My Most Likely Reason to Die Young is AI X-Risk
post by AISafetyIsNotLongtermist · 2022-07-04T17:08:27.209Z · LW · GW · 24 commentsThis is a link post for https://forum.effectivealtruism.org/posts/hJDid3goqqRAE6hFN/my-most-likely-reason-to-die-young-is-ai-x-risk
Contents
Introduction Analysis Caveats None 24 comments
Introduction
One of my pet peeves is people calling AI Safety a longtermist cause area. It is entirely [EA · GW] reasonable [EA · GW] to consider AI Safety a high priority cause area without putting significant value on future generations, let alone buying things like total utilitarianism or the astronomical waste arguments. Given fairly mainstream (among EAs) models of AI timelines and AI X-Risk, it seems highly likely that we get AGI within my lifetime, and that this will be a catastrophic/existential risk.
I think this misconception is actively pretty costly - I observe people introducing x-risk concerns via longtermism (eg in an EA fellowship) getting caught up in arguments over whether future people matter, total utilitarianism, whether expected value is the correct decision theory when using tiny probabilities and large utilities, etc. And people need to waste time debunking questions like ‘Is AI Safety a Pascal’s Mugging’. And yet, even if you convince people of these questions around longtermism, you still need to convince them of arguments around AI x-risk to get them to work on it.
I further think this is damaging, because the label ‘longtermist’ makes AI Safety seem like an abstract, far off thing. Probably not relevant to the world today, but maybe important to future generations, at some point, in the long-term future. And I think this is wildly incorrect. AI x-risk is a directly personal thing that will plausibly affect me, my loved ones, my community, and most people alive today. I think this is a pretty important motivator to some people to work on this - this is not some philosophical thought experiment that you only decide to work on if you buy into some particular philosophical assumptions. Instead, it entirely follows from common sense morality, so long as you buy a few empirical beliefs
To put this into perspective, I’m going to compare my probability of dying young from AI X-Risk to my probability of dying from other causes (operationalised as ‘probability of dying in the next 30 years). My headline result is that, as a 23 year old man living in the UK, conditional on dying in the next 30 years, the probability that I die due to AI x-risk is 41% (3.7% from AI, 5.3% from natural causes)
Analysis
The main point I want to make in this post is that ‘AI x-risk is a pressing concern for people alive today’ is an obvious consequence of mainstream EA beliefs. Accordingly, rather than using my personal models of this, I try to combine Ajeya Cotra’s timelines report and Joseph Carlsmith’s report on AI X-risk (the best research I know of on AGI timelines and AGI x-risk respectively) to get the probability.
To get the probability of dying from any other cause, I use UK actuarial tables (giving the probability of death from all-cause mortality in each year of life). Ideally I’d have taken the probability of death by cause, but that’s much harder to find data for. Any one cause is <=25% of all-cause mortality, so showing that AI x-risk is roughly competitive with all-cause mortality shows that it’s by far the most likely cause of death.
