mouse the accelerometers might be able to act as microphones and pick up changes in heart rate.
- Use arrow keys to scroll instead of touch screens or mouse wheels. If there are sample sizes of billions of mouse wheel or touch screen movements, then advanced human behavior analysis and comparison (e.g. in response to specific concepts) will become possible in less than a minute.
- It’s probably best to avoid sleeping in the same room as a smart device, or anything with sensors, an operating system, and also a speaker. The attack surface seems large, if the device can tell when people’s heart rate is near or under 50 bpm, then it can test all sorts of things [LW · GW]. Just drive to the store and buy a clock.
- Reading the great rationality texts will probably reduce your predictability coefficient [LW · GW], but it won’t reliably patch “zero days” in the human brain.
6 comments
Comments sorted by top scores.
comment by dain · 2024-01-21T13:44:36.565Z · LW(p) · GW(p)
The points and warnings in this article would generalise to the wider population, I'm not sure if the strict AI safety researcher angle is necessary.
It also sounds like you acknowledge that even with existing, cheaper to capture and process signals (scrolling, dwelling, engagement, accelerometer, etc) it's possible to build a very detailed profile, so even without speculating about covert webcam and microphone access, the threat is there and is more immediately important to acknowledge and take steps to mitigate by forgoing centralised, large scale social media as much as possible with immediate effect.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2024-01-21T16:56:21.593Z · LW(p) · GW(p)
That would actually decimate the big 5 American tech companies while leaving their Chinese counterparts in China largely intact. That doesn't seem like a good timeline so I never advocate for it.
Replies from: dain↑ comment by dain · 2024-01-21T22:11:57.261Z · LW(p) · GW(p)
I'm not quite sure if centralised social media sites being boycotted by AI safety researchers or even the entire Lesswrong readership will decimate Big Tech.
But even if you somehow managed to convice billions of people to decide to join the boycott and actually stick to it, social networks could rein back algorithmic curation of feeds and get people back on after reassuringly demonstrating a simple time based feed of posts by people you follow, maybe with optional filters.
Also, even if centralised social media doesn't implement any sensor tracking and analysis, it's pretty solid advice for people to try to avoid spending too much time on it for various reasons, especially if they have important, highly cognitive jobs.
That said, AI safety researchers (and everyone else) can benefit from networking, but a dedicated Mastodon server or other independent, community run, open source network can have all the benefits without the massive downsides.
So my point is, rather than trying to speculate about advanced algorithmic manipulation and how to mitigate it, a much simpler solution is to shift away time and attention from centralised social networks. Oh, and install various ad blockers and other privacy preserving and tracking prevention browser extensions and stop using official social network mobile apps that don't make this filtering possible. These actions would also protect people from whichever geopolitical or criminal power is trying to manipulate and exploit them.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2024-01-22T00:35:10.378Z · LW(p) · GW(p)
but a dedicated Mastodon server or other independent, community run, open source network can have all the benefits without the massive downsides.
Good news: we are discussing this on just such a network right now! While more such things might be beneficial, this one ain't so shabby itself.
comment by ProgramCrafter (programcrafter) · 2023-11-04T19:13:13.595Z · LW(p) · GW(p)
It’s probably best to avoid sleeping in the same room as a smart device, or anything with sensors, an operating system, and also a speaker.
I think it's best tested! Just direct a webcam/microphone on the phone with recording left on (if cable is long enough, computer may even be located in another room).
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2023-11-04T19:33:51.587Z · LW(p) · GW(p)
I think this is the right frame of mind, and might even deter technology being used in this way if enough people do it due to the risk of it getting leaked at some point from the agency/hacker failing to perform a basic check for unusual activity or unusual devices they didn't expect.
An analog tape recorder would be much better, but still, the thing that makes this substantially positive EV is protecting the AI safety community, and there aren't enough people in the AI safety community for it to be worthwhile to deter intelligence agencies in this way. I might be wrong about this if you think of something better, but right now it seems like keeping it simple and minimizing unnecessary IoT exposure is the best bet. Just buy a clock!