Concretely, I take the distribution of the probability of AGI in each year from Ajeya’s spreadsheet (column B in sheet 2); the probability of AI x-risk from Joseph’s report (section 8) - this is 7.9% conditioning on AGI happening; and the probability of dying each year from natural causes starting from my current age (in the UK). To get my headline result of 41%, I take the ratio of the cumulative probabilities in 2052
Over the next 40 years, this gets the following chart:
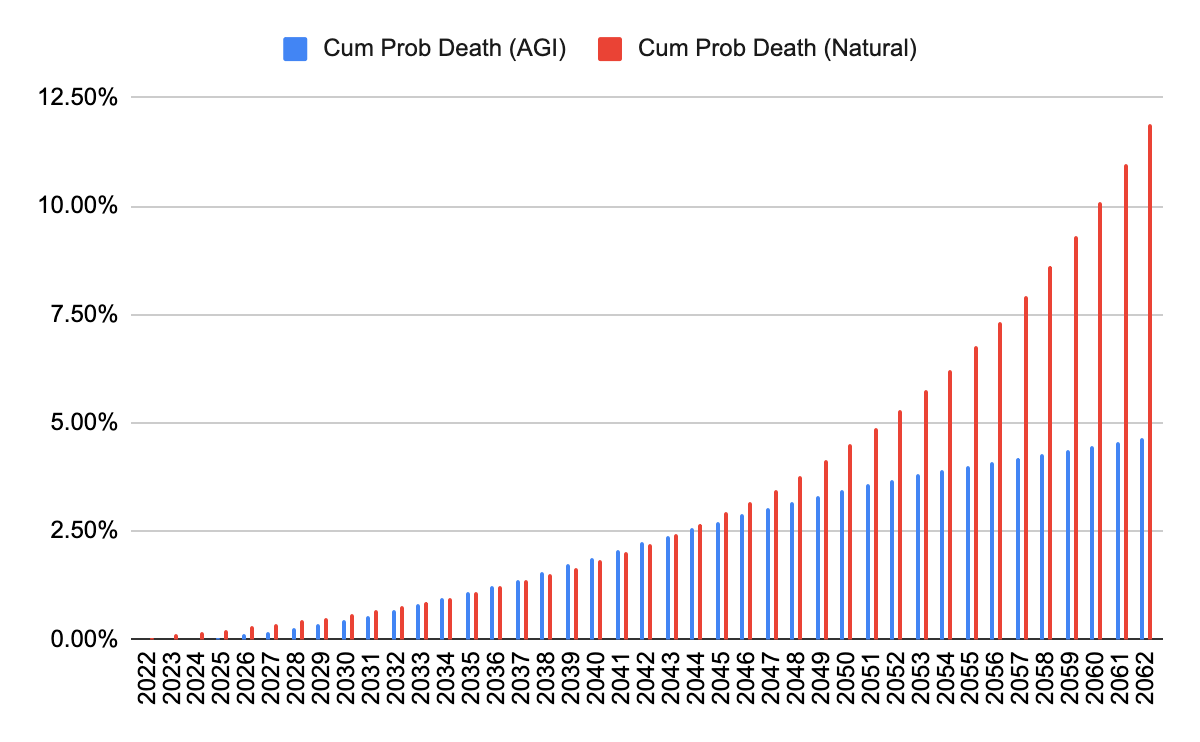
See my spreadsheet to play around with the numbers yourself.
Caveats
- The biggest caveat is that these numbers are plausibly biased pretty far upwards - I’ve seen basically no one outside of the EA community do a serious analysis on the question of AGI timelines or AGI x-risk, so the only people who do it are people already predisposed towards taking the issue seriously
- Another big caveat is that the numbers are juiced up heavily by the fact that I am conditioning on dying young - if I extend the timelines long enough, then probability of dying naturally goes to 100% while probability of dying from AI X-risk goes to 7.9%
- Is this enough to justify working on AI X-risk from a purely selfish perspective?
- Probably not - in the same way that it’s not selfish to work on climate change. The effect any one person can have on the issue is tiny, even if the magnitude that it affects any individual is fairly high.
- But this does help it appeal to my deontological/virtue ethics side - I am directly working on one of the world’s most pressing problems. This isn’t some abstract nerdy problem that’s an indulgence to work on over bednets, it’s a real danger to most people alive today, and something worthy and valuable to work on.
- My personal take is that the numbers used are too low, and this matches my sense of the median AI Safety researchers opinion. My personal rough guess would be 25% x-risk conditional on making AGI, and median AGI by 2040, which sharply increase the probability of death from AI to well above natural causes.
- If you take Yudkowsky-style numbers [LW · GW] you end up with even more ridiculous results, though IMO that take is wildly overblown and overly pessimistic.
- I’ve taken the 7.9% number from Joseph Carlsmith’s report, and assumed it’s the same, regardless of the year we get AGI. I expect it’s actually substantially higher with short timelines as we have less time to solve alignment.
- I’ve used actuarial tables for probability of death at each age today. I expect probability of death to go down over time with medical advances. In particular, if we do get close to AGI, I expect the rate of biotech advances to significantly accelerate.
- Does this mean that AI Safety is obviously the most important cause area even under a person-affecting view?
- Eh, probably not. You also need to think through tractability, cost effectiveness, what fraction of people alive today are alive by each time, etc. But I do expect it goes through if you just put some value on the long-term future (eg 2-10x the value of today), rather than 10^30 times more value.
Meta: I wrote this under a pseudonym because I mildly prefer this kind of post to not come up when you Google my name - I don’t expect it to be hard to de-anonymise me, but would rather people didn’t!
24 comments
Comments sorted by top scores.
comment by nostalgebraist · 2022-07-04T19:53:54.410Z · LW(p) · GW(p)
I think your spreadsheet's calculation is not quite right.
Your column "Cum Prob Death (Natural)" is computed correctly. For each marginal increment, you take the probability of natural death at that specific age ("Prob Death (Natural)"), and discount it by the probability of survival until that specific age.
However, you don't discount like this when computing "Cum Prob Death (AGI)." So it includes probability mass from timelines where you've already died before year Y, and treats you as "dying from AGI in year Y" in some of these timelines.
Once this is corrected, the ratio you compute goes down a bit, though it's not dramatically different. (See my modified sheet here.)
More importantly, I don't think this statistic should have any motivating force.
Dying young is unlikely, even granting your assumptions about AGI.
Conditional on the unlikely event of dying young, you are (of course) more likely to have died in the one of the ways young people tend to die, when they do.
So if you die young, your cause of death is unusually likely to be "AGI," or "randomly hit by a bus," as opposed to, say, "Alzheimer's disease." But why does this matter?
The same reasoning could be used to produce a surprising-looking statistic about dying-by-bus vs. dying-by-Alzheimer's, but that statistic should not motivate you to care more about buses and less about Alzheimer's. Likewise, your statistic should not motivate you to care more about dying-by-AGI.
Another phrasing: your calculation would be appropriate (for eg doing expected utility) if you placed no value on your life after 2052, while placing constant value on your life from now until 2052. But these are (presumably) not your true preferences.
Replies from: AISafetyIsNotLongtermist↑ comment by AISafetyIsNotLongtermist · 2022-07-05T09:23:59.104Z · LW(p) · GW(p)
Re cumulative probability calculations, I just copied the non-cumulative probabilities column from Ajeya Cotra's spreadsheet, where she defines it as the difference between successive cumulative probabilities (I haven't dug deeply enough to know whether she calculates cumulative probabilities correctly). Either way, it makes fairly little difference, given how small the numbers are.
Re your second point, I basically agree that you should not work on AI Safety from a personal expected utility standpoint, as I address in the caveats. My main crux for this is just the marginal impact of any one person is miniscule. Though I do think that dying young is significantly worse than dying old, just in terms of QALY loss - if I avoid dying of Alzheimers, something will kill me soon after, but if I avoid dying in a bus today, I probably have a good 60 years left. I haven't run the numbers, but expect that it does notably reduce life expectancy for a young person today.
My goal was just to demonstrate that AI Safety is a real and pressing problem for people alive today, and that discussion around longtermism elides this, in a way that I think is misleading and harmful. And I think 'most likely reason for me to die young' is an emotionally visceral way to demonstrate that. The underlying point is just kind of obvious if you buy the claims in the reports, and so my goal here is not to give a logical argument for it, just to try driving that point home in a different way.
Replies from: Vladimir_Nesov, TekhneMakre↑ comment by Vladimir_Nesov · 2022-07-05T17:57:56.295Z · LW(p) · GW(p)
in terms of QALY loss
Note that if AI risk doesn't kill you, but you survive to see AGI plus a few years, then you probably get to live however long you want, at much higher quality, so the QALY loss from AI risk in this scenario is not bounded by the no-AGI figure.
↑ comment by TekhneMakre · 2022-07-05T14:14:50.431Z · LW(p) · GW(p)
So then it is a long-termist cause, isn't it? It's something that some people (long-termists) want to collaborate on, because it's worth the effort, and that some people don't. I mean, there can be other reasons to work on it, like wanting your grandchildren to exist, but still.
Replies from: Ikaxas↑ comment by Vaughn Papenhausen (Ikaxas) · 2022-07-05T21:39:17.337Z · LW(p) · GW(p)
I think the point was that it's a cause you don't have to be a longtermist in order to care about. Saying it's a "longtermist cause" can be interpreted either as saying that there are strong reasons for caring about it if you're a longtermist, or that there are not strong reasons for caring about it if you're not a longtermist. OP is disagreeing with the second of these (i.e. OP thinks there are strong reasons for caring about AI risk completely apart from longtermism).
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-07-06T04:50:15.262Z · LW(p) · GW(p)
The whole point of EA is to be effective by analyzing the likely effects of actions. It's in the name. OP writes:
Is this enough to justify working on AI X-risk from a purely selfish perspective?
Probably not - in the same way that it’s not selfish to work on climate change. The effect any one person can have on the issue is tiny, even if the magnitude that it affects any individual is fairly high.
But this does help it appeal to my deontological/virtue ethics side [...]
I don't think one shouldn't follow one's virtue ethics, but I note that deontology / virtue ethics, on a consequentialist view, are good for when you don't have clear models of things and ability to compare possible actions. E.g. you're supposed to not murder people because you should know perfectly well that people who conclude they should murder people are mistaken empirically; so you should know that you don't actually have a clear analysis of things. So as I said, there's lots of reasons, such as virtue ethics, to want to work on AI risk. But the OP explicitly mentioned "longtermist cause" in the context of introducing AI risk as an EA cause; in terms of the consequentialist reasoning, longtermism is highly relevant! If you cared about your friends and family in addition to yourself, but didn't care about your hypothetical future great-grandchildren and didn't believe that your friends and family have a major stake in the long future, then it still wouldn't be appealing to work on, right?
If by "virtue ethics" the OP means "because I also care about other people", to me that seems like a consequentialist thing, and it might be useful for the OP to know that their behavior is actually consequentialist!
Replies from: AISafetyIsNotLongtermist↑ comment by AISafetyIsNotLongtermist · 2022-07-06T12:59:18.727Z · LW(p) · GW(p)
To be clear, I work on AI Safety for consequentialist reasons, and am aware that it seems overwhelmingly sensible from a longtermist perspective. I was trying to make the point that it also makes sense from a bunch of other perspectives, including perspectives that better feed in to my motivation system. It would still be worth working on even if this wasn't the case, but I think it's a point worth making.
comment by Ben Pace (Benito) · 2022-07-04T21:02:51.340Z · LW(p) · GW(p)
As a side-point about usernames, I personally don't like it when people pick usernames to signal a position in local political tugs-of-war (of which debates about messaging around AI safety is a central case).
Then every time I see them comment anywhere else, it feels like they defined themself by one little political fight they wanted to win, and reminds everyone that maybe they too have a tribal side on that, and moves the whole site toward tribalism.
For the record I would not mind anywhere near as much usernames that were staking out positions that pulled-the-rope-sideways, for example if a username was "AcronymsSeriouslySuck" or "RepealTheDredgeAct" or "GasStovesCostYouEightWeeksOfLifeInExpectation". That would feel much cuter to me.
Replies from: AISafetyIsNotLongtermist↑ comment by AISafetyIsNotLongtermist · 2022-07-05T09:14:37.445Z · LW(p) · GW(p)
Fair! I made a throwaway pseudonym I don't anticipate using elsewhere, but this seems like a reasonable criticism of the pseudonym choice.
comment by Sherrinford · 2022-07-08T09:20:20.742Z · LW(p) · GW(p)
"My personal rough guess would be 25% x-risk conditional on making AGI, and median AGI by 2040, which sharply increase the probability of death from AI to well above natural causes."
Could you please link to any plausible depiction of what the other 75% look like? I am always a bit puzzled by this and would like to know more.
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-08T10:04:29.953Z · LW(p) · GW(p)
I can't answer for AISafetyIsNotLongtermist but I have similar (more optimistic) AI-risk forecasts. I can see four possible futures:
- AGI does not arrive in our lifetimes
- Utopia
- Human extinction or s-risk due to misalignment
- AI is aligned, but aligned to some very bad people who either kill large numbers of people or oppress us in some way.
The bulk of the probability mass is on Utopia for me. Future #1is always a possibility, and this community could be doing more to grow that possibility, since it is far far preferable to #3 and #4.
Replies from: Vladimir_Nesov, florin-clapa, Sherrinford↑ comment by Vladimir_Nesov · 2022-07-09T18:12:05.501Z · LW(p) · GW(p)
I think an important distinction is one you don't make, where humans remain alive, but lose cosmic endowment. AGIs are probably not starting out as mature optimizers [LW · GW], so their terminal values are going to follow from a process of volition extrapolation, similar to that needed for humans. If they happen to hold enough human values from training on texts and other media, and don't get tuned into something completely alien, it's likely they at least give us some computational welfare sufficient for survival.
A less likely possibility is that somehow processes of volition extrapolation converge across different humans/AGIs to some currently illegible generic [LW(p) · GW(p)] terminal [LW(p) · GW(p)] values [LW(p) · GW(p)], in which case AGIs' use of cosmic endowment is going to be valuable to humanity's CEV as well, and human people are more likely to meaningfully participate.
↑ comment by Florin (florin-clapa) · 2022-07-09T00:23:30.599Z · LW(p) · GW(p)
#1 is a double-edged sword; it might help avoid #3 and #4 but might also avoid #2 (immortality). Although x-risk might be lower, billions will still suffer and die (assuming human-created medicine doesn't progress fast enough) in a present and future similar to #3. OTOH, future humanity might run resurrection sims to "rescue" us for our current #3 situation. However, I don't know if these sims are even possible for technical and philosophical reasons. From a self-preservation perspective, whether #1 is good or bad overall is not at all clear to me.
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-09T08:23:31.743Z · LW(p) · GW(p)
From a selfish perspective, sure let's shoot for immortality in utopia. From a selfless perspective, I think it's hard to argue that the earth should be destroyed just so that the people alive today can experience utopia, especially if we think that utopia will come eventually if we can be patient for a generation or two.
↑ comment by Sherrinford · 2022-07-08T10:22:47.870Z · LW(p) · GW(p)
Okay, but does the Utopia option rest on more than a vague hope that alignment is possible? Is there something like an understandable (for non-experts) description of how to get there?
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-09T08:19:41.161Z · LW(p) · GW(p)
It sounds like your intuition is that alignment is hard. My view is that both corrigibility and value alignment are easy, much easier than general autonomous intelligence. We can't really argue over intuitions though.
Replies from: TekhneMakre, Sherrinford↑ comment by TekhneMakre · 2022-07-09T12:21:32.542Z · LW(p) · GW(p)
Why is your view that corrigibility is easy?
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-09T12:57:51.597Z · LW(p) · GW(p)
The way I see it, the sort of thinking that leads to pessimism about alignment starts and ends with an inability to distinguish optimization from intelligence. Indeed, if you define intelligence as "that which achieves optimization" then you've essentially defined for yourself an unsolvable problem. Fortunately, there are plenty of forms of intelligence that are not described by this pure consequentialist universalizing superoptimization concept (ie Clippy).
Consider a dog: a dog doesn't try to take over the world, or even your house, but dogs are still more intelligent (able to operate in the physical world) than any robot, and dogs are also quite corrigible. Large numbers of humans are also corrigible, although I hesitate to try to describe a corrigible human because that will get into category debates that aren't useful for what I'm trying to point at. My point is just that corrigibility is not rare, at any level of intelligence. I was trying to make this argument with my post The Bomb that doesn't Explode [LW · GW] but I don't think I was clear enough.
Replies from: TekhneMakre, TAG↑ comment by TekhneMakre · 2022-07-09T13:19:21.763Z · LW(p) · GW(p)
Dogs and humans also can't be used to get much leverage on pivotal acts.
A pivotal act, or a bunch of acts that add up to being pivotal, imply that the actor was taking actions that make the world end up some way. The only way we currently know to summon computer programs that take actions that make the world end up some way, is to run some kind of search (such as gradient descent) for computations that make the world end up some way. The simple way to make the world end up some way, is to look in general for actions that make the world end up some way. Since that's the simple way, that's what's found by unstructured search. If a computer program makes the world end up some way by in general looking for and taking actions that make that happen, and that computer program can understand and modify itself, then, it is not corrigible, because corrigibility is in general a property that makes the world not end up the way the program is looking for actions to cause, so it would be self-modified away.
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-09T13:32:36.890Z · LW(p) · GW(p)
A robot with the intelligence and ability of a dog would be pretty economically useful without being dangerous. I'm working on a post to explore this with the title "Why do we want AI?"
To be honest, when you talk about pivotal acts, it looks like you are trying to take over the world.
Replies from: TekhneMakre↑ comment by TekhneMakre · 2022-07-09T14:44:33.886Z · LW(p) · GW(p)
Not take over the world, but prevent pivot unaligned incorrigible AI from destroying the world.
↑ comment by Sherrinford · 2022-07-09T17:57:51.976Z · LW(p) · GW(p)
Well, to be clear, I am not at all an expert on AI alignment - my impression from reading about the topic is that I find reasons for the impossibility of alignment agreeable while I did not yet find any test telling me why alignment should be easy. But maybe I'll find that in your sequence, once that it consists of more posts?
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2022-07-09T18:35:41.177Z · LW(p) · GW(p)
Perhaps! I am working on more posts. I'm not necessarily trying to prove anything though, and I'm not an expert on AI alignment. Part of the point of writing is so that I can understand these issues better myself.